
Intelligent Diagnosis Based on Double-Optimized Artificial Hydrocarbon Networks for Mechanical Faults of In-Wheel Motor


Abstract
:1. Introduction
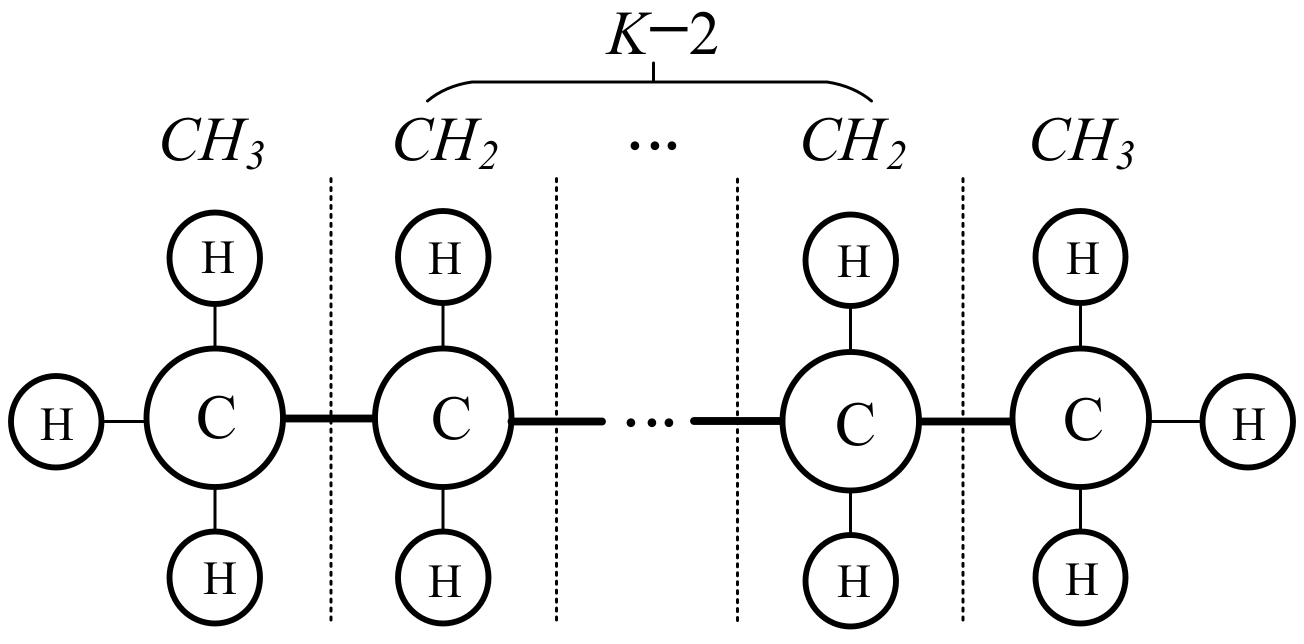
2. Artificial Hydrocarbon Networks
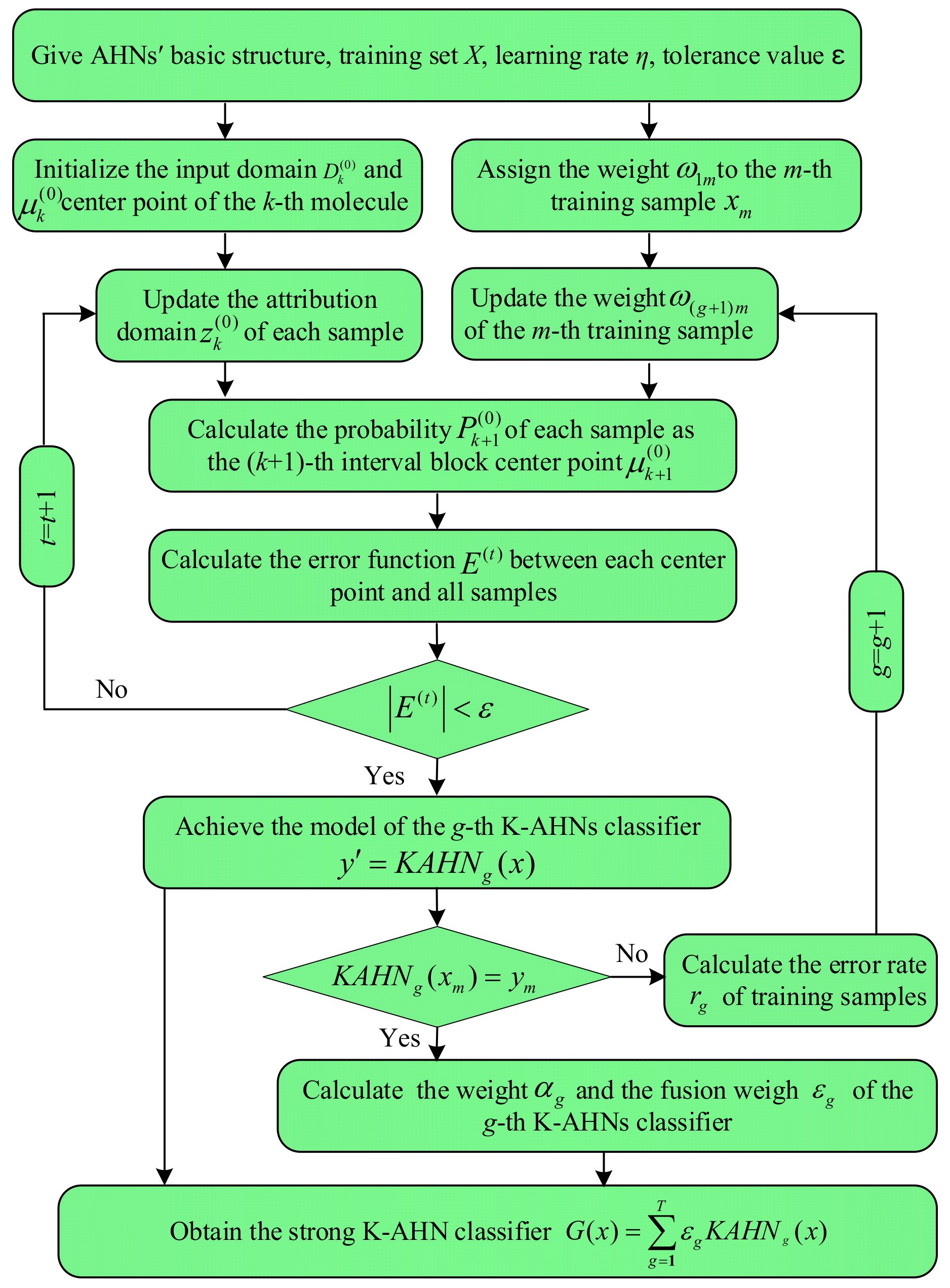
3. Double-Optimized AHNs
3.1. AHNs’ Model Optimization Based on K-Means
3.2. K-AHNs’ Model Optimization Based on AdaBoost
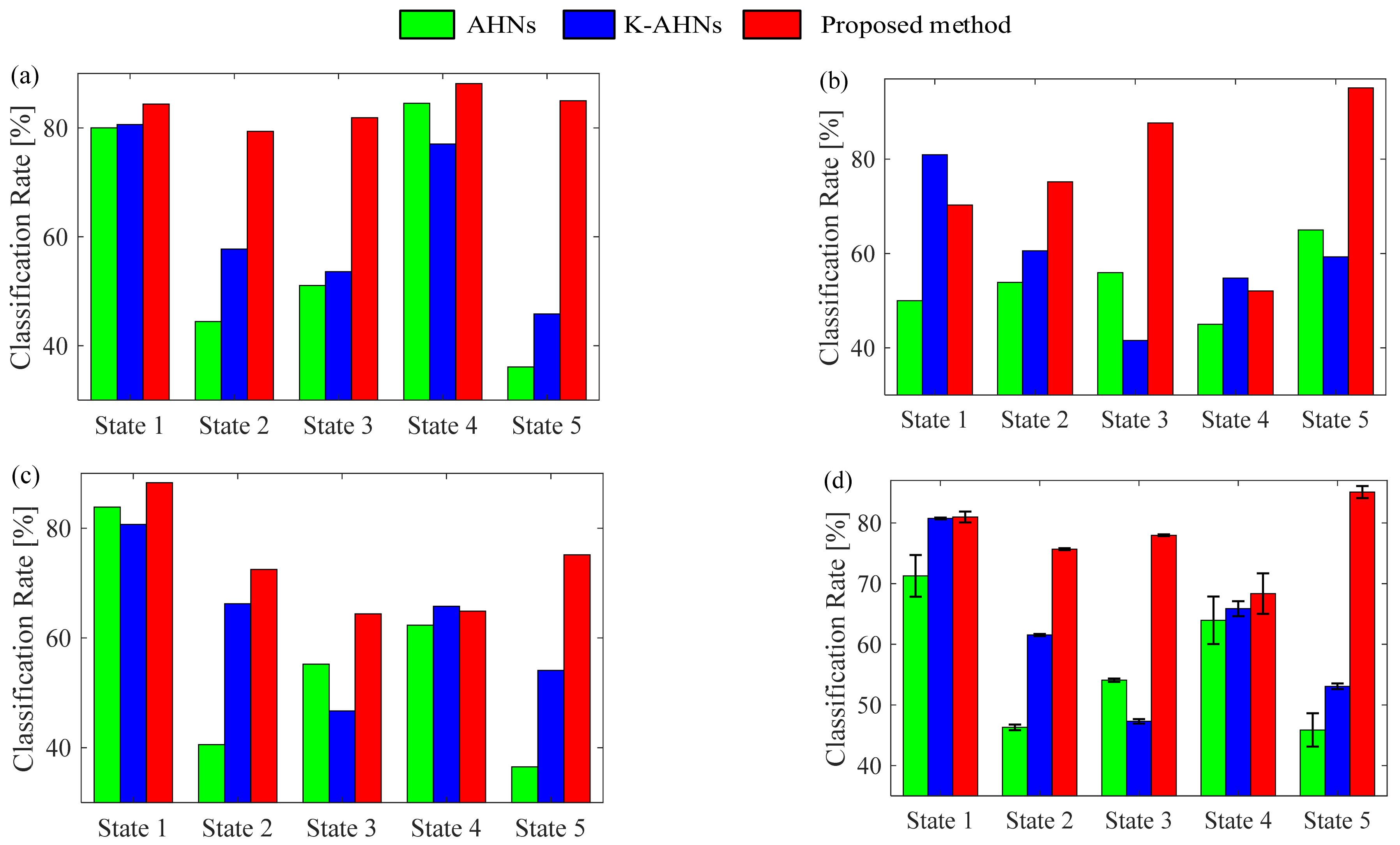
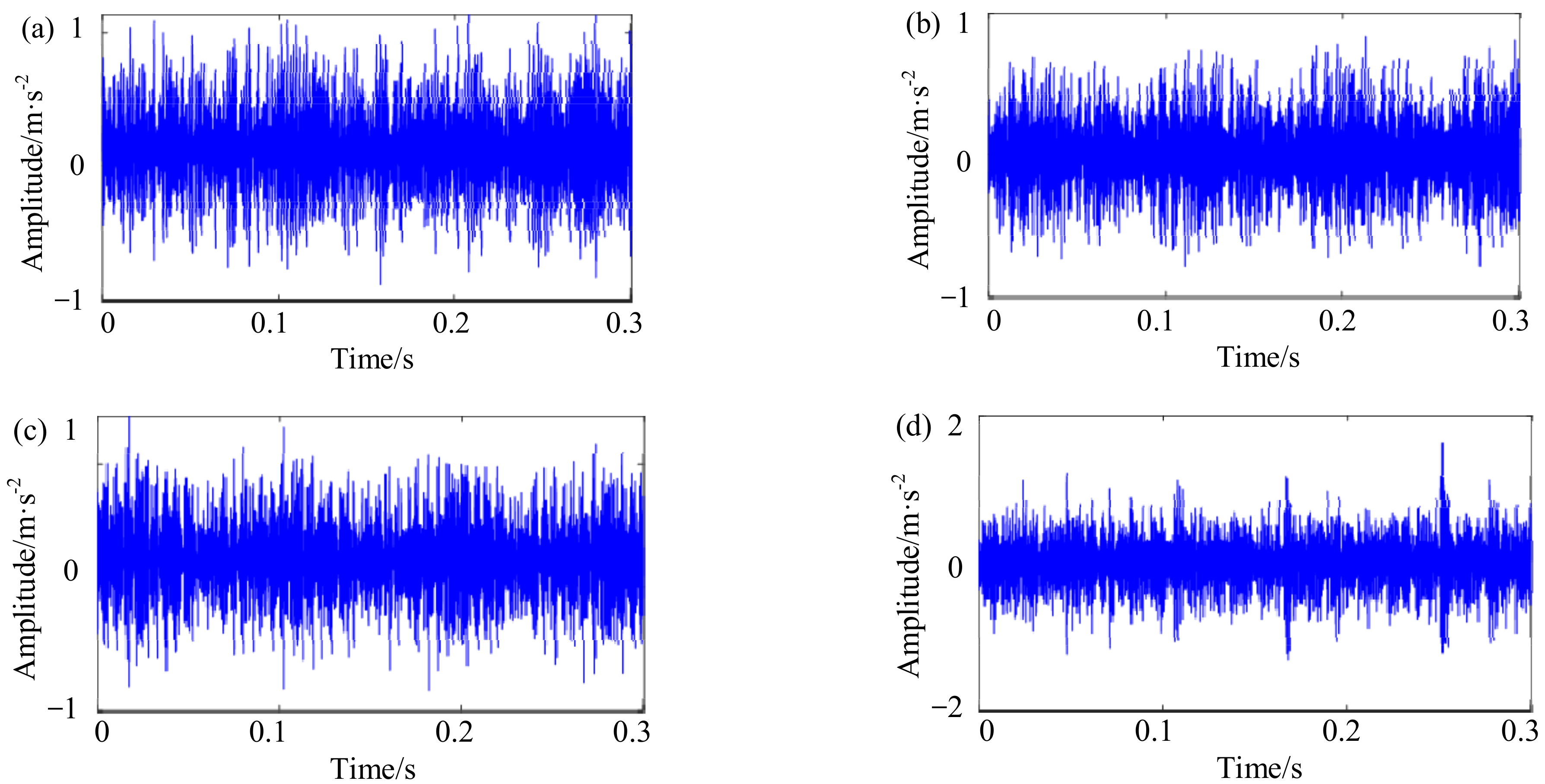
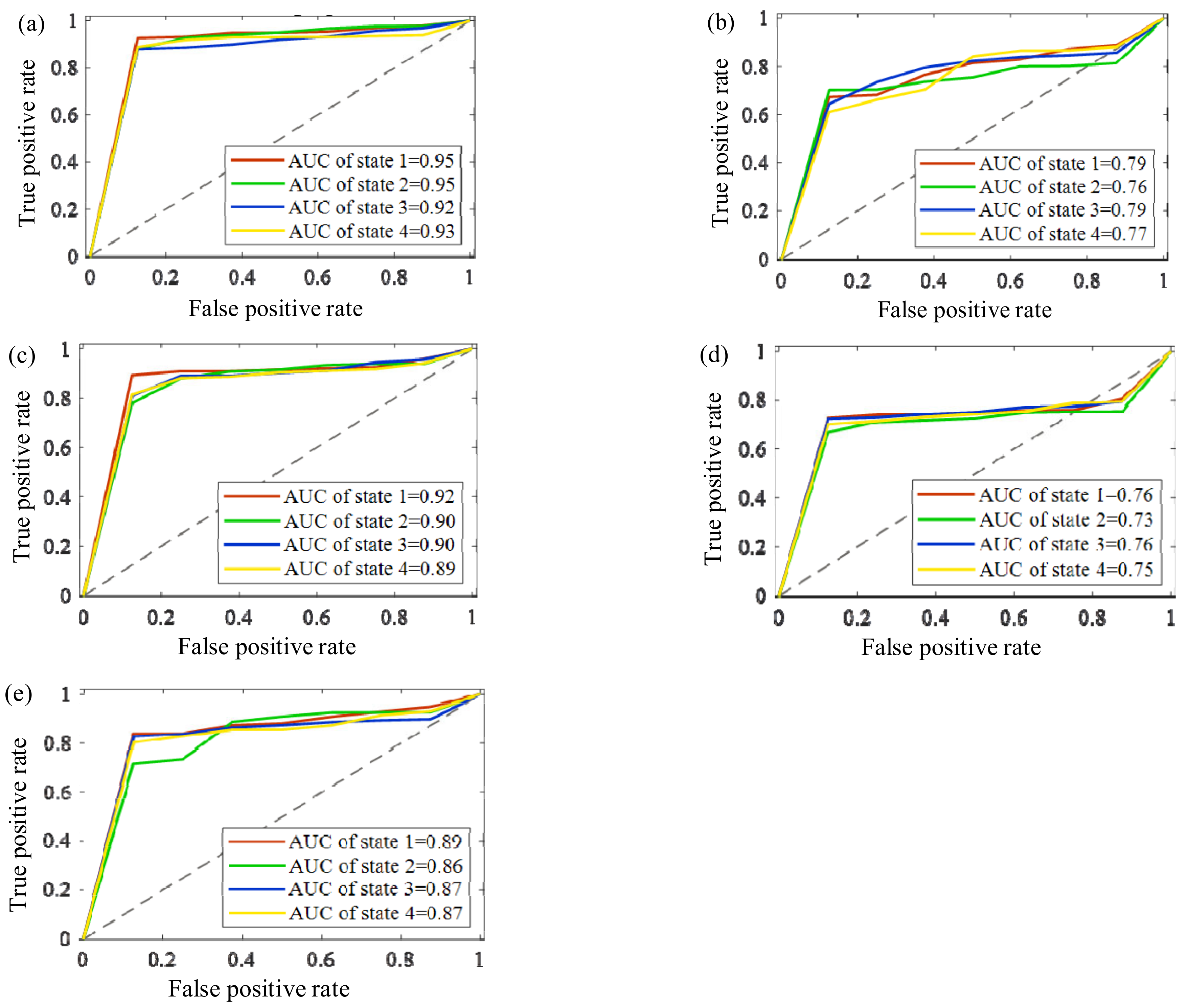
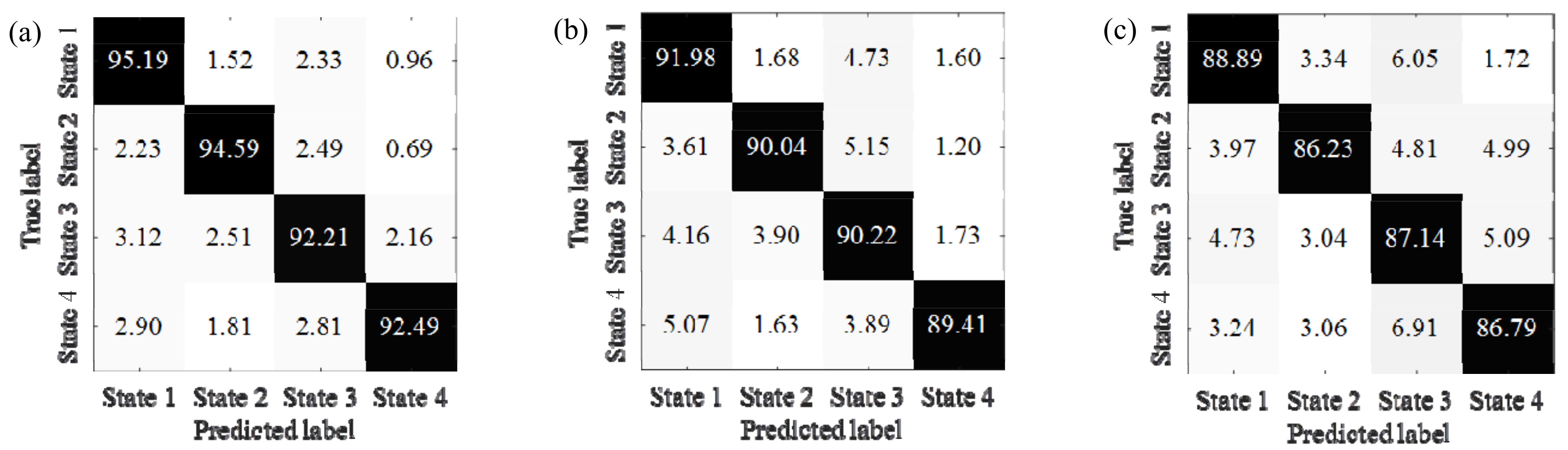
4. Experimental Verification
4.1. Case 1: The Bearing Data from Paderborn University
4.2. Case 2: The Bearing Data from Self-Made IWM Test Stand
5. Conclusions
- (1)
- K-means clustering and AdaBoost are used to optimize the AHNs algorithm, which not only simplify the complexity of the AHNs model, but also reconstitute the network structure of the AHNs; as a result, the double-optimized AHNs displays excellent performance due to the organic fusion of AHNs, K-means clustering, and AdaBoost mainly.
- (2)
- As long as the intelligent diagnosis system is built by the double-optimized AHNs, no matter how the rotating speed and load conditions of the IWM are altered, the high classification accuracy can be obtained. It is attributed primarily to the strong robustness of double-optimized AHNs.
- (3)
- The intelligent diagnosis method based on the double-optimized AHNs can avoid selecting configuration parameters and adaptively distribute the weight of multiple weak models for a strong classifier.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, F.; Zhang, J.; Xu, X.; Cai, Y.; Zhou, Z.; Sun, X. New teeth surface and back (TSB) modification method for transient torsional vibration suppression of planetary gear powertrain for an electric vehicle. Mech. Mach. Theory 2019, 140, 520–537. [Google Scholar] [CrossRef]
- Chen, L.; Xu, H.; Sun, X. A novel strategy of control performance improvement for six-phase permanent magnet synchronous hub motor drives of EVs under new European driving cycle. IEEE Trans. Veh. Technol. 2021, 70, 5628–5637. [Google Scholar] [CrossRef]
- Xue, H.; Ding, D.; Zhang, Z.; Wu, M.; Wang, H. A fuzzy system of operation safety assessment using multimodel linkage and multistage collaboration for in-wheel motor. IEEE Trans. Fuzzy Syst. 2022, 30, 999–1013. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Ruan, J.; Song, Q.; Yang, W. The application of hybrid energy storage system with electrified continuously variable transmission in battery electric vehicle. Energy 2019, 183, 315–330. [Google Scholar] [CrossRef]
- Najjari, B.; Mirzaei, M.; Tahouni, A. Constrained stability control with optimal power management strategy for in-wheel electric vehicles. Proc. Inst. Mech. Eng. Part K J. Multi Body Dyn. 2019, 233, 1014–1032. [Google Scholar] [CrossRef]
- Tang, Z.; Xu, X.; Wang, F.; Jiang, X.; Jiang, H. Coordinated control for path following of two-wheel independently actuated autonomous ground vehicle. IET Intell. Transp. Syst. 2019, 13, 628–635. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.; Chen, Z.; Zhao, J. Intelligent fault diagnosis for rotating machinery based on potential energy feature and adaptive transfer affinity propagation clustering. Meas. Sci. Technol. 2021, 32, 1–13. [Google Scholar] [CrossRef]
- Sun, W.; Yao, B.; Zeng, N.; Chen, B.; He, Y.; Cao, X.; He, W. An intelligent gear fault diagnosis methodology using a complex wavelet enhanced convolutional neural network. Materials 2017, 10, 790. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA–DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]
- Wei, Z.; Wang, Y.; He, S.; Bao, J. A novel intelligent method for bearing fault diagnosis based on affinity propagation clustering and adaptive feature selection. Knowl. Based Syst. 2017, 116, 1–12. [Google Scholar] [CrossRef]
- Han, C.; Lu, W.; Wang, P.; Song, L.; Wang, H. A recursive sparse representation strategy for bearing fault diagnosis. Measurement 2022, 187, 110360. [Google Scholar] [CrossRef]
- Bian, K.; Zhou, M.; Hu, F.; Lai, W. RF-PCA: A new solution for rapid identification of breast cancer categorical data based on attribute selection and feature extraction. Front. Genet. 2020, 11, 566057. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Liang, K.; Shi, P. Intelligent fault diagnosis of rotating machinery based on deep learning with feature selection. J. Low Freq. Noise Vib. Act. Control. 2020, 39, 939–953. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust target recognition and tracking of self-driving cars with radar and camera information fusion under severe weather conditions. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Indianapolis, IN, USA, 19–22 September 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Lv, X.; Zhou, D.; Ma, L.; Zhang, Y.; Tang, Y. An improved lagrange particle swarm optimization algorithm and its application in multiple fault diagnosis. Shock. Vib. 2020, 2020, 1091548. [Google Scholar] [CrossRef]
- Ji, W.; Cheng, C.; Xie, G.; Zhu, L.; Wang, Y.; Pan, L.; Hei, X. An intelligent fault diagnosis method based on curve segmentation and SVM for rail transit turnout. J. Intell. Fuzzy Syst. 2021, 41, 4275–4285. [Google Scholar] [CrossRef]
- Xue, H.; Wang, M.; Li, Z.; Chen, P. Sequential fault detection for sealed deep groove ball bearings of in-wheel motor in variable operating conditions. J. Vibroeng. 2018, 19, 5947–5959. [Google Scholar] [CrossRef]
- Feng, D.; Li, Y. Research on intelligent diagnosis method for large-scale ship engine fault in non-deterministic environment. Pol. Marit. Res. 2017, 24, 200–206. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. A novel prediction network for remaining useful life of rotating machinery. Int. J. Adv. Manuf. Technol. 2022, 1–10. [Google Scholar] [CrossRef]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. Intelligent fault diagnosis of rotor-bearing system under varying working conditions with modified transfer convolutional neural network and thermal images. IEEE Trans. Ind. Inform. 2020, 17, 3488–3496. [Google Scholar]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Processing 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Cheng, Y.; Lin, M.; Wu, J.; Zhu, H.; Shao, X. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowl. Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Wang, P.; Song, L.; Guo, X.; Wang, H.; Cui, L. A high-stability diagnosis model based on a multiscale feature fusion convolutional neural network. IEEE Trans. Instrum. Meas. 2021, 70, 3522709. [Google Scholar] [CrossRef]
- Wang, H.; Lin, T.; Cui, L.; Ma, B.; Dong, Z.; Song, L. Multi-task learning-based self-attention encoding atrous convolutional neural network for remaining useful life prediction. IEEE Trans. Instrum. Meas. 2022, 71, 3516108. [Google Scholar]
- Sun, G.-D.; Wang, Y.-R.; Sun, C.-F.; Jin, Q. Intelligent detection of a planetary gearbox composite fault based on adaptive separation and deep learning. Sensors 2019, 19, 5222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [Green Version]
- Haidong, S.; Hongkai, J.; Ke, Z.; Dongdong, W.; Xingqiu, L. A novel tracking deep wavelet auto-encoder method for intelligent fault diagnosis of electric locomotive bearings. Mech. Syst. Signal Processing 2018, 110, 193–209. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Li, Y.; Yan, Y. Bearing fault diagnosis with auto-encoder extreme learning machine: A comparative study. Proc. Inst. Mech. Eng. Part C: J. Mech. Eng. Sci. 2017, 231, 1560–1578. [Google Scholar] [CrossRef]
- Xue, H.; Zhou, J.; Chen, Z.; Li, Z. Real-time diagnosis of an in-wheel motor of an electric vehicle based on dynamic Bayesian networks. IEEE Access 2019, 7, 114685–114699. [Google Scholar] [CrossRef]
- Schmid, M.; Gebauer, E.; Hanzl, C.; Endisch, C. Active model-based fault diagnosis in reconfigurable battery systems. IEEE Trans. Power Electron. 2021, 36, 2584–2597. [Google Scholar] [CrossRef]
- Glowacz, A.; Tadeusiewicz, R.; Legutko, S.; Caesarendra, W.; Irfan, M.; Liu, H.; Brumercik, F.; Gutten, M.; Sulowicz, M.; Daviu, J.A.A.; et al. Fault diagnosis of angle grinders and electric impact drills using acoustic signals. Appl. Acoust. 2021, 179, 108070. [Google Scholar] [CrossRef]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Wang, W.; Wang, M.; Li, J.; Song, L.; Hao, Y. A novel signal separation method based on improved sparse non-negative matrix factorization. Entropy 2019, 21, 445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.-B.; Luo, L.; Tang, L.; Yang, Z.-X. Automatic representation and detection of fault bearings in in-wheel motors under variable load conditions. Adv. Eng. Inform. 2021, 49, 101321. [Google Scholar] [CrossRef]
- Xue, H.; Wu, M.; Zhang, Z.; Wang, H. Intelligent diagnosis of mechanical faults of in-wheel motor based on improved artificial hydrocarbon networks. ISA Trans. 2022, 120, 360–371. [Google Scholar] [CrossRef]
- Ponce, H.; Miralles-Pechuán, L.; Martínez-Villaseñor, M. A flexible approach for human activity recognition using artificial hydrocarbon networks. Sensors 2016, 16, 1715. [Google Scholar] [CrossRef] [Green Version]
- Ponce, H.; Martinez-Villasenor, M.; Miralles-Pechuan, L. A novel wearable sensor-based human activity recognition approach using artificial hydrocarbon networks. Sensors 2016, 16, 1033. [Google Scholar] [CrossRef]
- Ponce, H. A novel artificial hydrocarbon networks based value function approximation in hierarchical reinforcement learning. In Mexican International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2016; pp. 211–225. [Google Scholar]
- Yu, K.; Lin, T.R.; Ma, H.; Li, X.; Li, X. A multi-stage semi-supervised learning approach for intelligent fault diagnosis of rolling bearing using data augmentation and metric learning. Mech. Syst. Signal Processing 2021, 146, 107043. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys. Technol. 2017, 81, 7–16. [Google Scholar] [CrossRef]
- He, Y.-L.; Zhao, Y.; Hu, X.; Yan, X.-N.; Zhu, Q.-X.; Xu, Y. Fault diagnosis using novel AdaBoost based discriminant locality preserving projection with resamples. Eng. Appl. Artif. Intell. 2020, 91, 103631. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, G.; Paul, P.; Zhang, J.; Wu, T.; Fan, S.; Xiong, X. Dissolved gas analysis for transformer fault based on learning spiking neural P system with belief AdaBoost. Int. J. Unconv. Comput. 2021, 16, 239–258. [Google Scholar]
- Long, Z.; Zhang, X.; Zhang, L.; Qin, G.; Huang, S.; Song, D.; Shao, H.; Wu, G. Motor fault diagnosis using attention mechanism and improved adaboost driven by multi-sensor information. Measurement 2021, 170, 108718. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the European Conference of the Prognostics and Health Management Society (PHM Society), Bilbao, Spain, 5–7 July 2016. [Google Scholar]
- Chen, J.; Pan, J.; Li, Z.; Zi, Y.; Chen, X. Generator bearing fault diagnosis for wind turbine via empirical wavelet transform using measured vibration signals. Renew. Energy 2016, 89, 80–92. [Google Scholar] [CrossRef]
- Xue, H.T.; Liu, B.C.; Ding, D.Y.; Zhou, J.; Cui, X. Diagnosis method based on hidden Markov model and Weibull mixture model for mechanical faults of in-wheel motor. Meas. Sci. Technol. 2022, 33, 114002. [Google Scholar] [CrossRef]
- Xue, H.; Li, Z.; Li, Y.; Jiang, H.; Chen, P. A fuzzy diagnosis of multi-fault state based on information fusion from multiple sensors. J. Vibroeng. 2016, 18, 2135–2148. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating Condition | AHNs | K-AHNs | Proposed Method | ||||
|---|---|---|---|---|---|---|---|
| Speed [rpm] | Load [Nm] | Training [s] | Test [s] | Training [s] | Test [s] | Training [s] | Test [s] |
| 1500 | 0.7 | 35.21 | 14.73 | 4.50 | 2.45 | 9.69 | 2.58 |
| 900 | 0.7 | 31.60 | 13.69 | 4.75 | 2.16 | 8.76 | 1.95 |
| 1500 | 0.1 | 35.47 | 14.74 | 4.56 | 2.10 | 8.89 | 2.13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, H.; Song, Z.; Wu, M.; Sun, N.; Wang, H. Intelligent Diagnosis Based on Double-Optimized Artificial Hydrocarbon Networks for Mechanical Faults of In-Wheel Motor. Sensors 2022, 22, 6316. https://doi.org/10.3390/s22166316
Xue H, Song Z, Wu M, Sun N, Wang H. Intelligent Diagnosis Based on Double-Optimized Artificial Hydrocarbon Networks for Mechanical Faults of In-Wheel Motor. Sensors. 2022; 22(16):6316. https://doi.org/10.3390/s22166316
Chicago/Turabian StyleXue, Hongtao, Ziwei Song, Meng Wu, Ning Sun, and Huaqing Wang. 2022. "Intelligent Diagnosis Based on Double-Optimized Artificial Hydrocarbon Networks for Mechanical Faults of In-Wheel Motor" Sensors 22, no. 16: 6316. https://doi.org/10.3390/s22166316
APA StyleXue, H., Song, Z., Wu, M., Sun, N., & Wang, H. (2022). Intelligent Diagnosis Based on Double-Optimized Artificial Hydrocarbon Networks for Mechanical Faults of In-Wheel Motor. Sensors, 22(16), 6316. https://doi.org/10.3390/s22166316