





Pedestrian Flow Prediction and Route Recommendation with Business Events †


Abstract
:1. Introduction
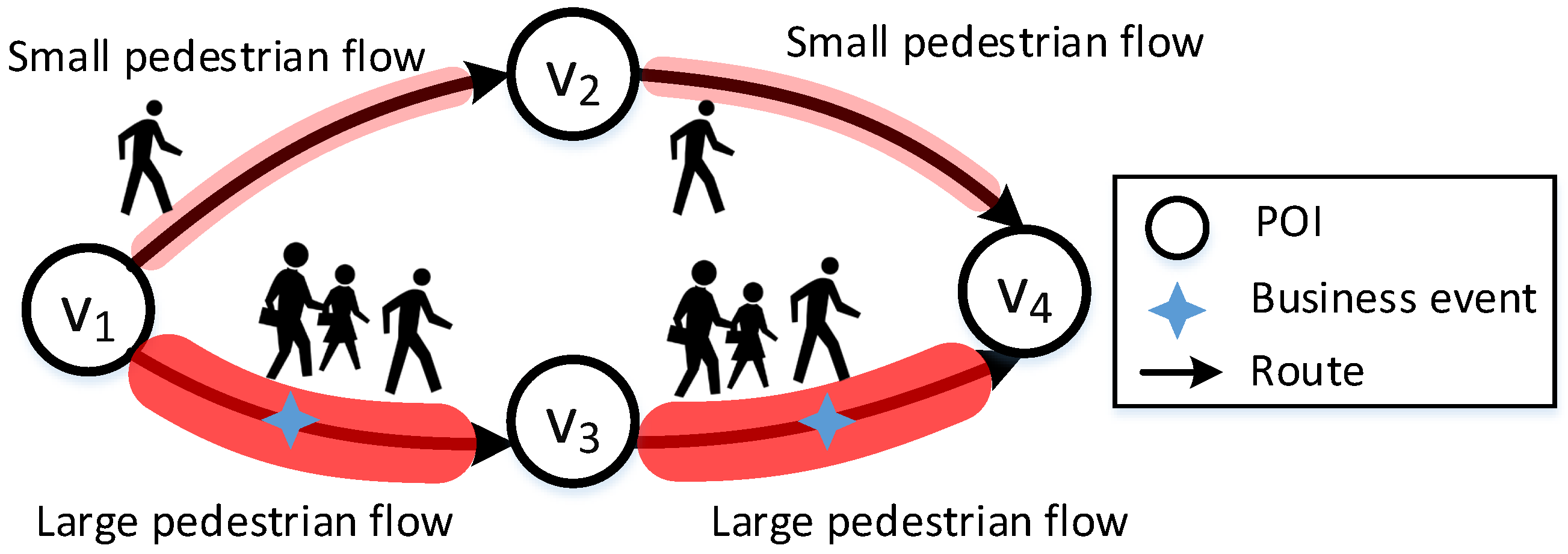
- As far as we know, we are the first to take business events into account when predicting pedestrian flow.
- To predict pedestrian flow based on business events, we present the ABMF model, and its highlight lies in that it introduces the attraction index of different categories to pedestrians in matrix factorization.
- To recommend routes for event placement, we learn route representations based on the Skip-gram model and consider the flow factors to recommend top-N routes for events.
- We compare the performance of the proposed two methods with state-of-the-art solutions on a simulation dataset and real-world datasets, and experiment results reveal that our algorithms outperform the baselines.
2. Related Work
3. Preliminaries
3.1. Data Model
3.2. Problem Definition

4. Predicting Pedestrian Flow
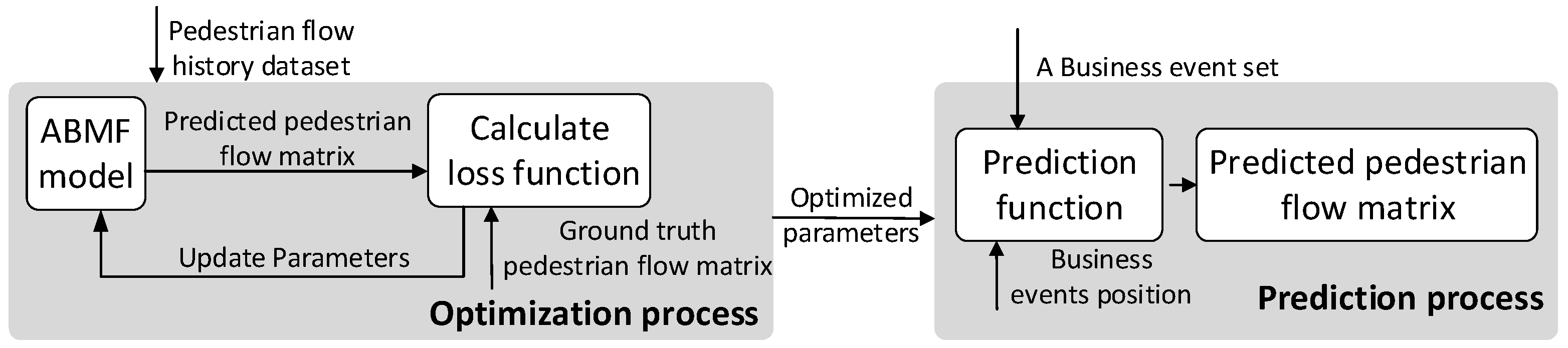
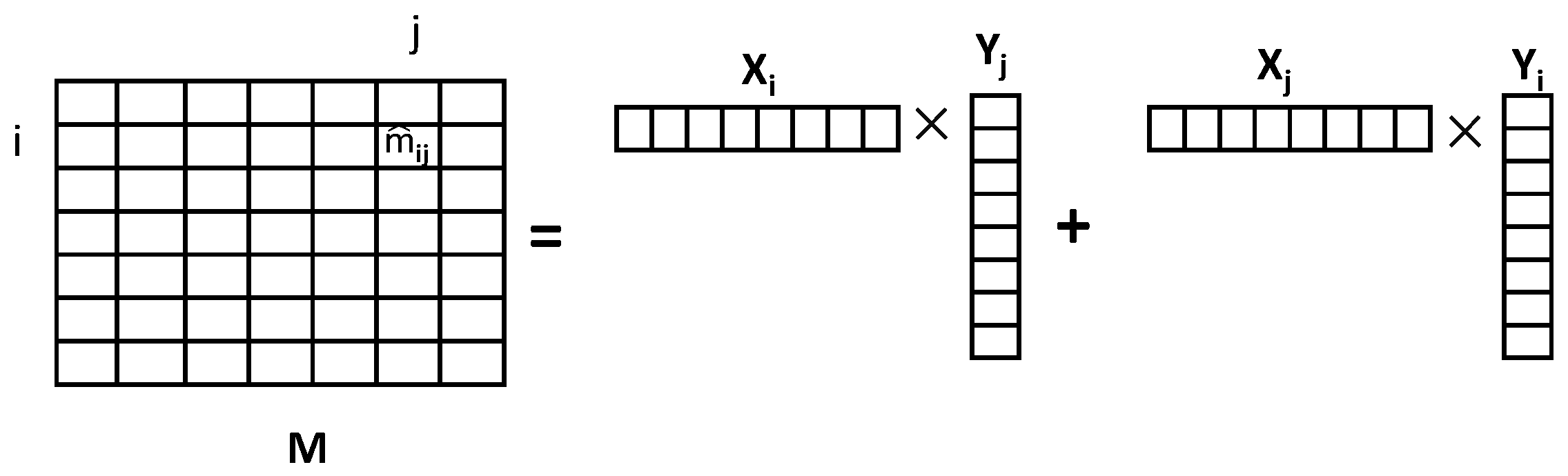
4.1. ABMF Model
4.2. Parameter Estimation
| Algorithm 1: The ABMF Optimization |
 |
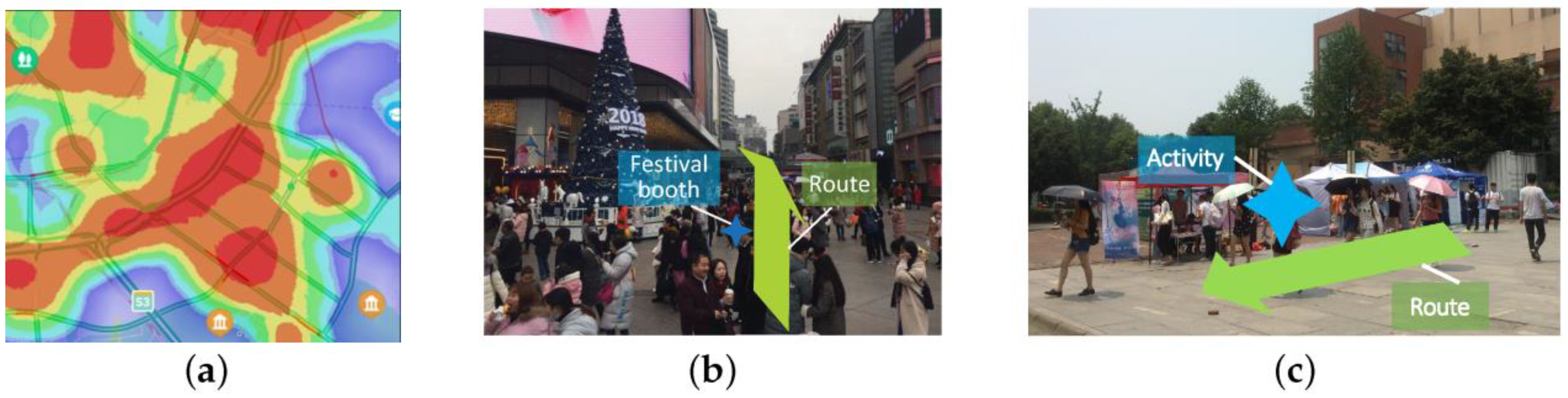
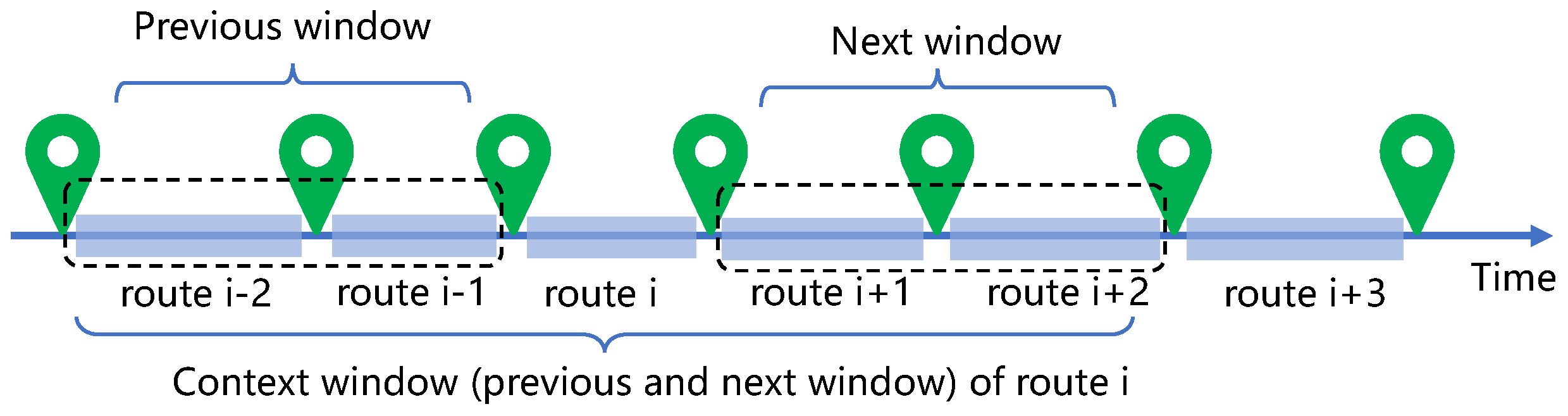
5. Extension: Route Recommendation for Business Events
5.1. Concepts and Problem Definition
5.2. Learning Route Representations
5.3. Flow-Aware Recommendation Model
6. Experiments
6.1. The Experimental Setup
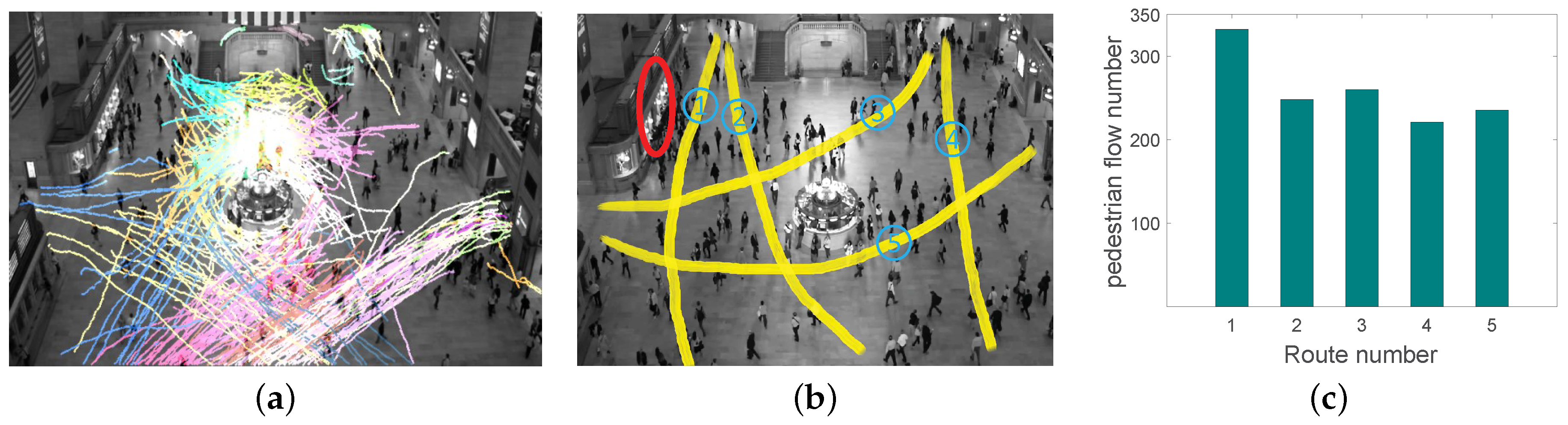
- The first is a surveillance video dataset of the New York Grand Central Station [40], which records people coming and passing by.
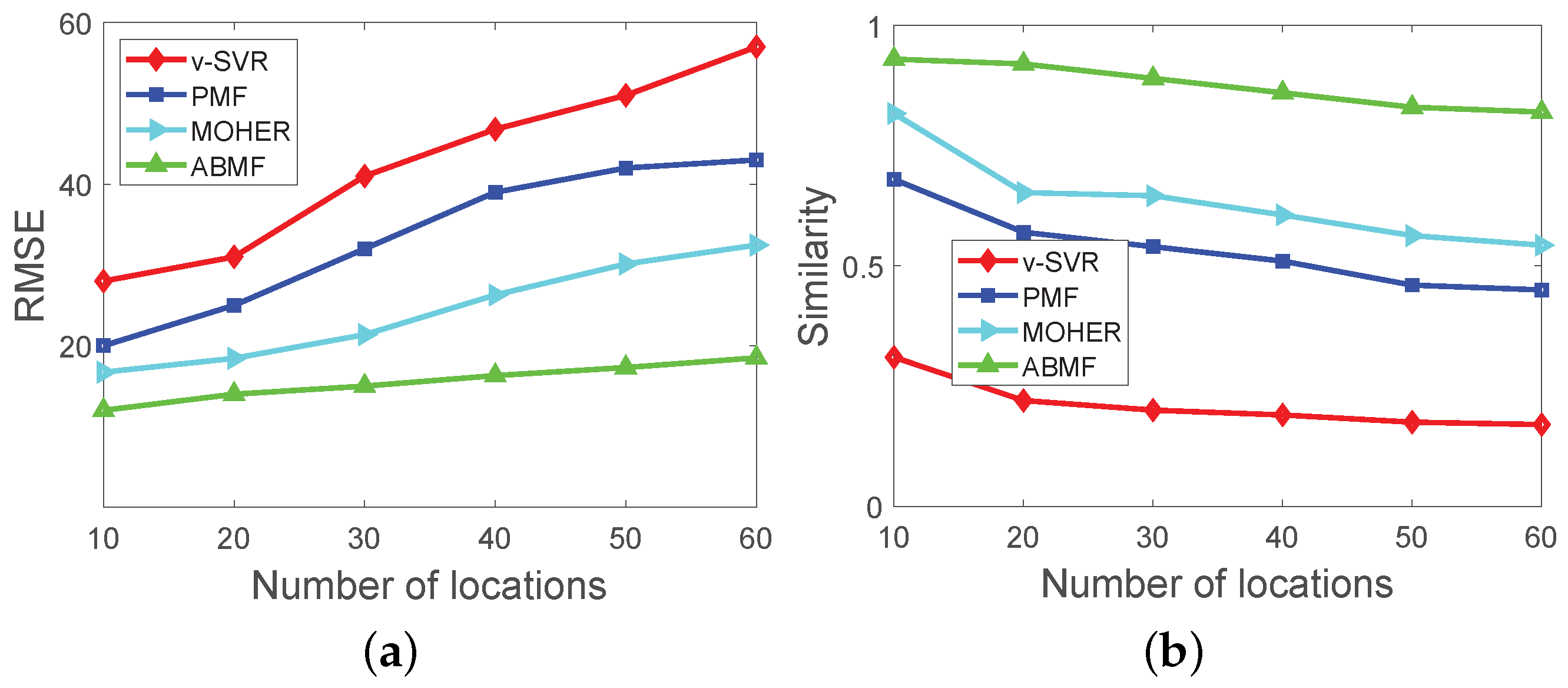
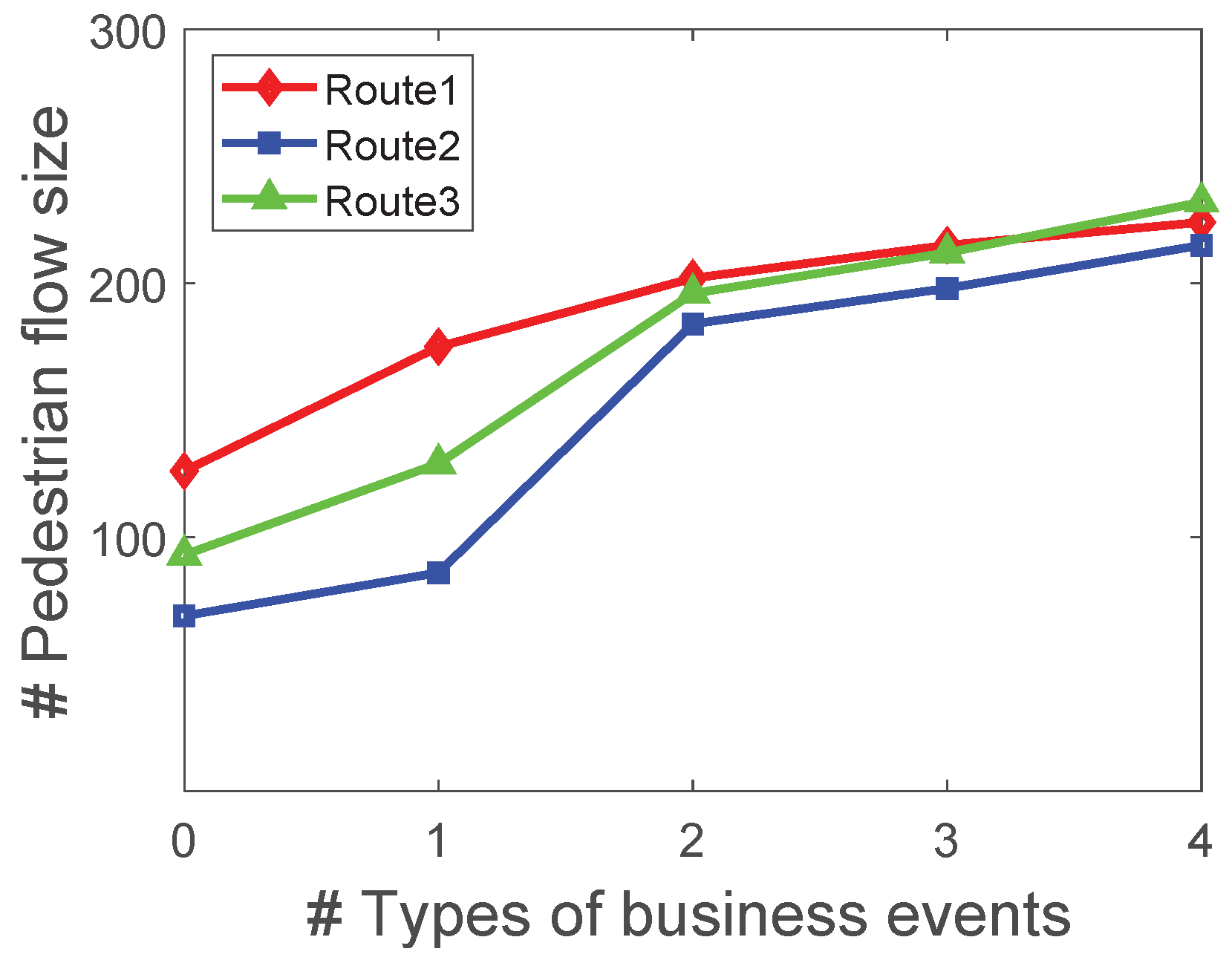
- The second one is a simulation dataset, which simulates pedestrian flow under different business event sets by using the social force model [41]. In the simulation dataset, the number of locations ranges from 10–60, and there are 8 types of business events, such as promotions, exhibitions of cloths, games and so on, each type of business event has a preference to attract visitors.
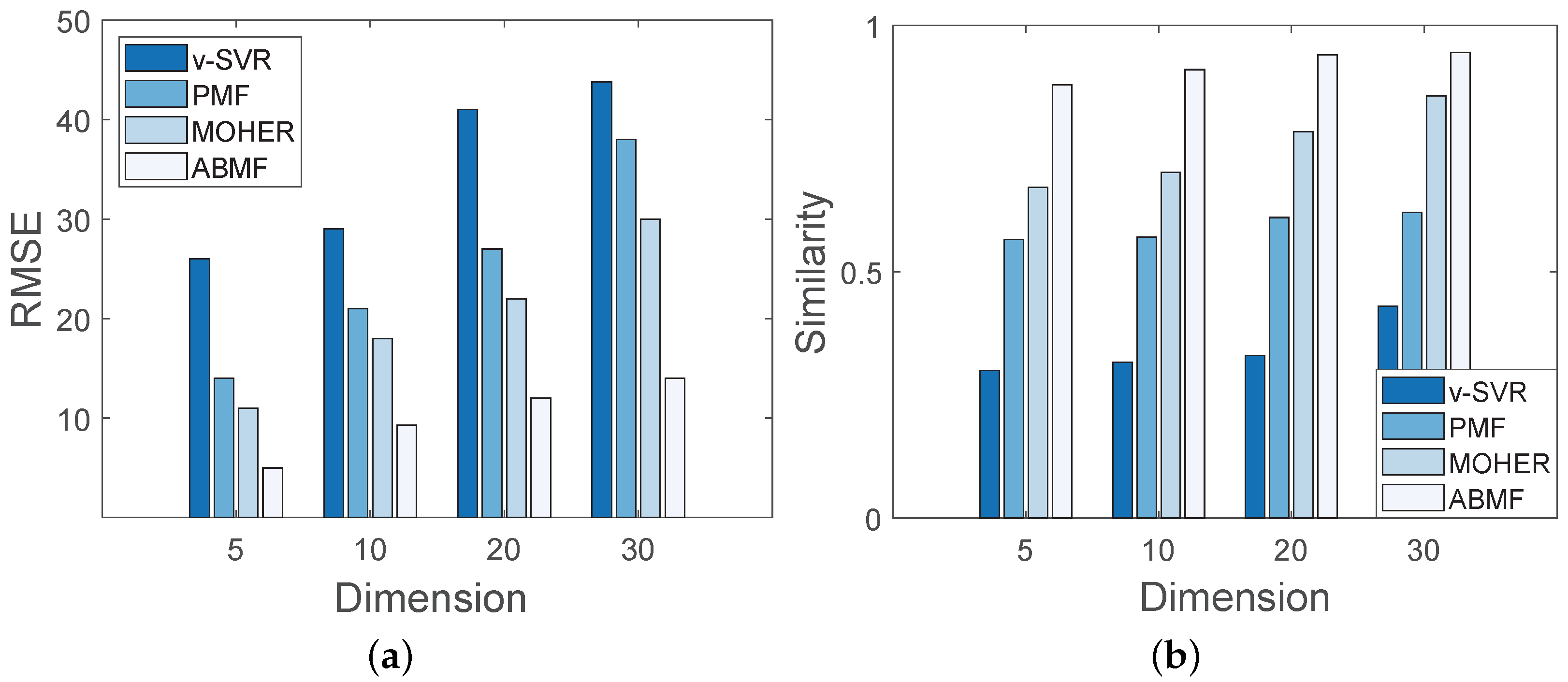
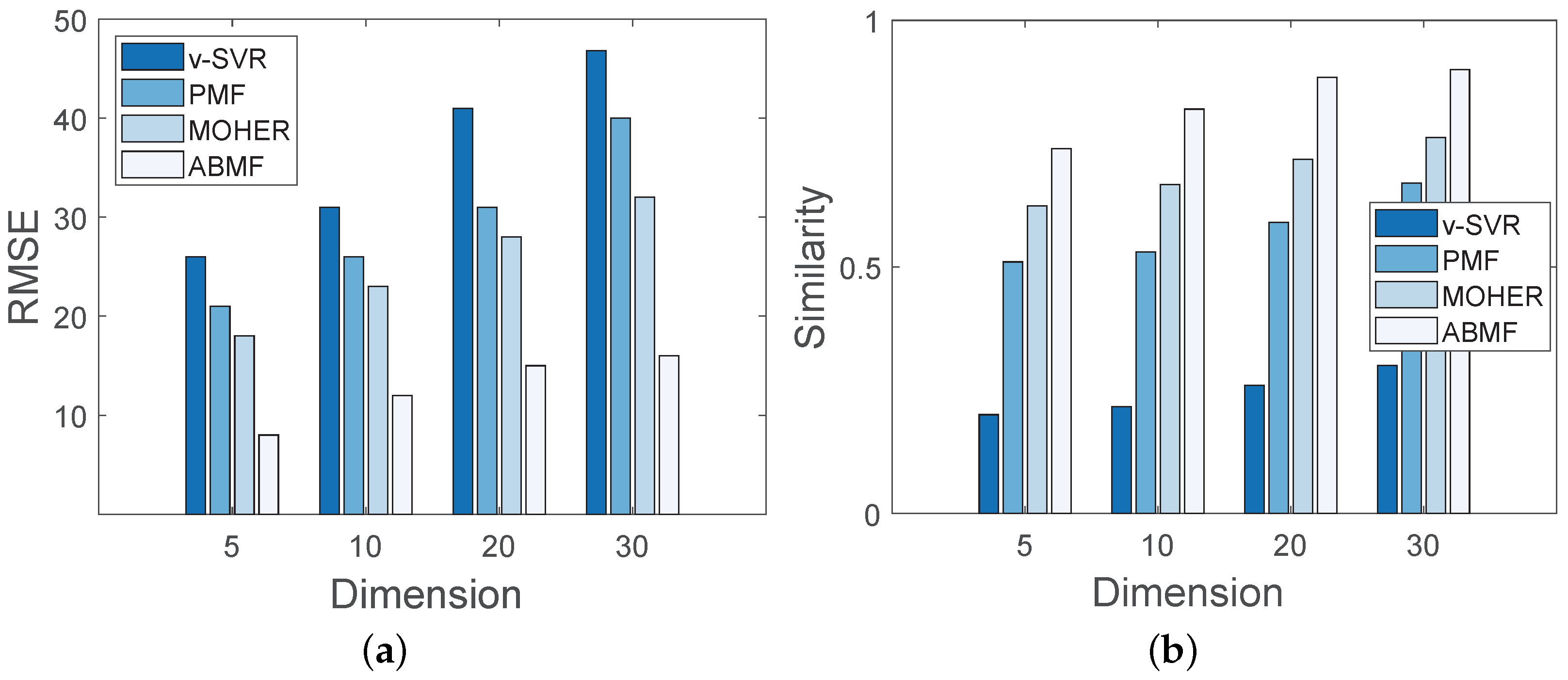
- The third one is Foursquare [2,42], a publicly crowdsourced large-scale check-in LBSNs dataset is free available. Foursquare of New York (NYC) has 1,385,223 check-ins, whereas Foursquare of Tokyo (TKY) has 573,703 check-ins. We obtain the check-in flows and identify the business events using the dataset’s visit counts for the routes.
6.2. Metrics
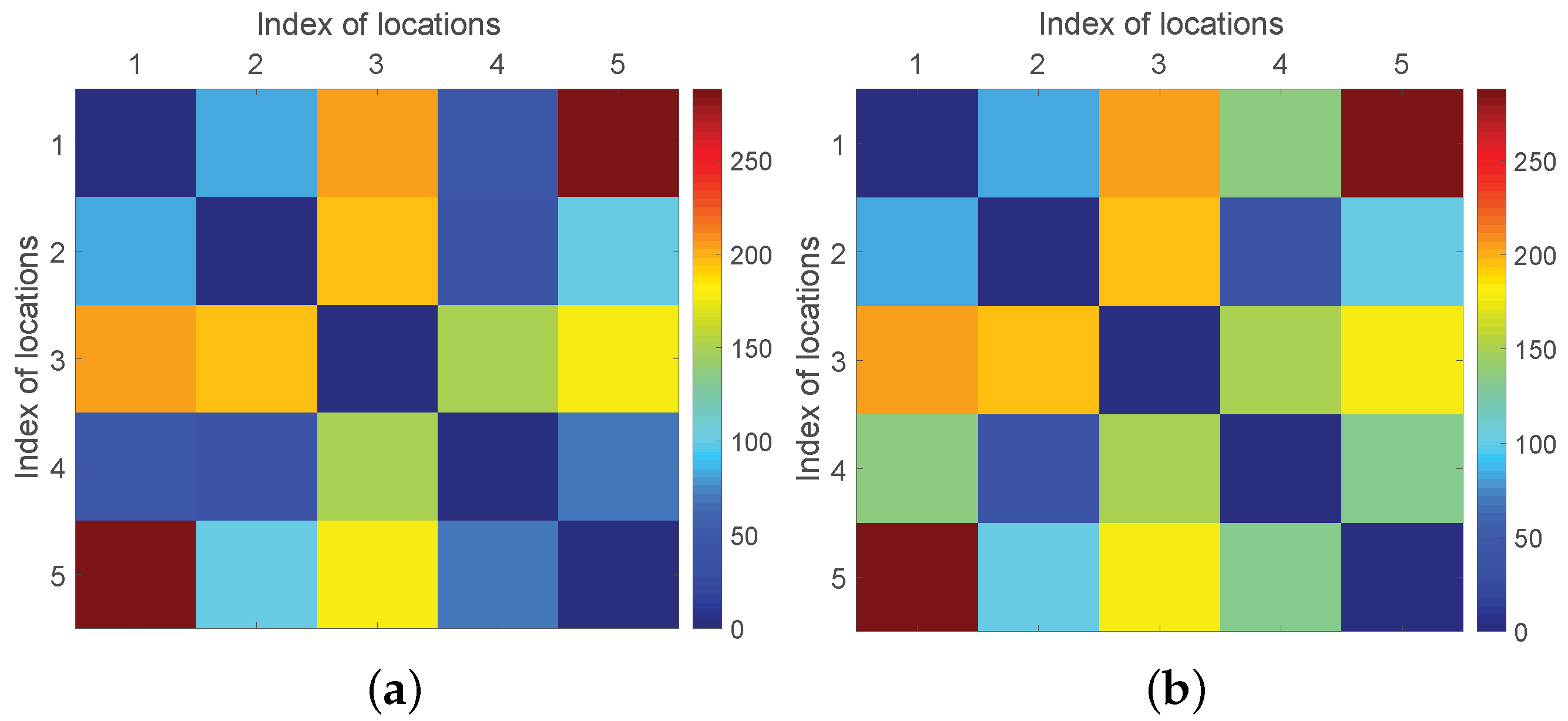
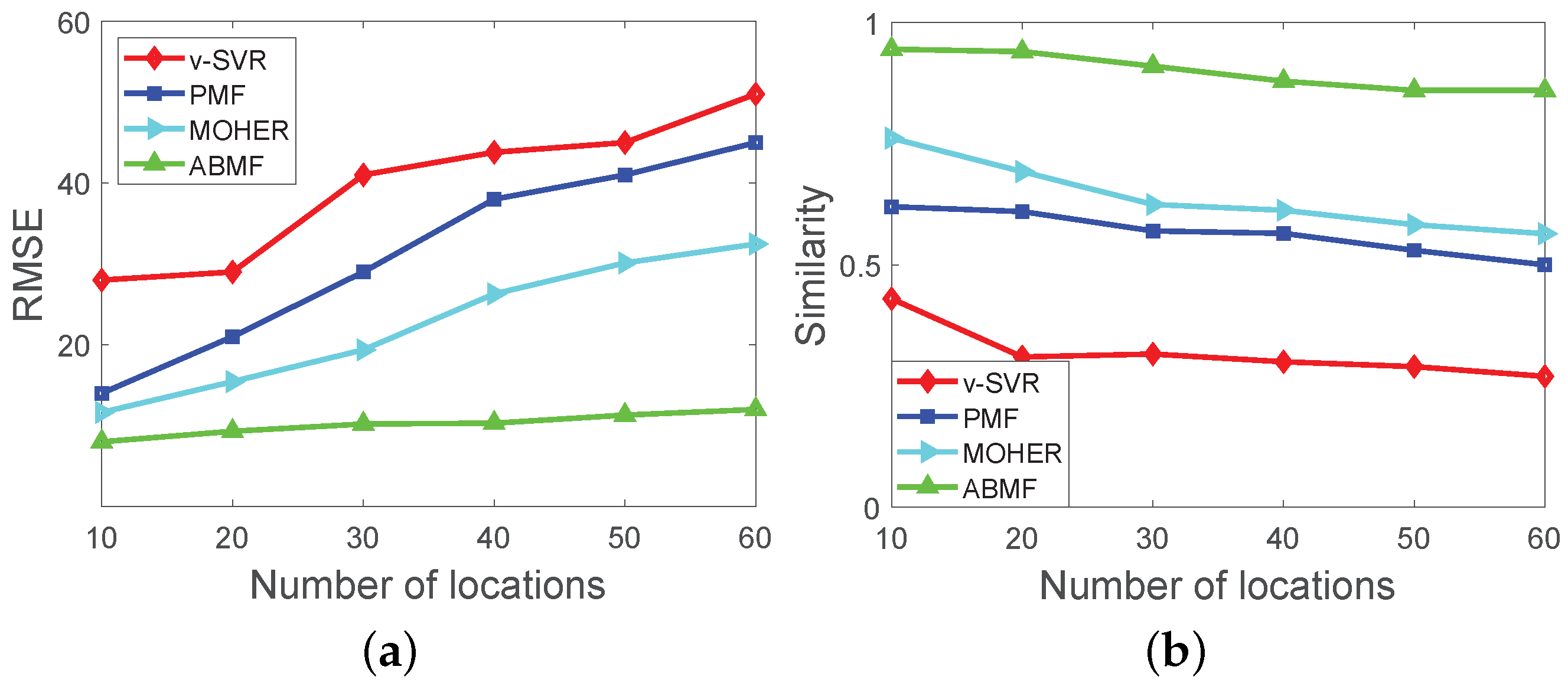
- The ABMF model is evaluated according to matrix similarity and root-mean-square error (RMSE), which are defined as:where represents the similarity degree between M and N adjusted to . Both M and N are n-order matrices that represent the ground truth and predicted pedestrian flow matrix, respectively. The average values of matrix M and matrix N are represented by and , respectively.
- To evaluate the performance of route recommendation for events, we use precision@N, which refers to the ratio of the successfully predicted routes to the top-N recommendations. We use Mean Reciprocal Rank (MRR) as another metric. This ranking metric measures the recommendation accuracy by finding out how far the first successfully predicted route is from the top of the recommendation list. MRR is defined as follows:where is the size of the event set. For the ith event, refers to the ranking position of the first route in the recommendation list in the ground-truth result. Note that all experiments are conducted 10 times for latent factor models, and we report the averaged results.
6.3. Baseline methods
- The ABMF model is used to predict pedestrian flow based on a set of business events. We compare the prediction results of the ABMF model with the other three prediction methods. The baseline algorithms include vSVR [21], PMF [37,43], and MOHER [18] (1) vSVR is an application of SVM (Support Vector Machine) to regression problems, which can be applied to predict the pedestrian flow density, and then covered to the number of individuals. (2) PMF is an effective method that is frequently used as a baseline in current work [44], which factors the pedestrian flow matrix into two feature matrices. (3) MOHER is to predict the potential crowd flow in a certain mode, which uses the LTSM module to predict the sequential flow. However, the baseline algorithms cannot reflect the diverse influence of business events, because they fuse the influence of business events into the pedestrian flow.
- We compare SG-FWARP with three top-N recommendation methods. (1) The first is WRMF [45], which is the weighted regularized matrix factorization model designed to handle implicit feedback data (i.e., an event taken on a route or not) for top-N recommendations. This method is used as a baseline in the latest work [46]. (2) The second one is WARP-MF [47]. This is a pairwise ranking method that utilizes matrix factorization to minimize the basic WARP loss. The latent factors of events and routes are learned by randomly sampling the positive and negative route pairs. (3) The third one is similarity pairwise ranking matrix factorization (SPRMF) [48]. This method uses a new penalty to eliminate the differences in the scores between popular and personalized items based on their similarity.
6.4. Analysis of Pedestrian Flow
6.5. Experimental Results
6.5.1. Experimental Results for the ABMF
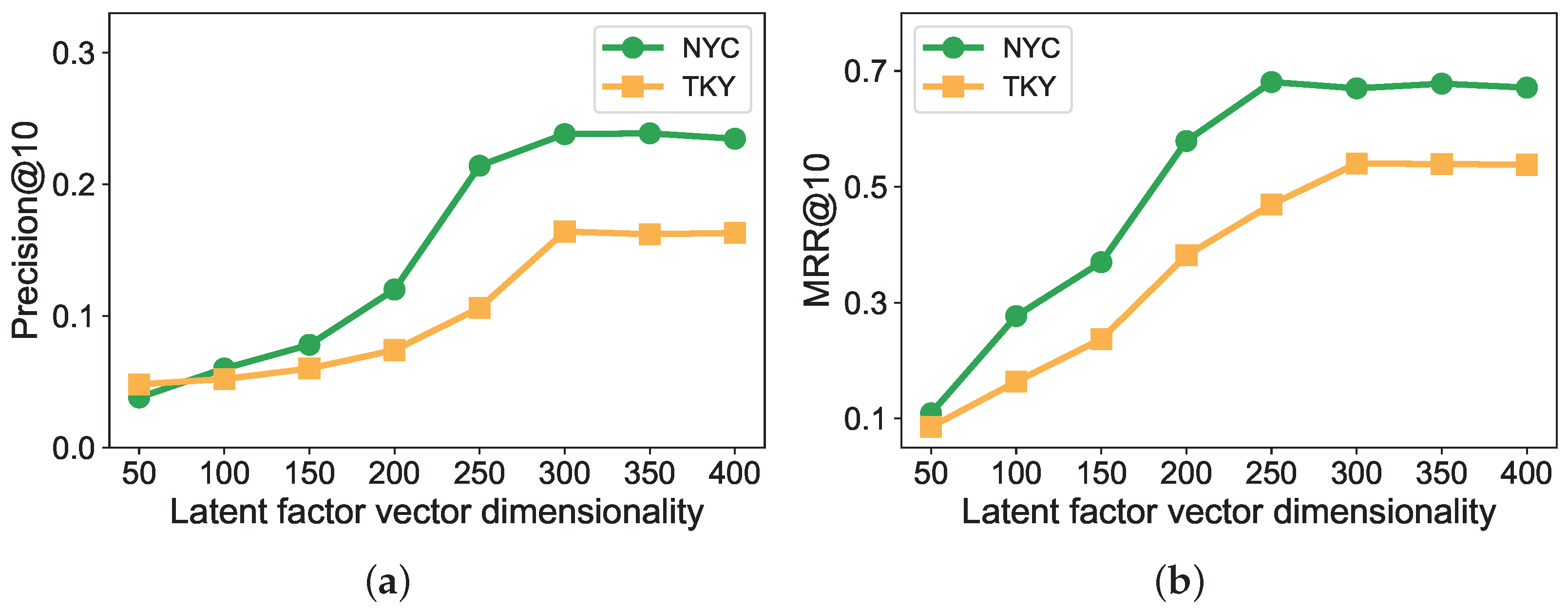
6.5.2. Experimental Results for SG-FWARP
6.6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, Z.; Ma, H.; Guo, B.; Yang, Z. Crowdsensing 2.0. Commun. ACM 2021, 64, 76–80. [Google Scholar] [CrossRef]
- Gu, J.; Song, C.; Jiang, W.; Wang, X.; Liu, M. Enhancing personalized trip recommendation with attractive routes. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 662–669. [Google Scholar]
- Estrada, R.; Mizouni, R.; Otrok, H.; Mourad, A. Task coalition formation for Mobile CrowdSensing based on workers’ routes preferences. Veh. Commun. 2021, 31, 100376. [Google Scholar] [CrossRef]
- Asahara, A.; Sato, N.; Nomiya, M. Pedestrian-Flow Analysis System for Improving Layout of Exhibitions. In Proceedings of the 14th International Symposium on Spatial and Temporal Databases, Hong Kong, China, 26–28 August 2015. [Google Scholar]
- May, M.; Scheider, S.; Schulz, D.; Hecker, D. Pedestrian flow prediction in extensive road networks using biased observational data. In Proceedings of the 16th ACM Sigspatial International Conference on Advances in Geographic Information Systems, Irvine, CA, USA, 5–7 November 2008. [Google Scholar]
- Wang, X.; Leckie, C.; Chan, J.; Lim, K.H.; Vaithianathan, T. Improving Personalized Trip Recommendation by Avoiding Crowds. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Rong, D.; Yu, Z.; Tao, M.; Wang, Z.; Guo, B. Predicting activity attendance in event-based social networks: Content, context and social influence. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Sahaleh, S.; Bierlaire, M.; Farooq, B.; Danalet, A.; Hänseler, F. Scenario analysis of pedestrian flow in public spaces. In Proceedings of the STRC 12th Swiss Transport Research Conference, Ascona, Switzerland, 2–4 May 2012. [Google Scholar]
- Widhalm, P.; Brandle, N. Learning Major Pedestrian Flows in Crowded Scenes. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Cooper, C.H.; Harvey, I.; Orford, S.; Chiaradia, A.J. Using multiple hybrid spatial design network analysis to predict longitudinal effect of a major city centre redevelopment on pedestrian flows. Transportation 2021, 48, 643–672. [Google Scholar]
- Tanaka, R.; Takahashi, H. Multi-agent simulation approach of pedestrian flow with group walking models. ICIC Exp. Lett. B Appl. 2020, 11, 363–371. [Google Scholar]
- Kaminka, G.A.; Fridman, N. Simulating Urban Pedestrian Crowds of Different Cultures. ACM Trans. Intell. Syst. Technol. 2018, 9, 1–27. [Google Scholar] [CrossRef]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. ACM Trans. Intell. Syst. Technol. 2014, 5, 1–55. [Google Scholar] [CrossRef]
- Fan, Z.; Song, X.; Adachi, R.; Adachi, R. Citymomentum: An online approach for crowd behavior prediction at a citywide level. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015. [Google Scholar]
- Song, X.; Zhang, Q.; Sekimoto, Y.; Shibasaki, R. Prediction of human emergency behavior and their mobility following arge-scale disaster. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Hoang, M.X.; Zheng, Y.; Singh, A.K. FCCF: Forecasting citywide crowd flows based on big data. In Proceedings of the 24th ACM Sigspatial International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Zhou, Q.; Gu, J.; Lu, X.; Zhuang, F.; Zhao, Y.; Wang, Q.; Zhang, X. Modeling heterogeneous relations across multiple modes for potential crowd flow prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 4723–4731. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2016. [Google Scholar]
- Eravci, B.; Bulut, N.; Etemoglu, C.; Ferhatosmanoǧlu, H. Location Recommendations for New Businesses Using Check-in Data. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Ma, Y.; Bai, G. Short term prediction of crowd density using v-SVR. In Proceedings of the 2010 IEEE Youth Conference on Information, Computing and Telecommunications, Beijing, China, 28–30 November 2010. [Google Scholar]
- Duan, J.; Wang, L.; Long, C.; Zhou, S.; Zheng, F.; Shi, L.; Hua, G. Complementary Attention Gated Network for Pedestrian Trajectory Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022. [Google Scholar]
- Li, Y.; Zheng, Y.; Ji, S.; Wang, W.; Hou, U.L.; Gong, Z. Location selection for ambulance stations: A data-driven approach. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015. [Google Scholar]
- Bao, J.; He, T.; Ruan, S.; Li, Y.; Zheng, Y. Planning Bike Lanes based on Sharing-Bikes’ Trajectories. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Liu, D.; Weng, D.; Li, Y.; Bao, J.; Zheng, Y.; Qu, H.; Wu, Y. SmartAdP: Visual Analytics of Large-scale Taxi Trajectories for Selecting Billboard Locations. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1–10. [Google Scholar] [CrossRef]
- Zhao, S.; King, I.; Lyu, M.R.; Zeng, J.; Yuan, M. Mining Business Opportunities from Location-based Social Networks. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Lin, J.; Oentaryo, R.J.; Lim, E.P.; Vu, C.; Vu, A.; Kwee, A.T.; Prasetyo, P.K. A Business Zone Recommender System Based on Facebook and Urban Planning Data. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2016; pp. 641–647. [Google Scholar]
- Sonosy, O.A.; Rady, S.; Badr, N.L.; Hashem, M. Exploiting location based social networks in business predictions. In Proceedings of the 2015 11th International Conference on Innovations in Information Technology (IIT), Dubai, United Arab Emirates, 1–3 November 2015. [Google Scholar]
- Hu, B. Recommendation in Location-based Social Networks. Ph.D. Thesis, Simon Fraser University, Vancouver, BC, Canada, 2014. [Google Scholar]
- Lu, K.; Zhang, Y.; Zhang, L.; Wang, S. Exploiting User and Business Attributes for Personalized Business Recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015. [Google Scholar]
- Ye, J.; Zhu, Z.; Cheng, H. What’s Your Next Move: User Activity Prediction in Location-based Social Networks. In Proceedings of the 2013 SIAM International Conference on Data Mining; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2013. [Google Scholar]
- Zhang, J.D.; Li, Y.; Li, Y. LORE: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014. [Google Scholar]
- Liu, X.; Liu, Y.; Li, X. Exploring the context of locations for personalized location recommendations. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Tang, D.; Qin, B.; Yang, Y.; Yang, Y. User modeling with neural network for review rating prediction. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Shanshan, F.; Gao, C.; Bo, A.; Yeow Meng, C. POI2Vec: Geographical Latent Representation for Predicting Future Visitors. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhao, S.; Zhao, T.; King, I.; Lyu, M.R. Geo-Teaser: Geo-Temporal Sequential Embedding Rank for Point-of-interest Recommendation. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Probabilistic Matrix Factorization. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Li, H.; Hong, R.; Zhu, S.; Yong, G. Point-of-Interest Recommender Systems: A Separate-Space Perspective. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar]
- Weston, J.; Bengio, S.; Usunier, N. Large scale image annotation: Learning to rank with joint word-image embeddings. Mach. Learn. 2010, 81, 21–35. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, X.; Tang, X. Understanding Collective Crowd Behaviors:Learning a Mixture Model of Dynamic Pedestrian-Agents. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Cheng, L.; Yarlagadda, R.; Fookes, C.; Yarlagadda, P.K. A review of pedestrian group dynamics and methodologies in modelling pedestrian group behaviours. World J. Mech. Eng. 2014, 1, 1–13. [Google Scholar]
- Lu, E.H.C.; Chen, C.Y.; Tseng, V.S. Personalized trip recommendation with multiple constraints by mining user check-in behaviors. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012. [Google Scholar]
- Pujahari, A.; Sisodia, D.S. Pair-wise preference relation based probabilistic matrix factorization for collaborative filtering in recommender system. Knowl.-Based Syst. 2020, 196, 105798. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, Z.; Liang, J.; Zhao, X. A Bayesian matrix factorization model for dynamic user embedding in recommender system. Front. Comput. Sci. 2022, 16, 165346. [Google Scholar] [CrossRef]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Fan, R.; Chen, J.; Zhang, J.; Lian, D.; Chen, E. Improving Implicit Alternating Least Squares with Ring-based Regularization. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 102–111. [Google Scholar]
- Zhao, S.; King, I.; Lyu, M.R. Geo-pairwise ranking matrix factorization model for point-of-interest recommendation. In Proceedings of the International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 368–377. [Google Scholar]
- Liu, J.; Yang, Z.; Li, T.; Wu, D.; Wang, R. SPR: Similarity pairwise ranking for personalized recommendation. Knowl. Based Syst. 2022, 239, 107828. [Google Scholar] [CrossRef]
- Tomasi, C.; Kanade, T. Detection and Tracking of Point Features. Int. J. Comput. Vis. 1991, 9, 137–154. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Interpretation |
|---|---|
| the set of locations/routes, , | |
| A | the business events set, |
| the current business events set | |
| the set of pedestrian flow history data | |
| the ith pedestrian flow matrix | |
| the ith the business events set, | |
| the position matrix of | |
| C | the set of categories, |
| X | the latent location feature matrix |
| H | the latent business event feature matrix |
| Y | latent factor feature matrix of location |
| F | latent factor feature matrix of business event |
| the function to map to its category index | |
| the regularization parameters of X, Y, H and F | |
| the reciprocal of the variance | |
| the learning rate | |
| s | the predicted pedestrian flow matrix index |
| z | the latent feature dimension |
| the ith trajectory, | |
| / | the vector of route/event |
| the flow size with event a on the route e | |
| loss function of learning route representations | |
| loss function of flow-aware WARP loss |
| Dataset | Metric | Context Window Size | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | ||
| Foursquare (NYC) | Precision@10 | 0.2024 | 0.2342 | 0.2548 | 0.2746 | 0.2383 | 0.2262 |
| MRR@10 | 0.5656 | 0.6198 | 0.6841 | 0.7071 | 0.6108 | 0.5026 | |
| Foursquare (TKY) | Precision@10 | 0.0983 | 0.1424 | 0.1663 | 0.1569 | 0.1322 | 0.1172 |
| MRR@10 | 0.4318 | 0.4655 | 0.5645 | 0.5142 | 0.4731 | 0.4128 | |
| Dataset | Algorithm | Precision | MRR |
|---|---|---|---|
| Foursquare NYC | WRMF | 0.1392 | 0.3712 |
| WARP-MF | 0.1253 | 0.3517 | |
| SPRMF | 0.1927 | 0.5461 | |
| SG-FWARP | 0.2436 | 0.6814 | |
| Foursquare TKY | WRMF | 0.0912 | 0.2310 |
| WARP-MF | 0.0836 | 0.2150 | |
| SPRMF | 0.1261 | 0.3952 | |
| SG-FWARP | 0.1632 | 0.5147 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Song, C.; Ren, Z.; Lu, L.; Jiang, W.; Liu, M. Pedestrian Flow Prediction and Route Recommendation with Business Events. Sensors 2022, 22, 7478. https://doi.org/10.3390/s22197478
Gu J, Song C, Ren Z, Lu L, Jiang W, Liu M. Pedestrian Flow Prediction and Route Recommendation with Business Events. Sensors. 2022; 22(19):7478. https://doi.org/10.3390/s22197478
Chicago/Turabian StyleGu, Jiqing, Chao Song, Zheng Ren, Li Lu, Wenjun Jiang, and Ming Liu. 2022. "Pedestrian Flow Prediction and Route Recommendation with Business Events" Sensors 22, no. 19: 7478. https://doi.org/10.3390/s22197478
APA StyleGu, J., Song, C., Ren, Z., Lu, L., Jiang, W., & Liu, M. (2022). Pedestrian Flow Prediction and Route Recommendation with Business Events. Sensors, 22(19), 7478. https://doi.org/10.3390/s22197478