
An Anomaly Detection Algorithm Based on Ensemble Learning for 5G Environment

Abstract
:1. Introduction
- We propose a neural network composed of a self-attention mechanism and a deep convolutional network, which learns from samples and converts them into sample embeddings.
- We propose a stacking ensemble learning method composed of the autoencoder and base learner, using the autoencoder to remove irrelevant information in the samples and the stacking method to integrate the detection results of sample embedding and the base learner.
- We design a novel loss function to observe the operation of the model through the introduced regularization term and base learner loss value. We use a network traffic dataset under an SDN architecture to evaluate the model’s performance. The results show that the model has a better abnormal traffic detection effect than the comparison model.
2. Related Works
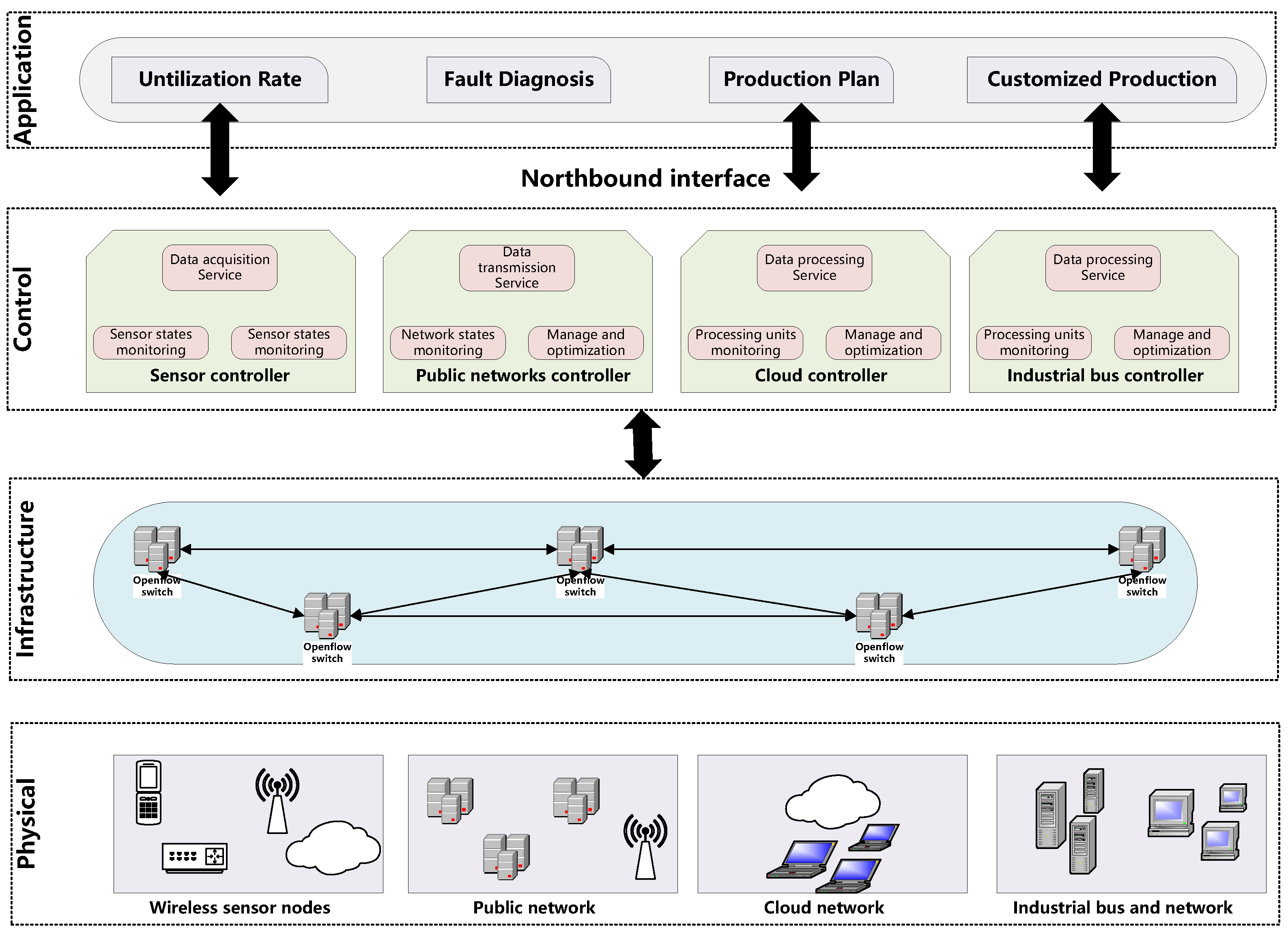
3. Materials and Methods
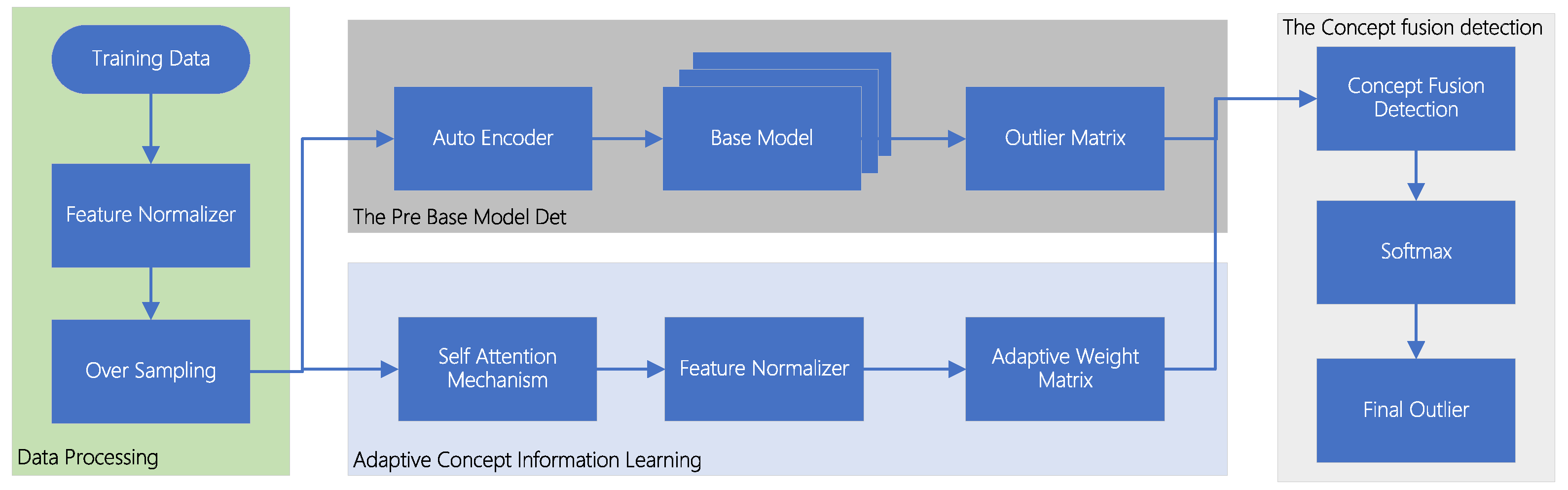
3.1. Data Preprocessing
3.2. Related Definitions
3.3. Sample Associative Learning
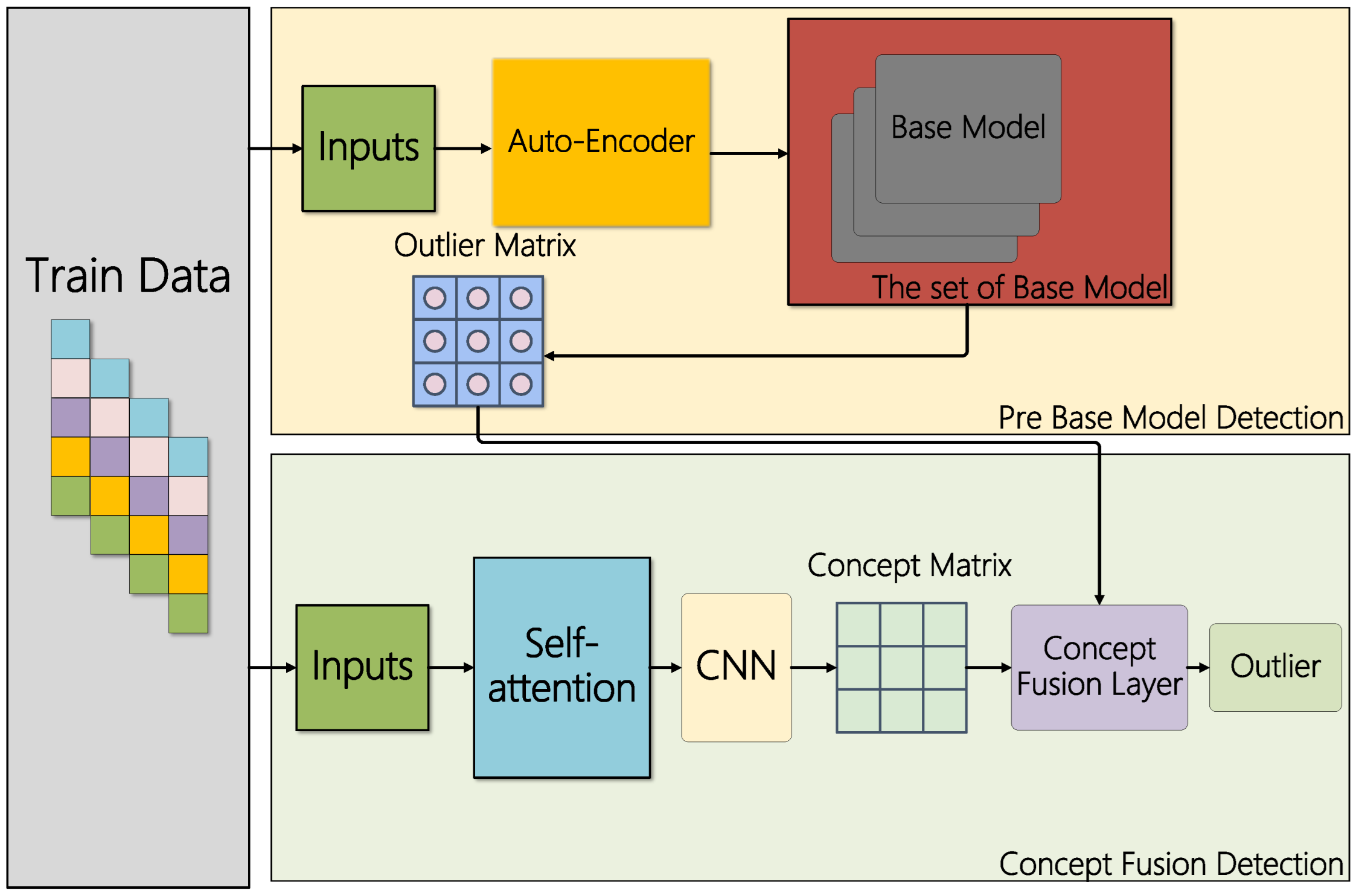
3.4. Ensemble Detection Network
3.4.1. Auto Encoder
3.4.2. Stacking Ensemble Detection Network
4. Experiment and Analysis
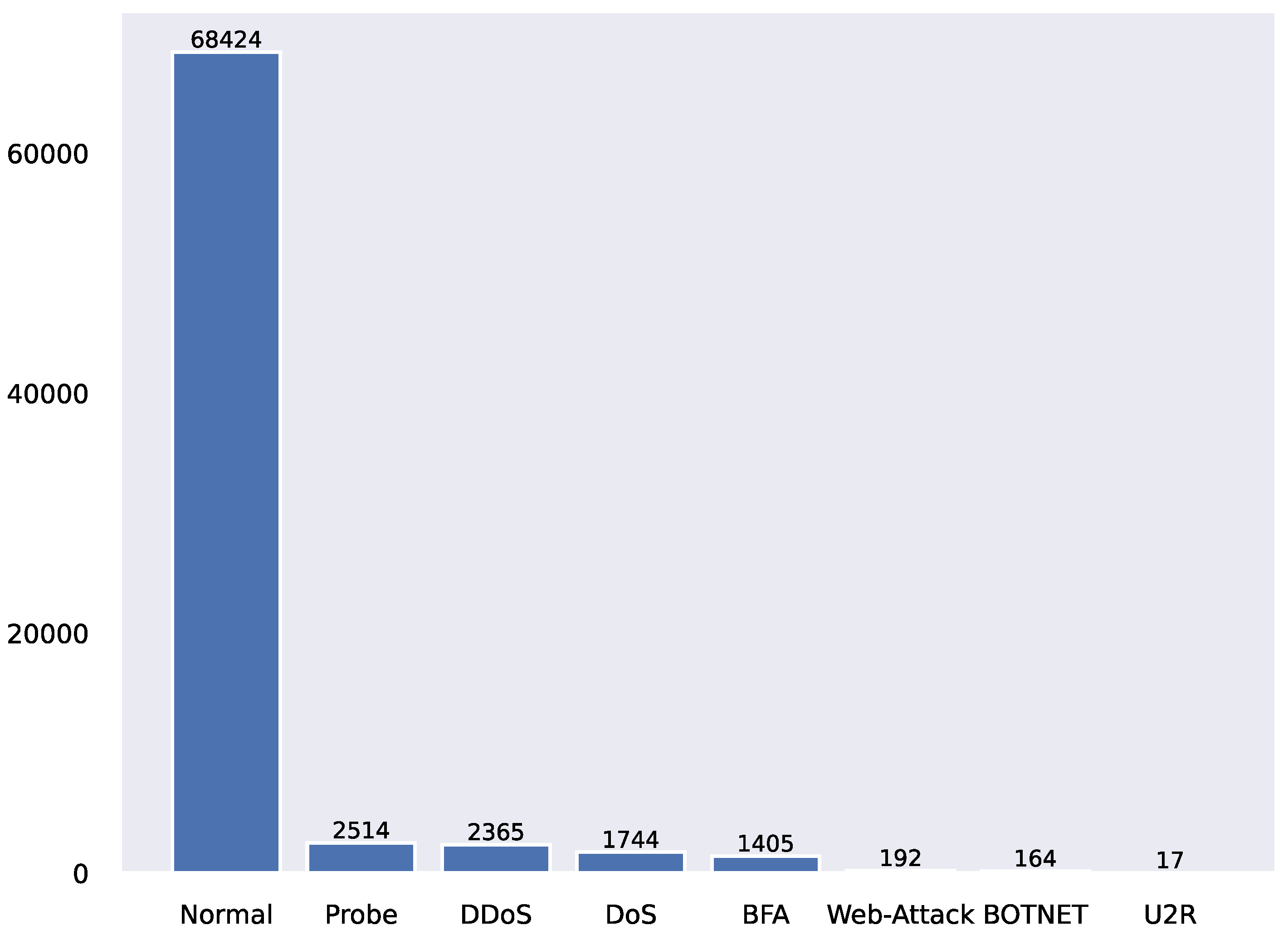
4.1. Experimental Environment and Datasets
4.2. Evaluation Indicators
- True positives (TP): TP represents the proportion of abnormal behavior correctly identified as abnormal behavior;
- False positives (FP): FP represents the proportion of normal behavior incorrectly identified as abnormal behavior;
- False negatives (FN): FN represents the proportion of abnormal behavior incorrectly identified as normal behavior;
- True negatives (TN): TN represents the proportion of normal behavior correctly identified as normal behavior;
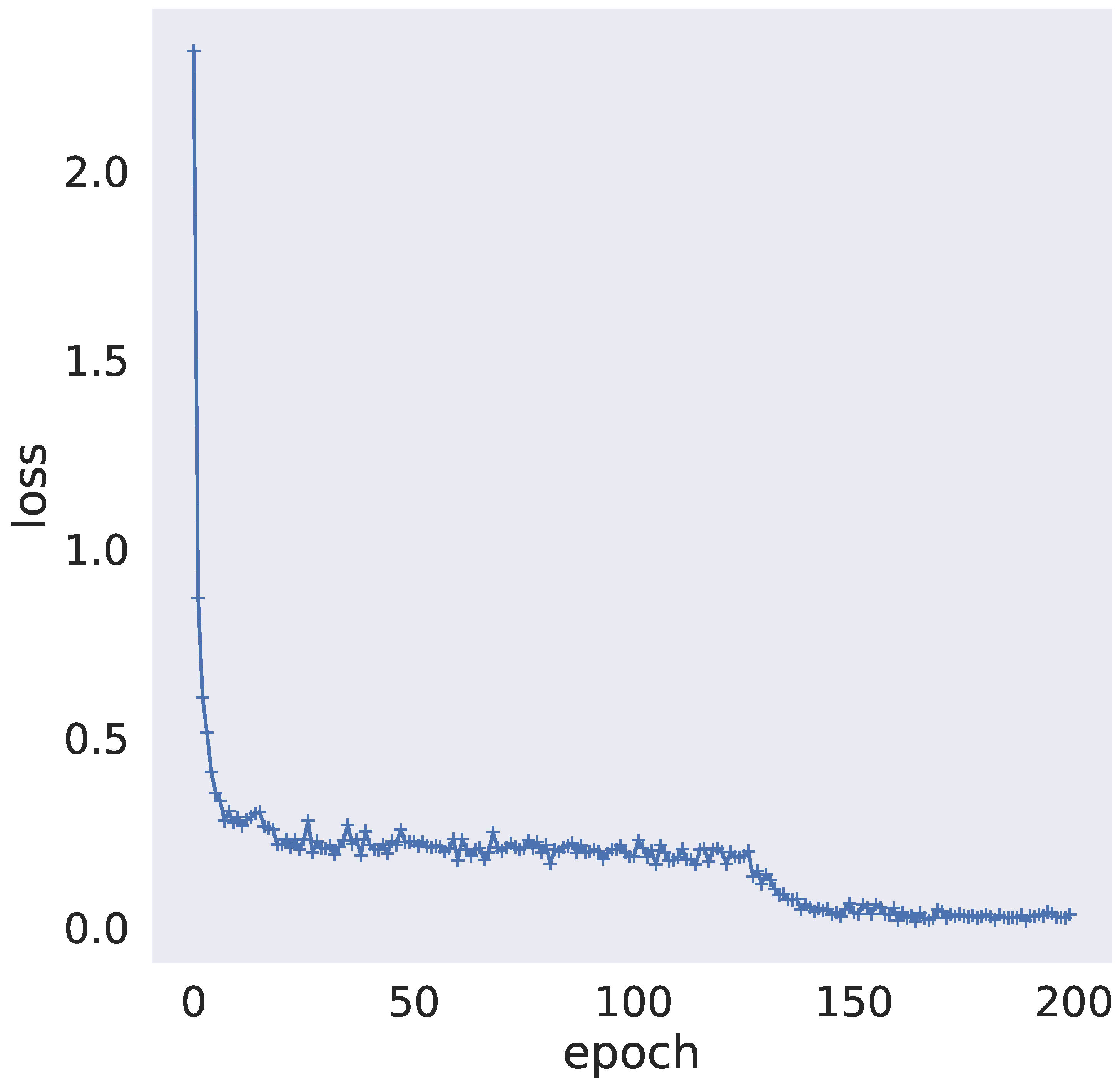
4.3. Performance Testing and Analysis
4.3.1. Performance Testing
4.3.2. Control Group Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Ali, S.T.; Sivaraman, V.; Radford, A.; Jha, S. A Survey of Securing Networks Using Software Defined Networking. IEEE Trans. Reliab. 2015, 64, 1086–1097. [Google Scholar] [CrossRef]
- Rawat, D.B.; Reddy, S.R. Software defined networking architecture, security and energy efficiency: A survey. IEEE Commun. Surv. Tutor. 2016, 19, 325–346. [Google Scholar] [CrossRef]
- Bian, S.; Zhang, P.; Yan, Z. A survey on software-defined networking security. In Proceedings of the 9th EAI International Conference on Mobile Multimedia Communications, Xi’an, China, 18–20 June 2016; pp. 190–198. [Google Scholar]
- Xu, Y.H.; Sun, Z.X. Research Development of Abnormal Traffic Detection in Software Defined Networking. J. Softw. 2020, 31, 25. [Google Scholar]
- Scott-Hayward, S.; O’Callaghan, G.; Sezer, S. SDN security: A survey. In Proceedings of the 2013 IEEE SDN for Future Networks and Services (SDN4FNS), Trento, Italy, 11–13 November 2013. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Jackson, K.; DuBois, D.; Stallings, C. An expert system application for network intrusion detection. In Proceedings of the National Computer Security Conference, Washington, DC, USA, 1–4 October 1991. [Google Scholar]
- Javitz, H.S.; Valdes, A. The SRI IDES statistical anomaly detector. In Proceedings of the 1991 IEEE Computer Society Symposium on Research in Security and Privacy, Oakland, CA, USA, 20–22 May 1991. [Google Scholar] [CrossRef]
- Sekar, R.; Gupta, A.; Frullo, J.; Shanbhag, T.; Tiwari, A.; Yang, H.; Zhou, S. Specification-based anomaly detection: A new approach for detecting network intrusions. In Proceedings of the CCS02: ACM Conference on Computer and Communications Security, Washington, DC, USA, 18–22 November 2002. [Google Scholar]
- Bauer, D.S.; Koblentz, M.E. NIDX—An expert system for real-time network intrusion detection. In In Proceedings of the 1988 Computer Networking Symposium, Washington, DC, USA, 11–13 April 1988. [CrossRef]
- Sinclair, C.; Pierce, L.; Matzner, S. An application of machine learning to network intrusion detection. In Proceedings of the 15th Annual Computer Security Applications Conference (ACSAC’99), Phoenix, AZ, USA, 6–10 December 1999. [Google Scholar] [CrossRef]
- Goldstein, M.; Dengel, A. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In Proceedings of the KI-2012: Poster and Demo Track, Saarbrücken, Germany, 24–27 September 2012. [Google Scholar]
- Wang, J.; Paschalidis, I.C. Statistical traffic anomaly detection in time-varying communication networks. IEEE Trans. Control Netw. Syst. 2015, 2, 100–111. [Google Scholar] [CrossRef]
- Thottan, M.; Ji, C. Anomaly detection in IP networks. IEEE Trans. Signal Process. 2003, 51, 2191–2204. [Google Scholar] [CrossRef] [Green Version]
- Buschkes, R.; Kesdogan, D.; Reichl, P. How to increase security in mobile networks by anomaly detection. In Proceedings of the 14th Annual Computer Security Applications Conference (Cat. No. 98EX217), Phoenix, AZ, USA, 7–11 December 1998. [Google Scholar] [CrossRef]
- Sarasamma, S.T.; Zhu, Q.A.; Huff, J. Hierarchical Kohonenen Net for anomaly detection in network security. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2005, 35, 302–312. [Google Scholar] [CrossRef]
- Simmross-Wattenberg, F.; Asensio-Pérez, J.I.; Casaseca-De-La-Higuera, P.; Martín-Fernandez, M.; Dimitriadis, I.A.; Alberola-López, C. Anomaly detection in network traffic based on statistical inference and α-stable modeling. IEEE Trans. Dependable Secur. Comput. 2011, 8, 494–509. [Google Scholar] [CrossRef]
- Sui, S.; Li, L.; Manikopoulo, C.N. Flow-based Statistical Aggregation Schemes for Network Anomaly Detection. In Proceedings of the 2006 IEEE International Conference on Networking, Sensing and Control, Ft. Lauderdale, FL, USA, 23–25 April 2006. [Google Scholar] [CrossRef]
- Nevat, I.; Divakaran, D.M.; Nagarajan, S.G.; Zhang, P.; Su, L.; Ko, L.L.; Thing, V.L. Anomaly detection and attribution in networks with temporally correlated traffic. IEEE/ACM Trans. Netw. 2018, 26, 131–144. [Google Scholar] [CrossRef]
- Qu, D.; Vetter, B.M.; Wang, F.; Narayan, R.; Wu, S.F.; Jou, Y.F.; Gong, F.; Sargor, C. Statistical anomaly detection for link-state routing protocols. In Proceedings of the Sixth International Conference on Network Protocols (Cat. No. 98TB100256), Austin, TX, USA, 13–16 October 1998. [Google Scholar] [CrossRef]
- Soule, A.; Salamatian, K.; Taft, N. Combining filtering and statistical methods for anomaly detection. In Proceedings of the 5th ACM SIGCOMM Conference on Internet Measurement, Berkeley, CA, USA, 19–21 October 2005. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-based outlier detection. arXiv 2020, arXiv:2009.09463. [Google Scholar]
- Maimo, L.F.; Gomez, A.L.P.; Clemente, F.J.G.; Perez, M.G.; Perez, G.M. A Self-Adaptive Deep Learning-Based System for Anomaly Detection in 5G Networks. IEEE Access 2018, 6, 7700–7712. [Google Scholar] [CrossRef]
- Van, N.T.; Thinh, T.N.; Sach, L.T. An anomaly-based network intrusion detection system using Deep learning. In Proceedings of the 2017 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 21–23 July 2017. [Google Scholar] [CrossRef]
- Garg, S.; Kaur, K.; Kumar, N.; Kaddoum, G.; Zomaya, A.Y.; Ranjan, R. A hybrid deep learning-based model for anomaly detection in cloud datacenter networks. IEEE Trans. Netw. Serv. Manag. 2019, 16, 924–935. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for Network Intrusion Detection in Software Defined Networking. In Proceedings of the 2016 International Conference on Wireless Networks and Mobile Communications (WINCOM), Fez, Morocco, 26–29 October 2016. [Google Scholar] [CrossRef]
- Garg, S.; Kaur, K.; Kumar, N.; Rodrigues, J.J. Hybrid deep-learning-based anomaly detection scheme for suspicious flow detection in SDN: A social multimedia perspective. IEEE Trans. Multimed. 2019, 21, 566–578. [Google Scholar] [CrossRef]
- Yang, L.; Song, Y.; Gao, S.; Xiao, B.; Hu, A. Griffin: An Ensemble of AutoEncoders for Anomaly Traffic Detection in SDN. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar] [CrossRef]
- Ujjan, R.M.A.; Pervez, Z.; Dahal, K.; Bashir, A.K.; Mumtaz, R.; González, J. Towards sFlow and adaptive polling sampling for deep learning based DDoS detection in SDN. Future Gener. Comput. Syst. 2020, 111, 763–779. [Google Scholar] [CrossRef]
- Elsayed, M.S.; Le-Khac, N.A.; Jurcut, A.D. InSDN: A novel SDN intrusion dataset. IEEE Access 2020, 8, 165263–165284. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| COPOD | 0.7799 | 0.7057 | 0.7403 |
| HBOS | 0.7968 | 0.7630 | 0.7792 |
| IForest | 0.8108 | 0.7043 | 0.7491 |
| VAE | 0.7988 | 0.6912 | 0.7378 |
| ECOD | 0.8219 | 0.6757 | 0.7323 |
| LOF | 0.8002 | 0.5627 | 0.6456 |
| TSMASAM | 0.9972 | 0.9996 | 9984 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| XGBOD | 0.9998 | 0.9998 | 0.9998 |
| LSCP | 0.7784 | 0.6240 | 0.6895 |
| SUOD | 0.7784 | 0.7920 | 0.7885 |
| LODA | 0.7656 | 0.6278 | 0.6892 |
| TSMASAM | 0.9972 | 0.9996 | 9984 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Stacking | 0.8059 | 0.8893 | 0.8390 |
| TSMASAM | 0.9972 | 0.9996 | 9984 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| CNN | 0.9973 | 0.9966 | 0.9970 |
| LSTM | 0.8017 | 1.0000 | 0.8899 |
| LENET | 0.8018 | 1.0000 | 0.8900 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| KDD99 | 0.9978 | 0.9981 | 0.9978 |
| UNSW-NB15 | 0.8051 | 0.9293 | 0.8627 |
| InSDN | 0.9972 | 0.9996 | 0.9984 |
| Base Leaner | Precision | Recall | F1-Score | Time |
|---|---|---|---|---|
| CNN(kernel_size = 5), Lenet, Lstm(hidden_size = 128, hidden_layer = 3) | 0.9978 | 0.9981 | 0.9978 | 1.3970-10 |
| CNN(kernel_size = 3), Lenet, Lstm(hidden_size = 128, hidden_layer = 3) | 0.9967 | 0.9971 | 0.9969 | 8.2888-10 |
| CNN(kernel_size = 5), Lenet, Lstm(hidden_size = 128, hidden_layer = 10) | 0.8016 | 1.0000 | 0.8899 | 8.9873-10 |
| CNN(kernel_size = 5), Lenet, Lstm(hidden_size = 64, hidden_layer = 3) | 0.9942 | 0.9899 | 0.9920 | 8.3121-10 |
| CNN(kernel_size = 3), Lenet, Lstm(hidden_size = 64, hidden_layer = 3) | 0.9899 | 0.9994 | 0.9946 | 8.8011-10 |
| CNN(kernel_size = 5), Lenet, Lstm(hidden_size = 64, hidden_layer = 10) | 0.8016 | 1.0000 | 0.8899 | 8.8915-10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, L.; Kou, L.; Zhan, X.; Zhang, J.; Ren, Y. An Anomaly Detection Algorithm Based on Ensemble Learning for 5G Environment. Sensors 2022, 22, 7436. https://doi.org/10.3390/s22197436
Lei L, Kou L, Zhan X, Zhang J, Ren Y. An Anomaly Detection Algorithm Based on Ensemble Learning for 5G Environment. Sensors. 2022; 22(19):7436. https://doi.org/10.3390/s22197436
Chicago/Turabian StyleLei, Lifeng, Liang Kou, Xianghao Zhan, Jilin Zhang, and Yongjian Ren. 2022. "An Anomaly Detection Algorithm Based on Ensemble Learning for 5G Environment" Sensors 22, no. 19: 7436. https://doi.org/10.3390/s22197436
APA StyleLei, L., Kou, L., Zhan, X., Zhang, J., & Ren, Y. (2022). An Anomaly Detection Algorithm Based on Ensemble Learning for 5G Environment. Sensors, 22(19), 7436. https://doi.org/10.3390/s22197436