


Cross-Language Speech Emotion Recognition Using Bag-of-Word Representations, Domain Adaptation, and Data Augmentation

Abstract
:1. Introduction
- We explore the combination of DA and BoW for improved cross-language SER. Experiments with the BoW methodology before or after domain adaptation are performed to assess their advantages/disadvantages. Different DA methods are explored to gauge their effects on overall cross-language SER. In particular, the CORAL [22], and Subspace alignment-based domain adaptation (SA-DA) are compared.
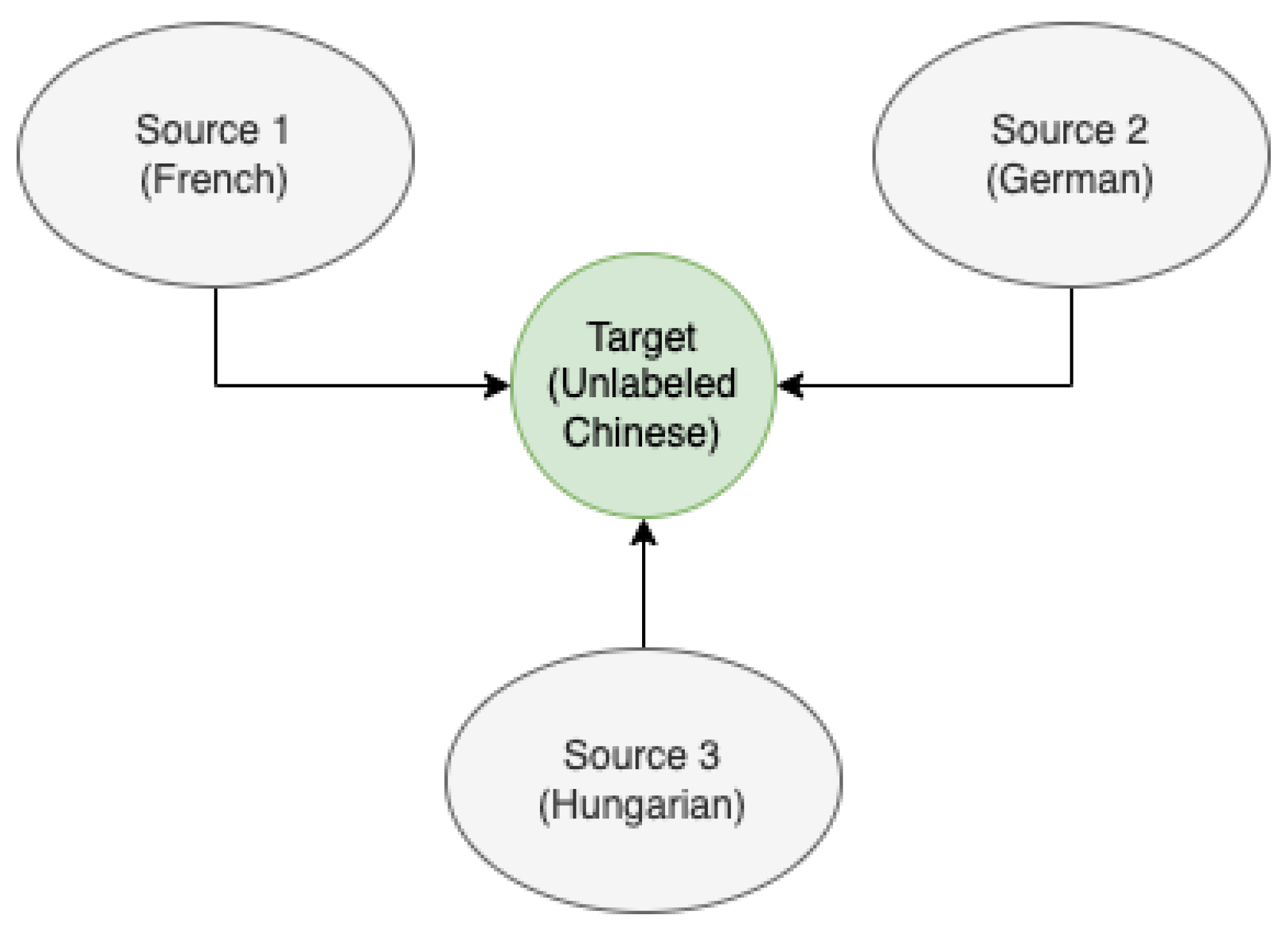
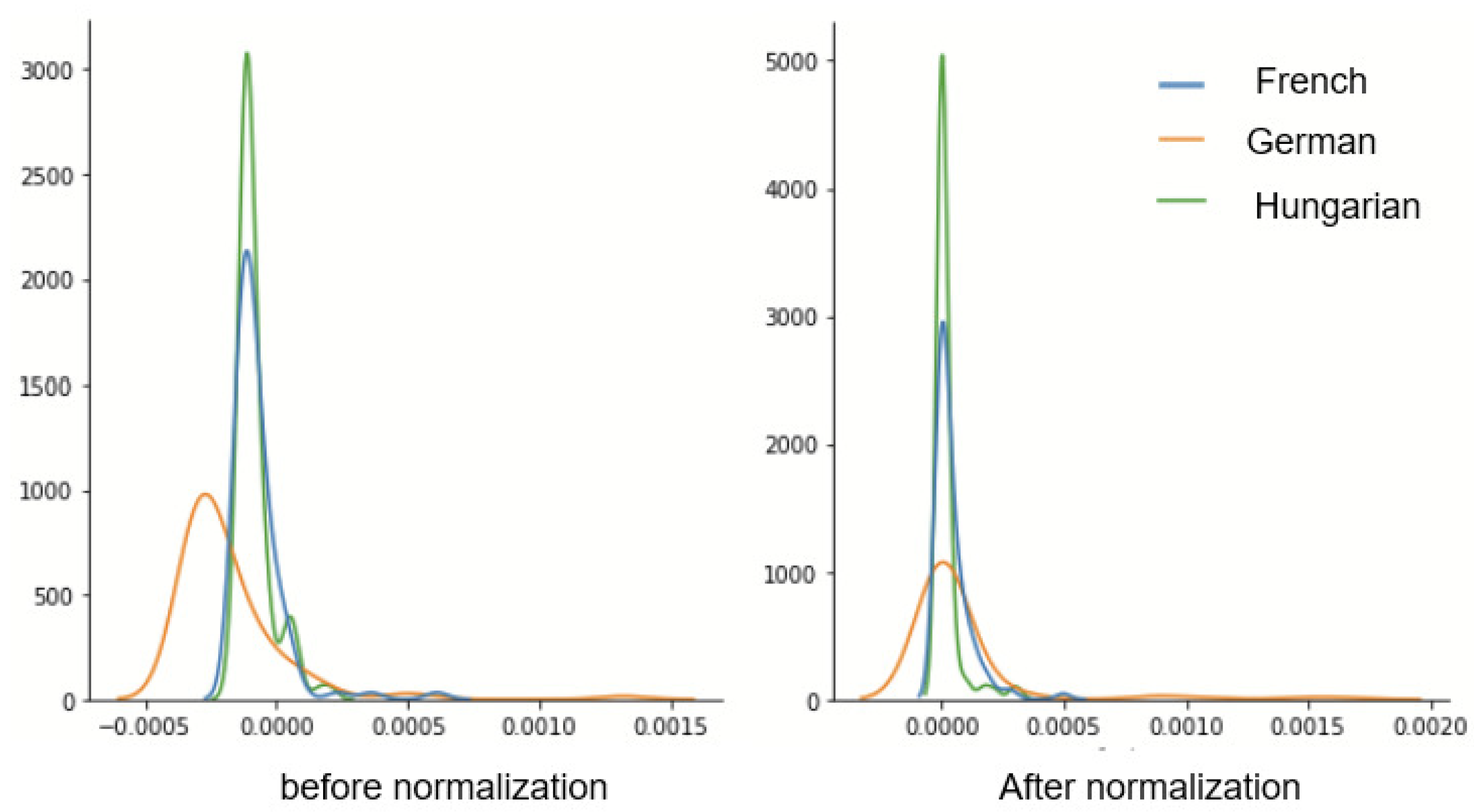
- A variant of the CORAL method is proposed for cross-language SER. The method, termed N-CORAL, makes use of a third unseen unlabeled dataset/language to adapt both domain and source data, in essence normalizing both training and test datasets to a common distribution, as typically done with domain generalization.
- Lastly, we explore the added benefits of data augmentation, on top of BoW and DA, for cross-language SER.
2. Related Work
2.1. Cross-Language SER
2.2. Multilingual Training and Data Augmentation for SER
2.3. Domain Adaptation for SER
2.4. Domain Generalization for SER
3. Proposed Method
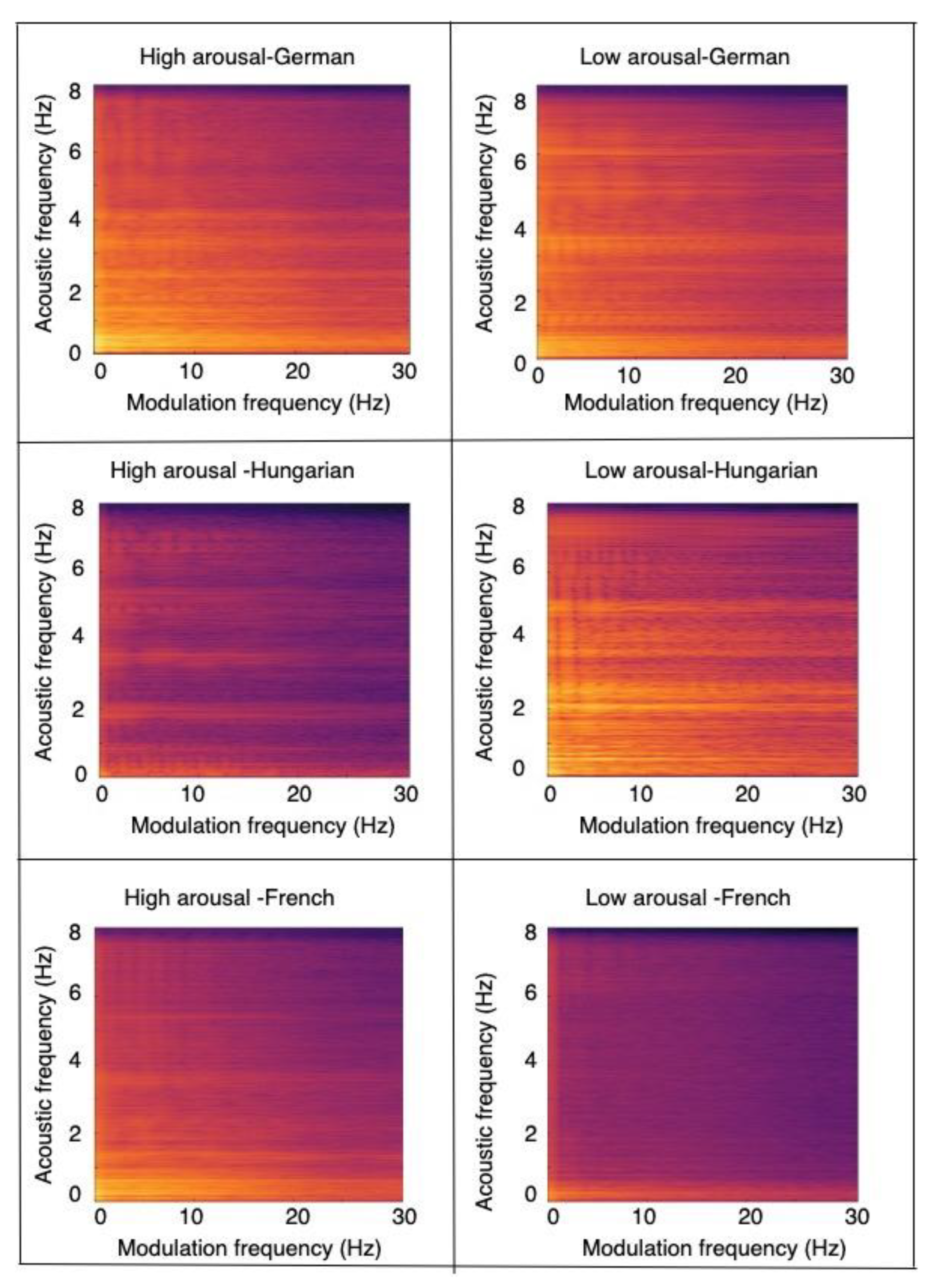
3.1. Speech Feature Extraction
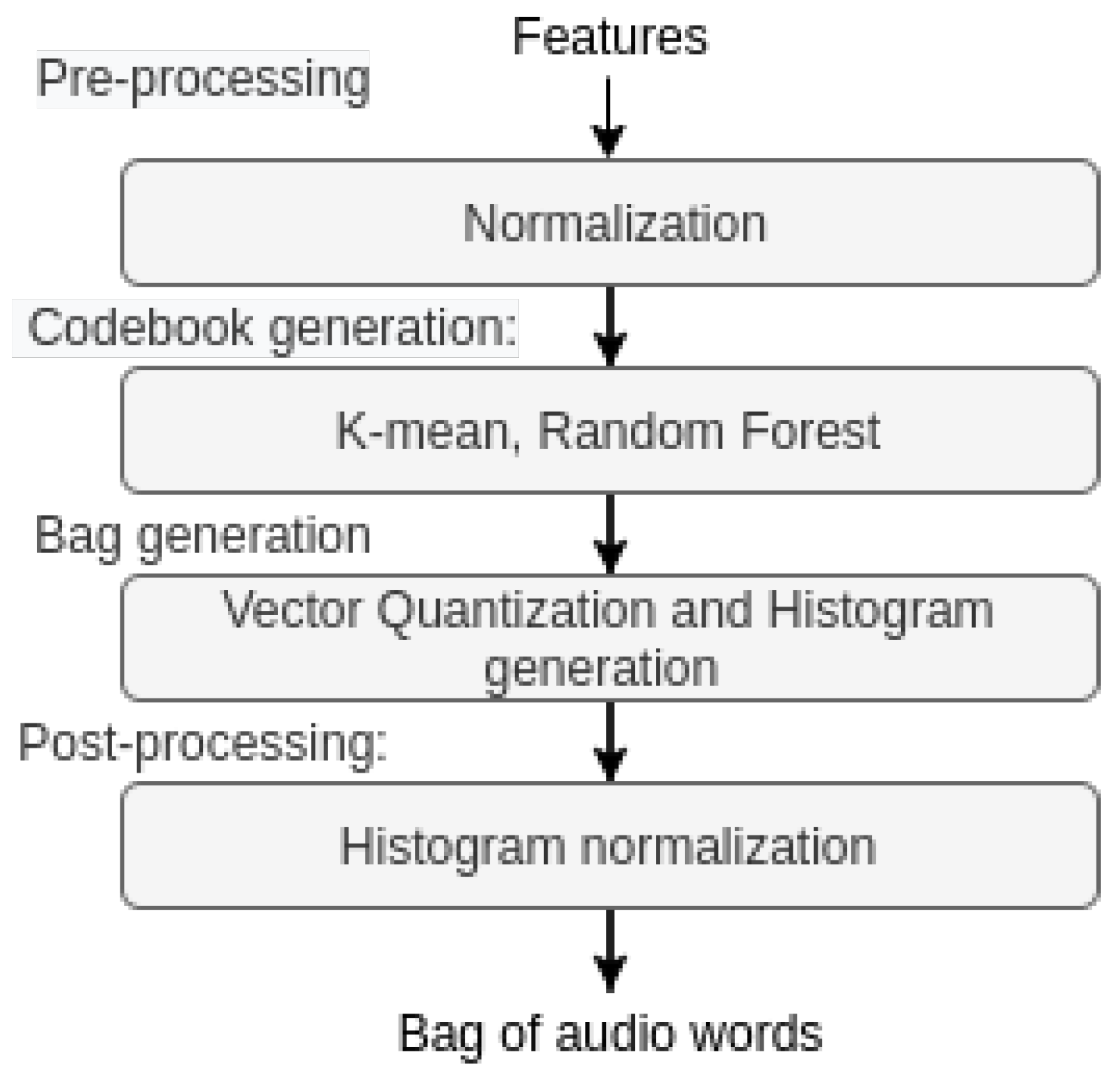
3.2. Bag-of-Words Methodology
3.3. Domain Adaptation/Generalization
3.3.1. Subspace Alignment-Based Domain Adaptation
3.3.2. Correlation Alignment
3.3.3. Domain Generalization with CORAL
4. Experimental Setup
4.1. Databases
4.2. Regression Model
4.3. Data Augmentation
4.4. Benchmark Systems
4.5. Figure-of-Merit, Testing setUp, and Experimental Aims
5. Experimental Results and Discussion
5.1. Ablation Study
5.2. Proposed System
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feraru, S.M.; Schuller, D. Cross-language acoustic emotion recognition: An overview and some tendencies. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Xi’an, China, 21–24 September 2015; pp. 125–131. [Google Scholar]
- Neumann, M. Cross-lingual and Multilingual Speech Emotion Recognition on English and French. arXiv 2018, arXiv:1803.00357. [Google Scholar]
- Hozjan, V.; Kačič, Z. Context-independent multilingual emotion recognition from speech signals. Int. J. Speech Technol. 2003, 6, 311–320. [Google Scholar] [CrossRef]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Cross Corpus Speech Emotion Classification-An Effective Transfer Learning Technique. arXiv 2018, arXiv:1801.06353. [Google Scholar]
- Lefter, I.; Rothkrantz, L.J.; Wiggers, P.; Leeuwen, D.A. Emotion recognition from speech by combining databases and fusion of classifiers. In Proceedings of the International Conference on Text, Speech and Dialogue, Czech Republic, 6–10 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 353–360. [Google Scholar]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Wöllmer, M.; Stuhlsatz, A.; Wendemuth, A.; Rigoll, G. Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar] [CrossRef]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. arXiv 2017, arXiv:1706.00612. [Google Scholar]
- Sagha, H.; Deng, J.; Gavryukova, M.; Han, J.; Schuller, B. Cross lingual speech emotion recognition using canonical correlation analysis on principal component subspace. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 5800–5804. [Google Scholar]
- Chiou, B.C.; Chen, C.P. Speech Emotion Recognition with Cross-lingual Databases. In Proceedings of the Interspeech, Singapore, 14–18 September 2014. [Google Scholar]
- Sagha, H.; Matejka, P.; Gavryukova, M.; Povolný, F.; Marchi, E.; Schuller, B. Enhancing Multilingual Recognition of Emotion in Speech by Language Identification. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 2949–2953. [Google Scholar]
- Hassan, A.; Damper, R.; Niranjan, M. On acoustic emotion recognition: Compensating for covariate shift. IEEE Trans. Audio, Speech, Lang. Process. 2013, 21, 1458–1468. [Google Scholar] [CrossRef]
- Song, P.; Zheng, W.; Ou, S.; Zhang, X.; Jin, Y.; Liu, J.; Yu, Y. Cross-corpus speech emotion recognition based on transfer non-negative matrix factorization. Speech Commun. 2016, 83, 34–41. [Google Scholar] [CrossRef]
- Wang, D.; Zheng, T.F. Transfer learning for speech and language processing. arXiv 2015, arXiv:1511.06066. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A. AVEC 2018 workshop and challenge: Bipolar disorder and cross-cultural affect recognition. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Korea, 22 October 2018. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cummins, N.; Cowie, R.; Tavabi, L.; Schmitt, M.; Alisamir, S.; Amiriparian, S.; Messner, E.M.; et al. AVEC 2019 Workshop and Challenge: State-of-Mind, Depression with AI, and Cross-Cultural Affect Recognition. In Proceedings of the 2019 on Audio/Visual Emotion Challenge and Workshop, Nice, France, 21–25 October 2019. [Google Scholar]
- Kshirsagar, S.R.; Falk, T.H. Quality-Aware Bag of Modulation Spectrum Features for Robust Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- Cummins, N.; Amiriparian, S.; Ottl, S.; Gerczuk, M.; Schmitt, M.; Schuller, B. Multimodal bag-of-words for cross domains sentiment analysis. In Proceedings of the 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4954–4958. [Google Scholar]
- Seo, M.; Kim, M. Fusing visual attention CNN and bag of visual words for cross-corpus speech emotion recognition. Sensors 2020, 20, 5559. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.; Feng, J.; Saenko, K. Correlation alignment for unsupervised domain adaptation. In Domain Adaptation in Computer Vision Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 153–171. [Google Scholar]
- Eyben, F.; Batliner, A.; Schuller, B.; Seppi, D.; Steidl, S. Cross-corpus classification of realistic emotions–some pilot experiments. In Proceedings of the 7th International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Xiao, Z.; Wu, D.; Zhang, X.; Tao, Z. Speech emotion recognition cross language families: Mandarin vs. western languages. In Proceedings of the 2016 International Conference on Progress in Informatics and Computing (PIC), Shanghai, China, 23–25 December 2016; pp. 253–257. [Google Scholar]
- Albornoz, E.M.; Milone, D.H. Emotion recognition in never-seen languages using a novel ensemble method with emotion profiles. IEEE Trans. Affect. Comput. 2015, 8, 43–53. [Google Scholar] [CrossRef]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Transfer learning for improving speech emotion classification accuracy. arXiv 2018, arXiv:1801.06353. [Google Scholar]
- Ning, Y.; Wu, Z.; Li, R.; Jia, J.; Xu, M.; Meng, H.; Cai, L. Learning cross-lingual knowledge with multilingual BLSTM for emphasis detection with limited training data. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5615–5619. [Google Scholar]
- Zhang, Y.; Liu, Y.; Weninger, F.; Schuller, B. Multi-task deep neural network with shared hidden layers: Breaking down the wall between emotion representations. In Proceedings of the 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4990–4994. [Google Scholar]
- Parry, J.; Palaz, D.; Clarke, G.; Lecomte, P.; Mead, R.; Berger, M.; Hofer, G. Analysis of Deep Learning Architectures for Cross-Corpus Speech Emotion Recognition. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 1656–1660. [Google Scholar]
- Kim, J.; Englebienne, G.; Truong, K.P.; Evers, V. Towards speech emotion recognition" in the wild" using aggregated corpora and deep multi-task learning. arXiv 2017, arXiv:1708.03920. [Google Scholar]
- Schuller, B.; Zhang, Z.; Weninger, F.; Rigoll, G. Using multiple databases for training in emotion recognition: To unite or to vote? In Proceedings of the Interspeech, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Li, X.; Akagi, M. Improving multilingual speech emotion recognition by combining acoustic features in a three-layer model. Speech Commun. 2019, 110, 1–12. [Google Scholar] [CrossRef]
- Zhang, Z.; Weninger, F.; Wöllmer, M.; Schuller, B. Unsupervised learning in cross-corpus acoustic emotion recognition. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, Waikoloa, HI, USA, 11–15 December 2011; pp. 523–528. [Google Scholar]
- Shami, M.; Verhelst, W. Automatic classification of expressiveness in speech: A multi-corpus study. In Speaker Classification II; Springer: Berlin/Heidelberg, Germany, 2007; pp. 43–56. [Google Scholar]
- Schuller, B.; Zhang, Z.; Weninger, F.; Rigoll, G. Selecting training data for cross-corpus speech emotion recognition: Prototypicality vs. generalization. In Proceedings of the Afeka-AVIOS Speech Processing Conference, Tel Aviv, Israel, 22 June 2011. [Google Scholar]
- Latif, S.; Qayyum, A.; Usman, M.; Qadir, J. Cross lingual speech emotion recognition: Urdu vs. western languages. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 88–93. [Google Scholar]
- Zong, Y.; Zheng, W.; Zhang, T.; Huang, X. Cross-corpus speech emotion recognition based on domain-adaptive least-squares regression. IEEE Signal Process. Lett. 2016, 23, 585–589. [Google Scholar] [CrossRef]
- Song, P.; Jin, Y.; Zhao, L.; Xin, M. Speech emotion recognition using transfer learning. IEICE Trans. Inf. Syst. 2014, 97, 2530–2532. [Google Scholar] [CrossRef]
- Abdelwahab, M.; Busso, C. Supervised domain adaptation for emotion recognition from speech. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Queensland, Australia, 19–24 April 2015; pp. 5058–5062. [Google Scholar]
- Abdelwahab, M.; Busso, C. Ensemble feature selection for domain adaptation in speech emotion recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5000–5004. [Google Scholar]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse autoencoder-based feature transfer learning for speech emotion recognition. In Proceedings of the Affective Computing and Intelligent Interaction (ACII), 2013 Humaine Association Conference, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Deng, J.; Xia, R.; Zhang, Z.; Liu, Y.; Schuller, B. Introducing shared-hidden-layer autoencoders for transfer learning and their application in acoustic emotion recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4818–4822. [Google Scholar]
- Mao, Q.; Xue, W.; Rao, Q.; Zhang, F.; Zhan, Y. Domain adaptation for speech emotion recognition by sharing priors between related source and target classes. In Proceedings of the 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2608–2612. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Universum autoencoder-based domain adaptation for speech emotion recognition. IEEE Signal Process. Lett. 2017, 24, 500–504. [Google Scholar] [CrossRef]
- Deng, J.; Zhang, Z.; Eyben, F.; Schuller, B. Autoencoder-based unsupervised domain adaptation for speech emotion recognition. IEEE Signal Process. Lett. 2014, 21, 1068–1072. [Google Scholar] [CrossRef]
- Deng, J.; Zhang, Z.; Schuller, B. Linked source and target domain subspace feature transfer learning–exemplified by speech emotion recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 21–23 August 2014; pp. 761–766. [Google Scholar]
- Latif, S.; Rana, R.; Qadir, J.; Epps, J. Variational autoencoders for learning latent representations of speech emotion: A preliminary study. arXiv 2017, arXiv:1712.08708. [Google Scholar]
- Eskimez, S.E.; Duan, Z.; Heinzelman, W. Unsupervised learning approach to feature analysis for automatic speech emotion recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5099–5103. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Xue, W.; Cucchiarini, C.; van Hout, R.; Strik, H. Acoustic Correlates of Speech Intelligibility. The Usability of the eGeMAPS Feature Set for Atypical Speech. 2019. Available online: https://repository.ubn.ru.nl/handle/2066/208512 (accessed on 20 September 2019).
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 3–10. [Google Scholar]
- Wu, S.; Falk, T.; Chan, W.Y. Automatic speech emotion recognition using modulation spectral features. Speech Commun. 2011, 53, 768–785. [Google Scholar] [CrossRef]
- Avila, A.R.; Momin, Z.A.; Santos, J.F.; O’Shaughnessy, D.; Falk, T.H. Feature Pooling of Modulation Spectrum Features for Improved Speech Emotion Recognition in the wild. IEEE Trans. Affect. Comput. 2018, 23, 177–188. [Google Scholar] [CrossRef]
- Weninger, F.; Staudt, P.; Schuller, B. Words that fascinate the listener: Predicting affective ratings of on-line lectures. Int. J. Distance Educ. Technol. 2013, 11, 110–123. [Google Scholar] [CrossRef]
- Wu, J.; Tan, W.C.; Rehg, J.M. Efficient and effective visual codebook generation using additive kernels. J. Mach. Learn. Res. 2011, 12, 3097–3118. [Google Scholar]
- Pancoast, S.; Akbacak, M. Softening quantization in bag-of-audio-words. In Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference, Florence, Italy, 4–9 May 2014; pp. 1370–1374. [Google Scholar]
- Riley, M.; Heinen, E.; Ghosh, J. A text retrieval approach to content-based audio retrieval. In Proceedings of the Int. Symp. on Music Information Retrieval (ISMIR), Online, 7–12 November 2008; pp. 295–300. [Google Scholar]
- Schmitt, M.; Schuller, B. OpenXBOW: Introducing the passau open-source crossmodal bag-of-words toolkit. J. Mach. Learn. Res. 2017, 18, 3370–3374. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Subspace alignment for domain adaptation. arXiv 2014, arXiv:1409.5241. [Google Scholar]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Kossaifi, J.; Walecki, R.; Panagakis, Y.; Shen, J.; Schmitt, M.; Ringeval, F.; Han, J.; Pit, V.; Toisoul, A.; Schuller, B.; et al. SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild. arXiv 2019, arXiv:1901.02839. [Google Scholar] [CrossRef]
- Hirsch, H.; Pearce, D. The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In Proceedings of the Automatic Speech Recognition: Challenges for the new Millenium ISCA Tutorial and Research Workshop (ITRW), Paris, France, 18–20 September 2000. [Google Scholar]
- Jeub, M.; Schafer, M.; Vary, P. A binaural room impulse response database for the evaluation of dereverberation algorithms. In Proceedings of the International Conference on Digital Signal Processing, Santorini, Greece, 5–7 July 2009. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Wang, Q.; Downey, C.; Wan, L.; Mansfield, P.; Moreno, I. Speaker diarization with LSTM. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Test | Arousal | Valence |
|---|---|---|---|
| German | German | 0.450 | 0.363 |
| AVEC 2019 | German | 0.434 | 0.455 |
| Multi-matched | German | 0.399 | 0.318 |
| Multi-unseen | German | 0.067 | 0.150 |
| Multi-unseen + Aug | German | 0.179 | 0.187 |
| Hungarian | Hungarian | 0.123 | 0.145 |
| AVEC 2019 | Hungarian | 0.291 | 0.135 |
| Multi-matched | Hungarian | 0.263 | 0.154 |
| Multi-unseen | Hungarian | 0.147 | 0.037 |
| Multi-unseen + Aug | Hungarian | 0.241 | 0.240 |
| French | French | 0.772 | 0.418 |
| AVEC 2019 | French | 0.323 | 0.144 |
| Multi-matched | French | 0.538 | 0.186 |
| Multi-unseen | French | 0.046 | 0.045 |
| Multi-unseen + Aug | French | 0.157 | 0.164 |
| Systems | Settings | Arousal | ||||||
|---|---|---|---|---|---|---|---|---|
| G-H | G-F | F-H | F-G | H-F | H-G | Avg | ||
| Benchmark | AVEC 2019 | 0.160 | 0.143 | 0.134 | 0.312 | 0.021 | 0.698 | 0.244 |
| No processing | 0.118 | 0.128 | 0.144 | 0.237 | 0.045 | 0.711 * | 0.230 | |
| BoW only | 0.179 * | 0.131 | 0.155 * | 0.320 | 0.115 * | 0.749 * | 0.274 * | |
| PCA | 0.130 | 0.146 | 0.097 | 0.125 | 0.028 | 0.717 * | 0.207 | |
| KCCA | 0.180 * | 0.228 * | 0.123 | 0.082 | 0.180 * | 0.674 | 0.244 | |
| SCL | 0.124 | 0.165* | 0.141 | 0.198 | 0.037 | 0.766 * | 0.238 | |
| SA-DA | 0.140 | 0.151 | 0.122 | 0.148 | 0.195 * | 0.762 * | 0.253 | |
| CORAL | 0.125 | 0.236 * | 0.124 | 0.161 | 0.119 * | 0.729 * | 0.249 | |
| Data augmentation | 0.201 * | 0.129 | 0.220 * | 0.119 | 0.150 * | 0.447 | 0.211 | |
| Proposed | SA-DA + BoW | 0.193 * | 0.154 | 0.188 * | 0.248 | 0.109 * | 0.765 * | 0.276 * |
| CORAL + BoW | 0.268* | 0.167 * | 0.138 | 0.433 * | 0.138 * | 0.739* | 0.313* | |
| N-CORAL | 0.207* | 0.127 | 0.167 * | 0.278 | 0.148 * | 0.733 * | 0.276 * | |
| N-CORAL + BoW | 0.282 * | 0.126 | 0.175 * | 0.464 * | 0.124 * | 0.787* | 0.326 * | |
| N-CORAL + BoW + Aug | 0.193 * | 0.189 * | 0.241 * | 0.369 | 0.156 * | 0.480 | 0.271 * | |
| Systems | Settings | Valence | ||||||
|---|---|---|---|---|---|---|---|---|
| G-H | G-F | F-H | F-G | H-F | H-G | Avg | ||
| Benchmark | AVEC 2019 | 0.046 | 0.112 | 0.200 | 0.073 | 0.090 | 0.671 | 0.198 |
| No processing | 0.014 | 0.104 | 0.204 | 0.130 * | 0.109 * | 0.719 * | 0.213 * | |
| BoW only | 0.074 * | 0.133 * | 0.260 * | 0.153 * | 0.141 * | 0.745 * | 0.251 * | |
| PCA | 0.031 | 0.160 * | 0.137 | 0.104 * | 0.048 | 0.712 * | 0.198 | |
| KCCA | 0.069 * | 0.129 | 0.165 | 0.069 | 0.057 | 0.641 | 0.188 | |
| SCL | 0.024 | 0.157 * | 0.169 | 0.092 * | 0.071 | 0.771 * | 0.214 * | |
| SA-DA | 0.033 | 0.126 | 0.128 | 0.117 * | 0.117 * | 0.782 * | 0.217 * | |
| CORAL | 0.065 * | 0.168 * | 0.315 * | 0.113 * | 0.09 | 0.726 * | 0.246 * | |
| Data augmentation | 0.107 * | 0.141 * | 0.214 | 0.075 | 0.154 * | 0.32 | 0.165 | |
| Proposed | SA-DA + BoW | 0.094 * | 0.139 * | 0.114 | 0.130 * | 0.158 * | 0.778 * | 0.235 * |
| CORAL + BoW | 0.128 * | 0.200 * | 0.371 * | 0.202 * | 0.123 * | 0.681 * | 0.284 * | |
| N-CORAL | 0.062 * | 0.125 | 0.143 | 0.131 * | 0.078 | 0.752 * | 0.215 * | |
| N-CORAL + BoW | 0.141 * | 0.169 * | 0.217 * | 0.310 * | 0.051 | 0.799 * | 0.281 * | |
| N-CORAL + BoW + Aug | 0.129 * | 0.131 * | 0.352 * | 0.247 * | 0.169 * | 0.473 | 0.267 * | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kshirsagar, S.; Falk, T.H. Cross-Language Speech Emotion Recognition Using Bag-of-Word Representations, Domain Adaptation, and Data Augmentation. Sensors 2022, 22, 6445. https://doi.org/10.3390/s22176445
Kshirsagar S, Falk TH. Cross-Language Speech Emotion Recognition Using Bag-of-Word Representations, Domain Adaptation, and Data Augmentation. Sensors. 2022; 22(17):6445. https://doi.org/10.3390/s22176445
Chicago/Turabian StyleKshirsagar, Shruti, and Tiago H. Falk. 2022. "Cross-Language Speech Emotion Recognition Using Bag-of-Word Representations, Domain Adaptation, and Data Augmentation" Sensors 22, no. 17: 6445. https://doi.org/10.3390/s22176445
APA StyleKshirsagar, S., & Falk, T. H. (2022). Cross-Language Speech Emotion Recognition Using Bag-of-Word Representations, Domain Adaptation, and Data Augmentation. Sensors, 22(17), 6445. https://doi.org/10.3390/s22176445