
A Framework for Trajectory Prediction of Preceding Target Vehicles in Urban Scenario Using Multi-Sensor Fusion


Abstract
:1. Introduction
- (1)
- Most trajectory prediction algorithms are validated by public datasets that provide the location directly. Therefore, the whole process of vehicle trajectory prediction cannot be systematically considered. We come up with a framework for PTV’s trajectory prediction using the real driving process collected from LIDAR, camera, and combined inertial navigation system fusion.
- (2)
- Vehicle trajectory prediction algorithms based on LSTM and its variants are difficult to model due to complex temporal dependencies. Therefore, the other contribution is two different transformer-based methods built to the PTV’s future trajectory.
2. Related Work
3. Sensors Fusion and History Trajectory Generation
3.1. Detection
3.2. Tracking
3.3. Lidar-Camera Fusion
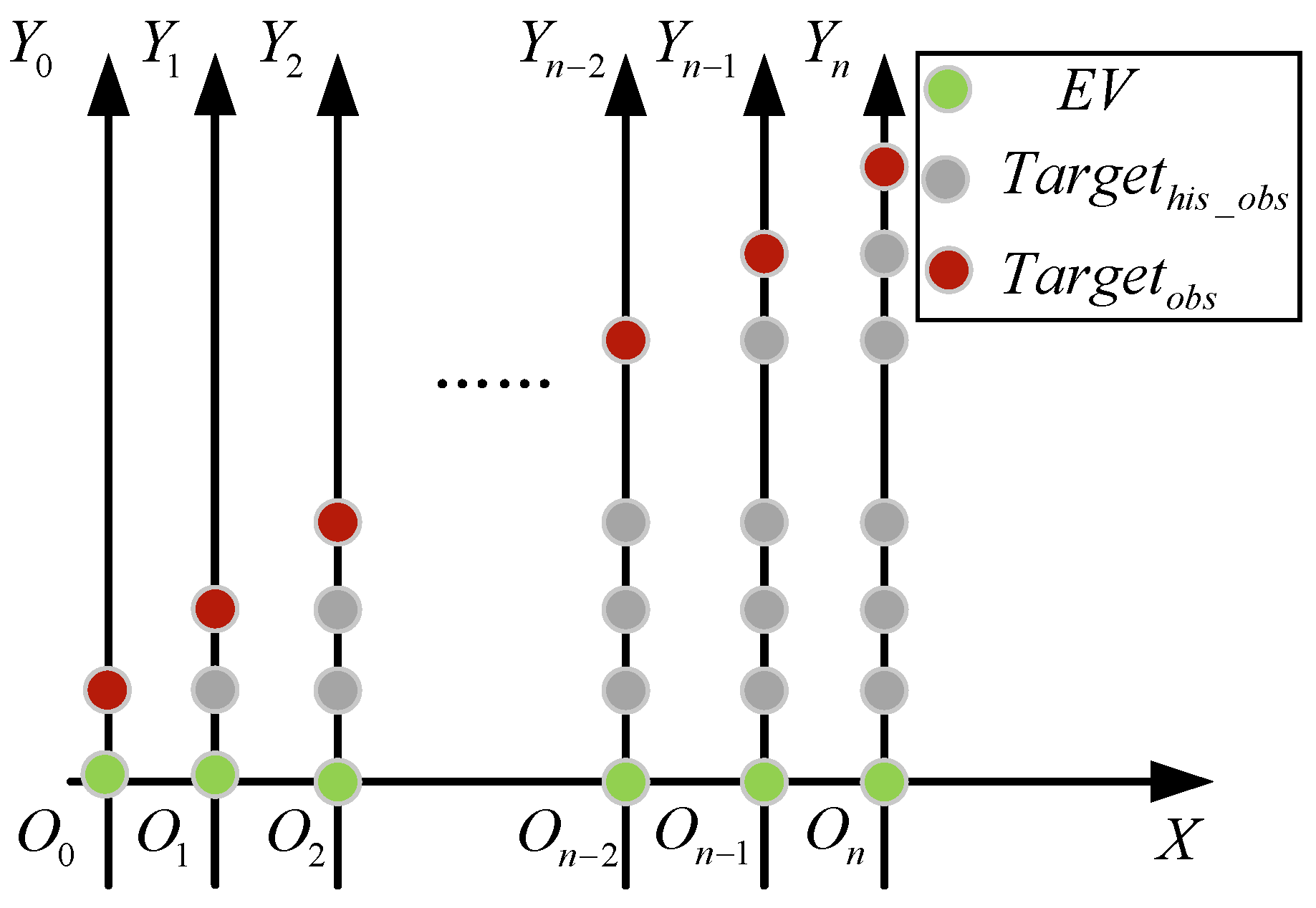
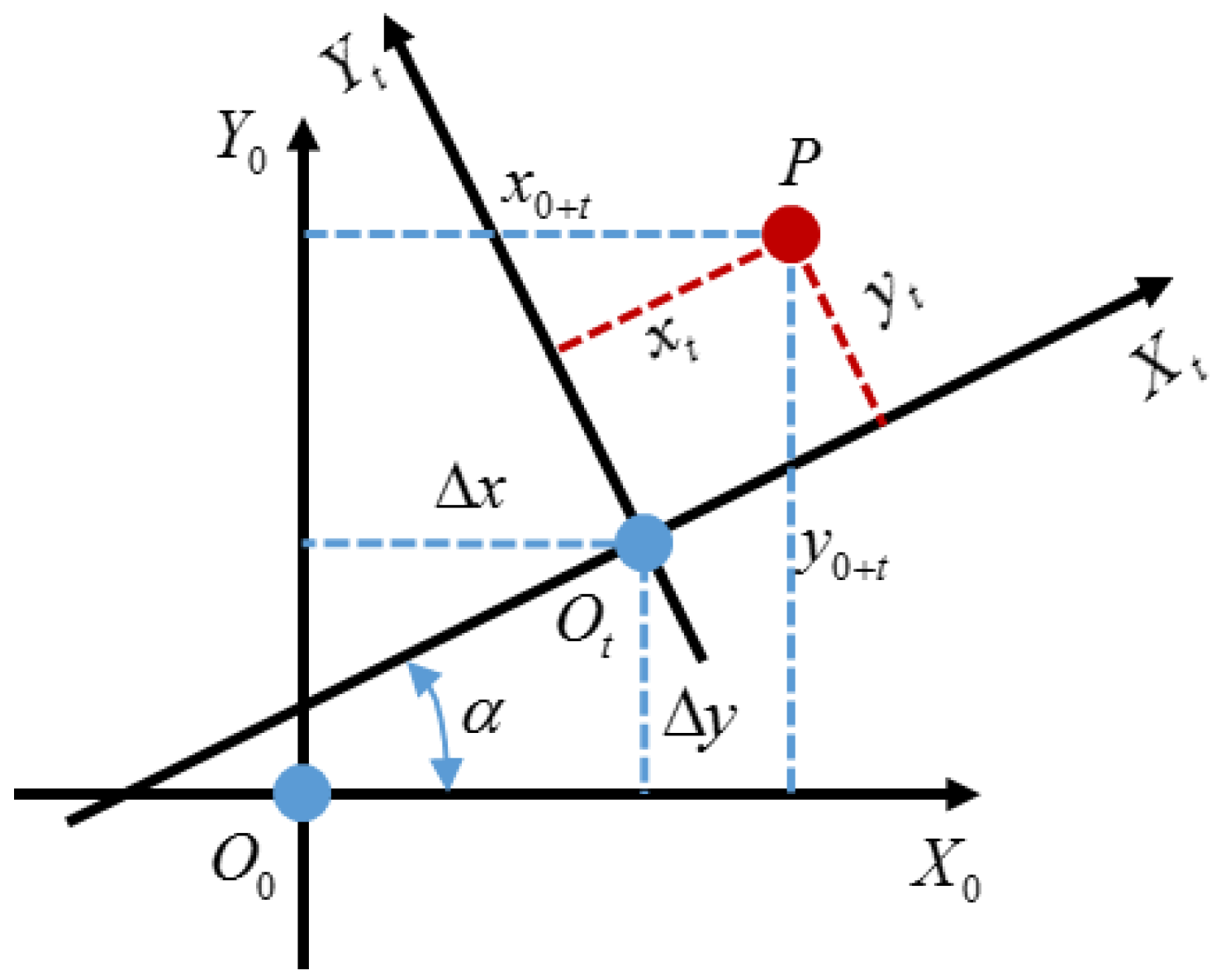
3.4. History Trajectory Generation
4. Proposed Model
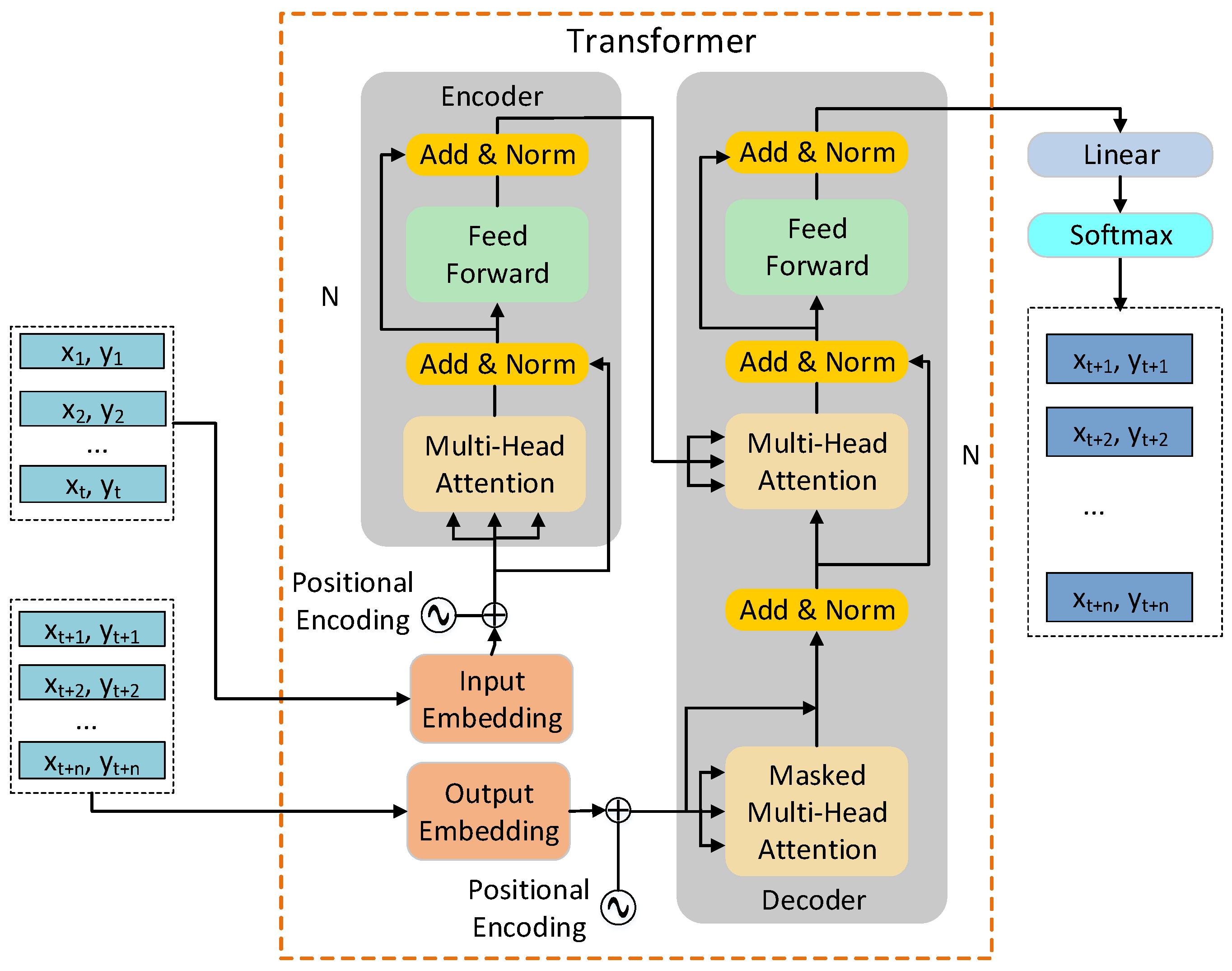
4.1. Transformer Network
4.1.1. Self-Attention Mechanism
4.1.2. Multi-Head Attention Mechanism
4.1.3. Feed-Forward Networks
4.1.4. Positional Encoding
4.2. TF Model
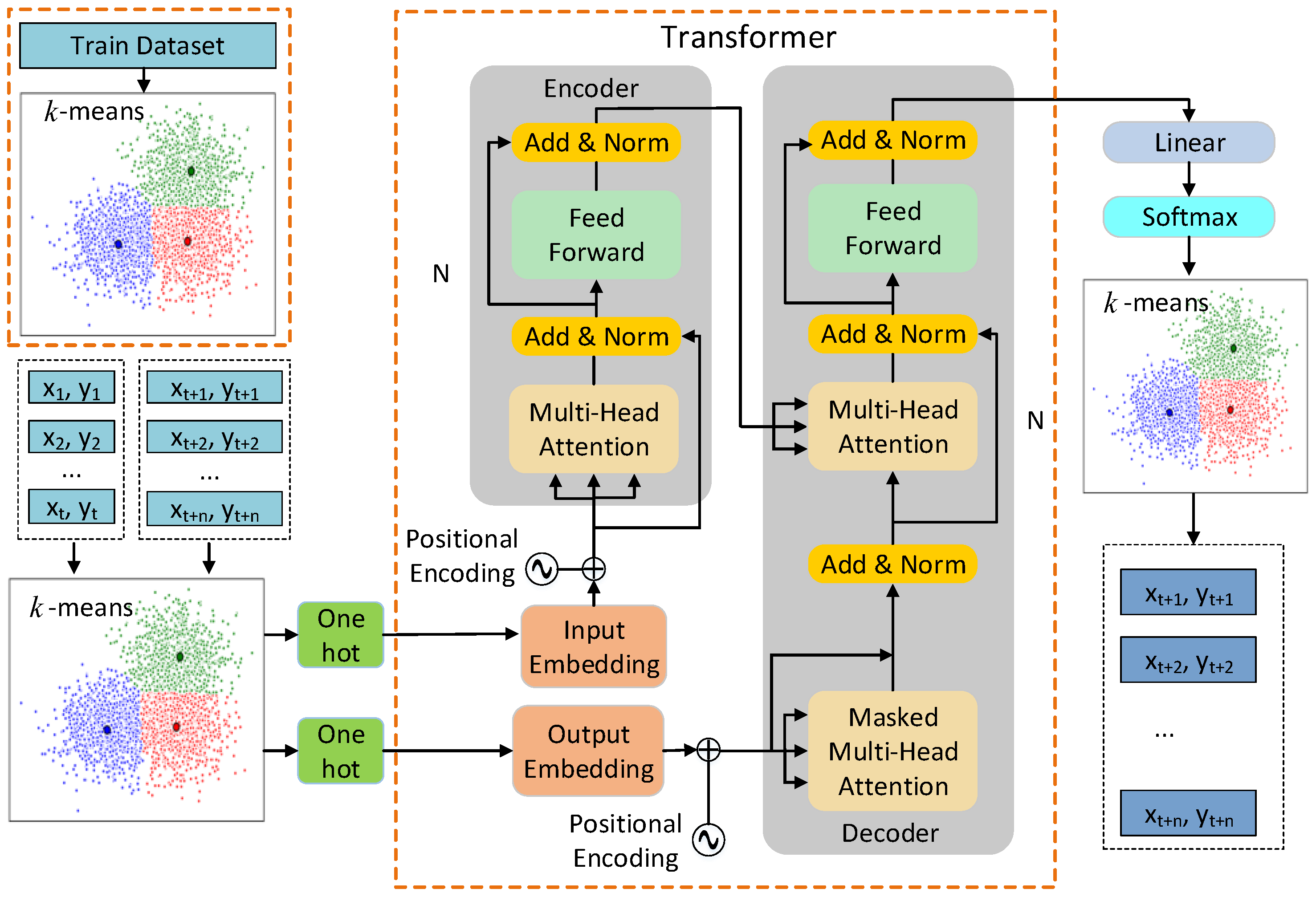
4.3. C-TF Model
5. Experiment and Result Analysis
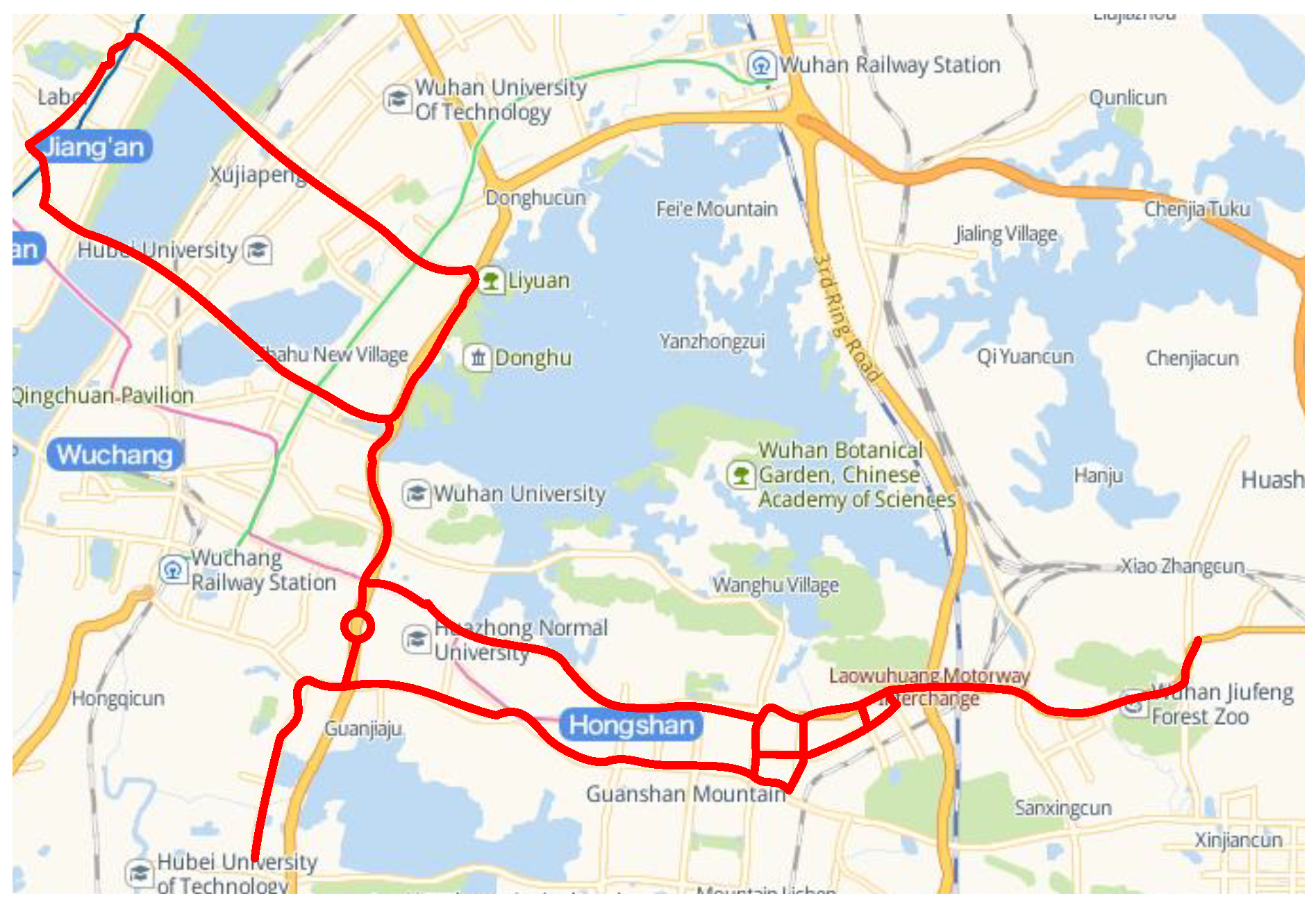
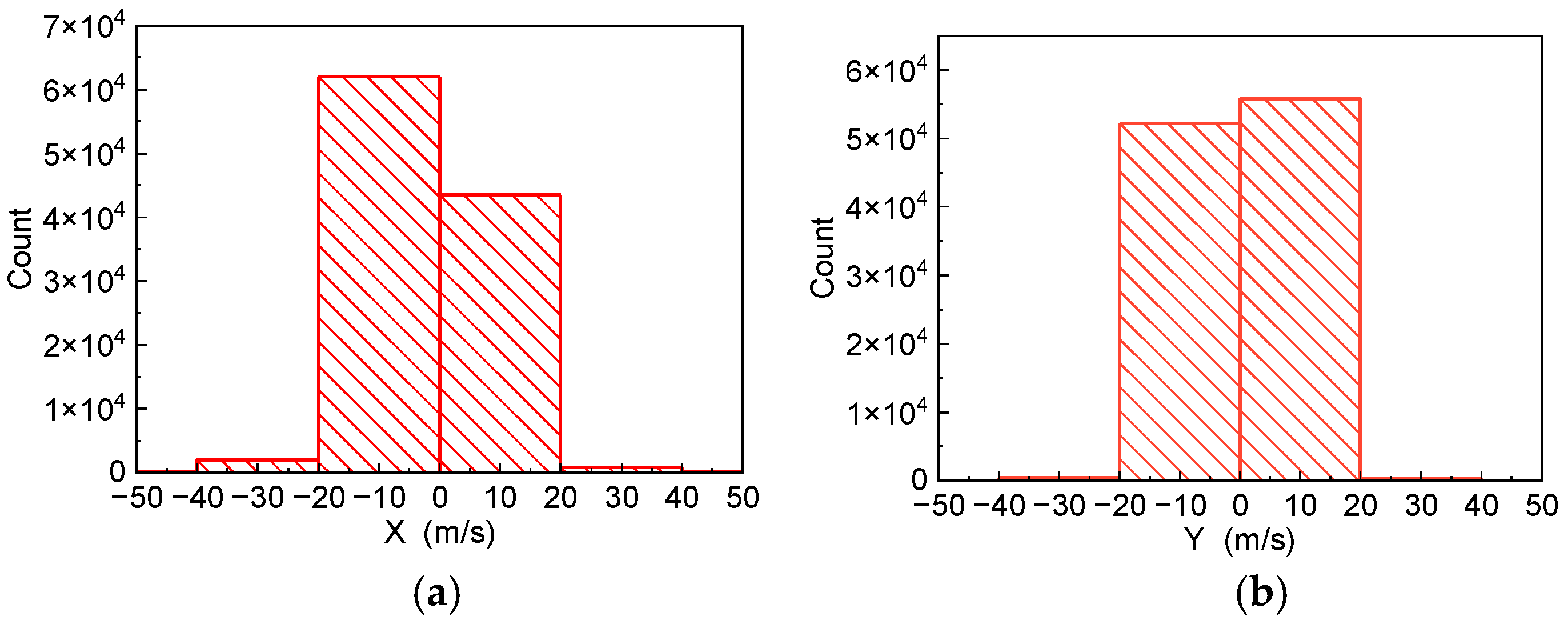
5.1. Driving Data Collection
5.2. Implementation Details
5.3. Evaluaiton Metrics
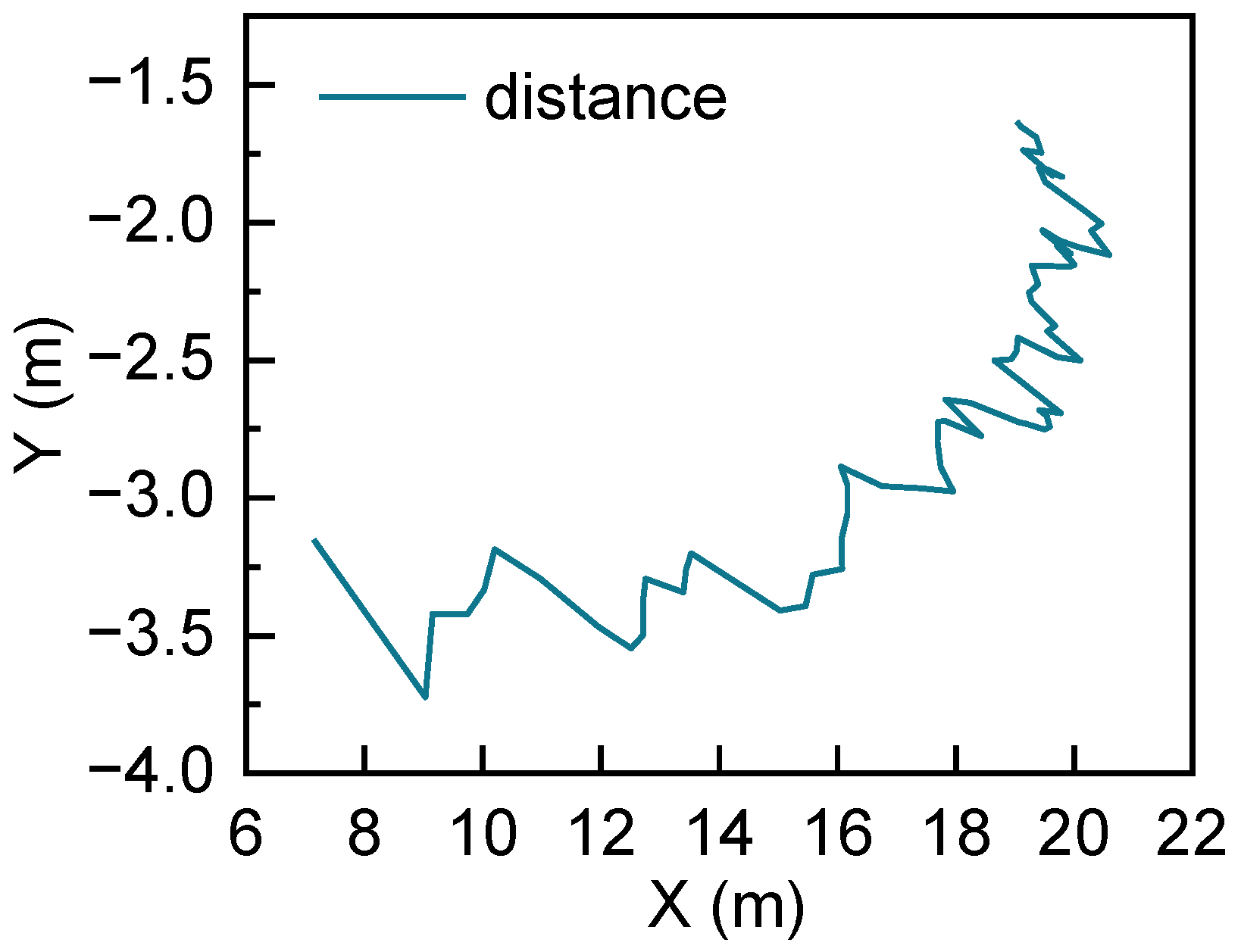
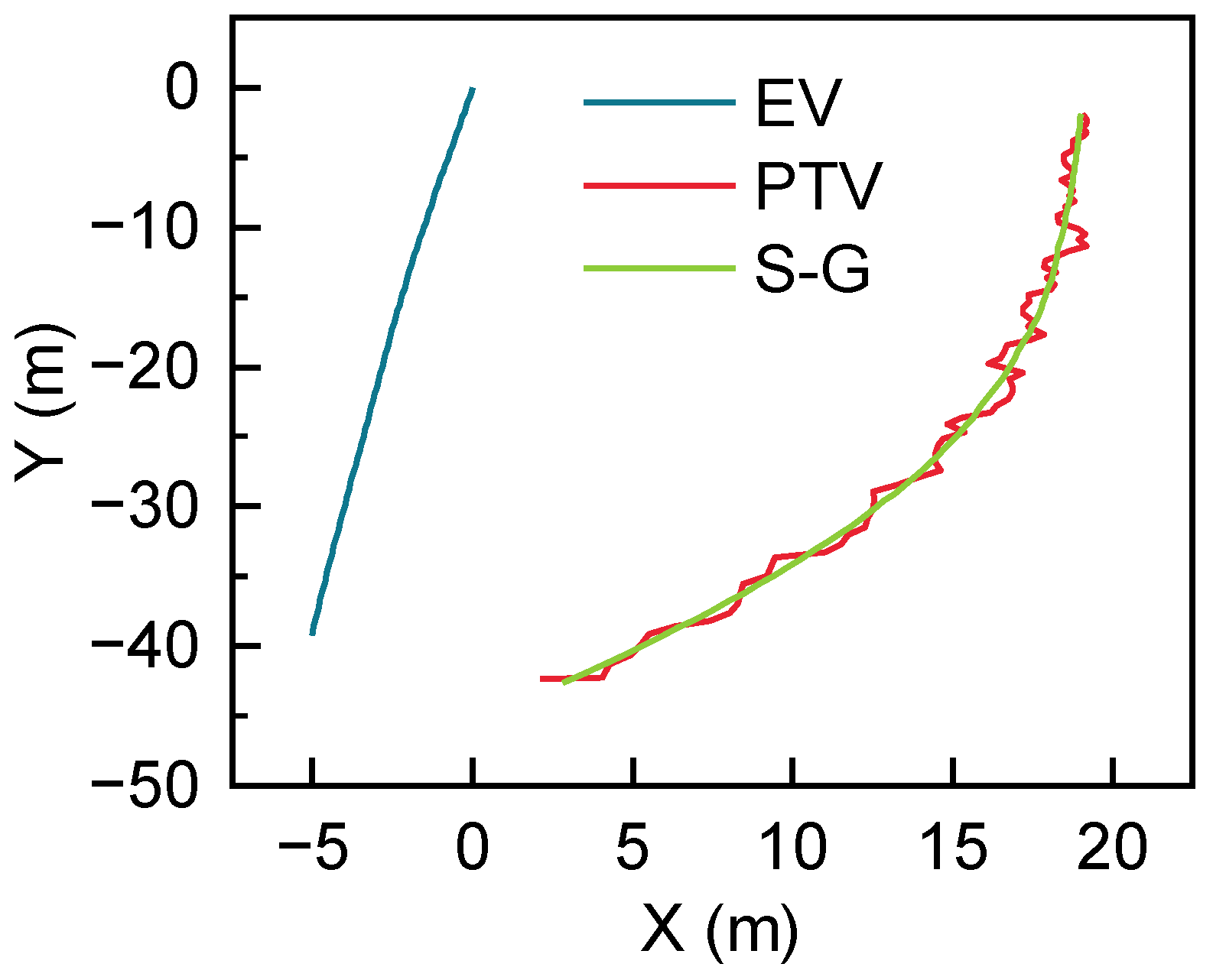
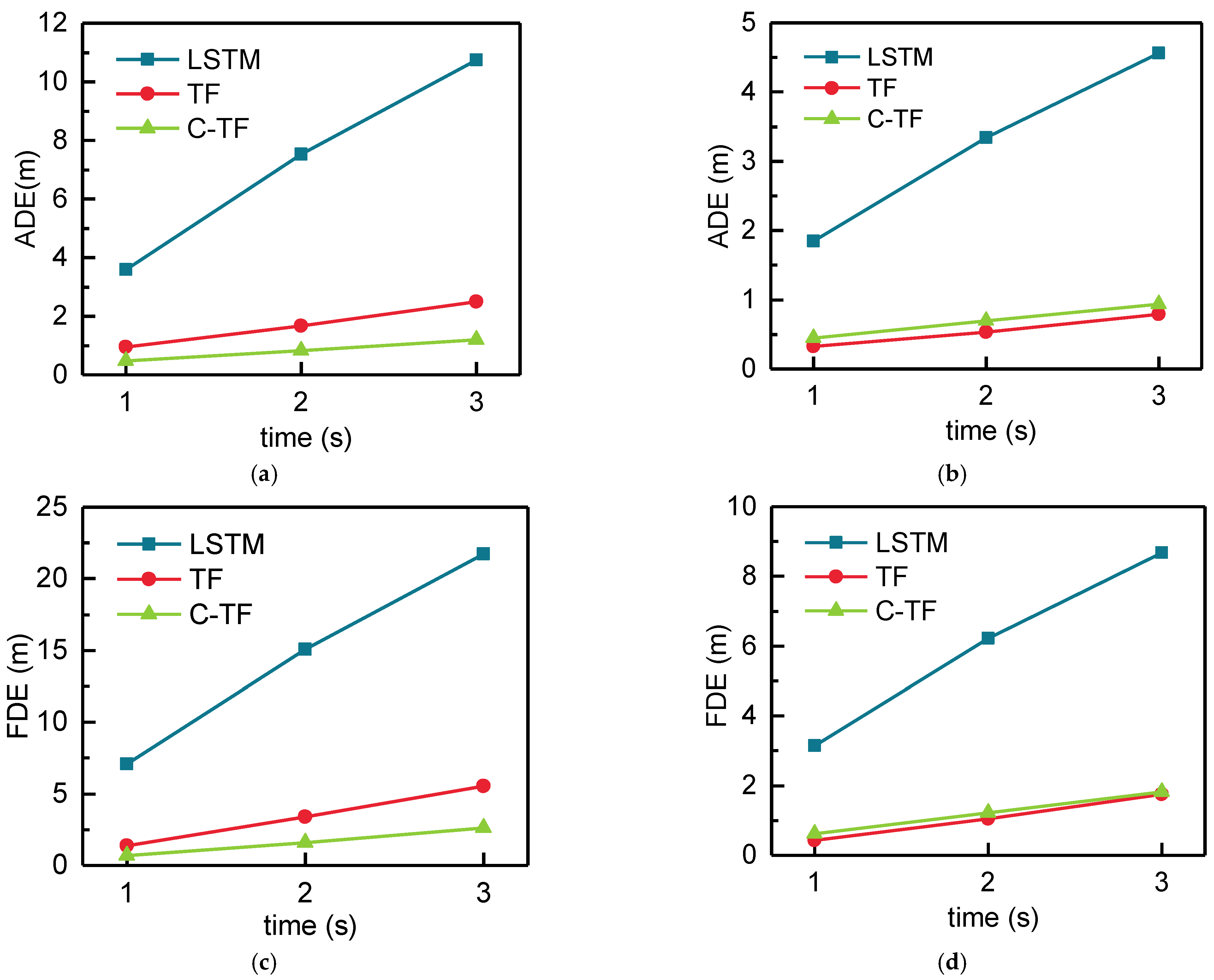
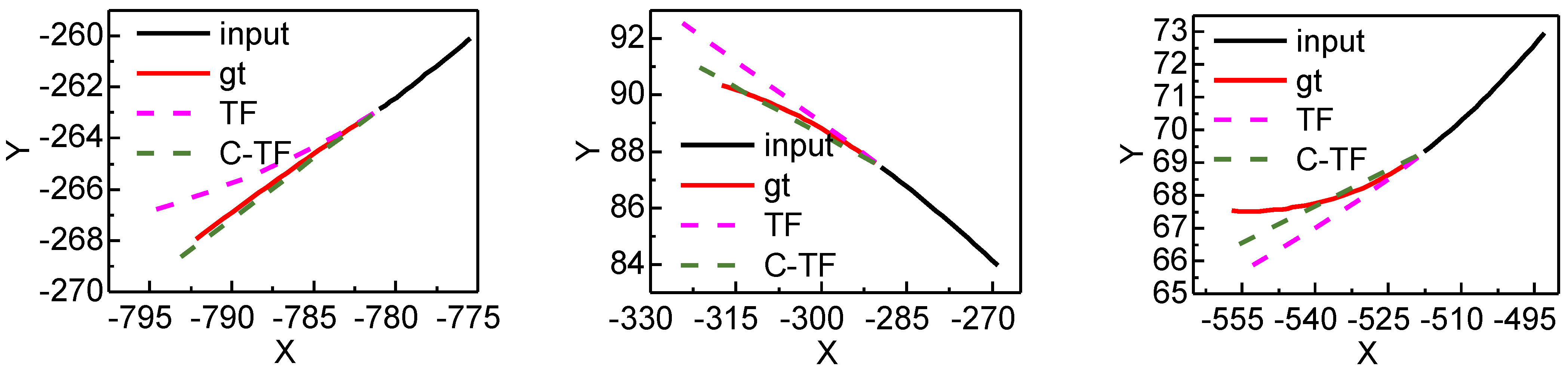
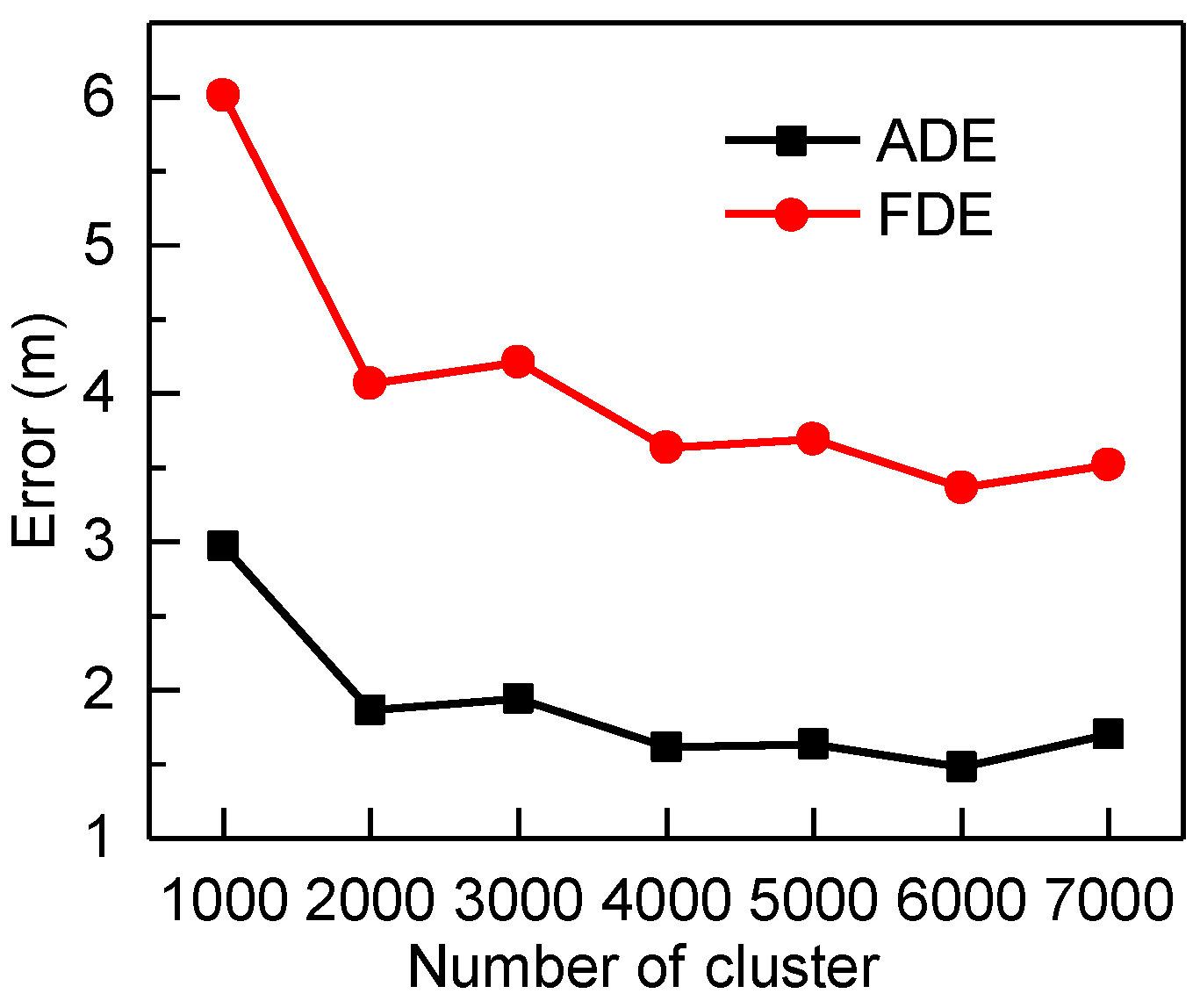
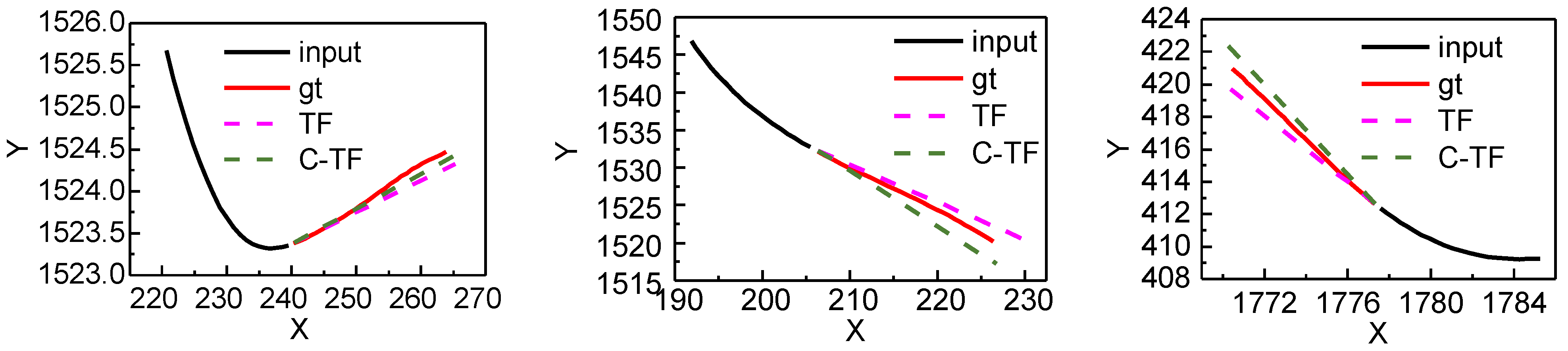
5.4. Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Wang, Y.; Zhou, Z.; Nam, K.; Wei, C.; Yin, C. Trajectory Prediction of Preceding Target Vehicles Based on Lane Crossing and Final Points Generation Model Considering Driving Styles. IEEE Trans. Veh. Technol. 2021, 70, 8720–8730. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, Z.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Environment-Attention Network for Vehicle Trajectory Prediction. IEEE Trans. Veh. Technol. 2021, 70, 11216–11227. [Google Scholar] [CrossRef]
- Yang, D.; Wu, Y.; Sun, F.; Chen, J.; Zhai, D.; Fu, C. Freeway accident detection and classification based on the multi-vehicle trajectory data and deep learning model. Transp. Res. Part C Emerg. Technol. 2021, 130, 103303. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, S.; Zhang, R.; Cheng, X.; Yang, L. Multi-Vehicle Collaborative Learning for Trajectory Prediction with Spatio-Temporal Tensor Fusion. IEEE Trans. Intell. Transp. Syst. 2022, 23, 236–248. [Google Scholar] [CrossRef]
- Lyu, N.; Wen, J.; Duan, Z.; Wu, C. Vehicle Trajectory Prediction and Cut-In Collision Warning Model in a Connected Vehicle Environment. IEEE Trans. Intell. Transp. Syst. 2022, 23, 966–981. [Google Scholar] [CrossRef]
- Chang, M.-F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape open dataset for autonomous driving and its application. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–10676. [Google Scholar] [CrossRef]
- Choi, D.; Yim, J.; Baek, M.; Lee, S. Machine learning-based vehicle trajectory prediction using v2v communications and on-board sensors. Electronics 2021, 10, 420. [Google Scholar] [CrossRef]
- Sedghi, L.; John, J.; Noor-A-Rahim, M.; Pesch, D. Formation Control of Automated Guided Vehicles in the Presence of Packet Loss. Sensors 2022, 22, 3552. [Google Scholar] [CrossRef] [PubMed]
- Jain, V.; Lapoehn, S.; Frankiewicz, T.; Hesse, T.; Gharba, M.; Gangakhedkar, S.; Ganesan, K.; Cao, H.; Eichinger, J.; Ali, A.R.; et al. Prediction based framework for vehicle platooning using vehicular communications. In Proceedings of the 2017 IEEE Vehicular Networking Conference (VNC), Turin, Italy, 27–29 November 2017; pp. 159–166. [Google Scholar] [CrossRef]
- Lee, J.-S.; Park, T.-H. Fast road detection by cnn-based camera–lidar fusion and spherical coordinate transformation. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5802–5810. [Google Scholar] [CrossRef]
- Zhao, X.; Sun, P.; Xu, Z.; Min, H.; Yu, H. Fusion of 3D LIDAR and Camera Data for Object Detection in Autonomous Vehicle Applications. IEEE Sens. J. 2020, 20, 4901–4913. [Google Scholar] [CrossRef] [Green Version]
- Bahari, M.; Nejjar, I.; Alahi, A. Injecting knowledge in data-driven vehicle trajectory predictors. Transp. Res. Part C Emerg. Technol. 2021, 128, 103010. [Google Scholar] [CrossRef]
- Ye, N.; Zhang, Y.; Wang, R.; Malekian, R. Vehicle trajectory prediction based on Hidden Markov Model. KSII Trans. Internet Inf. Syst. 2016, 10, 3150–3170. [Google Scholar] [CrossRef] [Green Version]
- Wiest, J.; Höffken, M.; Kreßel, U.; Dietmayer, K. Probabilistic trajectory prediction with Gaussian mixture models. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 141–146. [Google Scholar] [CrossRef]
- Houenou, A.; Bonnifait, P.; Cherfaoui, V.; Yao, W. Vehicle trajectory prediction based on motion model and maneuver recognition. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 4363–4369. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Sentouh, C.; Soualmi, B.; Haué, J.; Popieul, J. Adaptive vehicle longitudinal trajectory prediction for automated highway driving. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1279–1284. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Multi-modal trajectory prediction of surrounding vehicles with maneuver based LSTMs. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar] [CrossRef] [Green Version]
- Chandra, R.; Guan, T.; Panuganti, S.; Mittal, T.; Bhattacharya, U.; Bera, A.; Manocha, D. Forecasting Trajectory and Behavior of Road-Agents Using Spectral Clustering in Graph-LSTMs. IEEE Robot. Autom. Lett. 2020, 5, 4882–4890. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Yu, C.; Ma, X.; Ren, J.; Zhao, H.; Yi, S. Spatio-temporal graph transformer networks for pedestrian trajectory prediction. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Glasgow, UK, 2020; pp. 507–523. [Google Scholar] [CrossRef]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer networks for trajectory forecasting. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 13–18 September 2021. [Google Scholar] [CrossRef]
- Sun, F.; Li, Z.; Li, Z. A traffic flow detection system based on YOLOv5. In Proceedings of the 2nd International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Shanghai, China, 15–17 October 2021; pp. 458–464. [Google Scholar] [CrossRef]
- Perera, I.; Senavirathna, S.; Jayarathne, A.; Egodawela, S.; Godaliyadda, R.; Ekanayake, P.; Wijayakulasooriya, J.; Herath, V.; Sathyaprasad, S. Vehicle tracking based on an improved DeepSORT algorithm and the YOLOv4 framework. In Proceedings of the 2021 10th International Conference on Information and Automation for Sustainability (ICIAfS), Negombo, Sri Lanka, 11–13 August 2021; pp. 305–309. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep learning for image and point cloud fusion in autonomous driving: A review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 722–739. [Google Scholar] [CrossRef]
- Jiang, H.; Chang, L.; Li, Q.; Chen, D. Trajectory prediction of vehicles based on deep learning. In Proceedings of the 2019 4th International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 5–7 September 2019; pp. 190–195. [Google Scholar] [CrossRef]
- Choong, M.Y.; Angeline, L.; Chin, R.K.Y.; Yeo, K.B.; Teo, K.T.K. Modeling of vehicle trajectory using K-means and fuzzy C-means clustering. In Proceedings of the 2018 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Sabah, 8–9 November 2018; pp. 1–6. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LSTM | TF | C-TF | ||||
|---|---|---|---|---|---|---|
| ADE (m) | FDE (m) | ADE (m) | FDE (m) | ADE (m) | FDE (m) | |
| 1s | 4.244 | 8.090 | 1.042 | 1.495 | 0.737 | 1.056 |
| 2s | 8.596 | 16.960 | 1.816 | 3.642 | 1.204 | 2.244 |
| 3s | 12.159 | 24.300 | 2.708 | 6.046 | 1.699 | 3.519 |
| LSTM | TF | C-TF | ||||
|---|---|---|---|---|---|---|
| ADE (m) | FDE (m) | ADE (m) | FDE (m) | ADE (m) | FDE (m) | |
| 1 s | 2.76 | 5.52 | 0.72 | 0.88 | 0.60 | 0.67 |
| 2 s | 5.86 | 11.73 | 1.00 | 1.68 | 0.79 | 1.35 |
| 3 s | 8.32 | 16.59 | 1.30 | 2.49 | 1.11 | 2.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, B.; Li, W.; Hou, X.; Tang, L.; Yuan, Q. A Framework for Trajectory Prediction of Preceding Target Vehicles in Urban Scenario Using Multi-Sensor Fusion. Sensors 2022, 22, 4808. https://doi.org/10.3390/s22134808
Zou B, Li W, Hou X, Tang L, Yuan Q. A Framework for Trajectory Prediction of Preceding Target Vehicles in Urban Scenario Using Multi-Sensor Fusion. Sensors. 2022; 22(13):4808. https://doi.org/10.3390/s22134808
Chicago/Turabian StyleZou, Bin, Wenbo Li, Xianjun Hou, Luqi Tang, and Quan Yuan. 2022. "A Framework for Trajectory Prediction of Preceding Target Vehicles in Urban Scenario Using Multi-Sensor Fusion" Sensors 22, no. 13: 4808. https://doi.org/10.3390/s22134808
APA StyleZou, B., Li, W., Hou, X., Tang, L., & Yuan, Q. (2022). A Framework for Trajectory Prediction of Preceding Target Vehicles in Urban Scenario Using Multi-Sensor Fusion. Sensors, 22(13), 4808. https://doi.org/10.3390/s22134808