
An Oversampling Method of Unbalanced Data for Mechanical Fault Diagnosis Based on MeanRadius-SMOTE


Abstract
:1. Introduction
2. Related Works
2.1. SMOTE
- (1)
- For each sample x in the training set, calculate their Euclidean distance to each minority class sample xi, and obtain the k nearest neighbors of each minority class sample.
- (2)
- According to the sample imbalance rate, set the sampling ratio N. For xi, randomly select N samples from its k nearest neighbors, denoted as xh.
- (3)
- According to Equation (1), build new samples based on xi and xh until the classes are balanced, denoted as xnew.
2.2. LR-SMOTE
- (1)
- Use SVM to classify the data set, and then for the wrongly classified minority samples use the K-means method to judge and remove the noise samples.
- (2)
- Use K-means to find the center xc of the minority class sample, calculate the distance di from each minority class sample to the center xc, and calculate the average distance dm.
- (3)
- For each minority class sample xi, calculate the ratio Mi of the average distance dm and the distance di.
- (4)
- According to the number of the same samples in the neighbor samples, set the weight of each minority class sample, and then randomly select a minority class sample xi and build new samples xnew according to Equation (2).
- (5)
- Repeat steps 3 and 4 until the number of samples of the majority class and minority class is balanced.
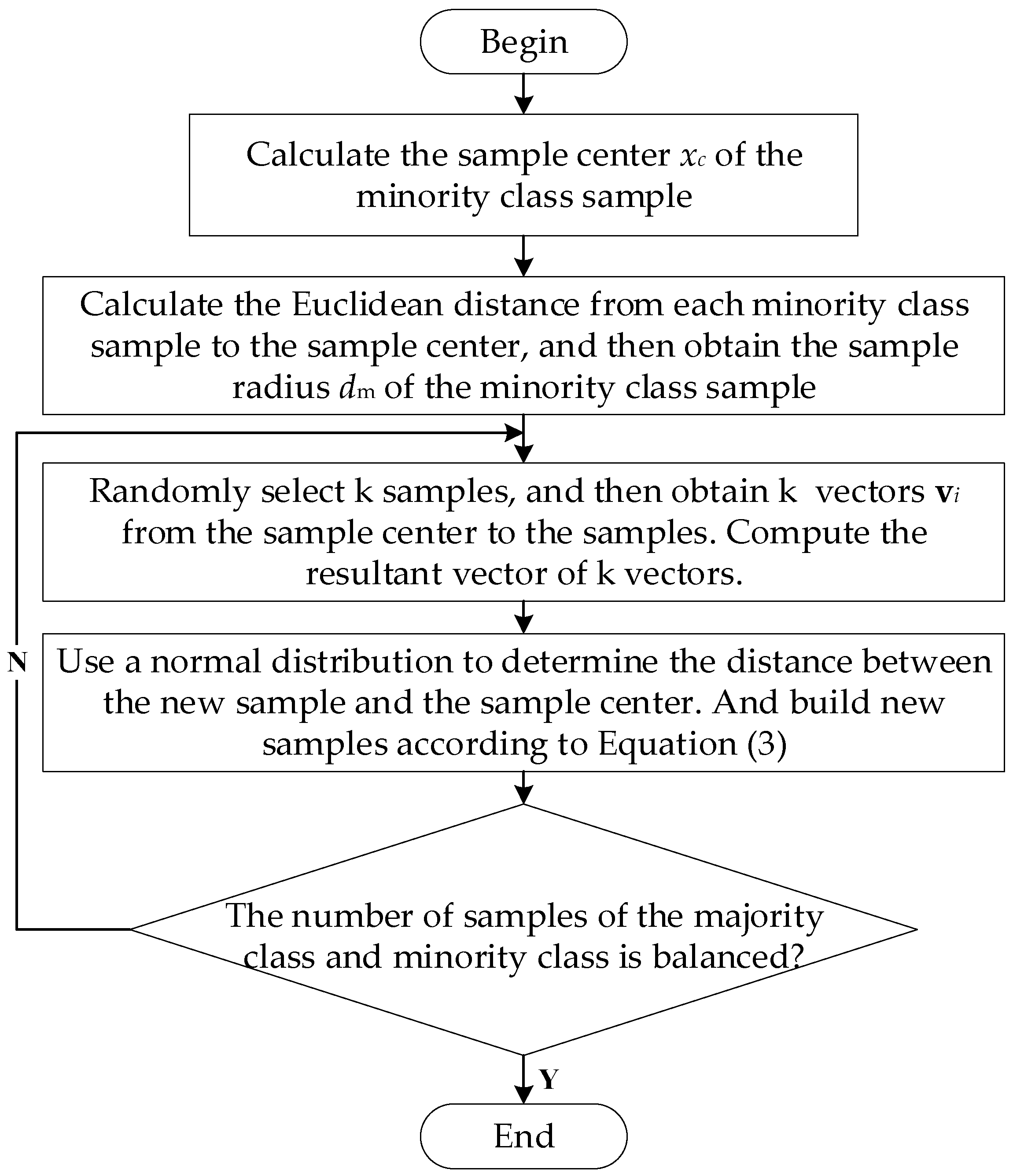
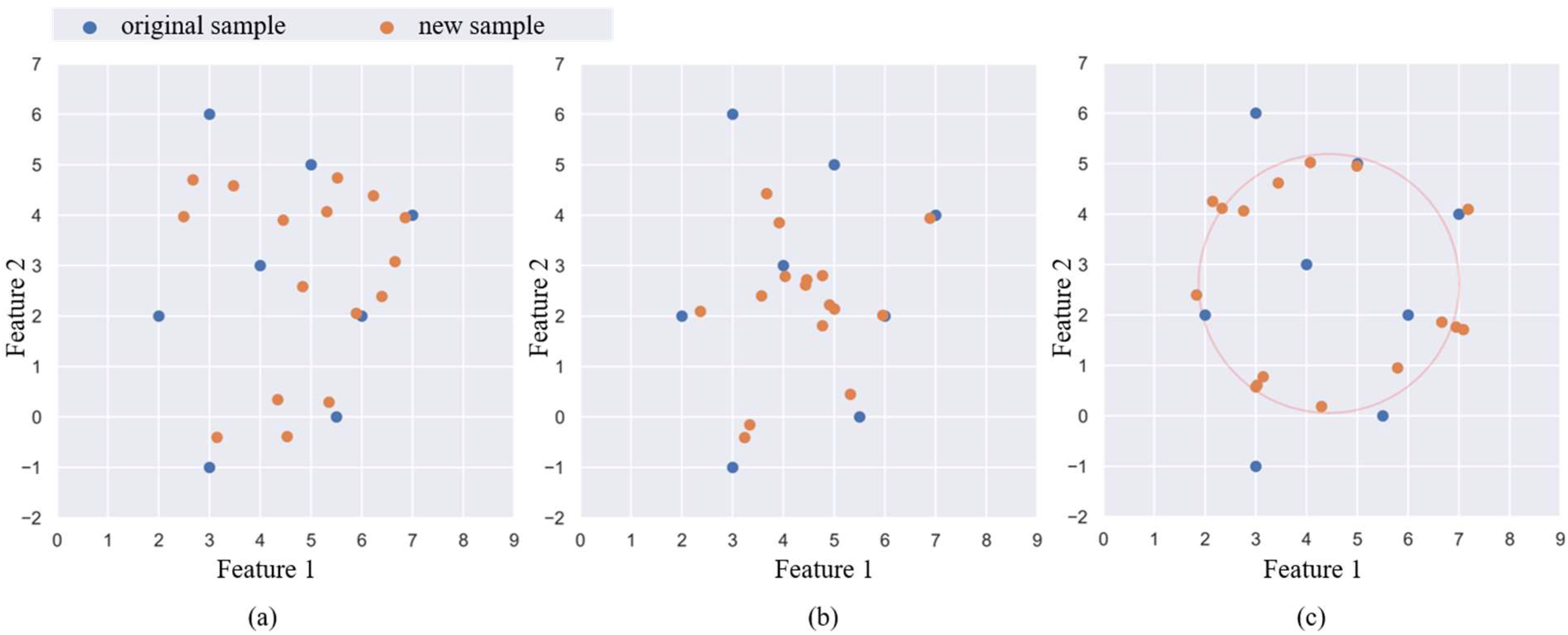
3. Proposed Method
- (1)
- According to each minority class sample, calculate the geometric center, denoted as the sample center xc of the minority class sample.
- (2)
- Calculate the Euclidean distance from each minority class sample to the sample center, and then obtain the average distance, denoted as the sample radius dm of the minority class.
- (3)
- Randomly select k minority class samples, and then obtain k vectors vi from the sample center xc to the samples. Compute the resultant vector of k vectors.
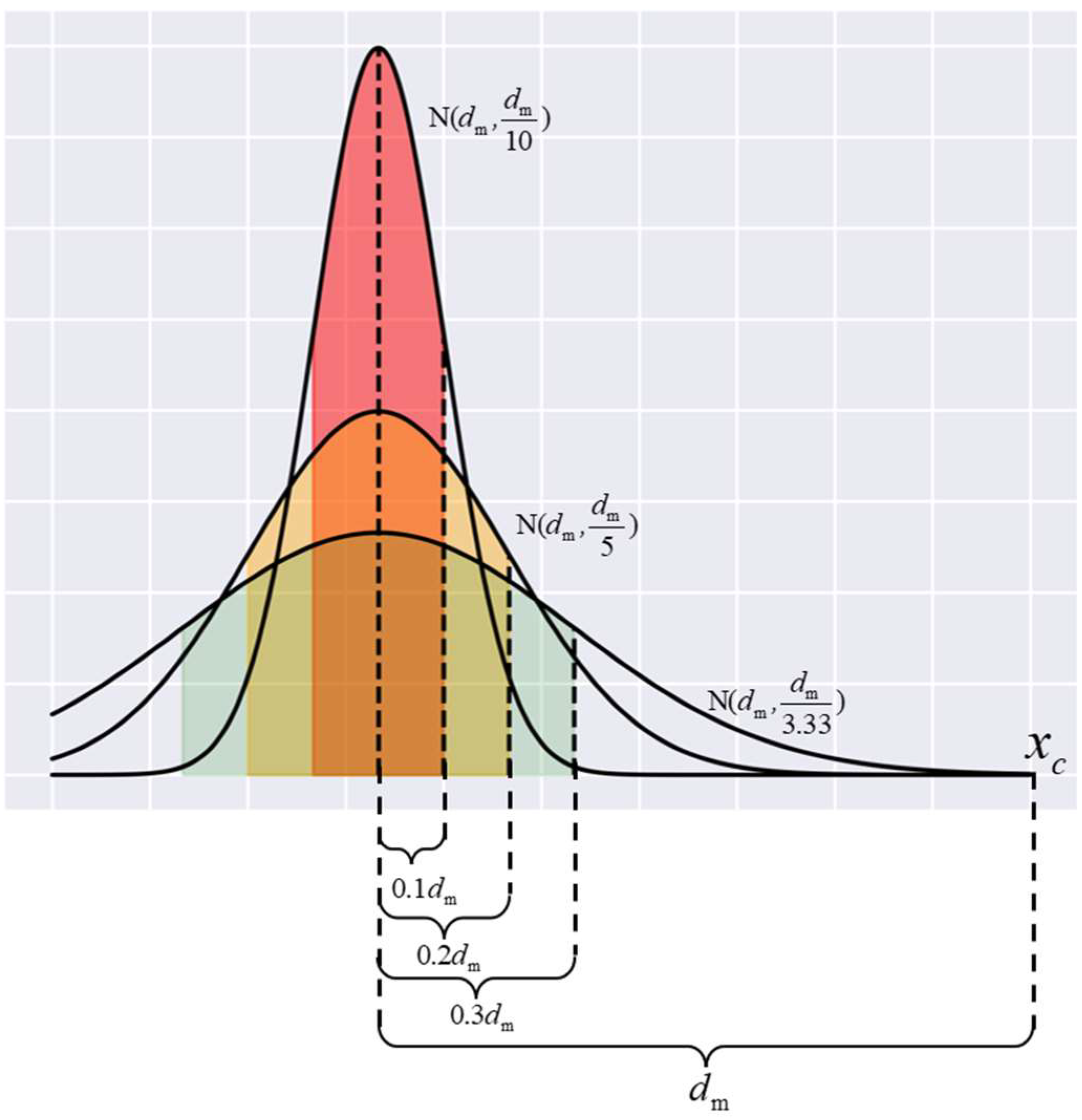
- (4)
- Use a normal distribution with mean dm and variance to determine the distance between the new sample and the sample canter. According to Equation (3), build new samples.
- (5)
- Repeat steps 3 and 4 until the number of samples of the majority class and minority class is balanced.
4. Experimental Preparation
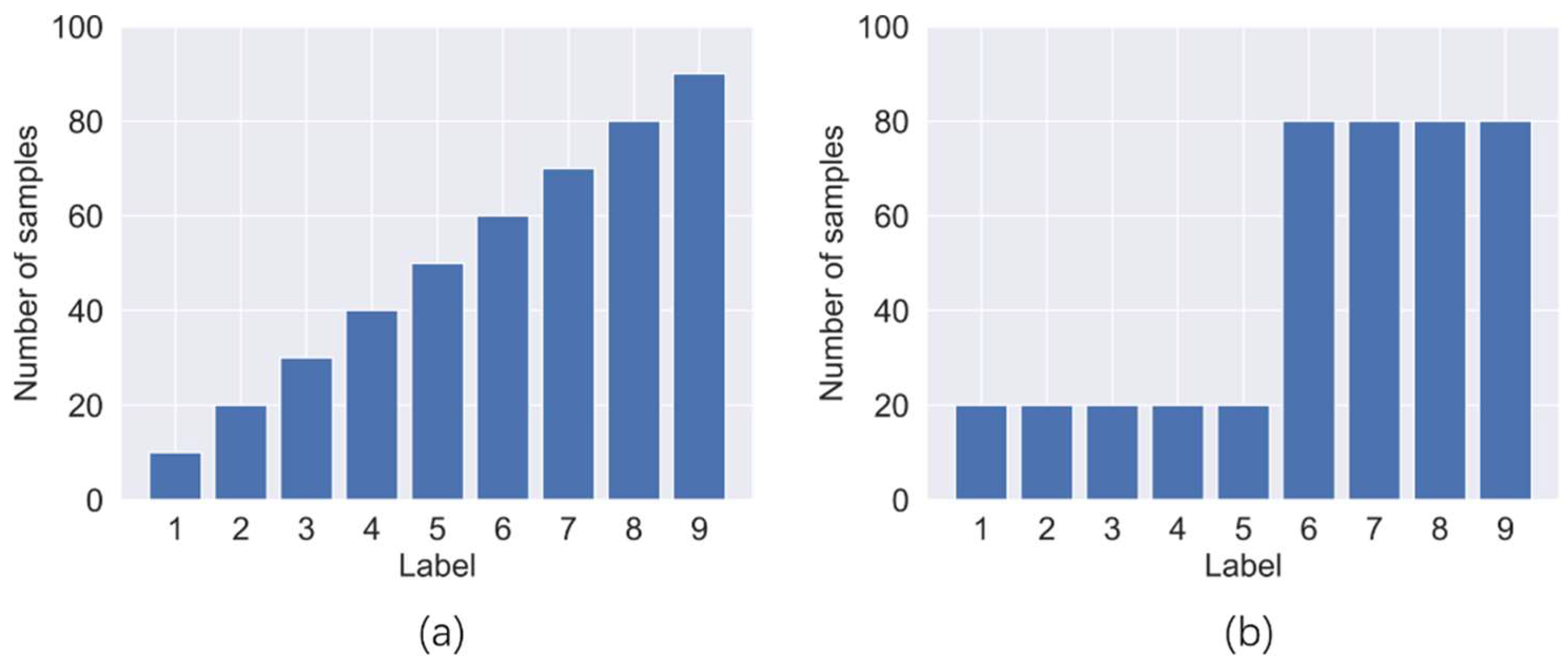
4.1. Data Set
4.2. Classifiers
4.3. Evaluation Indicators
- (1)
- Accuracy (Acc): The Acc value is the ratio of the number of correctly predicted samples to the total number of samples. The calculation method is as shown in Equation (4):The Acc value evaluates the overall prediction, but in the case of unbalanced data sets, it is not a good indicator to measure the results.
- (2)
- Macro-Precision (Mac-P): The calculation method of the Precision value for class i samples is as shown in Equation (5):In the multi-classification problem, the Precision value is divided into Macro and Micro methods. Micro-Precision focuses more on types of samples with a large number of samples, so it is more susceptible to the majority class. However, Mac-P will treat each type of sample equally, so it can better describe the model’s ability to deal with unbalanced data sets. The calculation method is as shown in Equation (6):
- (3)
- Macro-F1 (Mac-F1): It is contradictory to improve the Precision value and Recall value at the same time. The F1 value is a balance point with high Precision value and high Recall value, and its calculation method is as shown in Equation (7):In the multi-classification problem, The F1 value also has Macro and Micro methods such as the Precision value. This paper selects Mac-F1, which can better take into account the minority class. The calculation method is as shown in Equation (8):
- (4)
- Precision-Minority (Presmall): In order to pay more attention to the prediction effect of the model on the minority class samples after oversampling algorithms, we will calculate the Precision value of the minority class as an indicator, and its calculation method is as shown in Equation (9):
5. Experimental Design and Results
- (1)
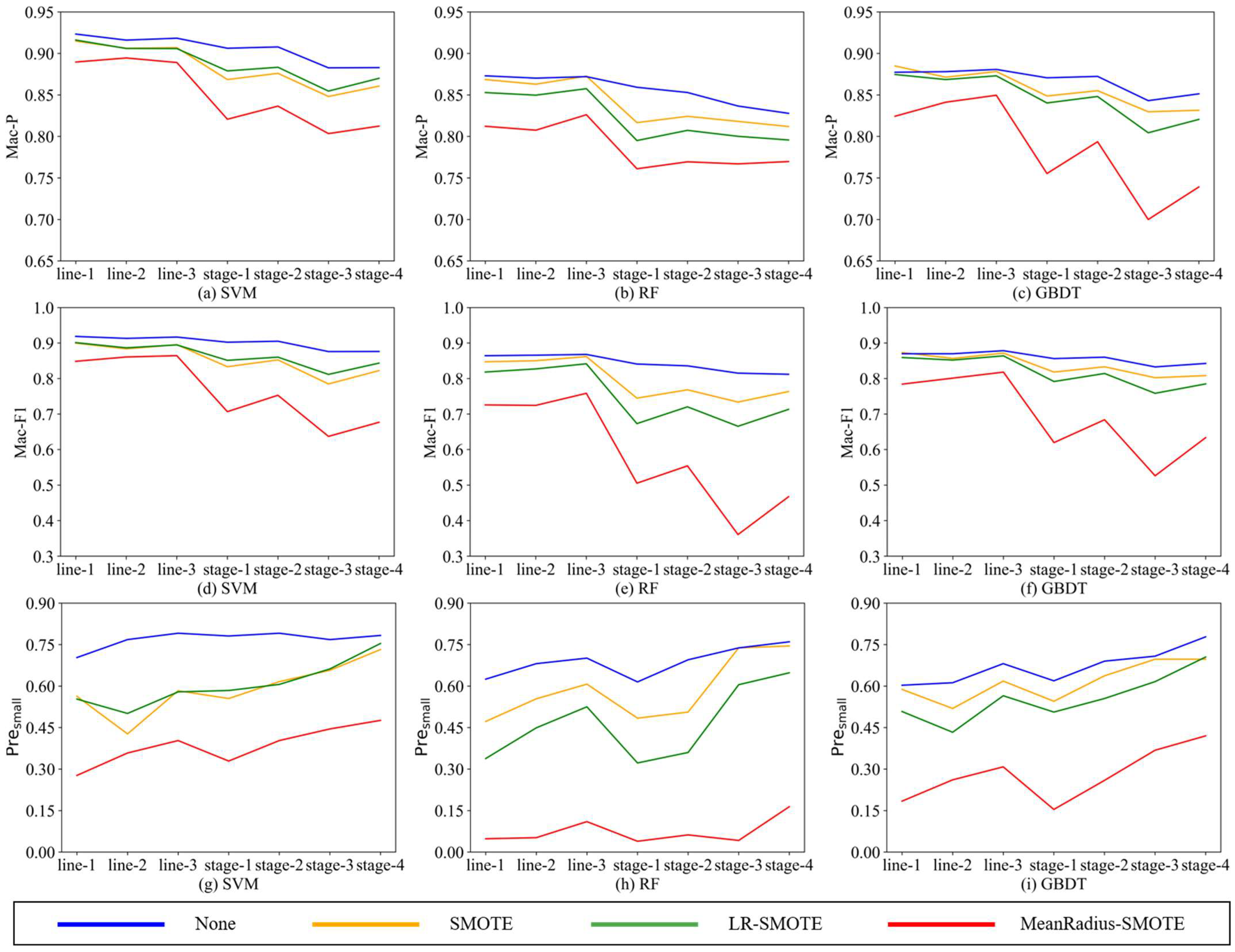
- Since these seven unbalanced data sets are homologous, the better the oversampling algorithm, the closer the indicators should be. Comparing the nine charts, all indicators are relatively stable in the MeanRadius-SMOTE experiment, which is less affected by the imbalance rate and data set form, and this stabilization is more obvious in the SVM classifier. This shows that MeanRadius-SMOTE has good robustness.
- (2)
- Analyzing the three charts—Figure 6a,d,g, in the seven data sets, MeanRadius-SMOTE on the SVM classifier can not only ensure that the overall prediction indicators reach about 0.9 but also ensure that Presmall is relatively high, about 0.75.
- (3)
- Comparing the three charts—Figure 6g–i, the SVM experiment can achieve a higher Presmall, and in most experiments, Presmall is greatly affected by the data sets, especially in the RF experiments. However, only in the model composed of MeanRadius-SMOTE and SVM do we obtain a very flat line, which shows that this model has good robustness and accuracy in predicting the minority class.
- (4)
- Comparing the three charts—Figure 6a–c, for SMOTE and LR-SMOTE, LR-SMOTE performs better than SMOTE on SVM, while it is the opposite on RF and GBDT. In addition, SMOTE even outperforms MeanRadius-SMOTE in some GBDT experiments. LR-SMOTE is also an oversampling algorithm for binary classification problems, which is more suitable for a classifier that is essentially a binary classification algorithm-SVM. Therefore, it can be inferred that MeanRadius-SMOTE is also more suitable for SVM classifiers.
6. Conclusions and Outlook
- (1)
- In this paper, in order to ensure that the experiment is carried out under a variety of unbalanced data sets, we use artificial unbalanced data sets in experiments. In future research, we will collect the failure unbalanced data sets of actual mechanical equipment to continue the verification experiment.
- (2)
- When constructing the data set in this paper, we only extracted the time–frequency domain features from the vibration signal. Currently, there are more methods to extract features from vibration signals, such as convolutional neural networks, wavelet packet decomposition, etc. Training sets composed of different types of features may have an impact on the performance of MeanRadius-SMOTE.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yongbo, L.; Wang, S.; Deng, Z. Intelligent fault identification of rotary machinery using refined composite multi-scale Lempel–Ziv complexity. J. Manuf. Syst. 2021, 61, 725–735. [Google Scholar]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor data fusion with Z-numbers and its application in fault diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal. Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Lu, S.; He, Q.; Yuan, T.; Kong, F. Online fault diagnosis of motor bearing via stochastic-resonance-based adaptive filter in an embedded. IEEE Trans. Syst. Man Cybern A 2018, 47, 1111–1122. [Google Scholar] [CrossRef]
- Cai, B.; Zhao, Y.; Liu, H.; Xie, M. A data-driven fault diagnosis methodology in Three-Phase inverters for PMSM drive systems. IEEE Trans. Power Electron. 2017, 32, 5590–5600. [Google Scholar] [CrossRef]
- Cofre-Martel, S.; Droguett, E.; Modarres, M. Big Machinery Data Preprocessing Methodology for Data-Driven Models in Prognostics and Health Management. Sensors 2021, 21, 6841. [Google Scholar] [CrossRef]
- Akilu, Y.; Sinha, J.; Nembhard, A. A novel fault diagnosis technique for enhancing maintenance and reliability of rotating machines. Struct. Health Monit. 2015, 14, 604–621. [Google Scholar]
- Yongbo, L.; Wang, X.; Si, S.; Huang, S. Entropy Based Fault Classification Using the Case Western Reserve University Data: A Benchmark Study. IEEE Trans. Reliab. 2020, 69, 754–767. [Google Scholar]
- Fernandez, A.; Garcia, S.; Luengo, J.; Bernado-Mansilla, E.; Herrera, F. Genetics-based machine learning for rule induction: State of the art, Taxonomy, and Comparative Study. IEEE Trans. Evol. Comput. 2010, 14, 913–941. [Google Scholar] [CrossRef]
- Swana, E.; Doorsamy, W.; Bokoro, P. Tomek Link and SMOTE Approaches for Machine Fault Classification with an Imbalanced Dataset. Sensors 2022, 22, 3246. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.; Jing, L.; Cheng, J.; Yang, Y. Transfer fault diagnosis of bearing installed in different machines using enhanced deep auto-encoder. Measurement 2020, 152, 107393. [Google Scholar]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [PubMed]
- Shao, H.; Lin, J.; Zhang, L.; Galar, D.; Kumar, U. A novel approach of multisensory fusion to collaborative fault diagnosis in maintenance. Inf. Fusion 2021, 74, 65–76. [Google Scholar] [CrossRef]
- Martin-Diaz, I.; Morinigo-Sotelo, D.; Duque-Perez, O.; De, R. Early fault detection in induction motors using adaboost with imbalanced small data and optimized sampling. IEEE Trans. Ind. Electron. 2022, 53, 3066–3075. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Pan, T.; He, S. A small sample focused intelligent fault diagnosis scheme of machines via multi-modules learning with gradient penalized generative adversarial networks. IEEE Trans. Ind. Electron. 2021, 68, 10130–10141. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. 2017, 45, 351–400. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Chawla, N.; Hall, L.; Bowyer, K.; Kegelmeyer, W. SMOTE: Synthetic minority over-sampling technique. Artif. Intell. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the Conference on Aristophanes Upstairs and Downstairs, Magdalen Coll, Oxford, UK, 16–18 September 2004. [Google Scholar]
- Haibo, H.; Yang, B.; Garcia, E.; Shutao, L. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105846. [Google Scholar] [CrossRef]
- Yen, S.; Lee, Y. Under-sampling approaches for improving prediction of the minority class in an imbalanced dataset. In Proceedings of the International Conference on Intelligent Computing, Kunming, China, 16–19 August 2006. [Google Scholar]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the 8th Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001. [Google Scholar]
- Zhang, C.; Gao, W.; Song, J.; Jiang, J. An imbalanced data classification algorithm of improved autoencoder neural network. In Proceedings of the 8th International Conference on Advanced Computational Intelligence, Chiang Mai, Thailand, 14–16 February 2016. [Google Scholar]
- Cheng, F.; Zhang, J.; Wen, C. Cost-sensitive large margin distribution machine for classification of imbalanced data. Pattern Recognit. Lett. 2016, 80, 107–112. [Google Scholar] [CrossRef]
- Xu, Q.; Lu, S.; Jia, W.; Jiang, C. Imbalanced fault diagnosis of rotating machinery via multi-domain feature extraction and cost-sensitive learning. J. Manuf. Syst. 2020, 31, 1467–1481. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M.; Lin, M. Deep laplacian auto-encoder and its application into imbalanced fault diagnosis of rotating machinery. Measurement 2020, 31, 1467–1481. [Google Scholar] [CrossRef]
- Yongbo, L.; Du, X.; Wang, X.; Si, S. Industrial gearbox fault diagnosis based on multi-scale convolutional neural networks and thermal imaging. ISA Trans. 2022, in press. [Google Scholar]
- Yongbo, L.; Wang, S.; Yang, Y.; Deng, Z. Multiscale symbolic fuzzy entropy: An entropy denoising method for weak feature extraction of rotating machinery. Mech. Syst. Signal. Process. 2022, 162, 108052. [Google Scholar]
- Zhang, C.; Chen, J.; Guo, X. A gear fault diagnosis method based on EMD energy entropy and SVM. Shock Vib. 2010, 29, 216–220. [Google Scholar]
- Yongbo, L.; Wang, X.; Si, S.; Du, X. A New Intelligent Fault Diagnosis Method of Rotating Machinery under Varying-Speed Conditions Using Infrared Thermography. Complexity 2019, 2019, 2619252. [Google Scholar]
- Farajzadeh-Zanjani, M.; Razavi-Far, R.; Saif, M. Efficient sampling techniques for ensemble learning and diagnosing bearing defects under class imbalanced condition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016. [Google Scholar]
- Mao, W.; He, L.; Yan, Y.; Wang, J. Online sequential prediction of bearings imbalanced fault diagnosis by extreme learning machine. Mech. Syst. Signal. Process. 2017, 83, 450–473. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Farajzadeh-Zanjani, M.; Saif, M. An integrated class-imbalanced learning scheme for diagnosing bearing defects in induction motors. IEEE Trans. Ind. Inform. 2017, 13, 2758–2769. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal. Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Lan, Y.; Han, X.; Xiong, X.; Huang, J.; Zong, W.; Ding, X.; Ma, B. Two-step fault diagnosis framework for rolling element bearings with imbalanced data based on GSA-WELM and GSA-ELM. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2018, 232, 2937–2947. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Zhang, K.; Zhoudong, H.; Yi, C. Review of multiple fault diagnosis methods. IET Control Theory Appl. 2015, 32, 1143–1157. [Google Scholar]
- Lei, Y.; He, Z.; Zi, Y.; Hu, Q. Fault diagnosis of rotating machinery based on multiple ANFIS combination with GAs. Mech. Syst. Signal. Process. 2007, 21, 2280–2294. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | |
|---|---|---|---|---|---|---|---|---|
| Feature 1 | 3 | 4 | 6 | 7 | 5 | 2 | 3 | 5.5 |
| Feature 2 | 6 | 3 | 2 | 4 | 5 | 2 | −1 | 0 |
| Label | Description |
|---|---|
| Label 1 | Good |
| Label 2 | Gear chipped and eccentric |
| Label 3 | Gear eccentric |
| Label 4 | Gear eccentric and broken, bearing ball fault |
| Label 5 | Gear chipped and eccentric and broken, bearing inner and ball and outer fault |
| Label 6 | Gear broken, bearing inner and ball and outer fault, shaft imbalance |
| Label 7 | Bearing inner fault, shaft keyway sheared |
| Label 8 | Bearing ball and outer fault, shaft imbalance |
| Time-Domain Feature | Frequency-Domain Feature | ||
|---|---|---|---|
| where x(n) is a signal series for n = 1 − N, and N is the number of data points. | where s(k) is a signal series for k = 1 − K, and K is the number of spectrum lines; fk is the frequency value of the kth spectrum line. | ||
| Positive Prediction | Negative Prediction | |
|---|---|---|
| Positive class | TPi | FNi |
| Negative class | FPi | TNi |
| Imbalance Forms | Name | Number of Samples | Imbalance Rate | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Label 1 | Label 2 | Label 3 | Label 4 | Label 5 | Label 6 | Label 7 | Label 8 | |||
| linear | line-1 | 1500 | 465 | 258 | 50 | 672 | 879 | 1293 | 1086 | 30 |
| line-2 | 1000 | 864 | 592 | 50 | 728 | 321 | 185 | 457 | 20 | |
| line-3 | 750 | 550 | 450 | 50 | 150 | 350 | 650 | 250 | 15 | |
| step | stage-1 | 1500 | 50 | 1500 | 50 | 1500 | 1500 | 1500 | 50 | 30 |
| stage-2 | 750 | 50 | 750 | 50 | 750 | 750 | 750 | 50 | 15 | |
| stage-3 | 1500 | 50 | 1500 | 50 | 50 | 50 | 50 | 1500 | 30 | |
| stage-4 | 750 | 50 | 750 | 50 | 50 | 50 | 50 | 750 | 15 | |
| Data Set | Methods | SVM | RF | GBDT | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Mac-P | Mac-F1 | Acc | Mac-P | Mac-F1 | Acc | Mac-P | Mac-F1 | ||
| line-1 | None | 0.8675 | 0.8896 | 0.8484 | 0.7726 | 0.8122 | 0.7256 | 0.8126 | 0.8243 | 0.7842 |
| SMOTE | 0.9045 | 0.9148 | 0.8997 | 0.8555 | 0.8685 | 0.8471 | 0.8774 | 0.8849 | 0.8731 | |
| LR-SMOTE | 0.9065 | 0.9161 | 0.9012 | 0.8339 | 0.8528 | 0.8182 | 0.8662 | 0.8746 | 0.8591 | |
| MR-SMOTE | 0.9206 | 0.9233 | 0.9186 | 0.8678 | 0.8730 | 0.8643 | 0.8739 | 0.8773 | 0.8698 | |
| line-2 | None | 0.8733 | 0.8945 | 0.8607 | 0.7668 | 0.8075 | 0.7243 | 0.8209 | 0.8412 | 0.8011 |
| SMOTE | 0.8891 | 0.9062 | 0.8836 | 0.8548 | 0.8629 | 0.8501 | 0.8626 | 0.8713 | 0.8566 | |
| LR-SMOTE | 0.8923 | 0.9059 | 0.8865 | 0.8354 | 0.8497 | 0.8271 | 0.8588 | 0.8685 | 0.852 | |
| MR-SMOTE | 0.9139 | 0.9160 | 0.9131 | 0.8675 | 0.8702 | 0.8657 | 0.8733 | 0.8780 | 0.8698 | |
| line-3 | None | 0.8754 | 0.8890 | 0.8644 | 0.792 | 0.8261 | 0.7583 | 0.8344 | 0.8496 | 0.818 |
| SMOTE | 0.8995 | 0.9069 | 0.8954 | 0.8646 | 0.8726 | 0.8618 | 0.8748 | 0.8782 | 0.8716 | |
| LR-SMOTE | 0.8988 | 0.9058 | 0.8947 | 0.8464 | 0.8575 | 0.8415 | 0.8683 | 0.8730 | 0.8639 | |
| MR-SMOTE | 0.9175 | 0.9183 | 0.9168 | 0.8691 | 0.8720 | 0.8679 | 0.8803 | 0.8807 | 0.8784 | |
| Data Set | Methods | SVM | RF | GBDT | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Mac-P | Mac-F1 | Acc | Mac-P | Mac-F1 | Acc | Mac-P | Mac-F1 | ||
| Stage-1 | None | 0.7403 | 0.8207 | 0.7066 | 0.6144 | 0.7610 | 0.5051 | 0.6793 | 0.7553 | 0.6194 |
| SMOTE | 0.8418 | 0.8685 | 0.8332 | 0.7614 | 0.8166 | 0.7447 | 0.8250 | 0.8487 | 0.8182 | |
| LR-SMOTE | 0.8566 | 0.8789 | 0.8512 | 0.7103 | 0.7950 | 0.6729 | 0.8021 | 0.8403 | 0.7915 | |
| MR-SMOTE | 0.9039 | 0.9062 | 0.9023 | 0.844 | 0.8592 | 0.8408 | 0.8596 | 0.8706 | 0.8561 | |
| Stage-2 | None | 0.7746 | 0.8365 | 0.7528 | 0.6398 | 0.7694 | 0.5538 | 0.7193 | 0.7936 | 0.6838 |
| SMOTE | 0.8575 | 0.8760 | 0.8525 | 0.7790 | 0.8242 | 0.7682 | 0.8368 | 0.8551 | 0.8330 | |
| LR-SMOTE | 0.8649 | 0.8833 | 0.8602 | 0.7429 | 0.8073 | 0.7202 | 0.8205 | 0.8481 | 0.8142 | |
| MR-SMOTE | 0.9064 | 0.9078 | 0.9051 | 0.838 | 0.8529 | 0.8357 | 0.8621 | 0.8723 | 0.8601 | |
| Stage-3 | None | 0.6465 | 0.8034 | 0.6369 | 0.4534 | 0.7669 | 0.3607 | 0.5651 | 0.6999 | 0.5259 |
| SMOTE | 0.7828 | 0.8481 | 0.7847 | 0.7390 | 0.8181 | 0.7336 | 0.8048 | 0.8297 | 0.8022 | |
| LR-SMOTE | 0.8118 | 0.8546 | 0.8116 | 0.6766 | 0.8001 | 0.6654 | 0.7641 | 0.8044 | 0.7583 | |
| MR-SMOTE | 0.8771 | 0.8826 | 0.8759 | 0.8163 | 0.8366 | 0.8151 | 0.8351 | 0.8431 | 0.8327 | |
| Stage-4 | None | 0.6823 | 0.8124 | 0.6767 | 0.5186 | 0.7697 | 0.4671 | 0.6491 | 0.7391 | 0.6334 |
| SMOTE | 0.8221 | 0.8606 | 0.8223 | 0.767 | 0.8119 | 0.7634 | 0.8098 | 0.8315 | 0.8082 | |
| LR-SMOTE | 0.8440 | 0.8700 | 0.8434 | 0.7186 | 0.7957 | 0.7131 | 0.7871 | 0.8205 | 0.7848 | |
| MR-SMOTE | 0.8766 | 0.8829 | 0.8762 | 0.8135 | 0.8278 | 0.8119 | 0.8436 | 0.8513 | 0.8425 | |
| Data Set | Methods | SVM Presmall | RF Presmall | GBDT Presmall | Data Set | Methods | SVM Presmall | RF Presmall | GBDT Presmall |
|---|---|---|---|---|---|---|---|---|---|
| line-1 | None | 0.277 | 0.048 | 0.184 | stage-1 | None | 0.329 | 0.039 | 0.154 |
| SMOTE | 0.563 | 0.472 | 0.588 | SMOTE | 0.555 | 0.484 | 0.545 | ||
| LR-SMOTE | 0.553 | 0.338 | 0.508 | LR-SMOTE | 0.584 | 0.322 | 0.506 | ||
| MR-SMOTE | 0.703 | 0.625 | 0.603 | MR-SMOTE | 0.781 | 0.615 | 0.619 | ||
| line-2 | None | 0.358 | 0.052 | 0.261 | stage-2 | None | 0.403 | 0.062 | 0.259 |
| SMOTE | 0.427 | 0.554 | 0.519 | SMOTE | 0.616 | 0.506 | 0.637 | ||
| LR-SMOTE | 0.501 | 0.449 | 0.433 | LR-SMOTE | 0.606 | 0.36 | 0.555 | ||
| MR-SMOTE | 0.768 | 0.681 | 0.612 | MR-SMOTE | 0.791 | 0.695 | 0.690 | ||
| line-3 | None | 0.403 | 0.110 | 0.308 | stage-3 | None | 0.445 | 0.042 | 0.368 |
| SMOTE | 0.583 | 0.607 | 0.618 | SMOTE | 0.657 | 0.738 | 0.697 | ||
| LR-SMOTE | 0.579 | 0.525 | 0.565 | LR-SMOTE | 0.662 | 0.605 | 0.616 | ||
| MR-SMOTE | 0.791 | 0.701 | 0.681 | MR-SMOTE | 0.768 | 0.738 | 0.708 | ||
| stage-4 | None | 0.476 | 0.164 | 0.42 | |||||
| SMOTE | 0.732 | 0.745 | 0.697 | ||||||
| LR-SMOTE | 0.754 | 0.648 | 0.705 | ||||||
| MR-SMOTE | 0.783 | 0.760 | 0.778 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, F.; Zhang, S.; Yan, Y.; Cai, Z. An Oversampling Method of Unbalanced Data for Mechanical Fault Diagnosis Based on MeanRadius-SMOTE. Sensors 2022, 22, 5166. https://doi.org/10.3390/s22145166
Duan F, Zhang S, Yan Y, Cai Z. An Oversampling Method of Unbalanced Data for Mechanical Fault Diagnosis Based on MeanRadius-SMOTE. Sensors. 2022; 22(14):5166. https://doi.org/10.3390/s22145166
Chicago/Turabian StyleDuan, Feng, Shuai Zhang, Yinze Yan, and Zhiqiang Cai. 2022. "An Oversampling Method of Unbalanced Data for Mechanical Fault Diagnosis Based on MeanRadius-SMOTE" Sensors 22, no. 14: 5166. https://doi.org/10.3390/s22145166
APA StyleDuan, F., Zhang, S., Yan, Y., & Cai, Z. (2022). An Oversampling Method of Unbalanced Data for Mechanical Fault Diagnosis Based on MeanRadius-SMOTE. Sensors, 22(14), 5166. https://doi.org/10.3390/s22145166