
LightFD: Real-Time Fault Diagnosis with Edge Intelligence for Power Transformers



Abstract
:1. Introduction
- Our proposed system identifies six types of faults: large load start-up (Large load start-up is a special condition in transformer operation, and the frequent occurrence of this condition will make transformer faults increase. Therefore, we include large load start-up as a diagnostic object.), severe internal short circuit, internal breakdown short circuit, poorly grounded iron core, loose silicon steel or coil, and high voltage. When the system diagnoses a fault, it can generate early warnings about various states of the transformer in a timely manner.
- We design a multidimensional spatio-temporal feature extraction method to obtain and fuse the dynamic features of faulty sound signals from different angles in multiple dimensions.
- We design a lightweight network for low-end edge equipment to enable quick identification of transformer faults.
2. Related Work
2.1. Conventional Approaches
2.2. Deep Learning Approaches
3. System Overview
4. Proposed Fault Diagnosis Method
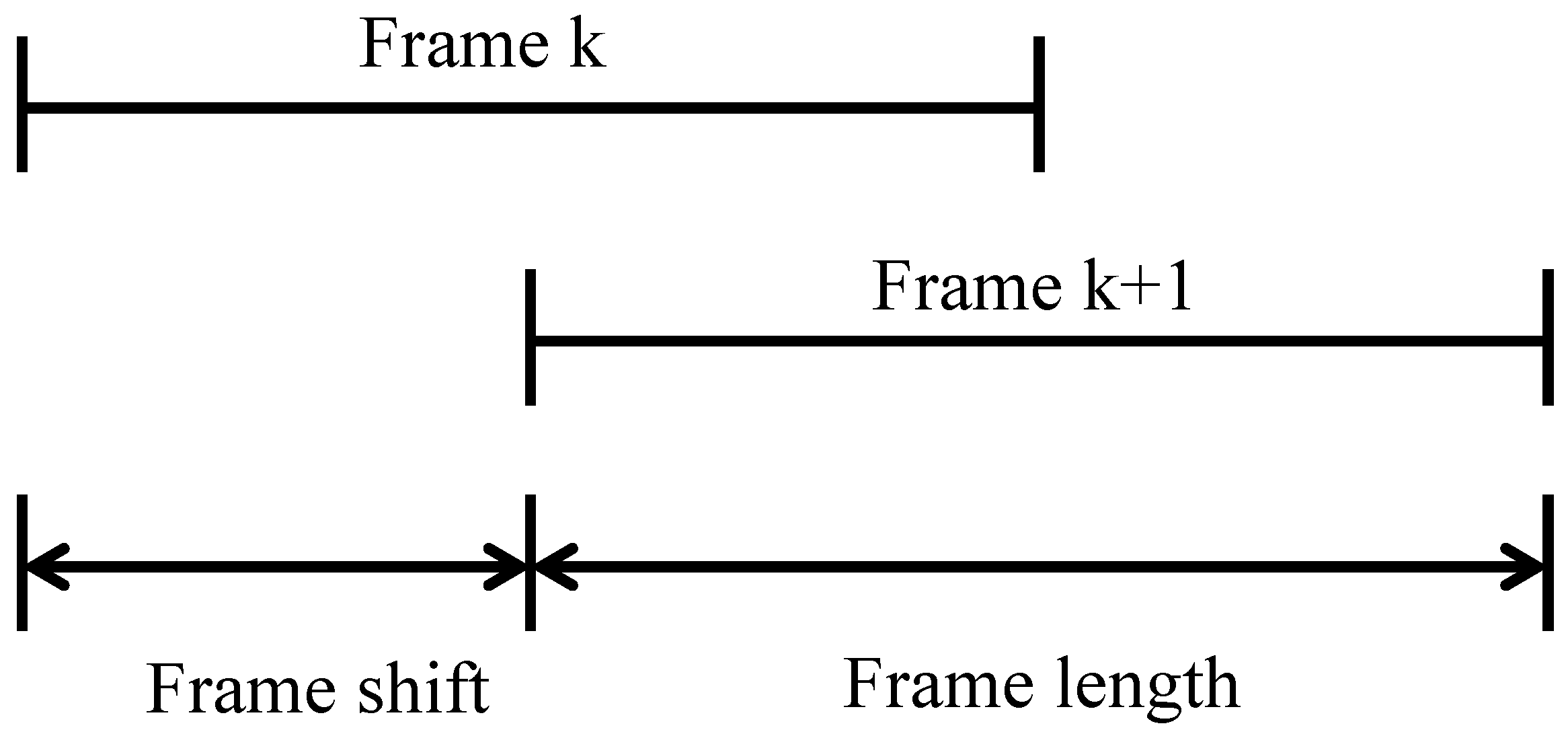
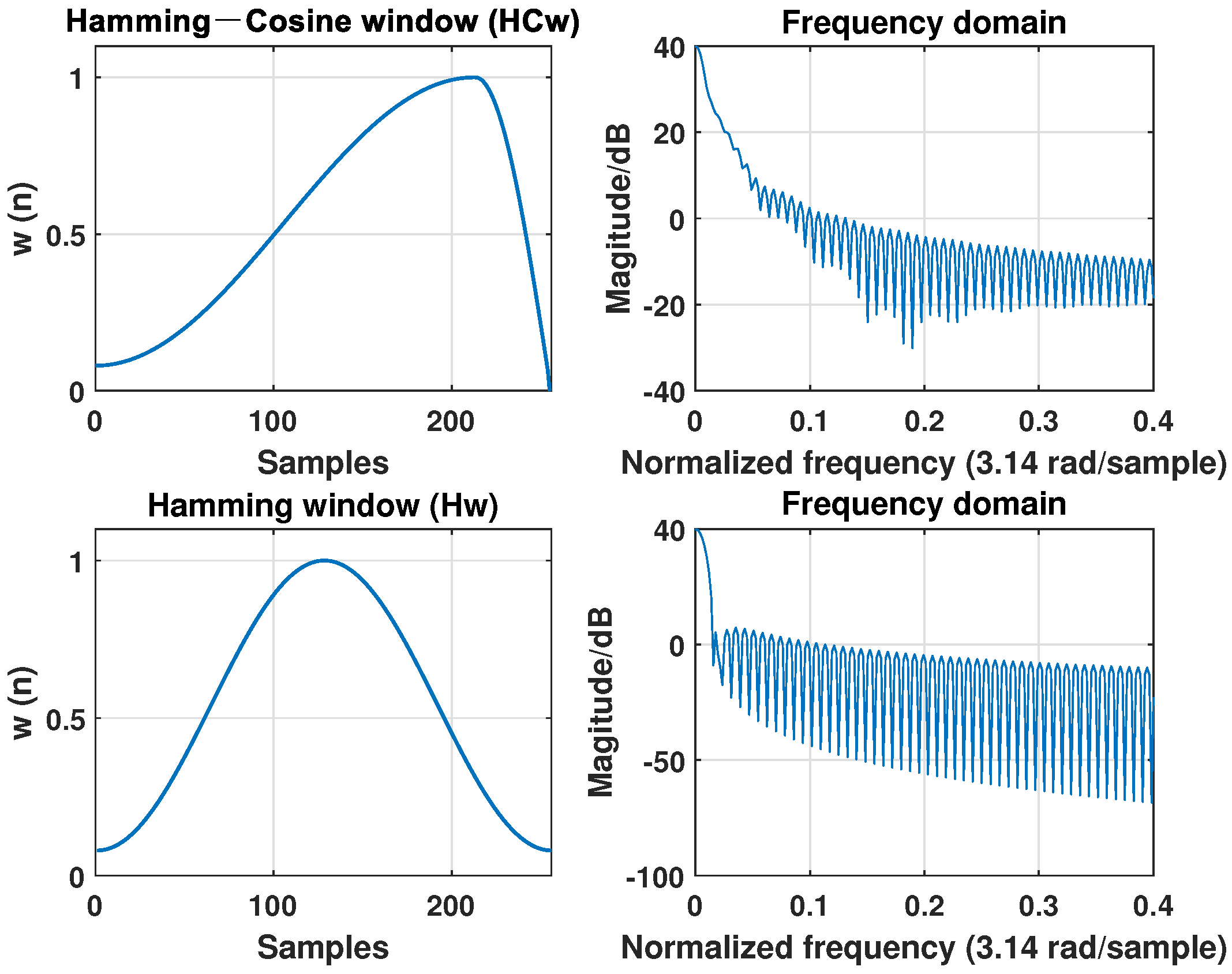
4.1. Pre-Processing
4.2. Spatio-Temporal Feature Extraction
4.2.1. Spatial Feature Extraction
4.2.2. Temporal Feature Extraction
4.3. A Classifier Using a Parallel Dual-Layer, Dual-Channel Lightweight Neural Network
4.3.1. Feature Extraction Layer
4.3.2. Feature Fusion Classification Layer
5. Experiments and Performance Evaluation
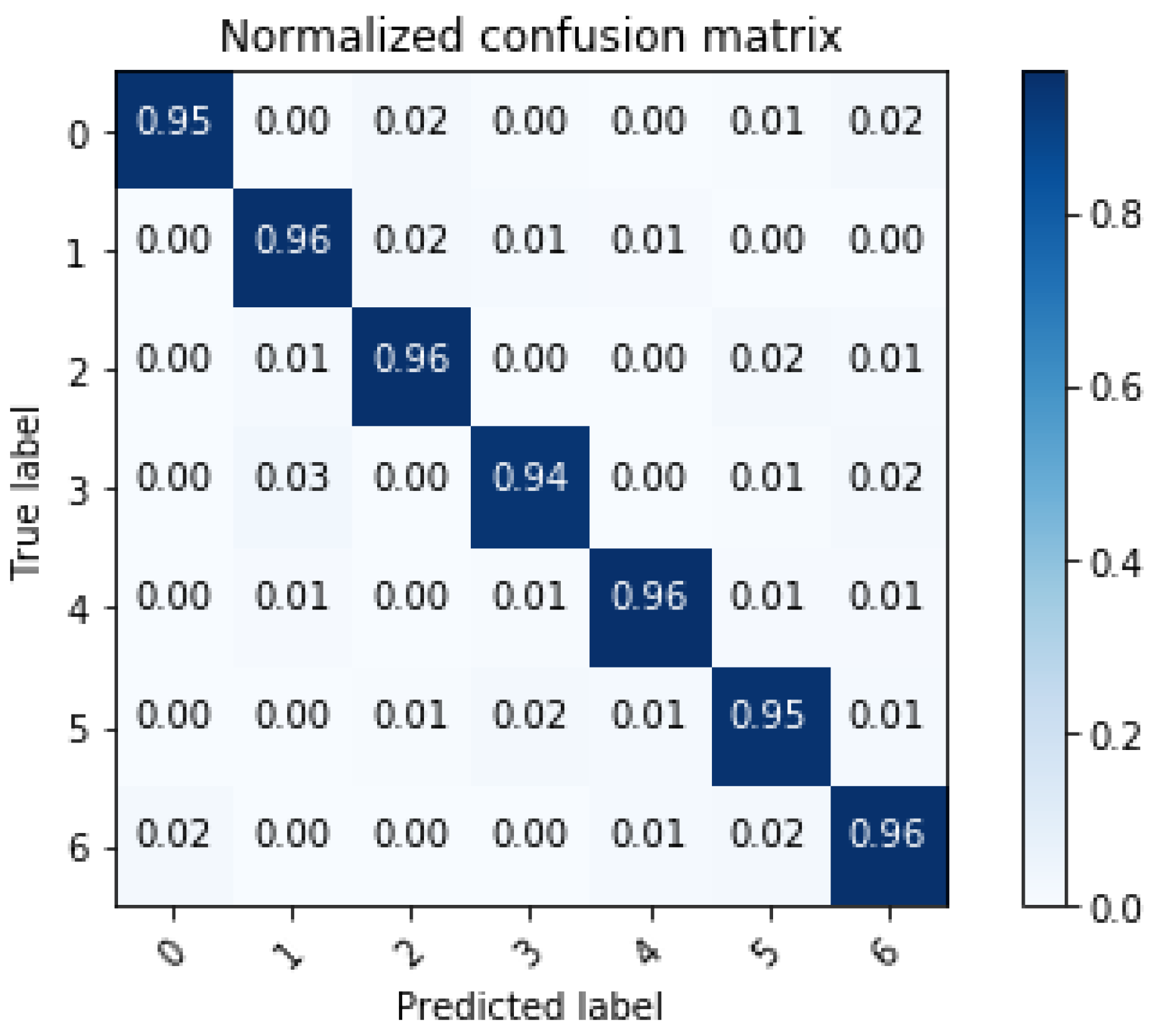
5.1. System Performance
5.2. Experimental on Feature Extraction for Sound Signals
5.3. Recognition Method and Computing Complexity Analysis
5.4. Experiments with Different Locations and Numbers of Sensors
6. Conclusions
- The extracted feature information reflects accurately the operating status of the transformer. An improved MFCC feature extraction method was proposed to characterize the dynamic features of acoustics. A multidimensional feature extraction method combining temporal and spatial features was proposed by combining the MFCC acoustic-based features with spectrograms.
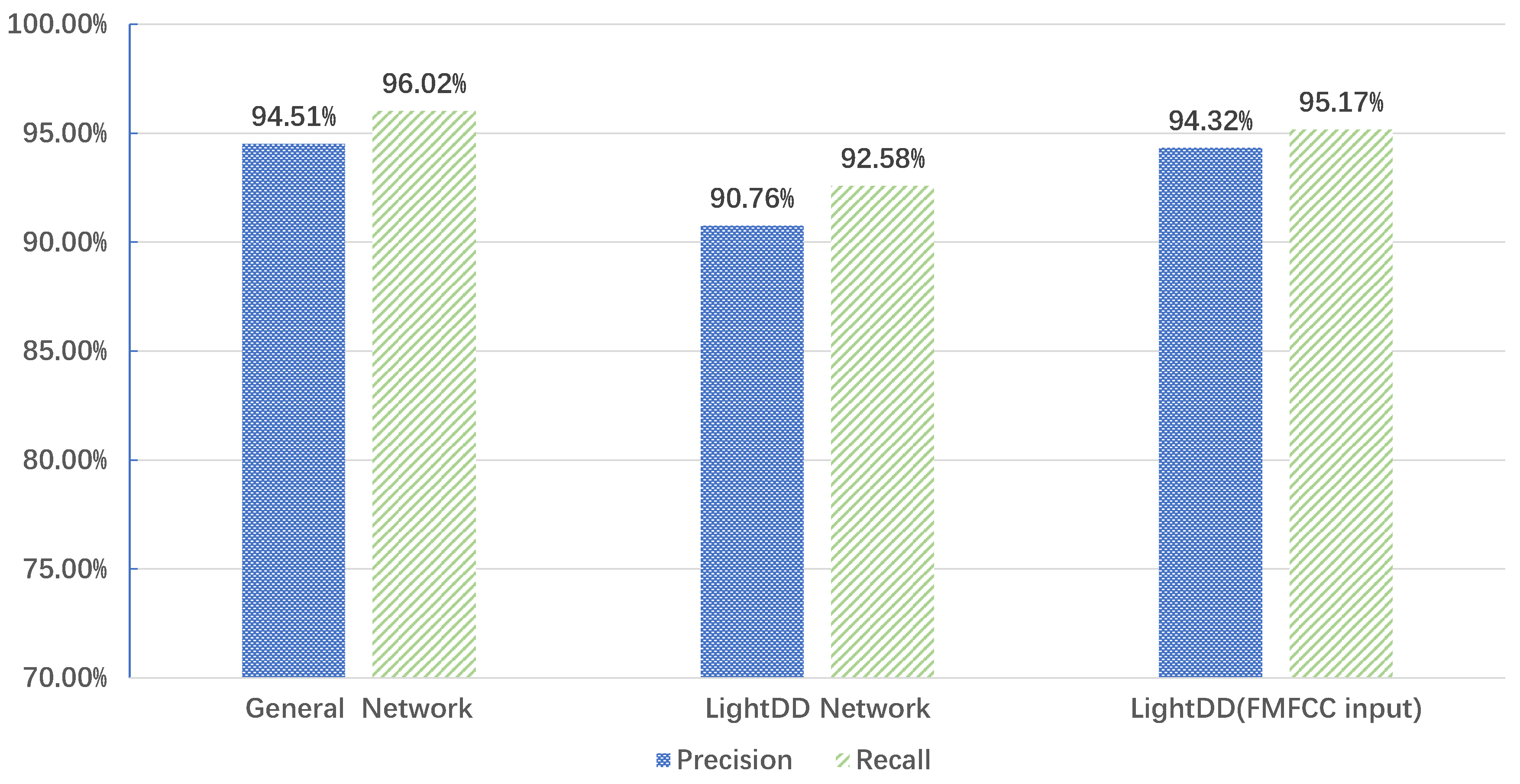
- The proposed dual-layer, dual-channel neural network achieved satisfactory recognition performance and reduced computational effort by 50% compared to a generic convolutional network. This makes it possible to perform fast and high-precision recognition on low-end devices.
- Compared with the conventional SVM method, the designed fault diagnosis method improved the Precision and Recall rates by 4% and 1.6%, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolution Neural Network |
| LightFD | Lightweight Fault Diagnosis |
| MFCC | Mel Frequency Cepstrum Coefficient |
| LPCC | Linear Predictive Cepstrum Coefficient |
| CFCC | Cochlear Filter Cepstral Coefficients |
| ANNs | Artificial Neural Networks |
| SVMs | Support Vector Machines |
| ΔMFCC | the first difference of MFCC |
| RMFCC | Relative-MFCC |
| FMFCC | Filtered-MFCC |
| LightDD | a parallel Dual-layer, Dual-channel Lightweight neural network |
| BiLSTM | Bidirectional Long Short-Term Memory |
References
- Rühl, C.; Appleby, P.; Fennema, J.; Naumov, A.; Schaffer, M. Economic development and the demand for energy: A historical perspective on the next 20 years. Energy Policy 2012, 50, 109–116. [Google Scholar] [CrossRef]
- Aziz, T.; Lin, Z.; Waseem, M.; Liu, S. Review on optimization methodologies in transmission network reconfiguration of power systems for grid resilience. Int. Trans. Electr. Energy Syst. 2021, 31, e12704. [Google Scholar] [CrossRef]
- Jürgensen, J.H.; Nordström, L.; Hilber, P. Estimation of individual failure rates for power system components based on risk functions. IEEE Trans. Power Deliv. 2019, 34, 1599–1607. [Google Scholar] [CrossRef] [Green Version]
- Cennamo, N.; De Maria, L.; D’Agostino, G.; Zeni, L.; Pesavento, M. Monitoring of low levels of furfural in power transformer oil with a sensor system based on a POF-MIP platform. Sensors 2015, 15, 8499–8511. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Duan, R.; Geng, C.; Qian, G.; Lu, Y. Research of vibration characteristics of power transformer winding based on magnetic-mechanical coupling field theory. Proc. CSEE 2016, 36, 2555–2562. [Google Scholar]
- Zhang, L.; Wang, G.; Dong, P.; Zou, L.; Zhao, T. Study on the Vibration of Grain-oriented Transformer Core Based on the Magnetos-trictive Intrinsic Characteristics. Proc. CSEE 2016, 36, 3990–4000. [Google Scholar]
- Boles, A.; Rad, P. Voice biometrics: Deep learning-based voiceprint authentication system. In Proceedings of the 12th System of Systems Engineering Conference (SoSE), Waikoloa, HI, USA, 18–21 June 2017; pp. 1–6. [Google Scholar]
- Tresadern, P.; McCool, C.; Poh, N.; Matejka, P.; Hadid, A.; Levy, C.; Cootes, T.; Marcel, S. Mobile biometrics (mobio): Joint face and voice verification for a mobile platform. IEEE Pervasive Comput. 2013, 12, 79–87. [Google Scholar] [CrossRef]
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw. 2020, 130, 22–32. [Google Scholar] [CrossRef]
- Campos Souza, P.V.; Lughofer, E. Identification of heart sounds with an interpretable evolving fuzzy neural network. Sensors 2020, 20, 6477. [Google Scholar] [CrossRef]
- Kulkarni, A.; Kalburgi, D.; Ghuli, P. Design of Predictive Model for Healthcare Assistance Using Voice Recognition. In Proceedings of the 2017 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bengaluru, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- He, M.; He, D. Deep learning based approach for bearing fault diagnosis. IEEE Trans. Ind. Appl. 2017, 53, 3057–3065. [Google Scholar] [CrossRef]
- Glowacz, A. Acoustic fault analysis of three commutator motors. Mech. Syst. Signal Process. 2019, 133, 106226. [Google Scholar] [CrossRef]
- Glowacz, A. Acoustic based fault diagnosis of three-phase induction motor. Appl. Acoust. 2018, 137, 82–89. [Google Scholar] [CrossRef]
- Paseddula, C.; Gangashetty, S.V. Late fusion framework for Acoustic Scene Classification using LPCC, SCMC, and log-Mel band energies with Deep Neural Networks. Appl. Acoust. 2021, 172, 107568. [Google Scholar] [CrossRef]
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502. [Google Scholar]
- Wan, X.; Song, H.; Luo, L.; Li, Z.; Sheng, G.; Jiang, X. Pattern recognition of partial discharge image based on one-dimensional convolutional neural network. In Proceedings of the Condition Monitoring and Diagnosis (CMD), Perth, WA, Australia, 23–26 September 2018; pp. 1–4. [Google Scholar]
- Lawson, A.; Vabishchevich, P.; Huggins, M.; Ardis, P.; Battles, B.; Stauffer, A. Survey and evaluation of acoustic features for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5444–5447. [Google Scholar]
- Singh, J.; Singh, S. Transformer failure analysis: Reasons and methods. Int. J. Eng. Res. Technol. 2016, 4, 1–5. [Google Scholar]
- Han, G.; He, Y.; Jiang, J.; Wang, N.; Guizani, M.; Ansere, J.A. A synergetic trust model based on SVM in underwater acoustic sensor networks. IEEE Trans. Veh. Technol. 2019, 68, 11239–11247. [Google Scholar] [CrossRef]
- Gupta, R.; Alam, M.A.; Agarwal, P. Modified support vector machine for detecting stress level using EEG signals. Comput. Intell. Neurosci. 2020, 2020, 8860841. [Google Scholar] [CrossRef]
- Faiz, J.; Soleimani, M. Assessment of computational intelligence and conventional dissolved gas analysis methods for transformer fault diagnosis. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 1798–1806. [Google Scholar] [CrossRef]
- Zhou, S.; Lei, X.; Qiao, B.; Hou, H. Research on insulator fault diagnosis and remote monitoring system based on infrared images. Procedia Comput. Sci. 2017, 109, 1194–1199. [Google Scholar]
- Mohammadi, F.; Nazri, G.A.; Saif, M. A fast fault detection and identification approach in power distribution systems. In Proceedings of the 2019 International Conference on Power Generation Systems and Renewable Energy Technologies (PGSRET), Istanbul, Turkey, 26–27 August 2019; pp. 1–4. [Google Scholar]
- Sykora, M.; Schlosser, M. Noise measurement of power transformer. In Proceedings of the Conference on Diagnostics in Electrical Engineering (Diagnostika), Pilsen, Czech Republic, 6–8 September 2016; pp. 1–4. [Google Scholar]
- Kendig, R.P.; Wright, S. Validation of acoustic intensity measurements for power transformers. IEEE Trans. Power Deliv. 1991, 6, 1524–1530. [Google Scholar] [CrossRef]
- Yan, B.; Qian, G.; Wang, F.; Chen, S. Noise recognition of power transformers based on improved MFCC and VQ. In Proceedings of the 2016 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Dallas, TX, USA, 3–5 May 2016; pp. 1–5. [Google Scholar]
- Hu, W.; Qian, Y.; Soong, F.K.; Wang, Y. Improved mispronunciation detection with deep neural network trained acoustic models and transfer learning based logistic regression classifiers. Speech Commun. 2015, 67, 154–166. [Google Scholar] [CrossRef]
- Xia, X.; Togneri, R.; Sohel, F.; Huang, D. Random forest classification based acoustic event detection utilizing contextual-information and bottleneck features. Pattern Recognit. 2018, 81, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Ye, G.Y.; Xu, K.J.; Wu, W.K. Multi-variable classification model for valve internal leakage based on acoustic emission time–frequency domain characteristics and random forest. Rev. Sci. Instrum. 2021, 92, 025108. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Xie, L.; Li, Y.; Gao, B. Acoustical damage detection of wind turbine yaw system using Bayesian network. Renew. Energy 2020, 160, 1364–1372. [Google Scholar] [CrossRef]
- Grandhi, R.T.; Krishna Prakash, N. Machine-Learning Based Fault Diagnosis of Electrical Motors Using Acoustic Signals. In Data Intelligence and Cognitive Informatics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 663–671. [Google Scholar]
- Boujelben, O.; Bahoura, M. Efficient FPGA-based architecture of an automatic wheeze detector using a combination of MFCC and SVM algorithms. J. Syst. Archit. 2018, 88, 54–64. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.W. A cost-efficient MFCC-based fault detection and isolation technology for electromagnetic pumps. Electronics 2021, 10, 439. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Gastli, A.; Ben-Brahim, L.; Al-Emadi, N.; Gabbouj, M. Real-time fault detection and identification for MMC using 1-D convolutional neural networks. IEEE Trans. Ind. Electron. 2018, 66, 8760–8771. [Google Scholar] [CrossRef]
- Park, D.; Kim, S.; An, Y.; Jung, J.Y. LiReD: A light-weight real-time fault detection system for edge computing using LSTM recurrent neural networks. Sensors 2018, 18, 2110. [Google Scholar] [CrossRef] [Green Version]
- Cza, B.; Yh, B.; Bd, B.; Ly, C.; Bing, L.C.; Sj, A. Transformer fault diagnosis method using IoT based monitoring system and ensemble machine learning - ScienceDirect. Future Gener. Comput. Syst. 2020, 108, 533–545. [Google Scholar]
- Do, T.D.; Tuyet-Doan, V.N.; Cho, Y.S.; Sun, J.H.; Kim, Y.H. Convolutional-neural-network-based partial discharge diagnosis for power transformer using UHF sensor. IEEE Access 2020, 8, 207377–207388. [Google Scholar] [CrossRef]
- Dang, X.; Wang, F.; Ma, W. Fault Diagnosis of Power Transformer by Acoustic Signals with Deep Learning. In Proceedings of the 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE), Beijing, China, 6–10 September 2020; pp. 1–4. [Google Scholar]
- Tian, Z.; Zuo, M.J. Health condition prediction of gears using a recurrent neural network approach. IEEE Trans. Reliab. 2010, 59, 700–705. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Lindemann, B.; Maschler, B.; Sahlab, N.; Weyrich, M. A survey on anomaly detection for technical systems using LSTM networks. Comput. Ind. 2021, 131, 103498. [Google Scholar] [CrossRef]
- Breitenbach, A. Against spectral leakage. Measurement 1999, 25, 135–142. [Google Scholar] [CrossRef]
- Shan, Y.; Zhu, Q. Speaker identification under the changed sound environment. In Proceedings of the 2014 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2014; pp. 362–366. [Google Scholar]
- Góngora, L.A.; Amaya, D.; Ramos, O.L. Pre-emphasis, Windowing and Spectral Estimation of Silent Speech Signals Using Embedded Systems. Int. J. Multimed. Ubiquitous Eng. 2016, 11, 349–360. [Google Scholar] [CrossRef]
- Hammond, J.; White, P. The analysis of non-stationary signals using time-frequency methods. J. Sound Vib. 1996, 190, 419–447. [Google Scholar] [CrossRef]
- Astuti, W.; Sediono, W.; Aibinu, A.; Akmeliawati, R.; Salami, M.J.E. Adaptive Short Time Fourier Transform (STFT) Analysis of seismic electric signal (SES): A comparison of Hamming and rectangular window. In Proceedings of the IEEE Symposium on Industrial Electronics and Applications, Bandung, Indonesia, 23–26 September 2012; pp. 372–377. [Google Scholar]
- Li, Y.F.; Chen, K.F. Eliminating the picket fence effect of the fast Fourier transform. Comput. Phys. Commun. 2008, 178, 486–491. [Google Scholar] [CrossRef]
- Paliwal, K.K.; Alsteris, L.D. Usefulness of Phase Spectrum in Human Speech Perception. Eurospeech Geneva 2003, 3, 2117–2120. [Google Scholar]
- Kotnik, B.; Vlaj, D.; Kacic, Z.; Horvat, B. Robust MFCC feature extraction algorithm using efficient additive and convolutional noise reduction procedures. Proc. ICSLP 2002, 2, 445–448. [Google Scholar]
- Chazan, D.; Hoory, R.; Cohen, G.; Zibulski, M. Speech reconstruction from mel frequency cepstral coefficients and pitch frequency. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 3, pp. 1299–1302. [Google Scholar]
- Martin, R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans. Speech Audio Process. 2001, 9, 504–512. [Google Scholar] [CrossRef] [Green Version]
- Hossan, M.A.; Memon, S.; Gregory, M.A. A novel approach for MFCC feature extraction. In Proceedings of the 2010 4th International Conference on Signal Processing and Communication System, Gold Coast, QLD, Australia, 13–15 December 2010; pp. 1–5. [Google Scholar]
- Mao, K. RBF neural network center selection based on Fisher ratio class separability measure. IEEE Trans. Neural Netw. 2002, 13, 1211–1217. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Guan, C.; Zhang, H.; Ang, K.K. A unified Fisher’s ratio learning method for spatial filter optimization. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2727–2737. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Yun, W.; Leonardo, N.; Florian, M. Audio-based multimedia event detection using deep recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2742–2746. [Google Scholar]
- Parascandolo, G.; Huttunen, H.; Virtanen, T. Recurrent neural networks for polyphonic sound event detection in real life recordings. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6440–6444. [Google Scholar]
- Jolles, J.W. Broad-scale applications of the Raspberry Pi: A review and guide for biologists. Methods Ecol. Evol. 2021, 12, 1562–1579. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
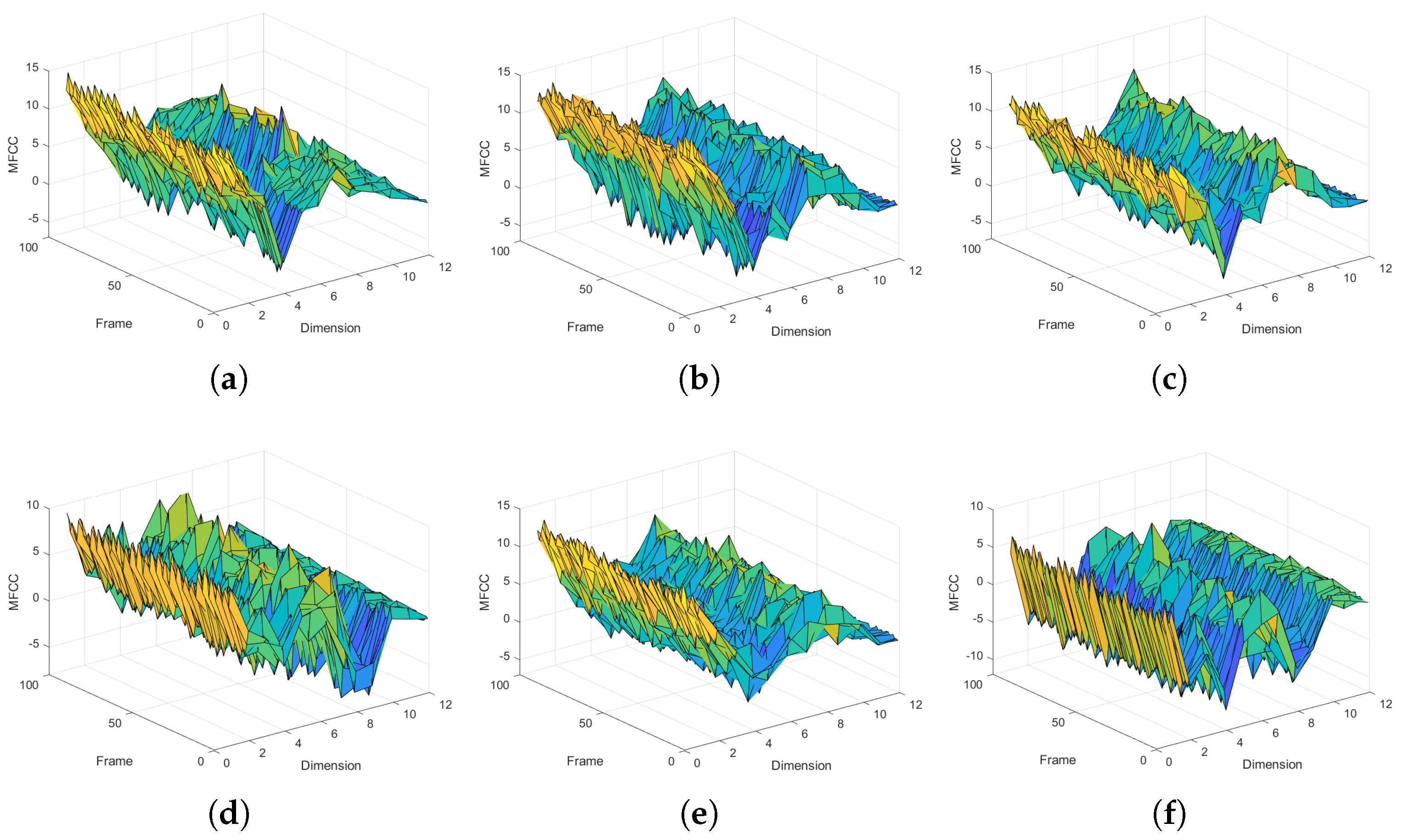{kind=link}
{kind=link}
| Anomaly | Fault Description and Causes | Number of Collected Signals | Serial Number |
|---|---|---|---|
| “Wawa” | Large load start-up or internal short circuit | 1360 | 1 |
| Sound of water boiling | Severe internal short circuit | 1280 | 2 |
| Crackle | Internal breakdown short circuit | 1314 | 3 |
| “Chichi” | Poorly grounded iron core | 1250 | 4 |
| “Jiji” | Loose silicon steel or coil | 1370 | 5 |
| “Wengweng” | High voltage | 1154 | 6 |
| The Fault Serial Number | SVM | LightDD | ||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| 1 | 90.12% | 92.74% | 94.95% | 95.57% |
| 2 | 87.41% | 88.02% | 94.95% | 95.57% |
| 3 | 92.47% | 96.54% | 95.76% | 94.2% |
| 4 | 93.30% | 94.57% | 96.99% | 96.23% |
| 5 | 91.85% | 94.97% | 94.42% | 94.79% |
| 6 | 87.77% | 93.68% | 90.78% | 95.63% |
| The Location of Sensors | Internal Breakdown Short Circuit | Loose Silicon Steel or Coil | ||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| A | 95.65% | 94.57% | 94.13% | 94.67% |
| B | 95.87% | 94.38% | 94.38% | 94.78% |
| C | 95.78% | 94.16% | 94.39% | 94.62% |
| A + B + C | 95.7% | 94.47% | 94.41% | 94.79% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Yang, K.; Liu, M.; Xing, T.; Wu, C. LightFD: Real-Time Fault Diagnosis with Edge Intelligence for Power Transformers. Sensors 2022, 22, 5296. https://doi.org/10.3390/s22145296
Fu X, Yang K, Liu M, Xing T, Wu C. LightFD: Real-Time Fault Diagnosis with Edge Intelligence for Power Transformers. Sensors. 2022; 22(14):5296. https://doi.org/10.3390/s22145296
Chicago/Turabian StyleFu, Xinhua, Kejun Yang, Min Liu, Tianzhang Xing, and Chase Wu. 2022. "LightFD: Real-Time Fault Diagnosis with Edge Intelligence for Power Transformers" Sensors 22, no. 14: 5296. https://doi.org/10.3390/s22145296
APA StyleFu, X., Yang, K., Liu, M., Xing, T., & Wu, C. (2022). LightFD: Real-Time Fault Diagnosis with Edge Intelligence for Power Transformers. Sensors, 22(14), 5296. https://doi.org/10.3390/s22145296