
Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning


Abstract
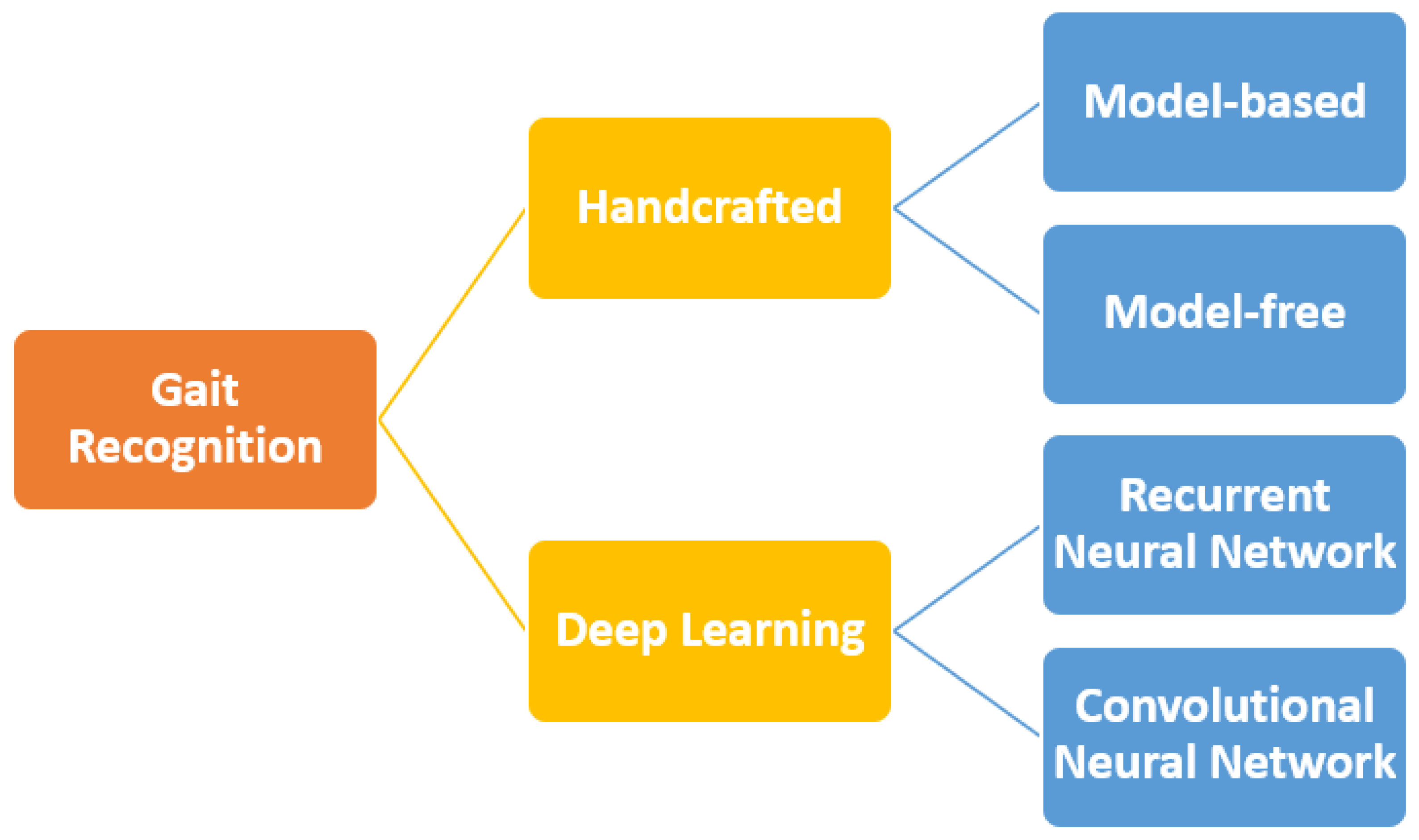
:1. Introduction
2. Handcrafted Approach
2.1. Model-Based Approach
2.2. Model-Free Approach
3. Deep Learning Approach
3.1. Recurrent Neural Networks
3.2. Convolutional Neural Networks
4. Gait Datasets
4.1. CASIA-B
4.2. OU-ISIR Treadmill Gait Dataset D
4.3. OU-ISIR Large Population Dataset
4.4. OU-ISIR Multi-View Large Population Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mannini, A.; Trojaniello, D.; Cereatti, A.; Sabatini, A.M. A machine learning framework for gait classification using inertial sensors: Application to elderly, post-stroke and huntington’s disease patients. Sensors 2016, 16, 134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lv, Z.; Xing, X.; Wang, K.; Guan, D. Class energy image analysis for video sensor-based gait recognition: A review. Sensors 2015, 15, 932–964. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manssor, S.A.; Sun, S.; Elhassan, M.A. Real-time human recognition at night via integrated face and gait recognition technologies. Sensors 2021, 21, 4323. [Google Scholar] [CrossRef] [PubMed]
- Dehzangi, O.; Taherisadr, M.; ChangalVala, R. IMU-based gait recognition using convolutional neural networks and multi-sensor fusion. Sensors 2017, 17, 2735. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. DeepGait: A learning deep convolutional representation for view-invariant gait recognition using joint Bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Saleem, F.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Armghan, A.; Alenezi, F.; Choi, J.I.; Kadry, S. Human gait recognition: A single stream optimal deep learning features fusion. Sensors 2021, 21, 7584. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. De Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Delgado-Escano, R.; Castro, F.M.; Cózar, J.R.; Marín-Jiménez, M.J.; Guil, N. An end-to-end multi-task and fusion CNN for inertial-based gait recognition. IEEE Access 2018, 7, 1897–1908. [Google Scholar] [CrossRef]
- Min, P.P.; Sayeed, S.; Ong, T.S. Gait recognition using deep convolutional features. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–5. [Google Scholar]
- Su, J.; Zhao, Y.; Li, X. Progressive Spatio-Temporal Feature Extraction Model For Gait Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1004–1008. [Google Scholar]
- Lin, B.; Zhang, S.; Liu, Y.; Qin, S. Multi-scale temporal information extractor for gait recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2998–3002. [Google Scholar]
- Sepas-Moghaddam, A.; Etemad, A. View-invariant gait recognition with attentive recurrent learning of partial representations. IEEE Trans. Biom. Behav. Identity Sci. 2020, 3, 124–137. [Google Scholar] [CrossRef]
- Jun, K.; Lee, D.W.; Lee, K.; Lee, S.; Kim, M.S. Feature extraction using an RNN autoencoder for skeleton-based abnormal gait recognition. IEEE Access 2020, 8, 19196–19207. [Google Scholar] [CrossRef]
- Zhang, Z.; Tran, L.; Liu, F.; Liu, X. On learning disentangled representations for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 345–360. [Google Scholar] [CrossRef]
- Tran, L.; Hoang, T.; Nguyen, T.; Kim, H.; Choi, D. Multi-model long short-term memory network for gait recognition using window-based data segment. IEEE Access 2021, 9, 23826–23839. [Google Scholar] [CrossRef]
- He, Y.; Zhang, J.; Shan, H.; Wang, L. Multi-task GANs for view-specific feature learning in gait recognition. IEEE Trans. Inf. Forensics Secur. 2018, 14, 102–113. [Google Scholar] [CrossRef]
- Hu, B.; Guan, Y.; Gao, Y.; Long, Y.; Lane, N.; Ploetz, T. Robust cross-view gait recognition with evidence: A discriminant gait GAN (DiGGAN) approach. arXiv 2018, arXiv:1811.10493. [Google Scholar]
- Gupta, S.K.; Chattopadhyay, P. Gait recognition in the presence of co-variate conditions. Neurocomputing 2021, 454, 76–87. [Google Scholar] [CrossRef]
- Chen, X.; Luo, X.; Weng, J.; Luo, W.; Li, H.; Tian, Q. Multi-view gait image generation for cross-view gait recognition. IEEE Trans. Image Process. 2021, 30, 3041–3055. [Google Scholar] [CrossRef]
- Kang, Z.; Deng, M.; Wang, C. Frontal-view human gait recognition based on Kinect features and deterministic learning. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 10834–10839. [Google Scholar]
- Deng, M.; Wang, C. Gait recognition under different clothing conditions via deterministic learning. IEEE/CAA J. Autom. Sin. 2018, 1–10, earlyaccess. [Google Scholar] [CrossRef] [Green Version]
- Deng, M.; Yang, H.; Cao, J.; Feng, X. View-invariant gait recognition based on deterministic learning and knowledge fusion. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Deng, M.; Fan, T.; Cao, J.; Fung, S.Y.; Zhang, J. Human gait recognition based on deterministic learning and knowledge fusion through multiple walking views. J. Frankl. Inst. 2020, 357, 2471–2491. [Google Scholar] [CrossRef]
- Deng, M.; Wang, C. Human gait recognition based on deterministic learning and data stream of microsoft kinect. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3636–3645. [Google Scholar] [CrossRef]
- Zhen, H.; Deng, M.; Lin, P.; Wang, C. Human gait recognition based on deterministic learning and Kinect sensor. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1842–1847. [Google Scholar]
- Choi, S.; Kim, J.; Kim, W.; Kim, C. Skeleton-based gait recognition via robust frame-level matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2577–2592. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Ahmed, M.; Al-Jawad, N.; Sabir, A.T. Gait recognition based on Kinect sensor. In Proceedings of the Real-Time Image and Video Processing 2014, Brussels, Belgium, 16–17 April 2014; Volume 9139, pp. 63–72. [Google Scholar]
- Wang, Y.; Sun, J.; Li, J.; Zhao, D. Gait recognition based on 3D skeleton joints captured by kinect. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3151–3155. [Google Scholar]
- Sun, J.; Wang, Y.; Li, J.; Wan, W.; Cheng, D.; Zhang, H. View-invariant gait recognition based on kinect skeleton feature. Multimed. Tools Appl. 2018, 77, 24909–24935. [Google Scholar] [CrossRef]
- Zeng, W.; Wang, C.; Li, Y. Model-based human gait recognition via deterministic learning. Cogn. Comput. 2014, 6, 218–229. [Google Scholar] [CrossRef]
- Deng, M.; Wang, C.; Cheng, F.; Zeng, W. Fusion of spatial-temporal and kinematic features for gait recognition with deterministic learning. Pattern Recognit. 2017, 67, 186–200. [Google Scholar] [CrossRef]
- Sattrupai, T.; Kusakunniran, W. Deep trajectory based gait recognition for human re-identification. In Proceedings of the TENCON 2018-2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018; pp. 1723–1726. [Google Scholar]
- Kovač, J.; Štruc, V.; Peer, P. Frame–based classification for cross-speed gait recognition. Multimed. Tools Appl. 2019, 78, 5621–5643. [Google Scholar] [CrossRef]
- Sah, S.; Panday, S.P. Model Based Gait Recognition Using Weighted KNN. In Proceedings of the 8th IOE Graduate Conference, Kathmandu, Nepal, 28–31 June 2020; pp. 1019–1026. [Google Scholar]
- Sharif, M.; Attique, M.; Tahir, M.Z.; Yasmim, M.; Saba, T.; Tanik, U.J. A machine learning method with threshold based parallel feature fusion and feature selection for automated gait recognition. J. Organ. End User Comput. 2020, 32, 67–92. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait recognition via optimally interpolated deformable contours. Pattern Recognit. Lett. 2013, 34, 663–669. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Time-sliced averaged motion history image for gait recognition. J. Vis. Commun. Image Represent. 2014, 25, 822–826. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait probability image: An information-theoretic model of gait representation. J. Vis. Commun. Image Represent. 2014, 25, 1489–1492. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait recognition with transient binary patterns. J. Vis. Commun. Image Represent. 2015, 33, 69–77. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.; Lim, K. Review on vision-based gait recognition: Representations, classification schemes and datasets. Am. J. Appl. Sci. 2017, 14, 252–266. [Google Scholar] [CrossRef] [Green Version]
- Jeevan, M.; Jain, N.; Hanmandlu, M.; Chetty, G. Gait recognition based on gait pal and pal entropy image. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 5–18 September 2013; pp. 4195–4199. [Google Scholar]
- Hosseini, N.K.; Nordin, M.J. Human gait recognition: A silhouette based approach. J. Autom. Control Eng. 2013, 1, 103–105. [Google Scholar] [CrossRef]
- Alvarez, I.R.T.; Sahonero-Alvarez, G. Gait recognition based on modified Gait energy image. In Proceedings of the 2018 IEEE Sciences and Humanities International Research Conference (SHIRCON), Lima, Peru, 20–22 November 2018; pp. 1–4. [Google Scholar]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Zhang, J.; Zi, C.; Niu, Y.; Tian, H.; Xiu, C. Gait recognition using GEI and AFDEI. Int. J. Opt. 2015, 2015, 763908. [Google Scholar] [CrossRef]
- Arora, P.; Srivastava, S. Gait recognition using gait Gaussian image. In Proceedings of the 2015 2nd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 19–20 February 2015; pp. 791–794. [Google Scholar]
- Fathima, S.S.S.; Banu, R.W.; Roomi, S.M.M. Gait Based Human Recognition with Various Classifiers Using Exhaustive Angle Calculations in Model Free Approach. Circuits Syst. 2016, 7, 1465–1475. [Google Scholar] [CrossRef] [Green Version]
- Rida, I.; Boubchir, L.; Al-Maadeed, N.; Al-Maadeed, S.; Bouridane, A. Robust model-free gait recognition by statistical dependency feature selection and globality-locality preserving projections. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016; pp. 652–655. [Google Scholar]
- Wang, X.; Wang, J.; Yan, K. Gait recognition based on Gabor wavelets and (2D) 2PCA. Multimed. Tools Appl. 2018, 77, 12545–12561. [Google Scholar] [CrossRef]
- Rida, I.; Almaadeed, S.; Bouridane, A. Improved gait recognition based on gait energy images. In Proceedings of the 2014 26th International Conference on Microelectronics (ICM), Doha, Qatar, 14–17 December 2014; pp. 40–43. [Google Scholar]
- Rida, I. Towards human body-part learning for model-free gait recognition. arXiv 2019, arXiv:1904.01620. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Tan, A.W. Gait recognition using binarized statistical image features and histograms of oriented gradients. In Proceedings of the 2017 International Conference on Robotics, Automation and Sciences (ICORAS), Melaka, Malaysia, 27–29 November 2017; pp. 1–6. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M. Gait recognition using histograms of temporal gradients. In Proceedings of the Journal of Physics: Conference Series, Xi’an, China, 18–19 October 2020; Volume 1502, p. 012051. [Google Scholar]
- McLaughlin, N.; Del Rincon, J.M.; Miller, P. Recurrent convolutional network for video-based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1325–1334. [Google Scholar]
- Rama Varior, R.; Shuai, B.; Lu, J.; Xu, D.; Wang, G. A Siamese Long Short-Term Memory Architecture for Human Re-Identification. arXiv 2016, arXiv:1607.08381. [Google Scholar]
- Li, J.; Qi, L.; Zhao, A.; Chen, X.; Dong, J. Dynamic long short-term memory network for skeleton-based gait recognition. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDC/om/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar]
- Zhang, Y.; Huang, Y.; Yu, S.; Wang, L. Cross-view gait recognition by discriminative feature learning. IEEE Trans. Image Process. 2019, 29, 1001–1015. [Google Scholar] [CrossRef]
- Battistone, F.; Petrosino, A. TGLSTM: A time based graph deep learning approach to gait recognition. Pattern Recognit. Lett. 2019, 126, 132–138. [Google Scholar] [CrossRef]
- Tong, S.; Fu, Y.; Ling, H.; Zhang, E. Gait identification by joint spatial-temporal feature. In Proceedings of the Chinese Conference on Biometric Recognition, Urumchi, China, 11–12 August 2017; pp. 457–465. [Google Scholar]
- Wang, X.; Yan, W.Q. Human gait recognition based on frame-by-frame gait energy images and convolutional long short-term memory. Int. J. Neural Syst. 2020, 30, 1950027. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, X.; Sun, T.; Xu, K. 3D gait recognition based on a CNN-LSTM network with the fusion of SkeGEI and DA features. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Hasan, M.M.; Mustafa, H.A. Multi-level feature fusion for robust pose-based gait recognition using RNN. Int. J. Comput. Sci. Inf. Secur. 2020, 18, 20–31. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Yu, S.; Ren, M. End-to-end model-based gait recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; pp. 1–17. [Google Scholar]
- Wen, J.; Wang, X. Cross-view gait recognition based on residual long short-term memory. Multimed. Tools Appl. 2021, 80, 28777–28788. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Huang, Y.; Jia, N.; Wang, L. Gaitnet: An end-to-end network for gait based human identification. Pattern Recognit. 2019, 96, 106988. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhu, X.; Yun, L.; Cheng, F.; Zhang, C. LFN: Based on the convolutional neural network of gait recognition method. J. Phys. Conf. Ser. 2020, 1650, 032075. [Google Scholar] [CrossRef]
- Su, J.; Zhao, Y.; Li, X. Deep metric learning based on center-ranked loss for gait recognition. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, 4–8 May 2020; pp. 4077–4081. [Google Scholar]
- Wen, J. Gait recognition based on GF-CNN and metric learning. J. Inf. Process. Syst. 2020, 16, 1105–1112. [Google Scholar]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. Gaitpart: Temporal part-based model for gait recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 14225–14233. [Google Scholar]
- Hou, S.; Cao, C.; Liu, X.; Huang, Y. Gait lateral network: Learning discriminative and compact representations for gait recognition. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 382–398. [Google Scholar]
- Chao, H.; Wang, K.; He, Y.; Zhang, J.; Feng, J. GaitSet: Cross-view gait recognition through utilizing gait as a deep set. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3467–3478. [Google Scholar] [CrossRef]
- Ding, X.; Wang, K.; Wang, C.; Lan, T.; Liu, L. Sequential convolutional network for behavioral pattern extraction in gait recognition. Neurocomputing 2021, 463, 411–421. [Google Scholar] [CrossRef]
- Yoo, J.S.; Park, K.H. Skeleton silhouette based disentangled feature extraction network for invariant gait recognition. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju, Korea, 13–16 January 2021; pp. 687–692. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Jia, P.; Zhao, Q.; Li, B.; Zhang, J. Cjam: Convolutional neural network joint attention mechanism in gait recognition. IEICE Trans. Inf. Syst. 2021, 104, 1239–1249. [Google Scholar] [CrossRef]
- Shiraga, K.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Geinet: View-invariant gait recognition using a convolutional neural network. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Yeoh, T.; Aguirre, H.E.; Tanaka, K. Clothing-invariant gait recognition using convolutional neural network. In Proceedings of the 2016 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Phuket, Thailand, 24–27 October 2016; pp. 1–5. [Google Scholar]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A comprehensive study on cross-view gait based human identification with deep cnns. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 209–226. [Google Scholar] [CrossRef]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. On input/output architectures for convolutional neural network-based cross-view gait recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 2708–2719. [Google Scholar] [CrossRef]
- Tong, S.; Ling, H.; Fu, Y.; Wang, D. Cross-view gait identification with embedded learning. In Proceedings of the Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 385–392. [Google Scholar]
- Alotaibi, M.; Mahmood, A. Improved gait recognition based on specialized deep convolutional neural network. Comput. Vis. Image Underst. 2017, 164, 103–110. [Google Scholar] [CrossRef]
- Wu, H.; Weng, J.; Chen, X.; Lu, W. Feedback weight convolutional neural network for gait recognition. J. Vis. Commun. Image Represent. 2018, 55, 424–432. [Google Scholar] [CrossRef]
- Khan, M.A.; Fathima, S.S.S.; Stepnila, B.A.; Ali, A.M.I. Joint intensity transformer network for gait recognition robust against clothing and carrying status. Mater. Today Proc. 2020, 33, 3008–3020. [Google Scholar] [CrossRef]
- Wu, Y.; Hou, J.; Su, Y.; Wu, C.; Huang, M.; Zhu, Z. Gait recognition based on feedback weight capsule network. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 155–160. [Google Scholar]
- Xu, C.; Makihara, Y.; Li, X.; Yagi, Y.; Lu, J. Cross-view gait recognition using pairwise spatial transformer networks. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 260–274. [Google Scholar] [CrossRef]
- Wang, X.; Yan, W.Q. Non-local gait feature extraction and human identification. Multimed. Tools Appl. 2021, 80, 6065–6078. [Google Scholar] [CrossRef]
- Balamurugan, S. Deep Features Based Multiview Gait Recognition. Turk. J. Comput. Math. Educ. 2021, 12, 472–478. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A. Gait recognition for person re-identification. J. Supercomput. 2021, 77, 3653–3672. [Google Scholar] [CrossRef]
- Xu, W. Deep Large Margin Nearest Neighbor for Gait Recognition. J. Intell. Syst. 2021, 30, 604–619. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Anbananthen, K.S.M.; Lim, K.M. Gait-DenseNet: A Hybrid Convolutional Neural Network for Gait Recognition. IAENG Int. J. Comput. Sci. 2022, 49, 393–400. [Google Scholar]
- Wang, X.; Zhang, J.; Yan, W.Q. Gait recognition using multichannel convolution neural networks. Neural Comput. Appl. 2020, 32, 14275–14285. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J. Gait feature extraction and gait classification using two-branch CNN. Multimed. Tools Appl. 2020, 79, 2917–2930. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J. Gait recognition method of underground coal mine personnel based on densely connected convolution network and stacked convolutional autoencoder. Entropy 2020, 22, 695. [Google Scholar] [CrossRef] [PubMed]
- Chai, T.; Mei, X.; Li, A.; Wang, Y. Silhouette-based view-embeddings for gait recognition under multiple views. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2319–2323. [Google Scholar]
- Wang, X.; Yan, K. Gait classification through CNN-based ensemble learning. Multimed. Tools Appl. 2021, 80, 1565–1581. [Google Scholar] [CrossRef]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Makihara, Y.; Mannami, H.; Tsuji, A.; Hossain, M.A.; Sugiura, K.; Mori, A.; Yagi, Y. The OU-ISIR gait database comprising the treadmill dataset. IPSJ Trans. Comput. Vis. Appl. 2012, 4, 53–62. [Google Scholar] [CrossRef] [Green Version]
- Iwama, H.; Okumura, M.; Makihara, Y.; Yagi, Y. The ou-isir gait database comprising the large population dataset and performance evaluation of gait recognition. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1511–1521. [Google Scholar] [CrossRef] [Green Version]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 1–14. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Literature | Gait Features | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|
| Ahmed et al. [30] | HDF and VDF | kNN | Own dataset | 92 |
| Wang et al. [31] | Static and dynamic parameters | NN | Own dataset | 92.30 |
| Sun et al. [32] | Static and dynamic features | NN | Own dataset | 92.30 |
| Zeng et al. [33] | Joint angles | Smallest error principle | CASIA-A | 92.50 |
| CASIA-B | 91.90 | |||
| CASIA-B | 94 | |||
| CASIA-C | 99 | |||
| Deng et al. [34] | Lower limbs regions and lower limbs joint angles | Smallest error principle | TUM GAID | 90 |
| OU-ISIR B | 98 | |||
| USF HumanID | 94.40 | |||
| Sattrupai & Kusakunniran [35] | Motion trajectory, HOG, HOF and MBH (x,y) | kNN + Euclidean distance | CASIA-B | 95 |
| Kovic et al. [36] | Gait signals + LDA | kNN | OU-ISIR A | - |
| Sah & Panday [37] | CoB coordinates | Weighted-kNN | Own dataset | - |
| CASIA-A | 98.90 | |||
| Sharif et al. [38] | Texture + shape + geometric | Euclidean distance | CASIA-B | 95.80 |
| CASIA-C | 97.30 |
| Literature | Gait Features | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|
| Jeevan et al. [44] | GPPE + PCA | SVM | CASIA-A | L-L: 73.68 L-R: 26.31 |
| CASIA-B | Nm: 93.36 Cl: 22.44 Bg: 56.12 | |||
| CASIA-C | Nm: 73.17 Bg: 43.74 Fast: 69.53 Slow: 56.95 | |||
| OU-ISIR A | 100 | |||
| Hosseini & Nordin [45] | Averaged silhouettes + PCA | Euclidean distance | TUM-IITKGP | 60 |
| Alvarez & Sahonero-Alvarez [46] | Modified GEI + PCA | LDA | CASIA-B | 90.12 |
| Luo et al. [48] | GEI + AFDEI | NN + Euclidean Distance | CASIA-B | Nm: 88.7 Cl: 91.9 Bg: 89.9 |
| Arora & Srivastava [49] | GGI | NN + Euclidean Distance | CASIA-B | 98 |
| Soton | 100 | |||
| Fathima et al. [50] | Kinematics parameters | SVM, kNN and RVM | CASIA-B | 91.5 |
| Rida et al. [51] | Scores of SD | 1-NN + GLPP | CASIA-B | 86.06 |
| CASIA-A | - | |||
| Wang et al. [52] | Gabor features + 2D2PCA | SVM | CASIA-B | 93.52 |
| CASIA-C | - | |||
| Rida et al. [53] | Masked-GEI + PCA | MDA | CASIA-B | 85.21 |
| Rida [54] | Dynamic body parts | NN + CDA | CASIA-B | 88.75 |
| CASIA-B | 93.42 | |||
| Mogan et al. [55] | MHI + BSIF + HOG | Euclidean distance + Majority voting | OU-ISIR D | DBhigh: 96 DBlow: 100 |
| CMU MoBo | 76 | |||
| CASIA-B | 97.37 | |||
| Mogan et al. [56] | HTG | Euclidean distance + Majority voting | OU-ISIR D | DBhigh: 99 DBlow: 100 |
| CMU MoBo | 92 |
| Literature | Method | Dataset | Accuracy (%) |
|---|---|---|---|
| McLaughlin et al. [57] | CNN + RNN + Temporal pooling | iLIDS-VID | - |
| PRID-2011 | - | ||
| Varior et al. [58] | LOMO + CN | Market-1501 | 61.6 |
| CUHK03 | 57.3 | ||
| VIPeR | 42.4 | ||
| Motion Capture Data AMC302.0 | 92.60 | ||
| Li et al. [59] | Skeleton data | KINECTUNITO | 97.33 |
| Kinect Gait Biometry | - | ||
| CASIA-B | 96.0 | ||
| Zhang et al. [60] | Local + frame-level + weighted features | OU-ISIR LP | 99.3 |
| OUMVLP | 88.3 | ||
| Battistone & Petrosino [61] | Changes of shape and size in graph | CASIA-B | 87.8 |
| TUM-GAID | 98.4 | ||
| Tong et al. [62] | Spatial and temporal features | CASIA-B | - |
| Wang & Yan [63] | ff-GEI + CNN + LSTM | CASIA-B | 95.9 |
| OU-ISIR LP | 99.1 | ||
| Kinect Gait Biometry | 97.39 | ||
| Liu et al. [64] | SkeGEI features + DA features | SDU Gait | 88.11 |
| CIL Gait | 80.20 | ||
| Zhang et al. [16] | Pose features + canonical features + appearance features | CASIA-B | Nm: 92.3 Bg: 88.9 Cl: 62.3 |
| USF | 99.7 | ||
| FVG | 91.3 | ||
| Hasan & Mustafa [65] | 2D body joints + joints angular trajectories + temporal displacement + body-part length | CASIA-A | - |
| CASIA-B | Nm: 99.41 Bg: 97.80 Cl: 93.34 | ||
| Li et al. [67] | HMR + CNN / LSTM | CASIA-B | Nm: 97.9 Bg: 93.1 Cl: 77.6 |
| OU-MVLP | 95.8 | ||
| Wen & Wang [68] | ff-GEIs + CNN + RLSTM | CASIA-B | - |
| OU-ISIR LP | - |
| Literature | Method | Dataset | Accuracy (%) |
|---|---|---|---|
| Song et al. [69] | GaitNet | CASIA-B | 92.6 |
| Zhu et al. [71] | LFN (pre-processing included) | OU-LP | 98.04 |
| Su et al. [72] | CNN + Center-ranked loss | CASIA-B | Nm: 74.8 |
| OU-MVLP | 57.8 | ||
| Wen [73] | Gabor filter + CNN | CASIA-B | - |
| OU-LP | - | ||
| Fan et al. [74] | FPFE + HP + MCM | CASIA-B | Nm: 96.2 Bg: 91.5 Cl: 78.7 |
| OU-MVLP | 88.7 | ||
| Hou et al. [75] | GLN | CASIA-B | Nm: 96.88 Bg: 94.04 Cl: 77.50 |
| OU-MVLP | 89.18 | ||
| Ding et al. [77] | SCN | CASIA-B | Nm: 95.2 Bg: 89.8 Cl: 73.9 |
| OU-MVLP | 83.8 | ||
| Yoo & Park [80] | Skeleton-based disentangled network | CASIA-B | Nm: 85.4 Bg: 77.4 Cl: 71.1 |
| Jia et al. [81] | CNN + attention mechanism | CASIA-B | Nm: 92.48 Bg: 86.2 Cl: 68.74 |
| Shiraga et al. [82] | GEINet | OU-LP | - |
| Yeoh et al. [83] | CNN | OU-ISIR Treadmill B | 91.38 |
| Alotaibi & Mahmood [87] | Deep CNN | CASIA-B | - |
| Wu et al. [88] | FBW-CNN | CASIA-B | 37.9 |
| OU-LP | - | ||
| Khan et al. [89] | JIMEN + DN | OU-LP Bag | 88.1 |
| OUTD-B | 89.6 | ||
| TUM-GAID | 63.5 | ||
| Wu et al. [84] | LB & MT | CASIA-B | LB: 88.4 MT: 91.2 |
| OU-LP | 94.8 | ||
| Wang & Yan [92] | NLNN | CASIA-B | - |
| OU-LP | - | ||
| Balamurugan et al. [93] | Deep CNN | CASIA-B | - |
| Wu et al. [90] | FWCN | CASIA-B | Nm: 88.62 Bg: 73.8 CL: 61.1 |
| OU-LP | - | ||
| Xu [91] | CNN (PST + RN) | CASIA-B | 92.7 |
| OU-LP | 98.93 | ||
| OU-MVLP | 63.1 | ||
| Elharrouss et al. [94] | Angle estimation CNN + Gait recognition CNN | CASIA-B | 96.3 |
| OU-LP | - | ||
| OU-MVLP | - | ||
| Takemura et al. [85] | 3in (3 CNNs) + 2 diff (2 CNNs) | OU-LP | 98.8 |
| OU-MVLP | 52.7 | ||
| Tong et al. [86] | Triplet-based CNN | CASIA-B | - |
| Xu [95] | DLMNN | CASIA-B | 80.67 |
| OU-LP | - | ||
| Mogan et al. [96] | DenseNet-201 + MLP | CASIA-B | 100 |
| OU-ISIR D | DBlow: 100 | ||
| DBhigh: 100 | |||
| OU-LP | 99.17 | ||
| Wang et al. [97] | Multichannel CNN | CASIA-A | - |
| CASIA-B | - | ||
| OU-LP | - | ||
| Wang & Zhang [98] | TCNN + SVM | CASIA-B | - |
| OU-LP | - | ||
| Chao et al. [76] | GaitSet | CASIA-B | Nm: 96.1 Bg: 90.8 Cl: 70.3 |
| OU-MVLP | 87.9 | ||
| Liu & Liu [99] | TS-Net | CASIA-B | Nm: 68.4 Bg: 58.4 Cl: 41.9 |
| UCMP-GAIT | 92.22 | ||
| Chai et al. [100] | Backbone + HPP + HPM | CASIA-B | Nm: 95.6 Bg: 89.2 Cl: 73.4 |
| OU-MVLP | 89.9 | ||
| Wang & Yan [101] | GCF-CNN | CASIA-A | 65.64 |
| CASIA-B | 62.36 | ||
| OU-LP | 64.33 |
| Datasets | Number of Subjects | Variations |
|---|---|---|
| CASIA-B | 124 | Normal walking Clothing Carrying condition |
| OU-ISIR D | 185 | Steady walking Fluctuated walking |
| OU-LP | 4016 | 4 viewing angles |
| OU-MVLP | 10,307 | 14 viewing angles |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mogan, J.N.; Lee, C.P.; Lim, K.M. Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning. Sensors 2022, 22, 5682. https://doi.org/10.3390/s22155682
Mogan JN, Lee CP, Lim KM. Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning. Sensors. 2022; 22(15):5682. https://doi.org/10.3390/s22155682
Chicago/Turabian StyleMogan, Jashila Nair, Chin Poo Lee, and Kian Ming Lim. 2022. "Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning" Sensors 22, no. 15: 5682. https://doi.org/10.3390/s22155682
APA StyleMogan, J. N., Lee, C. P., & Lim, K. M. (2022). Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning. Sensors, 22(15), 5682. https://doi.org/10.3390/s22155682