1. Introduction
A micro-expression is a human emotion expressed briefly, spontaneously, and unwillingly. Usually, there are emotions that people desire to keep hidden for a variety of reasons. Due to their subtlety and spontaneity, it is harder to conceal micro-expressions than to repress fake long-duration expressions. As a result, it is very difficult for a human to spot micro-expressions at a glance. However, slow-motion capturing of these micro-expressions using high-speed digital cameras allows us to play back the video for analysis purposes. In the early period of micro-expressions analysis systems development, handcrafted feature extraction techniques such as Histogram of Oriented Gradient (HOG) [
1], Main Directional Mean Optical flow (MDMO) [
2], Bi-Weighted Oriented Optical Flow (Bi-WOOF) [
3], and Local Binary Pattern with Three Orthogonal Planes (LBP-TOP) [
4] were used to extract the spatio-temporal information used for the automated recognition. In addition, all these conventional machine learning techniques are heavily dependent on designer experience in extracting the optimal set of features [
5]. As the machine learning technology becomes more mature, researchers have turned to convolutional neural networks (CNNs) to extract the optimal set of features needed for micro-expression-based emotion classification.
The classification of emotions using micro-expressions is a challenging task due to the issue of multi-scale in muscle movements among the subjects. Some subjects have a broader facial structure and hence, the muscle movements expressed by them affect wider areas, especially around the mouth and eyes. On the other hand, some subjects have a slimmer facial structure or smaller eyes, which will result in different movement patterns, thence creating variable size challenges to the recognition system. To reduce the facial size issue, all input images were resized and cropped to a standard format, in which only a region of interest from each subject will be processed by the system. The standardized facial region is readily available from each of the tested datasets. Yet, the size of the affected muscle movement areas cannot be standardized, especially when multi-datasets of various subject backgrounds are used for validation.
Figure 1 shows a few subjects that express a happy emotion, whereby they produce different movement intensity around the mouth regions. In this example, subject 3 produces bigger facial muscle movements compared to subjects 1 and 2. It is also observable that the subjects have different facial structures, which cause different patterns in the muscle excitation, which can be addressed by embedding multi-scale capability in the deep network.
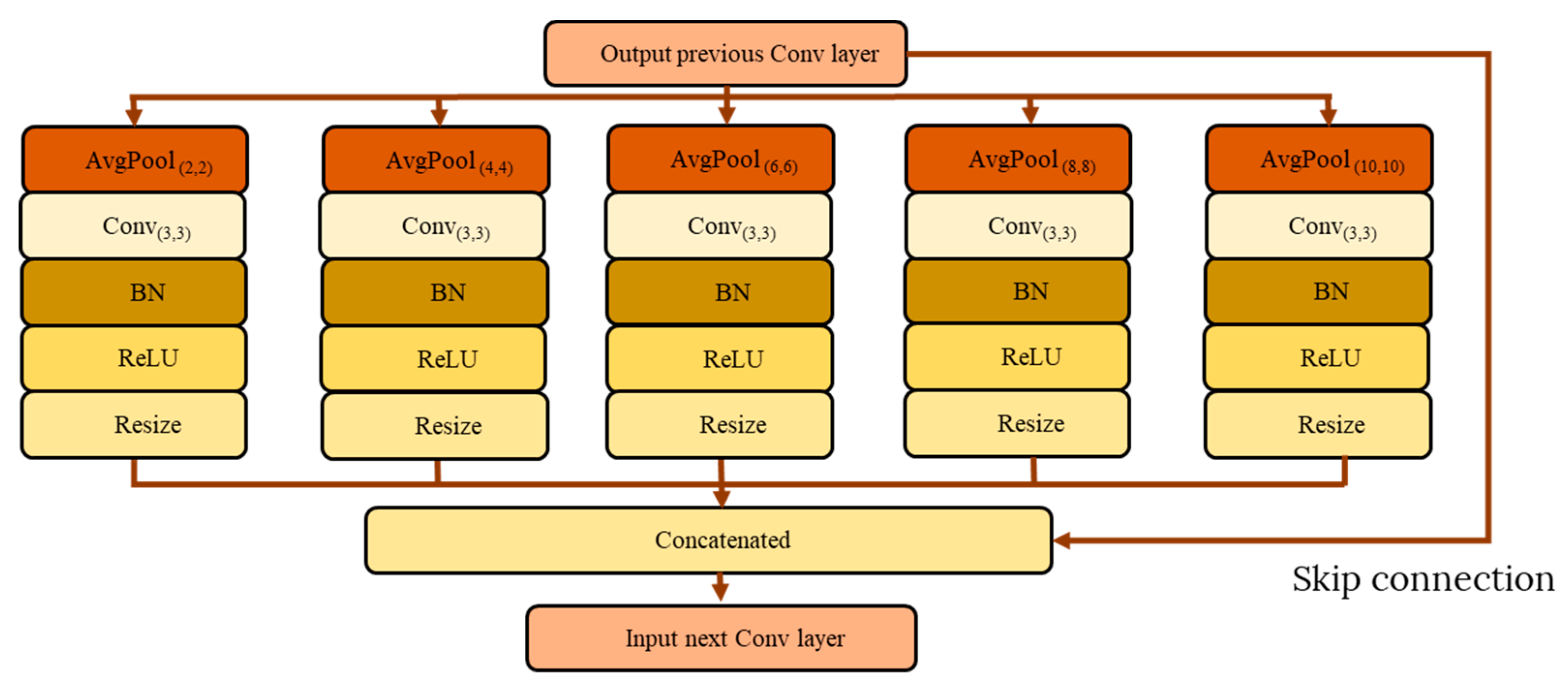
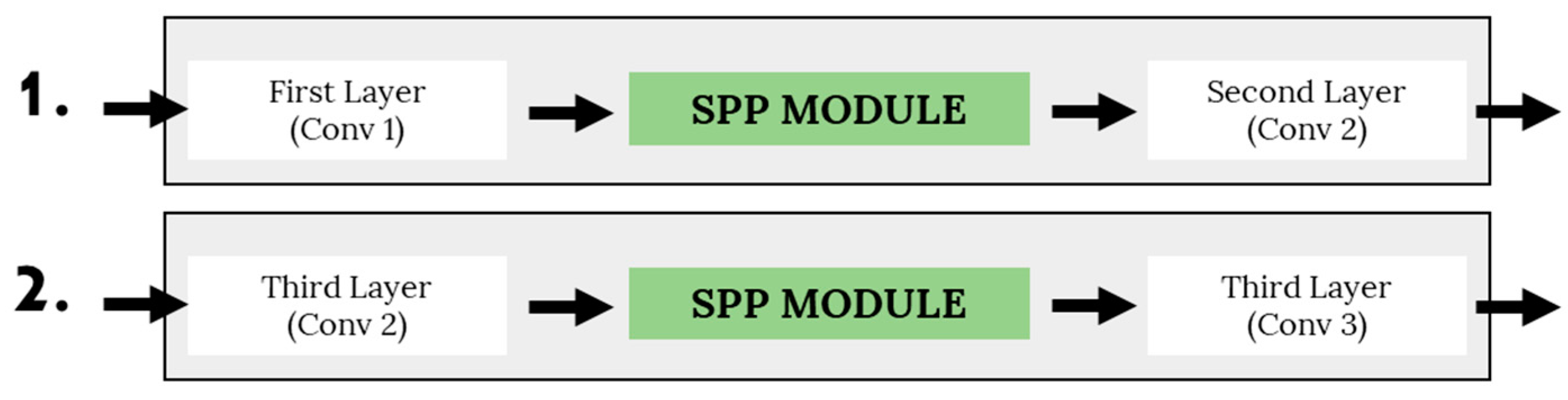
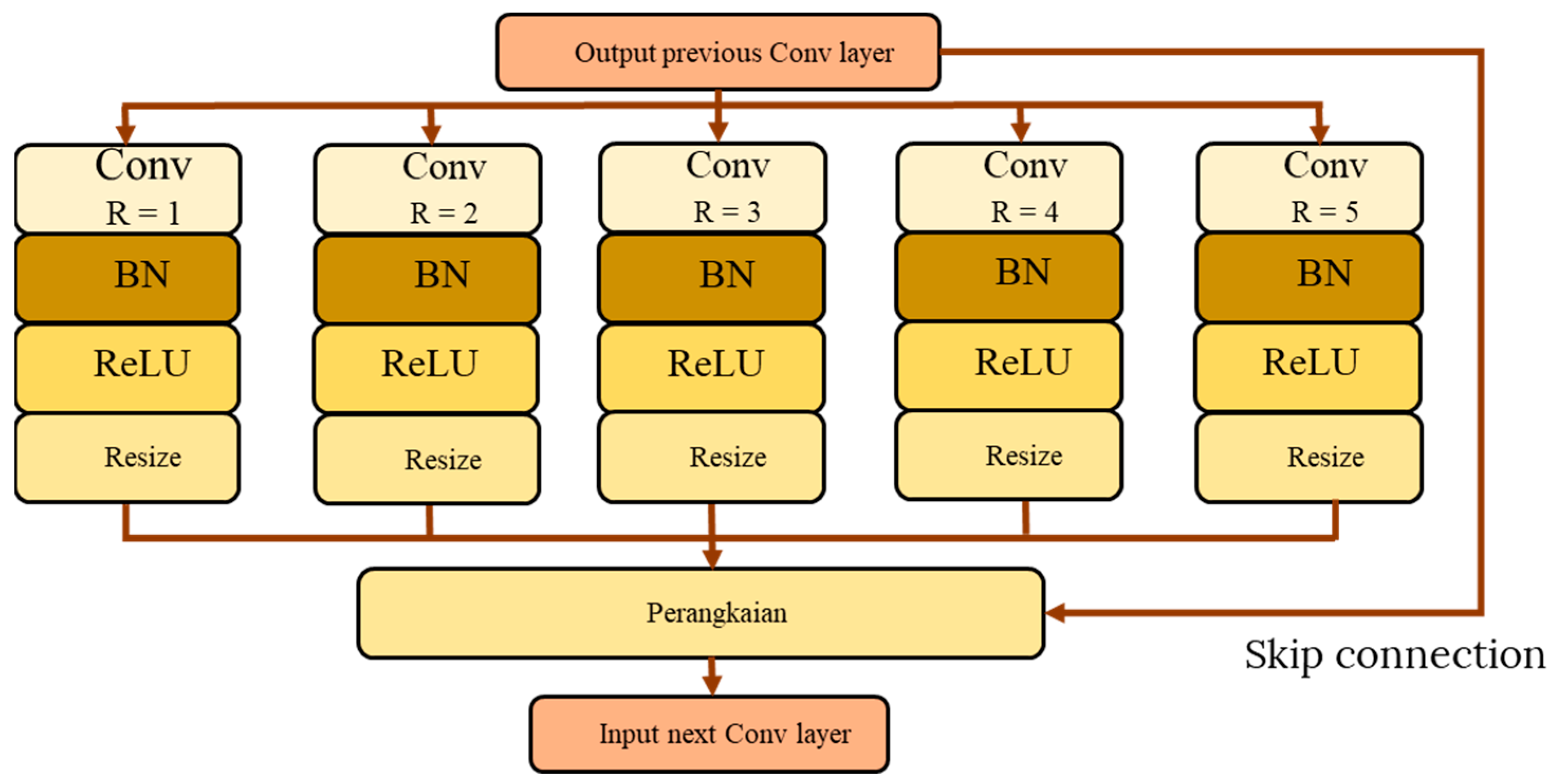
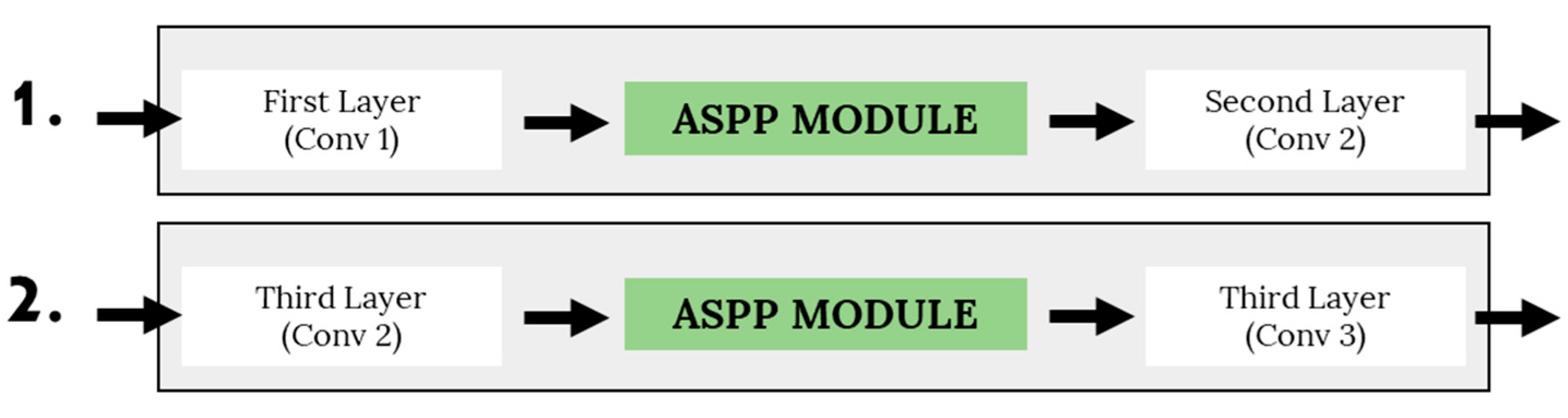
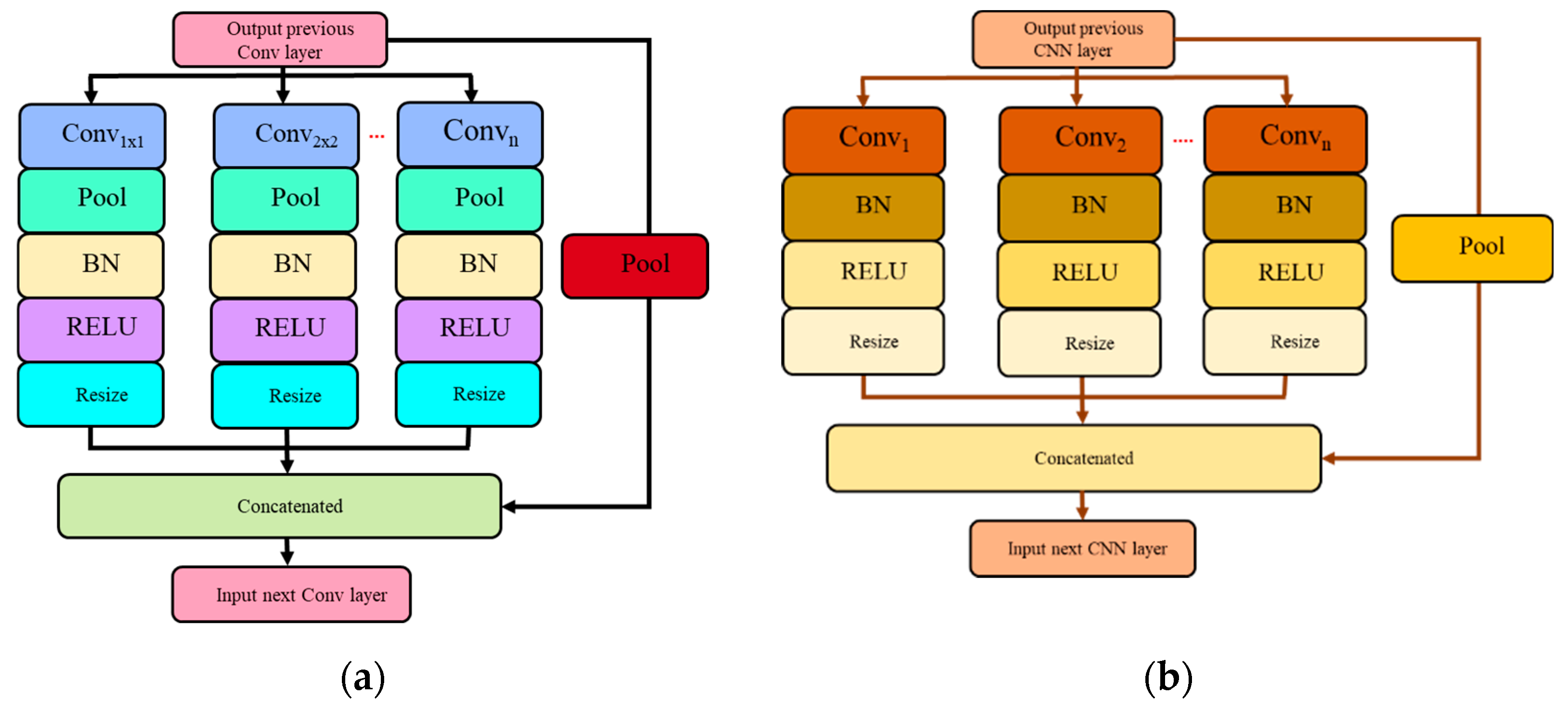
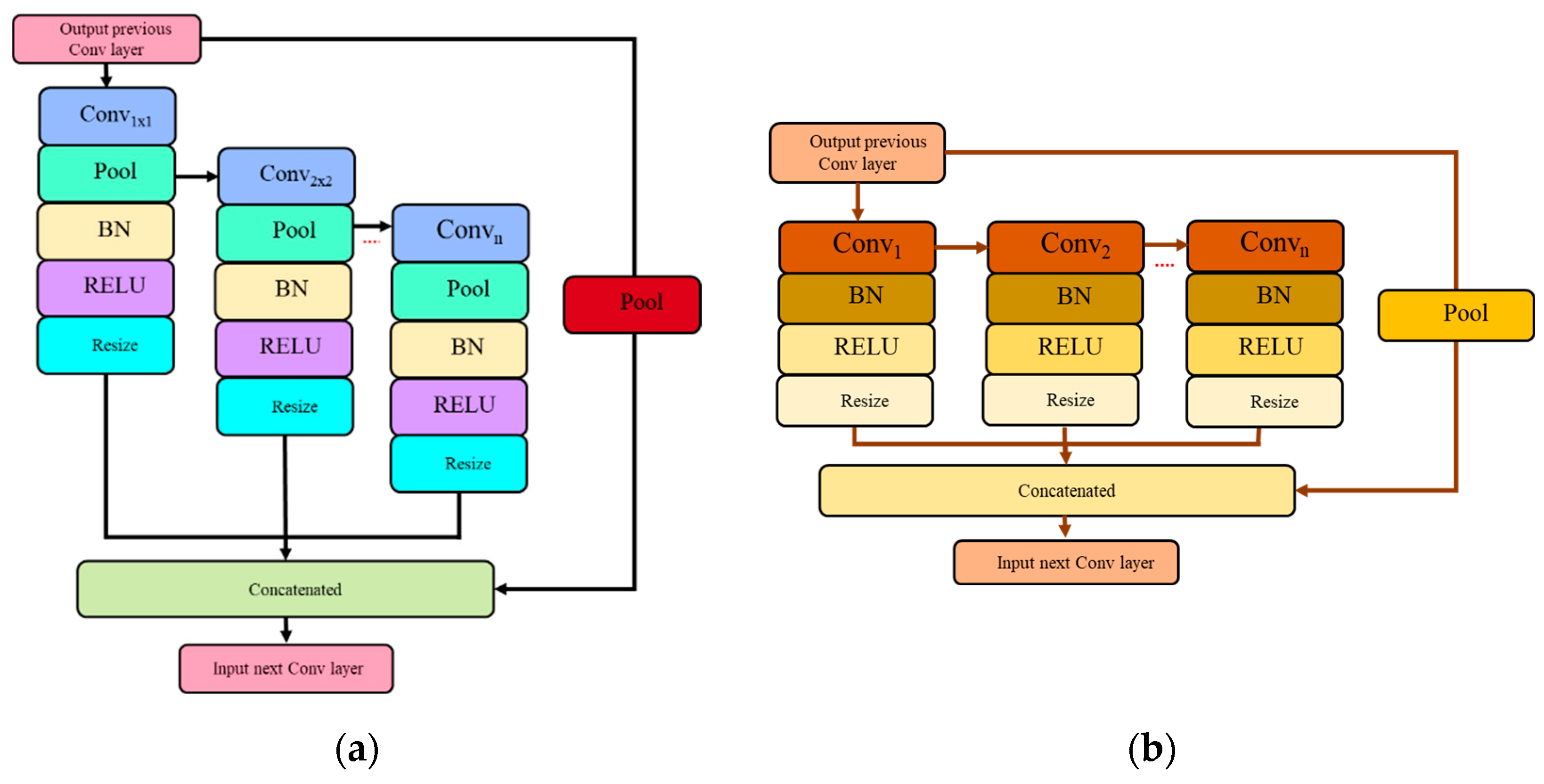
Therefore, multi-scale embedding in the CNN network was recently explored by Sian et al. [
6] through simple insertion of the Spatial Pyramid Pooling (SPP) module. However, the authors only tested a basic SPP using two sets of down-pooling kernels using a fixed number of parallel paths. Even more, the multi-scale unit is inserted into the original architecture of VGG-M without modifications or network optimization. In addition to that, they have not explored other multi-scale network configurations apart from the SPP unit. To overcome their suggested work limitations, we analyze and design a comprehensive multi-scale unit addition to a compact network. Two multi-scale approaches are explored that include the SPP and Atrous Spatial Pyramid Pooling (ASPP), which will be optimized in terms of unit placement, number of parallel paths, and down-pooling kernel sets. In addition, we also analyze the network flow of the multi-scale unit through direct and waterfall methodology to produce the best emotion recognition based on micro-expression input cues. Therefore, the following are main contributions of this paper: (i) optimize multi-scale approaches by exploring the optimal position and parallel branches for the SPP and ASPP module, (ii) optimize network flows—either direct or waterfall flows.
The proposed multi-scale networks are discussed in five sections, whereby the following
Section 2 provides an overview of various related works, while
Section 3 describes the technical details used to classify the emotions using facial micro-expression cues, which also include all the proposed architecture variants.
Section 4 discusses the results of the emotion classification experiments, followed by
Section 5 which concludes the findings and some plans for future work.
2. Recent Works
In general, micro-expression recognition systems are separated into two modules: spotting the maximum instantaneous changes in facial expressions and classifying the emotion behind the spotted micro-expression frame. The spotting approach assumes that a single frame information, which is the apex frame, is enough to detect the right emotion. On the other hand, if a long-video format is used, the spotting module aims to recognize three crucial frames, namely the onset, apex, and offset frames, which are then used to detect the presence of micro-expressions.
In ref. [
7], Davison et al. detected micro-expressions via histogram-oriented gradient by labeling the frames as the true positive detection if the frame sequence is less than 100 frames, which also includes noise issues from video flicker and fixation. Then, a false positive case is identified when the detected motion sequence is not encoded into the respective class. Their simulation results, which were tested on the SAMM database, produced accuracy, Recall Rate, and F1 score of 0.70, 0.84, and 0.76, respectively. According to the research in ref. [
8], the combination of optical strain and optical flow magnitudes can further improve the performance of automated emotion recognition using micro-expressions, which have been verified using both SMIC and CASME II datasets. In ref. [
2], Liu et al. employed a unique optical flow technique known as MDMO to better extract the textural information of the images. Then, an affine transformation was used to eliminate any subtlety of illumination and head motions. The facial areas were also subdivided into several regions of interest (ROIs), which were then fed to an SVM classifier to detect the genuine emotion class. One of the papers that popularizes the usage of the apex frame as the sole input for emotion classification is the work by Liong et al. [
3]. They utilized the Bi-WOOF method to extract the important features in the apex frame. Then, OffApexNet was proposed in ref. [
9] as a hybrid approach, whereby this network employs two frames of information to represent the micro-expression: onset and apex frames. Then, the computed optical flow features from these two frames were passed to a CNN model for optimal feature extraction.
Deep learning has shown promising results in various domains of study in recent years [
10,
11,
12], and it has also been used successfully in micro-expression recognition. Kim et al. [
13] proposed a combination between CNN and long short-term memory (LSTM) to capture the spatio-temporal information in a video to locate and recognize micro-expressions. The spatial features of facial expressions were first analyzed using CNN that covers all expressions, which are then passed to the LSTM to extract temporal relationships of the CNN inputs. Khor et al. [
14] presented a unique CNN-LSTM model through the Enriched Long-Term Recurrent Convolutional Network (ELRCN). Their approach utilized both optical flow and optical strain characteristics as the inputs to model the minute facial muscle movements. This combination of CNN-LSTM has been proven to be robust in extracting both the optimal temporal and spatial features from the tested videos [
15,
16,
17]. After the features were extracted, the emotion was categorized using a conventional machine learning approach through Support Vector Machines (SVM). For micro-expression recognition, Shaheen et al. [
18] proposed a framework for an emotion recognition system that treats emotions as generalized ideas abstracted from sentences by incorporating compositional, syntactic, and semantic analysis. Erenel et al. [
19] developed and compared a new feature selection approach for emotion classification to various feature reduction techniques, including chi-square, Gini-text, and delta. The proposed approach, known as the relevance score, was shown to improve emotion classification.
Peng et al. [
20] suggested a dual-template CNN model based on the optical flows extracted from successive micro-expression sequences. However, extracting their multiple optical flow input requires much computation, which significantly reduces the dual-template CNN model’s efficiency. The optical flow data from the entire video need to be retrieved first before they are supplied to the CNN feature extractor. Then, a new automated micro-expression analysis technique, which is called Flownet 2.0 [
21], was used by Li et al. [
22] to improve a dual-template CNN model performance, yet the performance is still inferior to the conventional approaches [
23]. Kumar et al. [
24] then employed a method based on frequency domain to delete low-intensity expression frames. In their paper, the frames with the least amount of texture variance are defined as the low-intensity frames. Significant motion will magnify the emotion image that was created from the remaining high-intensity frames. The emotions are then classified by passing through all these high-intensity frames into the respective CNN model. SPP was initially introduced by He et al. [
25], and has been effectively applied to various semantic segmentation tasks [
26], anti-spoofing applications [
27], expression analysis systems [
6], and many other automated systems in the computer vision literature. Meanwhile, ASPP was originally proposed by Chen et al. [
28], and demonstrated success in a range of works that include object detection [
29], image segmentation [
30,
31], image classification [
32], etc.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}