
LTC-Mapping, Enhancing Long-Term Consistency of Object-Oriented Semantic Maps in Robotics

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Work
2.1. Semantic Mapping
2.2. Object Detection and Semantic Segmentation
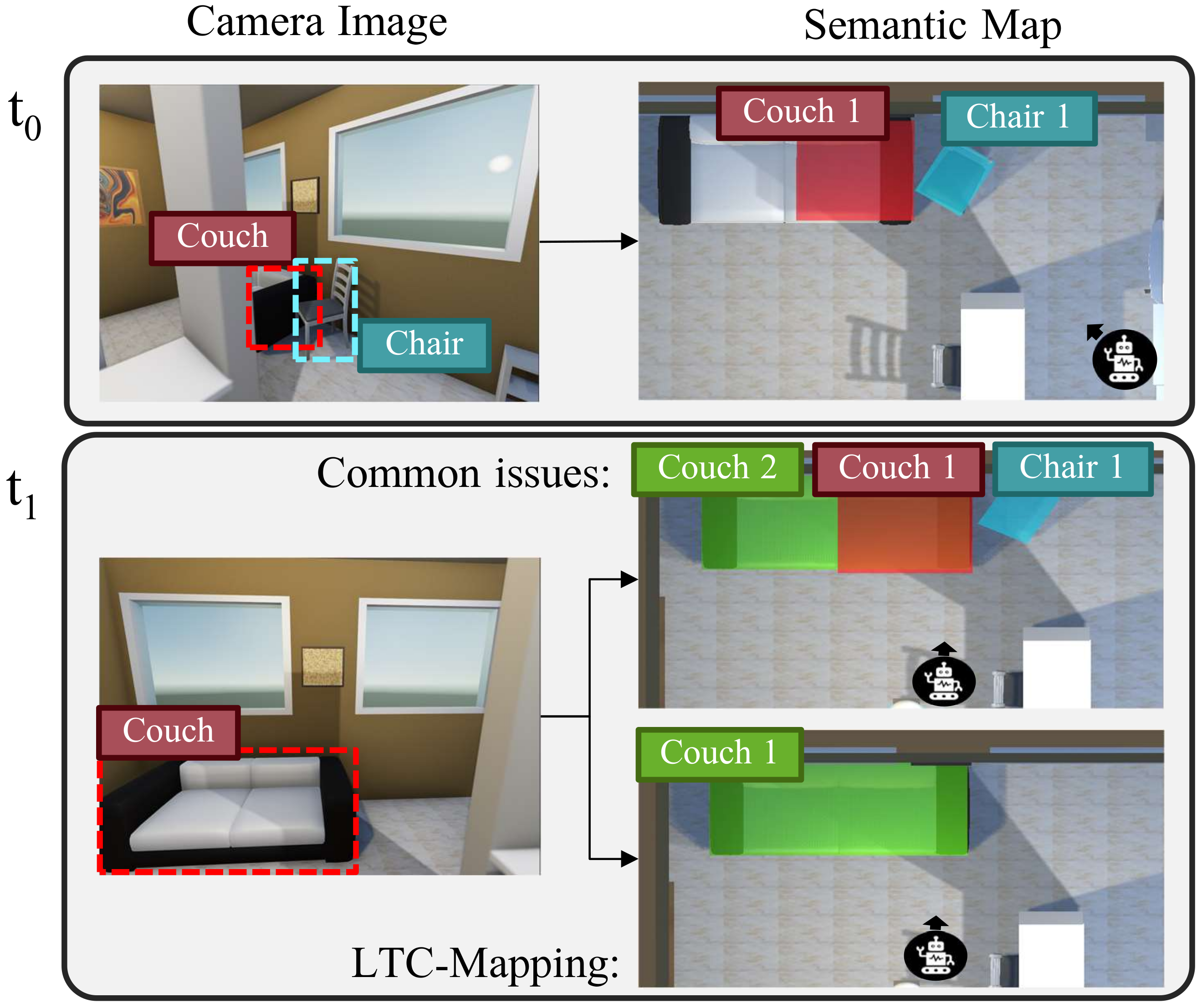
3. LTC-Mapping
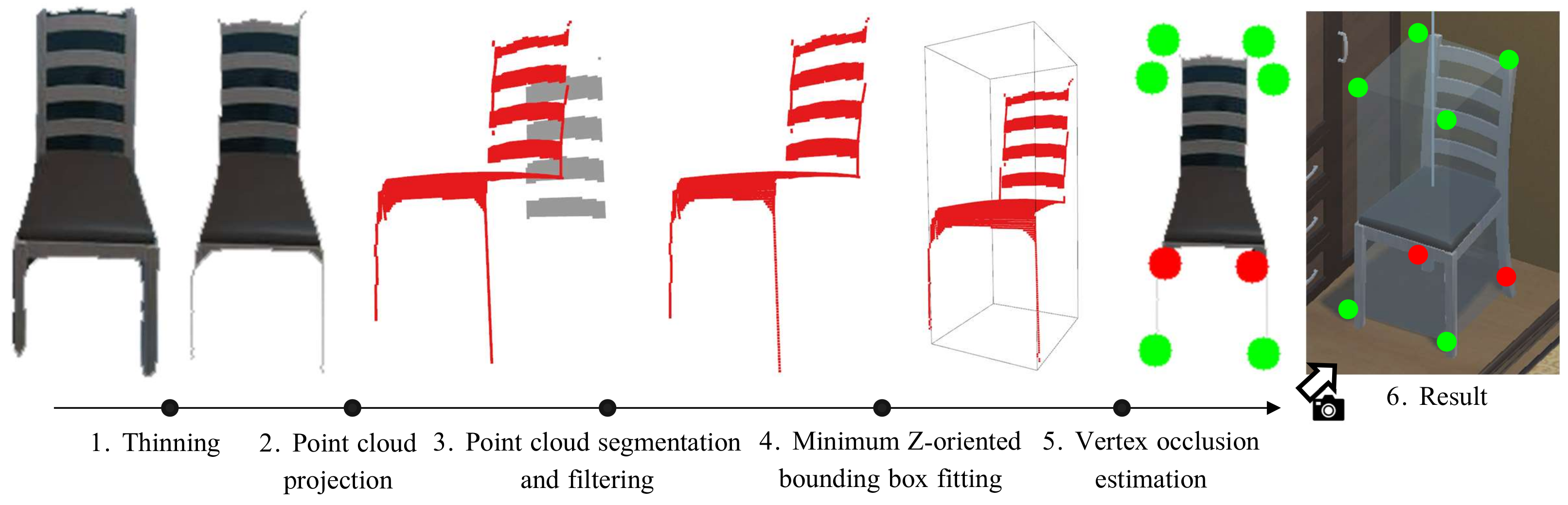
3.1. Object Detection and Modeling
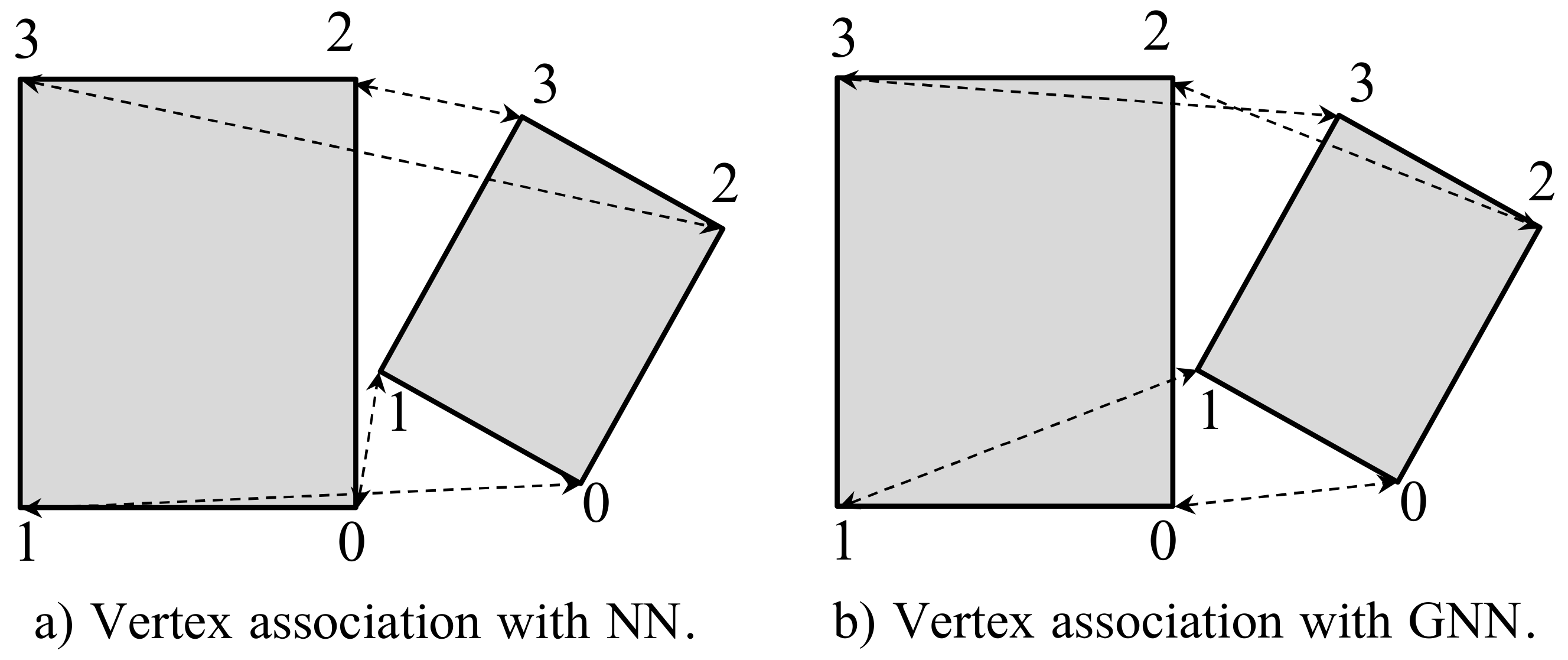
3.2. Data Association
- Three or more pairs of vertices are visible. A pair of vertices is considered as visible as long as each vertex is Visible in their respective bounding box. Based on this knowledge, we can assume that at least two dimensions of their size are known and are not expected to be highly modified with new detections. Therefore, the distance between these vertices is more informative than the distance between non-visible vertices, which may not represent a real vertex of the object. Hence, under this scenario, the metric is particularized just to the average distance between pairs of non-occluded vertices.
- Less than three pairs of vertices are visible. In this case, given the lack of reliable information, we compute the average distance between all pairs of vertices.
3.3. Map Integration
- Definedand Defined. In this scenario, both bounding boxes should cover the entire object and are expected to be similar. Hence, the resulting bounding box comes from separately averaging both size and orientation. The resulting bounding box remains as Defined.
- notDefinedand Defined. In this case, the new observation is partial (e.g., due to occlusions), so the obtained bounding box does not completely represent the real object. Therefore, we do not modify the bounding box of the already instantiated object.
- Definedand notDefined. Similarly to the above case, the bounding box of the new detection being the most complete one, we replace the instantiated bounding box with the new one , as it should represent the real object more accurately. Hence, the bounding box in the map is now set as Defined.
- notDefinedand notDefined. Under this scenario, both bounding boxes belong to partial observations. Hence, in this case, we compute the minimum bounding box that encloses both and . However, this operation is highly sensitive to the orientation of both bounding boxes and, consequently, minor errors in orientation affect the bounding box size highly. This leads to the fact that, after integrating multiple partial observations, the size tends to become larger and larger. To overcome this problem, we apply to the resulting bounding box a slight 3D morphological erosion [49], which prevents an endless expansion until a Defined detection is received.
3.4. Map Maintenance
- : a bounding box with no size located at the position where the instantiated object was expected to be found.
- : the confidence value of the class Other is set with a value obtained from a characterization of the object detector response (i.e., true positives, false negatives, etc.) obtained from a previous analysis. The remaining classes are set uniformly as:where r is the number of object classes detectable by the neural network.
- : an empty visibility vector.
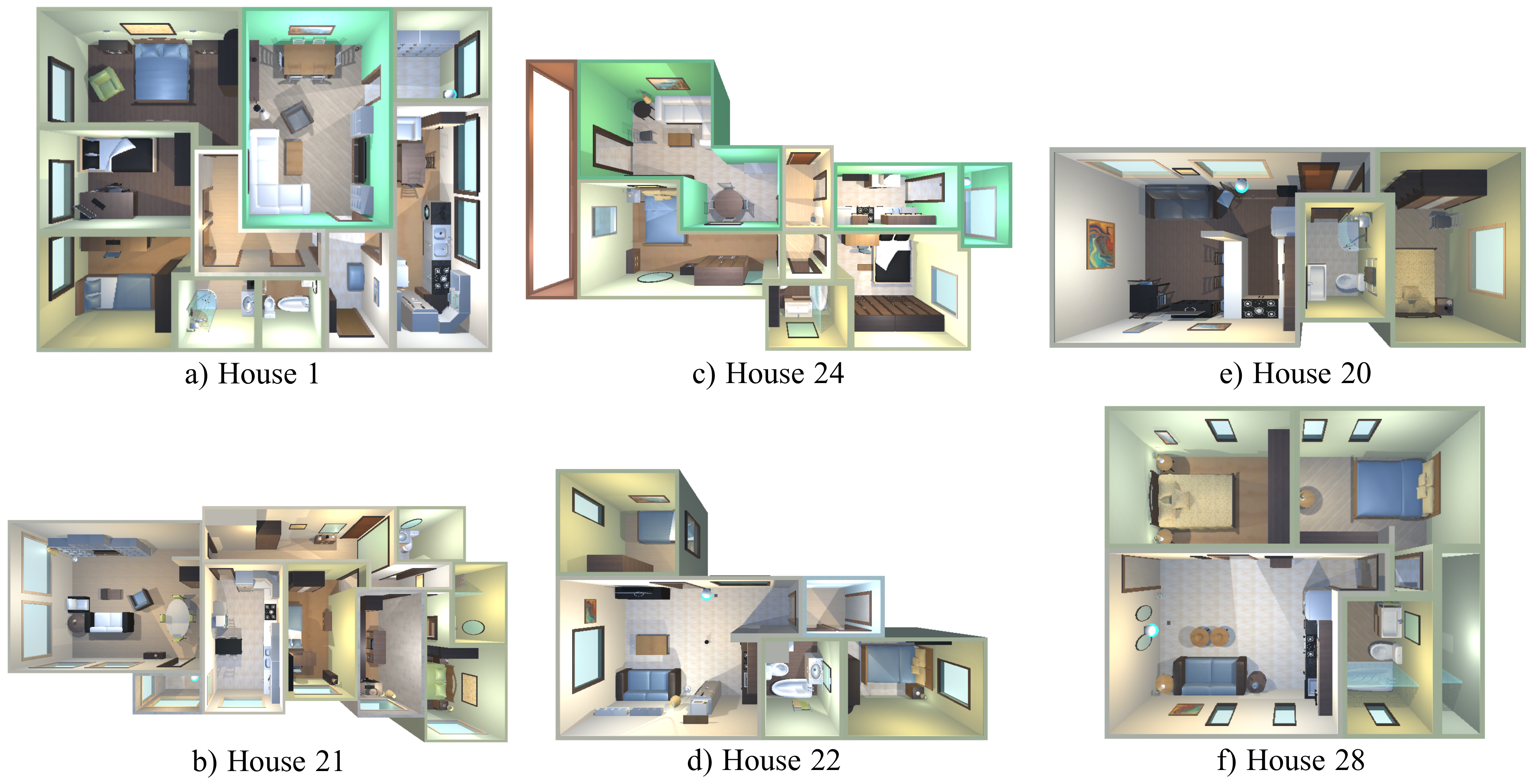
4. Experimental Setup
4.1. Robot@VirtualHome Ecosystem
4.2. Implementation Details
5. Experimental Results
5.1. Quantitative Results
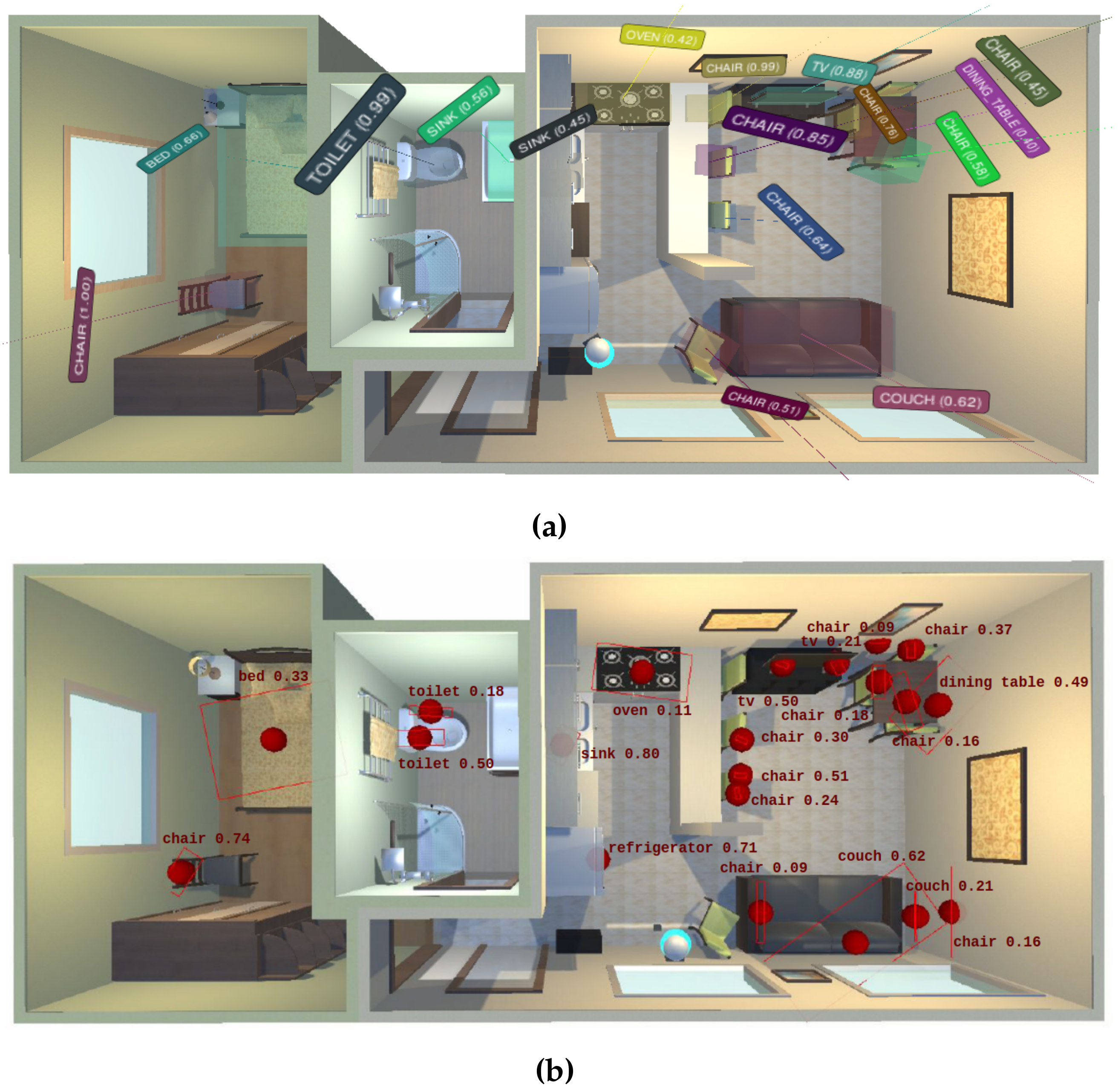
5.2. Qualitative Results
5.3. Analysis of Computational Time
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chatila, R.; Laumond, J. Position referencing and consistent world modeling for mobile robots. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 138–145. [Google Scholar]
- Kuipers, B. Modeling Spatial Knowledge. Cogn. Sci. 1978, 2, 129–153. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.R.; Galindo, C.; González-Jiménez, J. Building Multiversal Semantic Maps for Mobile Robot Operation. Knowl.-Based Syst. 2017, 119, 257–272. [Google Scholar] [CrossRef]
- Nüchter, A.; Hertzberg, J. Towards Semantic Maps for Mobile Robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Galindo, C.; Fernandez-Madrigal, J.; Gonzalez, J.; Saffiotti, A. Robot Task Planning Using Semantic Maps. Robot. Auton. Syst. 2008, 56, 955–966. [Google Scholar] [CrossRef] [Green Version]
- Pronobis, A.; Jensfelt, P. Large-scale semantic mapping and reasoning with heterogeneous modalities. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3515–3522. [Google Scholar]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5729–5736. [Google Scholar]
- Mutlu, B.; Roy, N.; Šabanović, S. Cognitive human–robot interaction. In Springer Handbook of Robotics; Springer: Cham, Switzerland, 2016; pp. 1907–1934. [Google Scholar]
- Matez-Bandera, J.L.; Monroy, J.; Gonzalez-Jimenez, J. Efficient semantic place categorization by a robot through active line-of-sight selection. Knowl.-Based Syst. 2022, 240, 108022. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5079–5085. [Google Scholar]
- Kaszuba, S.; Sabbella, S.R.; Suriani, V.; Riccio, F.; Nardi, D. RoSmEEry: Robotic Simulated Environment for Evaluation and Benchmarking of Semantic Mapping Algorithms. arXiv 2021, arXiv:2105.07938. [Google Scholar]
- Dengler, N.; Zaenker, T.; Verdoja, F.; Bennewitz, M. Online Object-Oriented Semantic Mapping and Map Updating. In Proceedings of the 2021 European Conference on Mobile Robots (ECMR), Bonn, Germany, 31 August–3 September 2020; pp. 1–7. [Google Scholar]
- Fernandez-Chaves, D.; Ruiz-Sarmiento, J.; Jaenal, A.; Petkov, N.; Gonzalez-Jimenez, J. Robot@VirtualHome, an ecosystem of virtual environments and tools for realistic indoor robotic simulation. Expert Syst. Appl. 2021; under review. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Garg, S.; Sünderhauf, N.; Dayoub, F.; Morrison, D.; Cosgun, A.; Carneiro, G.; Wu, Q.; Chin, T.J.; Reid, I.; Gould, S.; et al. Semantics for robotic mapping, perception and interaction: A survey. Found. Trends Robot. 2020, 8, 1–224. [Google Scholar] [CrossRef]
- Han, X.; Li, S.; Wang, X.; Zhou, W. Semantic Mapping for Mobile Robots in Indoor Scenes: A Survey. Information 2021, 12, 92. [Google Scholar] [CrossRef]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernandez-Madrigal, J.A.; Gonzalez, J. Multi-hierarchical semantic maps for mobile robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 2278–2283. [Google Scholar]
- Regier, P.; Milioto, A.; Stachniss, C.; Bennewitz, M. Classifying obstacles and exploiting class information for humanoid navigation through cluttered environments. Int. J. Hum. Robot. 2020, 17, 2050013. [Google Scholar] [CrossRef]
- Tateno, K.; Tombari, F.; Navab, N. Real-time and scalable incremental segmentation on dense slam. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4465–4472. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. Semanticfusion: Dense 3d semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Xiang, Y.; Fox, D. Da-rnn: Semantic mapping with data associated recurrent neural networks. arXiv 2017, arXiv:1703.03098. [Google Scholar]
- Li, J.; Liu, Y.; Wang, J.; Yan, M.; Yao, Y. 3D semantic mapping based on convolutional neural networks. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9303–9308. [Google Scholar]
- Sun, L.; Yan, Z.; Zaganidis, A.; Zhao, C.; Duckett, T. Recurrent-octomap: Learning state-based map refinement for long-term semantic mapping with 3-d-lidar data. IEEE Robot. Autom. Lett. 2018, 3, 3749–3756. [Google Scholar] [CrossRef] [Green Version]
- Narita, G.; Seno, T.; Ishikawa, T.; Kaji, Y. Panopticfusion: Online volumetric semantic mapping at the level of stuff and things. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4205–4212. [Google Scholar]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric instance-aware semantic mapping and 3D object discovery. IEEE Robot. Autom. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef] [Green Version]
- Nakajima, Y.; Saito, H. Efficient object-oriented semantic mapping with object detector. IEEE Access 2018, 7, 3206–3213. [Google Scholar] [CrossRef]
- Deeken, H.; Wiemann, T.; Hertzberg, J. Grounding semantic maps in spatial databases. Robot. Auton. Syst. 2018, 105, 146–165. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Sun, J.; Liu, X.; Zhao, L.; Seah, H.S.; Quah, C.K.; Tandianus, B. Multi-view fusion-based 3D object detection for robot indoor scene perception. Sensors 2019, 19, 4092. [Google Scholar] [CrossRef] [Green Version]
- Pontil, M.; Verri, A. Support vector machines for 3D object recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 637–646. [Google Scholar] [CrossRef] [Green Version]
- Nister, D.; Stewenius, H. Scalable recognition with a vocabulary tree. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2161–2168. [Google Scholar]
- Valentin, J.; Sengupta, S.; Warrell, J.; Shahrokni, A.; Torr, P. Mesh Based Semantic Modelling for Indoor and Outdoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2013), Portland, OR, USA, 23–28 June 2013; pp. 2067–2074. [Google Scholar]
- Ruiz-Sarmiento, J.R.; Galindo, C.; González-Jiménez, J. Exploiting Semantic Knowledge for Robot Object Recognition. Knowl.-Based Syst. 2015, 86, 131–142. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.R.; Galindo, C.; González-Jiménez, J. Scene Object Recognition for Mobile Robots Through Semantic Knowledge and Probabilistic Graphical Models. Expert Syst. Appl. 2015, 42, 8805–8816. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.R.; Galindo, C.; Monroy, J.; Moreno, F.A.; Gonzalez-Jimenez, J. Ontology-based conditional random fields for object recognition. Knowl.-Based Syst. 2019, 168, 100–108. [Google Scholar] [CrossRef]
- Uschold, M.; Gruninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Pham, T.T.; Do, T.T.; Sünderhauf, N.; Reid, I. Scenecut: Joint geometric and object segmentation for indoor scenes. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3213–3220. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Hu, R.; Dollár, P.; He, K.; Darrell, T.; Girshick, R. Learning to segment every thing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4233–4241. [Google Scholar]
- Lam, L.; Lee, S.W.; Suen, C.Y. Thinning methodologies-a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 869–885. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the kdd, Portland, Oregon, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Greene, N.; Kass, M.; Miller, G. Hierarchical Z-buffer visibility. In Proceedings of the 20th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 2–6 August 1993; pp. 231–238. [Google Scholar]
- Jonker, P.P. Morphological operations on 3D and 4D images: From shape primitive detection to skeletonization. In Proceedings of the International Conference on Discrete Geometry for Computer Imagery, Uppsala, Sweden, 13–15 December 2000; pp. 371–391. [Google Scholar]
- Gonzalez-Jimenez, J.; Galindo, C.; Ruiz-Sarmiento, J. Technical improvements of the Giraff telepresence robot based on users’ evaluation. In Proceedings of the RO-MAN, Paris, France, 9–13 September 2012; pp. 827–832. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 12 July 2022).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Fernandez-Chaves, D.; Ruiz-Sarmiento, J.; Petkov, N.; Gonzalez-Jimenez, J. ViMantic, a distributed robotic architecture for semantic mapping in indoor environments. Knowl.-Based Syst. 2021, 232, 107440. [Google Scholar] [CrossRef]
- Grunbaum, B.; Shephard, G.C. Pick’s Theorem. Am. Math. Mon. 1993, 100, 150–161. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lap 1 | Lap 2 | ||||||
|---|---|---|---|---|---|---|---|
| Environment | Method | IoU | VIoU | Position Error (m) | IoU | VIoU | Position Error (m) |
| House1 | LTC-Mapping | 0.478 | 0.377 | 0.255 | 0.365 | 0.268 | 0.247 |
| Dengler et al. [13] | 0.232 | – | 0.564 | 0.212 | – | 0.445 | |
| House20 | LTC-Mapping | 0.472 | 0.312 | 0.222 | 0.488 | 0.347 | 0.203 |
| Dengler et al. [13] | 0.307 | – | 0.563 | 0.461 | – | 0.501 | |
| House21 | LTC-Mapping | 0.396 | 0.196 | 0.302 | 0.397 | 0.299 | 0.268 |
| Dengler et al. [13] | 0.390 | – | 0.597 | 0.356 | – | 0.586 | |
| House22 | LTC-Mapping | 0.465 | 0.352 | 0.151 | 0.476 | 0.313 | 0.153 |
| Dengler et al. [13] | 0.294 | – | 0.543 | 0.259 | – | 0.579 | |
| House24 | LTC-Mapping | 0.392 | 0.227 | 0.306 | 0.405 | 0.246 | 0.264 |
| Dengler et al. [13] | 0.319 | – | 0.842 | 0.454 | – | 0.515 | |
| House28 | LTC-Mapping | 0.396 | 0.264 | 0.199 | 0.487 | 0.285 | 0.220 |
| Dengler et al. [13] | 0.365 | – | 0.626 | 0.463 | – | 0.569 | |
| Average | LTC-Mapping | 0.433 | 0.288 | 0.239 | 0.436 | 0.293 | 0.226 |
| Dengler et al. [13] | 0.318 | – | 0.622 | 0.368 | – | 0.532 | |
| Lap 1 | Lap 2 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Environment | Method | TP | FP | FN | Accuracy | Recall | F1-Score | TP | FP | FN | Accuracy | Recall | F1-Score |
| House1 | LTC-Mapping | 15 | 4 | 27 | 78.95% | 35.71% | 49.18% | 16 | 4 | 26 | 80.00% | 38.10% | 46.38% |
| Dengler et al. [13] | 5 | 38 | 37 | 11.63% | 11.90% | 11.76% | 6 | 27 | 36 | 18.18% | 14.29% | 16.00% | |
| House20 | LTC-Mapping | 10 | 3 | 9 | 76.92% | 52.63% | 62.50% | 11 | 4 | 8 | 73.33% | 57.89% | 64.71% |
| Dengler et al. [13] | 6 | 19 | 13 | 24.00% | 31.58% | 27.27% | 7 | 15 | 12 | 31.82% | 36.84% | 34.15% | |
| House21 | LTC-Mapping | 19 | 4 | 25 | 82.61% | 43.18% | 56.72% | 18 | 5 | 26 | 78.26% | 40.91% | 52.94% |
| Dengler et al. [13] | 7 | 33 | 37 | 17.50% | 15.91% | 16.67% | 7 | 41 | 37 | 14.58% | 15.91% | 15.22% | |
| House22 | LTC-Mapping | 6 | 2 | 6 | 75.00% | 50.00% | 60.00% | 6 | 3 | 6 | 66.67% | 50.00% | 57.14% |
| Dengler et al. [13] | 6 | 11 | 6 | 35.29% | 50.00% | 41.38% | 6 | 15 | 6 | 28.57% | 50.00% | 36.36% | |
| House24 | LTC-Mapping | 11 | 6 | 13 | 64.71% | 45.83% | 53.66% | 10 | 4 | 14 | 71.43% | 41.67% | 52.63% |
| Dengler et al. [13] | 12 | 32 | 12 | 27.27% | 50.00% | 35.29% | 7 | 23 | 17 | 23.33% | 29.17% | 25.93% | |
| House28 | LTC-Mapping | 4 | 7 | 17 | 36.36% | 19.05% | 25.00% | 6 | 7 | 15 | 46.15% | 28.57% | 33.33% |
| Dengler et al. [13] | 4 | 19 | 17 | 17.39% | 19.05% | 18.18% | 4 | 20 | 17 | 16.67% | 19.05% | 17.78% | |
| Average | LTC-Mapping | 10.83 | 4.33 | 16.17 | 69.09% | 41.07% | 51.18% | 11.17 | 4.50 | 15.83 | 69.31% | 42.86% | 51.19% |
| Dengler et al. [13] | 6.67 | 25.33 | 20.33 | 22.18% | 29.74% | 25.09% | 6.17 | 23.50 | 20.83 | 22.19% | 27.54% | 24.24% | |
| Stage | Avg. Time (ms) |
|---|---|
| Object Modeling | 137.58 |
| Data Association | 141.91 |
| Map Integration | 143.05 |
| Map Maintenance | 76.27 |
| Total | 498.81 |
| Object Detection (Detectron2) | 494.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matez-Bandera, J.-L.; Fernandez-Chaves, D.; Ruiz-Sarmiento, J.-R.; Monroy, J.; Petkov, N.; Gonzalez-Jimenez, J. LTC-Mapping, Enhancing Long-Term Consistency of Object-Oriented Semantic Maps in Robotics. Sensors 2022, 22, 5308. https://doi.org/10.3390/s22145308
Matez-Bandera J-L, Fernandez-Chaves D, Ruiz-Sarmiento J-R, Monroy J, Petkov N, Gonzalez-Jimenez J. LTC-Mapping, Enhancing Long-Term Consistency of Object-Oriented Semantic Maps in Robotics. Sensors. 2022; 22(14):5308. https://doi.org/10.3390/s22145308
Chicago/Turabian StyleMatez-Bandera, Jose-Luis, David Fernandez-Chaves, Jose-Raul Ruiz-Sarmiento, Javier Monroy, Nicolai Petkov, and Javier Gonzalez-Jimenez. 2022. "LTC-Mapping, Enhancing Long-Term Consistency of Object-Oriented Semantic Maps in Robotics" Sensors 22, no. 14: 5308. https://doi.org/10.3390/s22145308
APA StyleMatez-Bandera, J. -L., Fernandez-Chaves, D., Ruiz-Sarmiento, J. -R., Monroy, J., Petkov, N., & Gonzalez-Jimenez, J. (2022). LTC-Mapping, Enhancing Long-Term Consistency of Object-Oriented Semantic Maps in Robotics. Sensors, 22(14), 5308. https://doi.org/10.3390/s22145308