



Using Multi-Dimensional Dynamic Time Warping to Identify Time-Varying Lead-Lag Relationships


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review of DTW
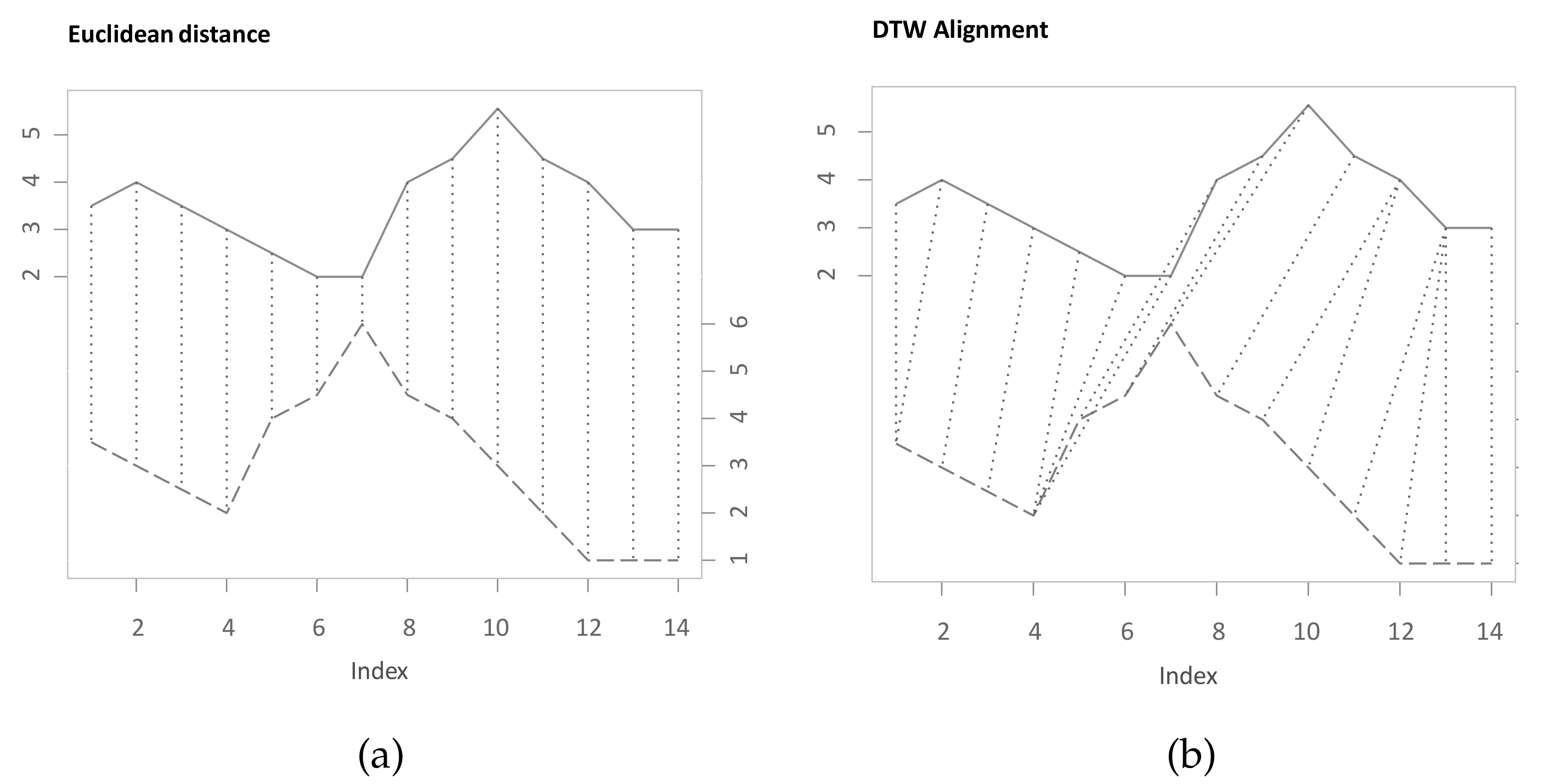
2.1. Concept of Classical DTW
- (a)
- Boundary condition: and .
- (b)
- Monotonicity condition: and .
- (c)
- Step size condition: with .
- (a)
- First column: with .
- (b)
- First row: with .
- (c)
- Remainder:.
2.2. Relevant Adaptions to DTW
2.3. Applications of DTW
2.4. Lead-Lag Relationships with DTW
3. Main Methodology (MM)
3.1. Theoretical Concept
| Algorithm 1 Main methodology to identify time-varying lead-lag relationships. |
| procedureMain step 1: Compute multi-dimensional DTW alignment (Input: two stationary univariate time series). |
| Step 1 Z-normalize both time series. |
| Step 2 Convert univariate time series to multi-dimensional descriptor series |
| as in shapeDTW [4]. |
| Step 2.1 Pad beginning and ending of time series by repeating the first and last |
| element times, respectively. |
| Step 2.2 At each original index i, extract the subsequence of length l centred |
| at i. |
| Step 2.3 Take each subsequence as vector for describing the respective index. |
| Step 2.4 Optionally concatenate subsequence with its first difference to |
| include shape characteristics invariant to the level of the values. |
| Step 3 Z-normalize each dimension to allow for equal contribution as in |
| Shokoohi-Yekta et al. [15]. |
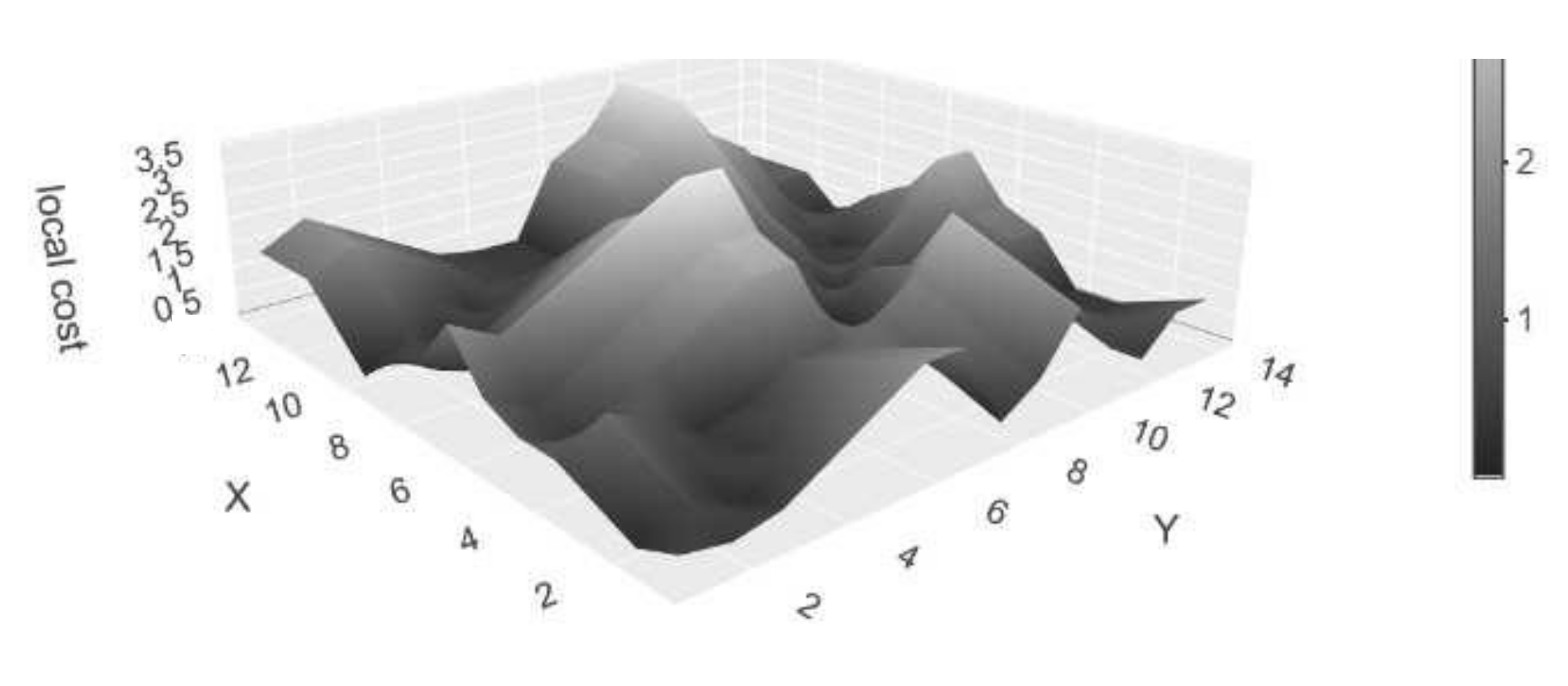
| Step 4 Calculate the local cost matrix using dependent multi-dimensional DTW. |
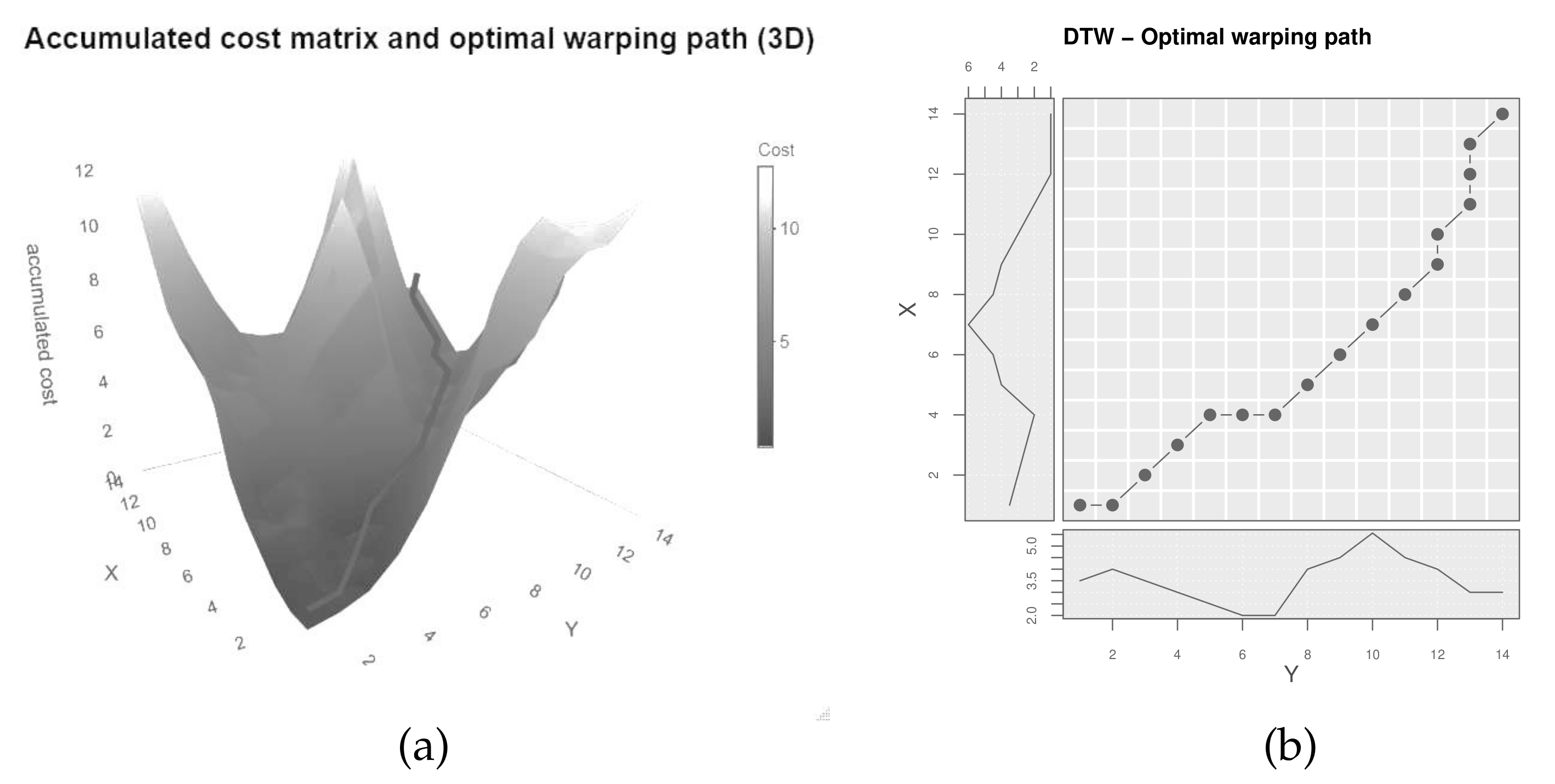
| Step 5 Perform DTW on the local cost matrix, while optionally relaxing the |
| boundary condition. |
| Output DTW distance, optimal warping path, accumulated cost matrix, |
| local cost matrix, optimal start- and endpoint. |
| end procedure |
| procedure Main step 2: Extract lead-lag relationship (Input: optimal warping path, optimal start- and endpoint). |
| Assumption Relationship of the form |
| in similar spirit to Sornette and Zhou [38]. |
| Step 1 If relaxed boundary condition, transfer optimal warping path to |
| indices of original local cost matrix. |
| Step 2 Subtract matched indices of the optimal warping path. |
| Step 3 For each index of Y, take a value that comes last in the optimal warping path. |
| Output Identified lead-lag relationship. |
| end procedure |
3.1.1. Main Step 1: Compute Multi-Dimensional DTW Alignment
3.1.2. Main Step 2: Extract Lead-Lag Relationship
3.2. Software
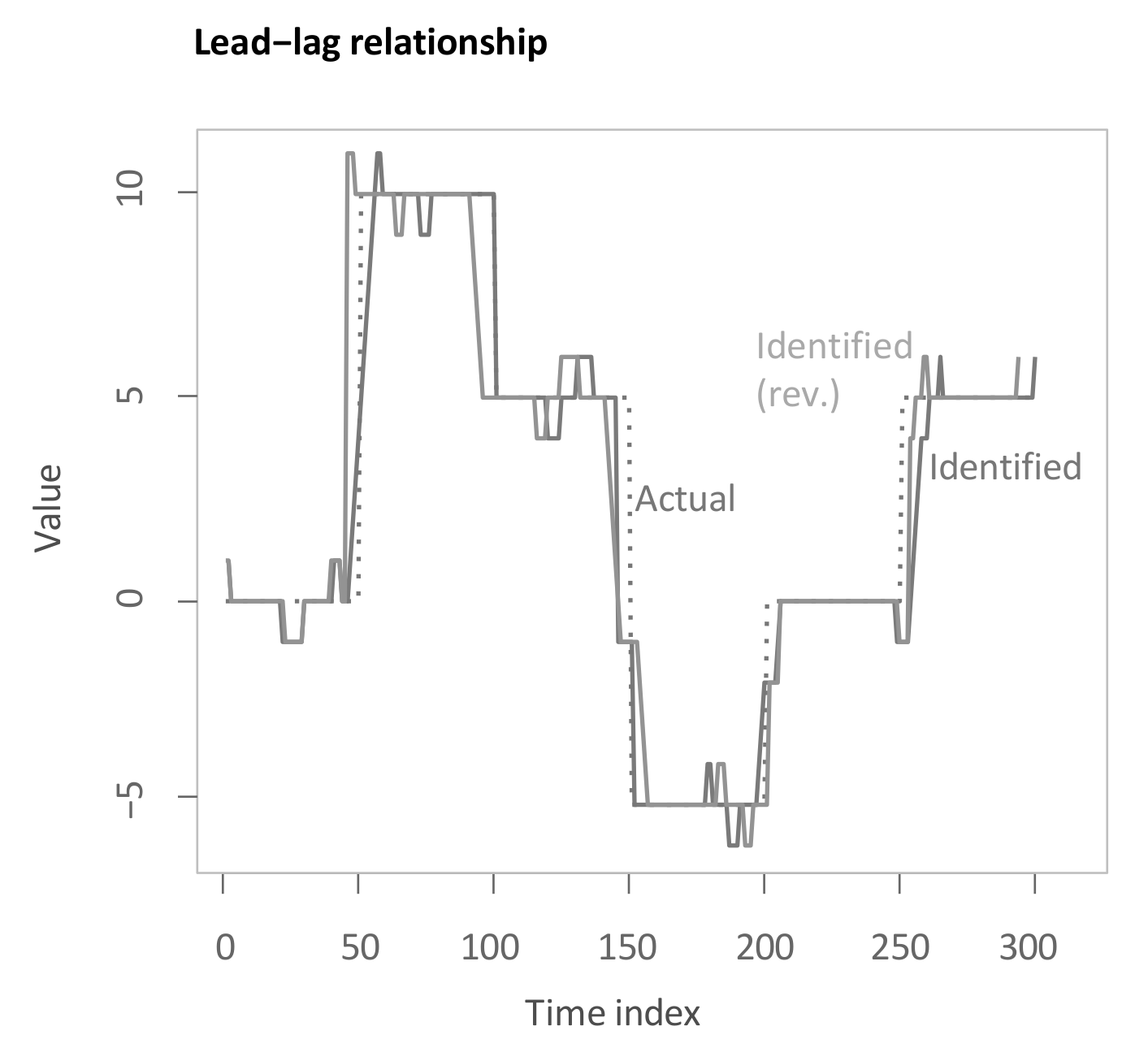
3.3. Example
4. Benchmarks
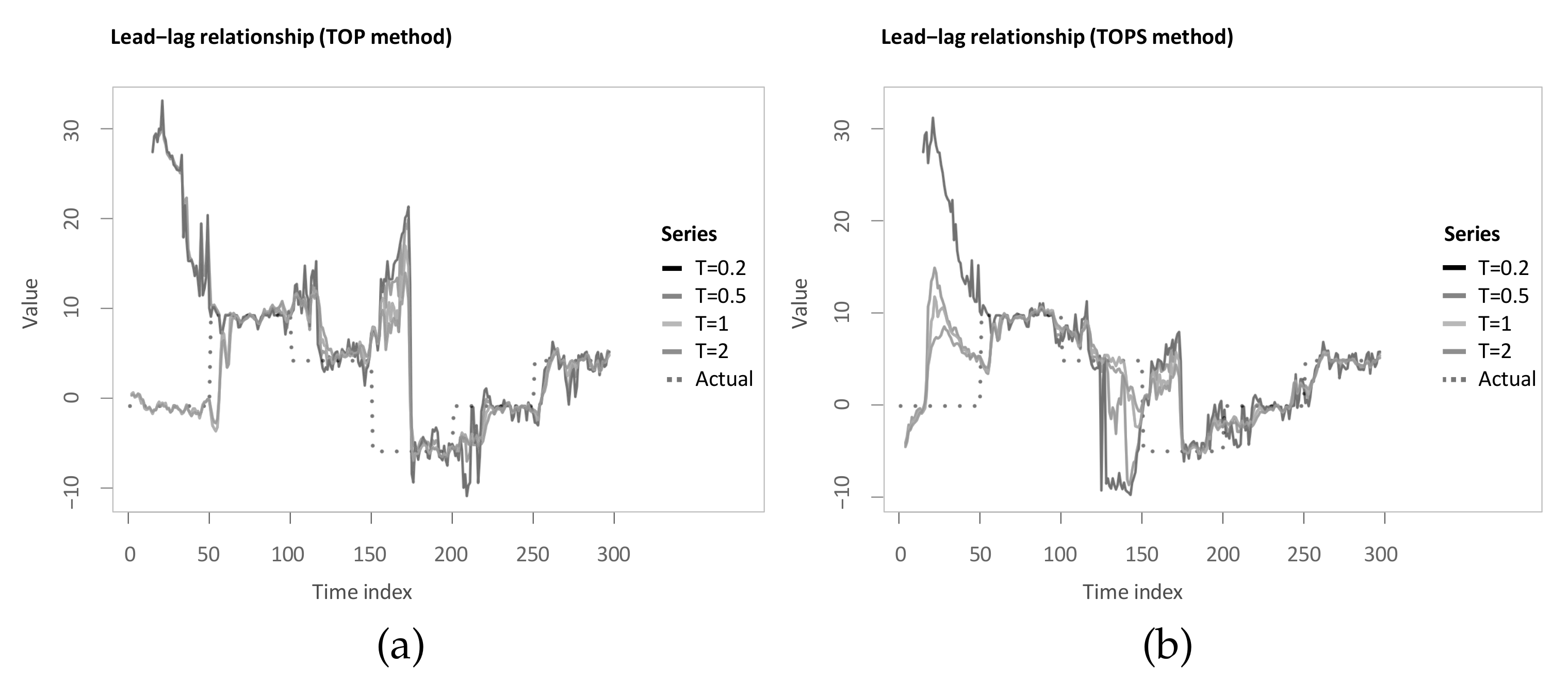
4.1. Thermal Optimal Path (TOP), Symmetric Thermal Optimal Path (TOPS)
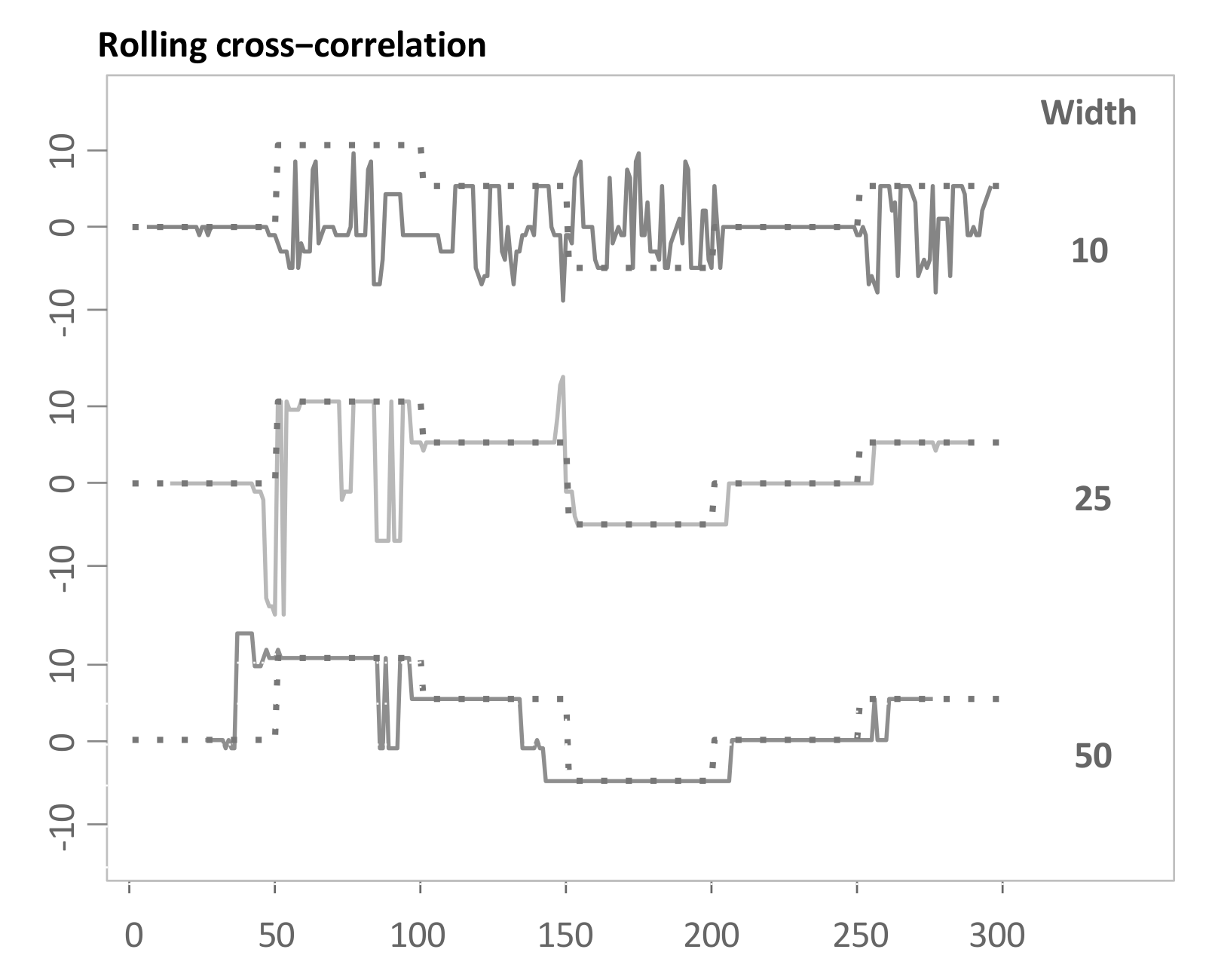
4.2. Rolling Cross-Correlation (RCC)
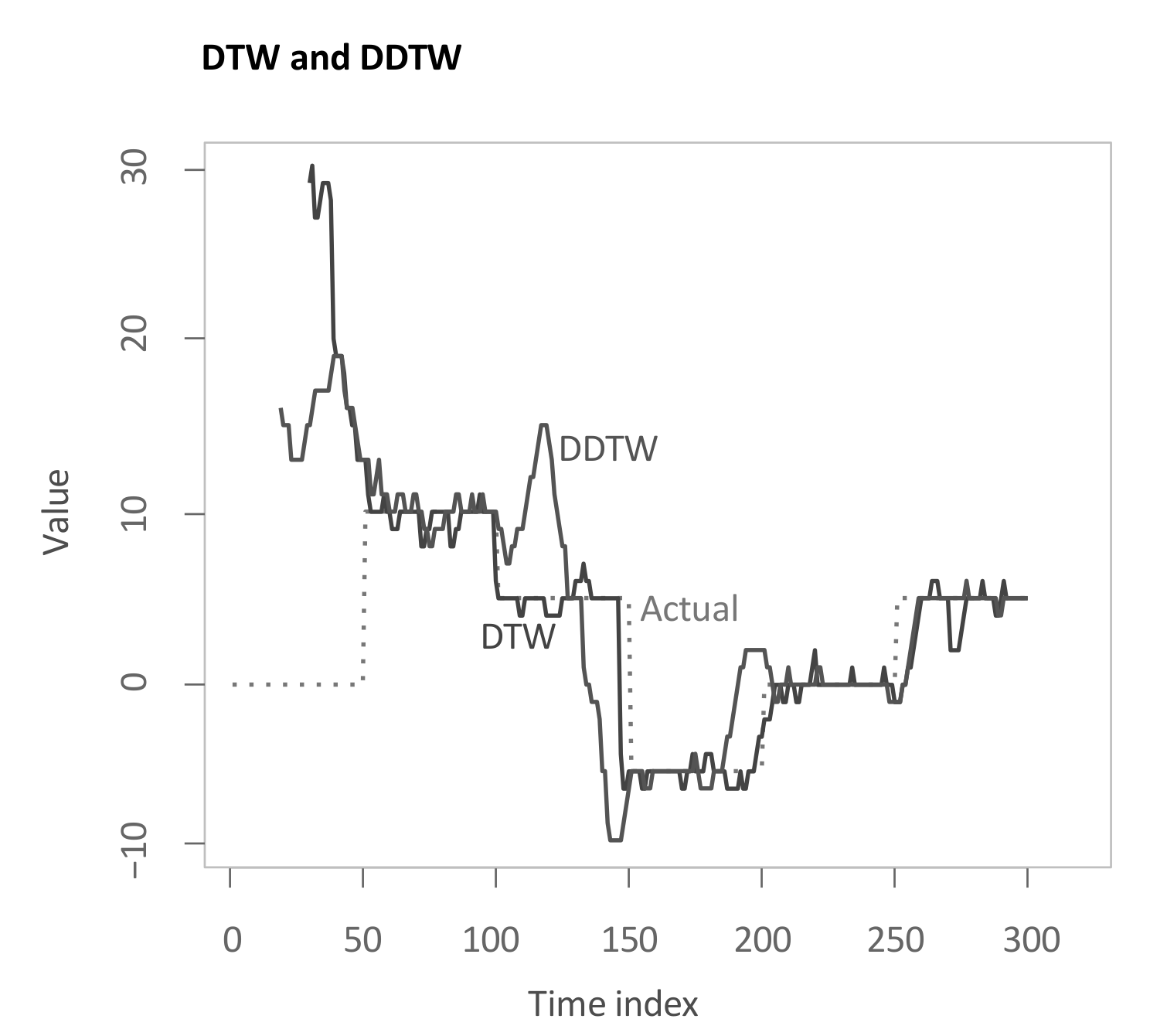
4.3. Dynamic Time Warping (DTW), Derivative Dynamic Time Warping (DDTW)
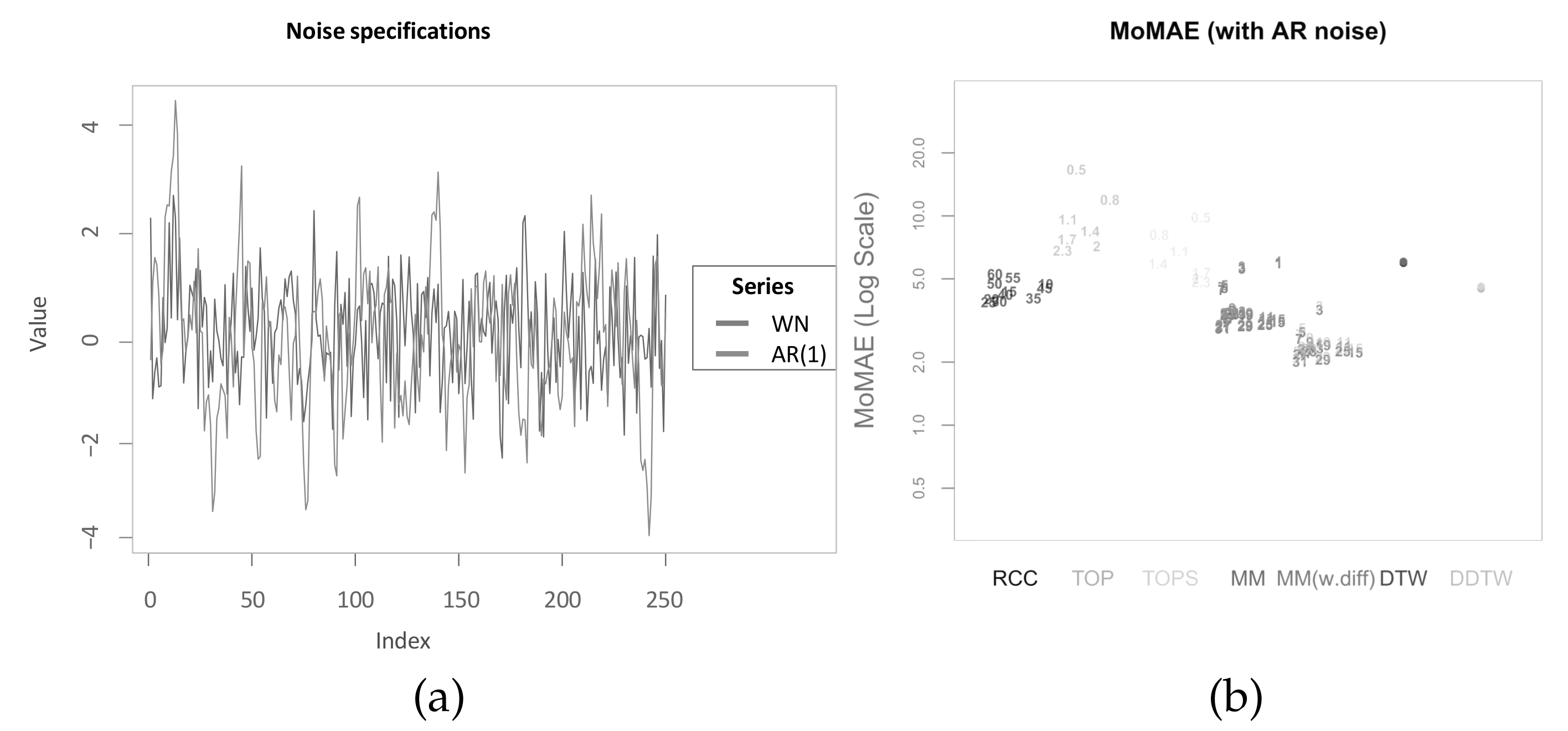
5. Simulation Study
5.1. Assessment Criterion
5.2. Assessment of Methods
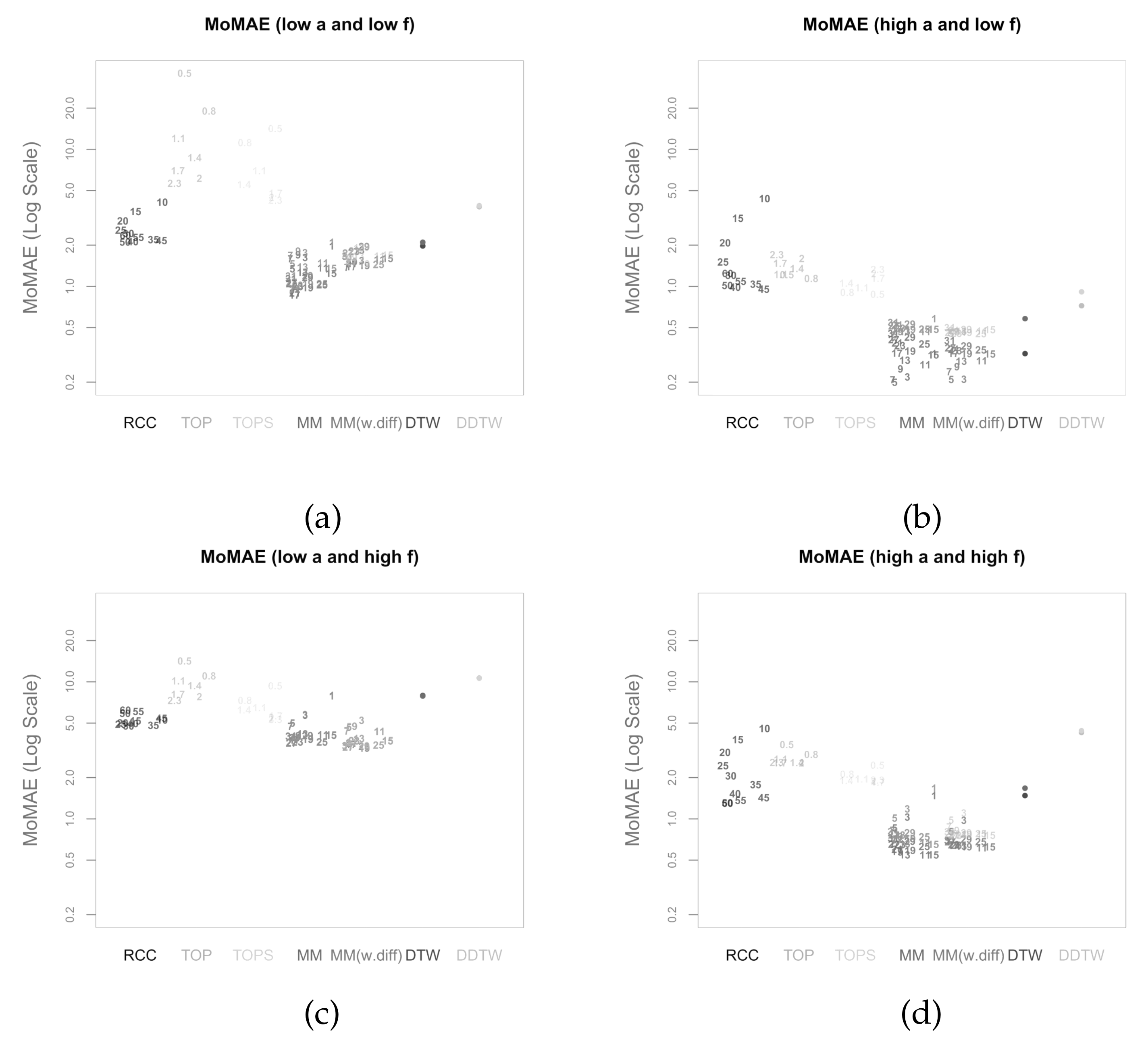
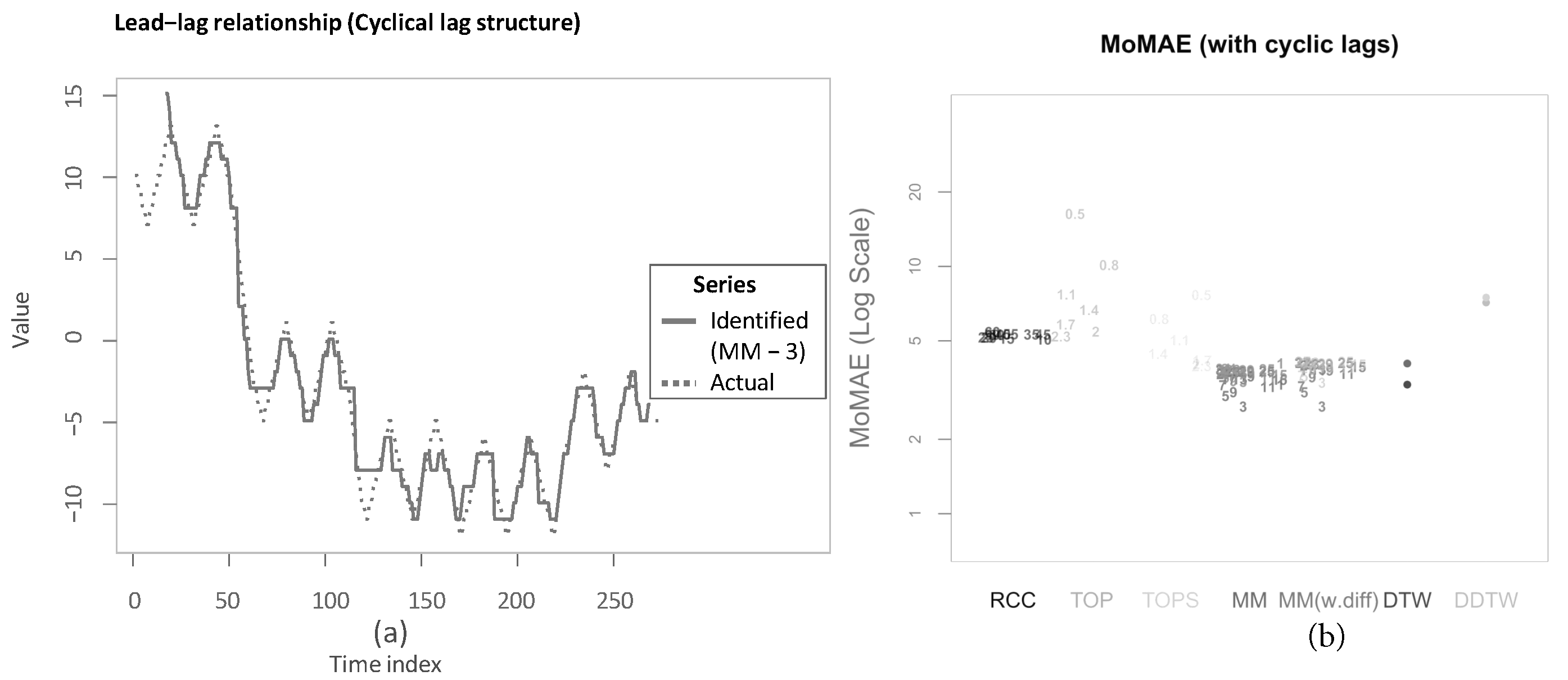
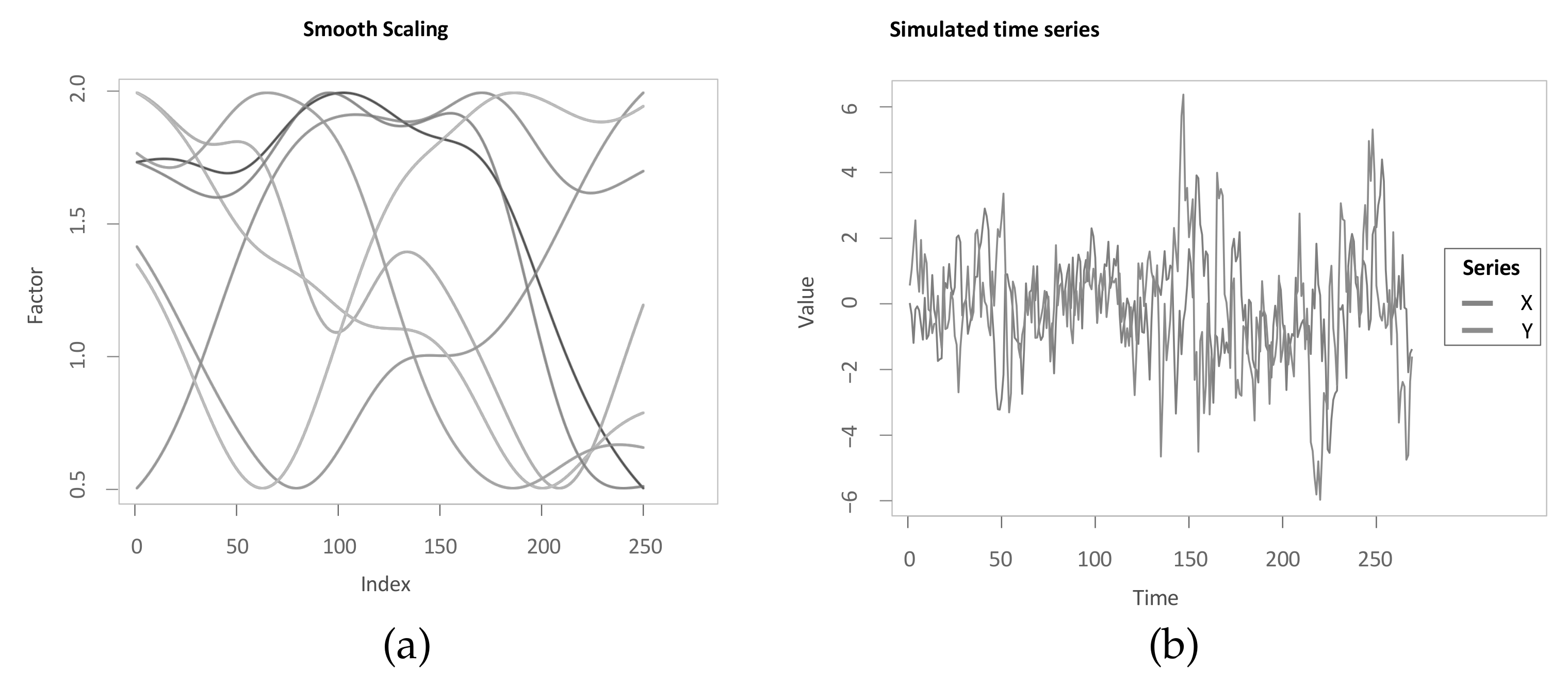
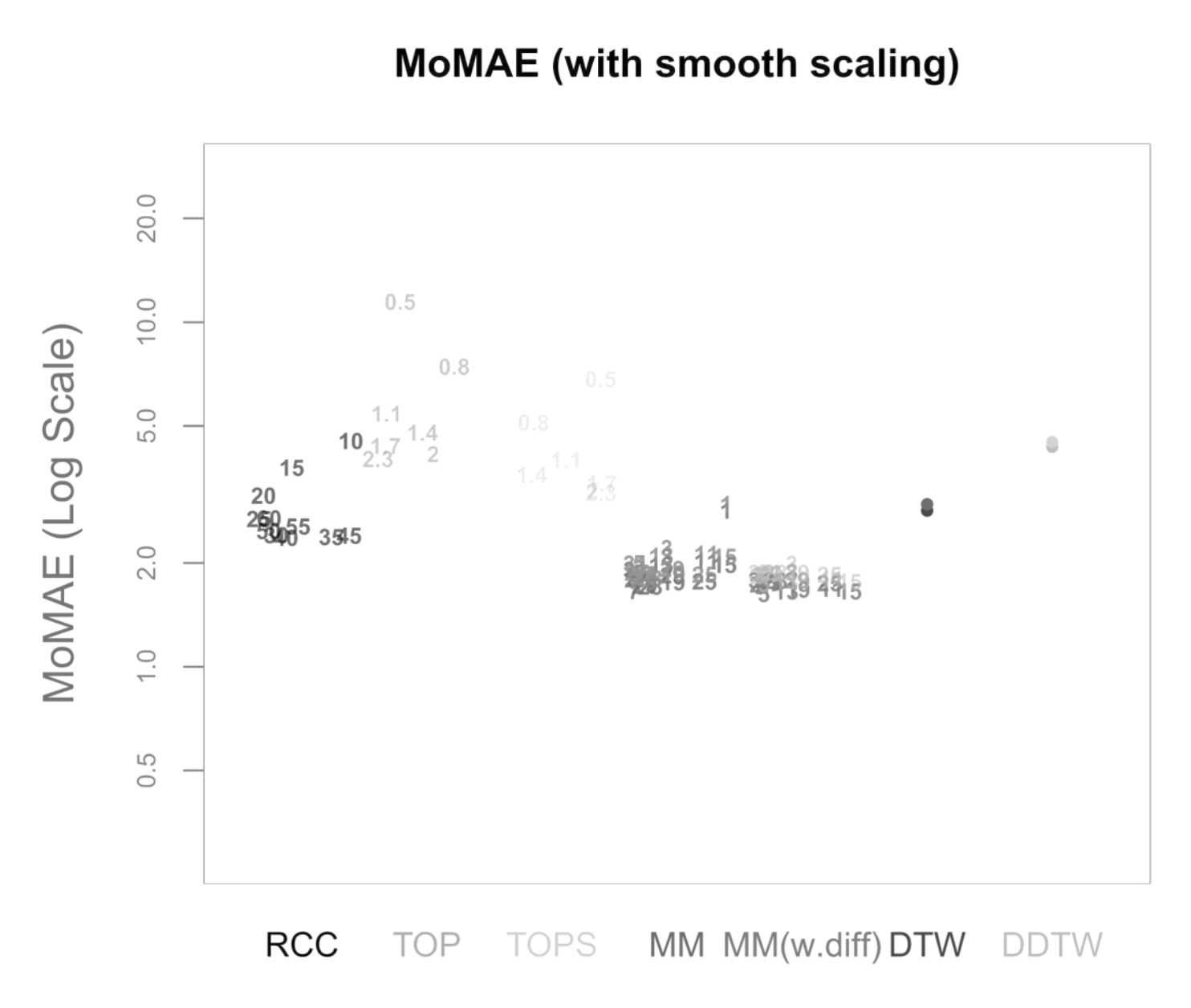
5.3. Robustness Checks
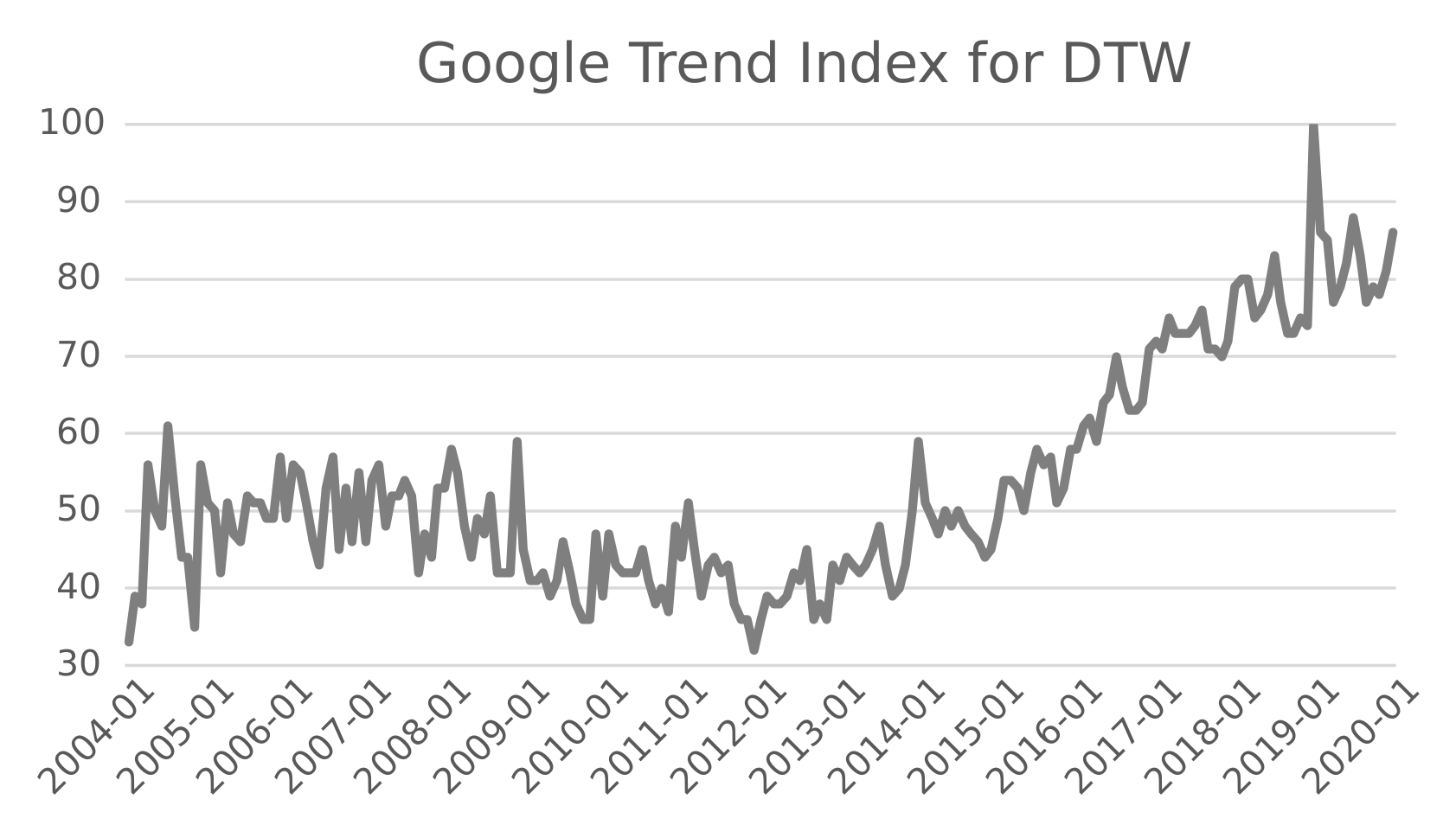
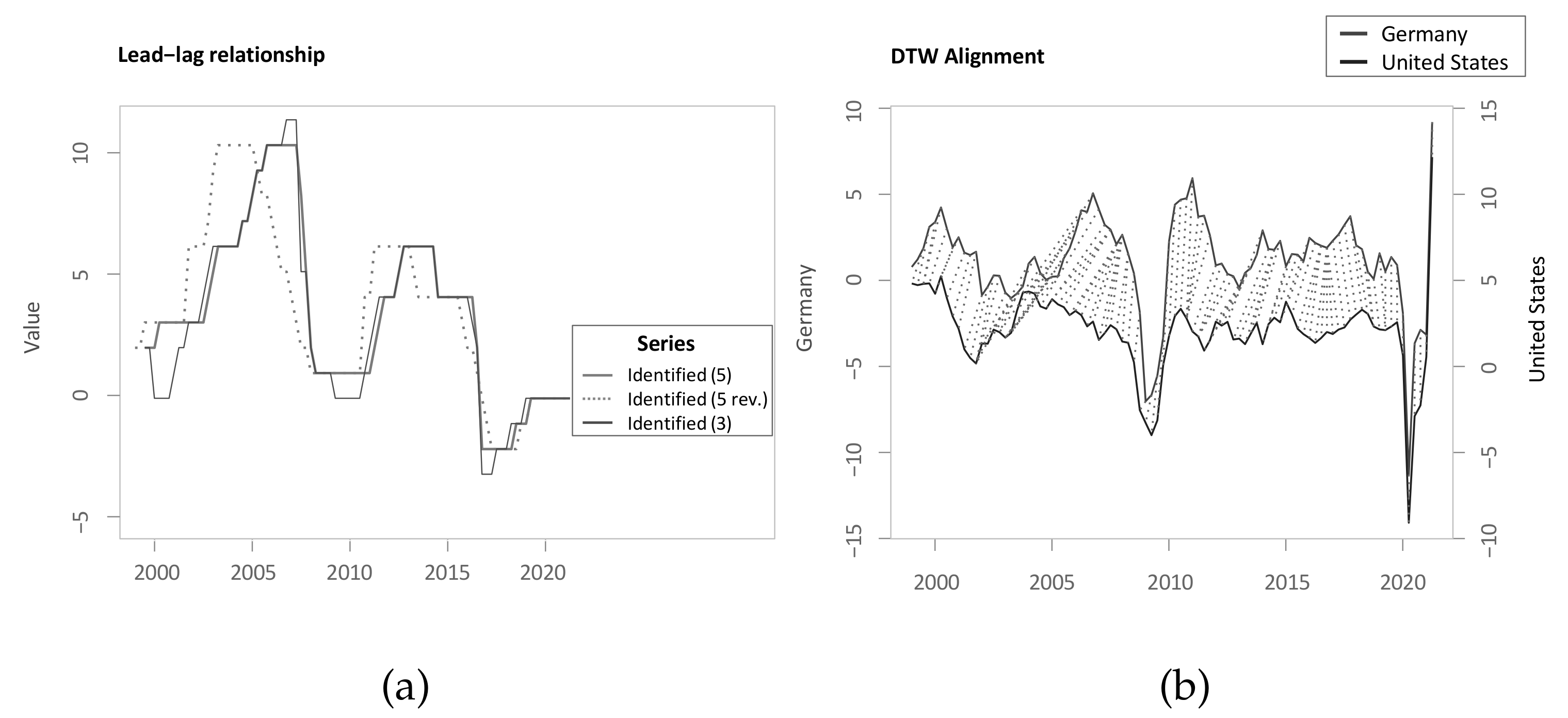
5.4. Real-World Application
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Keogh, E.; Pazzani, M.J. Scaling up dynamic time warping to massive datasets. In Principles of Data Mining and Knowledge Discovery; Goos, G., Hartmanis, J., van Leeuwen, J., Żytkow, J.M., Rauch, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1704, pp. 1–11. [Google Scholar]
- Müller, M. Dynamic time warping. In Information Retrieval for Music and Motion; Müller, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Mueen, A.; Keogh, E. Extracting optimal performance from dynamic time warping. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: San Francisco, CA, USA, 2016; pp. 2129–2130. [Google Scholar]
- Zhao, J.; Itti, L. shapeDTW: Shape dynamic time warping. Pattern Recognit. 2018, 74, 171–184. [Google Scholar] [CrossRef]
- Lin, T.; Wang, M.; Yang, M.; Yang, X. A hidden Markov ensemble algorithm design for time series analysis. Sensors 2022, 22, 2950. [Google Scholar] [CrossRef] [PubMed]
- Meng, H.; Xu, H.C.; Zhou, W.X.; Sornette, D. Symmetric thermal optimal path and time-dependent lead-lag relationship: Novel statistical tests and application to UK and US real-estate and monetary policies. Quant. Financ. 2017, 17, 959–977. [Google Scholar] [CrossRef]
- Li, J.; Gao, Y.; Gao, X.; Shi, Y.; Chen, G. SENTI2POP: Sentiment-aware topic popularity prediction on social media. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1174–1179. [Google Scholar]
- Senin, P. Dynamic time Warping Algorithm Review; Information and Computer Science Department University of Hawaii: Manoa, HI, USA, 2008; Volume 855, p. 40. [Google Scholar]
- Giorgino, T. Computing and visualizing dynamic time warping alignments in R: The dtw package. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Pagiatakis, S.D.; Hassan, Q.K. A survey on change detection and time series analysis with applications. Appl. Sci. 2021, 11, 6141. [Google Scholar] [CrossRef]
- Keogh, E.; Pazzani, M.J. Derivative dynamic time warping. In Proceedings of the 2001 SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2001; pp. 1–11. [Google Scholar]
- Gullo, F.; Ponti, G.; Tagarelli, A.; Greco, S. A time series representation model for accurate and fast similarity detection. Pattern Recognit. 2009, 42, 2998–3014. [Google Scholar] [CrossRef]
- Xie, Y.; Wiltgen, B. Adaptive feature based dynamic time warping. Int. J. Comput. Sci. Netw. Secur. 2010, 10, 264–273. [Google Scholar]
- Moser, U.; Schramm, D. Multivariate dynamic time warping in automotive applications: A review. Intell. Data Anal. 2019, 23, 535–553. [Google Scholar] [CrossRef]
- Shokoohi-Yekta, M.; Hu, B.; Jin, H.; Wang, J.; Keogh, E. Generalizing DTW to the multi-dimensional case requires an adaptive approach. Data Min. Knowl. Discov. 2017, 31, 1–31. [Google Scholar] [CrossRef]
- Ten Holt, G.; Reinders, M.; Hendriks, E. Multi-dimensional dynamic time warping for gesture recognition. In Proceedings of the Thirteenth Annual Conference of the Advanced School for Computing and Imaging, Heijen, The Netherlands, 13–15 June 2007. [Google Scholar]
- Kulbacki, M.; Bak, A. Unsupervised learning motion models Using dynamic time warping. In Intelligent Information Systems 2002; Kłopotek, M.A., Wierzchoń, S.T., Michalewicz, M., Eds.; Physica-Verlag HD: Heidelberg, Germany, 2002; pp. 217–226. [Google Scholar]
- Benedikt, L.; Kajic, V.; Cosker, D.; Rosin, P.L.; Marshall, D. Facial dynamics in biometric identification. In Proceedings of the British Machine Vision Conference 2008, Leeds, UK, 1–4 September 2008; pp. 107.1–107.10. [Google Scholar]
- Górecki, T.; Łuczak, M. Using derivatives in time series classification. Data Min. Knowl. Discov. 2013, 26, 310–331. [Google Scholar] [CrossRef]
- Łuczak, M. Hierarchical clustering of time series data with parametric derivative dynamic time warping. Expert Syst. Appl. 2016, 62, 116–130. [Google Scholar] [CrossRef]
- Skutkova, H.; Vitek, M.; Sedlar, K.; Provaznik, I. Progressive alignment of genomic signals by multiple dynamic time warping. J. Theor. Biol. 2015, 385, 20–30. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, P.; Duan, R. Dynamic time warping under pointwise shape context. Inf. Sci. 2015, 315, 88–101. [Google Scholar] [CrossRef]
- Folgado, D.; Barandas, M.; Matias, R.; Martins, R.; Carvalho, M.; Gamboa, H. Time alignment measurement for time series. Pattern Recognit. 2018, 81, 268–279. [Google Scholar] [CrossRef]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: https://www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 18 June 2022).
- Gasser, T.; Wang, K. Alignment of curves by dynamic time warping. The Annals of Statistics 1997, 25, 1251–1276. [Google Scholar]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Rabiner, L.; Rosenberg, A.; Levinson, S. Considerations in dynamic time warping algorithms for discrete word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 575–582. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Myers, C.; Rabiner, L.; Rosenberg, A. Performance trade-offs in dynamic time warping algorithms for isolated word recognition. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 623–635. [Google Scholar] [CrossRef]
- Ratanamahatana, C.A.; Keogh, E. Three myths about dynamic time warping data mining. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2005; pp. 506–510. [Google Scholar]
- Ding, H.; Trajcevski, G.; Scheuermann, P.; Wang, X.; Keogh, E. Querying and mining of time series data. Proc. Vldb Endow. 2008, 1, 1542–1552. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Searching and mining trillions of time series subsequences under dynamic time warping. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 262–270. [Google Scholar]
- Ahmed, W.; Chanda, K.; Mitra, S. Vision based hand gesture recognition using dynamic time warping for Indian sign language. In Proceedings of the 2016 International Conference on Information Science (ICIS), Kochi, India, 12–13 August 2016; pp. 120–125. [Google Scholar]
- Calin, A.D. Gesture Recognition on Kinect Time Series Data Using dynamic time warping and Hidden Markov Models. In Proceedings of the 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 24–27 September 2016; pp. 264–271. [Google Scholar]
- Al-Hmouz, R.; Pedrycz, W.; Daqrouq, K.; Morfeq, A.; Al-Hmouz, A. Quantifying dynamic time warping distance using probabilistic model in verification of dynamic signatures. Soft Comput. 2019, 23, 407–418. [Google Scholar] [CrossRef]
- Kim, S.; Lee, H.; Ko, H.; Jeong, S.; Byun, H.; Oh, K. Pattern matching trading system based on the dynamic time warping algorithm. Sustainability 2018, 10, 4641. [Google Scholar] [CrossRef] [Green Version]
- Jeong, Y.S.; Jeong, M.K.; Omitaomu, O.A. Weighted dynamic time warping for time series classification. Pattern Recognit. 2011, 44, 2231–2240. [Google Scholar] [CrossRef]
- Sornette, D.; Zhou, W.X. Non-parametric determination of real-time lag structure between two time series: The ’optimal thermal causal path’ method. Quant. Financ. 2005, 5, 577–591. [Google Scholar] [CrossRef]
- Yue, P.; Fan, Y.; Batten, J.A.; Zhou, W.X. Information transfer between stock market sectors: A comparison between the USA and China. Entropy 2020, 22, 194. [Google Scholar] [CrossRef]
- Granger, C.W.; Jeon, Y. A time-distance criterion for evaluating forecasting models. Int. J. Forecast. 2003, 19, 199–215. [Google Scholar] [CrossRef]
- Varfis, A.; Corleto, L.; Auger, J.M.; Perrotta, D.; Alvarez, M. Lead-Lag Estimation by Means of the Dynamic Time Warping Technique. Research in Official Statistics (European Communities). 2001, p. 5. Available online: https://www.researchgate.net/profile/Stefano-Falorsi/publication/228417589_Generalised_Software_for_Sampling_Errors-GSSE/links/00b7d5181840831dc4000000/Generalised-Software-for-Sampling-Errors-GSSE.pdf#page=4 (accessed on 18 June 2022).
- Gupta, K.; Chatterjee, N. Examining lead-lag relationships in-depth, with focus on FX market as COVID-19 crises unfolds. arXiv 2020, arXiv:2004.10560. [Google Scholar]
- Stübinger, J. Statistical arbitrage with optimal causal paths on high-frequency data of the S&P 500. Quant. Financ. 2019, 19, 921–935. [Google Scholar]
- Taylor, J.; Zhou, X.; Rouphail, N.M.; Porter, R.J. Method for investigating intradriver heterogeneity using vehicle trajectory data: A dynamic time warping approach. Transp. Res. Part B Methodol. 2014, 73, 59–80. [Google Scholar] [CrossRef]
- Claure, Y.N.; Matsubara, E.T.; Padovani, C.; Prati, R.C. PolyWaTT: A polynomial water travel time estimator based on derivative dynamic time warping and perceptually important points. Comput. Geosci. 2018, 112, 54–63. [Google Scholar] [CrossRef]
- Woo, H.; Boccelli, D.L.; Uber, J.G.; Janke, R.; Su, Y. Dynamic time warping for quantitative analysis of tracer study time-series water quality data. J. Water Resour. Plan. Manag. 2019, 145, 04019052. [Google Scholar] [CrossRef]
- Gao, T.; Bao, W.; Li, J.; Gao, X.; Kong, B.; Tang, Y.; Chen, G.; Li, X. DancingLines: An analytical scheme to depict cross-platform event popularity. In Database and Expert Systems Applications; Lecture Notes in Computer Science; Hartmann, S., Ma, H., Hameurlain, A., Pernul, G., Wagner, R.R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11029, pp. 283–299. [Google Scholar]
- Franses, P.H.; Wiemann, T. Intertemporal similarity of economic time series: An application of dynamic time warping. Comput. Econ. 2020, 56, 59–75. [Google Scholar] [CrossRef]
- Ito, K.; Sakemoto, R. Direct estimation of lead-lag relationships using multinomial dynamic time warping. Asia-Pac. Financ. Mark. 2020, 27, 325–342. [Google Scholar] [CrossRef]
- Gupta, K.; Chatterjee, N. Selecting stock pairs for pairs trading while incorporating lead-lag relationship. Phys. A Stat. Mech. Appl. 2020, 551, 124103. [Google Scholar] [CrossRef]
- Guo, K.; Sun, Y.; Qian, X. Can investor sentiment be used to predict the stock price? Dynamic analysis based on China stock market. Phys. A Stat. Mech. Appl. 2017, 469, 390–396. [Google Scholar] [CrossRef]
- Shao, Y.H.; Yang, Y.H.; Shao, H.L.; Stanley, H.E. Time-varying lead-lag structure between the crude oil spot and futures markets. Phys. A Stat. Mech. Appl. 2019, 523, 723–733. [Google Scholar] [CrossRef]
- Xu, H.C.; Zhou, W.X.; Sornette, D. Time-dependent lead-lag relationship between the onshore and offshore Renminbi exchange rates. J. Int. Financ. Mark. Institutions Money 2017, 49, 173–183. [Google Scholar] [CrossRef]
- Keogh, E.; Kasetty, S. On the need for time series data mining benchmarks: A survey and empirical demonstration. Data Min. Knowl. Discov. 2003, 7, 349–371. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Addressing big data time series. ACM Trans. Knowl. Discov. Data 2013, 7, 1–31. [Google Scholar] [CrossRef]
- Silva, D.F.; Batista, G.E.A.P.A.; Keogh, E. Prefix and suffix invariant dynamic time warping. In Proceedings of the IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1209–1214. [Google Scholar]
- Tormene, P.; Giorgino, T.; Quaglini, S.; Stefanelli, M. Matching incomplete time series with dynamic time warping: An algorithm and an application to post-stroke rehabilitation. Artif. Intell. Med. 2009, 45, 11–34. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing-Software; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- RStudio Team. RStudio: Integrated Development Environment for R-Software; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Meyer, D.; Buchta, C. Proxy: Distance and Similarity Measures-Software. 2021. Available online: https://CRAN.R-project.org/package=proxy (accessed on 18 June 2022).
- Sievert, C. Interactive Web-Based Data Visualization with R, Plotly, and Shiny; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Zeileis, A.; Grothendieck, G. zoo: S3 infrastructure for regular and irregular time series. J. Stat. Softw. 2005, 14, 1–27. [Google Scholar] [CrossRef]
- Trapletti, A.; Hornik, K. tseries: Time Series Analysis and Computational Finance-Software. 2020. Available online: https://CRAN.R-project.org/package=tseries (accessed on 18 June 2022).
- Youssefi, F.; Zoej, M.J.V.; Hanafi-Bojd, A.A.; Dariane, A.B.; Khaki, M.; Safdarinezhad, A.; Ghaderpour, E. Temporal monitoring and predicting of the abundance of Malaria vectors using time series analysis of remote sensing data through Google Earth Engine. Sensors 2022, 22, 1942. [Google Scholar] [CrossRef] [PubMed]
- OECD Publishing. Main Economic Indicators—Complete Database. 2012. Available online: https://www.oecd-ilibrary.org/economics/data/main-economic-indicators/main-economic-indicators-complete-database_data-00052-en (accessed on 18 June 2022).
- Duran, H.E.; Ferreira-Lopes, A. Determinants of co-movement and of lead and lag behavior of business cycles in the Eurozone. Int. Rev. Appl. Econ. 2017, 31, 255–282. [Google Scholar] [CrossRef]
- Belke, A.; Domnick, C.; Gros, D. Business cycle synchronization in the EMU: Core vs. periphery. Open Econ. Rev. 2017, 28, 863–892. [Google Scholar] [CrossRef]
- The World Bank Group. Trade (% of GDP)—United States. 2021. Available online: https://data.worldbank.org/indicator/NE.TRD.GNFS.ZS?end=2019&locations=US&start=2004&view=chart (accessed on 18 June 2022).
- Grinsted, A.; Moore, J.C.; Jevrejeva, S. Application of the cross wavelet transform and wavelet coherence to geophysical time series. Nonlinear Process. Geophys. 2004, 11, 561–566. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Ince, E.S.; Pagiatakis, S.D. Least-squares cross-wavelet analysis and its applications in geophysical time series. J. Geod. 2018, 92, 1223–1236. [Google Scholar] [CrossRef]
- Ghaderpour, E. Least-squares wavelet and cross-wavelet analyses of VLBI baseline length and temperature time series: Fortaleza–Hartebeesthoek–Westford–Wettzell. Publ. Astron. Soc. Pac. 2020, 133, 014502. [Google Scholar] [CrossRef]
- Assent, I.; Wichterich, M.; Krieger, R.; Kremer, H.; Seidl, T. Anticipatory DTW for efficient similarity search in time series databases. Proc. Vldb Endow. 2009, 2, 826–837. [Google Scholar] [CrossRef] [Green Version]

















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stübinger, J.; Walter, D. Using Multi-Dimensional Dynamic Time Warping to Identify Time-Varying Lead-Lag Relationships. Sensors 2022, 22, 6884. https://doi.org/10.3390/s22186884
Stübinger J, Walter D. Using Multi-Dimensional Dynamic Time Warping to Identify Time-Varying Lead-Lag Relationships. Sensors. 2022; 22(18):6884. https://doi.org/10.3390/s22186884
Chicago/Turabian StyleStübinger, Johannes, and Dominik Walter. 2022. "Using Multi-Dimensional Dynamic Time Warping to Identify Time-Varying Lead-Lag Relationships" Sensors 22, no. 18: 6884. https://doi.org/10.3390/s22186884
APA StyleStübinger, J., & Walter, D. (2022). Using Multi-Dimensional Dynamic Time Warping to Identify Time-Varying Lead-Lag Relationships. Sensors, 22(18), 6884. https://doi.org/10.3390/s22186884