1. Introduction
Instance segmentation is a classical task in computer vision that combines object-detection and semantic-segmentation tasks. It is widely used in fields such as unmanned vehicles and medical image analysis. HTC [
1] designed a multitasking, multistage hybrid cascade structure that combines cascading and multitasking at each stage to improve information flow. It also incorporated a semantic segmentation branch to further improve accuracy. Fine boundaries, according to Cheng and others [
2], can offer precise localization and improve the visibility of the mask segmentation. Object masks and boundaries are learned using the exemplary boundary information, and a mask head with preserved boundaries is built. Kirillov and others [
3] viewed the image-segmentation problem as a rendering problem, and optimized object edge segmentation with a novel upsampling approach with better performance on edge segmentation. PointRend iteratively performs point-based predictions at blurred areas for high-quality image segmentation. CondInst [
4] uses an instance-based dynamic instance-aware network instead of ROI, which lacks cropping and alignment operations, and speeds up inference. SOLO [
5] transformed the instance segmentation problem into a category-aware prediction problem and an instance-aware mask-generation problem by dividing the grid and improving inference speed. YOLACT [
6] generates instance masks with the linear combination of prototype masks and mask coefficients, and this process does not rely on repooling, which improves mask quality and inference speed. BlendMask [
7] achieves high-quality mask prediction by combining top–down and bottom–up approaches to exploit fine-grained information at lower layers. Polytransform [
8] is a postprocessing method that first generates instance-level masks using the segmentation network, and then transforms the masks into polygons and inputs them into the deformation network, which transforms these polygons into object boundary shapes.
Mask R-CNN [
9], a top–down detector that follows the idea of detection first and segmentation subsequently, is the most representative instance-segmentation approach. It uses a deep backbone network that drives the detector to obtain powerful localization and differentiation capabilities to recognize objects at different scales. However, deep networks result in coarse feature resolution. When these features are mapped back to the original input space, a large number of image details are lost. Feature alignment operation [
9] further exacerbates this phenomenon. Unlike instance segmentation, semantic segmentation can gradually fuse shallow features through multiple upsampling operations to obtain high-resolution features with a large amount of detailed information, such as Unet [
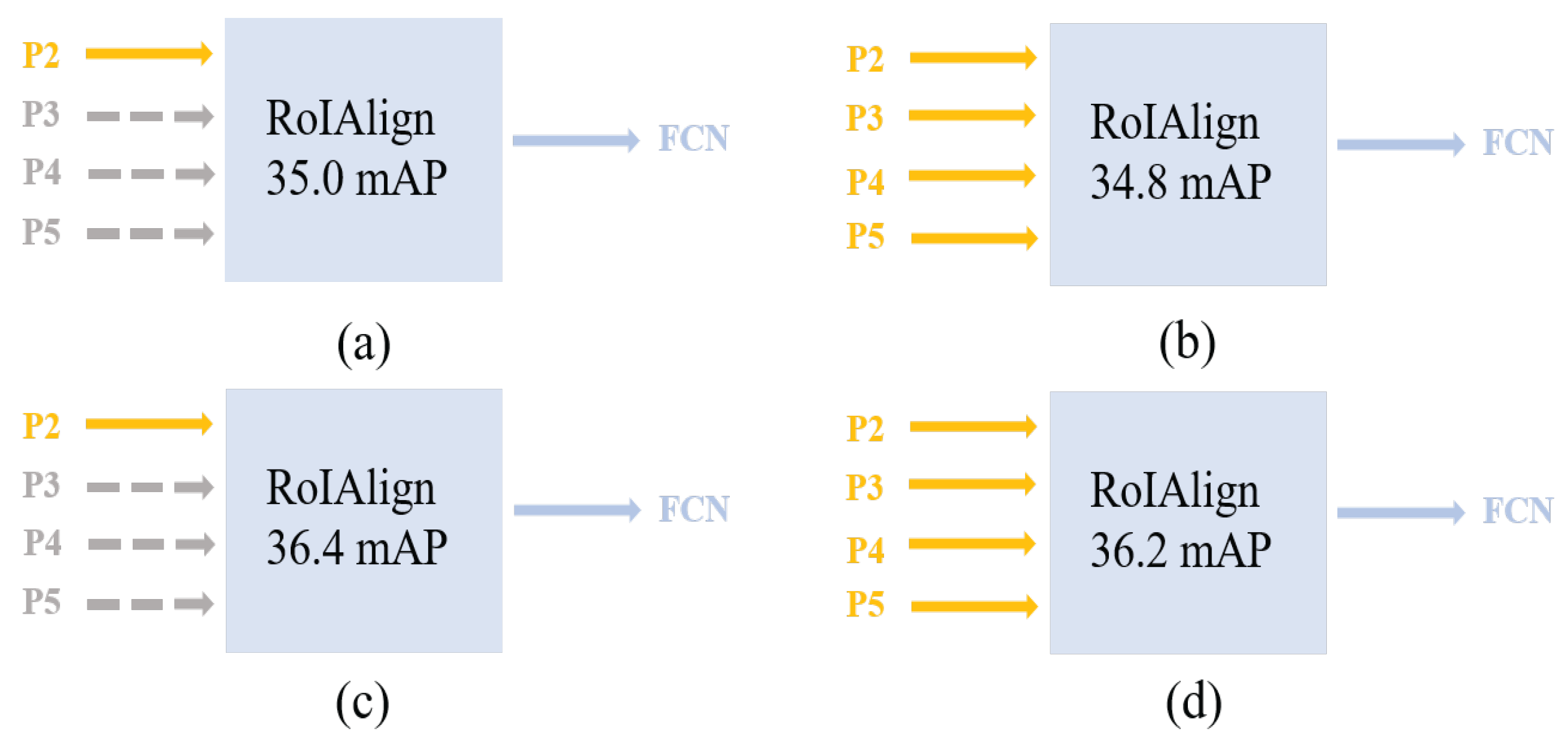
10]. Instance segmentation shares some traits with semantic segmentation.To prove this conjecture, the P2 feature map with the finest feature information in feature pyramid networks (FPNs) [
11] is used as the input feature of the mask network. As shown in
Figure 1, using the P2 layer as segmentation feature achieved the same performance as that using different layer features as segmentation features. This indicates that the P2 layer is fully equipped with different scales of mask information and has higher feature resolution.
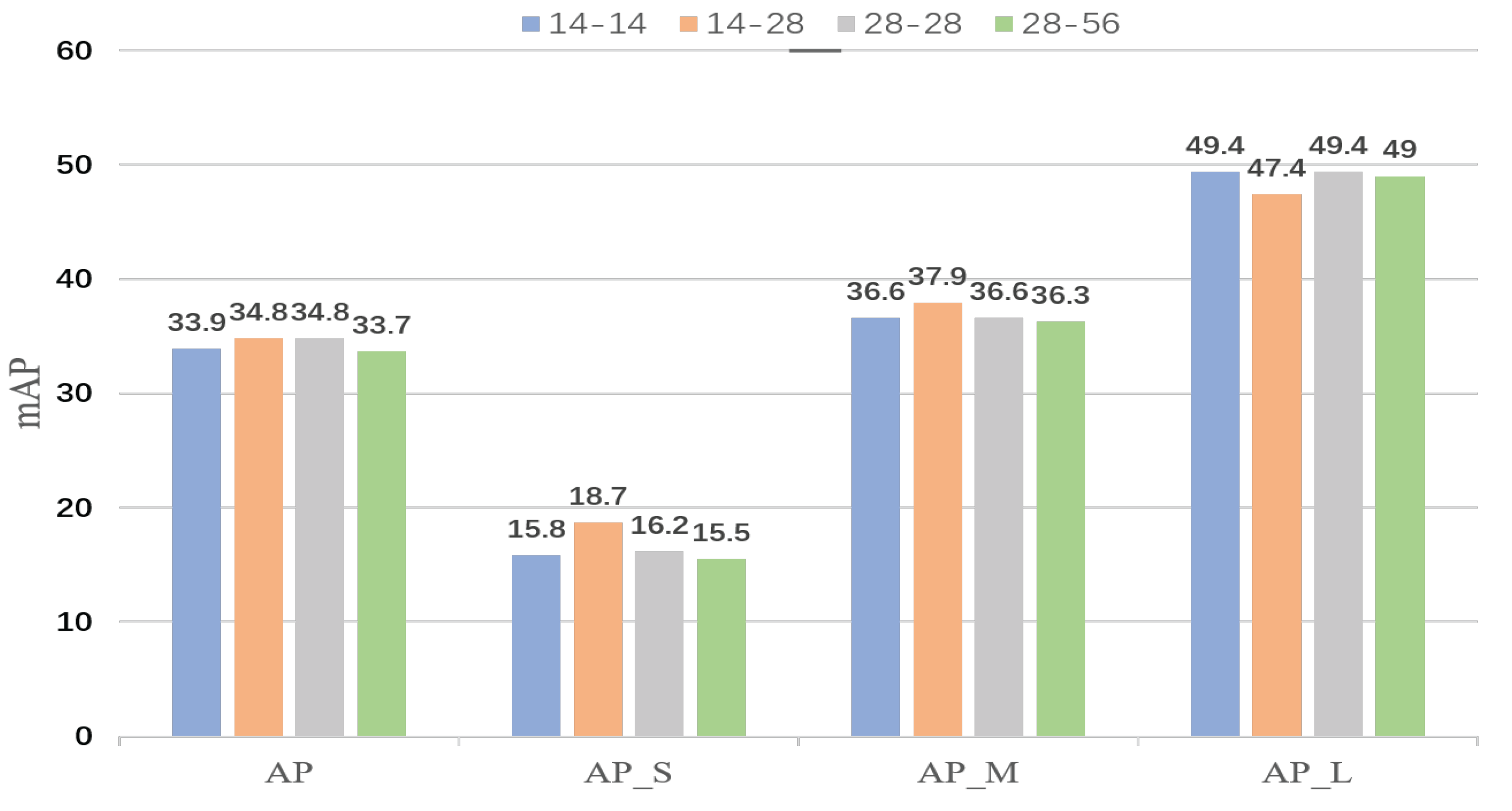
The greater the resolution is, the more detailed the mask prediction in terms of feature space resolution. However, the experiment showed that the results were not so. With the change in resolution, inconsistency in segmentation appared at different scales. As shown in
Figure 2, the performance effect of small- and medium-object segmentation decreases when the performance on large objects is improved. When the segmentation performance of large objects is poor, the segmentation performance of small and medium-sized objects is better. The loss function may be to blame for this phenomenon.To address this phenomenon, subsequent work will revolve around the loss function.
The significance of the object’s boundary and shape information was ignored by previous instance segmentation methods [
1,
4,
5,
6,
9,
13,
14], which treated all pixels equally. More consideration is given to object boundaries for a segmentation task. It is challenging to categorize the pixels of the boundary since the proportion of boundary pixels is significantly smaller than the proportion of overall object pixels (around 1% and even smaller for large targets). As shown in
Figure 3, the boundaries are rough, and the overlap between objects is not reasonable. The prediction of the boundary pixels almost completely determines the segmentation quality. Fine boundaries, according to Cheng and others [
2], can offer precise localization and improve the visibility of the mask segmentation. Object masks and boundaries are learned using the exemplary boundary information, and a mask head with preserved boundaries is built. Kirillov and others [
3] viewed the image-segmentation problem as a rendering problem, and optimized object edge segmentation with a novel upsampling approach with better performance on edge segmentation.
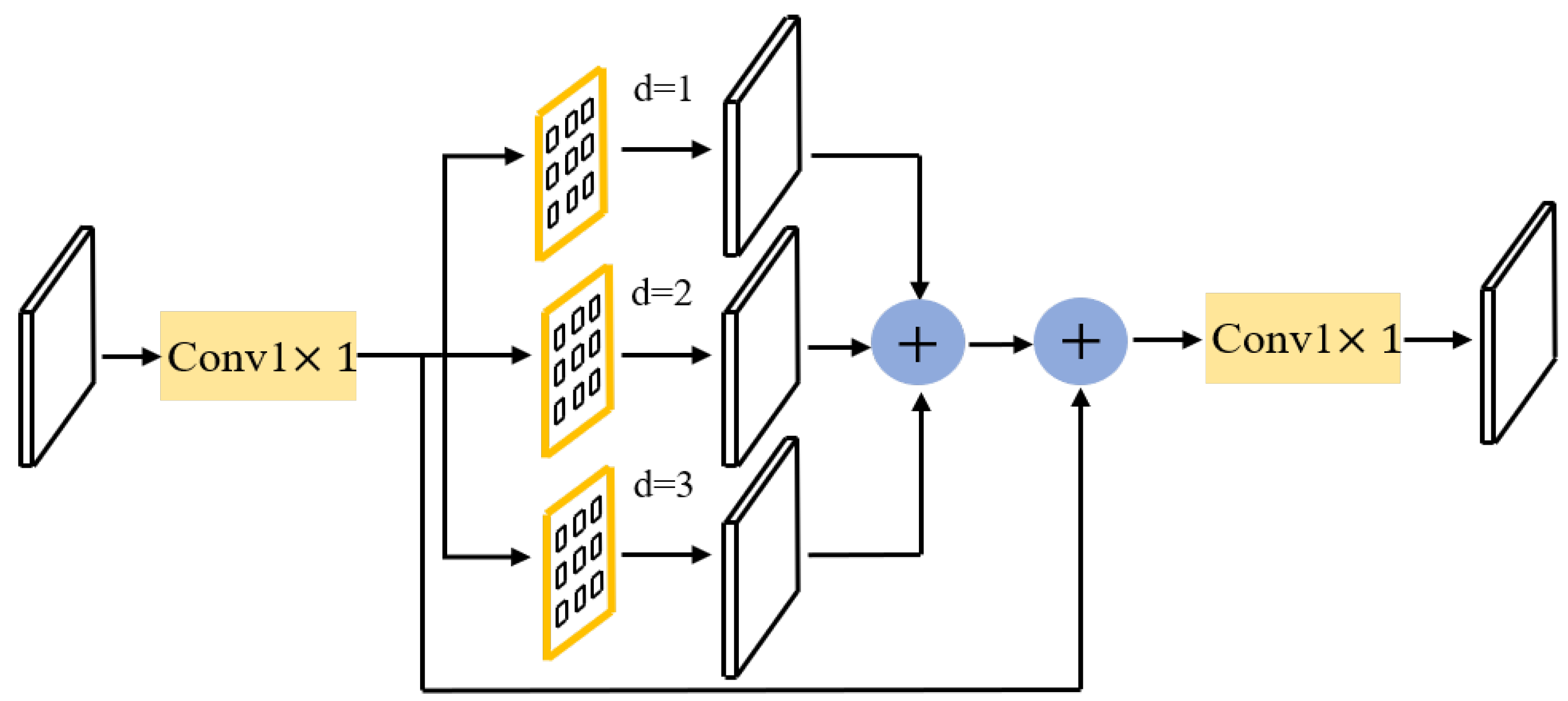
On the basis of the analysis above, our primary goal was to build a straightforward and effective mask head that produces high-quality masks while retaining the robust detection capabilities of Mask R-CNN [
9].To implement it, the FCN [
9] mask-prediction network was used as the base network. The fine-grained mask features were then supplemented with much detailed information in the P2 layer. The detailed information that the model loses can be supplemented by these fine-grained features. The multistage idea is widely used in object detection [
13,
15] and image segmentation [
1,
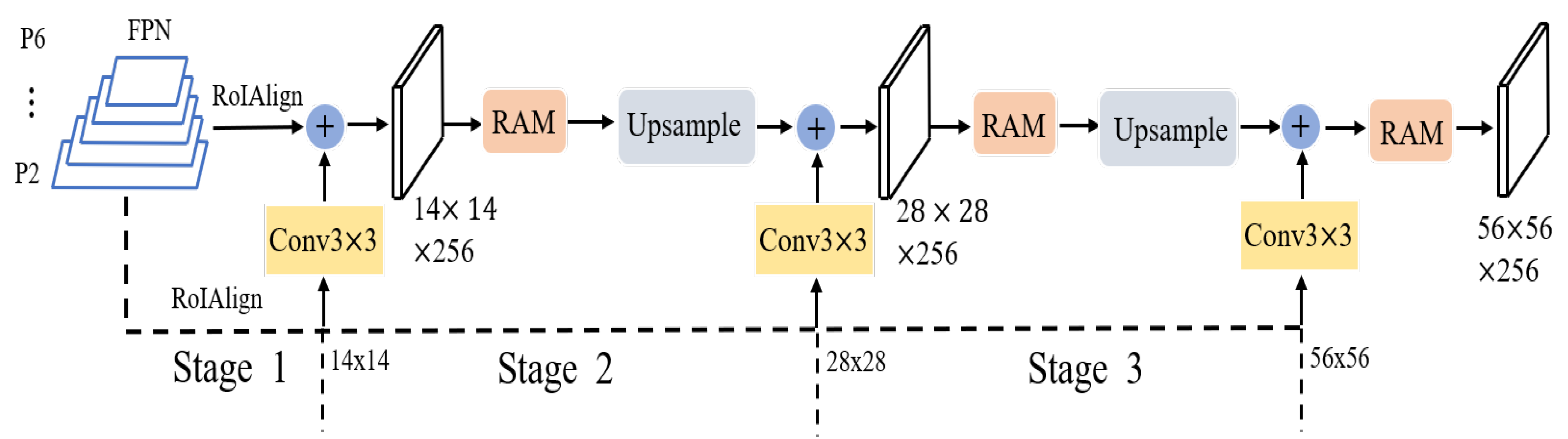
3]. We applied this idea to instance segmentation to compensate for the loss of detailed features caused by ROIAlign. In particular, upsampling is used to gradually increase the
feature map to
using FCN as the baseline. Then, after convolutional layers, fine-grained features are gradually fused to produce high-quality mask prediction by parallelizing a fine-grained feature complimentary auxiliary line that extracts various resolution features on the P2 layer using RoIAlign. To address the difficulty of boundary partitioning, the cross-entropy loss function is extended, and boundary region cross-entropy loss (BRCE) is proposed. This loss function enables the model to put the focus on top of the boundary that is difficult to partition. Replacing the mask head with the proposed mask head, the multiscale segmentation inconsistency shown in
Figure 2 occurs. Different resolutions may impact the cross-entropy loss function, which results in unstable segmentation. Balanced cross-entropy, focal [
16], Dice [
17], and their combinations of loss functions are used, and the effect is mitigated to some extent, but does not completely solve the problem. Due to the poor effect of a single loss function, multiobjective loss function was established.Rank and sort [
18] loss (R and S loss) was introduced to solve the segmentation inconsistency. Boundary region cross-entropy loss was proposed to segment a finer boundary. By combining the two loss functions above, the BRank and Sort loss function is proposed. BRefine obtains significant results in segmentation tasks, especially in the target’s curved parts, and could obtain clear boundary masks.
We evaluated BRefine on different datasets and achieved significant segmentation results. Compared with Mask R-CNN, BRefine could output better segmentation quality, especially in difficult boundary regions. For large targets, the performance was improved by 5.0 AP.
2. Related Work
Instance segmentation. In recent years, the mainstream instance segmentation methods adopted a top–down segmentation method, that is, a powerful detector is used to generate a target frame, and then each pixel in the object frame is classified into the foreground and background. Deeper backbone networks are frequently used to enhance the performance of object detectors. This type of network, however, uses more downsampling operations, resulting in the loss of a large amount of image detail information. RoIAlign [
9] performs scale normalization and feature extraction from the feature pyramid [
11], which exacerbates the loss of image details and hinders producing high-quality instance masks. To obtain high-quality instance masks, instance segmentation is performed by supplementing detailed features.
Semantic segmentation. To supplement detailed information, the encoder–decoder structure of semantic segmentation increases the spatial resolution of the features. The renowned UNet [
10] network joins the feature map of the encoder to the feature map of the decoder at each stage. The feature pyramid network (FPN) and ResNet network structure of the Mask R-CNN network resembles that of UNet [
12]. The UNet network is different in that it only employs shallow features as segmentation features. The P2 layer provides rich mask information, as shown in
Figure 1. Therefore, we used the P2 layer as a mask detail supplement feature. The detailed features of different resolutions are fused by a multistage approach. Loss function. Cross-entropy loss in segmentation tasks is susceptible to foreground and background pixels, favoring the side with more pixel points. Therefore, it requires a high balance of positive and negative pixels. Focal loss [
16], proposed by He and others, addresses hard and easy samples, and positive and negative samples. On the basis of the cross-entropy loss function, we added the coefficients of positive and negative sample coefficients, and hard and easy sample coefficients. During the training process, the model focuses on samples in the priority order of positive hard, negative hard, positive easy, and negative easy. Dice [
17] loss is a region-dependent loss function that, in semantic segmentation, primarily addresses the issue of extreme imbalance between positive and negative samples. In extreme circumstances, it may result in training instability. In addition to the above traditional loss functions, ranking-based loss functions directly optimize the performance metric, rendering the training and evaluation consistent, representing loss functions such as AP loss [
19], and aLRP loss [
20]. Such loss functions address classification and regression inconsistencies by concentrating more on positive than on negative samples. On the basis of these ranking-based loss functions, rank and sort loss [
18] (R and S loss) is proposed. It further ranks the positive samples according to IoU and can address data imbalance. In addition, this function uses a heuristic algorithm to unify the multitask loss function.
5. Discussion
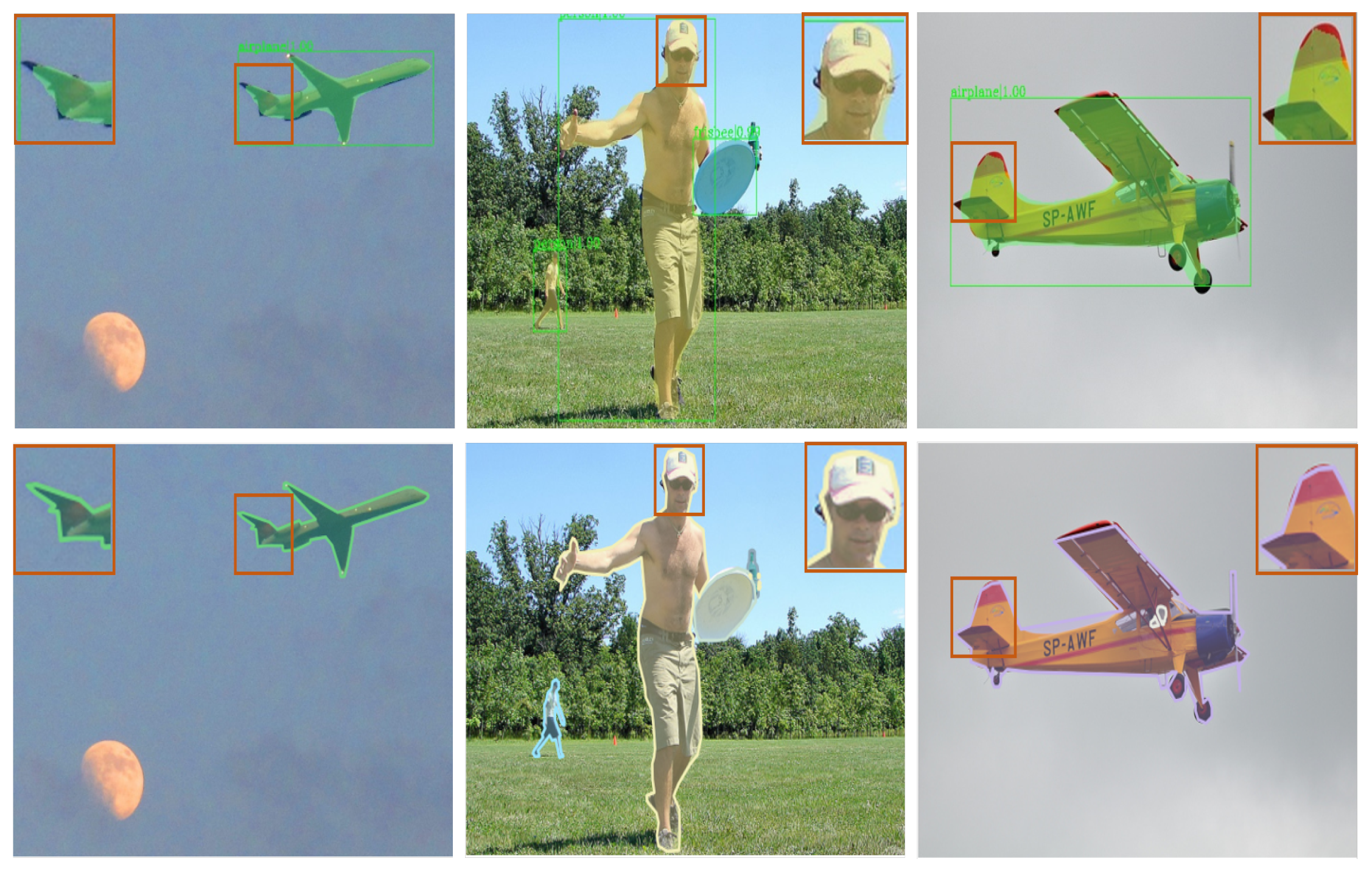
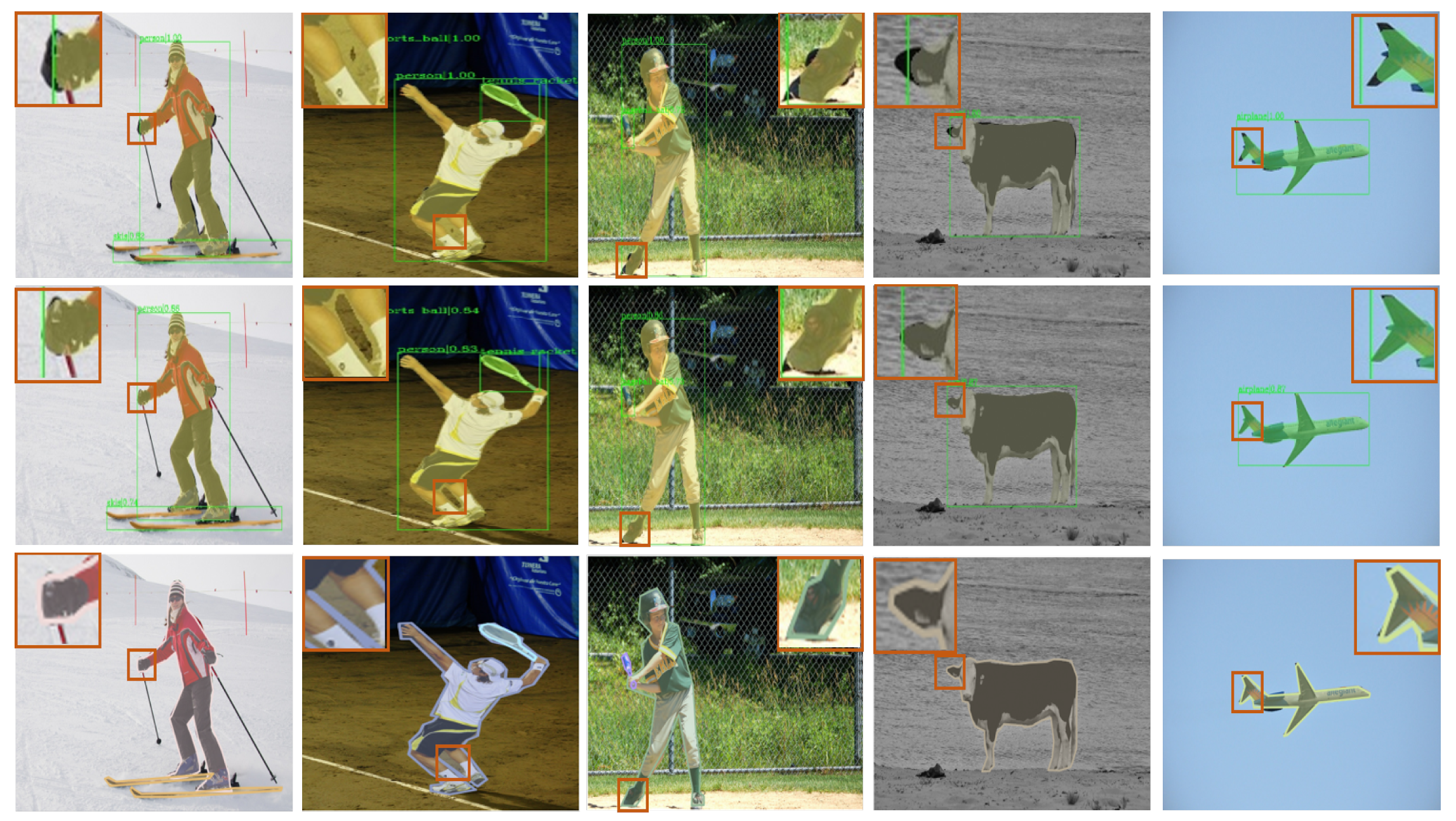
In this work, we aimed to solve the mask coarseness problem in instance segmentation. The visualization (
Figure 7) demonstrates that BRefine could output high-quality masks, especially in curved boundary areas to overcome polygon annotation defects. In comparison with previous methods (
Table 2), BRefine achieved excellent performance.
However, BRefine still has limitations, mainly in the form of poor real-time performance (
Table 2) and the lack of the interpretability of segmentation inconsistencies. Extracting the detailed information of objects at different scales on shallow features and higher output resolution features increases the computational cost, which results in poor real-time performance. The experiments (
Table 5) show that the multiscale segmentation inconsistency is not caused by a single loss function, but by multitask losses. In a detection task, classification and regression are trained separately, and the loss is calculated and reverse-optimized. However, in prediction, it is filtered with classification scores. This may result in a bbox with high classification scores, but with bad regression being retained. Due to the top–down structure, feature maps are cropped using the bbox. The cropped feature maps are fed into the mask head. Thus, the segmentation task is directly influenced by the detection task.
Our future work will build on this foundation to design lightweight feature extractors that reduce computational cost and increase inference speed. We also aim to further explore the reasons for inconsistencies being generated in multiscale segmentation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}