
Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks


Abstract
:1. Introduction
- We evaluated our model by focusing on the challenge of the driver being at different distances from the camera. To understand better how this problem might reduce accuracy while making a classification and how to overcome it, we gathered data, implemented a model, analyzed the obtained results, and wrote a discussion.
- We propose applying a 3D convolution operation to extract spatial and temporal features from videos and overcome this problem. We evaluate and demonstrate the benefits of implementing it in driving situations where the driver has different distances from the camera.
- Since a per-frame-based recognition is often used inside gaze classifiers, we evaluate the proposed 3D CNN baseline model against a 2D CNN baseline model. The experimental results show that the proposed 3D model can outperform the 2D CNN model overall.
- We propose a model portable and extensible system since we used only one camera and no external sensors for acquiring the data.
- We propose a model that can correctly classify new distinct subjects.
2. Related Works
3. Methodology
- Frames caused by blurred images while using a per-frame recognition system.
- Situations where a driver has different distances from the camera.
3.1. Face Detector
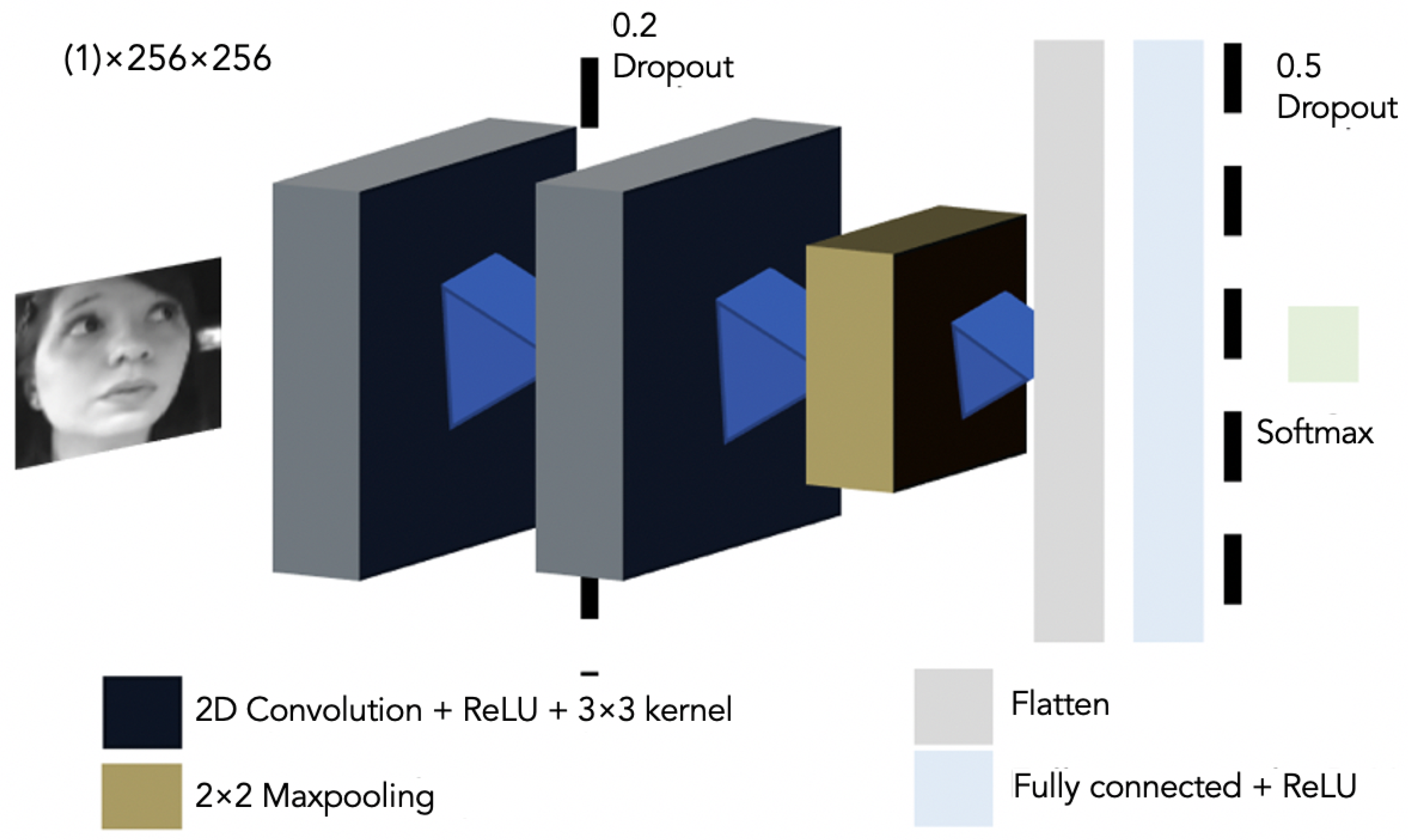
3.2. Two-Dimensional CNN Model
- 1st 2D convolutional layer, kernel with an activation function ReLU.
- Drop-out of 20% for preventing over-fitting [40].
- 2nd 2D convolutional layer kernel with an activation function ReLU.
- Max-pooling sub-sampling layer for removing spatial information by local dimensionality [41]. After the second convolution, we use a pooling layer to reduce the size of the next layer of neurons and prevail salient features.
- Flatten layer.
- Dense layer with a maximum norm weight constraint to reduce the probability of over-fitting.
- The domain of this research is very narrow; therefore, there is no need to use complex pre-trained networks.
- Fine-tuning a pre-trained network on a small dataset might lead to overfitting.
- Optimisation method: Stochastic gradient descent (SGD).
- Batch size: 32.
- Number of epochs: 200.
- Loss function: Categorical Crossentropy.
- Learning rate: 0.01.
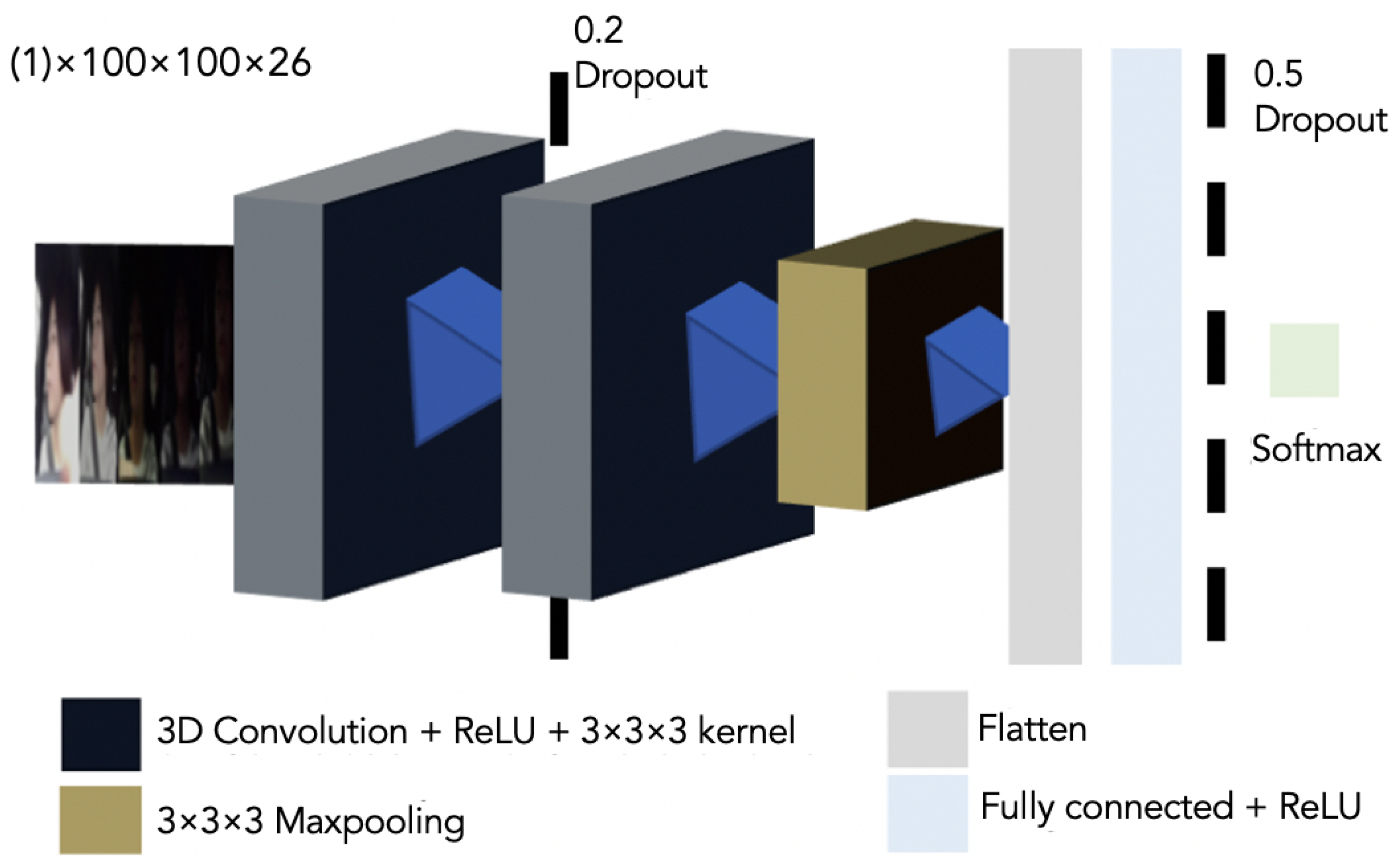
3.3. 3D CNN Model
3.4. Network Architecture
- 1st 3D Convolution Layer with ReLU activation and kernel.
- Dropout of 20%.
- 2nd 3D Convolution Layer with ReLU activation and kernel.
- A 3D Maxpooling.
- A flatten layer.
- A fully conected layer with ReLU activation.
- Optimization method: SGD.
- Batch size: 32.
- Number of epochs: 200.
- Loss function: Categorical Crossentropy.
- Learning rate: 0.01.
4. Experimental Evaluation and Results
4.1. Participants
- In the training dataset, the data of 4 females and 8 males were used.
- In the testing dataset, the data of 2 females and 4 males were used.
4.2. Dataset and Labeling
4.3. Evaluation Metrics
4.4. Experimental Setup
- For each label, there are videos with different face positions toward the camera.
- The experiment has three kinds of condition evaluation: face with near distance from the camera, face with middle distance from the camera, and face with far distance from the camera.
- Videos may have slight variations.
- Videos may have occasional occlusions.
- Eye direction is not evaluated for this experiment.
- For 2D CNN, the classification was made for the first frame of the video.
- For 3D CNN, the classification was made for the odd frames of a 26-frame sequence.
- There are no videos of the same drivers in the training and test datasets.
- To sustain our third statement in Section 1—a portable and extensible system—all the videos were captured inside a real car using a Logicool Web Camera c920r, manufacturer no. V-U0028, Tokyo, Japan (Logitech®, Newark, CA, USA).
4.5. Results and Discussion
- Videos with a far face distance from the camera results: Face with a far distance position from the camera—frequently used data in other approaches—2D CNN model and 3D CNN model has more or less same Recall. The results are shown in Figure 6.
- In the case of FF and LL labels, the 2D CNN outperforms 3D CNN. In normal situations, when the driver is facing the front, slight movements may fall into a misclassification for the 3D CNN.
- Two-dimensional CNN failed the classification several times when the frame was blurred.
- Mean Value for 2D CNN model was 74.96%, while for the 3D CNN model, it was 81.93%.
- Videos with faces positioned at a middle distance from the camera results: In this evaluation, the 3D CNN model outperformed 2D CNN in almost every case. The explanation for this is what was explained in Section 1.In real driving scenarios, the choice of features is highly problem-dependent since the same gaze staring situations may appear in different patterns. Instead, motion patterns seem to keep the relevant salient features independent of how near or far from the camera the driver is. The results are shown in Figure 7.
- In the 2D CNN model, the NN label has a low recall. With the 2D CNN model, the model produces multiple misclassifications with the label BB.
- In the 2D CNN model, the SS label was misclassified as label FF. Since the face fills a larger area when it is close to the camera, the SS and FF labels may contain more shared salient features.
- Mean value for 2D CNN model was 70.7%, while the 3D CNN model was 91.07%.
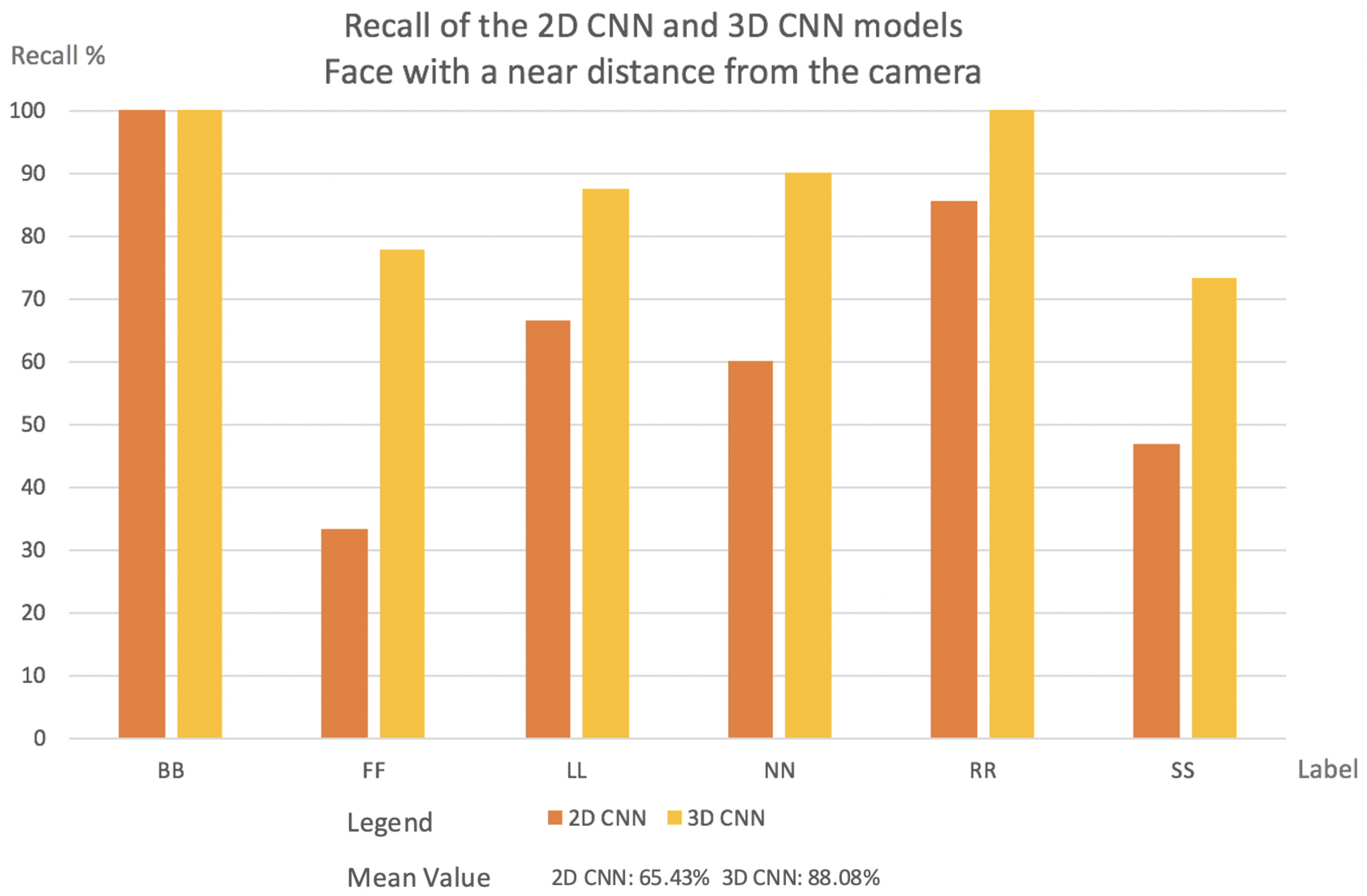
- Videos with a face positioned near the camera results: In all circumstances, the 3D CNN outperformed 2D CNN. This is due to the fact that the 3D CNN can manage temporal occlusions. The results are shown in Figure 8.
- The NN label in the 2D CNN model has a very low recall. The NN label is misclassified mostly with the labels SS, BB, and LL. That happens because, inside one frame at a near camera distance, the face in all these three labels has almost the same shape.
- FF had the lowest Recall value in the 2D CNN model. This comes from the deformations compared to a far-distance face position that may occur when the face is near the camera.
- Figure 9 indicates the cause of SS’s low Recall value. The bottom of the image can be reached during face detection, and the image’s bottom will be transformed into a thick black line.
- Mean value for 2D CNN model was 65.43%, while for the 3D CNN model, it was 88.08%.
- 3D CNN can handle better temporal occlusions.
- 2D CNN can handle light differences in the cases where the light is not occluding almost all of the face.
- 3D CNN can address very strong light differences if some frames inside the image sequence are not occluding the full face of the driver.
- 2D CNN cannot handle temporal occlusions well.
- One interesting point for us was that the mean of the near and middle distance to the camera for the 3D CNN model was higher than the far distance. We believe that this is due to more forceful facial movements, which create a distinct pattern.
5. Contribution to Intelligent Transportation Systems
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ashraf, I.; Hur, S.; Shafiq, M.; Park, Y. Catastrophic factors involved in road accidents: Underlying causes and descriptive analysis. PLoS ONE 2019, 14, e0223473. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramachandiran, V.M.; Babu, P.K.; Manikandan, R. Prediction of road accidents severity using various algorithms. Int. J. Pure Appl. Math. 2018, 119, 16663–16669. [Google Scholar]
- Kini, S. Road traffic accidents in India: Need for urgent attention and solutions to ensure road safety. Indian J. Forensic Med. Toxicol. 2019, 13, 144–148. [Google Scholar] [CrossRef]
- Hayashi, H.; Kamezaki, M.; Manawadu, U.E.; Kawano, T.; Ema, T.; Tomita, T.; Catherine, L.; Sugano, S. A Driver Situational Awareness Estimation System Based on Standard Glance Model for Unscheduled Takeover Situations. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 718–723. [Google Scholar]
- Hayashi, H.; Oka, N.; Kamezaki, M.; Sugano, S. Development of a Situational Awareness Estimation Model Considering Traffic Environment for Unscheduled Takeover Situations. Int. J. Intell. Transp. Res. 2020, 19, 167–181. [Google Scholar] [CrossRef]
- Manawadu, U.E.; Kawano, T.; Murata, S.; Kamezaki, M.; Muramatsu, J.; Sugano, S. Multiclass Classification of Driver Perceived Workload Using Long Short-Term Memory based Recurrent Neural Network. In Proceedings of the IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018; pp. 2009–2014. [Google Scholar]
- Hayashi, H.; Kamezaki, M.; Sugano, S. Toward Health-Related Accident Prevention: Symptom Detection and Intervention based on Driver Monitoring and Verbal Interaction. IEEE Open Intell. Transp. Syst. 2021, 2, 240–253. [Google Scholar] [CrossRef]
- Lollett, C.; Hayashi, H.; Kamezaki, M.; Sugano, S. A Robust Driver’s Gaze Zone Classification using a Single Camera for Self-occlusions and Non-aligned Head and Eyes Direction Driving Situations. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 4302–4308. [Google Scholar]
- Lollett, C.; Kamezaki, M.; Sugano, S. Towards a Driver’s Gaze Zone Classifier using a Single Camera Robust to Temporal and Permanent Face Occlusions. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021. [Google Scholar]
- Lollett, C.; Kamezaki, M.; Sugano, S. Driver’s Drowsiness Classifier using a Single Camera Robust to Mask-wearing Situations using an Eyelid, Face Contour and Chest Movement Feature Vector GRU-based Model. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022. [Google Scholar]
- Chen, M.; Hauptmann, A. Mosift: Recognizing Human Actions in Surveillance Videos. 2009. Available online: https://kilthub.cmu.edu/articles/journal_contribution/MoSIFT_Recognizing_Human_Actions_in_Surveillance_Videos/6607523 (accessed on 29 June 2022).
- Li, B. 3D Fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Tawari, A.; Chen, K.H.; Trivedi, M.M. Where is the driver looking: Analysis of head, eye and iris for robust gaze zone estimation. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 988–994. [Google Scholar]
- Fridman, L.; Toyoda, H.; Seaman, S.; Seppelt, B.; Angell, L.; Lee, J.; Mehler, B.; Reimer, B. What can be predicted from six seconds of driver glances? In Proceedings of the Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2805–2813. [Google Scholar]
- Fridman, L.; Lee, J.; Reimer, B.; Victor, T. ‘Owl’and ‘Lizard’: Patterns of head pose and eye pose in driver gaze classification. IET Comput. Vis. 2016, 10, 308–314. [Google Scholar] [CrossRef] [Green Version]
- Chuang, M.C.; Bala, R.; Bernal, E.A.; Paul, P.; Burry, A. Estimating gaze direction of vehicle drivers using a smartphone camera. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 165–170. [Google Scholar]
- Naqvi, A.; Arsalan, M.; Batchuluun, G.; Yoon, S.; Park, R. Deep Learning-Based Gaze Detection System for Automobile Drivers Using a NIR Camera Sensor. Sensors 2018, 18, 456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Martin, S.C. Vision based, Multi-cue Driver Models for Intelligent Vehicles. Ph.D. Dissertation, University of California, San Diego, CA, USA, 2016. [Google Scholar]
- Burgos-Artizzu, X.; Perona, P.; Doll’ar, P. Robust face landmark estimation under occlusion. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Tayibnapis, I.R.; Choi, M.K.; Kwon, S. Driver’s gaze zone estimation by transfer learning. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; pp. 1–5. [Google Scholar]
- Shan, X.; Wang, Z.; Liu, X.; Lin, M.; Zhao, L.; Wang, J.; Wang, G. Driver Gaze Region Estimation Based on Computer Vision. In Proceedings of the Measuring Technology and Mechatronics Automation (ICMTMA), Phuket, Thailand, 28–29 February 2020; pp. 357–360. [Google Scholar]
- Vora, S.; Rangesh, A.; Trivedi, M.M. Driver gaze zone estimation using convolutional neural networks: A general framework and ablative analysis. IEEE Trans. Intell. Transp. 2018, 3, 254–265. [Google Scholar] [CrossRef]
- Schwehr, J.; Willert, V. Driver’s gaze prediction in dynamic automotive scenes. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Guasconi, S.; Porta, M.; Resta, C.; Rottenbacher, C. A low-cost implementation of an eye tracking system for driver’s gaze analysis. In Proceedings of the 10th International Conference on Human System Interactions (HSI), Ulsan, Korea, 17–19 July 2017; pp. 264–269. [Google Scholar]
- Wang, Y.; Yuan, G.; Mi, Z.; Peng, J.; Ding, X.; Liang, Z.; Fu, X. Continuous driver’s gaze zone estimation using rgb-d camera. Sensors 2019, 19, 1287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Zhao, T.; Ding, X.; Bian, J.; Fu, X. Head pose-free eye gaze prediction for driver attention study. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 42–46. [Google Scholar]
- Jha, S.; Busso, C. Probabilistic Estimation of the Gaze Region of the Driver using Dense Classification. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 697–702. [Google Scholar]
- Yuen, K.; Martin, S.; Trivedi, M.M. Looking at faces in a vehicle: A deep CNN based approach and evaluation. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 649–654. [Google Scholar]
- Hu, T.; Jha, S.; Busso, C. Robust Driver Head Pose Estimation in Naturalistic Conditions from Point-Cloud Data. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1176–1182. [Google Scholar]
- Rangesh, A.; Zhang, B.; Trivedi, M. Driver Gaze Estimation in the Real World: Overcoming the Eyeglass Challenge. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1054–1059. [Google Scholar]
- Dari, S.; Kadrileev, N.; Hüllermeier, E. A Neural Network-Based Driver Gaze Classification System with Vehicle Signals. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Ruiz, N.; Chong, E.; Rehg, J.M. Fine-grained head pose estimation without keypoints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2074–2083. [Google Scholar]
- Yu, J.; Park, S.; Lee, S.; Jeon, M. Driver drowsiness detection using condition-adaptive representation learning framework. IEEE Trans. Intell. Transp. Syst. 2018, 20, 4206–4218. [Google Scholar] [CrossRef] [Green Version]
- Huynh, X.P.; Park, S.M.; Kim, Y.G. Detection of driver drowsiness using 3D deep neural network and semi-supervised gradient boosting machine. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Wilson, P.I.; Fernandez, J. Facial feature detection using Haar classifiers. J. Comput. Sci. Coll. 2006, 21, 127–133. [Google Scholar]
- Déniz, O.; Bueno, G.; Salido, J.; la Torre, F.D. Face recognition using histograms of oriented gradients. Pattern Recognit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Minaee, S.; Luo, P.; Lin, Z.; Bowyer, K. Going Deeper Into Face Detection: A Survey. arXiv 2021, arXiv:2103.14983. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale-invariant face detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learningspatiotemporal features with 3d convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Khan, M.Q.; Lee, S. A comprehensive survey of driving monitoring and assistance systems. Sensors 2019, 19, 2574. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Movement | Label | Movement |
|---|---|---|---|
| BB | Stare at the back mirror | FF | Stare to front |
| LL | Stare at the left window | RR | Stare at right window |
| NN | Stare at the navigator | SS | Stare at speed meter |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lollett, C.; Kamezaki, M.; Sugano, S. Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors 2022, 22, 5857. https://doi.org/10.3390/s22155857
Lollett C, Kamezaki M, Sugano S. Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors. 2022; 22(15):5857. https://doi.org/10.3390/s22155857
Chicago/Turabian StyleLollett, Catherine, Mitsuhiro Kamezaki, and Shigeki Sugano. 2022. "Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks" Sensors 22, no. 15: 5857. https://doi.org/10.3390/s22155857
APA StyleLollett, C., Kamezaki, M., & Sugano, S. (2022). Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors, 22(15), 5857. https://doi.org/10.3390/s22155857