
NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection

Abstract
:1. Introduction
- A one-stage detector is proposed to boost efficiency and reduce complexity for remote sensing object detection;
- A nested residual Transformer module is proposed to acquire global information, and it is verified that the structure boosts the accuracy of tiny object detection and reduces complexity;
- Some efficient improvements and tricks are added in YOLOv5 to address tiny object problems, such as an extra prediction head, nested residual attention and multi-scale testing.
2. Related Work
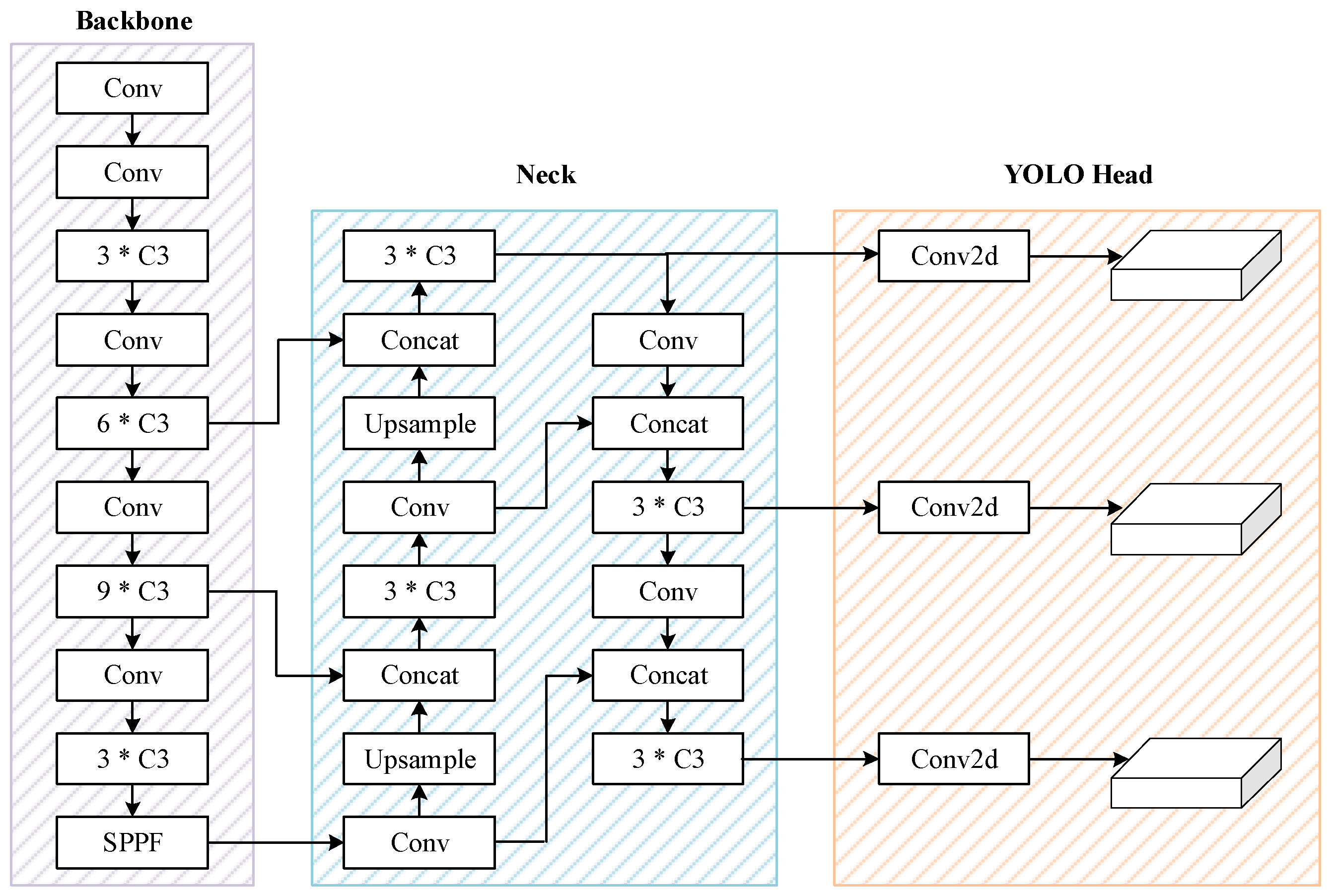
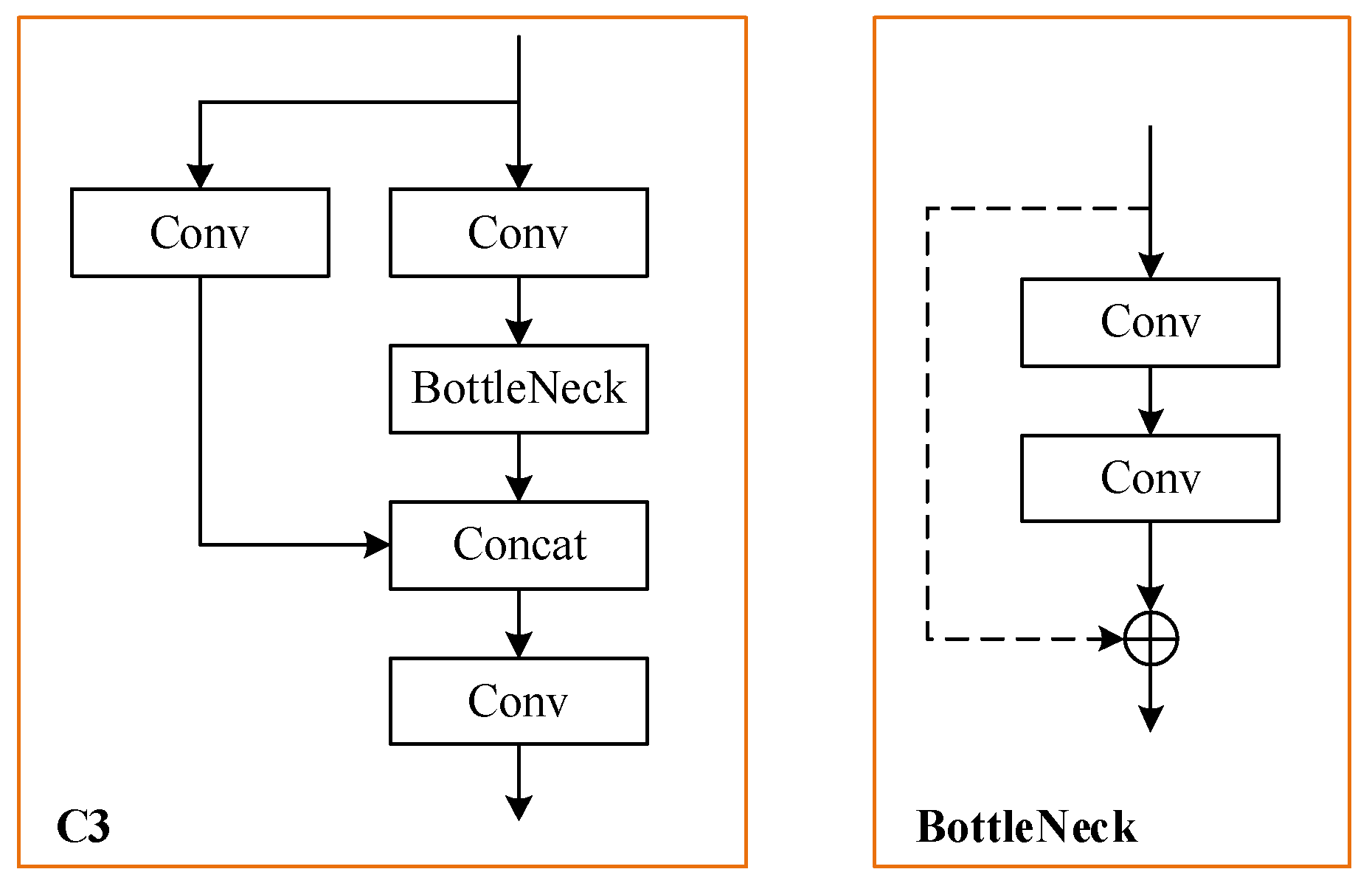
2.1. YOLOv5
- It lacks shallow network information as a consequence of the neglect of features in the first C3 block;
- It lacks the ability to obtain global and contextual information which can benefit the network with regard to accuracy and efficiency.
2.2. Vision Transformer
- It requires ultra-scale datasets to reach its maximum potential without the capability of inductive bias of CNNs;
- If the input image size becomes larger, the sequence will become longer, which may significantly increase complexity as a consequence.
2.3. Attention Mechanism
3. Approach
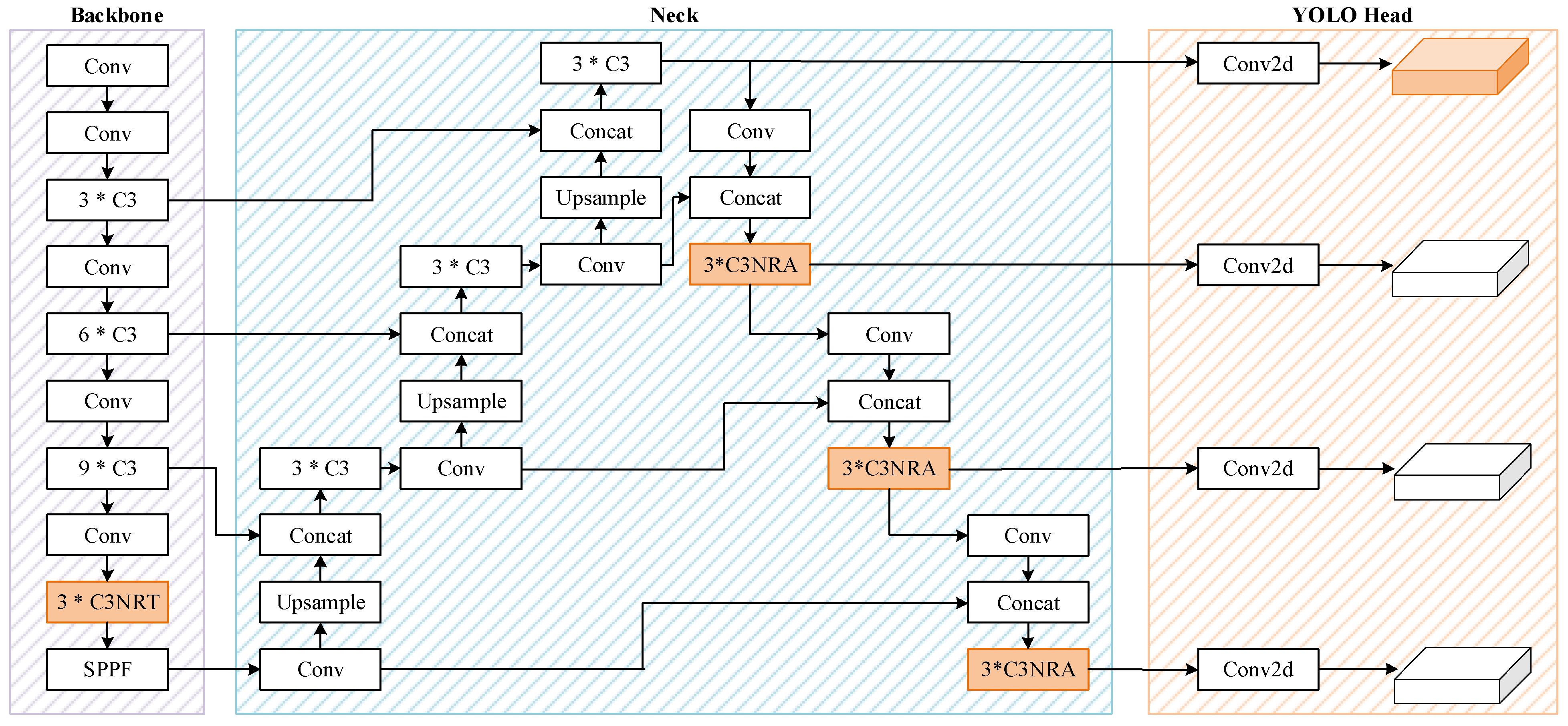
3.1. Overview of NRT-YOLO
3.2. Tiny Object Prediction Head
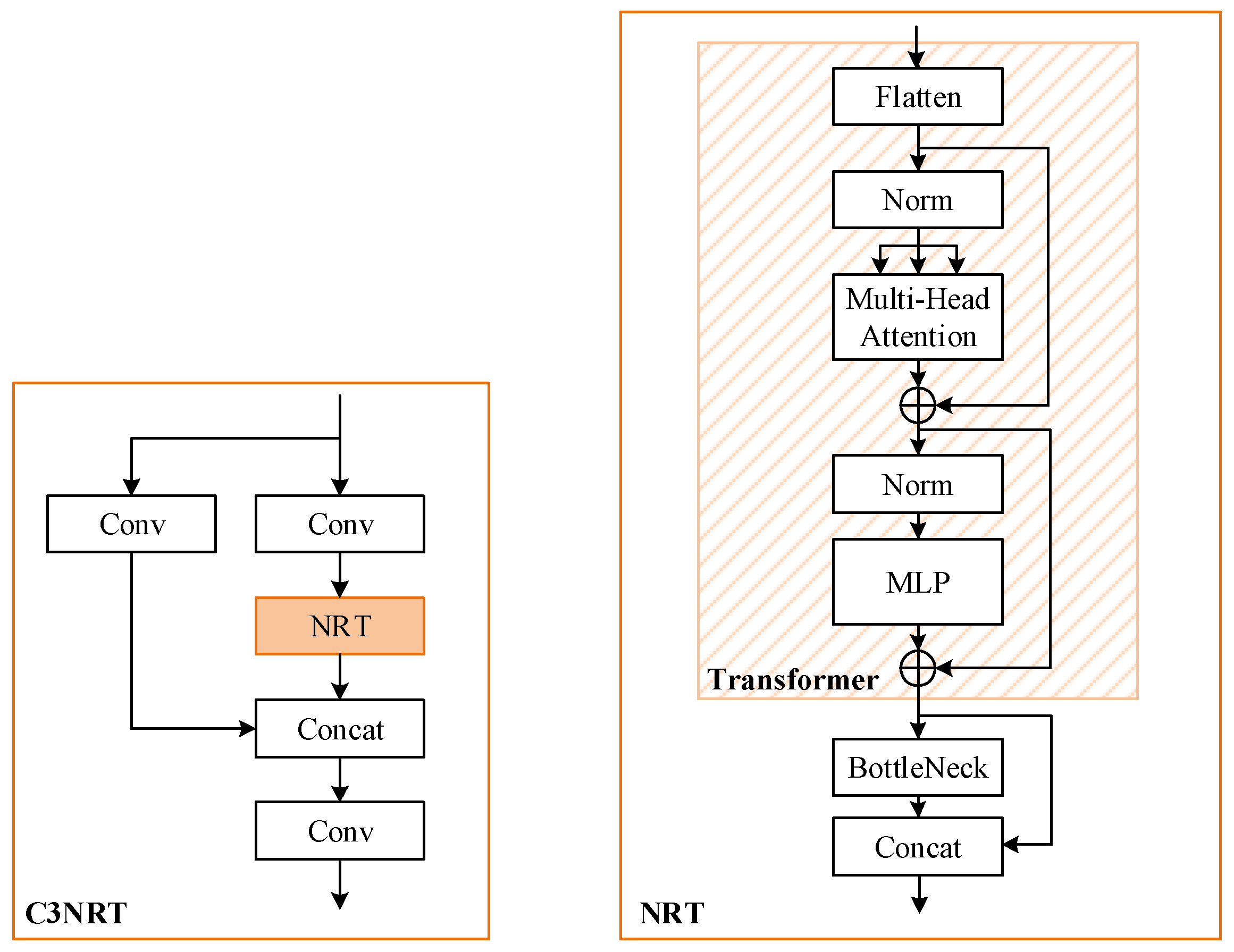
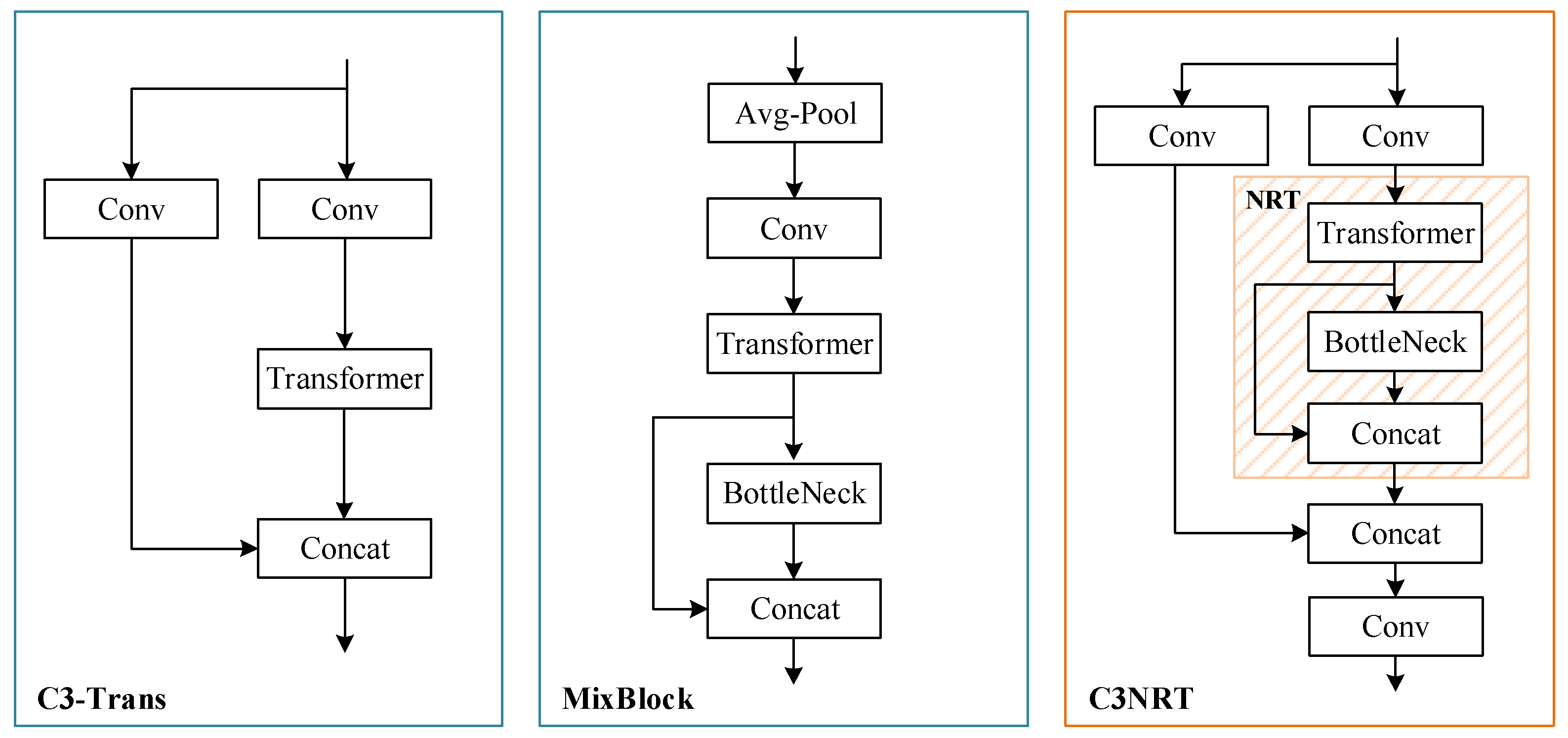
3.3. Nested Residual Transformer (C3NRT) Module
3.3.1. Transformer Encoder Block
- Flatten
- 2.
- Multi-head attention
- 3.
- MLP
3.3.2. C3NRT Module
- 1.
- Nested residual architecture
- 2.
- Module location
- 3.
- Size of feature map
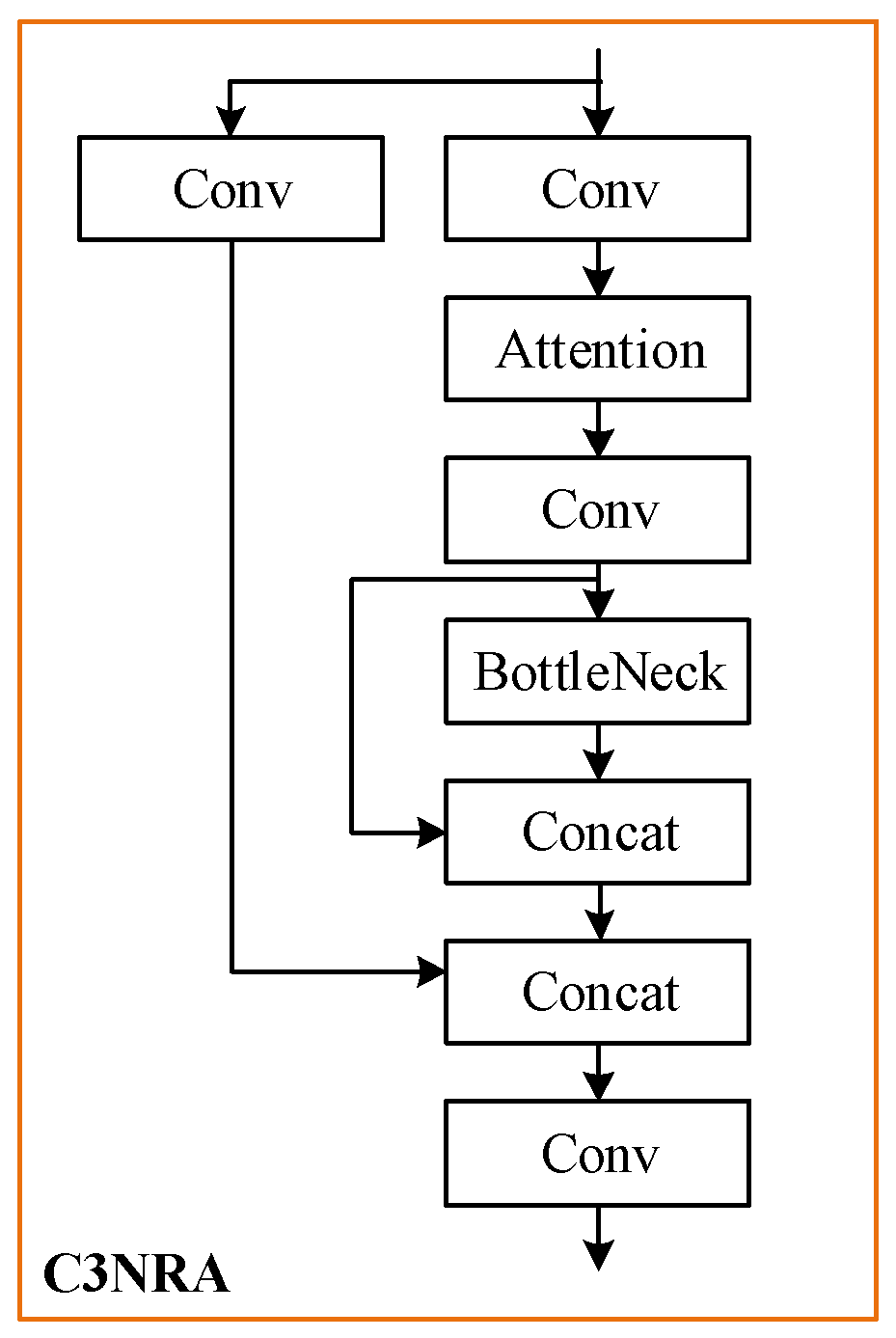
3.4. Nested Residual Attention
3.5. Multi-Scale Testing
4. Experiments
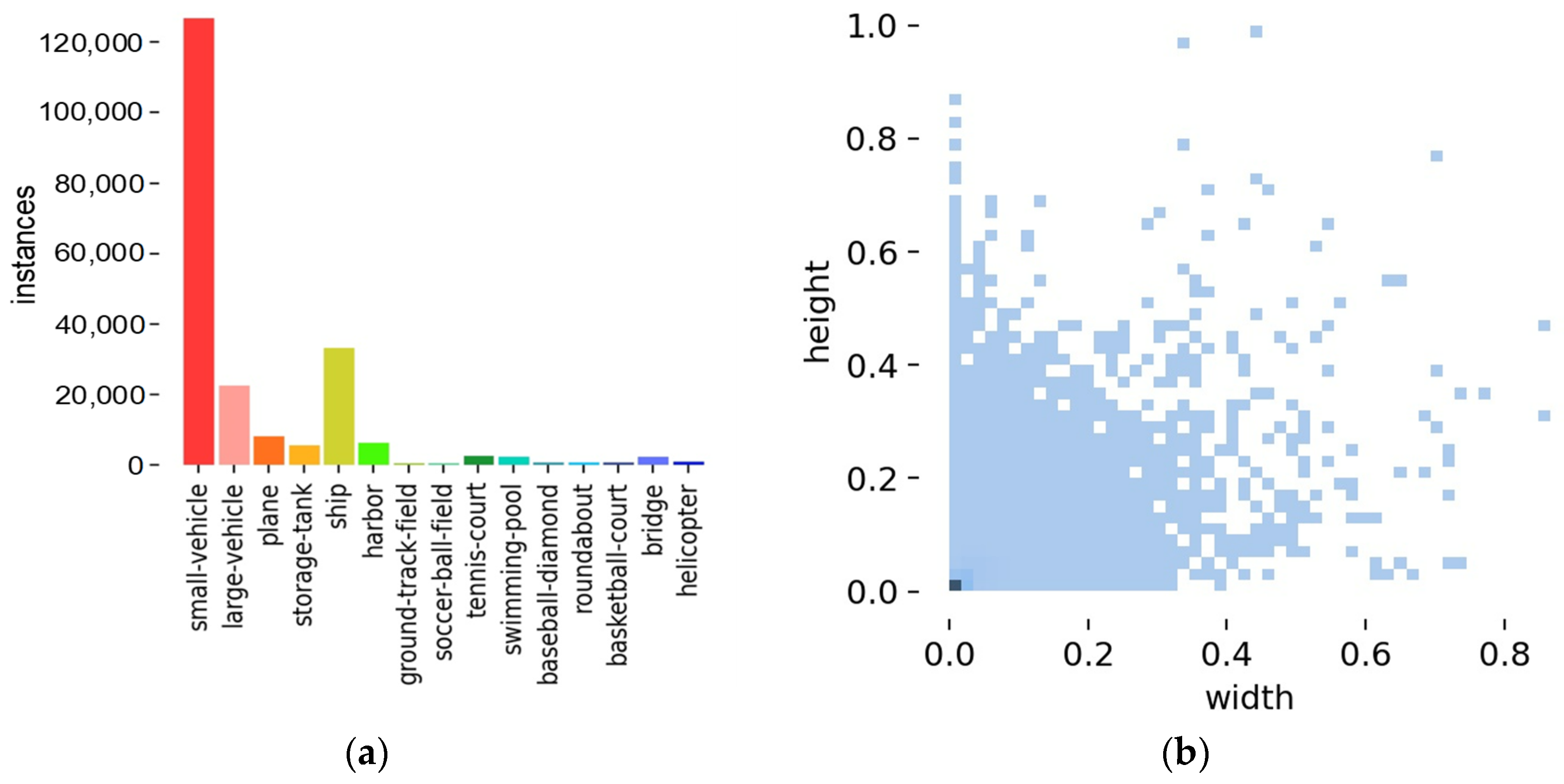
4.1. Dataset
4.2. Implementation Details and Evaluation Metrics
- 1.
- Implementation details
- 2.
- Evaluation metrics.
4.3. Experiment Results
4.4. Ablation Study
4.5. Comparison between NRT and Other Transformer Blocks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates: Red Hook, NY, USA, 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Pt. I, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Pt. V, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Part I. pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual Event, 6–14 December 2021; pp. 26183–26197. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Van Etten, A. You Only Look Twice: Rapid Multi-Scale Object Detection in Satellite Imagery. arXiv 2018, arXiv:1805.09512v1. [Google Scholar]
- Unel, F.O.; Ozkalayci, B.O.; Cigla, C.; IEEE. The Power of Tiling for Small Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 582–591. [Google Scholar]
- LaLonde, R.; Zhang, D.; Shah, M. ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Information. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4003–4012. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8310–8319. [Google Scholar]
- Wang, Y.; Yang, Y.; Zhao, X. Object Detection Using Clustering Algorithm Adaptive Searching Regions in Aerial Images. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 651–664. [Google Scholar]
- Liao, J.; Piao, Y.; Su, J.; Cai, G.; Huang, X.; Chen, L.; Huang, Z.; Wu, Y. Unsupervised Cluster Guided Object Detection in Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11204–11216. [Google Scholar] [CrossRef]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 737–746. [Google Scholar]
- Duan, C.; Wei, Z.; Zhang, C.; Qu, S.; Wang, H. Coarse-grained Density Map Guided Object Detection in Aerial Images. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2789–2798. [Google Scholar]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery. arXiv 2021, arXiv:2112.10415v2. [Google Scholar]
- Gao, M.; Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Dynamic Zoom-in Network for Fast Object Detection in Large Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2021; pp. 6926–6935. [Google Scholar]
- Xu, J.; Li, Y.; Wang, S. AdaZoom: Adaptive Zoom Network for Multi-Scale Object Detection in Large Scenes. arXiv 2021, arXiv:2106.10409v1. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2778–2788. [Google Scholar]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. MSFT-YOLO: Improved YOLOv5 Based on Transformer for Detecting Defects of Steel Surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Yang, Q.; Luo, C.; Li, R.; Zhou, Y.; Zhang, F. Vessel Detection from Nighttime Remote Sensing Imagery Based on Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12536–12544. [Google Scholar] [CrossRef]
- Du, F.-J.; Jiao, S.-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767v1. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Part VII. pp. 3–19. [Google Scholar]
- Xia, X.; Li, J.; Wu, J.; Wang, X.; Xiao, X.; Zheng, M.; Wang, R. TRT-ViT: TensorRT-oriented Vision Transformer. arXiv 2022, arXiv:2205.09579v2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P (%) | R (%) | mAP0.5 (%) | mAP (%) | Parameters (M) | GFLOPs | Latency (ms) |
|---|---|---|---|---|---|---|---|
| YOLOv4 | 76.8 | 43.2 | 48.1 | 27.6 | 26.9 | 51.0 | 37.8 |
| YOLOv5m | 79.0 | 46.2 | 51.0 | 30.2 | 20.9 * | 48.1 | 35.2 |
| YOLOv5l | 79.3 | 47.6 | 52.4 | 31.4 | 46.2 | 108.0 | 41.9 |
| YOLOv5x | 81.5 | 49.2 | 54.1 | 32.2 | 86.3 | 204.3 | 51.6 |
| NRT-YOLO | 78.1 | 51.5 | 56.9 | 33.2 | 38.1 | 115.2 | 48.7 |
| Method | mAPsmall (%) | mAPmedium (%) | mAPlarge (%) |
|---|---|---|---|
| YOLOv4 | 6.7 | 21.5 | 39.1 |
| YOLOv5m | 8.3 | 23.9 | 42.5 |
| YOLOv5l | 9.0 | 25.8 | 43.2 |
| YOLOv5x | 10.6 | 26.8 | 46.6 |
| NRT-YOLO | 13.0 * | 28.4 | 47.2 |
| Class | YOLOv4 | YOLOv5m | YOLOv5l | YOLOv5x | NRT-YOLO |
|---|---|---|---|---|---|
| Small vehicle | 28.6 | 31.6 | 31.9 | 32.1 | 33.2 * |
| Large vehicle | 66.0 | 69.0 | 68.8 | 68.7 | 71.7 |
| Plane | 77.2 | 79.9 | 80.0 | 79.3 | 82.6 |
| Storage tank | 42.4 | 50.2 | 44.6 | 46.4 | 52.2 |
| Ship | 56.9 | 58.8 | 61.0 | 61.5 | 65.6 |
| Harbor | 69.3 | 71.2 | 72.0 | 76.3 | 72.4 |
| Ground track field | 32.8 | 35.9 | 41.8 | 40.3 | 48.8 |
| Soccer ball field | 38.2 | 38.2 | 38.6 | 43.5 | 38.1 |
| Tennis court | 90.4 | 93.0 | 92.8 | 93.9 | 93.0 |
| Swimming pool | 49.9 | 53.7 | 54.7 | 57.1 | 57.2 |
| Baseball diamond | 59.1 | 61.4 | 68.2 | 69.9 | 71.8 |
| Roundabout | 36.7 | 37.0 | 42.2 | 44.1 | 43.3 |
| Basketball-court | 45.2 | 47.8 | 49.3 | 51.0 | 55.5 |
| Bridge | 27.4 | 34.9 | 35.6 | 41.6 | 39.9 |
| Helicopter | 1.5 | 2.5 | 5.0 | 5.6 | 27.7 |
| Method | mAP0.5 (%) | mAP (%) | Parameters (M) | GFLOPs | Latency (ms) |
|---|---|---|---|---|---|
| YOLOv5l-1024 | 52.4 | 31.4 | 46.2 | 108.0 | 41.9 |
| +prediction head | 53.4 (+1.0) * | 31.5 (+0.1) | 47.2 | 127.8 | 47.9 |
| +C3NRT | 56.1 (+2.7) | 33.4 (+1.9) | 44.5 | 126.0 | 49.9 |
| +C3NRA | 56.0 (−0.1) | 33.4 (−−) | 37.9 | 113.8 | 48.7 |
| +ms testing | 56.9 (+0.9) | 33.5 (+0.1) | 37.9 | 113.8 | 48.7 |
| Class | YOLOv5l | +Detection Head | +C3NRT | +C3NRA | +ms Testing |
|---|---|---|---|---|---|
| Small vehicle | 31.9 | 33.0 * | 33.4 | 33.3 | 33.2 |
| Large vehicle | 68.8 | 71.4 | 71.7 | 70.9 | 71.7 |
| Plane | 80.0 | 80.6 | 80.8 | 81.2 | 82.6 |
| Storage tank | 44.6 | 51.0 | 52.9 | 53.7 | 52.2 |
| Ship | 61.0 | 65.4 | 66.5 | 66.3 | 65.6 |
| Harbor | 72.0 | 75.6 | 74.6 | 74.6 | 72.4 |
| Ground track field | 41.8 | 42.0 | 45.5 | 44.7 | 48.8 |
| Soccer ball field | 38.6 | 36.0 | 38.1 | 37.6 | 38.1 |
| Tennis court | 92.8 | 91.7 | 92.8 | 92.6 | 93.0 |
| Swimming pool | 54.7 | 54.4 | 56.1 | 54.7 | 57.2 |
| Baseball diamond | 68.2 | 67.8 | 70.6 | 68.9 | 71.8 |
| Roundabout | 42.2 | 37.9 | 38.9 | 40.5 | 43.3 |
| Basketball-court | 49.3 | 50.4 | 52.4 | 52.7 | 55.5 |
| Bridge | 35.6 | 37.5 | 41.2 | 39.7 | 39.9 |
| Helicopter | 5.0 | 6.2 | 25.7 | 29.2 | 27.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors 2022, 22, 4953. https://doi.org/10.3390/s22134953
Liu Y, He G, Wang Z, Li W, Huang H. NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors. 2022; 22(13):4953. https://doi.org/10.3390/s22134953
Chicago/Turabian StyleLiu, Yukuan, Guanglin He, Zehu Wang, Weizhe Li, and Hongfei Huang. 2022. "NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection" Sensors 22, no. 13: 4953. https://doi.org/10.3390/s22134953
APA StyleLiu, Y., He, G., Wang, Z., Li, W., & Huang, H. (2022). NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors, 22(13), 4953. https://doi.org/10.3390/s22134953