
Human Activity Recognition: Review, Taxonomy and Open Challenges



Abstract
:1. Introduction
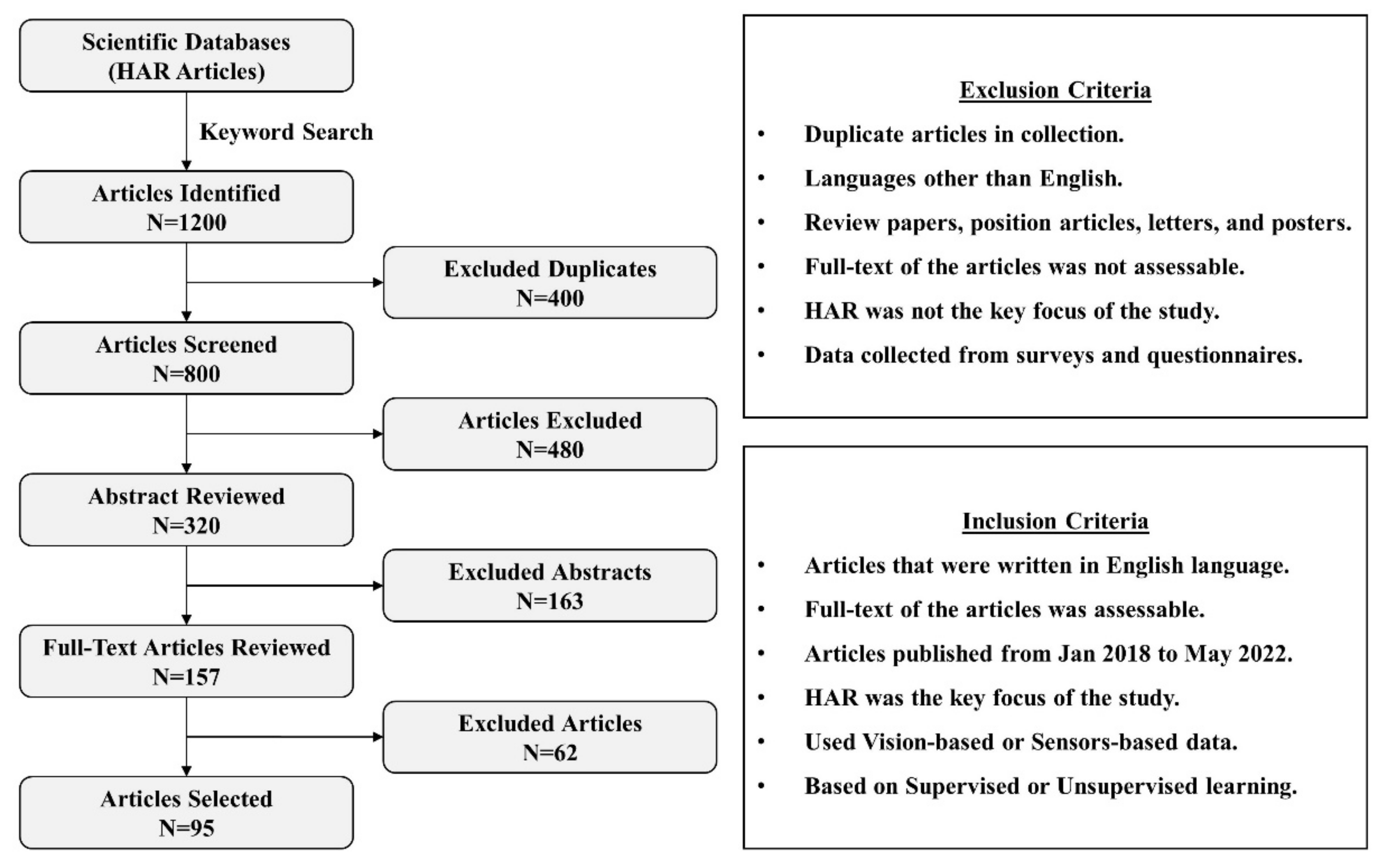
2. Materials and Methods
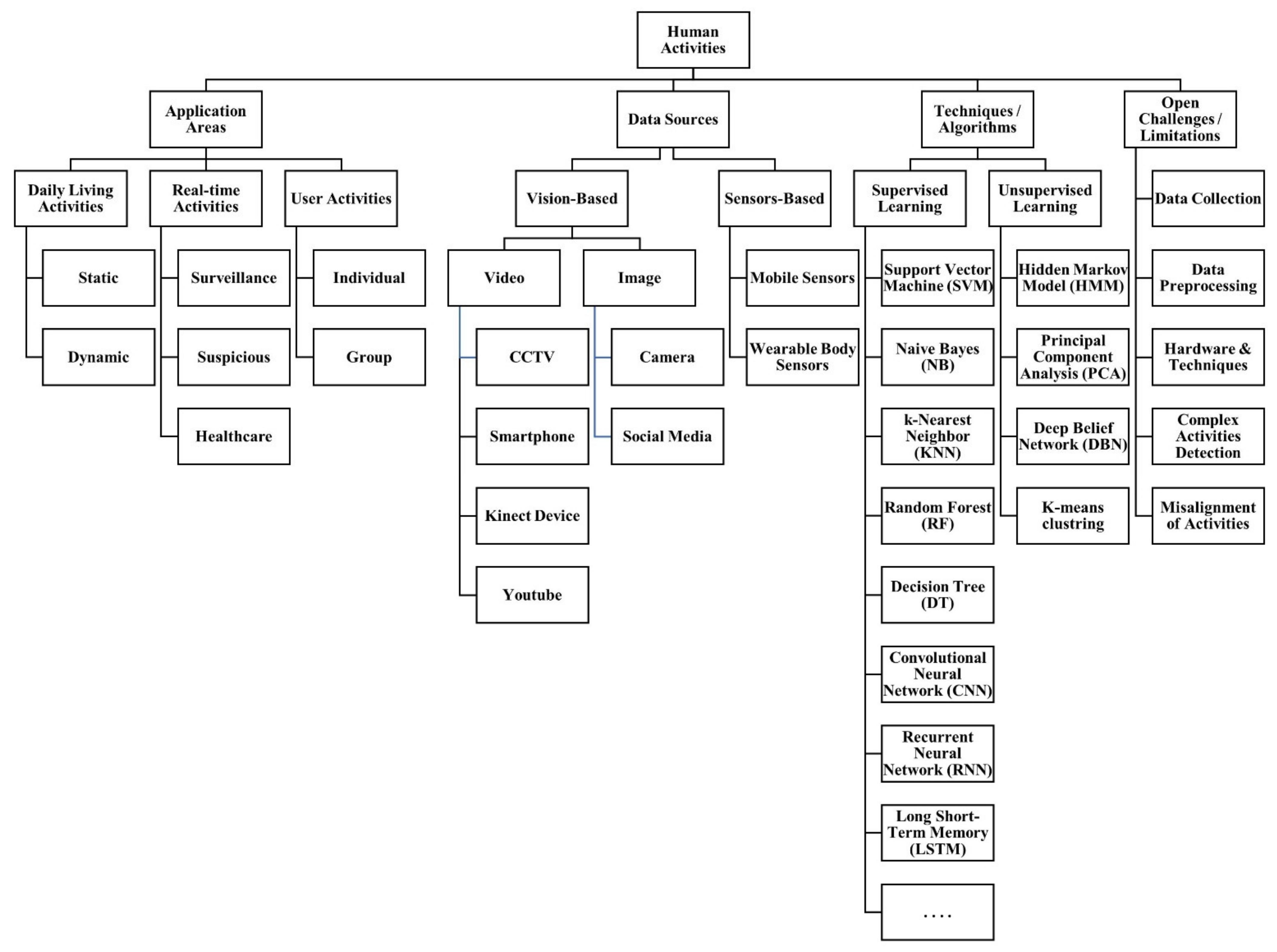
3. Human Activity
4. Application Areas
4.1. Daily Living Activities
4.1.1. Static Activities
4.1.2. Dynamic Activities
4.2. Real-Time Activities
4.2.1. Surveillance
4.2.2. Suspicious Activities
4.2.3. Healthcare
4.3. User Activities
4.3.1. Individual Activities
4.3.2. Group Activities
5. Data Sources
6. Techniques
7. Open Challenges and Limitations
7.1. Data Collection
7.2. Data Preprocessing
7.3. Hardware and Techniques
7.4. Complex Activities Detection
7.5. Misalignment of Activities
8. Discussion
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ghayvat, H.; Awais, M.; Pandya, S.; Ren, H.; Akbarzadeh, S.; Mukhopadhyay, S.C.; Chen, C.; Gope, P.; Chouhan, A.; Chen, W. Smart aging system: Uncovering the hidden wellness parameter for well-being monitoring and anomaly detection. Sensors 2019, 19, 766. [Google Scholar] [CrossRef] [PubMed]
- Gupta, N.; Gupta, S.K.; Pathak, R.K.; Jain, V.; Rashidi, P.; Suri, J.S. Human activity recognition in artificial intelligence framework: A narrative review. Artif. Intell. Rev. 2022, 55, 4755–4808. [Google Scholar] [CrossRef] [PubMed]
- Dhiman, C.; Vishwakarma, D.K. A review of state-of-the-art techniques for abnormal human activity recognition. Eng. Appl. Artif. Intell. 2019, 77, 21–45. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimedia Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Nayak, R.; Pati, U.C.; Das, S.K. Review article A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Afiq, A.A.; Zakariya, M.A.; Saad, M.N.; Nurfarzana, A.A.; Khir, M.H.M.; Fadzil, A.F.; Jale, A.; Gunawan, W.; Izuddin, Z.A.A.; Faizari, M. A review on classifying abnormal behavior in crowd scene. J. Vis. Commun. Image Represent. 2018, 58, 285–303. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Dou, Y.; Fudong, C.; Li, J.; Wei, C. Abnormal Behavior Detection Based on Optical Flow Trajectory of Human Joint Points. In Proceedings of the 2019 Chinese Control And Decision Conference, Nanchang, China, 3–5 June 2019. [Google Scholar]
- Fridriksdottir, E.; Bonomi, A.G. Accelerometer-based human activity recognition for patient monitoring using a deep neural network. Sensors 2020, 20, 6424. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Köping, L.; Shirahama, K.; Grzegorzek, M. A general framework for sensor-based human activity recognition. Comput. Biol. Med. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Futur. Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Sukor, A.S.A.; Zakaria, A.; Rahim, N.A. Activity recognition using accelerometer sensor and machine learning classifiers. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), Batu Feringghi, Malaysia, 9–10 March 2018; pp. 233–238. [Google Scholar]
- Bota, P.; Silva, J.; Folgado, D.; Gamboa, H. A semi-automatic annotation approach for human activity recognition. Sensors 2019, 19, 501. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, Z.; Soh, Y.C. A Novel Semisupervised Deep Learning Method for Human Activity Recognition. IEEE Trans. Ind. Informatics 2018, 15, 3821–3830. [Google Scholar] [CrossRef]
- Du, Y.; Lim, Y.; Tan, Y. A novel human activity recognition and prediction in smart home based on interaction. Sensors 2019, 19, 4474. [Google Scholar] [CrossRef]
- Shelke, S.; Aksanli, B. Static and dynamic activity detection with ambient sensors in smart spaces. Sensors 2019, 19, 804. [Google Scholar] [CrossRef]
- Chelli, A.; Patzold, M. A Machine Learning Approach for Fall Detection and Daily Living Activity Recognition. IEEE Access 2019, 7, 38670–38687. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A Semisupervised Recurrent Convolutional Attention Model for Human Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef]
- Javed, A.R.; Sarwar, M.U.; Khan, S.; Iwendi, C.; Mittal, M.; Kumar, N. Analyzing the effectiveness and contribution of each axis of tri-axial accelerometer sensor for accurate activity recognition. Sensors 2020, 20, 2216. [Google Scholar] [CrossRef] [Green Version]
- Tong, C.; Tailor, S.A.; Lane, N.D. Are accelerometers for activity recognition a dead-end? In Proceedings of the HotMobile ′20: Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3 March 2020; pp. 39–44. [Google Scholar]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced human activity recognition based on smartphone sensor data using hybrid feature selection model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [PubMed]
- Khan, Z.N.; Ahmad, J. Attention induced multi-head convolutional neural network for human activity recognition. Appl. Soft Comput. 2021, 110, 107671. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Biometric user identification based on human activity recognition using wearable sensors: An experiment using deep learning models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Haresamudram, H.; Essa, I.; Plötz, T. Contrastive Predictive Coding for Human Activity Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–26. [Google Scholar] [CrossRef]
- Pan, J.; Hu, Z.; Yin, S.; Li, M. GRU with Dual Attentions for Sensor-Based Human Activity Recognition. Electronics 2022, 11, 1797. [Google Scholar] [CrossRef]
- Luwe, Y.J.; Lee, C.P.; Lim, K.M. Wearable Sensor-Based Human Activity Recognition with Hybrid Deep Learning Model. Informatics 2022, 9, 56. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A.; Youplao, P.; Yupapin, P. Enhanced hand-oriented activity recognition based on smartwatch sensor data using LSTMs. Symmetry 2020, 12, 1570. [Google Scholar] [CrossRef]
- Saini, R.; Kumar, P.; Roy, P.P.; Dogra, D.P. A novel framework of continuous human-activity recognition using Kinect. Neurocomputing 2018, 311, 99–111. [Google Scholar] [CrossRef]
- Rueda, F.M.; Grzeszick, R.; Fink, G.A.; Feldhorst, S.; Hompel, M.T. Convolutional neural networks for human activity recognition using body-worn sensors. Informatics 2018, 5, 26. [Google Scholar]
- Espinilla, M.; Medina, J.; Hallberg, J.; Nugent, C. A new approach based on temporal sub-windows for online sensor-based activity recognition. J. Ambient Intell. Humaniz. Comput. 2018, 1–13. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A fast and robust deep convolutional neural networks for complex human activity recognition using smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef] [Green Version]
- Alghyaline, S. A real-time street actions detection. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 322–329. [Google Scholar] [CrossRef]
- Zhang, Y.; Tokmakov, P.; Hebert, M.; Schmid, C. A structured model for action detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9967–9976. [Google Scholar]
- Chen, Z.; Jiang, C.; Xie, L. A Novel Ensemble ELM for Human Activity Recognition Using Smartphone Sensors. IEEE Trans. Ind. Informatics 2018, 15, 2691–2699. [Google Scholar] [CrossRef]
- Ma, H.; Li, W.; Zhang, X.; Gao, S.; Lu, S. Attnsense: Multi-level attention mechanism for multimodal human activity recognition. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3109–3115. [Google Scholar]
- Almaadeed, N.; Elharrouss, O.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A Novel Approach for Robust Multi Human Action Recognition and Summarization based on 3D Convolutional Neural Networks. arXiv 2019. [Google Scholar] [CrossRef]
- Gleason, J.; Ranjan, R.; Schwarcz, S.; Castillo, C.D.; Chen, J.C.; Chellappa, R. A proposal-based solution to spatio-temporal action detection in untrimmed videos. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 141–150. [Google Scholar]
- Guo, J.; Mu, Y.; Xiong, M.; Liu, Y.; Gu, J. Activity Feature Solving Based on TF-IDF for Activity Recognition in Smart Homes. Complexity 2019, 2019, 5245373. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, C.; Ma, C.Y.; Socher, R.; Davis, L.S. ADAFRAME: Adaptive frame selection for fast video recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1278–1287. [Google Scholar]
- Nadeem, A.; Jalal, A.; Kim, K. Accurate physical activity recognition using multidimensional features and markov model for smart health fitness. Symmetry 2020, 12, 1766. [Google Scholar] [CrossRef]
- Yoon, D.-H.; Cho, N.-G.; Lee, S.-W. A novel online action detection framework from untrimmed video streams. Pattern Recognit. 2020, 106, 107396. [Google Scholar] [CrossRef]
- Ma, C.; Li, W.; Cao, J.; Du, J.; Li, Q.; Gravina, R. Adaptive sliding window based activity recognition for assisted livings. Inf. Fusion 2019, 53, 55–65. [Google Scholar] [CrossRef]
- Culman, C.; Aminikhanghahi, S.; Cook, D.J. Easing power consumption of wearable activity monitoring with change point detection. Sensors 2020, 20, 310. [Google Scholar] [CrossRef]
- Pan, J.; Chen, S.; Shou, M.Z.; Liu, Y.; Shao, J.; Li, H. Actor-Context-Actor Relation Network for Spatio-Temporal Action Localization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 464–474. [Google Scholar]
- Lin, X.; Zou, Q.; Xu, X. Action-guided attention mining and relation reasoning network for human-object interaction detection. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 1104–1110. [Google Scholar]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating over-segmentation errors by detecting action boundaries. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2321–2330. [Google Scholar]
- Helmi, A.M.; Al-Qaness, M.A.A.; Dahou, A.; Damaševičius, R.; Krilavičius, T.; Elaziz, M.A. A novel hybrid gradient-based optimizer and grey wolf optimizer feature selection method for human activity recognition using smartphone sensors. Entropy 2021, 23, 1065. [Google Scholar] [CrossRef]
- Li, X.; He, Y.; Fioranelli, F.; Jing, X. Semisupervised Human Activity Recognition with Radar Micro-Doppler Signatures. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5103112. [Google Scholar] [CrossRef]
- D’Arco, L.; Wang, H.; Zheng, H. Assessing Impact of Sensors and Feature Selection in Smart-Insole-Based Human Activity Recognition. Methods Protoc. 2022, 5, 45. [Google Scholar] [CrossRef]
- Najeh, H.; Lohr, C.; Leduc, B. Dynamic Segmentation of Sensor Events for Real-Time Human Activity Recognition in a Smart Home Context. Sensors 2022, 22, 5458. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, J.; Liang, Y.; Xia, J. Combining static and dynamic features for real-time moving pedestrian detection. Multimed. Tools Appl. 2019, 78, 3781–3795. [Google Scholar] [CrossRef]
- Basha, A.; Parthasarathy, P.; Vivekanandan, S. Detection of Suspicious Human Activity based on CNN-DBNN Algorithm for Video Surveillance Applications. In Proceedings of the 2019 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 22–23 March 2019; pp. 1–7. [Google Scholar]
- Dhaya, R. CCTV Surveillance for Unprecedented Violence and Traffic Monitoring. J. Innov. Image Process. 2020, 2, 25–34. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A combined multiple action recognition and summarization for surveillance video sequences. Appl. Intell. 2021, 51, 690–712. [Google Scholar] [CrossRef]
- Qin, Z.; Liu, H.; Song, B.; Alazab, M.; Kumar, P.M. Detecting and preventing criminal activities in shopping malls using massive video surveillance based on deep learning models. Ann. Oper. Res. 2021, 1–18. [Google Scholar] [CrossRef]
- Mahdi, M.S.; Jelwy, A. Detection of Unusual Activity in Surveillance Video Scenes Based on Deep Learning Strategies. J. Al-Qadisiyah Comput. Sci. Math. 2021, 13, 1–9. [Google Scholar]
- Sunil, A.; Sheth, M.H.; Shreyas, E.; Mohana. Usual and Unusual Human Activity Recognition in Video using Deep Learning and Artificial Intelligence for Security Applications. In Proceedings of the 2021 Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 15–17 September 2021. [Google Scholar]
- Yu, L.; Qian, Y.; Liu, W.; Hauptmann, A.G. Argus++: Robust Real-time Activity Detection for Unconstrained Video Streams with Overlapping Cube Proposals. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2022; pp. 112–121. [Google Scholar]
- Mohan, A.; Choksi, M.; Zaveri, M.A. Anomaly and Activity Recognition Using Machine Learning Approach for Video Based Surveillance. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 8–13. [Google Scholar]
- Rajpurkar, O.M.; Kamble, S.S.; Nandagiri, J.P.; Nimkar, A.V. Alert Generation on Detection of Suspicious Activity Using Transfer Learning. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020. [Google Scholar]
- Amrutha, C.V.; Jyotsna, C.; Amudha, J. Deep Learning Approach for Suspicious Activity Detection from Surveillance Video. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA 2020), Bangalore, India, 5–7 March 2020; pp. 335–339. [Google Scholar] [CrossRef]
- Khan, M.A.; Zahid, F.; Shah, J.H.; Akram, T. Human action recognition: A framework of statistical weighted segmentation and rank correlation-based selection. Pattern Anal Applic 2020, 23, 281–294. [Google Scholar] [CrossRef]
- Pyataeva, A.V.; Eliseeva, M.S. Video based human smoking event detection method. CEUR Workshop Proc. 2021, 3006, 343–352. [Google Scholar]
- Riaz, H.; Uzair, M.; Ullah, H.; Ullah, M. Anomalous Human Action Detection Using a Cascade of Deep Learning Models. In Proceedings of the 2021 9th European Workshop on Visual Information Processing (EUVIP), Paris, France, 23–25 June 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Mudgal, M.; Punj, D.; Pillai, A. Suspicious action detection in intelligent surveillance system using action attribute modelling. J. Web Eng. 2021, 20, 129–145. [Google Scholar] [CrossRef]
- Vallathan, G.; John, A.; Thirumalai, C.; Mohan, S.; Srivastava, G.; Lin, J.C.W. Suspicious activity detection using deep learning in secure assisted living IoT environments. J. Supercomput. 2021, 77, 3242–3260. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Muhammad, K.; Heidari, A.A.; Del Ser, J.; Baik, S.W.; de Albuquerque, V.H.C. Artificial Intelligence of Things-assisted two-stream neural network for anomaly detection in surveillance Big Video Data. Futur. Gener. Comput. Syst. 2022, 129, 286–297. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y. Rethinking Video Anomaly Detection–A Continual Learning Approach. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3036–3045. [Google Scholar]
- Gumaei, A.; Hassan, M.M.; Alelaiwi, A.; Alsalman, H. A Hybrid Deep Learning Model for Human Activity Recognition Using Multimodal Body Sensing Data. IEEE Access 2019, 7, 99152–99160. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M. Activity Recognition for Cognitive Assistance Using Body Sensors Data and Deep Convolutional Neural Network. IEEE Sens. J. 2019, 19, 8413–8419. [Google Scholar] [CrossRef]
- Taylor, W.; Shah, S.A.; Dashtipour, K.; Zahid, A.; Abbasi, Q.H.; Imran, M.A. An intelligent non-invasive real-time human activity recognition system for next-generation healthcare. Sensors 2020, 20, 2653. [Google Scholar] [CrossRef]
- Bhattacharya, D.; Sharma, D.; Kim, W.; Ijaz, M.F.; Singh, P.K. Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring. Biosensors 2022, 12, 393. [Google Scholar] [CrossRef]
- Issa, M.E.; Helmi, A.M.; Al-Qaness, M.A.A.; Dahou, A.; Abd Elaziz, M.; Damaševičius, R. Human Activity Recognition Based on Embedded Sensor Data Fusion for the Internet of Healthcare Things. Healthcare 2022, 10, 1084. [Google Scholar] [CrossRef]
- Hsu, S.C.; Chuang, C.H.; Huang, C.L.; Teng, P.R.; Lin, M.J. A video-based abnormal human behavior detection for psychiatric patient monitoring. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar]
- Ko, K.E.; Sim, K.B. Deep convolutional framework for abnormal behavior detection in a smart surveillance system. Eng. Appl. Artif. Intell. 2018, 67, 226–234. [Google Scholar] [CrossRef]
- Gunale, K.G.; Mukherji, P. Deep learning with a spatiotemporal descriptor of appearance and motion estimation for video anomaly detection. J. Imaging 2018, 4, 79. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, C.; Wang, Y.; Wang, P. Detection of abnormal behavior in narrow scene with perspective distortion. Mach. Vis. Appl. 2018, 30, 987–998. [Google Scholar] [CrossRef]
- Founta, A.M.; Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Vakali, A.; Leontiadis, I. A unified deep learning architecture for abuse detection. In Proceedings of the WebSci 2019—Proceedings of the 11th ACM Conference on Web Science, Boston, MA, USA, 30 June—3 July 2019; pp. 105–114. [Google Scholar]
- Moukafih, Y.; Hafidi, H.; Ghogho, M. Aggressive Driving Detection Using Deep Learning-based Time Series Classification. In Proceedings of the 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–5. [Google Scholar]
- Sabzalian, B.; Marvi, H.; Ahmadyfard, A. Deep and Sparse features for Anomaly Detection and Localization in video. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; pp. 173–178. [Google Scholar]
- Lee, J.; Shin, S. A Study of Video-Based Abnormal Behavior Recognition Model Using Deep Learning. Int. J. Adv. Smart Converg. 2020, 9, 115–119. [Google Scholar]
- Bhargava, A.; Salunkhe, G.; Bhosale, K. A comprehensive study and detection of anomalies for autonomous video surveillance using neuromorphic computing and self learning algorithm. In Proceedings of the 2020 International Conference on Convergence to Digital World—Quo Vadis (ICCDW), Mumbai, India, 18–20 February 2020; pp. 2020–2023. [Google Scholar]
- Xia, L.; Li, Z. A new method of abnormal behavior detection using LSTM network with temporal attention mechanism. J. Supercomput. 2021, 77, 3223–3241. [Google Scholar] [CrossRef]
- Zhang, C.; Song, J.; Zhang, Q.; Dong, W.; Ding, R.; Liu, Z. Action Unit Detection with Joint Adaptive Attention and Graph Relation. arXiv 2021. [CrossRef]
- Jyothi, K.L.B.; Vasudeva. Chronological Poor and Rich Tunicate Swarm Algorithm integrated Deep Maxout Network for human action and abnormality detection. In Proceedings of the 2021 Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 15–17 September 2021. [Google Scholar]
- Belhadi, A.; Djenouri, Y.; Srivastava, G.; Djenouri, D.; Lin, J.C.W.; Fortino, G. Deep learning for pedestrian collective behavior analysis in smart cities: A model of group trajectory outlier detection. Inf. Fusion 2021, 65, 13–20. [Google Scholar] [CrossRef]
- Shu, X.; Zhang, L.; Sun, Y.; Tang, J. Host-Parasite: Graph LSTM-in-LSTM for Group Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 663–674. [Google Scholar] [CrossRef]
- Ebrahimpour, Z.; Wan, W.; Cervantes, O.; Luo, T.; Ullah, H. Comparison of main approaches for extracting behavior features from crowd flow analysis. ISPRS Int. J. Geo-Inf. 2019, 8, 440. [Google Scholar] [CrossRef]
- Azar, S.M.; Atigh, M.G.; Nickabadi, A.; Alahi, A. Convolutional relational machine for group activity recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7884–7893. [Google Scholar]
- Wang, Q.; Chen, M.; Nie, F.; Li, X. Detecting Coherent Groups in Crowd Scenes by Multiview Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 46–58. [Google Scholar] [CrossRef]
- Ullah, H.; Islam, I.U.; Ullah, M.; Afaq, M.; Khan, S.D.; Iqbal, J. Multi-feature-based crowd video modeling for visual event detection. Multimedia Syst. 2020, 27, 589–597. [Google Scholar] [CrossRef]
- Tang, J.; Shu, X.; Yan, R.; Zhang, L. Coherence Constrained Graph LSTM for Group Activity Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 636–647. [Google Scholar] [CrossRef]
- Lazaridis, L.; Dimou, A.; Daras, P. Abnormal behavior detection in crowded scenes using density heatmaps and optical flow. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2060–2064. [Google Scholar]
- Wang, T.; Qiao, M.; Deng, Y.; Zhou, Y.; Wang, H.; Lyu, Q.; Snoussi, H. Abnormal event detection based on analysis of movement information of video sequence. Optik 2018, 152, 50–60. [Google Scholar] [CrossRef]
- Rabiee, H.; Mousavi, H.; Nabi, M.; Ravanbakhsh, M. Detection and localization of crowd behavior using a novel tracklet-based model. Int. J. Mach. Learn. Cybern. 2017, 9, 1999–2010. [Google Scholar] [CrossRef]
- Amraee, S.; Vafaei, A.; Jamshidi, K.; Adibi, P. Abnormal event detection in crowded scenes using one-class SVM. Signal Image Video Process. 2018, 12, 1115–1123. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Hu, S.; Guo, C.; Yu, H. Energy level-based abnormal crowd behavior detection. Sensors 2018, 18, 423. [Google Scholar] [CrossRef]
- Vahora, S.A.; Chauhan, N.C. Deep neural network model for group activity recognition using contextual relationship. Eng. Sci. Technol. Int. J. 2019, 22, 47–54. [Google Scholar] [CrossRef]
- Liu, Y.; Hao, K.; Tang, X.; Wang, T. Abnormal Crowd Behavior Detection Based on Predictive Neural Network. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 29–31 March 2019; pp. 221–225. [Google Scholar]
- Khan, S.D. Congestion detection in pedestrian crowds using oscillation in motion trajectories. Eng. Appl. Artif. Intell. 2019, 85, 429–443. [Google Scholar] [CrossRef]
- Zhang, X.; Shu, X.; He, Z. Crowd panic state detection using entropy of the distribution of enthalpy. Phys. A Stat. Mech. Its Appl. 2019, 525, 935–945. [Google Scholar] [CrossRef]
- Gupta, T.; Nunavath, V.; Roy, S. CrowdVAS-Net: A deep-CNN based framework to detect abnormal crowd-motion behavior in videos for predicting crowd disaster. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2877–2882. [Google Scholar]
- Direkoglu, C. Abnormal Crowd Behavior Detection Using Motion Information Images and Convolutional Neural Networks. IEEE Access 2020, 8, 80408–80416. [Google Scholar] [CrossRef]
- Alafif, T.; Alzahrani, B.; Cao, Y.; Alotaibi, R.; Barnawi, A.; Chen, M. Generative adversarial network based abnormal behavior detection in massive crowd videos: A Hajj case study. J. Ambient Intell. Humaniz. Comput. 2021, 13, 4077–4088. [Google Scholar] [CrossRef]
- Kwon, H.; Abowd, G.D.; Plötz, T. Handling annotation uncertainty in human activity recognition. In Proceedings of the 23rd International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 109–117. [Google Scholar]
- D’Angelo, G.; Palmieri, F. Enhancing COVID-19 tracking apps with human activity recognition using a deep convolutional neural network and HAR-images. Neural Comput. Appl. 2021, 1–17. [Google Scholar] [CrossRef]
- Sardar, A.W.; Ullah, F.; Bacha, J.; Khan, J.; Ali, F.; Lee, S. Mobile sensors based platform of Human Physical Activities Recognition for COVID-19 pandemic spread minimization. Comput. Biol. Med. 2022, 146, 105662. [Google Scholar] [CrossRef]
- Genemo, M.D. Suspicious activity recognition for monitoring cheating in exams. Proc. Indian Natl. Sci. Acad. 2022, 88, 1–10. [Google Scholar] [CrossRef]
- Hussain, A.; Ali, S.; Abdullah; Kim, H.-C. Activity Detection for the Wellbeing of Dogs Using Wearable Sensors Based on Deep Learning. IEEE Access 2022, 10, 53153–53163. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Description |
|---|---|---|
| [13] | 2018 | The proposed data integration framework has two components: data collection from various sensors and a codebook-based feature learning approach to encode data into an effective feature vector. Non-Linear SVM used as min method in proposed framework. |
| [14] | 2018 | Features were extracted from raw data collected with a smartphone sensor, processed with KPCA and LDA, and trained with DBN for activity recognition. |
| [15] | 2018 | PCA is used to reduce dimensionality and extract significant features, which are then compared using a machine learning classifier to raw data and PCA-based features for HAR. |
| [16] | 2019 | Introduced SSAL, based on the ST approach to automate and reduce annotation efforts for HAR. |
| [17] | 2019 | Proposed a method based on DLSTM and DNN for accurate HAR with smartphone sensors. |
| [18] | 2019 | Proposed a three-stage framework for recognizing and forecasting HAR with LSTM: post activity recognition, recognition in progress, and in advance prediction. |
| [19] | 2019 | Trained LR, NB, SVM, DT, RF and ANN (vanilla feed-forward) on data collected with low-resolution (4 × 16) thermal sensors. |
| [20] | 2019 | Proposed new time and frequency domain features to improve algorithms’ classification accuracy and compare four algorithms in terms of accuracy: ANN, KNN, QSVM, EBT. |
| [21] | 2020 | Proposed a pattern-based RCAM for extracting and preserving diverse patterns of activity and solving problem of imbalanced dataset. |
| [22] | 2020 | Proposed a method for predicting activities that used a 2-axis accelerometer and MLP, J48, and LR classifiers. |
| [23] | 2020 | Investigated that images should be used as HAR sensors rather than accelerometers because they contain more information. Claimed that CNN with images will not burden the modern devices. |
| [24] | 2020 | Proposed a hybrid feature selection process in which SFFS extracts features and SVM classifies activities. |
| [25] | 2021 | Proposed a one-dimensional CNN framework with three convolutional heads to improve representation ability and automatic feature selection. |
| [26] | 2021 | Using CNN and LSTM, a framework CNN-LSTM Model was proposed for multiclass wearable user identification while performing various activities. |
| [27] | 2021 | Proposed a CPC framework based on CNN and LSTM for monitoring construction equipment activity. |
| [30] | 2022 | Proposed a hybrid model that combines one-dimensional CNN with bidirectional LSTM (1D-CNN-BiLSTM) to recognize individual actions using wearable sensors. |
| [28] | 2022 | Aimed to address these issues by employing the GRU network, which collects valuable moments and temporal attention in order to minimize model attributes for HAR in the absence of I.I.D. |
| Ref. | Year | Description |
|---|---|---|
| [31] | 2018 | Proposed Coarse-to-Fine framework that uses Microsoft Kinect to capture activity sequences in 3D skeleton form, groups them into two forms, and then classifies them using the BLSTM-NN classifier. |
| [32] | 2018 | A deep NN was applied on multichannel time series collected from various body-worn sensors for HAR. Deep architecture CNN-IMU finds basic and complex attributes of human movements and categorize them in actions. |
| [33] | 2018 | Proposed online activity recognition with three temporal sub-windows for predicting activity start time based on an activity’s end label and comparing results of NA, SVM, and C4.5 with different changes. |
| [34] | 2019 | The proposed FR-DCNN for HAR improves the effectiveness and extends the information collected from the IMU sensor by building a DCNN classifier with a signal processing algorithm and a data compression module. |
| [35] | 2019 | Proposed an approach for detecting real-time human activities employing three methods: YOLO object detection, the Kalman Filter, and homography. |
| [36] | 2019 | The I3D network included a tracking module, and GNNs are used for actor and object interactions. |
| [37] | 2019 | Proposed an ensemble ELM algorithm for classifying daily living activities, which used Gaussian random projection to initialize base input weights. |
| [38] | 2019 | Proposed AttnSense with CNN and GRU is for multimodal HAR to capture signal dependencies in spatial and temporal domains. |
| [39] | 2019 | Proposed a 3Dimensional deep learning technique that detect multiple HAR using a new data representation. |
| [40] | 2019 | Proposed approach has different modules. The first stage generates dense spatiotemporal data using Mask R-CNN, second module has deep 3D-CNN performing classification and localization, then classification using a TRI-3D network. |
| [41] | 2019 | Proposed strategy based on 3 classifiers (TF-IDF, TF-IDF + Sigmod, TF-IDF + Tanh) for utilizing statistical data about individual and aggregate activities. |
| [42] | 2019 | Demonstrated AdaFrame, which included LSTM to select relevant frames for fast video recognition and time savings. |
| [45] | 2020 | In the proposed adaptive time-window-based algorithm, MGD was used to detect signals, define time window size, and then adjust window size to detect activity. |
| [46] | 2020 | Implemented CPAM to detect real-time activities in a range calculated by SEP algorithm and reduce energy consumption. |
| [44] | 2020 | Proposed a framework for future frame generation, as well as an online temporal action localization solution. Framework contains 4 deep neural network PRs for background reduction, AR for activity type prediction, F2G for future frame generation, and LSTM to recognize action on the basis of input received by AR and PR. |
| [43] | 2020 | A HAR framework is proposed that is based on features, quadratic discriminant analysis, and features processed by the maximum entropy Markov model. |
| [50] | 2021 | The proposed method improved GBO performance by selecting features and classifying them with SVM using an FS method called GBOGWO. |
| [48] | 2021 | The AGRR network has been proposed to solve HOI problems with a large combination space and non-interactive pair domains. |
| [47] | 2021 | The ACAR-Net model is proposed to support actor interaction-based indirect relation reasoning. |
| [49] | 2021 | In the proposed ASRF framework, an ASB is used to classify video frames, a BRB is used to regress action boundaries, and a loss function is used to smooth action probabilities. |
| [52] | 2022 | SVM to identify daily living activities in the proposed system by adjusting the size of the sliding window, reducing features, and implanting inertial and pressure sensors. |
| [53] | 2022 | Tried to figure out whether the currently performing action is a continuation of a previously performed activity or is novel in three steps: sensor correlation (SC), temporal correlation (TC), and determination of the activity activating the sensor. |
| Ref. | Year | Description |
|---|---|---|
| [54] | 2019 | Extract static sparse features from each frame by feature pyramid and sparse dynamic features from successive frames to improve feature extraction speed, then combine them in Adaboost classification. |
| [55] | 2019 | CNN extracted features from videos after background reduction, fed these features to DDBN, and compared CNN extracted features with labelled video features to classify suspicious activities. |
| [56] | 2020 | Identified object movement, performed video synchronization, and ensured proper detail alignment in CCTV videos for traffic and violence monitoring with Lucas–Kanade model. |
| [58] | 2021 | Proposed a DPCA-SM framework for detecting suspicious activity in a shopping mall from extracted frames that trained with VGG, along with applications for tracing people’s routes and identifying measures in a store setting. |
| [57] | 2021 | Proposed an effective approach to detect and recognize multiple human actions using TDMap HOG by comparing existing HOG and generated HOG using CNN model. |
| [59] | 2021 | Proposed an efficient method for automatically detecting abnormal behavior in both indoor and outdoor settings in academics and alerting appropriate authorities. Proposed system process video with VGG and LSTM network differentiates normal and abnormal frames. |
| [60] | 2021 | To detect normal and unusual activity in a surveillance system, an SSD algorithm with bounded box explicitly trained with a transfer learning approach DS-GRU is used. |
| [61] | 2022 | For dealing with untrimmed multi-scale multi-instance video streams with a wide field of view, a real-time activity detection system based on Argus++ is proposed. Argus++ combined Mask R-CNN and ResNet101. |
| Ref. | Year | Description |
|---|---|---|
| [62] | 2019 | PCANet and CNN were used to overcome issues with manual detection of anomalies in videos and false alarms. In video frames, abnormal event is determined with PCA and SVM. |
| [63] | 2020 | CCTV footage is fed into a CNN model, which detects shoplifting, robbery, or a break-in in a retail store and immediately alerts the shopkeeper. |
| [64] | 2020 | Pretrained CNN model VGG16 was used to obtain features from videos, then a feature classifier LSTM was used to detect normal and abnormal behavior in an academic setting and alert the appropriate authorities. |
| [65] | 2021 | The proposed system offered a framework for analyzing video statistics obtained from a CCTV digital camera installed in a specific location. |
| [66] | 2021 | Three-dimensional CNN ResNet with spatio-temporal features was used to recognize and detect smoking events. |
| [67] | 2021 | A pretrained model was used to estimate human poses, and deep CNN was built to detect anomalies in examination halls. |
| [68] | 2021 | The GMM was combined with the UAM to distinguish between normal and abnormal activities such as hitting, slapping, punching, and so on. |
| [69] | 2021 | Deep learning was used to detect suspicious activities automatically, saving time and effort spent manually monitoring videos. |
| [70] | 2022 | A two-stream neural network was proposed using AIoT to recognize anomalies in Big Video Data. BD-LSTM classified anomaly classes of data stored on cloud. Different modeling choices used by researcher to obtain better results. |
| [71] | 2022 | Created a larger benchmark dataset than was previously available and proposed an algorithm to address the problems of continuous learning and few-shot learning. YOLO v4 discovers items from frames and kNN based RNN model avoids catastrophic forgetting from frames. |
| Ref. | Year | Description |
|---|---|---|
| [72] | 2019 | Deep learning was used to create a multi-sensory framework that combined SRU and GRU. SRU is concerned with multimodal input data, whereas GRU is concerned with accuracy issues. |
| [74] | 2020 | SDRs were used to create a dataset of radio wave signals, and a RF machine learning model was developed to provide near-real-time classification between sitting and standing. |
| [73] | 2019 | Gausian kernel-based PCA gets significant features from sensors data and recognizes activities using Deep CNN. |
| [75] | 2022 | “CNN-net”, “CNNLSTM-net”, “ConvLSTM-net”, and “StackedLSTM-net” models based on one dimensional CNN and LSTM stacked predictions and then trained a blender on them for final prediction. |
| [76] | 2022 | Used a model based on handcrafted features and RF on data collected with two smartphones. |
| Ref. | Year | Description |
|---|---|---|
| [77] | 2018 | SVM and the N-cut algorithm were used to label video segments, and the CRF was used to detect anomalous events. |
| [78] | 2018 | A deep convolutional framework was used to develop a unified framework for detecting abnormal behavior with LSTM in RGB images. YOLO was used determine the action of individuals in video frames and then VGG-16 classify them. |
| [79] | 2018 | Proposed a HOME FAST spatiotemporal feature extraction approach based on optical flow information to detect anomalies. Proposed approach obtained low-level features with KLT feature extractor and supplied to DCNN for categorization. |
| [80] | 2019 | Proposed an algorithm used adaptive transformation to conceal the affected area and the pyramid L-K optical flow method to extract abnormal behavior from videos. |
| [81] | 2019 | By combining extracted hidden patterns of text with available metadata, a deep learning architecture RNN was proposed to detect abusive behavioral norms. |
| [10] | 2019 | SVM was used to determine abnormal behavior using extracted feature vectors and vector trajectories from the computed optical flow field of determined joint points with LK method. |
| [82] | 2019 | The proposed LSTM-FCN detects aggressive driving sessions as time series classification to solve the problem of driver behavior. |
| [83] | 2019 | A method that combined CNN with HOF and HOG was proposed to detect anomalies in surveillance video frames. |
| [84] | 2020 | A deep learning model was used to detect abnormal behavior in videos automatically, and experiments with 2D CNN-LSTM, 3D CNN, and I3D models were conducted. |
| [85] | 2020 | Propose to do instance segmentation in video bytes and predicting the actions with the help of DBN based on RBM. Aimed to present an implementation of an algorithm that can depict anomalies in real time video feed. |
| [86] | 2021 | Proposed a method for detecting abnormal behavior that is both accurate and effective. VGG16 network transferred to full CNN to extract features. Then LSTM is used for prediction at that moment. |
| [87] | 2021 | Proposed a method in the ABAW competition that used a pre-trained JAA model and AU local features. |
| [88] | 2021 | Proposed a strategy for recognizing and detecting anomalies in human actions and extracting effective features using a CPRTSA based Deep Maxout Network. |
| [89] | 2021 | The algorithm was classified into two types. The first employs data mining and knowledge discovery, whereas the second employs deep CNN to detect collective abnormal behavior. Researcher planned variation of DBSCAN, kNN feature selection, and ensemble learning for behavior identification. |
| [90] | 2021 | Residual LSTM was introduced to learn static and temporal person-level residual features, and GLIL was proposed to model person-level and group-level activity for group activity recognition. |
| Ref. | Year | Description |
|---|---|---|
| [96] | 2018 | A two-stream convolutional network with density heat-maps and optical flow information was proposed to classify abnormal crowd behavior and generate a large-scale video dataset. To prevent long-term dependency, they used LSTM. |
| [97] | 2018 | For abnormal event detection in surveillance videos, an algorithm based on image descriptors derived from the HMM that used HOFO as feature extractor and a classification method is proposed. |
| [98] | 2018 | The proposed descriptor is based on spatiotemporal 3D patches and can be used in conjunction with sHOT to detect abnormal behavior. Then one class SVM classifies behaviors. |
| [99] | 2018 | HOG-LBP and HOF were calculated from extracted candidate regions and passed to two distinct one-class SVM models to detect abnormal events after redundant information was removed. |
| [100] | 2018 | Particle velocities are extracted using the optical flow method, and motion foreground is extracted using the crowded motion segmentation method. The distance to the camera is calculated using linear interpolation, and crowd behavior is analysed using the contrast of three descriptors. |
| [91] | 2019 | Reviewed crowd analysis fundamentals and three main approaches: crowd video analysis, crowd spatiotemporal analysis, and social media analysis. |
| [92] | 2019 | Presented a deep CRM component that learns to generate activity maps, a multi-stage refinement component that reduces incorrect activity map predictions, and an aggregation component that recognizes group activities based on refined data. |
| [101] | 2019 | Presented a contextual relationship-based learning model that uses a deep NN to recognize a group of people’s activities in a video sequence. Action-poses are classified with pre-trained CNN, then passed to RNN and GRU. |
| [102] | 2019 | A Gaussian average model was proposed to overcome the disadvantage of slow convergence speed, and a predictive neural network was used to detect abnormal behavior by determining the difference between predictive and real frames. |
| [103] | 2019 | Extracted optical flow motion features, generated a trajectory oscillation pattern, and proposed a method for detecting crowd congestion. |
| [104] | 2019 | A method for detecting crowd panic states based on entropy and enthalpy was proposed, with enthalpy describing the system’s state and entropy measuring the degree of disorder in the system. Crowded movement area represented in the form of text with LIC. |
| [105] | 2019 | The CrowdVAS-Net framework is proposed, which extracts features from videos using DCNN and trains these features with a RF classifier to differentiate between normal and abnormal behavior. |
| [93] | 2020 | The proposed MPF framework is built on the L1 and L2 norms. Descriptor of structure context for self-weighted structural properties Framework for group detection and multiview feature point clustering. |
| [106] | 2020 | MII is generated from frames based on optical flow and angle difference and used to train CNN, provide visual appearance and distinguish between normal and unusual crowd motion with one class SVM. |
| [94] | 2021 | The proposed method employs a two-stream convolutional architecture to obtain the motion field from video using dense optical flow and to solve the problem of capturing information from still frames. |
| [107] | 2021 | Extracted dynamic features based on optical flow and used an optical flow framework with U-Net and Flownet based on GAN and transfer learning to distinguish between normal and abnormal crowd behavior. |
| [95] | 2022 | CCGLSTM with STCC and GCC is proposed to recognize group activity and build a spatial and temporal gate to control memory and capture relevant motion for group activity recognition. |
| Ref. | Vision-Based | Sensor-Based | ||||||
|---|---|---|---|---|---|---|---|---|
| CCTV | Kinect Device | YouTube | Smart Phone | Camera Images | Social Media Images | Mobile Sensor | Wearable Device Sensor | |
| [97] | ✔ | |||||||
| [98] | ✔ | |||||||
| [13] | ✔ | |||||||
| [33] | ✔ | |||||||
| [31] | ✔ | |||||||
| [14] | ✔ | |||||||
| [77] | ✔ | |||||||
| [96] | ✔ | ✔ | ||||||
| [99] | ✔ | |||||||
| [15] | ✔ | |||||||
| [65] | ✔ | |||||||
| [54] | ✔ | |||||||
| [32] | ✔ | |||||||
| [78] | ✔ | |||||||
| [79] | ✔ | |||||||
| [101] | ✔ | |||||||
| [80] | ✔ | |||||||
| [100] | ✔ | |||||||
| [34] | ✔ | |||||||
| [72] | ✔ | |||||||
| [18] | ✔ | |||||||
| [35] | ✔ | |||||||
| [16] | ✔ | |||||||
| [36] | ✔ | |||||||
| [81] | ✔ | |||||||
| [20] | ✔ | |||||||
| [39] | ✔ | |||||||
| [37] | ✔ | |||||||
| [17] | ✔ | |||||||
| [40] | ✔ | |||||||
| [10] | ✔ | |||||||
| [102] | ✔ | |||||||
| [41] | ✔ | ✔ | ||||||
| [73] | ✔ | |||||||
| [42] | ✔ | |||||||
| [82] | ✔ | ✔ | ||||||
| [62] | ✔ | |||||||
| [38] | ✔ | |||||||
| [91] | ✔ | |||||||
| [103] | ✔ | ✔ | ||||||
| [92] | ✔ | |||||||
| [104] | ✔ | |||||||
| [105] | ✔ | ✔ | ||||||
| [83] | ✔ | |||||||
| [55] | ✔ | |||||||
| [44] | ✔ | |||||||
| [84] | ✔ | |||||||
| [85] | ✔ | |||||||
| [21] | ✔ | |||||||
| [106] | ✔ | |||||||
| [43] | ✔ | |||||||
| [45] | ✔ | |||||||
| [63] | ✔ | |||||||
| [74] | ✔ | |||||||
| [22] | ✔ | |||||||
| [23] | ✔ | |||||||
| [56] | ✔ | |||||||
| [64] | ✔ | |||||||
| [93] | ✔ | |||||||
| [24] | ✔ | |||||||
| [46] | ✔ | |||||||
| [48] | ✔ | |||||||
| [57] | ✔ | |||||||
| [86] | ✔ | |||||||
| [50] | ✔ | |||||||
| [87] | ✔ | |||||||
| [47] | ✔ | |||||||
| [49] | ✔ | |||||||
| [67] | ✔ | |||||||
| [25] | ✔ | |||||||
| [26] | ✔ | |||||||
| [88] | ✔ | |||||||
| [27] | ✔ | |||||||
| [89] | ✔ | |||||||
| [58] | ✔ | |||||||
| [59] | ✔ | |||||||
| [107] | ✔ | |||||||
| [90] | ✔ | |||||||
| [94] | ✔ | |||||||
| [68] | ✔ | |||||||
| [69] | ✔ | |||||||
| [60] | ✔ | |||||||
| [66] | ✔ | |||||||
| [61] | ✔ | |||||||
| [70] | ✔ | |||||||
| [71] | ✔ | |||||||
| [51] | ✔ | |||||||
| [95] | ✔ | |||||||
| [76] | ✔ | |||||||
| [53] | ✔ | |||||||
| [30] | ✔ | |||||||
| [19] | ✔ | |||||||
| [52] | ✔ | |||||||
| [75] | ✔ | ✔ | ||||||
| [28] | ✔ | |||||||
| Ref. | SVM | KNN | RF | DT | CNN | RNN | LSTM | HMM | PCA | DBN | K-Means | VGG | Lucas-Kanade | Gaussian Model | I3D | LR | GRU | HOG | Others |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [97] | ✔ | ||||||||||||||||||
| [98] | ✔ | ✔ | |||||||||||||||||
| [13] | ✔ | ||||||||||||||||||
| [33] | ✔ | ✔ | |||||||||||||||||
| [31] | ✔ | ✔ | |||||||||||||||||
| [14] | ✔ | ✔ | ✔ | ||||||||||||||||
| [77] | ✔ | ||||||||||||||||||
| [96] | ✔ | ✔ | |||||||||||||||||
| [99] | ✔ | ✔ | |||||||||||||||||
| [15] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [65] | ✔ | ||||||||||||||||||
| [54] | ✔ | ||||||||||||||||||
| [32] | ✔ | ||||||||||||||||||
| [78] | ✔ | ✔ | ✔ | ||||||||||||||||
| [79] | ✔ | ✔ | |||||||||||||||||
| [101] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [80] | ✔ | ✔ | |||||||||||||||||
| [100] | ✔ | ||||||||||||||||||
| [34] | ✔ | ||||||||||||||||||
| [72] | ✔ | ✔ | |||||||||||||||||
| [18] | ✔ | ||||||||||||||||||
| [35] | ✔ | ||||||||||||||||||
| [16] | ✔ | ||||||||||||||||||
| [36] | ✔ | ||||||||||||||||||
| [81] | ✔ | ||||||||||||||||||
| [20] | ✔ | ✔ | ✔ | ||||||||||||||||
| [39] | ✔ | ||||||||||||||||||
| [37] | ✔ | ||||||||||||||||||
| [17] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [40] | ✔ | ✔ | ✔ | ||||||||||||||||
| [10] | ✔ | ✔ | |||||||||||||||||
| [102] | ✔ | ||||||||||||||||||
| [41] | ✔ | ||||||||||||||||||
| [73] | ✔ | ✔ | |||||||||||||||||
| [42] | ✔ | ||||||||||||||||||
| [82] | ✔ | ✔ | ✔ | ||||||||||||||||
| [62] | ✔ | ✔ | ✔ | ||||||||||||||||
| [38] | ✔ | ✔ | ✔ | ✔ | ✔ | ||||||||||||||
| [95] | ✔ | ||||||||||||||||||
| [91] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||
| [103] | ✔ | ||||||||||||||||||
| [92] | ✔ | ||||||||||||||||||
| [104] | ✔ | ||||||||||||||||||
| [105] | ✔ | ✔ | |||||||||||||||||
| [83] | ✔ | ✔ | |||||||||||||||||
| [55] | ✔ | ✔ | |||||||||||||||||
| [44] | ✔ | ✔ | |||||||||||||||||
| [84] | ✔ | ✔ | ✔ | ||||||||||||||||
| [85] | ✔ | ||||||||||||||||||
| [21] | ✔ | ||||||||||||||||||
| [106] | ✔ | ✔ | |||||||||||||||||
| [43] | ✔ | ||||||||||||||||||
| [45] | ✔ | ||||||||||||||||||
| [63] | ✔ | ||||||||||||||||||
| [74] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [22] | ✔ | ✔ | |||||||||||||||||
| [23] | ✔ | ||||||||||||||||||
| [56] | ✔ | ||||||||||||||||||
| [64] | ✔ | ✔ | ✔ | ||||||||||||||||
| [93] | ✔ | ||||||||||||||||||
| [24] | ✔ | ||||||||||||||||||
| [46] | ✔ | ||||||||||||||||||
| [57] | ✔ | ✔ | |||||||||||||||||
| [86] | ✔ | ✔ | ✔ | ||||||||||||||||
| [50] | ✔ | ||||||||||||||||||
| [87] | ✔ | ||||||||||||||||||
| [48] | ✔ | ||||||||||||||||||
| [47] | ✔ | ||||||||||||||||||
| [49] | ✔ | ||||||||||||||||||
| [67] | ✔ | ||||||||||||||||||
| [25] | ✔ | ||||||||||||||||||
| [26] | ✔ | ✔ | |||||||||||||||||
| [88] | |||||||||||||||||||
| [27] | ✔ | ✔ | |||||||||||||||||
| [89] | ✔ | ||||||||||||||||||
| [58] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [59] | ✔ | ✔ | ✔ | ||||||||||||||||
| [107] | ✔ | ||||||||||||||||||
| [90] | ✔ | ✔ | |||||||||||||||||
| [94] | ✔ | ||||||||||||||||||
| [51] | ✔ | ||||||||||||||||||
| [68] | ✔ | ||||||||||||||||||
| [69] | ✔ | ✔ | |||||||||||||||||
| [60] | ✔ | ||||||||||||||||||
| [66] | ✔ | ||||||||||||||||||
| [61] | ✔ | ||||||||||||||||||
| [70] | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| [71] | ✔ | ✔ | ✔ | ||||||||||||||||
| [75] | ✔ | ✔ | |||||||||||||||||
| [28] | ✔ | ||||||||||||||||||
| [53] | ✔ | ||||||||||||||||||
| [52] | ✔ | ||||||||||||||||||
| [30] | ✔ | ✔ | |||||||||||||||||
| [76] | ✔ | ||||||||||||||||||
| [19] | ✔ | ✔ | ✔ | ✔ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshad, M.H.; Bilal, M.; Gani, A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors 2022, 22, 6463. https://doi.org/10.3390/s22176463
Arshad MH, Bilal M, Gani A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors. 2022; 22(17):6463. https://doi.org/10.3390/s22176463
Chicago/Turabian StyleArshad, Muhammad Haseeb, Muhammad Bilal, and Abdullah Gani. 2022. "Human Activity Recognition: Review, Taxonomy and Open Challenges" Sensors 22, no. 17: 6463. https://doi.org/10.3390/s22176463
APA StyleArshad, M. H., Bilal, M., & Gani, A. (2022). Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors, 22(17), 6463. https://doi.org/10.3390/s22176463