1. Introduction
It is predictable that with the expansion in the Internet of Things (IoT) and the development of communication, a large number of wireless connections and huge data traffic will pose challenges for next-generation wireless systems [
1]. The demand for spectrum efficiency and network capacity has grown rapidly [
2]; since orthogonal resources are limited, traditional orthogonal multiple access (OMA) has difficulty meeting the multiple UEs demands [
3,
4]. Recently, due to the superior spectral efficiency, non-orthogonal multiple access (NOMA) has attracted tremendous attention in industry and academia [
5]. Compared with traditional OAM, NOMA can reuse non-orthogonal superposition and then assume large-scale connectivity [
6,
7].
Previous research on single-carrier NOMA technology is relatively complete, and performance evaluations at the link and system levels have proven that NOMA has a better transmission rate and lower error rate than OMA systems [
8]. For multi-carrier NOMA technology, the research is not sufficient and has mainly focused on the typical sparse code multiple access (SCMA) and pattern division multiple access (PDMA) technology. Research on SCMA technology mainly focuses on codebook design, channel transmission rate assessment and receiver design [
9,
10,
11,
12]. Research on PDMA technology has primarily focused on pattern design, interruption probability analysis and receiver design [
13,
14,
15].
Cooperative communication is an important method for combating channel fading and path loss and for reducing the shadow effect [
16,
17]. It was first introduced in [
18] and became an important component in the previous communication network. With the distributed transmission of relay at the transmitting site and the combination of signals at the receiving site, cooperative communication technology can obtain a cooperative diversity gain similar to the spatial diversity gain of the multiple input multiple output (MIMO) [
19]. Because of the above feature, cooperative communication is widely used in IoT scenarios where the size of massive UEs is small and difficult to implement multiple antennas [
20,
21].
NOMA cooperative communication technology was introduced in [
22]. It can combine the advantages of NOMA and cooperative communication to meet the demands of next-generation communication. However, there have been few studies addressing the combination of the two technologies, especially on NOMA multi-carrier cooperative communication technology.
Multi-carrier multiplexed NOMA cooperative technology can effectively obtain multiplexing diversity gain and improve system performance [
23]. Luo et al. [
24] studied the resource allocation optimization of an SCMA cooperative system, and the optimization was carried out with the weighted sum of power, codebook and subcarrier pairing as the alternative objective. Han et al. [
25] studied the method of self-interference mitigation for an SCMA cooperative system with a large-scale transceiver antenna. Tang et al. [
26] proposed an uplink PDMA collaboration system with a half-duplex decoder and relay, and they analyzed the interrupt performance. Tang et al. [
27] analyzed the outage probability of a downlink PDMA collaboration system with decoding and forwarding of a half-duplex relay. However, in [
26,
27], the derived closed-form expression of interrupt probability was simplified to only the scenario with three users and two carriers while not considering the return link discontinuity. The more general interrupt probability expression and the full-duplex scenario still need to be studied and analyzed. In addition, Sun et al. [
28] studied the multi-carrier NOMA cooperative system, which adopts a full-duplex base station for upstream and downstream simultaneous transmission, but the resource allocation optimization algorithm also assumes that the stack number of upstream or downstream users on each subcarrier does not exceed 2.
There are still several problems in the previous research studies. First, the theoretical boundaries of capacity and outage probability in a general scenario are not clear. Second, scheduling and resource allocation under multi-user and multi-relay with multi-carrier are extended to larger dimensions. Furthermore, effective multi-dimensional constellations, such as those in SCMA and PDMA, are more difficult to design and optimize than single-dimensional power segmentation. Finally, the widespread deployment of multi-carrier NOMA in conjunction with existing orthogonal frequency division multiple access lacks viable applications and validation.
In this paper, we studied multi-carrier multiplexed NOMA cooperative technology in a super-dense network, and the main contributions of this paper are listed below.
We designed a user-centered multi-carrier multiplexed NOMA cooperative system that can fully combine the advantages of multi-carrier NOMA and cooperative communication technology to meet the abundant UE demands.
We constructed a problem to optimize throughput while ensuring multiple users’ demands and decomposed it into two subproblems. Then, we proposed the corresponding dynamic grouping matching algorithm and iterative algorithm based on the difference of convex functions programing (DCP) to solve them.
Simulations were used to verify the effectiveness of the proposed NOMA cooperative network framework and the corresponding algorithms. Compared with two existing schemes, combining the dynamic grouping matching algorithm with an iterative algorithm improved system throughput while ensuring user quality of service (QoS).
The remainder of the paper is organized as follows.
Section 2 describes the system model, including the signaling model and the throughput model. In
Section 3, the problem is formulated as an optimization problem. In
Section 4, we propose the resource allocation algorithm of the cooperative network.
Section 5 presents the simulation results, which prove the effectiveness of the proposed algorithm. Finally, the conclusions are drawn in
Section 6.
2. System Model
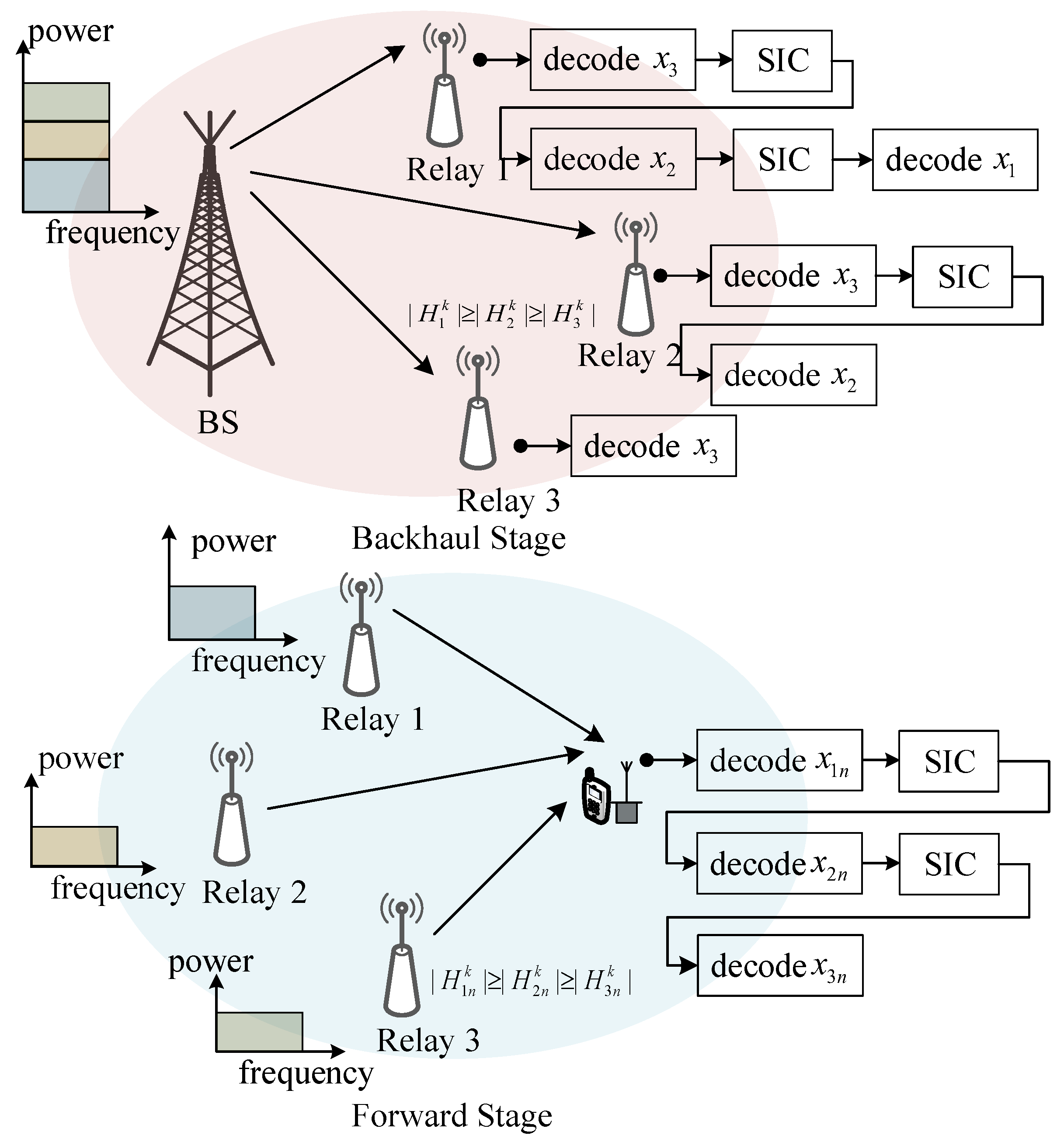
In this section, we describe the downlink NOMA-based cooperative network setting [
29] consisting of a base station (BS),
M relays, and
N UEs, as shown in
Figure 1. Each node is equipped with a transmit antenna and a receive antenna. The system frequency band is divided into
K subcarriers. The signals of different UEs or different packets of a UE can be superposed in one subcarrier to transmit simultaneously. In addition, all the relays are connected to the BS in the backhaul stage. We assume that the UEs and relays follow two independent Poisson point processes (PPPs) with the densities of
and
, respectively. The notions about the system model in this section are listed in
Table 1.
The BS can support the backhaul stage for relays and provide access services for UEs. In this paper, the UEs are assumed to be served dynamically via dense relays. The BS and the relays share the same frequency band, and the relays work in the time division duplex (TDD) mode. The signals passed into the backhaul stage and forward stage do not affect each other. At the backhaul stage, the signal is transmitted from the BS to the relays, and then, the relays decode the information of users and transmit it to corresponding users during the forward stage. Therefore, the downlink transmission can be divided into two processes, backhaul transmission and forward transmission, as illustrated in
Figure 1.
2.1. Signaling Model
In the forward stage, we take the
nth UE as an example to illustrate the signals in the downlink cooperative network,
. The inter-group interference can be avoided by properly grouping relays and allocating subcarriers [
30]. We use
to denote the signal, transmitted from the
mth relay to the
nth UE on the
kth subcarrier. The transit power of
is
. Meanwhile,
and
are the small-scale and large-scale fading channel coefficients from the
mth relay to the
nth UE on the
kth subcarrier, respectively. The channels of the forward and backhaul stages are independent Rayleigh fading channels, and the path loss exponent is
.
, where
denotes the distance from the
mth relay to the
nth UE. Then, the signal received on the
kth subcarrier of the
nth UE can be written as
where
is the AWGN at the receiver of the
nth UE on the
kth subcarrier with mean zero and variance
.
In the backhaul stage, we take the
mth relay (
) as an example to analyze the backhaul stage signals in the considered downlink cooperative network. Suppose that the signal transmitted from the BS to the
mth relay on the
kth subcarrier is
, and the power of the signal is
. Additionally,
and
denote the small-scale and large-scale channel coefficients from the BS to the
mth relay on the
kth subcarrier. Then, the received signal on the
kth subcarrier of the
mth relay can be written as
where
denotes the additive white Gaussian noise (AWGN) with mean zero and variance
at the receiver of the
mth relay on the
kth subcarrier.
2.2. Throughput Model
Since the transmission process is divided into two stages, the throughput is analyzed separately at the two stages.
In the forward stage, since the successive interference cancellation (SIC) technique is applied at the receivers to decode the signals from different relays, we assume that the channel coefficients meet
.
represents the channel coefficient between the
nth UE and the
mth relay on the
kth subcarrier. Then, the decoding order is consistent with the relay indexes. Thus, the received signal-to-interference-plus-noise ratio (SINR) of the
nth UE served by the
mth relay on the
kth subcarrier is written as
The corresponding throughput of the
nth UE is given by
In the backhaul stage, without loss of generality, we assume that the channel coefficients yield
. Here,
represents the channel coefficient between the BS and the
mth relay on the
kth subcarrier. Then, the decoding is carried out in the reverse order of the relay indexes. The SINR of the
mth relay on the
kth subcarrier is given by
Correspondingly, the backhaul throughput for the
nth UE can be given by
where
indicates whether the
nth UE is served by the
mth relay on the
kth subcarrier or not, and
. If
=1, the
nth UE is served by the
mth relay on the
kth subcarrier.
(
) denotes the proportion of a time slot occupied by the forward stage on the
kth subcarrier, and
is the proportion of the time slot used for backhaul.
Since the signal needs to be transmitted to the relays first and then forwarded to the UEs, the system throughput is given by
3. Problem Formulation
In this section, we maximize the system throughput under QoS constraints. Because the SIC technique is applied at the receiver, the complexity of the receiver grows with the number of superposed signals on a subcarrier. We assume that each UE can be served by up to
Q relays on a subcarrier to harness the complexity of the receiver at the UEs. The constraints are written as
Apart from the overall power constraints of the system, the power allocation in the NOMA system needs to satisfy the threshold for SIC decoding at the receiver (cf., the OMA system). Therefore, constraints
C2 and
C3 are given by
and
where
and
denote the maximum available powers of the BS and the
mth relay, respectively, and
is the decoding power threshold for the SIC receiver.
In terms of the QoS of each UE, we consider
where
denotes the target data rate of the
nth UE. Additionally, the time slot assignment coefficient between the access stage and backhaul stage on an arbitrary
kth subcarrier needs to meet
Therefore, the optimization problem can be formulated as
where
and
collect the power
allocated on the BS and the power
allocated on the relays, respectively.
and
collect the variables
and
, respectively.
4. Resource Allocation Algorithms
Problem (
13) is a mixed integer non-linear programming problem. It is challenging to derive a global-optimal solution [
31]. In this paper, a low-complexity suboptimal solution is developed in the presence of multiple relays and UEs. Problem (
13) is divided into two subproblems. First, we apply a dynamic group matching algorithm to map each UE with relays. Then, an iterative algorithm is proposed based on the D.C. programming to achieve a suboptimal solution for the joint power and subcarrier allocation.
4.1. Dynamic Group Matching for UEs and Relays
The grouping process of relays and UEs is a matching process between each UE and a set of relays serving the UE. To maximize the system throughput, we apply a deferred-acceptance strategy from the Gale–Shapley algorithm to balance the two-side matching priority of the UEs and relays. Let
represent the matched pair of the
mth relay and the
nth UE, and let
denote the set of matched pairs.
denotes that the
nth UE is matched with the
mth relay; otherwise,
. We define an evaluation model of the pair between the
nth UE and the
mth relay as
where
With a two-sided competitive selection of the UEs and relays, each node has its matching priority list to match with others. We denote the matching priority sets of UEs and relays as
where
is the matching priority list that the
nth UE matches with its nearby relays; similarly,
is the matching priority list of the nearby UEs that the
mth relay can match with. They can be further represented as
where
and
are the number of relays near the
nth UE and the number of UEs near the
mth relay, respectively;
denotes the relay whose matching priority of the
nth UE is
, and
denotes the UE whose matching priority of the
mth relay is
. If
, it signifies that the matching priority of the
nth UE with the
th relay is higher than the matching priority of the
nth UE with the
th relay. We also define the relay with the highest matching priority of the
nth UE as
. Correspondingly, we define the UE with the highest matching priority of the
mth relay as
. In this paper, to maximize system throughput, we have
and
The reason for our choice of the throughput and small-scale channel coefficient as the priority judgment criteria of relays and UEs is that they are our optimization function or one of the parameters of the optimization function, and the results screened by these criteria are more conducive to the maximization of throughput.
With the above illustration, the dynamic grouping matching algorithm between UEs and relays can be described as follows. First, we initialize the matching priority according to the available CSI. Then, we divide the grouping process into two matching processes. The first process is to guarantee that each UE can be served by a relay, and the second process is to group the relays for each UE.
In the first process, each UE requests matching the relay that prioritizes the UE over the other UEs. Then, each relay that has received the matching request from the UEs matches the UE which prioritizes the relay over the other relays, and then, it rejects the other UEs. This process is repeated until all UEs are served by at least one relay.
In the second process, each UE requests matching the unmatched relay that has the highest priority to the UE. Subsequently, the relay that has received matching requests from UEs selects the UE according to its matching priority if the number of relays in a group is below Q. When the number of relays in a group is Q, we determine whether the UE sending this matching request is more effective for improving the throughput than the other UEs in the group.
If this is the case, then we update the matched pair; otherwise, we reject the matching request. This process is repeated until all the relays are grouped or no UEs request matching with any relays. The details of the dynamic grouping matching algorithm are provided in Algorithm 1.
| Algorithm 1 Dynamic Group Matching Algorithm. |
- 1:
Initialization: Initialize the matched pairing set of the UEs and relays , the unmatched set of the UEs and relays , , and initialize the matching priority sets of the UEs and relays , through the Equations ( 20) and ( 21) - 2:
while do - 3:
Each UE in requests to match its highest matching priority relay from according to the matching priority set - 4:
for relay m = 1, 2,…, M do - 5:
Each relay matches the UE with the highest priority according to the matching priority set of relays and rejects the other UEs - 6:
The rejected UEs remove the mth relay from its matching priority set - 7:
Add the matched paring to the set and remove the mth relay and nth UE from and , respectively - 8:
end for - 9:
end while - 10:
while or do - 11:
Each UE requests to match its highest matching priority relay from according to the updated set - 12:
for relay m = 1, 2,…, M do - 13:
The mth relay makes the following judgment for its highest matching priority UE according to its matching priority set - 14:
if then - 15:
Add the matched paring to the set and remove the mth relay and nth UE from and , respectively - 16:
else - 17:
The relay matches with the nth UE when there exists a relay that satisfies and ; then, it updates and removes the lth relay into - 18:
Otherwise, reject the matching request of the nth UE and remove the mth relay from its matching priority set - 19:
end if - 20:
end for - 21:
end while
|
4.2. Joint Power and Subcarrier Allocation Algorithm for the Cooperative Network
Given the matching outcome described in Section IV, we propose the joint power and subcarrier allocation algorithm based on the D.C. programming to optimize the system throughput of the cooperative network. We denote the assignment
as
, where
denotes the matched pair of the
nth UE and the
mth relay, and
denotes whether the
nth UE is served on the
kth subcarrier or not. Problem (
13) can be rewritten as
where
collects variables
.
We combine the mixed integer constraint
with constraint
, as given by
The matching between the UEs and relays in constraint
C1 is obtained by Algorithm 1. Only
remains to be solved in constraint
C1. The integer constraint
is equivalent to the following expression:
Now, the optimization with the integer constraints is transformed to a continuous-value problem. We define
, and
to collect the variables
and
, respectively. Problem (
22) can be reformulated as:
According to the theorem of monotone optimization [
28], the equivalent problem of (
25) can be formed as:
where
is a sufficiently large penalty factor if
is neither 0 nor 1, and
.
Then, we transform the decoding threshold constraint
C3 into a maximum interference [
32] constraint
C3’ by
The new constraint
C3′ is a convex set. However, the problem is still a non-convex problem, since neither the objective function nor constraint
C4 is convex. Nevertheless, the following equivalent form always holds,
Therefore, we derive that
Then, the non-convex constraint
C4 can be rewritten as
Constraint
C4′ is the difference of two convex Functions (
31)–(
33). Additionally, we have
Therefore, we can rewrite (
26) as
where
,
.
Note that
,
,
,
,
, and
are convex functions. Therefore, problem (
35) is a D.C. program. We can implement successive convex approximation to obtain a suboptimal solution of the problem [
33,
34]. Given the differentiability of the convex functions
,
,
, and
, for any feasible point
,
,
, and
, we have
and
In (
36)–(
39),
,
,
, and
are affine functions of
,
,
, and
, respectively. The gradients in the affine functions can be given by
and
For a given feasible point
,
,
, and
, we can achieve the upper bound of (
35) by solving the following convex optimization problem:
where
.
Generally, the convex problem in (
48) can be readily settled by standard convex program solvers, and it can be solved by standard convex programming solvers such as CVX [
33]. We propose a successive convex approximation to tighten the upper bound solution in (
48) by an iterative algorithm, i.e., Algorithm 2. It can generate a sequence of feasible solutions continuously and achieve a locally optimal solution in polynomial time [
34].
| Algorithm 2 Iterative Algorithm for Resource Allocation. |
- 1:
Initialization: Initialize the maximum number of iterations and set iteration index ; and initialize the current feasible point , , , and a penalty factor - 2:
repeat - 3:
Set the variables , , , and to be solved by the standard convex program solvers - 4:
Evaluate the convex functions , , , and - 5:
According to the current point , , , and , evaluate the affine functions , , , and - 6:
Substitute them into ( 48) to solve the convex problem for getting the upper-bound optimal point , , , and - 7:
Update iteration index - 8:
Update the next iteration point , , , - 9:
until or - 10:
Output the suboptimal solution , , ,
|
4.3. Computational Complexity Analysis
The computational complexity of an exhaustive search in the grouping matching algorithm is . The exhaustive search scheme is user-centric, as it divides each UE into a group, and each relay can either belong to the group of the UE or not. Thus, the solution to all groupings is , and the computational complexity of the exhaustive search is . The computational complexity of Algorithm 1 is . Specifically, steps are needed, while each UE matches with a relay for grouping in the proposed grouping algorithm, and the steps for the grouping process are less than steps. Therefore, the total computational complexity of the proposed grouping algorithm is . The computational complexity of the D.C. programming is ; as is no more than , the computational complexity of the D.C. programming is . Thus, the computational complexity is .
4.4. Convergence of Algorithm 1
We divide the algorithm into two processes, and the first process guarantees UE communications. The system performance is slightly degraded to satisfy QoS. The second process of the algorithm is convergent, and the proof is as follows.
Proof. When UE matches with relays , , …, and (the descending order of priority) in the second process, assuming that there exists a relay matching UE , the priority of for is higher than that of . is higher than in the priority list of relay simultaneously. □
When UE matches relay not , there are two situations: UE sends a request to , and relay is rejected, which indicates that the priority of is higher than in the priority list of . does not send the request to . We can conclude that the priority of is higher than in the priority list of . The two situations of the hypothesis cannot exist simultaneously, and thus, the hypothesis is not true. There are no better matched pairs, so the matched pair obtained is stable.
5. Simulation Results and Analysis
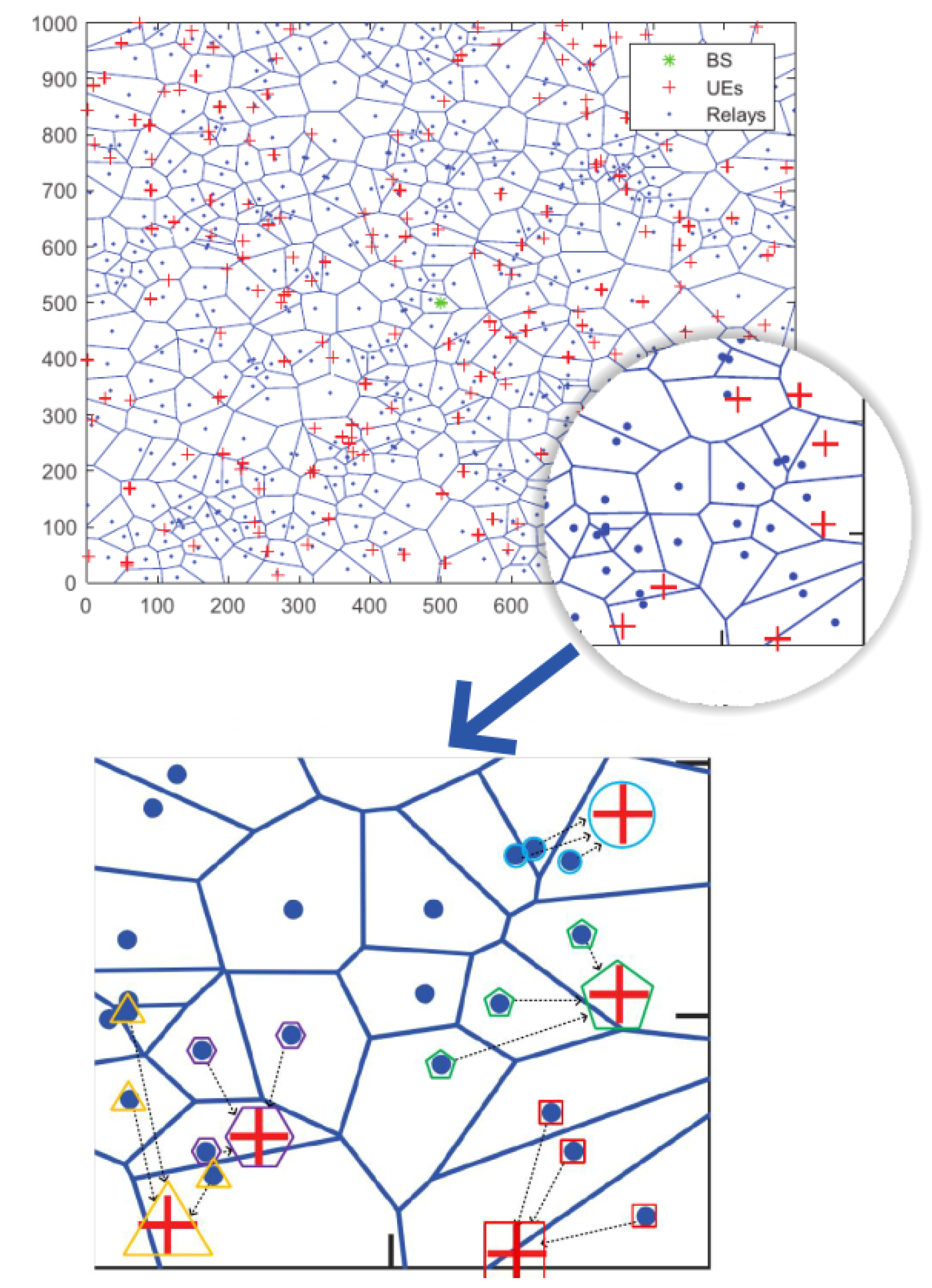
In this section, we evaluate the proposed framework and algorithms in terms of the system throughput through simulations. To make a fair comparison, we try to use the same system configuration in OMA, Co-OMA and the traditional NOMA system with the proposed scheme. We deploy the BS in the middle of a 1000 m × 1000 m area. The UEs and relays are modeled as independent PPP with density
and
. UEs are generated in the area randomly, as illustrated in the top of
Figure 2. Other simulation parameters are summarized in
Table 2. To show the grouping directly, we provide the schematic diagram when the maximum stack semaphore Q in our proposed scheme is set as 3. The matched pairs of relays and UEs chosen by our proposed algorithms are shown at the bottom of
Figure 2. The codes are developed on MATLAB using the CVX toolbox and are executed on a 64-bit operating system with 16 GB RAM and Intel CORE i7, 3.4 GHz.
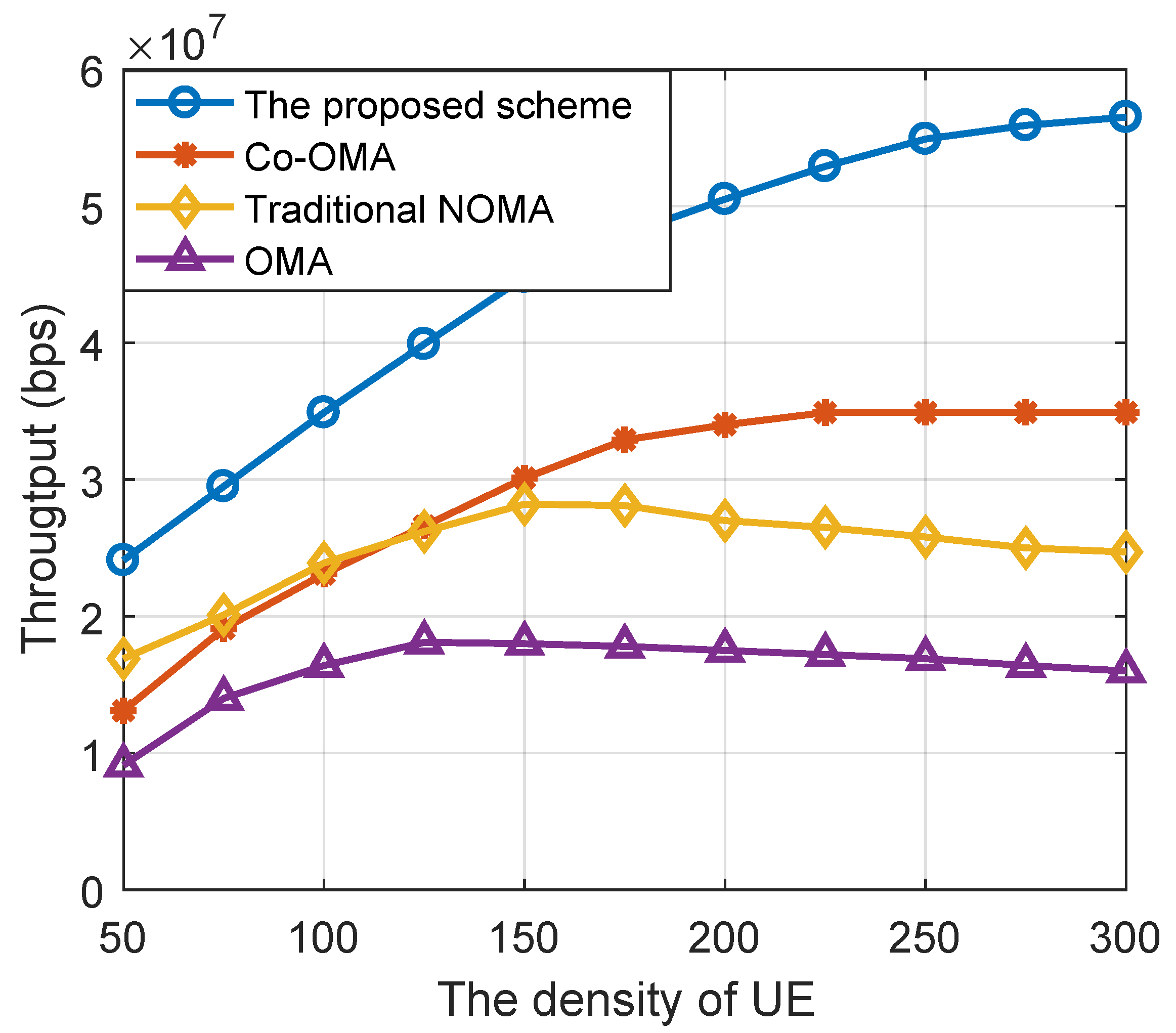
In
Figure 3, we compared the system throughput of the proposed NOMA-based cooperative network scheme, the OMA-based cooperative network (Co-OMA) scheme, the NOMA, and the OMA scheme under different densities of UEs. The density of relays was set to 300. According to
Figure 3, we can see that the proposed scheme achieved the highest system throughput, and it exhibited a 50% gain when the density of UEs exceeded 200 compared to the Co-OMA scheme. This is because with the increasing density of UEs, the spectrum resources is limited, and the proposed scheme shows the advantage of using non-orthogonal resources.
In addition, NOMA and OMA solutions without collaborative communication technology can provide high overall throughput when the density of user nodes becomes too high. This is because to ensure the QoS of some weak channel UEs, a large number of system resources are sacrificed to the specific UEs, which leads to the slow decline of the total throughput of the system and eventually tends to be stable. The comparison between NOMA and cooperative OMA in [
35] shows the relationship between backhaul capacity and micro-area access number. When the number of UEs served by the system exceeds the threshold value, the system performance will decline OMA with sufficient system resources (low user node density). However, the user node density increases, and the cooperative OMA can improve the throughput by using the channel gain of the backhaul link and the multiplexing gain of a large number of relay nodes, thus exceeding the throughput performance of a non-collaborative NOMA scenario.
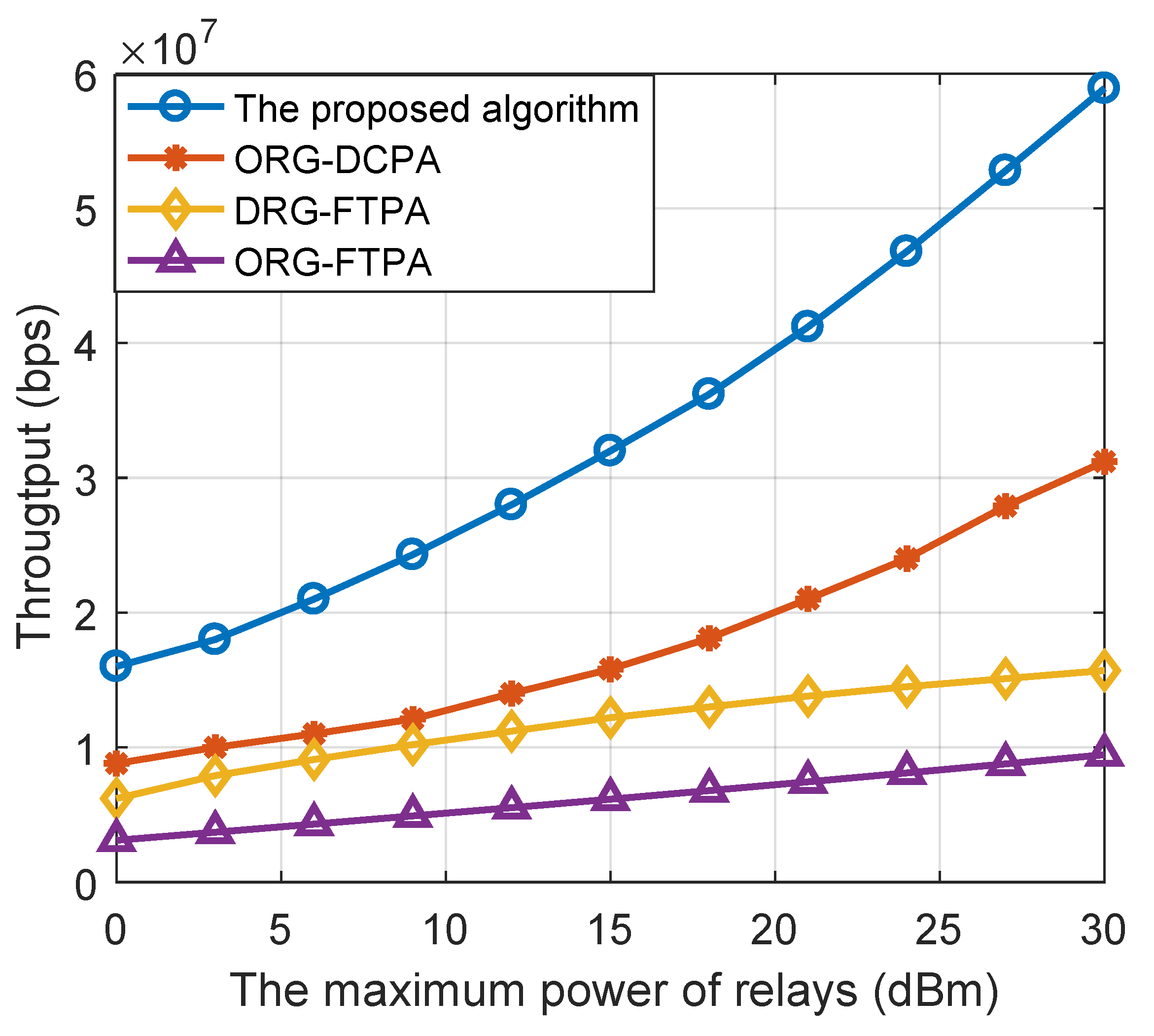
To verify the effectiveness of our proposed algorithms, we compared it with the following benchmarks in the NOMA-based cooperative network: (1) opportunistic with DCP-based allocation (ORG-DCPA), (2) dynamic relay grouping with fixed transmit power allocation (DRG-FTPA), and (3) opportunistic relay grouping with fixed transmit power allocation (ORG-FTPA). The four algorithms can be seen as the combination of DRG, ORG, DCPA and FTPA. The computational complexity of DRG is as shown in the analyses above; the worst case of ORG is exhaustive search, so the computational complexity is . The computational complexity of DCPA and FTPA are and , respectively. Thus, the complexity of DRG-DCPA, ORG-DCPA, DRG-FTPA, and ORG-FTPA can be present as , , , and . It needs to be emphasized that although DRG-FTPA has the lowest complexity, due to the unchangeable natuer of the transmit power, the DRG-FTPA shows the worst performance during the simulation. Then, we showed the simulation results in terms of the maximum power of relays, the density of relays and the density of UEs.
Figure 4 shows the system throughput diagram of several algorithm schemes under different relay transmitting powers, where the densities of UEs and relays are 200 and 500, respectively. The proposed DRG-DCPA resource allocation algorithm can obtain the highest system throughput, which is followed by the ORG-DCPA algorithm and ORG-FTPA algorithm. In particular, compared with the system throughput of other resource allocation algorithms, the DRG-DCPA algorithm can at least double the system throughput when the maximum power is more than 15 dBm.
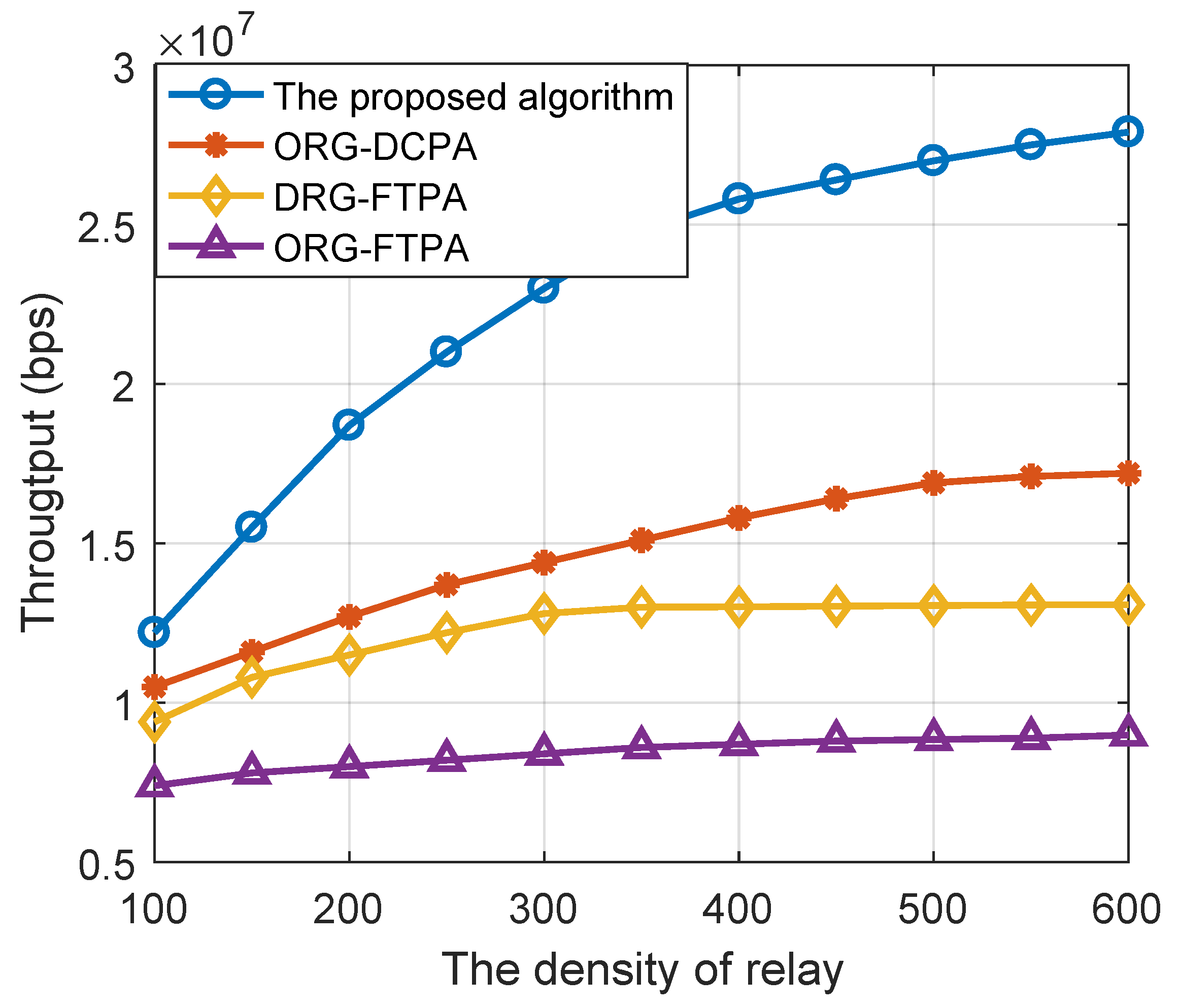
Figure 5 shows the system throughput comparison of the above resource allocation algorithm schemes under different relay densities where the user node density is set to 50. When the density of relays is large enough, the system throughput of the DRG-DCPA resource allocation algorithm improved by more than 60%, 100% and 200%. When the density of intermediate relays increases, the system throughput of the DRG-DCPA algorithm improves faster, indicating that the algorithm has a stronger ability to utilize relay resources and thus can obtain more multiplexing gain.
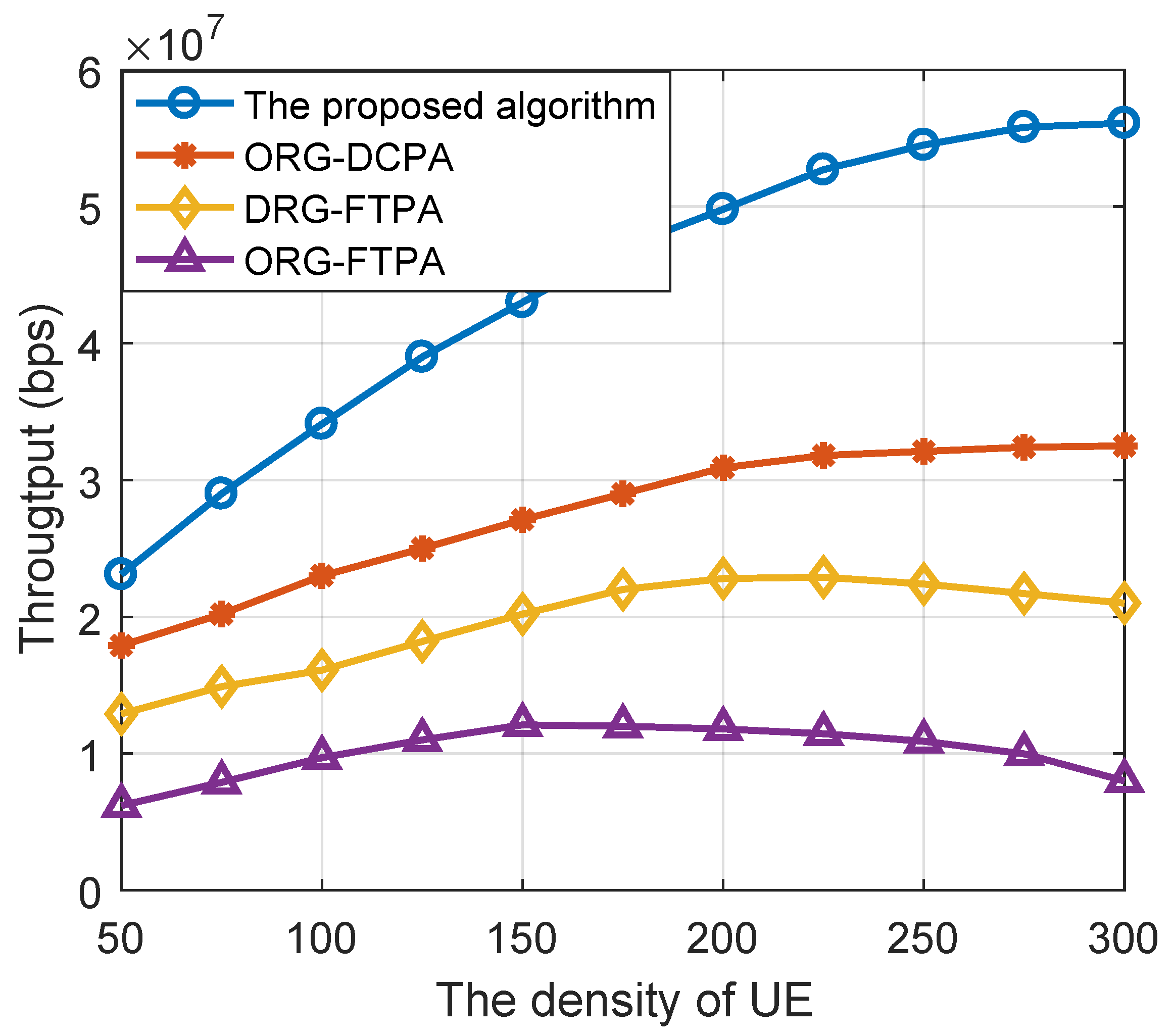
Figure 6 shows the system throughput comparison of the above resource allocation algorithm schemes for different densities of UE. The density of the relay is set to 300. When the relay node density is sufficient, the throughput of the DRG-DCPA algorithm will increase with increasing user density, and when the user node density is 200, the throughput of the DRG-DCPA algorithm will increase by more than 60%, 120% and 210% compared with the other three algorithms. In addition, the use of a fixed percentage of the power allocation algorithm under the condition of excessive user node density decreases. This is because the above allocation algorithm may spend too much power to weak channel users to ensure the QoS. This causes the system to not effectively utilize resources; when the user node is too saturated, the system throughput will deduce.
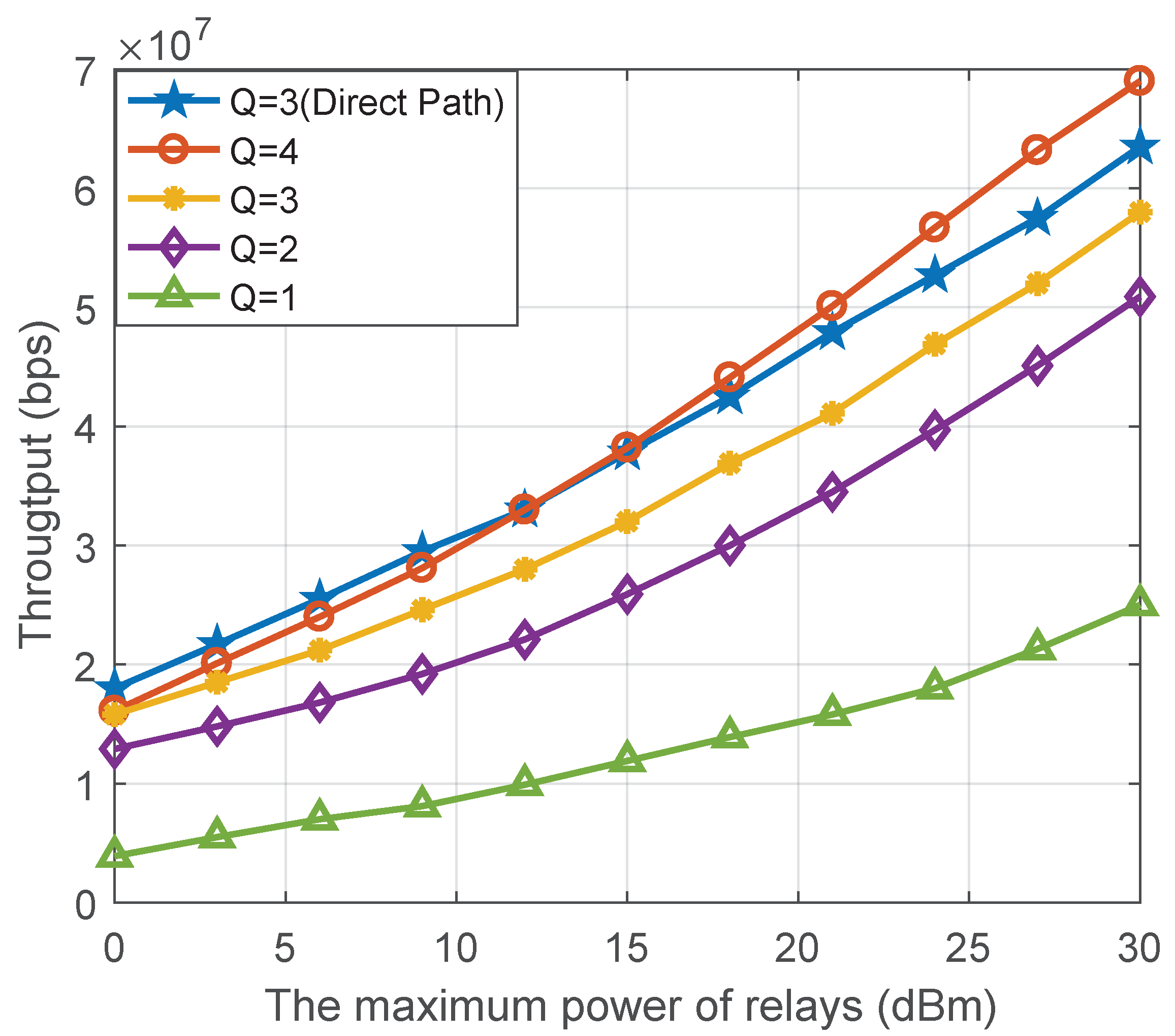
In
Figure 7, we present the effect in the proposed collaborative system on throughput with different maximum numbers of signals superposed per subcarrier. When the maximum relay power is 15 dBm, the proposed system can improve the throughput more than twice under QoS constraints. In addition, we use Q to denote the maximum number of signals superposed per subcarrier; when Q is larger, the proposed scheme can achieve a higher throughput. In particular, the throughput increases rapidly when the intermediate maximum power is higher. One possible reason is that the number of overstacked signals at low SINR will make the interference in the SIC decoder too large to meet the constraint
C3; thus, the gain of the throughput is reduced.
It should be noted that the influence of the direct path is not considered in the reference, and the channel condition is poor. The simulation comparison result is the lower bound of the system and algorithm performance, but it can also effectively demonstrate the effectiveness of the proposed collaborative system and optimization algorithm. To confirm the above conjecture, we give a further simulation. In this simulation, we consider the direst path scenario. In addition, if the impact of the direct path on the system is considered, there is generally a direct path between the BS and the relay, but there is no direct path between the relay and the user. At this point, the channel between the base station and the relay is better, which is generally regarded as the Rician fading channel, and the improvement of the channel condition can help relax the constraint C3. The simulation shows that in the low SINR, Q = 3 with direct path performances better than Q = 4, but as the power increased, the Q = 4 without a direct solution plays a non-orthogonal higher resource utilization. The simulation result can further improve our conjecture.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}