
SM-SegNet: A Lightweight Squeeze M-SegNet for Tissue Segmentation in Brain MRI Scans



Abstract
:1. Introduction
- We propose “lightweight SM-SegNet,” a fully automatic brain tissue segmentation on MRI, using a multi-scale deep network integrated with a fire module.
- Our SM-SegNet architecture represents an end-to-end training network that applies an M-shape convolutional network with multi-scale side layers at the input side to learn discriminative information; the upsampling layer at the output side provides deep supervision.
- The proposed long skip connections stabilize the gradient updates in the proposed architecture, improving the optimization convergence speed.
- The encoder and decoder (designed with fire modules) reduce the number of parameters and the computational complexity, resulting in a more efficient network for brain MRI segmentation.
- We propose using a uniform division of patches from brain MRI scans to enhance local details in the trained model; this minimizes the loss of semantic features.
2. Materials and Methods
3. Proposed Methodology
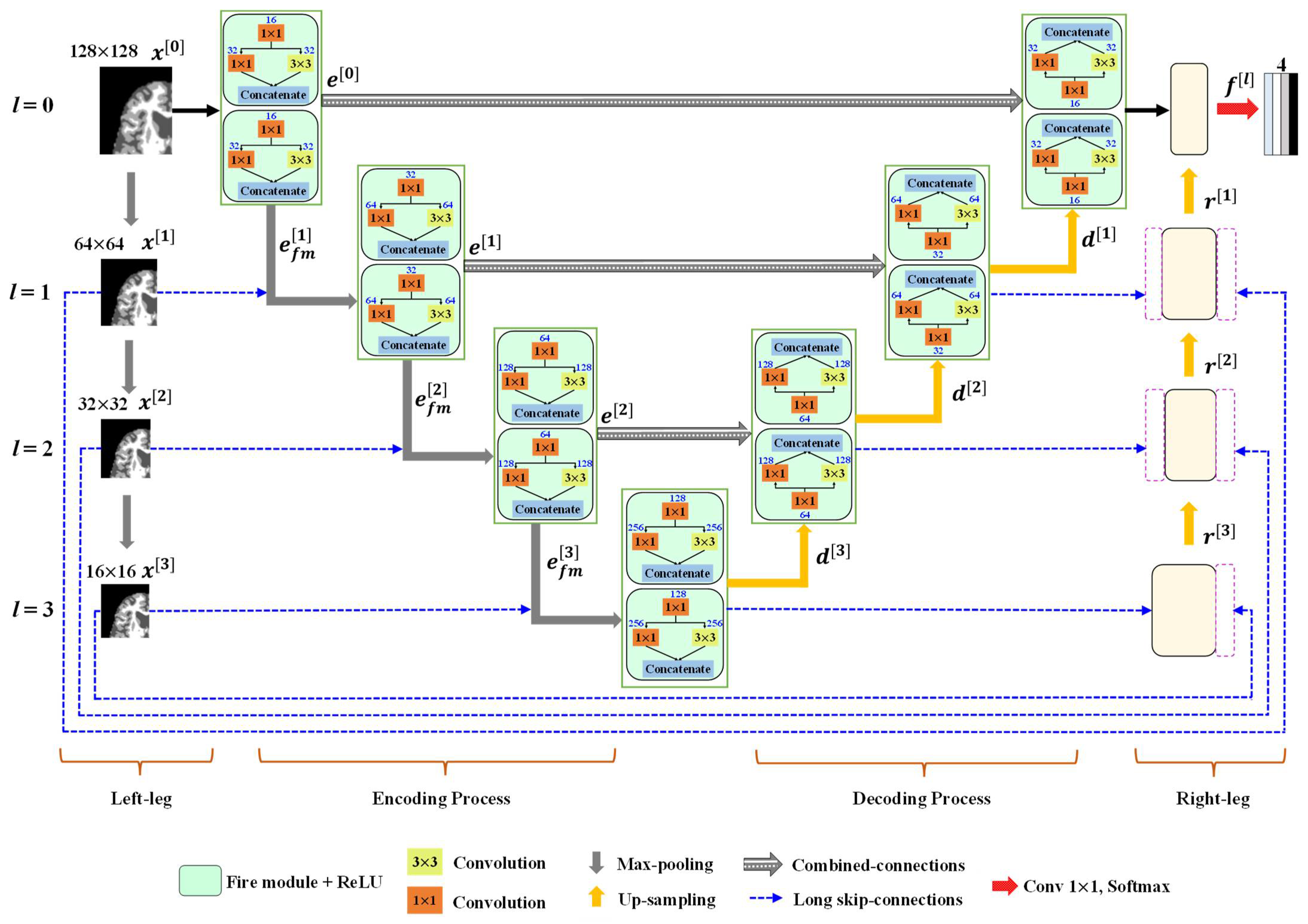
3.1. Outline of the Proposed Method
3.2. Outline of the Proposed Method
3.2.1. Encoder Block
3.2.2. Decoder Block
3.2.3. Classification Layer
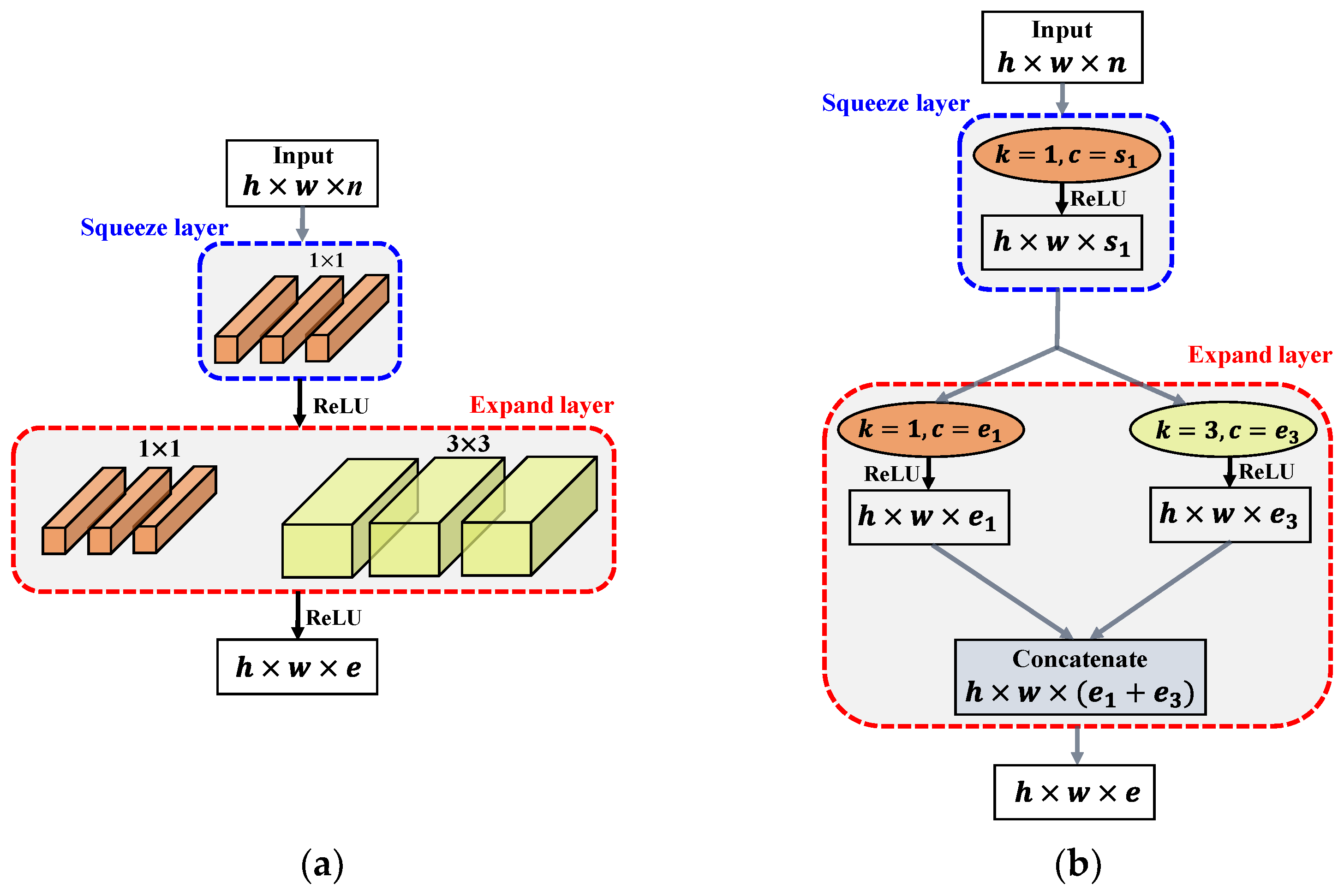
3.2.4. Fire Module
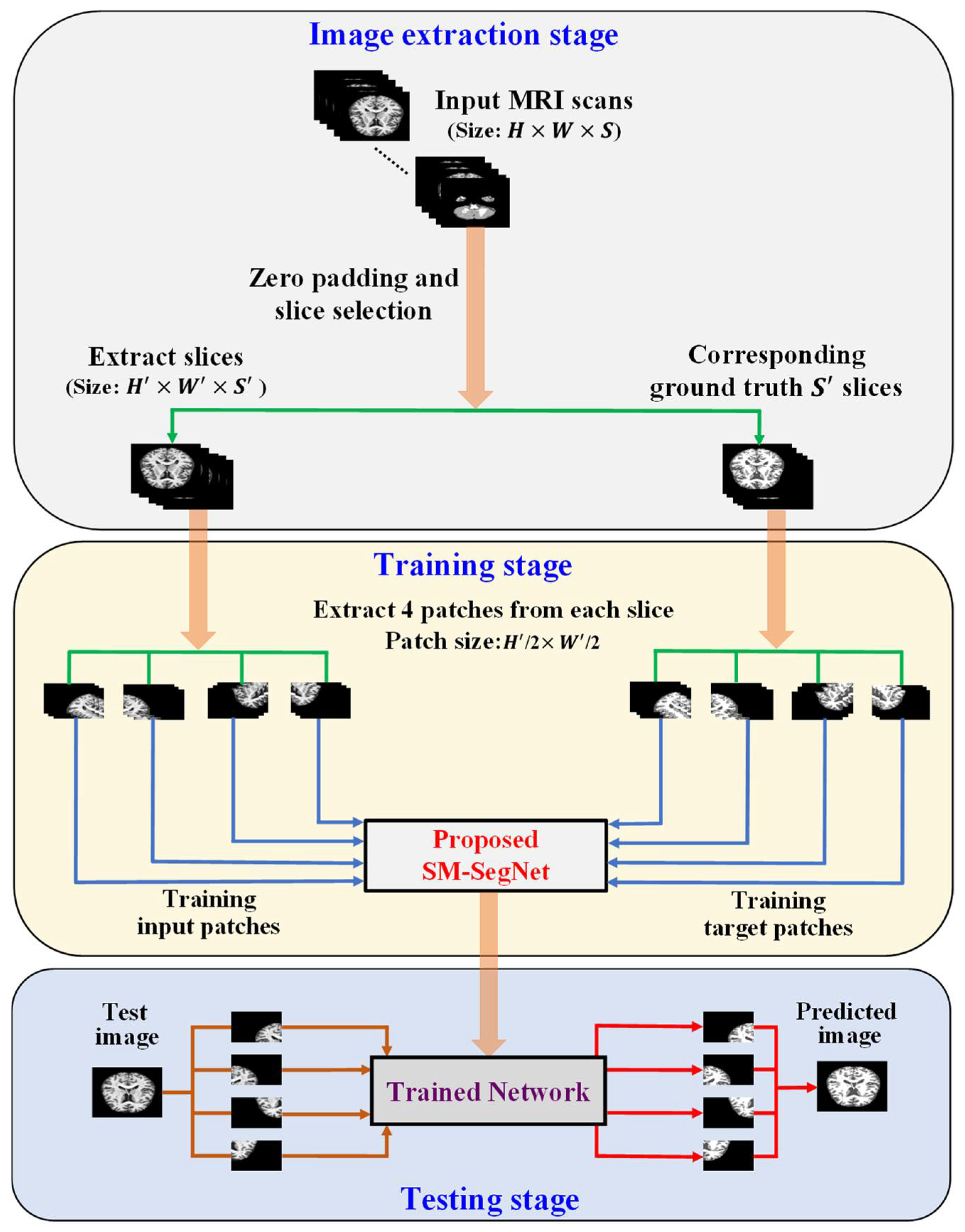
3.2.5. Training of OASIS and IBSR Datasets
4. Experimental Results and Analysis
4.1. Materials
4.1.1. OASIS Dataset
4.1.2. IBSR Dataset
4.2. Experimental Setups
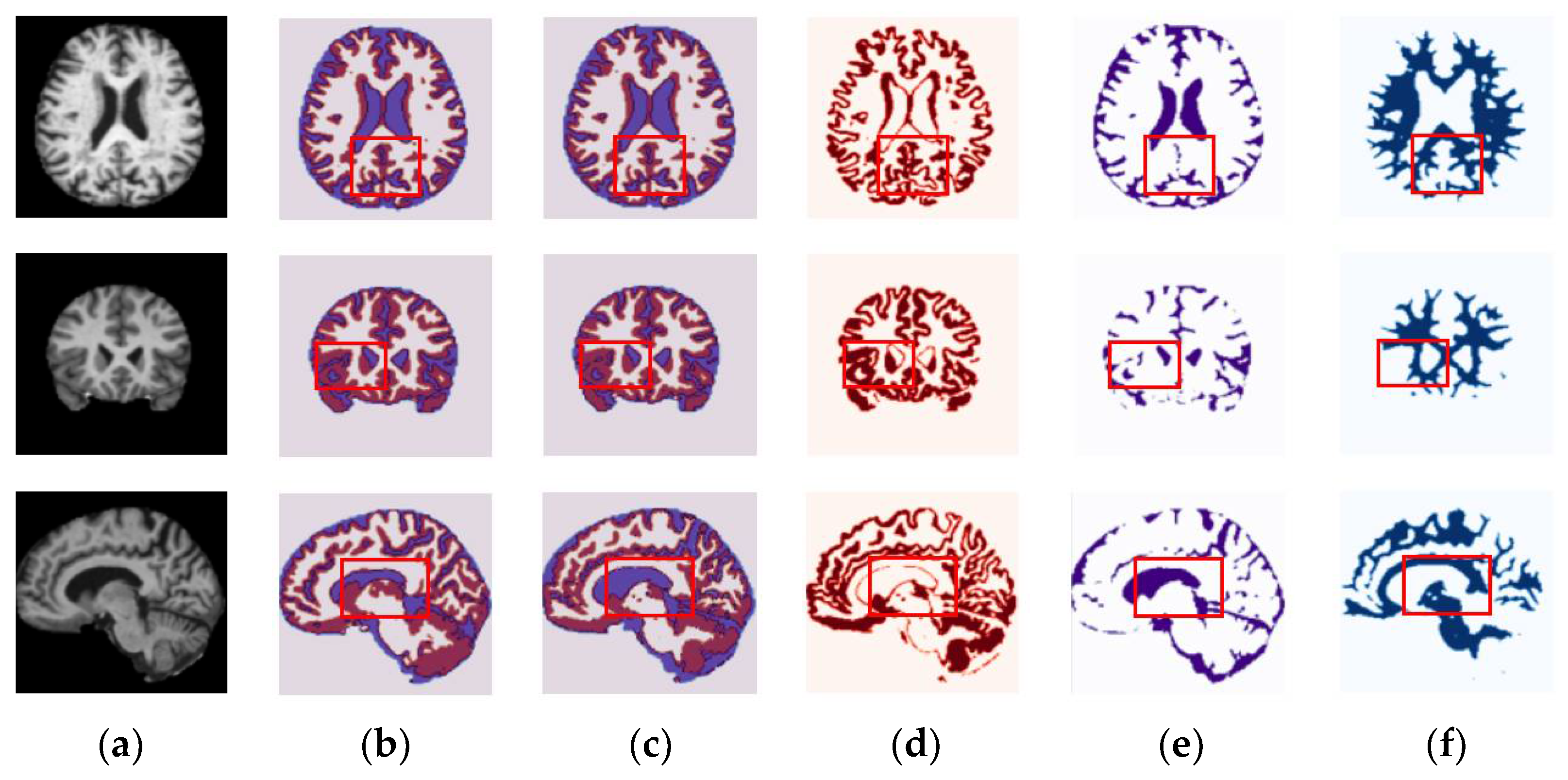
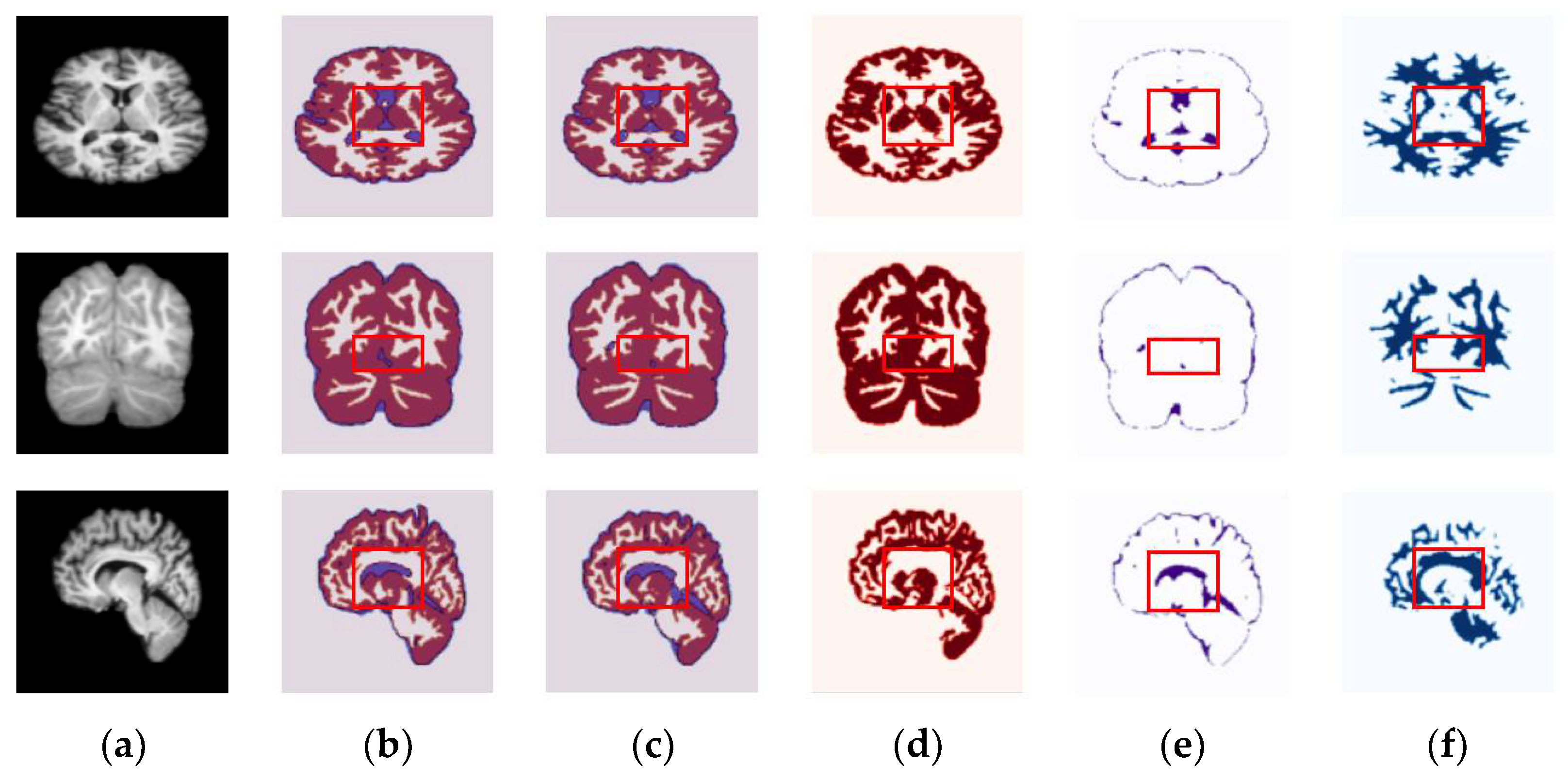
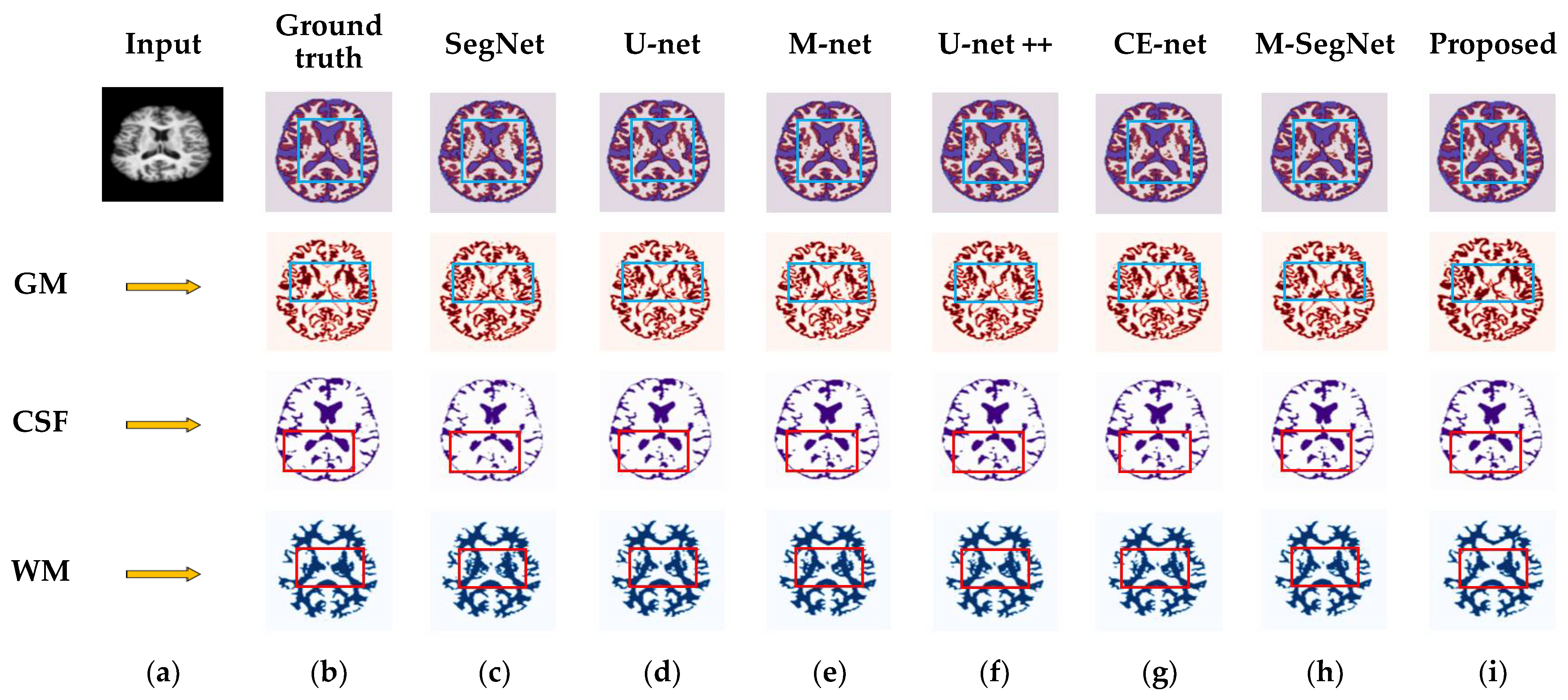
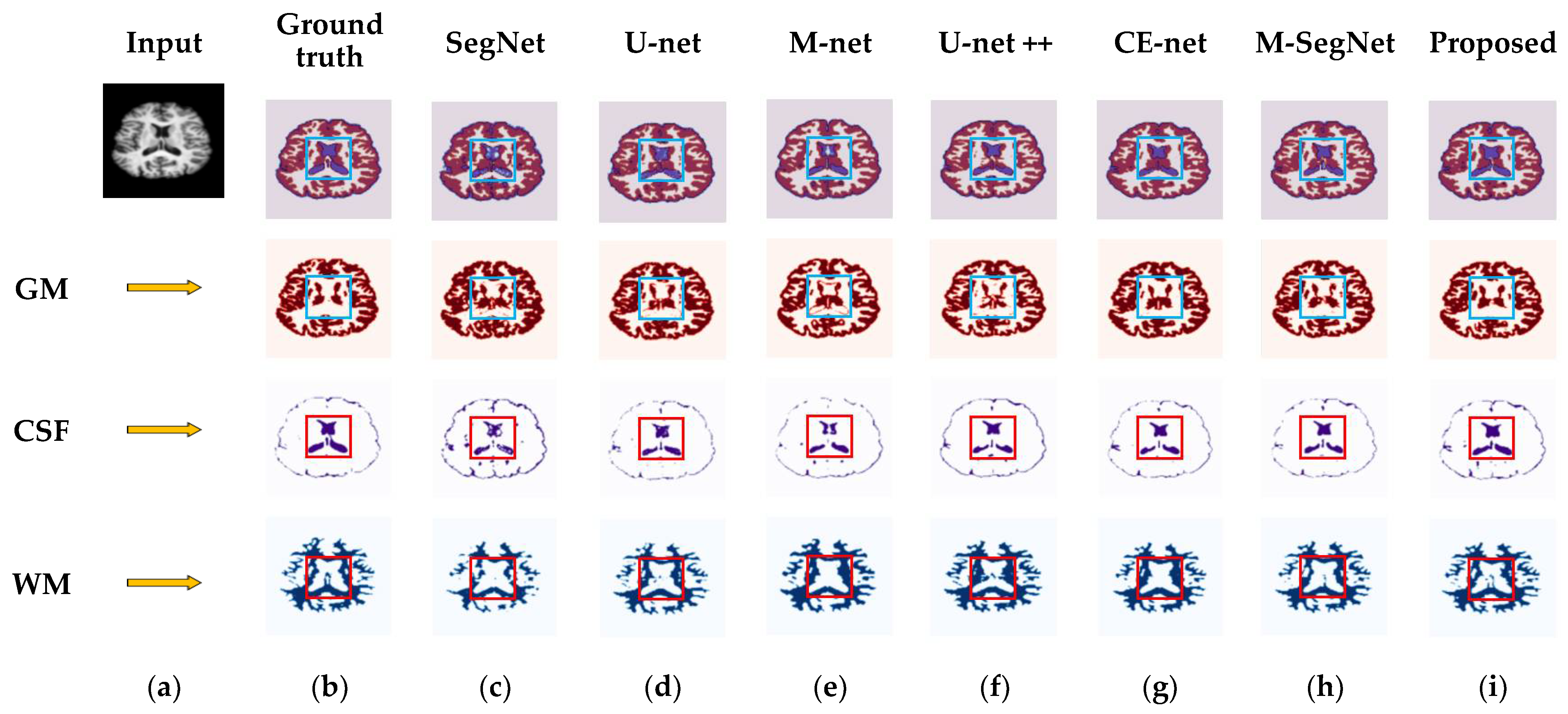
4.3. Results for OASIS and IBSR Datasets
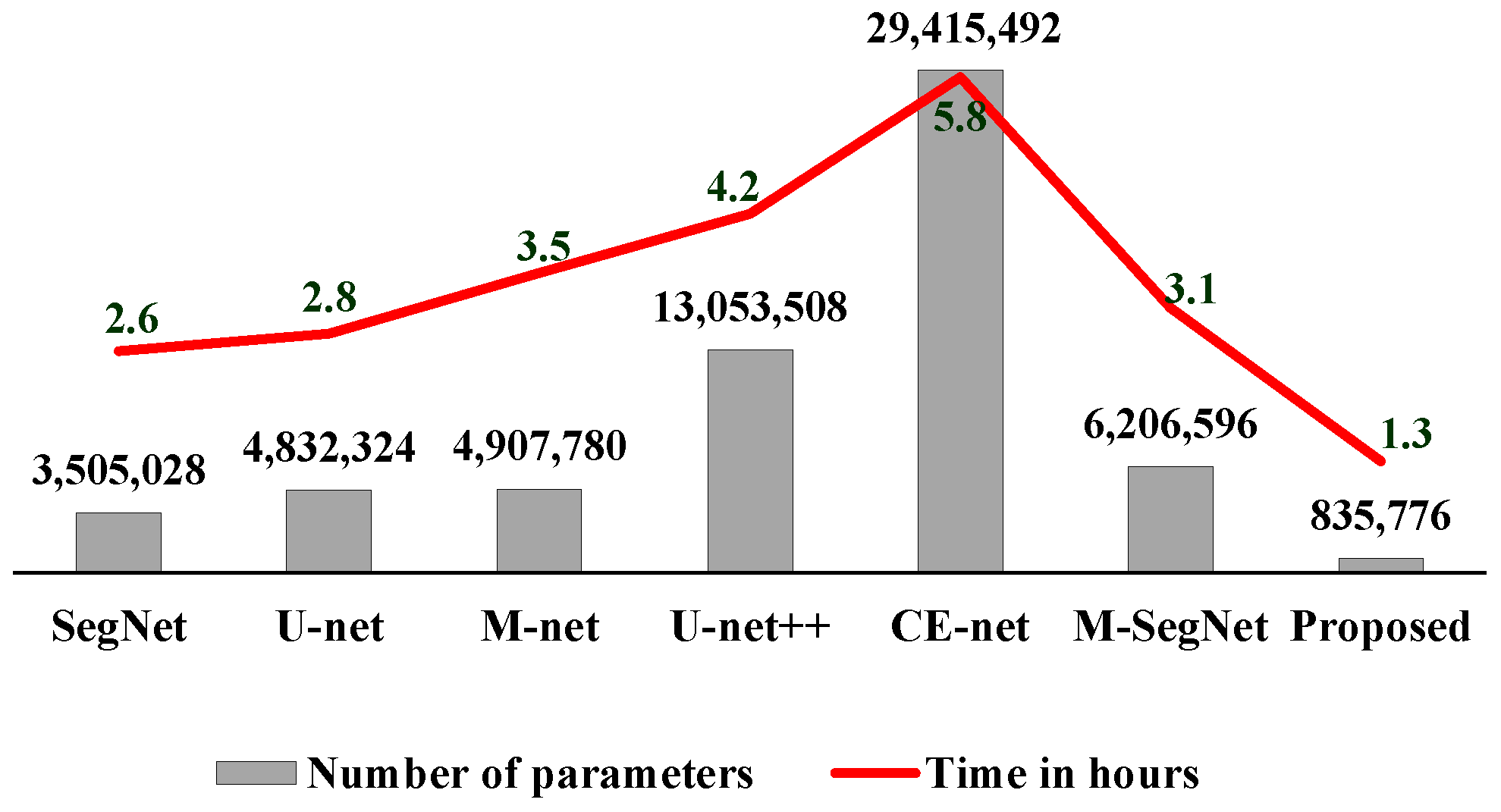
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, W.; Abdel-Basset, M.; Hawash, H.; Pedrycz, W. Multimodal Infant Brain Segmentation by Fuzzy-Informed Deep Learning. IEEE Trans. Fuzzy Syst. 2021, 30, 1088–1101. [Google Scholar] [CrossRef]
- Miriam, R.; Malin, B.; Jan, A.; Patrik, B.; Fredrik, B.; Jorgen, R.; Ingrid, L.; Lennart, B.; Richard, P.; Martin, R.; et al. PET/MRI and PET/CT hybrid imaging of rectal cancer–description and initial observations from the Rectal Cancer trial on PET/MRI/CT study. Cancer Imaging 2019, 19, 52. [Google Scholar]
- Rebecca, S.; Diana, M.; Eric, J.; Choonsik, L.; Heather, F.; Michael, F.; Robert, G.; Randell, K.; Mark, H.; Douglas, M.; et al. Use of Diagnostic Imaging Studies and Associated Radiation Exposure for Patients Enrolled in Large Integrated Health Care Systems, 1996–2010. JAMA 2012, 307, 2400–2409. [Google Scholar]
- Yamanakkanavar, N.; Choi, J.Y.; Lee, B. MRI Segmentation and Classification of Human Brain Using Deep Learning for Diagnosis of Alzheimer’s disease: A Survey. Sensors 2020, 20, 3243. [Google Scholar] [CrossRef]
- Krinidis, S.; Chatzis, V. A robust fuzzy local information C-means clustering algorithm. IEEE Trans. Image Process. 2010, 19, 1328–1337. [Google Scholar] [CrossRef]
- Roy, S.; Maji, P. Medical image segmentation by partitioning spatially constrained fuzzy approximation spaces. IEEE Trans. Fuzzy Syst. 2020, 28, 965–977. [Google Scholar] [CrossRef]
- Feng, C.; Zhao, D.; Huang, M. Image segmentation and bias correction using local inhomogeneous iNtensity clustering (LINC): A region-based level set method. Neurocomputing 2017, 219, 107–129. [Google Scholar] [CrossRef] [Green Version]
- Nagaraj, Y.; Madipalli, P.; Rajan, J.; Kumar, P.K.; Narasimhadhan, A. Segmentation of intima media complex from carotid ultrasound images using wind driven optimization technique. Biomed. Signal Process. Control 2018, 40, 462–472. [Google Scholar] [CrossRef]
- Wang, L.; Gao, Y.; Shi, F.; Li, G.; Gilmore, J.; Lin, W.; Shen, D. Links: Learning-based multi-source integration framework for segmentation of infant brain images. NeuroImage 2014, 108, 160–172. [Google Scholar] [CrossRef] [Green Version]
- Nagaraj, Y.; Asha, C.S.; Hema Sai Teja, A.; Narasimhadhan, A.V. Carotid wall segmentation in longitudinal ultrasound images using structured random forest. Comput. Electr. Eng. 2018, 69, 753–767. [Google Scholar]
- Xu, H.; Ye, C.; Zhang, F.; Li, X.; Zhang, C. A Medical Image Segmentation Method with Anti-Noise and Bias-Field Correction. IEEE Access 2020, 8, 98548–98561. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [Green Version]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef]
- Manjón, J.V.; Coupe, P. MRI denoising using deep learning. In Proceedings of the International Workshop on Patch-Based Techniques in Medical Imaging, Granada, Spain, 20 September 2018; Springer: Cham, Switzerland, 2018; pp. 12–19. [Google Scholar]
- Jiang, D.; Dou, W.; Vosters, L.; Xu, X.; Sun, Y.; Tan, T. Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network. Jpn. J. Radiol. 2018, 36, 566–574. [Google Scholar] [CrossRef] [Green Version]
- Ran, M.; Hu, J.; Chen, Y.; Chen, H.; Sun, H.; Zhou, J.; Zhang, Y. Denoising of 3-Dmagnetic resonance images using a residual encoder-decoder wasserstein generative adversarial network. arXiv 2018, arXiv:1808.03941. [Google Scholar]
- Küstner, T.; Liebgott, A.; Mauch, L.; Martirosian, P.; Bamberg, F.; Nikolaou, K.; Yang, B.; Schick, F.; Gatidis, S. Automated reference-free detection of motion artifacts in magnetic resonance images. Magn. Reson. Mater. Phys. Biol. Med. 2018, 31, 243–256. [Google Scholar] [CrossRef]
- Vijay, S.; Kamalakanta, M. MIL based Visual Object Tracking with Kernel and Scale Adaptation. Signal Process. Image Commun. 2017, 53, 51–64. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention-MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Adiga, V.; Sivaswamy, J. FPD-M-net: Fingerprint Image Denoising and Inpainting Using M-net Based Convolutional Neural Networks. In Inpainting and Denoising Challenges; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The importance of skip connections in biomedical image segmentation. In Deep Learning and Data Labeling for Medical Applications; Springer: Cham, Switzerland, 2016; pp. 179–187. [Google Scholar]
- Wu, J.; Zhang, Y.; Wang, K.; Tang, X. Skip Connection U-Net for White Matter Hyperintensities Segmentation from MRI. IEEE Access 2019, 7, 155194–155202. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. CVPR 2015, 1, 3431–3440. [Google Scholar]
- Hu, Y.; Huber, A.E.; Anumula, J.; Liu, S. Overcoming the vanishing gradient problem in plain recurrent networks. arXiv 2018, arXiv:1801.06105. [Google Scholar]
- Li, C.; Zia, M.Z.; Tran, Q.-H.; Yu, X.; Hager, G.D.; Chandraker, M. Deep Supervision with Intermediate Concepts. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1828–1843. [Google Scholar] [CrossRef] [Green Version]
- Yamanakkanavar, N.; Lee, B. MF2-Net: A multipath feature fusion network for medical image segmentation. Eng. Appl. Artif. Intell. 2022, 114, 105004. [Google Scholar] [CrossRef]
- Lee, B.; Yamanakkanavar, N.; Choi, J.Y. Automatic segmentation of brain MRI using a novel patch-wise U-net deep architecture. PLoS ONE 2020, 15, e0236493. [Google Scholar] [CrossRef]
- Milletari, F.; Ahmadi, S.-A.; Kroll, C.; Plate, A.; Rozanski, V.; Maiostre, J.; Levin, J.; Dietrich, O.; Ertl-Wagner, B.; Bötzel, K.; et al. Hough-CNN: Deep learning for segmentation of deep brain regions in MRI and ultrasound. Comput. Vis. Image Underst. 2017, 164, 92–102. [Google Scholar] [CrossRef] [Green Version]
- Zhenglun, K.; Junyi, L.; Shengpu, X.; Ting, L. Automatical and accurate segmentation of cerebral tissues in fMRI dataset with combination of image processing and deep learning. SPIE 2018, 10485, 24–30. [Google Scholar]
- Ren, X.; Zhang, L.; Wei, D.; Shen, D.; Wang, Q. Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization. In Machine Learning in Medical Imaging MLMI 2019; Lecture Notes in Computer Science; Suk, H.I., Liu, M., Yan, P., Lian, C., Eds.; Springer: Cham, Switzerland, 2019; Volume 11861. [Google Scholar]
- Wachinger, C.; Reuter, M.; Klein, T. Deepnat: Deep convolutional neural network for segmenting neuroanatomy. NeuroImage 2018, 170, 434–445. [Google Scholar] [CrossRef]
- Jie, W.; Xia, Y.; Zhang, Y. M3Net: A multi-model, multi-size, and multi-view deep neural network for brain magnetic resonance image segmentation. Pattern Recognit. 2019, 91, 366–378. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. arXiv 2018, arXiv:1807.10165. [Google Scholar]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2009.13120. [Google Scholar] [CrossRef]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kong, Y.; Deng, Y.; Dai, Q. Discriminative Clustering and Feature Selection for Brain MRI Segmentation. IEEE Signal Process. Lett. 2015, 22, 573–577. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A Hierarchical Fused Fuzzy Deep Neural Network for Data Classification. IEEE Trans. Fuzzy Syst. 2016, 25, 1006–1012. [Google Scholar] [CrossRef]
- Yamanakkanavar, N.; Lee, B. A novel M-SegNet with global attention CNN architecture for automatic segmentation of brain MRI. Comput. Biol. Med. 2021, 136, 104761. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural networks. Adv. Neural Inf. Process. Syst. 2015, 2015, 1135–1143. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards Real-time Generic Object Detection. arXiv 2019, arXiv:1903.11752. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating fully convolutional networks with spatial and channel ’squeeze & excitation’ blocks. arXiv 2018, arXiv:1808.08127. [Google Scholar]
- Pereira, S.; Pinto, A.; Amorim, J.; Ribeiro, A.; Alves, V.; Silva, C.A. Adaptive Feature Recombination and Recalibration for Semantic Segmentation with Fully Convolutional Networks. IEEE Trans. Med. Imaging 2019, 38, 2914–2925. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention unet: Learning where to look for the pancreas. In Proceedings of the International Conference on Medical Imaging with Deep Learning (MIDL), Montréal, QC, Canada, 6–8 July 2018. [Google Scholar]
- Qin, Y.; Kamnitsas, K.; Ancha, S.; Nanavati, J.; Cottrell, G.; Criminisi, A.; Nori, A. Autofocus layer for semantic segmentation. arXiv 2018, arXiv:1805.08403. [Google Scholar]
- Wang, A.; Wang, M.; Jiang, K.; Cao, M.; Iwahori, Y. A Dual Neural Architecture Combined SqueezeNet with OctConv for LiDAR Data Classification. Sensors 2019, 19, 4927. [Google Scholar] [CrossRef] [Green Version]
- Nazanin, B.; Lennart, J. Squeeze U-Net: A Memory and Energy Efficient Image Segmentation Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–18 June 2020. [Google Scholar]
- Pulkit, K.; Pravin, N.; Chetan, A. U-SegNet: Fully Convolutional Neural Network based Automated Brain tissue segmentation Tool. In Proceedings of the 2018 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Yamanakkanavar, N.; Lee, B. Using a Patch-Wise M-Net Convolutional Neural Network for Tissue Segmentation in Brain MRI Images. IEEE Access 2020, 8, 120946–120958. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural network. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open access series of imaging studies (OASIS): Cross-sectional MRI data in young, middle aged, non-demented, and demented older adults. J. Cognit. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef] [Green Version]
- Center for Morphometric Analysis at Massachusetts General Hospital, The Internet Brain Segmentation Repository (IBSR) Dataset. Available online: https://www.nitrc.org/projects/ibsr, (accessed on 1 March 2022).
- Prechelt, L. Early Stopping—But When? In Neural Networks: Tricks of the Trade; Lecture Notes in Computer Science; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700. [Google Scholar]
- Schindelin, J.; Arganda-Carreras, I.; Frise, E.; Kaynig, V.; Longair, M.; Pietzsch, T.; Cardona, A. Fiji (ImageJ): An open-source platform for biological-image analysis. Nat. Methods 2012, 9, 676–682. [Google Scholar] [CrossRef] [Green Version]
- FMRIB Software Library (FSL) Software Suite. Available online: http://www.fmrib.ox.ac.uk/fsl (accessed on 8 November 2021).
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation–maximization algorithm. IEEE Trans. Med. Imaging 2001, 20, 45–57. [Google Scholar] [CrossRef]
- Fotenos, A.F.; Snyder, A.Z.; Girton, L.E.; Morris, J.C.; Buckner, R.L. Normative estimates of cross-sectional and longitudinal brain volume decline in aging and AD. Neurology 2005, 64, 1032–1039. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Jaccard, P. The distribution of the flora in the alpine zone.1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Gunter, R. Computing the Minimum Hausdorff Distance between Two Point Sets on a Line under Translation. Inf. Process. Lett. 1991, 38, 123–127. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Sergi, V.; Arnau, O.; Mariano, C.; Eloy, R.; Xavier, L. Comparison of 10 Brain Tissue Segmentation Methods Using Revisited IBSR annotations. J. Magn. Reson. Imaging JMRI 2015, 41, 93–101. [Google Scholar]
- Roy, S.; Carass, A.; Bazin, P.-L.; Resnick, S.; Prince, J.L. Consistent segmentation using a Rician classifier. Med. Image Anal. 2012, 16, 524–535. [Google Scholar] [CrossRef] [Green Version]
- Bao, S.; Chung, A.C.S. Multi-scale structured CNN with label consistency for brain MR image segmentation. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2016, 6, 113–117. [Google Scholar] [CrossRef]
- Khagi, B.; Kwon, G.-R. Pixel-Label-Based Segmentation of Cross-Sectional Brain MRI Using Simplified SegNet Architecture-Based CNN. J. Health Eng. 2018, 2018, 2040–2295. [Google Scholar] [CrossRef] [Green Version]
- Shakeri, M.; Tsogkas, S.; Ferrante, E.; Lippe, S.; Kadoury, S.; Paragios, N.; Kokkinos, I. Sub-cortical brain structure segmentation using F-CNNs. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016. [Google Scholar]
- Dolz, J.; Desrosiers, C.; Ben Ayed, I. 3D fully convolutional networks for subcortical segmentation in MRI: A large-scale study. NeuroImage 2018, 170, 456–470. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, R.; Deng, H.; Wang, L.; Lin, W.; Ji, S.; Shen, D. Deep convolutional neural networks for multi-modality isointense infant brain image segmentation. NeuroImage 2015, 108, 214–224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, N.; Wang, L.; Gao, Y.; Shen, D. Fully convolutional networks for multi-modality isointense infant brain image segmentation. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 1342–1345. [Google Scholar]
- Chen, C.-C.C.; Chai, J.-W.; Chen, H.-C.; Wang, H.C.; Chang, Y.-C.; Wu, Y.-Y.; Chen, W.-H.; Chen, H.-M.; Lee, S.-K.; Chang, C.-I. An Iterative Mixed Pixel Classification for Brain Tissues and White Matter Hyperintensity in Magnetic Resonance Imaging. IEEE Access 2019, 7, 124674–124687. [Google Scholar] [CrossRef]
- Islam, K.T.; Wijewickrema, S.; O’Leary, S. A Deep Learning Framework for Segmenting Brain Tumors Using MRI and Synthetically Generated CT Images. Sensors 2022, 22, 523. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Hu, C.; Liu, Z.; Zhou, Y. MRI Segmentation of Brain Tissue and Course Classification in Alzheimer’s Disease. Electronics 2022, 11, 1288. [Google Scholar] [CrossRef]
- Cocosco, C.A.; Kollokian, V.; Kwan, R.K.-S.; Evans, A.C. BrainWeb: Online Interface to a 3D MRI Simulated Brain Database. NeuroImage 1997, 5, S425. [Google Scholar]
- Özgün, C.; Ahmed, A.; Soeren, L.; Thomas, B.; Olaf, R. 3D U-Net: Learning Dense Volumetric Segmentation from sparse annotation. In Medical Image Computing and Computer-Assisted Intervention; LNCS 9901; Springer: Cham, Switzerland, 2016; pp. 424–432. [Google Scholar]
- Wang, G.; Zuluaga, M.A.; Pratt, R.; Aertsen, M.; Doel, T.; Klusmann, M.; David, A.L.; Deprest, J.; Vercauteren, T.; Ourselin, S. Slic-Seg: A minimally interactive segmentation of the placenta from sparse and motion-corrupted fetal MRI in multiple views. Med. Image Anal. 2016, 34, 137–147. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Number of Subjects | |
|---|---|---|
| OASIS | IBSR | |
| Males | 160 | 14 |
| Females | 256 | 4 |
| Total | 416 | 18 |
| OASIS | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Axial Plane | |||||||||
| Methods | WM | GM | CSF | ||||||
| DSC | JI | HD | DSC | JI | HD | DSC | JI | HD | |
| SegNet [19] | 0.087 | 0.096 | 0.077 | 0.069 | 0.089 | 0.053 | 0.048 | 0.068 | 0.079 |
| U-net [20] | 0.059 | 0.068 | 0.064 | 0.048 | 0.061 | 0.046 | 0.076 | 0.090 | 0.039 |
| M-net [21] | 0.046 | 0.057 | 0.023 | 0.055 | 0.072 | 0.077 | 0.044 | 0.065 | 0.043 |
| U-net++ [34] | 0.053 | 0.062 | 0.048 | 0.035 | 0.048 | 0.025 | 0.039 | 0.052 | 0.036 |
| CE-Net [36] | 0.039 | 0.044 | 0.050 | 0.042 | 0.057 | 0.044 | 0.043 | 0.063 | 0.061 |
| M-SegNet [39] | 0.030 | 0.053 | 0.041 | 0.033 | 0.048 | 0.026 | 0.029 | 0.042 | 0.032 |
| Proposed | 0.032 | 0.040 | 0.028 | 0.027 | 0.034 | 0.019 | 0.021 | 0.036 | 0.015 |
| Coronal Plane | |||||||||
| SegNet [19] | 0.058 | 0.065 | 0.023 | 0.044 | 0.068 | 0.053 | 0.056 | 0.074 | 0.084 |
| U-net [20] | 0.043 | 0.059 | 0.042 | 0.057 | 0.069 | 0.042 | 0.063 | 0.081 | 0.073 |
| M-net [21] | 0.048 | 0.060 | 0.066 | 0.021 | 0.032 | 0.038 | 0.034 | 0.051 | 0.032 |
| U-net++ [34] | 0.066 | 0.073 | 0.047 | 0.042 | 0.057 | 0.044 | 0.048 | 0.059 | 0.043 |
| CE-Net [36] | 0.031 | 0.046 | 0.076 | 0.038 | 0.050 | 0.071 | 0.039 | 0.053 | 0.050 |
| M-SegNet [39] | 0.024 | 0.038 | 0.046 | 0.024 | 0.036 | 0.066 | 0.032 | 0.048 | 0.036 |
| Proposed | 0.023 | 0.032 | 0.038 | 0.033 | 0.046 | 0.054 | 0.044 | 0.062 | 0.028 |
| Sagittal plane | |||||||||
| SegNet [19] | 0.054 | 0.066 | 0.027 | 0.083 | 0.095 | 0.033 | 0.040 | 0.057 | 0.088 |
| U-net [20] | 0.058 | 0.070 | 0.030 | 0.074 | 0.090 | 0.026 | 0.058 | 0.073 | 0.079 |
| M-net [21] | 0.038 | 0.045 | 0.046 | 0.083 | 0.094 | 0.026 | 0.029 | 0.046 | 0.082 |
| U-net++ [34] | 0.060 | 0.072 | 0.031 | 0.038 | 0.049 | 0.019 | 0.041 | 0.063 | 0.041 |
| CE-Net [36] | 0.043 | 0.064 | 0.020 | 0.025 | 0.037 | 0.034 | 0.051 | 0.062 | 0.055 |
| M-SegNet [39] | 0.029 | 0.047 | 0.035 | 0.021 | 0.035 | 0.042 | 0.036 | 0.047 | 0.027 |
| Proposed | 0.035 | 0.044 | 0.038 | 0.044 | 0.056 | 0.035 | 0.058 | 0.073 | 0.045 |
| Axial Plane | |||||||||
| SegNet [19] | 0.036 | 0.042 | 0.65 | 0.049 | 0.058 | 0.91 | 0.079 | 0.095 | 0.46 |
| U-net [20] | 0.022 | 0.034 | 0.51 | 0.027 | 0.038 | 0.51 | 0.062 | 0.079 | 0.31 |
| M-net [21] | 0.043 | 0.051 | 0.39 | 0.053 | 0.068 | 0.65 | 0.039 | 0.048 | 0.18 |
| U-net++ [34] | 0.085 | 0.096 | 0.36 | 0.037 | 0.049 | 0.29 | 0.058 | 0.072 | 0.64 |
| CE-Net [36] | 0.055 | 0.073 | 0.84 | 0.068 | 0.083 | 0.38 | 0.037 | 0.054 | 0.93 |
| M-SegNet [39] | 0.038 | 0.049 | 0.64 | 0.055 | 0.028 | 0.47 | 0.032 | 0.055 | 0.24 |
| Proposed | 0.042 | 0.054 | 0.57 | 0.026 | 0.040 | 0.92 | 0.026 | 0.039 | 0.79 |
| Coronal Plane | |||||||||
| SegNet [19] | 0.043 | 0.052 | 0.82 | 0.037 | 0.052 | 0.84 | 0.064 | 0.086 | 0.75 |
| U-net [20] | 0.035 | 0.046 | 0.67 | 0.044 | 0.056 | 0.38 | 0.028 | 0.043 | 0.47 |
| M-net [21] | 0.046 | 0.058 | 0.21 | 0.035 | 0.043 | 0.19 | 0.075 | 0.093 | 0.25 |
| U-net++ [34] | 0.059 | 0.073 | 0.39 | 0.063 | 0.078 | 0.24 | 0.048 | 0.067 | 0.39 |
| CE-Net [36] | 0.054 | 0.066 | 0.21 | 0.049 | 0.068 | 0.93 | 0.056 | 0.072 | 0.20 |
| M-SegNet [39] | 0.026 | 0.043 | 0.42 | 0.071 | 0.040 | 0.36 | 0.033 | 0.047 | 0.52 |
| Proposed | 0.039 | 0.051 | 0.43 | 0.019 | 0.032 | 0.67 | 0.022 | 0.034 | 0.12 |
| Sagittal Plane | |||||||||
| SegNet [19] | 0.036 | 0.048 | 0.61 | 0.073 | 0.089 | 0.76 | 0.073 | 0.092 | 0.41 |
| U-net [20] | 0.049 | 0.062 | 0.37 | 0.036 | 0.045 | 0.21 | 0.071 | 0.089 | 0.15 |
| M-net [21] | 0.026 | 0.038 | 0.14 | 0.045 | 0.062 | 0.06 | 0.056 | 0.073 | 0.09 |
| U-net++ [34] | 0.033 | 0.045 | 0.54 | 0.063 | 0.081 | 0.22 | 0.049 | 0.070 | 0.44 |
| CE-Net [36] | 0.054 | 0.065 | 0.66 | 0.051 | 0.077 | 0.55 | 0.033 | 0.045 | 0.37 |
| M-SegNet [39] | 0.032 | 0.049 | 0.52 | 0.029 | 0.042 | 0.31 | 0.020 | 0.035 | 0.32 |
| Proposed | 0.035 | 0.053 | 0.36 | 0.028 | 0.043 | 0.18 | 0.024 | 0.039 | 0.66 |
| Methods | WM | GM | CSF | Parameters | Training Time | |||
|---|---|---|---|---|---|---|---|---|
| DSC | JI | DSC | JI | DSC | JI | |||
| M-SegNet only | 0.94 | 0.89 | 0.95 | 0.90 | 0.94 | 0.89 | 5,468,932 | 3.09 h |
| SM-SegNet without long skip | 0.95 | 0.90 | 0.94 | 0.89 | 0.94 | 0.89 | 835,770 | 1.50 h |
| M-SegNet with long skip | 0.96 | 0.92 | 0.95 | 0.90 | 0.94 | 0.89 | 5,468,944 | 3.15 h |
| Combined | 0.97 | 0.94 | 0.96 | 0.92 | 0.95 | 0.90 | 835,776 | 1.30 h |
| Patch Size | WM | GM | CSF | Training Time | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DSC | JI | HD | DSC | JI | HD | DSC | JI | HD | ||
| 3232 | 0.98 | 0.96 | 3.10 | 0.97 | 0.94 | 3.05 | 0.96 | 0.92 | 3.15 | 13.90 h |
| 6464 | 0.98 | 0.96 | 3.16 | 0.97 | 0.94 | 3.09 | 0.95 | 0.90 | 3.19 | 6.50 h |
| 128128 | 0.97 | 0.94 | 3.25 | 0.96 | 0.92 | 3.15 | 0.95 | 0.90 | 3.22 | 1.30 h |
| No. | Parameters | Overlapping Patches | Non-Overlapping Patches |
|---|---|---|---|
| 1 | Input size | 128 | 128 |
| 2 | Training set | 120 subjects | 120 subjects |
| 3 | Testing set | 30 subjects | 30 subjects |
| 4 | # of patches | 32 (stride: 8 pixels) | 4 |
| 5 | # of epochs | 10 | 10 |
| 6 | DSC | 0.97 | 0.96 |
| 7 | JI | 0.94 | 0.92 |
| 8 | Training time | 28.5 h | 1.3 h |
| Methods | DSC and JI | Datasets | Features | |||
|---|---|---|---|---|---|---|
| GM | WM | CSF | ||||
| 1 | Bao [67] | 0.85 | 0.82 | 0.82 | IBSR | Multi-scale structured CNN |
| 2 | Khagi [68] | 0.74 | 0.81 | 0.72 | OASIS | Simplified SegNet architecture |
| 3 | Shakeri [69] | 0.82 | 0.82 | 0.82 | IBSR | Multi-label segmentation using fully CNN (FCNN) |
| 4 | Dolz [70] | 0.90 | 0.90 | 0.90 | IBSR | 3D FCNN |
| 5 | Proposed | 0.96 | 0.97 | 0.95 | OASIS | Patch-wise-based SM-SegNet architecture |
| 0.92 | 0.90 | 0.83 | IBSR | |||
| Sets | Training (Subject #) | Test (Subject #) | Parameter | GM | WM | CSF |
|---|---|---|---|---|---|---|
| TestSet0 | 6–17 | 0–5 | DSC | 0.91 | 0.88 | 0.79 |
| JI | 0.83 | 0.79 | 0.65 | |||
| TestSet1 | 0–5 and 12–7 | 6–11 | DSC | 0.90 | 0.90 | 0.80 |
| JI | 0.82 | 0.82 | 0.67 | |||
| TestSet2 | 0–11 | 12–17 | DSC | 0.92 | 0.89 | 0.83 |
| JI | 0.85 | 0.80 | 0.71 |
| Metrics | SegNet vs. Proposed | U-Net vs. Proposed | M-Net vs. Proposed | U-Net++ vs. Proposed | CE-Net vs. Proposed |
|---|---|---|---|---|---|
| DSC | 0.018 | 0.026 | 0.029 | 0.034 | 0.038 |
| Model | Training Set | Test Set | DSC | ||
|---|---|---|---|---|---|
| GM | WM | CSF | |||
| Proposed | IBSR—18 Subjects | OASIS—15 Subjects | 0.81 | 0.88 | 0.63 |
| OASIS—50 Subjects | IBSR—18 Subjects | 0.60 | 0.67 | 0.54 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamanakkanavar, N.; Choi, J.Y.; Lee, B. SM-SegNet: A Lightweight Squeeze M-SegNet for Tissue Segmentation in Brain MRI Scans. Sensors 2022, 22, 5148. https://doi.org/10.3390/s22145148
Yamanakkanavar N, Choi JY, Lee B. SM-SegNet: A Lightweight Squeeze M-SegNet for Tissue Segmentation in Brain MRI Scans. Sensors. 2022; 22(14):5148. https://doi.org/10.3390/s22145148
Chicago/Turabian StyleYamanakkanavar, Nagaraj, Jae Young Choi, and Bumshik Lee. 2022. "SM-SegNet: A Lightweight Squeeze M-SegNet for Tissue Segmentation in Brain MRI Scans" Sensors 22, no. 14: 5148. https://doi.org/10.3390/s22145148
APA StyleYamanakkanavar, N., Choi, J. Y., & Lee, B. (2022). SM-SegNet: A Lightweight Squeeze M-SegNet for Tissue Segmentation in Brain MRI Scans. Sensors, 22(14), 5148. https://doi.org/10.3390/s22145148