

Cross-Modal Reconstruction for Tactile Signal in Human–Robot Interaction

Abstract
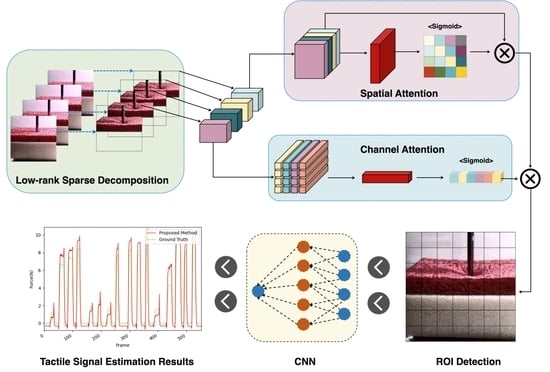
:
1. Introduction
- 1.
- Multidimensional.
- 2.
- Interactive.
- 3.
- Contextually relevant.
- Challenge 1: Hard-to-use video information for reconstruction of haptic information.
- Challenge 2: The network structure is too complicated and the amount of computation is large.
- 1.
- An LRCNN that makes full use of the correlation between GOPs to make the prediction results more accurate is proposed. The network only utilizes the CNN, which reduces the complexity of the network and lowers the requirements for equipment.
- 2.
- We add the LAM to the LRCNN to make it perform better. Through the LAM, the network can better extract the features of the ROIs so that the results are better. In the case of complex illumination, the LRCNN with LAM improves the performance of the experimental materials beyond 40%. Moreover, the proposed attention mechanism can be better used in combination.
2. Related Work
2.1. Video Stream Processing
2.2. Haptic Signal Processing
2.3. Video Reconstruction of Haptic Information
3. Proposed Method
3.1. Preprocessing
3.2. LAM
3.3. LRCNN
4. Experiment and Evaluation
4.1. Dataset and Preprocessing
4.2. Experimental Setup
4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vuletic, T. Systematic literature review of hand gestures used in human computer interaction interfaces. Int. J. Hum.-Comput. Stud. 2019, 129, 74–94. [Google Scholar] [CrossRef]
- Fang, Y.; Wu, B.; Huang, F.; Tang, W. Research on teleoperation surgery simulation system based on virtual reality. In Proceeding of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014. [Google Scholar]
- Park, C.H.; Howard, A.M. Towards real-time haptic exploration using a mobile robot as mediator. In Proceedings of the IEEE Haptics Symposium, Waltham, MA, USA, 25–26 March 2010. [Google Scholar]
- Romano, J.M.; Kuchenbecker, K.J. Methods for robotic tool-mediated haptic surface recognition. In Proceedings of the IEEE Haptics Symposium (HAPTICS), Houston, TX, USA, 23–26 February 2014. [Google Scholar]
- Pham, T.H.; Kheddar, A.; Qammaz, A.; Argyros, A.A. Towards force sensing from vision: Observing hand-object interactions to infer manipulation forces. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ehsani, K.; Tulsiani, S.; Gupta, S.; Farhadi, A.; Gupta, A. Use the Force, Luke! Learning to Predict Physical Forces by Simulating Effects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Naeini, F.B.; AlAli, A.M.; Al-Husari, R.; Rigi, A.; Al-Sharman, M.K.; Makris, D.; Zweiri, Y. A Novel Dynamic-Vision-Based Approach for Tactile Sensing Applications. IEEE Trans. Instrum. Meas. 2020, 69, 1881–1893. [Google Scholar] [CrossRef]
- Kalsotra, R.; Arora, S. A Comprehensive Survey of Video Datasets for Background Subtraction. IEEE Access 2019, 7, 59143–59171. [Google Scholar] [CrossRef]
- Gutchess, D.; Trajkovics, M.; Cohen-Solal, E.; Lyons, D.; Jain, A.K. A background model initialization algorithm for video surveillance. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; pp. 20017–142001. [Google Scholar]
- Chen, C.C.; Aggarwal, J.K. An adaptive background model initialization algorithm with objects moving at different depths. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008. [Google Scholar]
- Han, G.; Zhang, G.; Zhang, G. Background Initialization Based on Adaptive Online Low-rank Subspace Learning. In Proceedings of the 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image De-Raining Using a Conditional Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Chen, J.; Tan, C.-H.; Hou, E.J. Robust Video Content Alignment and Compensation for Rain Removal in a CNN Framework. In Proceedings of the Robust Video Content Alignment and Compensation for Rain Removal in a CNN Framework, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, M.; Cao, X.; Zhao, Q.; Zhang, L.; Gao, C.; Meng, D. Video Rain/Snow Removal by Transformed Online Multiscale Convolutional Sparse Coding. arXiv 2019, arXiv:1909.06148. [Google Scholar]
- Moore, B.E.; Gao, C.; Nadakuditi, R.R. Panoramic Robust PCA for Foreground–Background Separation on Noisy, Free-Motion Camera Video. IEEE Trans. Comput. Imaging 2019, 5, 195–211. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Zhang, H.; Lin, Z.; Otazo, R. On the Applications of Robust PCA in Image and Video Processing. Proc. IEEE 2018, 16, 1427–1457. [Google Scholar] [CrossRef]
- Ye, X.; Yang, J.; Sun, X.; Li, K.; Hou, C.; Wang, Y. Foreground–Background Separation From Video Clips via Motion-Assisted Matrix Restoration. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1721–1734. [Google Scholar] [CrossRef]
- Zhong, Z.; Zhang, B.; Lu, G.; Zhao, Y.; Xu, Y. An Adaptive Background Modeling Method for Foreground Segmentation. Adapt. Backgr. Model. Method Foreground Segmentation 2017, 18, 1109–1121. [Google Scholar] [CrossRef]
- Toyama, K.; Krumm, J.; Brumitt, B. Wallflower: Principles and practice of background maintenance. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Chalidabhongse, T.H.; Kim, K.; Harwood, D.; Davis, L. A perturbation method for evaluating background subtraction algorithms. In Proceedings of the Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance (VS-PETS), Beijing, China, 12–13 October 2003. [Google Scholar]
- Yang, T.; Pan, Q.; Li, S.Z. Multiple layer based background maintenance in complex environment. In Proceedings of the Third International Conference on Image and Graphics (ICIG’04), Hong Kong, China, 18–20 December 2004. [Google Scholar]
- Peng, D.-Z.; Lin, C.-Y.; Sheu, W.-T. Architecture design for a low-cost and low-complexity foreground object segmentation with Multi-model Background Maintenance algorithm. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- He, R.T. Robust principal component analysis based on maximum correntropy criterion. IEEE Trans. Image Process. 2011, 20, 1485–1494. [Google Scholar]
- YukiY, T. Constrained nonmetric principal component analysis. Behaviormetrika 2019, 4, 313–332. [Google Scholar]
- Islam, R.; Ahmed, B.; Hossain, D. Feature Reduction Based on Segmented Principal Component Analysis for Hyperspectral Images Classification. In Proceedings of the International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices. Adv. Neural Inf. Process. Syst. 2009, 4, 3–56. [Google Scholar]
- Dang, C.; Radha, H. RPCA-KFE: Key frame extraction for video using robust principal component analysis. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2015, 11, 3742–3753. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Wu, D.; Wei, X.; Chen, J. Cross-Modal Stream Scheduling for eHealth. IEEE J. Sel. Areas Commun. 2021, 9, 426–437. [Google Scholar] [CrossRef]
- Liang Zhou, T. Cross-Modal Collaborative Communications. IEEE Wirel. Commun. 2021, 27, 112–117. [Google Scholar] [CrossRef]
- Zhou, L.; Wu, D.; Chen, J.; Wei, X. Seeing Isn’t Believing: QoE Evaluation for Privacy-Aware Users. IEEE J. Sel. Areas Commun. 2019, 37, 1656–1665. [Google Scholar] [CrossRef]
- Wu, Y.; Yue, C.; Yang, Y.; Ao, L. Resource allocation for D2D-assisted haptic communications. Digit. Commun. Netw. 2022, 8, 2352–8648. [Google Scholar] [CrossRef]
- Liu, S.; Yu, Y.; Guo, L.; Yeoh, P.L.; Vucetic, B.; Li, Y. Adaptive delay-energy balanced partial offloading strategy in Mobile Edge Computing networks. Digit. Commun. Netw. 2022, 8, 2352–8648. [Google Scholar] [CrossRef]
- Hangai, S.; Nozaki, T. Haptic Data Prediction and Extrapolation for Communication Traffic Reduction of Four-Channel Bilateral Control System. IEEE Trans. Ind. Inform. 2021, 17, 2611–2620. [Google Scholar] [CrossRef]
- Nozaki, T.; Shimizu, S.; Murakami, T.; Oboe, R. Impedance Field Expression of Bilateral Control for Reducing Data Traffic in Haptic Transmission. IEEE Trans. Ind. Electron. 2019, 66, 1142–1150. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hwang, W.; Lim, S.C. Inferring Interaction Force from Visual Information without Using Physical Force Sensors. Sensors 2017, 17, 2455. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.H.; Hwang, W.; Lim, S.C. Interaction Force Estimation Using Camera and Electrical Current Without Force/Torque Sensor. IEEE Sens. J. 2018, 18, 8863–8872. [Google Scholar] [CrossRef]
- Kim, D.; Cho, H.; Shin, H.; Lim, S.C.; Hwang, W. An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video. Sensors 2019, 19, 3579. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.; Cho, H.; Kim, D.; Ko, D.K.; Lim, S.C.; Hwang, W. Sequential Image-Based Attention Network for Inferring Force Estimation Without Haptic Sensor. IEEE Access 2019, 7, 150237–150246. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, T.; Qi, J. Progressive Attention Guided Recurrent Network for Salient Object Detection. In Proceedings of the 7th International Conference on Robot Intelligence Technology and Applications (RiTA), Daejeon, Korea, 18–23 June 2018. [Google Scholar]
- Cho, H.; Kim, H.; Ko, D.-K. Which LSTM Type is Better for Interaction Force Estimation? In Proceedings of the 7th International Conference on Robot Intelligence Technology and Applications (RiTA), Daejeon, Korea, 1–3 November 2019. [Google Scholar]
- Ahmed, E.; Moustafa, M.N. House Price Estimation from Visual and Textual Features. In Proceedings of the IJCCI, Porto, Portugal, 9–11 November 2016. [Google Scholar]
- Mnih, T. Recurrent Models of Visual Attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Bahdanau, T. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. Comput. Sci. 2015, 4, 259–272. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Jang, T. ANFIS: Adaptive-Network-Based Fuzzy Inference System. IEEE Trans. SMC 1993, 3, 665–685. [Google Scholar] [CrossRef]
- Tang, Y. Learn: TensorFlow’s High-level Module for Distributed Machine Learning. arXiv 2016, arXiv:1612.04251. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Types | Kernel Nums |
|---|---|---|
| Layer1-1 | conv | 64 |
| Layer1-2 | conv | 64 |
| Pooling1 | Maxpooling (stride2) | |
| Layer2-1 | conv | 128 |
| Layer2-2 | conv | 128 |
| Pooling2 | Maxpooling (stride2) | |
| Layer3-1 | conv | 256 |
| Layer3-2 | conv | 256 |
| Layer3-3 | conv | 256 |
| Pooling3 | Maxpooling (stride2) | |
| Layer4-1 | conv | 512 |
| Layer4-2 | conv | 512 |
| Layer4-2 | conv | 512 |
| Pooling4 | Maxpooling (stride2) | |
| Layer5-1 | conv | 512 |
| Layer5-2 | conv | 512 |
| Layer5-2 | conv | 512 |
| Pooling2 | Maxpooling (stride2) | |
| Flatten | Flatten () | |
| Fully connect 1 | FC-4096 | |
| Fully connect 2 | FC-4096 | |
| Fully connect 3 | FC-1 |
| Epoch | Input Size | Batch Size | |||
|---|---|---|---|---|---|
| LRCNN | 0.001 | 0.01 | 100 | 128 × 128 × 3 | 64 |
| Paper Cup | Sponge | Stapler | Tube | |
|---|---|---|---|---|
| single input | 0.0543 | 0.2448 | 1.9392 | 2.4693 |
| LRCNN | 0.0654 | 0.0643 | 0.9133 | 0.7434 |
| LRCNN+LAM | 0.0300 | 0.0256 | 1.0560 | 0.8656 |
| Papercup | Sponge | Stapler | Tube | |
|---|---|---|---|---|
| LRCNN + LSAM | 0.0440 | 0.0092 | 0.7375 | 0.8566 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Xie, Y. Cross-Modal Reconstruction for Tactile Signal in Human–Robot Interaction. Sensors 2022, 22, 6517. https://doi.org/10.3390/s22176517
Chen M, Xie Y. Cross-Modal Reconstruction for Tactile Signal in Human–Robot Interaction. Sensors. 2022; 22(17):6517. https://doi.org/10.3390/s22176517
Chicago/Turabian StyleChen, Mingkai, and Yu Xie. 2022. "Cross-Modal Reconstruction for Tactile Signal in Human–Robot Interaction" Sensors 22, no. 17: 6517. https://doi.org/10.3390/s22176517
APA StyleChen, M., & Xie, Y. (2022). Cross-Modal Reconstruction for Tactile Signal in Human–Robot Interaction. Sensors, 22(17), 6517. https://doi.org/10.3390/s22176517