1. Introduction
Pitch is a subjective psychoacoustic phenomenon synthesized by the ear auditory cortex system for the brain [
1]. As a basic feature, pitch is widely used in the areas of speech interaction [
2,
3,
4,
5,
6], music signal processing [
7,
8,
9,
10,
11], and medical diagnosis [
12,
13]. Research on pitch estimation has been going on for decades, and estimating pitch from clean speech has been considered a solved problem because many methods achieve high estimation accuracy under high signal-to-noise ratio (SNR) conditions. However, the robustness of pitch estimation under noise and reverberation conditions still needs to be improved. Drugman and Alwan of the University of Mons, Belgium, authors of the well-known summation of residual harmonics (SRH) pitch estimation method, emphasize that performance under noisy conditions is the focus of research in pitch estimation over the next decade [
14,
15].
The robustness of pitch estimation is affected by the model accuracy of the method, and the modeling of almost all pitch estimation methods directly or indirectly depends on the harmonic structure since the harmonic structure is an essential feature of audio signals.
Figure 1 shows the harmonic structure of an audio signal. The spectral peak with a frequency of 100 Hz is the pitch, and the higher spectral peaks located near integer multiples of 100 Hz constitute the harmonic structure of the pitch. A fundamental assumption of modeling harmonic structures used in the pitch estimation is that the harmonic components are strictly distributed at integer multiples of the pitch [
14,
16,
17,
18]. Expressed in a formula, this modeling method on harmonic structures is generally realized by the product of an integer and the pitch, that is:
The harmonic summation (HS)-based methods such as SRH and subharmonic-to-harmonic ratio (SHR), are a typical category of methods using (
1) to select the harmonic components directly. Besides, (
1) also exists in the commonly used harmonic models, as follows, wherein parameters
l in (
2) and (
3) correspond to the strict integer multiple relationship between the pitch and its harmonics.
(1) Harmonic model or harmonic plus noise model [
12,
19], which can be denoted by:
where
is the discrete time signal, including noise sequence
;
,
,
, and
are the linear weights and the initial phase of the
harmonic, respectively;
is the normalized angular frequency in radians;
is the sampling rate. The second part of (
2) is one equivalent example of the first part of (
2), and it is derived using the trigonometric product-to-sum formula.
(2) Tied Gaussian mixture model (tied-GMM) [
20], within which each harmonic is assumed to be a frequency probability distribution approximated with a Gaussian distribution. In log-frequency scale, integer multiples of harmonics correspond to addition operations. Thus, the means of the tied-GMM are represented by:
where
u corresponds to the pitch
, and
l denotes the index of the harmonic.
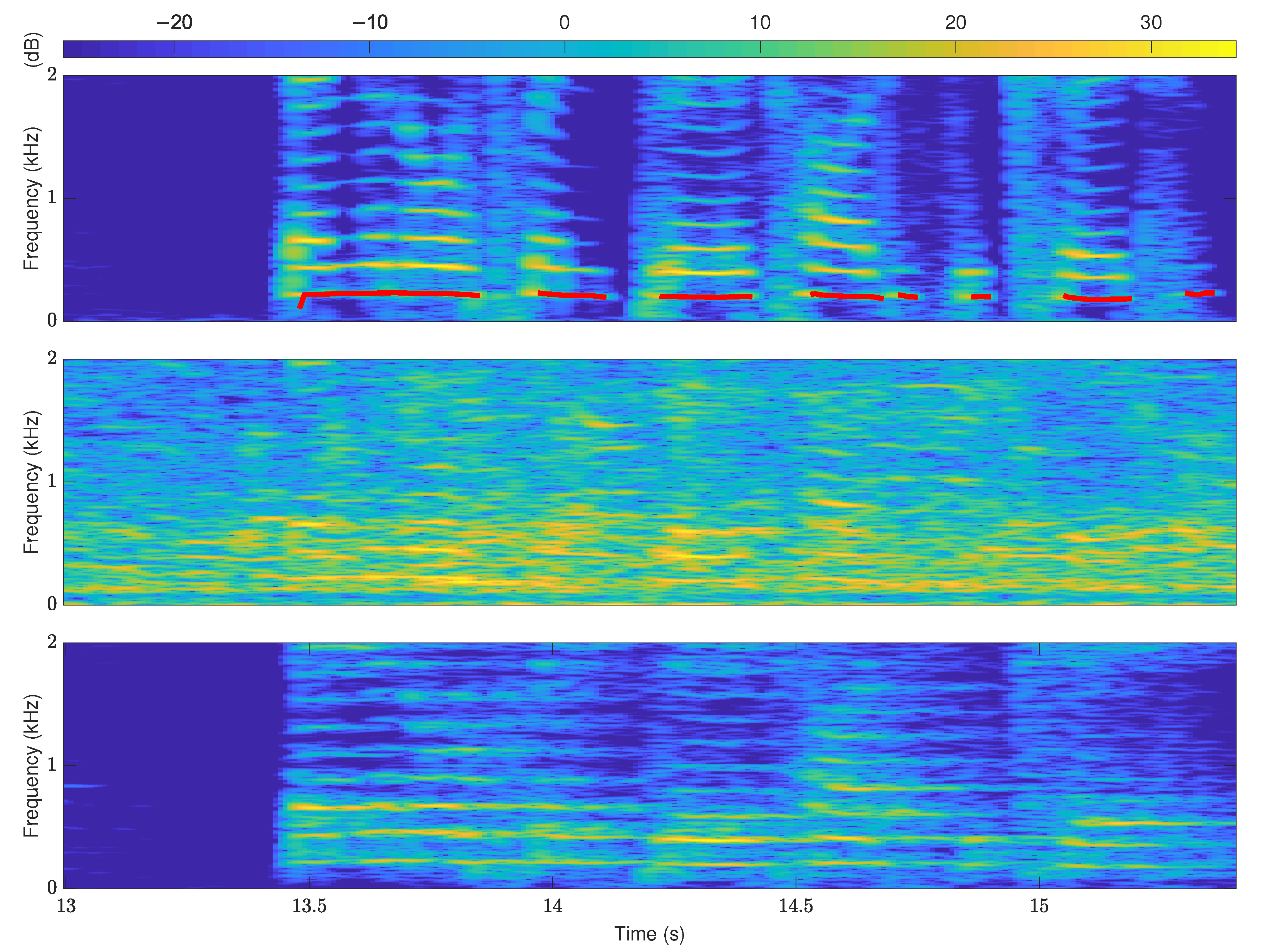
However, the assumption that the harmonic structure has a strict integer multiple relationship with the pitch does not always hold in practice. The effects of the structure of the vocal tract, the acoustic nature of musical equipment, and the spectral leakage issue may all cause harmonic components to be shifted relative to integer frequency positions. In addition to the above-mentioned accuracy of modeling the harmonic structure affecting the robustness of the pitch estimation, the use of priors by pitch estimation methods also matters. Noise and reverberation can corrupt and distort the harmonic structure of speech signals, and it is necessary to introduce additional priors into pitch estimation methods to improve robustness. The middle and lower parts in
Figure 2 correspond to the spectrograms under noise and reverberation conditions, respectively. Obviously, the harmonic structures represented by the bright yellow parts in
Figure 2 are ambiguous. It is challenging to obtain high accuracy for pitch estimation methods that rely entirely on harmonic structure. This is also the main reason that the performance of many pitch estimation methods decreases rapidly when the SNR continues to decrease below negative values. Smooth prior is the basic prior knowledge of pitch and provides a constructive method for pitch estimation. The red line in the upper part of
Figure 2 is the connection of the pitches of voiced frames. The smooth prior represents that the pitch trajectory is generally continuous and smooth with the time change. The idea of smooth prior has been integrated into the pitch estimation methods to improve the pitch estimation robustness and accuracy in different ways, such as Bayesian [
12], Kalman filtering [
13], and particle filter [
21]. However, the current methods of using smooth prior are still computationally expensive compared to HS, which has been theoretically proven to be a theoretical approximation of the most accurate non-linear least squares (NLS) method [
19]. This not only affects the robustness of HS-based pitch estimation methods under noise and reverberation conditions, but also limits the application of pitch estimation in computing-limited scenarios.
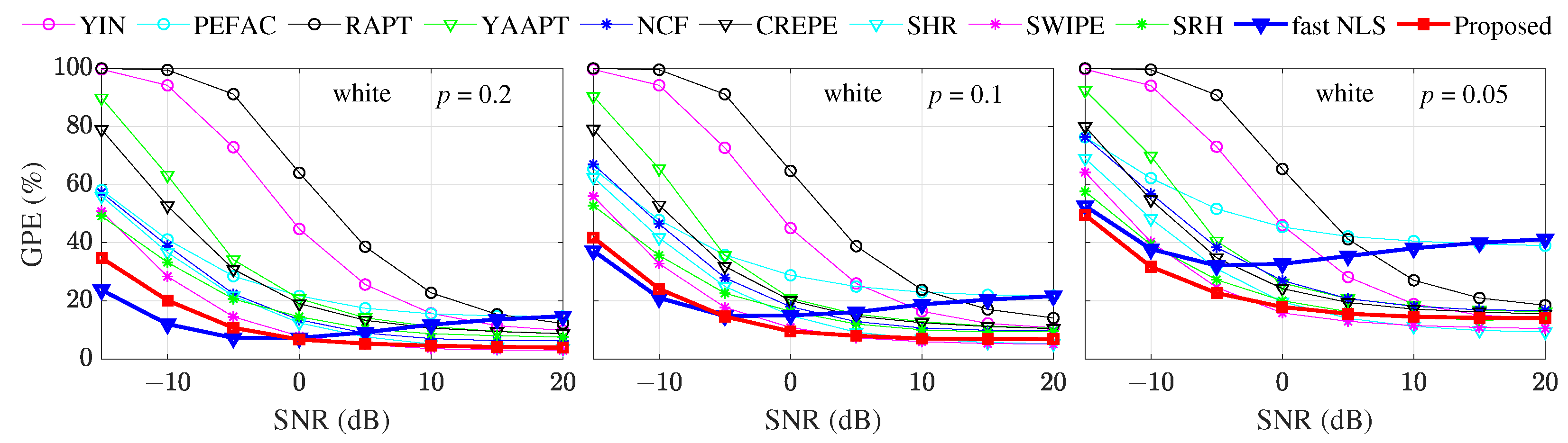
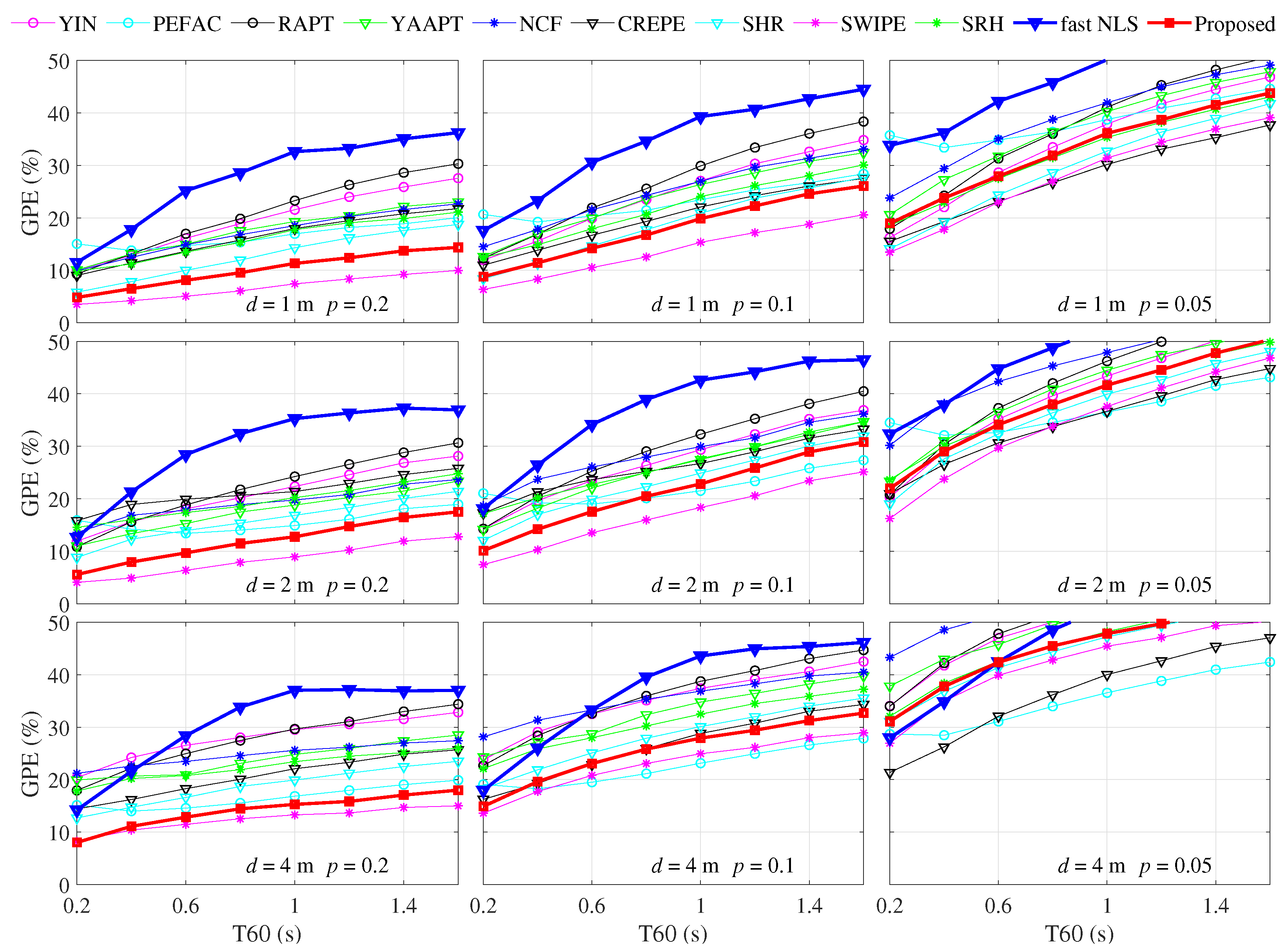
This paper’s contribution is to improve pitch estimation’s robustness more efficiently by improving the accuracy of modeling harmonic structure and realizing the smooth prior at a low computational cost. Two improvements are proposed and integrated into the proposed pitch estimation method based on SRH. First, a loose constraint is introduced to make the modeling of harmonic structure more closely match the actual harmonic distribution. Second, the smooth prior is utilized in a low-complexity way by finding the continuous pitch segment with high confidence, and expanding this pitch segment forward and backward, respectively. Besides, the idea of the continuous pitch segment is also integrated into the SRH’s voiced/unvoiced decision to reduce the short-term errors at both ends and in the middle of the voiced segment. Accuracy comparison experiments under noise and reverberation conditions with ten pitch estimation methods show that the proposed method possesses better overall accuracy and robustness. Time cost comparison shows that the time cost of the proposed method reduces to around one-eighth of the state-of-the-art fast NLS method on the experimental computer.
The paper is organized as follows: In
Section 2, related works in the literature are briefly introduced. In
Section 3, the overall structure of the proposed pitch estimation method is introduced, and the differences relative to the SRH method are highlighted subsequently. In
Section 4, experiments under noise and reverberation conditions that influence the accuracy of pitch estimation methods are carried out and analyzed. Finally, the conclusions are summarized in
Section 5.
2. Related Work
The existing pitch estimation methods can be classified as time-domain methods, frequency-domain methods, mixed-domain methods, and neural network-based methods. YIN and RAPT are well-known time-domain methods that estimate pitch directly from the signal waveform using autocorrelation [
22,
23]. As a supplement, the cumulative average normalized difference function and some post-processing techniques are used in YIN to improve the accuracy of the autocorrelation. Similarly, RAPT calculates the pitch based on a short-term speech signal’s normalized cross-correlation function (NCCF). The characteristic of RAPT is using two different sampling rates, one at the original sampling rate, and the other at a significantly reduced sampling rate [
23]. However, the general problem of time-domain methods is the robustness under low SNR conditions. Comparative experiments in multiple research show that YIN fails rapidly under negative SNRs, and is more sensitive to colored noise [
12,
15].
In contrast, frequency-domain methods, such as various harmonic summation (HS)-based methods, generally exhibit better robustness. The HS-based methods have the advantage of being a theoretical approximation to the most accurate NLS method, while having a much lower computational complexity [
12,
19]. The HS-based methods generally obtain pitch candidates by processing the peaks in the power spectrum and select the pitch according to the HS value of the candidates. The differences between the HS-based methods are mainly in the objective function used for summing the power of the harmonics [
16,
17], or residual harmonics [
14]. The original objective function summed the powers of the harmonics directly in [
16]. Then, the SHR method revised the objective function as a ratio of the harmonic power summation to the power summation of the subharmonic [
17]. This replacement not only measures the harmonic power, but also excludes non-harmonic noise. Further, the summation of residual harmonics (SRH) method used an auto-regressive linear predictive coding (LPC) filter to achieve the function of pre-whitening and the removal of vocal tract effects [
14]. Besides, typical frequency-domain methods also include PEFAC [
18] and SWIPE [
24]. Both the PEFAC and SWIPE can be seen as HS-based methods in a broad sense. SWIPE is a harmonic comb pitch estimation method with cosine-shaped teeth that smoothly connects harmonic peaks with sub-harmonic valleys, and another feature is that it only uses the first few significant harmonics of the signal [
24]. The PEFAC realized a harmonic summation filter in the log-frequency power spectral domain [
18], and PEFAC’s objective function is similar to the original HS. However, the long frame length requirement of PEFAC makes it inappropriate for time-critical applications, such as in hearing aids [
12].
Mixed-domain methods are theoretically more advantageous than time-domain or frequency-domain methods, but this advantage is still not obvious in practice. YAAPT is a typical mixed-domain method with features of nonlinear processing and dynamic programming [
25]. Although the accuracy of YAAPT is better than the time-domain methods such as Yin, its gap with the excellent frequency-domain methods is noticeable under low SNR conditions according to the results in [
15]. Besides, mixed-domain pitch extractions are also adopted in ETSI extended distributed speech recognition (DSR) standards ES 202 211 and ES 202 212 for server-side voice reconstruction [
26,
27,
28], and in a high-quality speech manipulation system for time interval and frequency cues extraction [
29]. Although the pitch estimation method based on a neural network is indeed based on time-domain and/or frequency-domain methods, the use of neural networks makes this category distinctly different. The recently proposed LACOPE is a deep learning-based pitch estimation algorithm, and it is trained in a joint pitch estimation and speech enhancement framework [
3]. The feature of LACOPE provides a trade-off between pitch accuracy and latency by allowing for a configurable latency. This feature is achieved by compensating for the delay caused by feature computation by predicting the pitch through a neural network. CREPE is a deep convolutional neural network-based pitch estimation method based on the time-domain signal [
30]. CREPE is claimed to be slightly better than the probabilistic successor of the classic YIN in [
3]. However, the CREPE needs to be retrained if the user’s frequency resolution or frame length requirement is not the same as the pre-trained model, which can be a very time-consuming process as pointed out in [
12].
3. Proposed Pitch Estimation Method
The proposed pitch estimation method belongs to the HS-based method, and specifically, it is a variant of the SRH [
14]. However, the core formula of modeling the harmonic structure and the scheme of using the smooth prior of the proposed pitch estimation method differs from the HS-based methods and SRH, and these differences contribute to the performance improvement. This section first introduces the overall structure of the proposed pitch estimation method, and then highlights the differences.
3.1. Overall Structure of the Proposed Pitch Estimation Method
The overall structure of the proposed pitch estimation method is shown in
Figure 3. The proposed pitch estimation method mainly includes three portions: (1) whiten the input speech signal through an LPC filter; (2) narrow the target pitch range of the second SRH operation through the initial estimation of the first SRH operation; (3) perform the segment expansion on the candidate pitch array and perform filtering on the pitch trajectory. The three portions correspond to the seven steps in
Figure 3.
Step 1: Calculate the speech signal’s residual spectrum by using an auto-regressive LPC filter. This operation is for pre-whitening and removing the effect of the vocal tract, and the LPC filter in the proposed method is the same as that in the original SRH [
14]. The data frame length for calculating the spectrum affects the accuracy of pitch estimation. In harsh environments, the signal integrity is severely destroyed. Thus, acquiring more signal periods is necessary for accurate signal identification. The longer the data frame, the more signal power is integrated by the FFT, which benefits the signal extraction from noise. However, a longdata frame length decreases the temporal resolution of pitch changes. Therefore, the data frame length in the proposed method is set to 102.4 ms with 10 ms hop size, which is a trade-off between accuracy and temporal resolution. The FFT length is set to the sampling rate by padding each data frame with zeros, which is inherited from the original SRH method. For the dataset with a 20 kHz sampling rate, 102.4 ms corresponds to 2048 samplings, and the FFT length is achieved by extending the 2048 samples to 20 k by padding zeros. Similar to the original SRH method, resampling is used in the proposed method to avoid overlong FFT and LPC computation under high sampling rate conditions. The input signal is resampled to 16 kHz if the input signal’s sampling rate exceeds 22.05 kHz.
Step 2: for each frame of the residual spectrum, calculate the SRH values of each frequency within the default searching range
of pitch based on the residual spectrum. The frequency corresponding to the largest SRH value is selected as the initial estimation of this frame. The default parameter of
in the proposed method is set to [50, 400], which are commonly used values in practice. Since the formula for calculating the SRH value is the core of the SRH, the formulas in the SRH method and the improved method are separately introduced in the subsequent
Section 3.2.
Step 3: apply the median function to the initial estimation of the pitch sequence to get the frequency median . This median is used to adjust the subsequent pitch search range.
Step 4: narrow the pitch search range by narrowing the default
according to the frequency median
. The constrained parameters 2 and 1/2 are based on the assumption that a normal speaker will not exceed these limits [
31].
wherein the function
and
represent selecting the maximal and the minimal value from
x and
y, respectively.
Step 5: for each frame of the residual spectrum, recalculate the SRH value of each frequency within the narrowed searching range of pitch based on the residual spectrum. Select the frequencies corresponding to each frame’s largest SRH value as the candidate array’s first row. Besides, select the frequencies that correspond to the second largest SRH value of each frame as the second row of the candidate array. Thus, in addition to selecting the frequency with the largest SRH value, only one candidate frequency is selected for each frame. This is because octave error is a major aspect of SRH estimation error, and when octave error occurs, the frequency with the second largest SRH value is usually the correct pitch.
Step 6: update the pitch sequence from the candidate array by using the segment extension operation. The segment extension operation is added in the proposed pitch estimation relative to the SRH, and the details are introduced in the subsequent
Section 3.3.
Step 7: apply a moving median filter to the pitch sequence with a window length of three hops. This post-processing operation helps to improve the accuracy of the pitch estimation method by smoothing the pitch trajectory.
The main steps of the proposed pitch estimation method are described above. The significant differences between the pitch estimation method and the SRH method are the newly added segment expansion operation for reducing pitch jumping, and the revision of the core formula for calculating SRH. Next, we introduce the significant differences in detail.
3.2. Modeling Harmonics with Loose Constraint
In the SRH method, assume the specified pitch estimation range is
, the SRH value of each frequency within the range is calculated by:
where the integer multiple relationship
in (
5) equals
in (
1). Parameter
P denotes the residual spectrum function. The first summation portion in (
5) represents the harmonic comb of the SRH method that is based on the integer multiple relationship of harmonic structure. The second summation portion in (
5) shows the supplemented harmonic comb with negative teeth at the sub-harmonic that is also based on the integer multiple relationship of harmonic structure.
In the proposed method, the strict integer multiple constraint of harmonic frequencies in (
5) is modified by adding an adjustable parameter
to capture harmonics more accurately. The harmonic frequency
is selected in a small range that is controlled by
:
where
is the frequency of the harmonic of order number
l, and
L is the maximum order of harmonic to be considered. The expression
represents the maximum power FFT spectrum within the frequency range from
x to
y. Therefore, when summing the harmonic power, the proposed method does not select the frequency bin at the integer multiple position as in the SRH, but searches in a frequency range from
to
. The frequency deviations of actual harmonics are small, and the deviations are enlarged to demonstrate the capture effect of the proposed modeling method on harmonics, as shown in
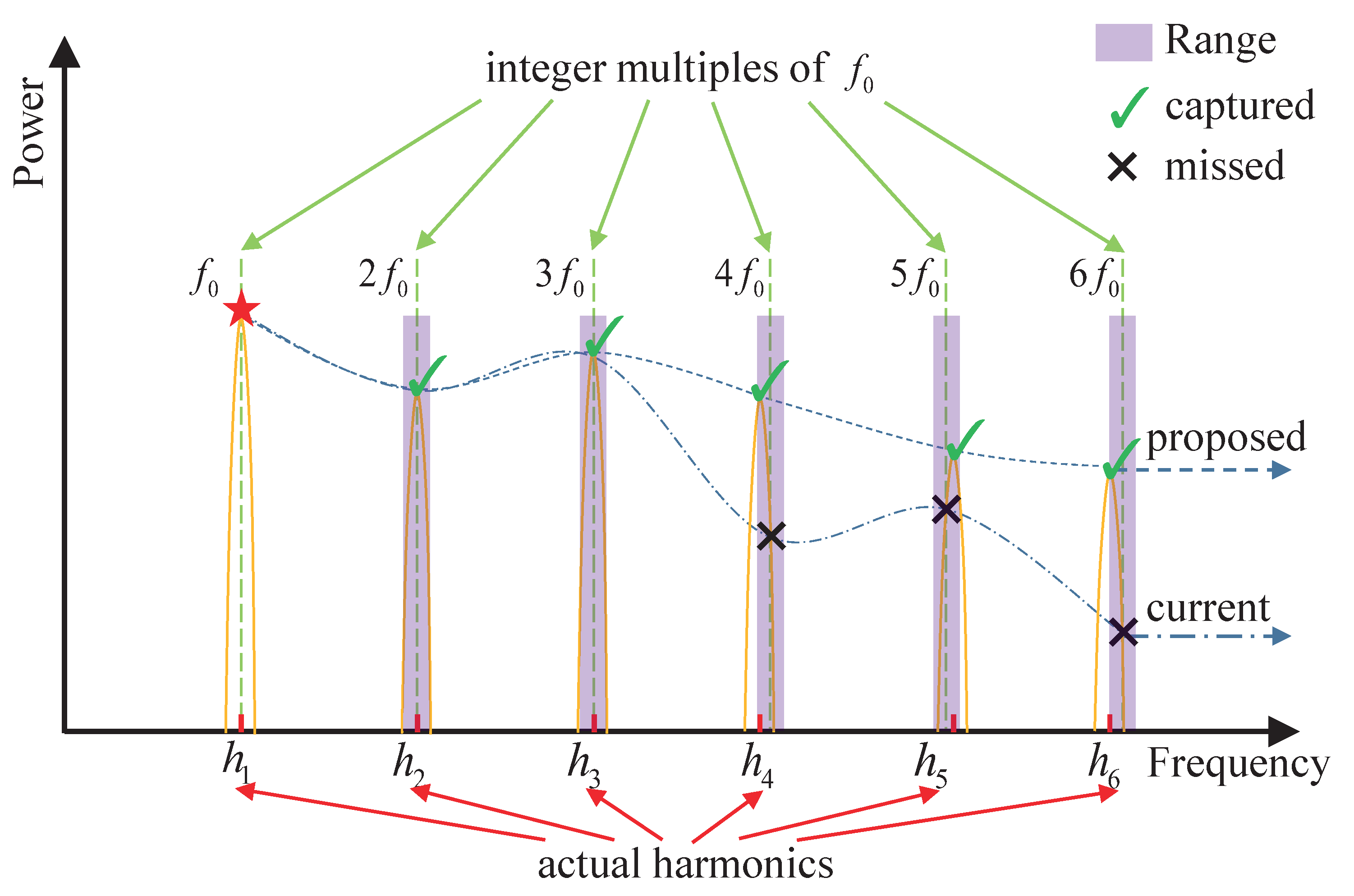
Figure 4. The frequency range is determined by the order number
l and parameter
. The order number
l controls the primary harmonic position, and parameter
determines the allowable deviation degree of harmonic frequency relative to the integer multiple position. A large value of
or
L decreases the accuracy because too loose of a constraint could capture spectral peaks that do not belong to the harmonic. Experiments show that setting
as two frequency bins is a good balance between the accuracy and the loose constraint. Two frequency bins correspond to 2 Hz since the frequency resolution in this paper is 1 Hz. In the case of lower frequency resolution, two frequency bins are still reasonable. Because leakage is the primary factor affecting the capture of harmonics, the two frequency bins cover the effects of different types of windowing operations. Besides, since the first few significant harmonics contain most of the energy of the speech signal,
L is set to 5 in the proposed method.
In
Figure 4, symbols, such as
,
,
, etc., on the horizontal axis represent the peak positions of the actual harmonic frequencies, and the corresponding peaks on the vertical axis represent the harmonic spectrum. Symbols
, 2
, 3
, etc. in the upper position denote the frequencies with a strict integer multiple relationship. The symbols “
√” and “×” are the intersections of the vertical dashed lines and the harmonic peaks. The fourth to sixth harmonics in the spectrum slightly deviate from the position of integer multiples of the pitch. The purple shading shows the allowable frequency deviations of the proposed method. The mismatch between the symbols “×” and the harmonic peaks indicates that the current modeling method on the harmonic structure cannot accurately capture all the harmonics in this situation. The coincidence of the symbol “
√” and the harmonic peak represents the effectiveness of the proposed method.
3.3. Segment Extension
The first row of the candidate array is selected as the initial sequence, as is shown in the top of
Figure 5, and the numbers 1, 2, 3, …, n in
Figure 5 indicate the frame index. The initial sequence is used to find the main segment of the pitch because the frequencies within the first row of the candidate array are most likely to be the pitch from the perspective of the SRH value. Based on the smooth prior of the pitch trajectory, the parameter
is utilized to control the maximal frequency shift between frames. If the frequency change of two adjacent frames
is less than the size controlled by the parameter
, the two adjacent frames are considered as continuous frames, as follows:
where
i denotes the index of the initial sequence. Parameter
is critical because it should balance the continuity and the changing trend of the pitch trajectory. Parameter
is set to 0.11 in the proposed pitch estimation method. This value is initially guided by statistical analysis of the TIMIT pitch dataset [
32], and then fine-tuned by experiments. The value of 0.11 is small for the pitch range. For the 100 Hz pitch, the frequency difference is only 100 × 0.11 = 11 Hz. Therefore, increasing the frequency resolution is necessary to distinguish the tiny frequency difference, and the frequency resolution in the proposed method is set to 1 Hz.
The minimal length of the main pitch segment in this paper is set to 140 ms, corresponding to 5 frames for the selected parameter setting. If other hop size
is specified, the minimal number of consecutive frame
needs to be adjusted by:
where
represents the function of rounding the elements of
x to the nearest integers towards infinity, and
denotes the data frame length. The main pitch segment consisting of frames 5 to 9 illustrates how the extension is performed on the main pitch segment in the middle portion of
Figure 5. The main pitch segment is extended forward and backward by searching frequencies from the candidate pitch array, and the frequency that satisfies (
7) is added at the corresponding end of the main pitch segment in turn. Frames 4 to 12 constitute an example of the extension segment, which is then used to replace the corresponding segment of the initial sequence and form the updated sequence. After that, forward and repeat the “find segment” and “extend” processes in the initial sequence until its end.
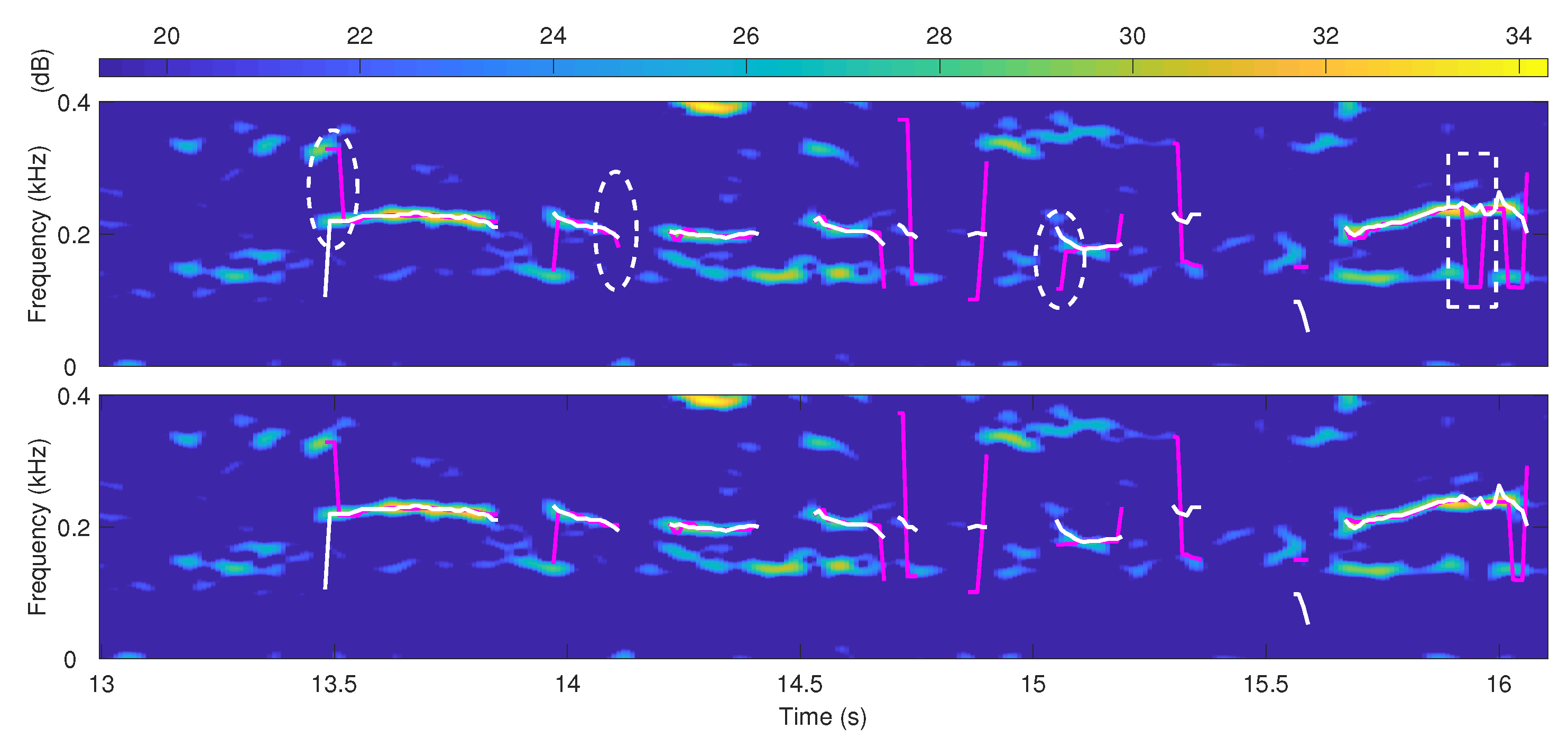
Figure 6 shows how segment extension improves the performance. The improvement mainly includes two aspects highlighted by the circle dashed boxes and the square dashed boxes. The circle dashed box parts reflect the improvement for two pitch segment ends, where the error jumps are reduced by extending the correct pitch segment. The square dashed box part represents the improvement for the errors in the middle of the pitch segment, where the main pitch segment extension scheme enables most correct estimates to suppress short-term error estimates.
3.4. Voiced/Unvoiced Decision
A small modification to the voiced/unvoiced decision of the original SRH method is made and integrated into the proposed method. This subsection will first introduce the scheme of the voiced/unvoiced decision in the original SRH method, and then realize the modification.
The original SRH method realizes the voiced/unvoiced decision through two SRH thresholds. Based on the fact that the SRH value of the voiced segment is higher than that of the unvoiced segment, the original SRH method judges the SRH values corresponding to the pitch sequence, and generates voiced/unvoiced decisions for threshold values higher or not higher than the threshold. This threshold is set to 0.07 in the code. Besides, a threshold adjustment is realized by judging the standard deviation of the SRH values. When the standard deviation exceeds 0.05, the threshold 0.07 is increased to 0.085. This concept of double threshold is inherited also in the proposed method. The threshold adjustment is beneficial to improve the adaptability to different SNR conditions. Because a larger standard deviation means a higher SRH dispersion degree, and a higher SRH dispersion degree generally means a higher SNR.
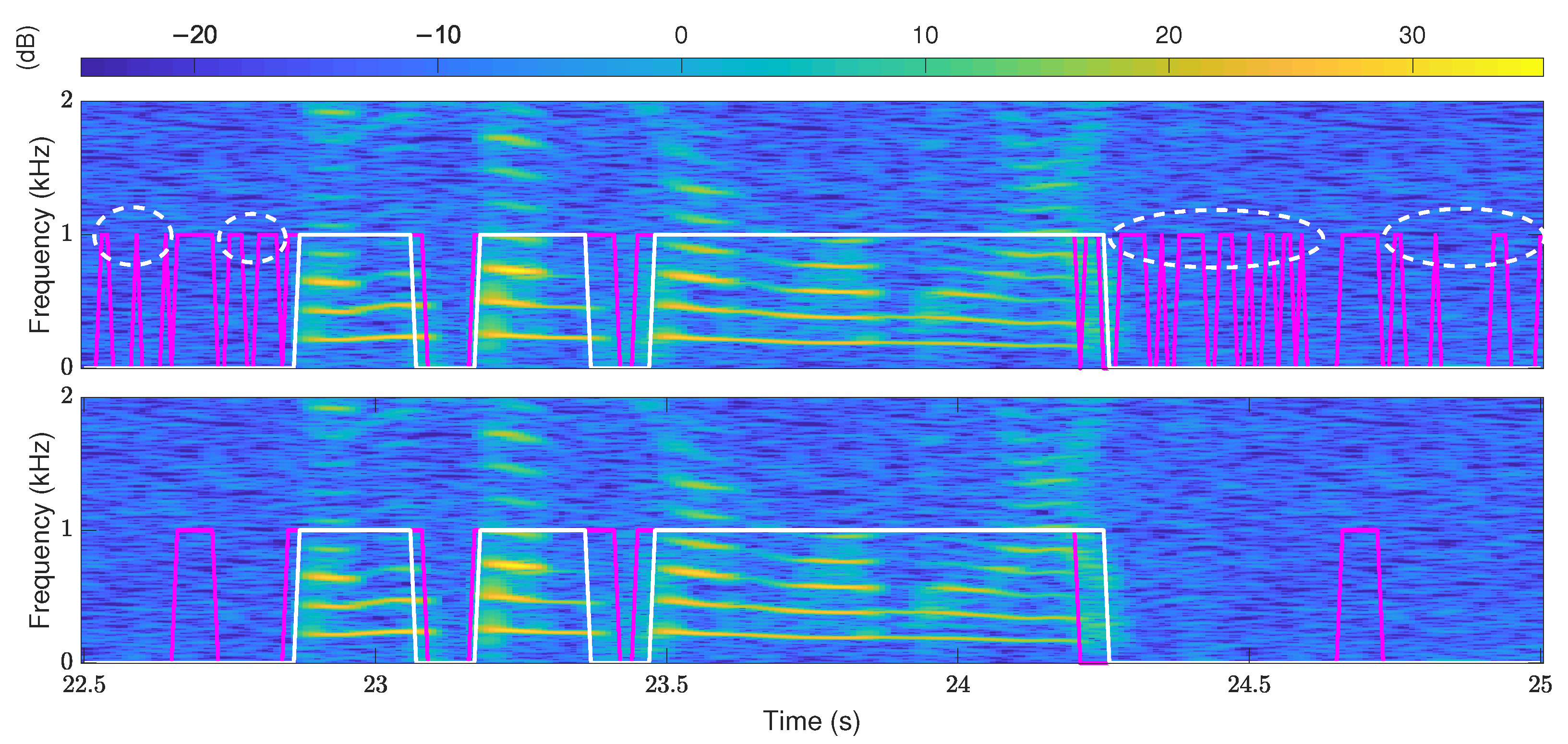
The above voiced/unvoiced decision lacks the consideration of continuity, which leads to temporary errors. As shown by the upper one in
Figure 7, many temporary voiced decisions that differ from the ground truth are short-term errors. The modification handles the temporary errors by adding a judgment on the voiced/unvoiced decision results. The time of consecutive voiced decisions is checked, and the voiced decisions that are less than a time threshold are modified as unvoiced. The time threshold is set to 140 ms, which is the same as the threshold of the main pitch segment. The results of the modified voiced/unvoiced decisions are shown by the lower one in
Figure 7. It can be seen that the modified voiced/unvoiced decision effectively reduces multiple short-term errors circled by the white dotted lines.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}