


Visual Relationship Detection with Multimodal Fusion and Reasoning


Abstract
:1. Introduction
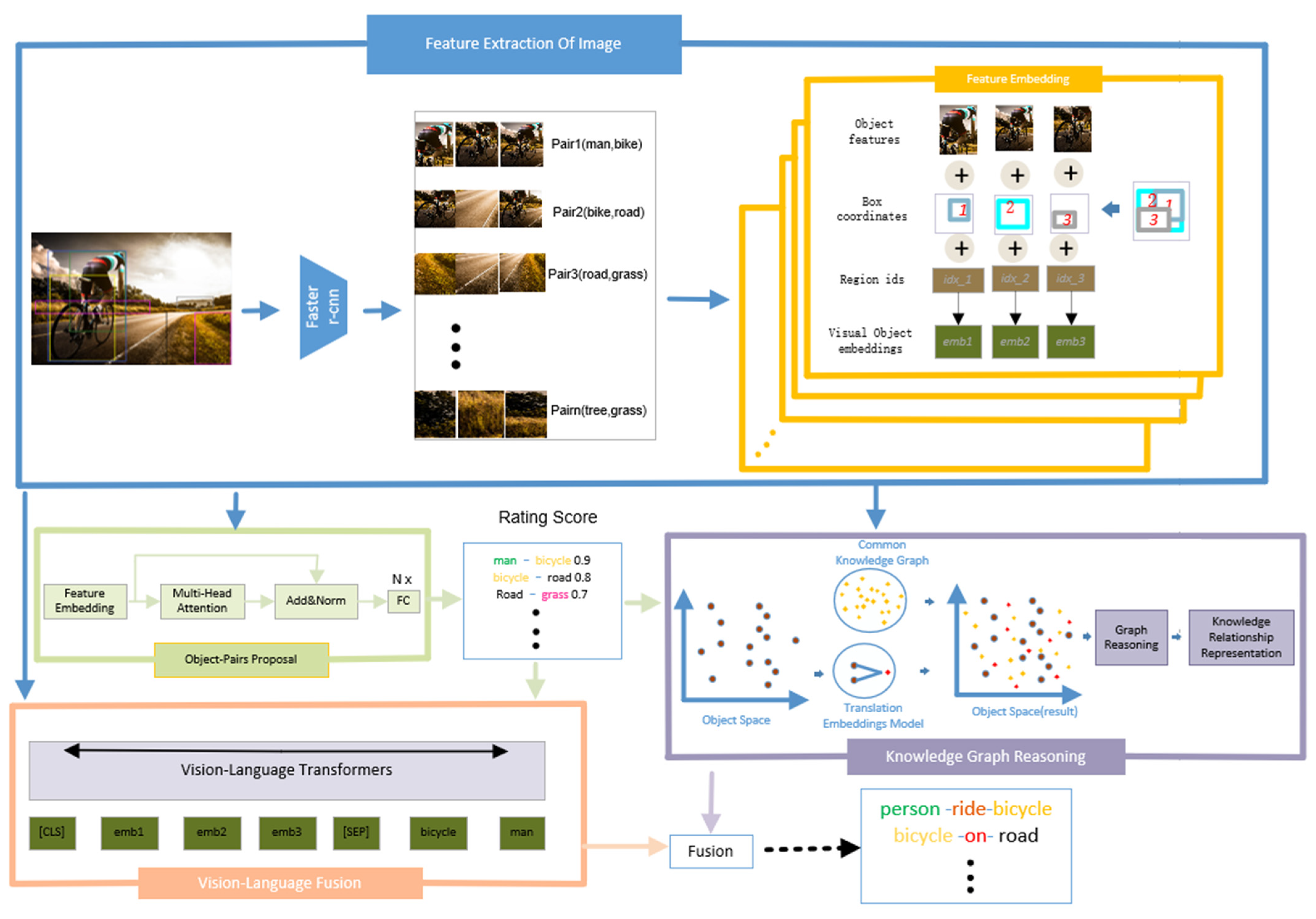
- We propose a novel two-step prediction framework that unifies visual semantic relationship prediction, visual–language fusion prediction, and commonsense reasoning with a knowledge graph.
- In the first step, we designed a relationship proposing module, which can effectively filter out irrelevant objects to solve the problem of combination explosion in visual relationship detection.
- In the second step, we propose a relationship prediction model that fuses the two modules of visual–language fusion and knowledge graph reasoning. Visual–language fusion combines visual features and semantic embedding to find the potential association between objects. Knowledge graph reasoning integrates visual semantic relationships and external common knowledge to facilitate predicate inference.
- Experiments on the Visual Genome and Visual Relationship Detection (VRD) datasets show that our proposed method performs better than current state-of-the-art methods, especially working well for infrequent relationships.
2. Related Work
3. Approach
3.1. Image Feature Extraction
3.2. Relationship Proposing
3.3. Proposal Scores of Object-Pairs
3.4. Vision–Language Fusion
3.5. Knowledge Graph Reasoning
3.6. Training and Inference Procedures
4. Experiments
4.1. Datasets
4.2. Analysis of Common Sense Knowledge
4.3. Evaluation of Model
4.4. Experimental Environment and Parameter Settings
4.5. Comparison with the State-of-the-Art Methods
4.5.1. Experiments on the VRD
4.5.2. Experiments on the VG
4.5.3. Qualitative Comparison of Our Model
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Johnson, J.; Gupta, A.; Li, F.F. Image generation from scene graphs. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1219–1228. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural. Inf. Process. Syst. 2019, 32, 13–23. [Google Scholar]
- Liu, C.; Mao, Z.; Zhang, T.; Xie, H.; Wang, B.; Zhang, Y. Graph structured network for image-text matching. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10918–10927. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure inference net: Object detection using scene-level context and instance-level relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6985–6994. [Google Scholar]
- Peng, Y.; Chi, J. Unsupervised cross-media retrieval using domain adaptation with scene graph. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4368–4379. [Google Scholar] [CrossRef]
- Qian, T.; Chen, J.; Chen, S.; Wu, B.; Jiang, Y. Scene Graph Refinement Network for Visual Question Answering. IEEE Trans. Multimed. 2022, 32, 1–13. [Google Scholar] [CrossRef]
- Sharma, P.; Ding, N.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Jing, B.; Ding, H.; Yang, Z.; Li, B.; Liu, Q. Image generation step by step: Animation generation-image translation. Applined Intell. 2021, 52, 8087–8100. [Google Scholar] [CrossRef]
- Qi, M.; Wang, Y.; Li, A.; Luo, J. Sports video captioning via attentive motion representation and group relationship modeling. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2617–2633. [Google Scholar] [CrossRef]
- Song, H.; Dai, Z.; Xu, P.; Ren, L. Interactive Visual Pattern Search on Graph Data via Graph Representation Learning. IEEE Trans. Visual. Comput. Graph. 2022, 28, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Zhang, C.; Zhao, M. Improving Visual Relationship Detection with Two-stage Correlation Exploitation. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2751–2763. [Google Scholar] [CrossRef]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-training of generic visual-linguistic representations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 2–16. [Google Scholar]
- Wu, S.; Yuan, Y.; Ma, Y.; Huang, J.; Yuan, N. Deep Convolution Neural Network Label Decomposition Method for Large Scale DOA Estimation. Signal Process. 2021, 37, 1–10. [Google Scholar]
- Sadeghi, M.A.; Farhadi, A. Recognition using visual phrases. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1745–1752. [Google Scholar]
- Liu, A.A.; Wang, Y.; Ning, X. Adaptively Clustering-Driven Learning for Visual Relationship Detection. IEEE Trans. Multimed. 2021, 23, 4515–4525. [Google Scholar] [CrossRef]
- Lu, C.; Krishna, R.; Bernstein, M.S.; Li, F. Visual relationship detection with language priors. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 852–869. [Google Scholar]
- Ben-Younes, H.; Cadene, R.; Thome, N.; Cord, M. Block: Bilinear superdiagonal fusion for visual question answering and visual relationship detection. In Proceedings of the Association for the Advancement of Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8102–8109. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE conference on computer vision and Pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X.; Tang, X. ViP-CNN: Visual phrase guided convolutional neural network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7244–7253. [Google Scholar]
- Wu, B.; Niu, G.; Yu, J.; Xiao, X.; Zhang, J.; Wu, H. Towards Knowledge-aware Video Captioning via Transitive Visual Relationship Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6753–6765. [Google Scholar] [CrossRef]
- Liu, Z.; Zheng, W. Learning multimodal relationship interaction for visual relationship detection. Pattern Recognit. 2022, 132, 108848–108851. [Google Scholar] [CrossRef]
- Li, Z.; Du, X.; Cao, Y. GAR: Graph assisted reasoning for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1284–1293. [Google Scholar]
- Zhou, H.; Hu, C.; Zhang, C.; Shen, S. Visual relationship recognition via language and position guided attention. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2097–2101. [Google Scholar]
- Zhang, W.; Yu, J.; Zhao, W. DMRFNet: Deep Multimodal Reasoning and Fusion for Visual Question Answering and explanation generation. Inf. Fusion 2021, 72, 70–79. [Google Scholar] [CrossRef]
- Ren, Y.; Xu, X.; Yang, S.; Nie, L. A Physics-Based Neural-Network Way to Perform Seismic Full Waveform Inversion. IEEE Access 2020, 8, 112266–112277. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–13. [Google Scholar]
- Mi, L.; Chen, Z. Hierarchical graph attention network for visual relationship detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13886–13895. [Google Scholar]
- Cui, Z.; Xu, C.; Zheng, W.; Yang, J. Context-dependent diffusion network for visual relationship detection. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1475–1482. [Google Scholar]
- Diederik, P.K.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yinet, G.; Lu, S.; Liu, B. Zoom-Net: Mining deep feature interactions for visual relationship recognition. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 322–338. [Google Scholar]
- Zhan, Y.; Yu, J.; Yu, T.; Tao, D. On exploring undetermined relationships for visual relationship detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5128–5137. [Google Scholar]
- Zhan, Y.; Yu, J.; Yu, T.; Tao, D. Multi-task compositional network for visual relationship detection. Int. J. Comput. Vis. 2020, 128, 2146–2165. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Predicate Detection | Phrase Detection | Relationship Detection | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R@100/50 | R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | |
| k = 1 | k = 70 | k = 70 | k = 1 | k = 1 | k = 70 | k = 70 | k = 1 | k = 1 | k = 70 | k = 70 | |
| Zoom-Net [32] | 55.98 | 94.56 | 89.03 | 28.09 | 24.82 | 37.34 | 29.05 | 21.41 | 18.92 | 27.30 | 21.37 |
| BLOCK [17] | - | 92.58 | 86.58 | - | - | 28.96 | 26.32 | - | - | 20.96 | 19.06 |
| TCE [11] | 57.93 | 96.05 | 90.25 | 40.01 | 33.46 | 45.69 | 36.69 | 31.37 | 26.76 | 37.13 | 30.19 |
| MF-URLN [33] | 58.20 | - | - | 36.10 | 31.05 | - | - | 26.80 | 23.90 | - | - |
| HGAT [29] | 59.54 | 97.02 | 90.91 | - | - | - | - | 24.63 | 22.52 | 27.73 | 22.90 |
| MSGRIN [22] | 57.9 | 96.9 | 91.0 | - | 33.8 | 47.3 | 37.4 | - | 27.2 | 38.0 | 30.8 |
| Ours | 61.13 | 97.59 | 92.35 | 42.55 | 35.71 | 47.96 | 38.83 | 34.43 | 29.95 | 41.87 | 33.81 |
| Method | Predicate Detection | |||
|---|---|---|---|---|
| k = 1 | k = 70 | |||
| R@100/50 | R@50 | R@100 | R@50 | |
| MCN [34] | 26.7 | 26.7 | - | - |
| TCE | 26.52 | 26.52 | 86.66 | 72.97 |
| MSGRIN | - | - | 89.15 | 75.28 |
| Ours | 29.13 | 29.13 | 89.87 | 75.95 |
| k | Methods | Predicate Detection | Phrase Detection | Relationship Detection | |||
|---|---|---|---|---|---|---|---|
| R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | ||
| 1 | MF-URLN | 72.20 | 71.90 | 32.10 | 26.60 | 16.50 | 14.40 |
| TCE | 71.25 | 70.95 | 34.31 | 26.90 | 21.45 | 17.22 | |
| MSGRIN | 71.64 | 71.23 | 33.49 | 26.35 | 21.08 | 16.79 | |
| Ours | 73.32 | 72.69 | 36.83 | 28.76 | 25.59 | 20.59 | |
| 100 | TCE | 96.23 | 91.19 | 35.04 | 27.75 | 22.82 | 18.47 |
| MSGRIN | 96.58 | 91.36 | 35.47 | 27.82 | 23.19 | 19.51 | |
| Ours | 97.86 | 92.79 | 36.92 | 28.66 | 26.95 | 21.82 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, S.; Fu, W. Visual Relationship Detection with Multimodal Fusion and Reasoning. Sensors 2022, 22, 7918. https://doi.org/10.3390/s22207918
Xiao S, Fu W. Visual Relationship Detection with Multimodal Fusion and Reasoning. Sensors. 2022; 22(20):7918. https://doi.org/10.3390/s22207918
Chicago/Turabian StyleXiao, Shouguan, and Weiping Fu. 2022. "Visual Relationship Detection with Multimodal Fusion and Reasoning" Sensors 22, no. 20: 7918. https://doi.org/10.3390/s22207918
APA StyleXiao, S., & Fu, W. (2022). Visual Relationship Detection with Multimodal Fusion and Reasoning. Sensors, 22(20), 7918. https://doi.org/10.3390/s22207918