
Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding



Abstract
:1. Introduction
- 1
- Different from previous studies that reduced the computation by terminating CU partition early, we propose a method to reduce computation complexity by investigating the MTS process, to make it more suitable for real-time applications than VVC.
- 2
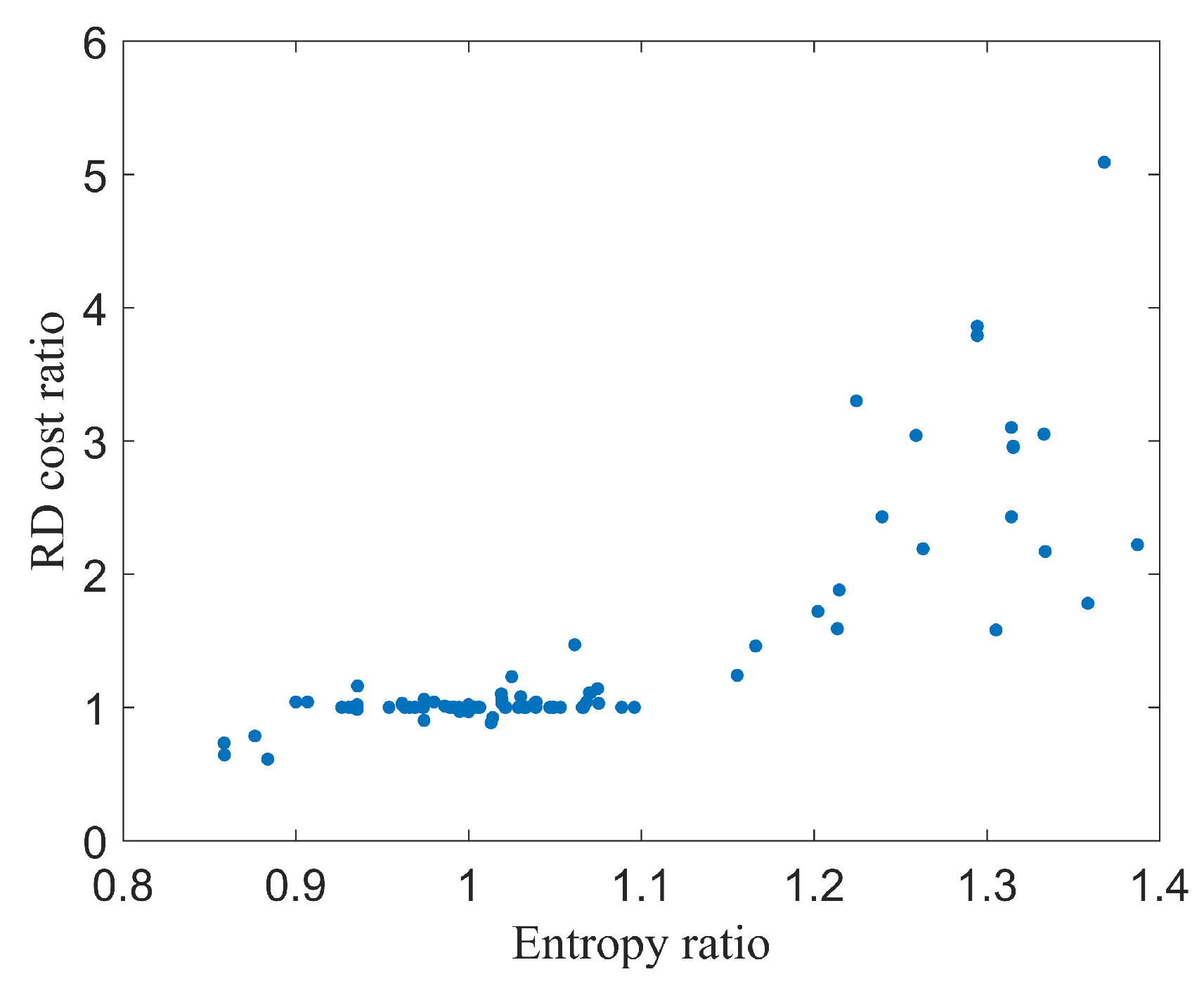
- An MTS skipping method is introduced by exploring the relationship between the RD cost of transforms and the correlation between Sub-Coding Units (sub-CUs) information entropy. The RD checking of MTS can be skipped by comparing the sum of the RD costs of the sub-CUs with the RD cost of their parent CU.
- 3
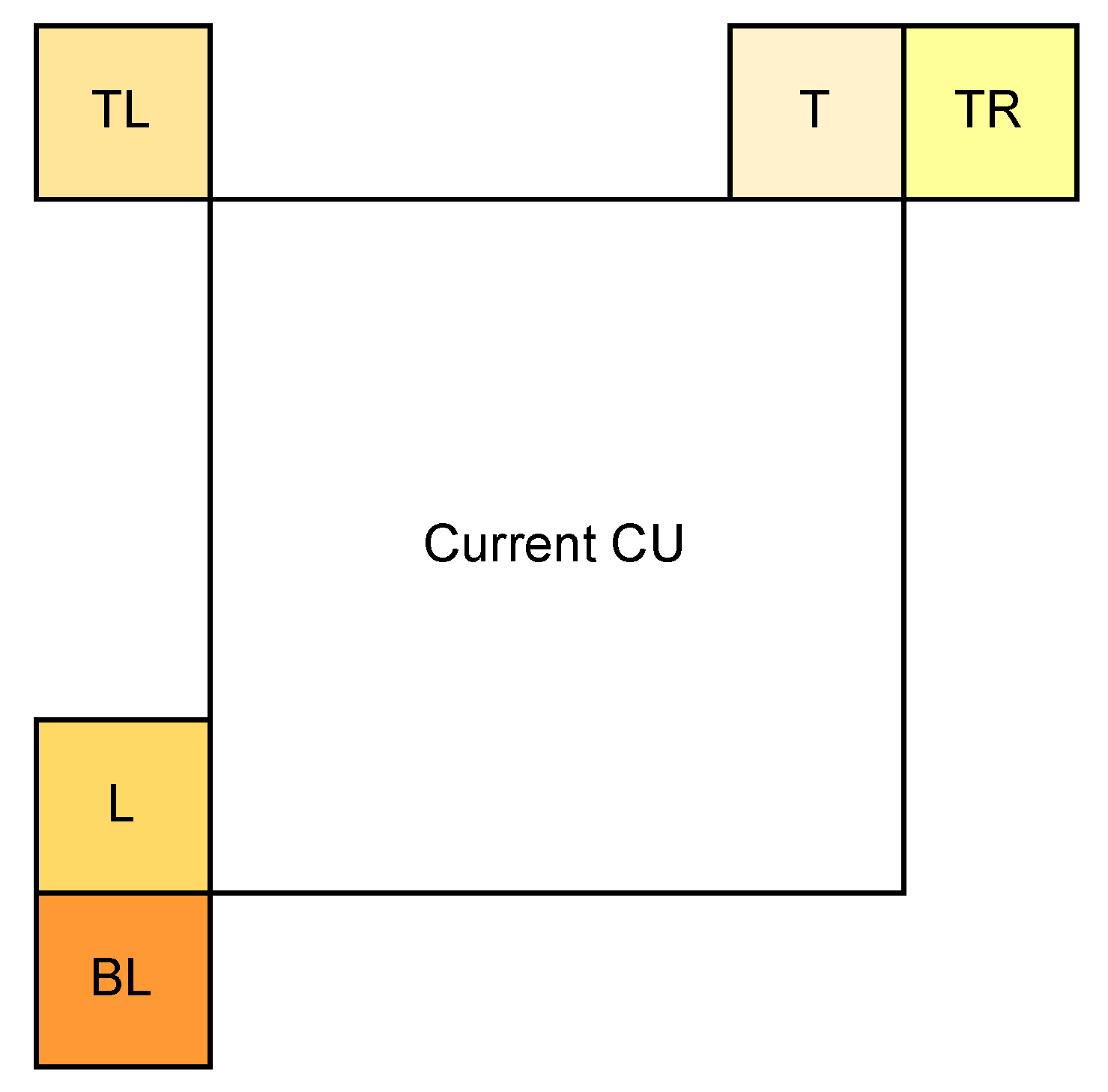
- Based on the coding information of neighboring CUs, the MTS early-termination method is proposed to reorder the candidates in MTS for subsequent RD checking.
2. Related Work
3. Materials and Methods
3.1. MTS Early Skipping Method
| Algorithm 1 The proposed MTS early skipping method |
| Input: , , , Output:
|
3.2. MTS Early Termination Method
- (1)
- If MTS is not included in the transform sets of the neighbouring CUs, only DCT-II is performed on the selected intra-mode.
- (2)
- If MTS is used in the neighbouring CUs, DCT-II is first executed for the current CU, then the transform set is ranked from high to low according to the frequency of each transform in the MTS candidates used in the neighbouring CUs (the set of unused transforms is ranked after the set of used transforms in the original order). When the RD cost of the current transform is larger than the previous one, the subsequent MTS process is terminated early. After determining the best transform, the optimal prediction mode is obtained by RD checking of the prediction modes list. The overall MTS early termination method is specified in Algorithm 2.
| Algorithm 2 The proposed MTS early termination method |
| Input: the prediction modes list L Output: the minimum RD cost of second pass and the best results
|
4. Results
4.1. Experimental Settings
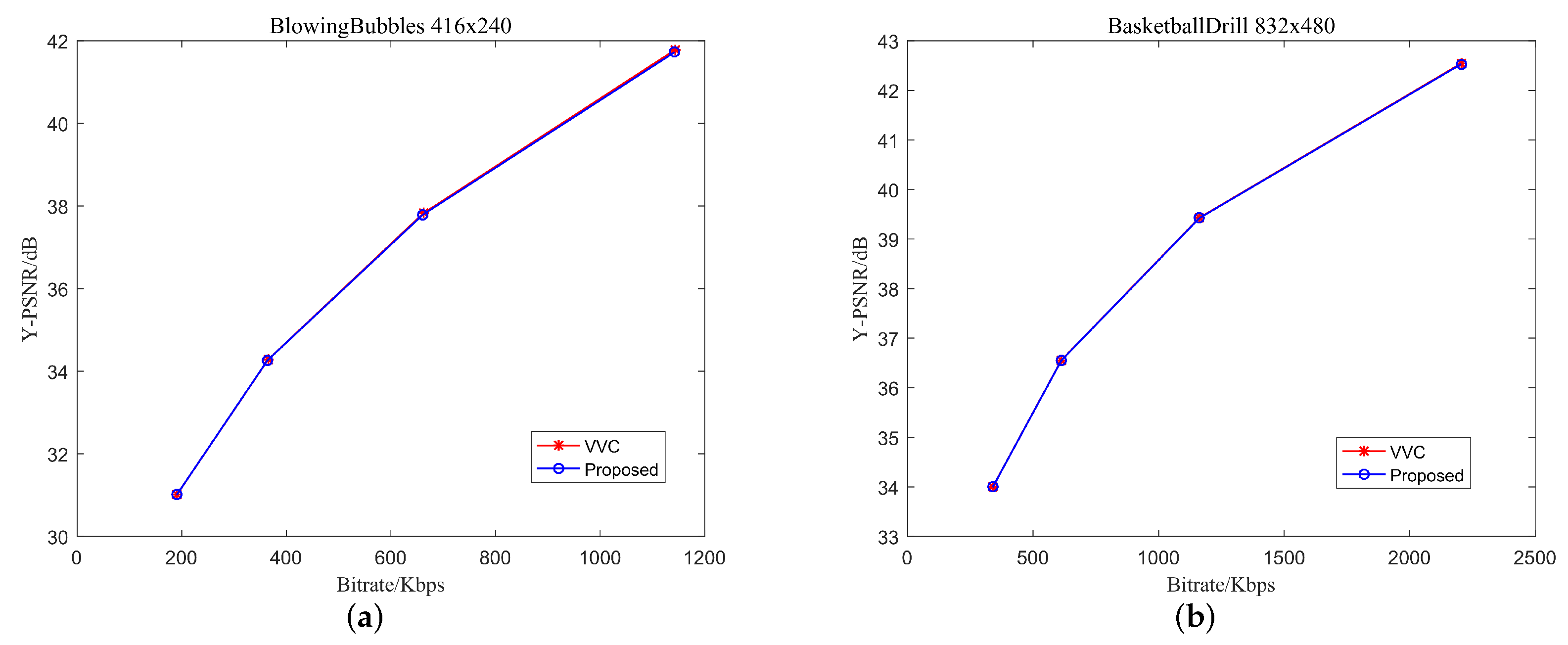
4.2. Experimental Results and Analyses
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, D.; Zhang, Z.; Wu, S.; Yang, J.; Wang, R. Biologically inspired resource allocation for network slices in 5G-enabled Internet of Things. IEEE Internet Things J. 2018, 6, 9266–9279. [Google Scholar] [CrossRef]
- Nightingale, J.; Salva-Garcia, P.; Calero, J.M.A.; Wang, Q. 5G-QoE: QoE modelling for ultra-HD video streaming in 5G networks. IEEE Trans. Broadcast. 2018, 64, 621–634. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Shi, H.; Wang, H.; Wang, R.; Fang, H. A feature-based learning system for Internet of Things applications. IEEE Internet Things J. 2018, 6, 1928–1937. [Google Scholar] [CrossRef]
- Zarca, A.M.; Bernabe, J.B.; Skarmeta, A.; Calero, J.M.A. Virtual IoT HoneyNets to mitigate cyberattacks in SDN/NFV-enabled IoT networks. IEEE J. Sel. Areas Commun. 2020, 38, 1262–1277. [Google Scholar] [CrossRef]
- Hafeez, I.; Antikainen, M.; Ding, A.Y.; Tarkoma, S. IoT-KEEPER: Detecting malicious IoT network activity using online traffic analysis at the edge. IEEE Trans. Netw. Serv. Manag. 2020, 17, 45–59. [Google Scholar] [CrossRef] [Green Version]
- Dhou, S.; Alnabulsi, A.; Al-Ali, A.R.; Arshi, M.; Darwish, F.; Almaazmi, S.; Alameeri, R. An IoT Machine Learning-Based Mobile Sensors Unit for Visually Impaired People. Sensors 2022, 22, 5202. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Liu, S. Versatile video coding (Draft 1), document JVET-J1001. In Proceedings of the 10th JVET Meeting, San Diego, CA, USA, 10–20 April 2018. [Google Scholar]
- Li, X.; Chuang, H.C.; Chen, J.; Karczewicz, M.; Zhang, L.; Zhao, X.; Said, A. Multi-type-tree, document JVET-D0117. In Proceedings of the 4th JVET meeting, Chengdu, China, 15–21 October 2016. [Google Scholar]
- De-Luxán-Hernández, S.; George, V.; Ma, J.; Nguyen, T.; Schwarz, H.; Marpe, D.; Wiegand, T. An intra subpartition coding mode for VVC. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1203–1207. [Google Scholar]
- Zhao, L.; Zhao, X.; Liu, S.; Li, X.; Lainema, J.; Rath, G.; Urban, F.; Racapé, F. Wide angular intra prediction for versatile video coding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 53–62. [Google Scholar]
- Zhang, K.; Chen, Y.W.; Zhang, L.; Chien, W.J.; Karczewicz, M. An improved framework of affine motion compensation in video coding. IEEE Trans. Image Process. 2018, 28, 1456–1469. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, L.; Zhang, K.; Xu, J.; Wang, Y.; Luo, J.; He, Y. Adaptive motion vector resolution for affine-inter mode coding. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Schwarz, H.; Nguyen, T.; Marpe, D.; Wiegand, T. Hybrid video coding with trellis-coded quantization. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 182–191. [Google Scholar]
- Zhao, X.; Chen, J.; Karczewicz, M.; Said, A.; Seregin, V. Joint separable and non-separable transforms for next-generation video coding. IEEE Trans. Image Process. 2018, 27, 2514–2525. [Google Scholar] [CrossRef]
- Zhao, X.; Seregin, V.; Said, A.; Zhang, K.; Egilmez, H.E.; Karczewicz, M. Low-complexity intra prediction refinements for video coding. In Proceedings of the 2018 Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 139–143. [Google Scholar]
- Said, A.; Zhao, X.; Karczewicz, M.; Chen, J.; Zou, F. Position dependent prediction combination for intra-frame video coding. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 534–538. [Google Scholar]
- Huo, J.; Ma, Y.; Wan, S.; Yu, Y.; Wang, M.; Zhang, K.; Zhang, L.; Liu, H.; Xu, J.; Wang, Y.; et al. CE3-1.5: CCLM derived with four neighbouring samples, Document JVET N0271. In Proceedings of the 14th JVET Meeting, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Laroche, G.J.; Taquet, C.G.P.O. CE3-5.1: On cross-component linear model simplification, Document JVET-L0191. In Proceedings of the 12th JVET Meeting, Macao, China, 3–12 October 2018. [Google Scholar]
- Zhang, C.; Ugur, K.; Lainema, J.; Hallapuro, A.; Gabbouj, M. Video coding using spatially varying transform. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 127–140. [Google Scholar] [CrossRef] [Green Version]
- Koo, M.; Salehifar, M.; Lim, J.; Kim, S.H. Low frequency non-separable transform (LFNST). In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Salehifar, M.; Koo, M. CE6: Reduced Secondary Transform (RST) (CE6-3.1), document JVET-N0193. In Proceedings of the 14th JVET Meeting, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Peloso, R.; Capra, M.; Sole, L.; Ruo Roch, M.; Masera, G.; Martina, M. Steerable-Discrete-Cosine-Transform (SDCT): Hardware Implementation and Performance Analysis. Sensors 2020, 20, 1405. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lainema, J. CE6-Related: Shape Adaptive Transform Selection, document JVET-L0134. In Proceedings of the 12th JVET Meeting, Macao, China, 3–12 October 2018. [Google Scholar]
- Chen, J.Y.; Ye, S.H.K. Algorithm description for Versatile Video Coding and Test Model 7 (VTM 7), document JVET-P2002-V1. In Proceedings of the 16th JVET Meeting, Geneva, Switzerland, 1–11 October 2019. [Google Scholar]
- Lin, S.; Chen, H.; Zhang, H.; Sychev, M.; Yang, H.; Zhou, J. Affine Transform Prediction for Next Generation Video Coding. In Proceedings of the ITUT SG16/Q6 Doc. COM16-C1016, Geneva, Switzerland, February 2015. [Google Scholar]
- Chen, J.; Karczewicz, M.; Huang, Y.W.; Choi, K.; Ohm, J.R.; Sullivan, G.J. The joint exploration model (JEM) for video compression with capability beyond HEVC. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1208–1225. [Google Scholar] [CrossRef]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU partition decision algorithm for VVC intra and inter coding. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 361–364. [Google Scholar]
- Lin, T.L.; Jiang, H.Y.; Huang, J.Y.; Chang, P.C. Fast binary tree partition decision in H. 266/FVC intra Coding. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taiwan, China, 19–21 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–2. [Google Scholar]
- Fu, G.; Shen, L.; Yang, H.; Hu, X.; An, P. Fast intra coding of high dynamic range videos in SHVC. IEEE Signal Process. Lett. 2018, 25, 1665–1669. [Google Scholar] [CrossRef]
- Park, J.; Kim, B.; Jeon, B. Fast VVC Intra Subpartition based on Position of Reference Pixels. In Proceedings of the 2022 International Conference on Electronics, Information, and Communication (ICEIC), New York, NY, USA, 8–9 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–2. [Google Scholar]
- Dong, X.; Shen, L.; Yu, M.; Yang, H. Fast intra mode decision algorithm for versatile video coding. IEEE Trans. Multimed. 2021, 24, 400–414. [Google Scholar] [CrossRef]
- Zhang, M.; Qu, J.; Bai, H. Entropy-based fast largest coding unit partition algorithm in high-efficiency video coding. Entropy 2013, 15, 2277–2287. [Google Scholar] [CrossRef] [Green Version]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Configurable Fast Block Partitioning for VVC Intra Coding Using Light Gradient Boosting Machine. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3947–3960. [Google Scholar] [CrossRef]
- Jin, Z.; An, P.; Shen, L.; Yang, C. CNN oriented fast QTBT partition algorithm for JVET intra coding. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU split decision with pooling-variable CNN for VVC intra encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Pan, Z.; Zhang, P.; Peng, B.; Ling, N.; Lei, J. A CNN-Based Fast Inter Coding Method for VVC. IEEE Signal Process. Lett. 2021, 28, 1260–1264. [Google Scholar] [CrossRef]
- Wu, S.; Shi, J.; Chen, Z. HG-FCN: Hierarchical Grid Fully Convolutional Network for Fast VVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2022. [Google Scholar] [CrossRef]
- Sharabayko, M.P.; Ponomarev, O.G. Fast rate estimation for RDO mode decision in HEVC. Entropy 2014, 16, 6667–6685. [Google Scholar] [CrossRef] [Green Version]
- Hamidouche, W.; Philippe, P.; Fezza, S.A.; Haddou, M.; Pescador, F.; Menard, D. Hardware-friendly multiple transform selection module for the VVC standard. IEEE Trans. Consum. Electron. 2022, 68, 96–106. [Google Scholar] [CrossRef]
- Wang, R.; Tang, L.; Tang, T. Fast Sample Adaptive Offset Jointly Based on HOG Features and Depth Information for VVC in Visual Sensor Networks. Sensors 2020, 20, 6754. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Feng, J.; Song, T.; Katayama, T. Low-complexity and hardware-friendly H. 265/HEVC encoder for vehicular ad-hoc networks. Sensors 2019, 19, 1927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Two-stage fast multiple transform selection algorithm for VVC intra coding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 61–66. [Google Scholar]
- Bossen, F.; Boyce, J.; Li, X.; Seregin, V.; Sühring, K. JVET common test conditions and software reference configurations for SDR video. Jt. Video Experts Team (JVET) ITU-T SG 2019, 16, 19–27. [Google Scholar]
- Bjontegaard, G. Improvements of the BD-PSNR model. In Proceedings of the ITU-T SG16/Q6, 35th VCEG Meeting, Berlin, Germany, 16–18 July 2008. [Google Scholar]
- Zhang, Z.; Zhao, X.; Li, X.; Li, Z.; Liu, S. Fast adaptive multiple transform for versatile video coding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 63–72. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MTS Candidate Indexes | Horizontal | Vertical |
|---|---|---|
| 0 | DST-VII | DST-VII |
| 1 | DST-VII | DCT-VIII |
| 2 | DCT-VIII | DST-VII |
| 3 | DCT-VIII | DCT-VIII |
| Video Sequences | Probability |
|---|---|
| BasketballPass | 94.7% |
| RaceHorsesC | 93.6% |
| Johnny | 96.7% |
| BasketballDrive | 95.5% |
| Average | 95.1% |
| Video Sequences | ||
|---|---|---|
| BasketballPass | 88.5% | 78.6% |
| RaceHorsesC | 80.6% | 82.7% |
| Johnny | 82.3% | 79.3% |
| BasketballDrive | 85.6% | 80.5% |
| Average | 84.3% | 80.3% |
| Items | Descriptions |
|---|---|
| Software | VTM-3.0 |
| Configuration File | encoder intra vtm.cfg |
| Video Sequence Size | 416 × 240, 832 × 480, |
| 1280 × 720, 1920 × 1080 | |
| Number of Encoded Frames | 30 |
| Quantization Parameter (QP) | 22, 27, 32 and 37 |
| Sampling of Luminance to Chrominance | 4:2:0 |
| Class | Sequences | Size | Bit-Depth | Frame Rate |
|---|---|---|---|---|
| BasketballDrive | 1920 × 1280 | 8 | 50 | |
| B | BQTerrace | 1920 × 1280 | 8 | 60 |
| Cactus | 1920 × 1280 | 8 | 50 | |
| BasketballDrill | 832 × 480 | 8 | 50 | |
| C | BQMall | 832 × 480 | 8 | 60 |
| PartyScene | 832 × 480 | 8 | 50 | |
| BasketballPass | 416 × 240 | 8 | 50 | |
| D | BlowingBubbles | 416 × 240 | 8 | 50 |
| RaceHorses | 416 × 240 | 8 | 30 | |
| FourPeople | 1280 × 720 | 8 | 60 | |
| E | Johhny | 1280 × 720 | 8 | 60 |
| KristenAndSara | 1280 × 720 | 8 | 60 | |
| Slideshow | 1280 × 720 | 8 | 20 | |
| F | SlideEditing | 1280 × 720 | 8 | 30 |
| BasketballDrillText | 832 × 480 | 8 | 50 |
| Class | Sequences | BDBR/% | BD-PSNR/db | /% |
|---|---|---|---|---|
| BasketballDrive | 0.08 | −0.007 | 29.16 | |
| B | BQTerrace | 0.10 | −0.004 | 28.02 |
| Cactus | 0.15 | −0.008 | 26.06 | |
| BasketballDrill | 0.12 | −0.007 | 27.42 | |
| C | BQMall | 0.09 | −0.003 | 24.53 |
| PartyScene | 0.10 | −0.009 | 29.30 | |
| BasketballPass | 0.15 | −0.007 | 24.18 | |
| D | BlowingBubbles | 0.12 | −0.008 | 27.09 |
| RaceHorses | 0.14 | −0.007 | 25.13 | |
| FourPeople | 0.16 | −0.006 | 26.89 | |
| E | Johhny | 0.14 | −0.007 | 25.47 |
| KristenAndSara | 0.11 | −0.005 | 29.40 | |
| Slideshow | 0.18 | −0.009 | 24.64 | |
| F | SlideEditing | 0.14 | −0.008 | 22.35 |
| BasketballDrillText | 0.13 | −0.008 | 26.42 | |
| Average | - | 0.13 | −0.007 | 26.40 |
| Sequences | Fu et al. [43] | Zhang et al. [46] | Proposed | |||
|---|---|---|---|---|---|---|
| BDBR(%) | (%) | BDBR(%) | (%) | BDBR(%) | (%) | |
| Cactus | 0.18 | 23 | −0.01 | 10 | 0.15 | 26.06 |
| BQTerrace | 0.12 | 25 | 8 | 0.10 | 28.02 | |
| BasketballDrive | 0.09 | 23 | 8 | 0.08 | 29.16 | |
| BQMall | 0.11 | 24 | 0.02 | 3 | 0.09 | 24.53 |
| PartyScene | 0.16 | 25 | 5 | 0.10 | 29.30 | |
| BasketballDrill | 0.14 | 21 | 9 | 0.12 | 27.42 | |
| BasketballPass | 0.19 | 23 | 0.06 | 7 | 0.15 | 24.18 |
| BlowingBubbles | 0.17 | 24 | 6 | 0.12 | 27.09 | |
| RaceHorses | 0.16 | 23 | 1 | 0.14 | 25.13 | |
| FourPeople | 0.22 | 23 | 0.03 | 7 | 0.16 | 26.89 |
| KristenAndSara | 0.19 | 23 | 10 | 0.11 | 29.40 | |
| Johnny | 0.2 | 22 | 9 | 0.14 | 25.47 | |
| Average | 0.16 | 23.30 | 0.03 | 6.92 | 0.12 | 26.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Xiong, S.; Yang, R.; He, X.; Chen, H. Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding. Sensors 2022, 22, 5523. https://doi.org/10.3390/s22155523
He L, Xiong S, Yang R, He X, Chen H. Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding. Sensors. 2022; 22(15):5523. https://doi.org/10.3390/s22155523
Chicago/Turabian StyleHe, Liqiang, Shuhua Xiong, Ruolan Yang, Xiaohai He, and Honggang Chen. 2022. "Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding" Sensors 22, no. 15: 5523. https://doi.org/10.3390/s22155523
APA StyleHe, L., Xiong, S., Yang, R., He, X., & Chen, H. (2022). Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding. Sensors, 22(15), 5523. https://doi.org/10.3390/s22155523