
Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligence in Internet of Things: State-of-the-Art and Future Directions




Abstract
:1. Introduction
2. Federated Learning in IoT
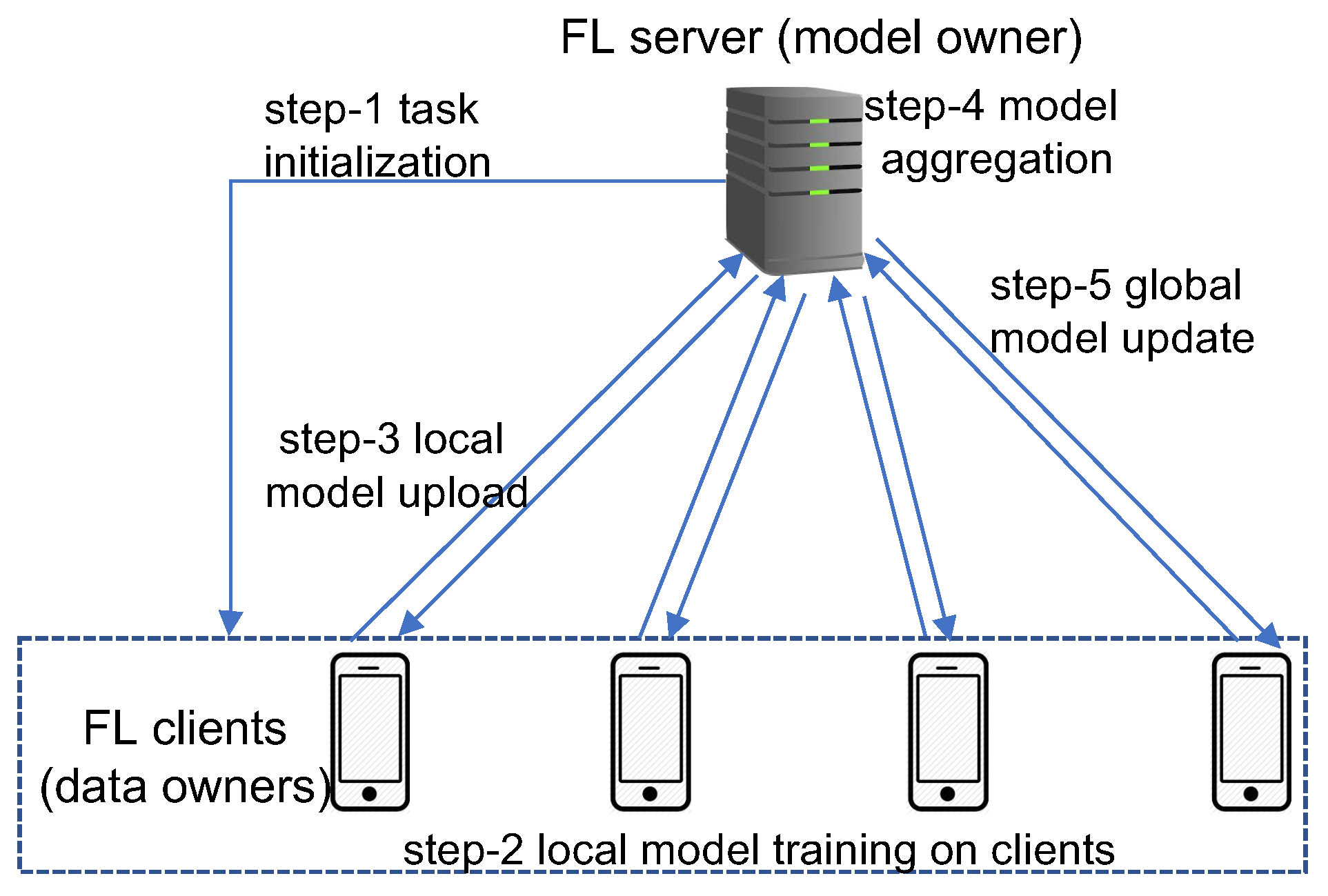
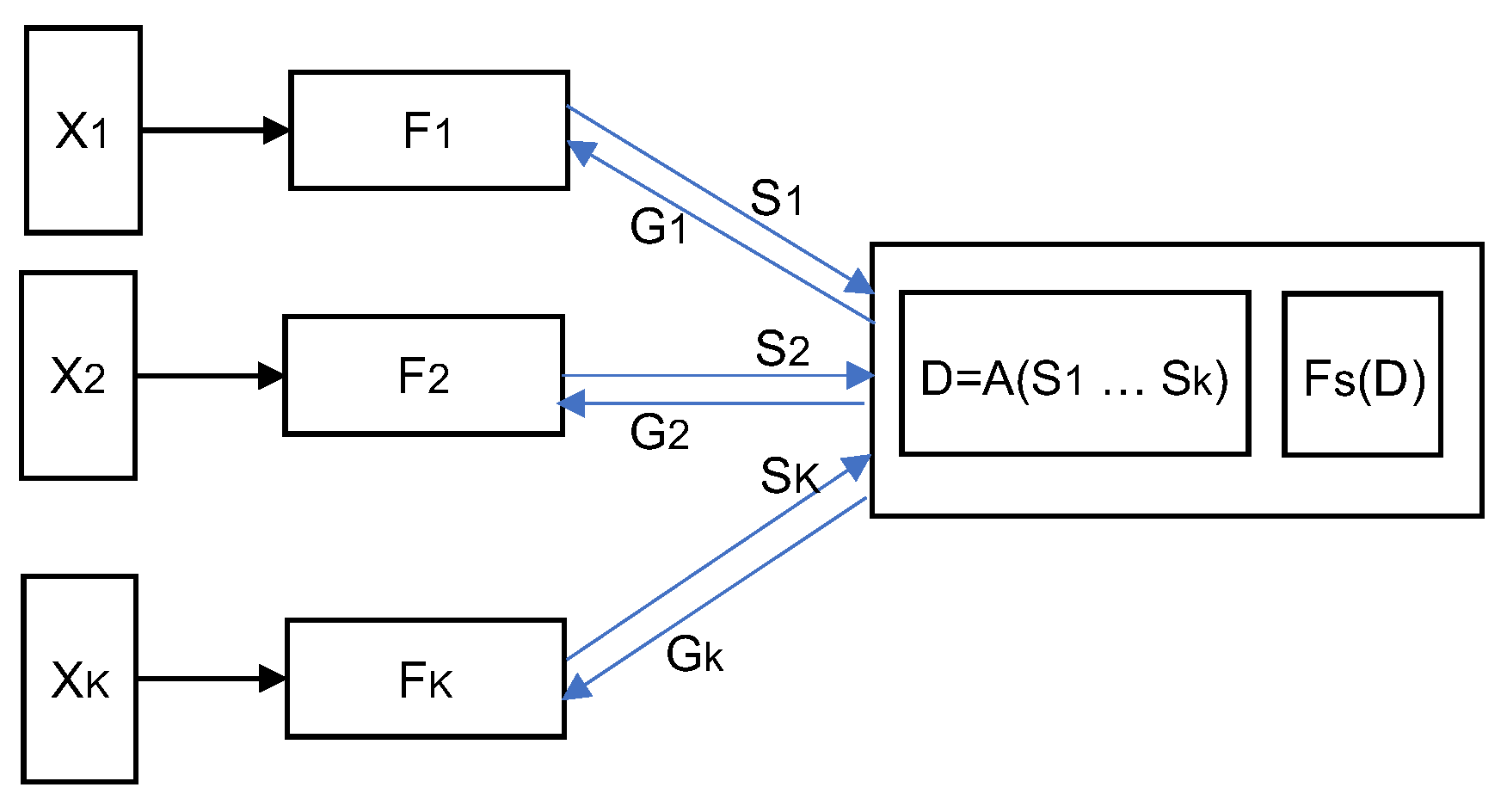
2.1. Introduction to Federated Learning
| Algorithm 1 FedAvg |
| Require: The K clients are indexed by k; B is the local minibatch size, E is the number of local epochs, and is the learning rate.
|
2.2. Challenges to Federated Learning in Edge-Based IoT
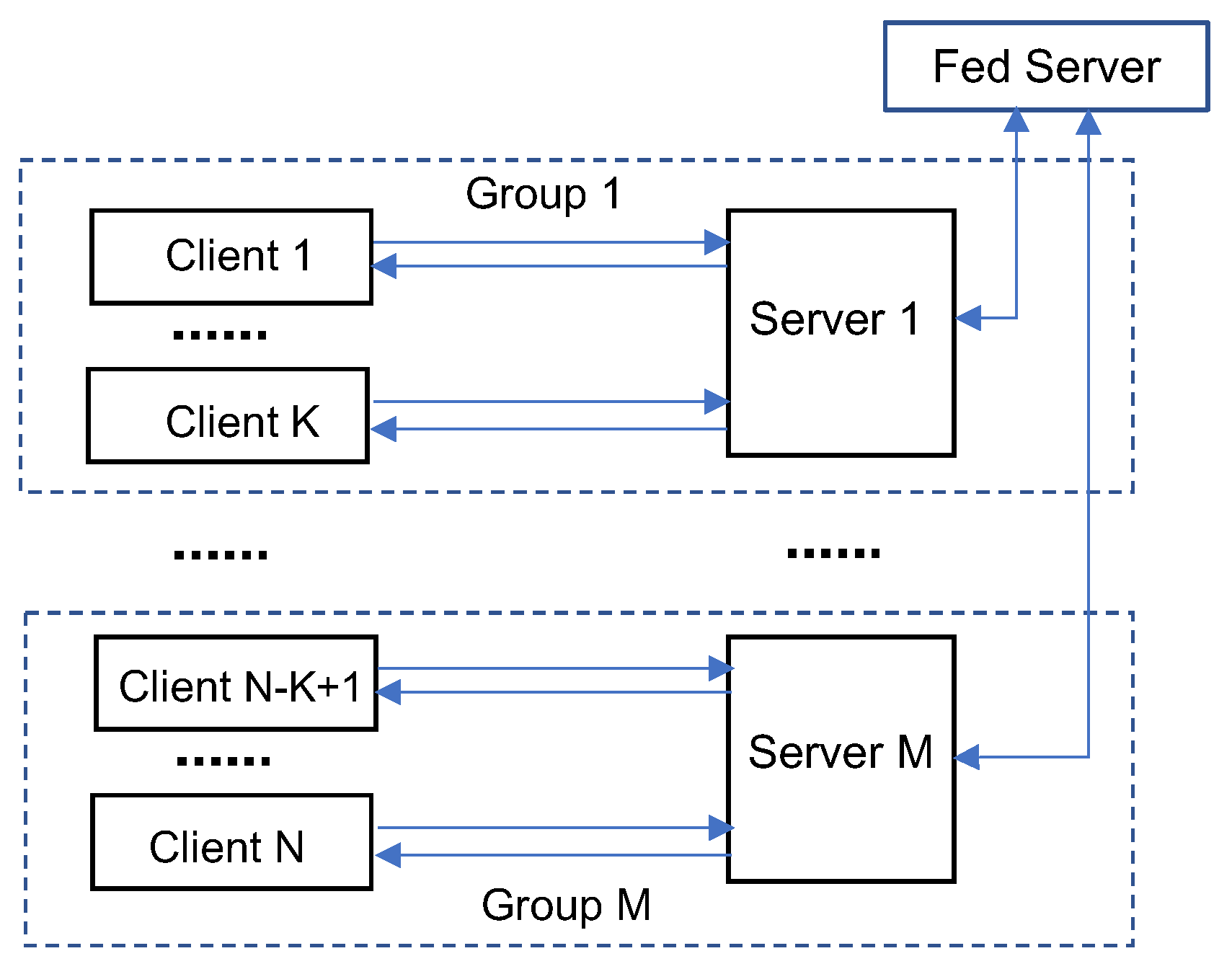
2.3. Enabling Federated Learning in IoT
2.3.1. Enhancing FL Algorithms and Model Aggregation
2.3.2. Client Selection in FL
2.3.3. Communication Efficient FL
2.3.4. Privacy and Security Protection in FL
3. Split Learning in IoT
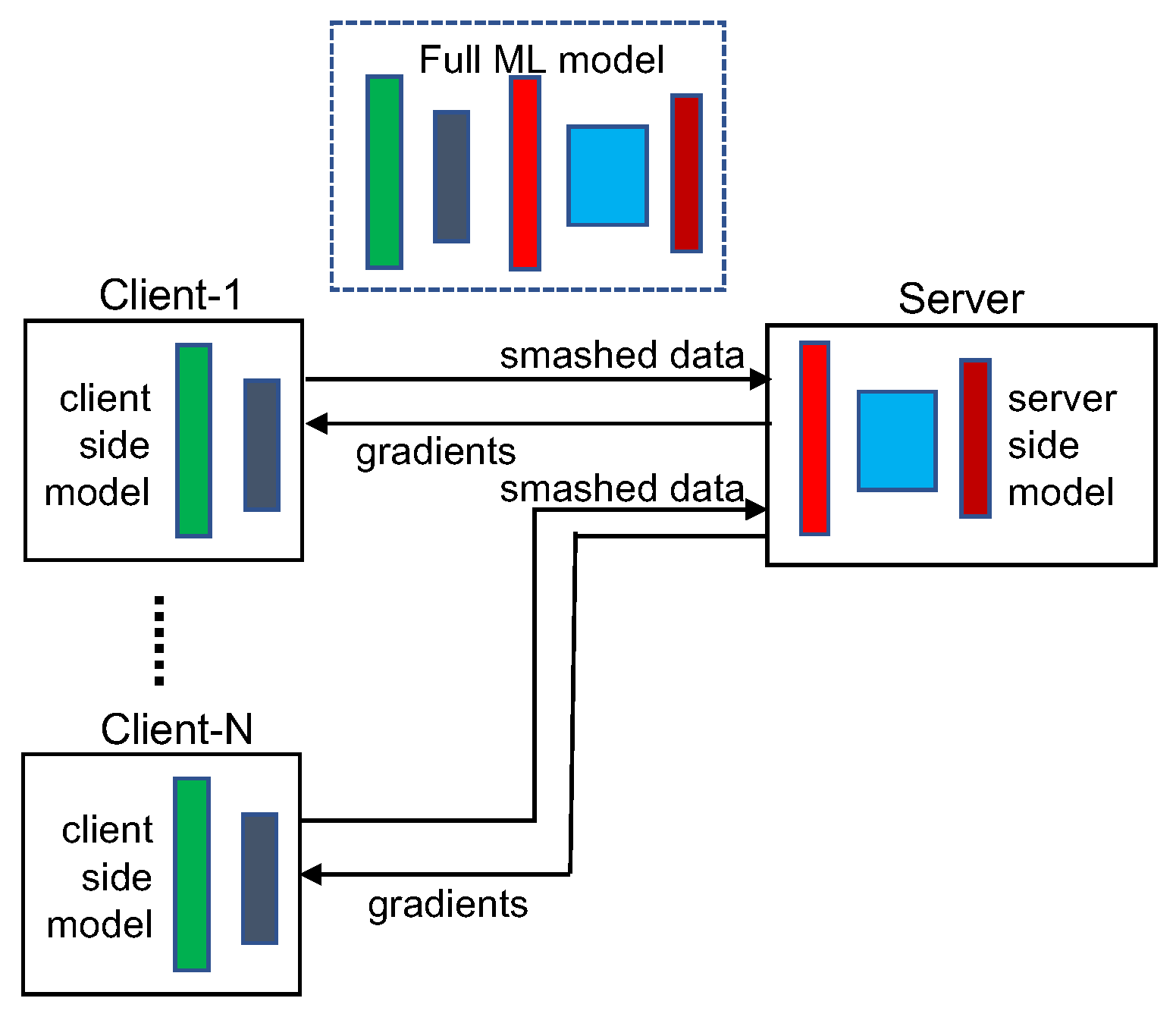
3.1. Split Learning Framework Architecture
3.2. Split Learning Performance
3.3. Enhancing Split Learning in IoT
4. Combing Split Learning and Federated Learning
4.1. Hybrid Frameworks for Combining Split Learning with Federated Learning
4.2. Model Decomposition in Hybrid SL-FL Frameworks
4.3. Reducing Overheads of Hybrid SL-FL Frameworks
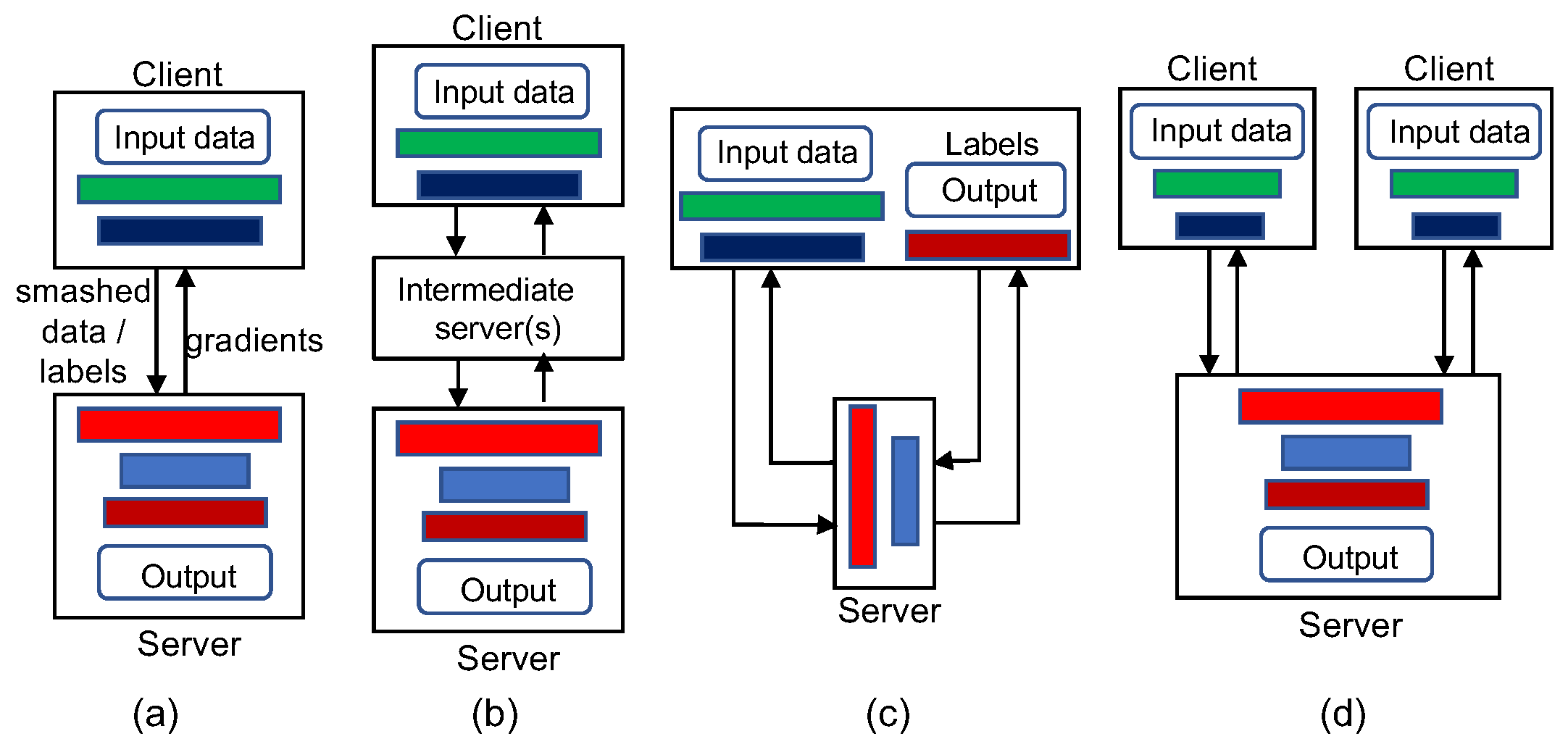
4.4. Hybrid SL-FL Frameworks with Vertical and Sequential Configurations
5. Privacy Protection in Split Learning
5.1. Privacy Attacks on Split Learning
5.1.1. Training Data Inference
5.1.2. Client Model Inversion
5.1.3. Private Label Leakage
5.2. Privacy Protection in Split Learning
5.2.1. Techniques for Protecting SL against Data Inference and Model Inversion
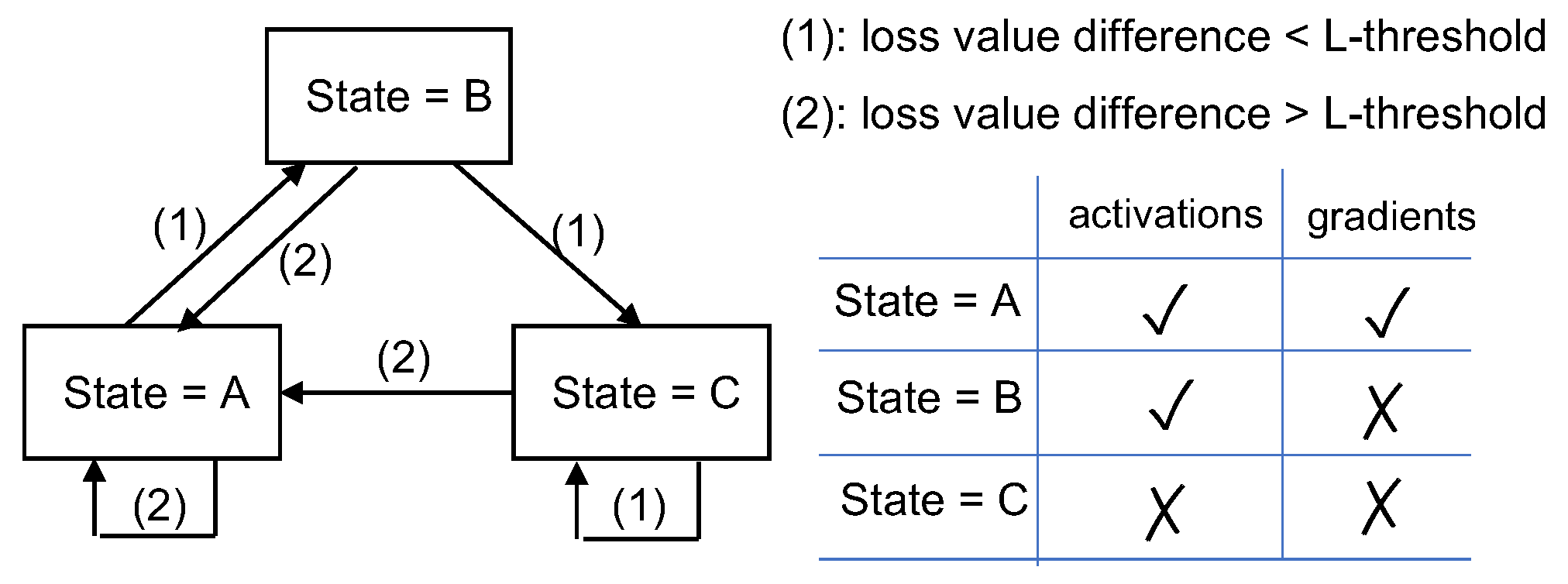
5.2.2. Mechanisms for Protecting SL against Label Leakage
6. Directions for Future Research
6.1. Model Decomposition and Deployment for Hybrid SL-FL
6.2. Cross-Layer Resource Management for Hybrid SL-FL
6.3. Communication Efficient Hybrid SL-FL
6.4. Alternative Architecture for Hybrid SL-FL Frameworks
6.5. Performance Evaluation of Hybrid SL-FL in Edge-Based IoT
6.6. Privacy and Security of Hybrid SL-FL
6.7. Combining SL and FL with Vertical and Sequential Configurations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ali, O.; Ishak, M.K.; Bhatti, M.K.L.; Khan, I.; Kim, K.I. A Comprehensive Review of Internet of Things: Technology Stack, Middlewares, and Fog/Edge Computing Interface. Sensors 2022, 22, 995. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Gupta, O.; Raskar, R. Distributed Learning of Deep Neural Network over Multiple Agents. J. Netw. Comput. Appl. 2018, 116, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Xia, Q.; Ye, W.; Tao, Z.; Wu, J.; Li, Q. A Survey of Federated Learning for Edge Computing: Research Problems and Solutions. High-Confid. Comput. 2021, 1, 100008. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Wang, C.; Paik, H.Y.; Zhu, L. A Systematic Literature Review on Federated Machine Learning: From a Software Engineering Perspective. ACM Comput. Surv. (CSUR) 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Thapa, C.; Chamikara, M.A.P.; Camtepe, S.A. Advancements of federated learning towards privacy preservation: From federated learning to split learning. In Federated Learning Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 79–109. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Zhang, X.; Li, L.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. A communication efficient collaborative learning framework for distributed features. arXiv 2019, arXiv:1912.11187. [Google Scholar]
- Hu, Y.; Niu, D.; Yang, J.; Zhou, S. FDML: A collaborative machine learning framework for distributed features. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2232–2240. [Google Scholar]
- Chen, T.; Jin, X.; Sun, Y.; Yin, W. VAFL: A method of vertical asynchronous federated learning. arXiv 2020, arXiv:2007.06081. [Google Scholar]
- Li, T.; Anit, K.S.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the 3rd Machine Learning and Systems Conference, Austin, TX, USA, 2–4 March 2020. [Google Scholar]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. arXiv 2020, arXiv:1905.10497. [Google Scholar]
- Caldas, S.; Smith, V.; Talwalkar, A. Federated kernelized multi-task learning. In Proceedings of the 1st Conference on Machine Learning and Systems, Macau, China, 26–28 February 2018; pp. 1–3. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous Federated Optimization. arXiv 2020, arXiv:1903.03934. [Google Scholar]
- Nguyen, J.; Malik, K.; Zhan, H.; Yousefpour, A.; Rabbat, M.; Malek, M.; Huba, D. Federated Learning with Buffered Asynchronous Aggregation. arXiv 2021, arXiv:12106.06639v2. [Google Scholar]
- Liua, J.; Xu, H.; Xu, Y.; Ma, Z.; Wang, Z.; Qian, C.; Huang, H. Communication-efficient asynchronous federated learning in resource-constrained edge computing. Comput. Netw. 2021, 199, 108429. [Google Scholar] [CrossRef]
- Stripelis, D.; Ambit, J.L. Semi-synchronous federated learning. arXiv 2021, arXiv:2102.02849v1. [Google Scholar]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the 2019 IEEE International Conference on Communications (ICC 2019), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Zhang, H.; Xie, Z.; Zarei, R.; Wu, T.; Chen, K. Adaptive Client Selection in Resource Constrained Federated Learning Systems: A Deep Reinforcement Learning Approach. IEEE Access 2021, 9, 98423–98432. [Google Scholar] [CrossRef]
- Cho, Y.J.; Wang, J.; Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Zhang, W.; Wang, X.; Zhou, P.; Wu, W.; Zhang, X. Client Selection for Federated Learning With Non-IID Data in Mobile Edge Computing. IEEE Access 2021, 9, 24462–24474. [Google Scholar] [CrossRef]
- Balakrishnan, R.; Akdeniz, M.; Dhakal, S.; Anand, A.; Zeira, A.; Himayat, N. Resource Management and Model Personalization for Federated Learning over Wireless Edge Networks. J. Sens. Actuator Netw. 2021, 10, 17. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A Joint Learning and Communications Framework for Federated Learning over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 269–283. [Google Scholar] [CrossRef]
- Yao, X.; Huang, C.; Sun, L. Two-stream federated learning: Reduce the communication costs. In Proceedings of the 2018 IEEE Visual Communications and Image Processing, Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Luping, W.; Wei, W.; Bo, L. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the 39th IEEE International Conference on Distributed Computing Systems (ICDCS 2019), Dallas, TX, USA, 7–9 July 2019; pp. 954–964. [Google Scholar]
- Li, L.; Shi, D.; Hou, R.; Li, H.; Pan, M.; Han, Z. To Talk or to Work: Flexible Communication Compression for Energy Efficient Federated Learning over Heterogeneous Mobile Edge Devices. In Proceedings of the 2021 IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar]
- Agarwal, N.; Suresh, A.T.; Yu, F.; Kumar, S.; Mcmahan, H.B. cpSGD: Communication-efficient and differentially-private distributed SGD. arXiv 2018, arXiv:1805.10559. [Google Scholar]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 26–28 August 2020; pp. 2021–2031. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3400–3413. [Google Scholar] [CrossRef] [Green Version]
- Han, P.; Wang, S.; Leung, K.K. Adaptive Gradient Sparsification for Efficient Federated Learning: An Online Learning Approach. In Proceedings of the 40th IEEE International Conference on Distributed Computing Systems (ICDCS 2020), Singapore, 29 November–1 December 2020. [Google Scholar]
- Tao, Z.; Li, Q. eSGD: Communication efficient distributed deep learning on the edge. In Proceedings of the 2018 USENIX Workshop on Hot Topics in Edge Computing (HotEdge 18), Boston, MA, USA, 10 July 2018. [Google Scholar]
- Caldas, S.; Konečny, J.; McMahan, H.B.; Talwalkar, A. Expanding the reach of federated learning by reducing client resource requirements. arXiv 2018, arXiv:1812.07210. [Google Scholar]
- Malhotra, P.; Singh, Y.; Anand, P.; Bangotra, D.K.; Singh, P.K.; Hong, W.C. Internet of things: Evolution, concerns and security challenges. Sensors 2021, 21, 1809. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef] [Green Version]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, C.; Liu, Y.; Wang, L.; Liu, Y.; Li, L.; Zheng, N. Joint intelligence ranking by federated multiplicative update. IEEE Intell. Syst. 2020, 35, 15–24. [Google Scholar] [CrossRef]
- Chamikara, M.A.P.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy preserving distributed machine learning with federated learning. Comput. Commun. 2021, 171, 112–125. [Google Scholar] [CrossRef]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Hardy, S.; Henecka, W.; Ivey-Law, H.; Nock, R.; Patrini, G.; Smith, G.; Thorne, B. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv 2017, arXiv:1711.10677. [Google Scholar]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Muñoz-González, L.; Co, K.T.; Lupu, E.C. Byzantine-robust federated machine learning through adaptive model averaging. arXiv 2019, arXiv:1909.05125. [Google Scholar]
- Li, S.; Cheng, Y.; Liu, Y.; Wang, W.; Chen, T. Abnormal client behavior detection in federated learning. In Proceedings of the 2nd International Workshop on Federated Learning for Data Privacy and Confidentiality (FL-NeurIPS 19), Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Zhao, L.; Hu, S.; Wang, Q.; Jiang, J.; Shen, C.; Luo, X.; Hu, P. Shielding Collaborative Learning: Mitigating Poisoning Attacks Through Client-Side Detection. IEEE Trans. Dependable Secur. Comput. 2021, 18, 2029–2041. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Jia, J.; Gong, N.Z. Provably Secure Federated Learning against Malicious Clients. In Proceedings of the 2021 AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 6885–6893. [Google Scholar]
- Xie, C.; Chen, M.; Chen, P.Y.; Li, B. CRFL: Certifiably Robust Federated Learning against Backdoor Attacks. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021), Online, 18–24 July 2021. [Google Scholar]
- Gao, Y.; Kim, M.; Abuadbba, S.; Kim, Y.; Thapa, C.; Kim, K.; Camtepe, S.A.; Kim, H.; Nepal, S. End-to-end evaluation of federated learning and split learning for Internet of Things. arXiv 2020, arXiv:2003.13376. [Google Scholar]
- Singh, A.; Vepakomma, P.; Gupta, O.; Raskar, R. Detailed Comparison of Communication Efficiency of Split Learning and Federated Learning. arXiv 2019, arXiv:1909.09145. [Google Scholar]
- Ceballos, I.; Sharma, V.; Mugica, E.; Singh, A.; Roman, A.; Vepakomma, P.; Raskar, R. SplitNN-driven vertical partitioning. arXiv 2020, arXiv:2008.04137. [Google Scholar]
- Abuadbba, S.; Kim, K.; Kim, M.; Thapa, C.; Camtepe, S.A.; Gao, Y.; Kim, H.; Nepal, S. Can We Use Split Learning on 1D CNN Models for Privacy Preserving Training? In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020; pp. 305–318. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2015, 63, 664–675. [Google Scholar] [CrossRef]
- Li, D.; Zhang, J.; Zhang, Q.; Wei, X. Classification of ECG signals based on 1D convolution neural network. In Proceedings of the 19th IEEE International Conference on e-Health Networking, Applications and Services (Healthcom 2017), Dalian, China, 12–15 October 2017; pp. 1–6. [Google Scholar]
- Chen, X.; Li, J.; Chakrabarti, C. Communication and Computation Reduction for Split Learning using Asynchronous Training. In Proceedings of the 2021 IEEE Workshop on Signal Processing Systems, Coimbra, Portugal, 19–21 October 2021; pp. 76–81. [Google Scholar]
- Chopra, A.; Sahu, S.K.; Singh, A.; Java, A.; Vepakomma, P.; Sharma, V.; Raskar, R. AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning. arXiv 2021, arXiv:2112.01637. [Google Scholar]
- Auer, P. Using confidence bounds for exploitation-exploration trade-offs. J. Mach. Learn. Res. 2002, 3, 397–422. [Google Scholar]
- Neyshabur, B.; Li, Z.; Bhojanapalli, S.; LeCun, Y.; Srebro, N. Towards understanding the role of over-parametrization in generalization of neural networks. arXiv 2018, arXiv:1805.12076. [Google Scholar]
- Golkar, S.; Kagan, M.; Cho, K. Continual learning via neural pruning. arXiv 2019, arXiv:1903.04476. [Google Scholar]
- Jeon, J.; Kim, J. Privacy-Sensitive Parallel Split Learning. In Proceedings of the 2020 IEEE International Conference on Information Networking, Barcelona, Spain, 7–10 January 2020; pp. 7–9. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thapa, C.; Chamikara, M.A.P.; Camtepe, S.; Sun, L. SplitFed: When federated learning meets split learning. arXiv 2021, arXiv:2004.12088. [Google Scholar] [CrossRef]
- Gawali, M.; Arvind, C.; Suryavanshi, S.; Madaan, H.; Gaikwad, A.; Bhanu Prakash, K.; Kulkarni, V.; Pant, A. Comparison of Privacy-Preserving Distributed Deep Learning Methods in Healthcare. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis, Oxford, UK, 12–14 July 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 457–471. [Google Scholar]
- Wu, W.; Li, M.; Qu, K.; Zhou, C.; Zhuang, W.; Li, X.; Shi, W. Split Learning over Wireless Networks: Parallel Design and Resource Management. arXiv 2022, arXiv:2204.08119. [Google Scholar]
- Liu, X.; Deng, Y.; Mahmoodi, T. Energy Efficient User Scheduling for Hybrid Split and Federated Learning in Wireless UAV Networks. In Proceedings of the 2022 IEEE International Conference on Communications, Seoul, Korea, 16–20 May 2022. [Google Scholar]
- Turina, V.; Zhang, Z.; Esposito, F.; Matta, I. Combining Split and Federated Architectures for Efficiency and Privacy in deep learning. In Proceedings of the 16th International Conference on Emerging Networking Experiments and Technologies, Barcelona, Spain, 1–4 December 2020; pp. 562–563. [Google Scholar]
- Turina, V.; Zhang, Z.; Esposito, F.; Matta, I. Federated or Split? A Performance and Privacy Analysis of Hybrid Split and Federated Learning Architectures. In Proceedings of the 14th IEEE International Conference on Cloud Computing, Chicago, IL, USA, 5–10 September 2021; pp. 250–260. [Google Scholar]
- Gao, Y.; Kim, M.; Thapa, C.; Abuadbba, S.; Zhang, Z.; Camtepe, S.; Kim, H.; Nepal, S. Evaluation and Optimization of Distributed Machine Learning Techniques for Internet of Things. IEEE Trans. Comput. 2021. [Google Scholar] [CrossRef]
- Park, S.; Kim, G.; Kim, J.; Kim, B.; Ye, J.C. Federated split task-agnostic vision transformer for COVID-19 CXR diagnosis. Adv. Neural Inf. Process. Syst. 2021, 34, 24617–24630. [Google Scholar]
- Tian, Y.; Wan, Y.; Lyu, L.; Yao, D.; Jin, H.; Sun, L. FedBERT: When Federated Learning Meets Pre-Training. ACM Trans. Intell. Syst. Technol. 2022. [Google Scholar] [CrossRef]
- Wu, D.; Ullah, R.; Harvey, P.; Kilpatrick, P.; Spence, I.; Varghese, B. FedAdapt: Adaptive offloading for IoT devices in federated learning. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Joshi, P.; Thapa, C.; Camtepe, S.; Hasanuzzamana, M.; Scully, T.; Afli, H. SplitFed learning without client-side synchronization: Analyzing client-side split network portion size to overall performance. arXiv 2021, arXiv:2109.09246. [Google Scholar]
- Han, D.J.; Bhatti, H.I.; Lee, J.; Moon, J. Accelerating Federated Learning with Split Learning on Locally Generated Losses. In Proceedings of the 2021 ICML Workshop on Federated Learning for User Privacy and Data Confidentiality, Shanghai, China, 24 July 2021. [Google Scholar]
- Wang, J.; Qi, H.; Rawat, A.S.; Reddi, S.; Waghmare, S.; Yu, F.X.; Joshi, G. FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients. arXiv 2022, arXiv:2201.11865. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Pham, N.D.; Abuadbba, A.; Gao, Y.; Phan, T.K.; Chilamkurti, N. Binarizing Split Learning for Data Privacy Enhancement and Computation Reduction. arXiv 2022, arXiv:2206.04864. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Oh, S.; Park, J.; Vepakomma, P.; Baek, S.; Raskar, R.; Bennis, M.; Kim, S.L. LocFedMix-SL: Localize, Federate, and Mix for Improved Scalability, Convergence, and Latency in Split Learning. In Proceedings of the 2022 ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 3347–3357. [Google Scholar]
- Pal, S.; Uniyal, M.; Park, J.; Vepakomma, P.; Raskar, R.; Bennis, M.; Jeon, M.; Choi, J. Server-Side Local Gradient Averaging and Learning Rate Acceleration for Scalable Split Learning. arXiv 2021, arXiv:2112.05929. [Google Scholar]
- Huang, Y.; Evans, D.; Katz, J. Private set intersection: Are garbled circuits better than custom protocols? In Proceedings of the 19th Network and Distributed Security Symposium, San Diego, CA, USA, 5–8 February 2012. [Google Scholar]
- Romanini, D.; Hall, A.J.; Papadopoulos, P.; Titcombe, T.; Ismail, A.; Cebere, T.; Sandmann, R.; Roehm, R.; Hoeh, M.A. PyVertical: A Vertical Federated Learning Framework for Multi-headed SplitNN. arXiv 2021, arXiv:2104.00489. [Google Scholar]
- Angelou, N.; Benaissa, A.; Cebere, B.; Clark, W.; Hall, A.J.; Hoeh, M.A.; Liu, D.; Papadopoulos, P.; Roehm, R.; Sandmann, R.; et al. Asymmetric private set intersection with applications to contact tracing and private vertical federated machine learning. arXiv 2020, arXiv:2011.09350. [Google Scholar]
- Mugunthan, V.; Goyal, P.; Kagal, L. Multi-VFL: A vertical federated learning system for multiple data and label owners. arXiv 2021, arXiv:2106.05468. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečnỳ, J.; Kumar, S.; McMahan, H.B. Adaptive federated optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Abedi, A.; Khan, S.S. FedSL: Federated Split Learning on Distributed Sequential Data in Recurrent Neural Networks. arXiv 2021, arXiv:2011.03180. [Google Scholar]
- Jiang, L.; Wang, Y.; Zheng, W.; Jin, C.; Li, Z.; Teo, S.G. LSTMSPLIT: Effective Split Learning based LSTM on Sequential Time-Series Data. arXiv 2022, arXiv:2203.04305. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Pasquini, D.; Ateniese, G.; Bernaschi, M. Unleashing the tiger: Inference attacks on split learning. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 November 2021; pp. 2113–2129. [Google Scholar]
- Gawron, G.; Stubbings, P. Feature Space Hijacking Attacks against Differentially Private Split Learning. arXiv 2022, arXiv:2201.04018. [Google Scholar]
- Huang, X.; Wu, L.; Ye, Y. A review on dimensionality reduction techniques. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1950017. [Google Scholar] [CrossRef]
- Erdogan, E.; Kupcu, A.; Cicek, A.E. UnSplit: Data-Oblivious Model Inversion, Model Stealing, and Label Inference Attacks against Split Learning. arXiv 2021, arXiv:2108.09033. [Google Scholar]
- Li, O.; Sun, J.; Yang, X.; Gao, W.; Zhang, H.; Xie, J.; Smith, V.; Wang, C. Label Leakage and Protection in Two-Party Split Learning. arXiv 2021, arXiv:2102.08504. [Google Scholar]
- Kariyappa, S.; Qureshi, M.K. Gradient Inversion Attack: Leaking Private Labels in Two-Party Split Learning. arXiv 2021, arXiv:2112.01299. [Google Scholar]
- Liu, J.; Lyu, X. Clustering Label Inference Attack against Practical Split Learning. arXiv 2022, arXiv:2203.05222. [Google Scholar]
- Vepakomma, P.; Singh, A.; Gupta, O.; Raskar, R. NoPeek: Information leakage reduction to share activations in distributed deep learning. In Proceedings of the 2020 IEEE International Conference on Data Mining Workshops, Sorrento, Italy, 17–20 November 2020; pp. 933–942. [Google Scholar]
- Titcombe, T.; Hall, A.J.; Papadopoulos, P.; Romanini, D. Practical Defenses against Model Inversion Attacks for Split Neural Networks. arXiv 2021, arXiv:2104.05743. [Google Scholar]
- Li, J.; Rakin, A.S.; Chen, X.; He, Z.; Fan, D.; Chakrabarti, C. ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Waikoloa, HI, USA, 4–8 January 2022; pp. 10194–10202. [Google Scholar]
- Erdogan, E.; Kupcu, A.; Cicek, A.E. SplitGuard: Detecting and Mitigating Training-Hijacking Attacks in Split Learning. arXiv 2021, arXiv:2108.09052. [Google Scholar]
- Yang, X.; Sun, J.; Yao, Y.; Xie, J.; Wang, C. Differentially Private Label Protection in Split Learning. arXiv 2022, arXiv:2203.02073. [Google Scholar]
- Xiao, D.; Yang, C.; Wu, W. Mixing Activations and Labels in Distributed Training for Split Learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 3165–3177. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Uchiyama, H.; Matsuda, H. HiveMind: Towards cellular native machine learning model splitting. IEEE J. Sel. Areas Commun. 2022, 40, 626–640. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Optimal Model Placement and Online Model Splitting for Device-Edge Co-Inference. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Duan, Q.; Wang, S.; Ansari, N. Convergence of networking and cloud/edge computing: Status, challenges, and opportunities. IEEE Netw. 2020, 34, 148–155. [Google Scholar] [CrossRef]
- Hegedűs, I.; Danner, G.; Jelasity, M. Gossip learning as a decentralized alternative to federated learning. In Proceedings of the 2019 IFIP International Conference on Distributed Applications and Interoperable Systems, Kongens Lyngby, Denmark, 17–21 June 2019; pp. 74–90. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pham, Q.V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated Learning Meets Blockchain in Edge Computing: Opportunities and Challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, X.; Yang, F.; Zhang, T.; Gan, Y.; Xiang, T.; Liu, Y. Robust and Privacy-Preserving Collaborative Learning: A Comprehensive Survey. arXiv 2021, arXiv:2112.10183. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Challenges | Brief Descriptions |
|---|---|
| Statistical Heterogeneity | imbalanced and non-iid data distributions |
| System Heterogeneity | heterogeneous implementations with diverse system capabilities |
| Communication Overheads | data transmissions for exchanging models |
| Constrained Resources | resource-constrained IoT devices |
| System Scalability | a large number of IoT devices involved in FL |
| System Dynamism | time-varying resource availability in IoT |
| Privacy & Security | privacy/security vulnerabilities of FL in IoT |
| FL Algorithms | Model Aggregation | Client Selection | Communication Control | Privacy/Security Protection | |
|---|---|---|---|---|---|
| Data Heterogeneity | + | + | + | ||
| System Heterogeneity | + | + | + | ||
| Communication Overheads | + | ||||
| Constrained Resources | + | + | |||
| System Scalability | + | + | |||
| System Dynamism | + | + | |||
| Privacy & Security | + |
| Methods | Communication Cost per Client | Total Communication Cost |
|---|---|---|
| SL with synchronization | ||
| SL without synchronization | ||
| Federated learning |
| SL-FL Frameworks | Federated Parallel Training | Server Deployment |
|---|---|---|
| SplitFed [64] | on both client and server | centralized on a single server |
| SplitFedv2 [64] | only on client | centralized on a single server |
| SplitFedv3 [65] | only on client (alternative mini-batch on server) | centralized on a single server |
| CPSL [66] | parallel-first-then-sequential | centralized on a single server |
| HSFL [67] | mixed sequential SL and FL | centralized on a single server |
| FedSL [68] | on both client and server | distributed to multi-servers |
| SFLG [70] | on both client and server | hierarchically distributed |
| Information Revealed | Raw Data | Model Parameters | Intermediate Representation |
|---|---|---|---|
| FL | No | Yes | No |
| SL | No | No | Yes |
| hybrid SL-FL | No | Yes | Yes |
| Data Inference [92] | Model Inversion [95] | Label Leakage [96,97,98] | |
|---|---|---|---|
| SplitGuard [102] | + | ||
| correlation-based defense [99] | + | + | |
| noise-based defense [100] | + | + | |
| binarization-based defense [79] | + | + | |
| client-based protection [69] | + | + | |
| resistance transfer scheme [101] | + | ||
| random perturbation technique [96] | + | ||
| gradient perturbation technique [103] | + | ||
| activations and labels mixing [104] | + |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, Q.; Hu, S.; Deng, R.; Lu, Z. Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligence in Internet of Things: State-of-the-Art and Future Directions. Sensors 2022, 22, 5983. https://doi.org/10.3390/s22165983
Duan Q, Hu S, Deng R, Lu Z. Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligence in Internet of Things: State-of-the-Art and Future Directions. Sensors. 2022; 22(16):5983. https://doi.org/10.3390/s22165983
Chicago/Turabian StyleDuan, Qiang, Shijing Hu, Ruijun Deng, and Zhihui Lu. 2022. "Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligence in Internet of Things: State-of-the-Art and Future Directions" Sensors 22, no. 16: 5983. https://doi.org/10.3390/s22165983
APA StyleDuan, Q., Hu, S., Deng, R., & Lu, Z. (2022). Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligence in Internet of Things: State-of-the-Art and Future Directions. Sensors, 22(16), 5983. https://doi.org/10.3390/s22165983