

A Single Stage and Single View 3D Point Cloud Reconstruction Network Based on DetNet

Abstract
:1. Introduction
- We propose a one-stage neural network for 3D reconstruction from a single image, namely, 3D-SSRecNet. 3D-SSRecNet takes an image as input and directly outputs the predicted point cloud without further processing.
- 3D-SSRecNet includes feature extraction and 3D point cloud generation. The feature extraction network is better at extracting the detailed features of the 2D input. The point cloud generation network has a plain structure and uses a suitable activation function in its multi-layer perceptron, which reduces the loss of features during forwarding propagation to obtain an elaborate output.
- Experiments on ShapeNet and pix3D dataset have shown that 3D-SSRecNet outperforms the state-of-art reconstruction methods for the task of single-view reconstruction. At the same time, we also proved the validity of the activation function of the point cloud generation network through experiments.
2. Related Work
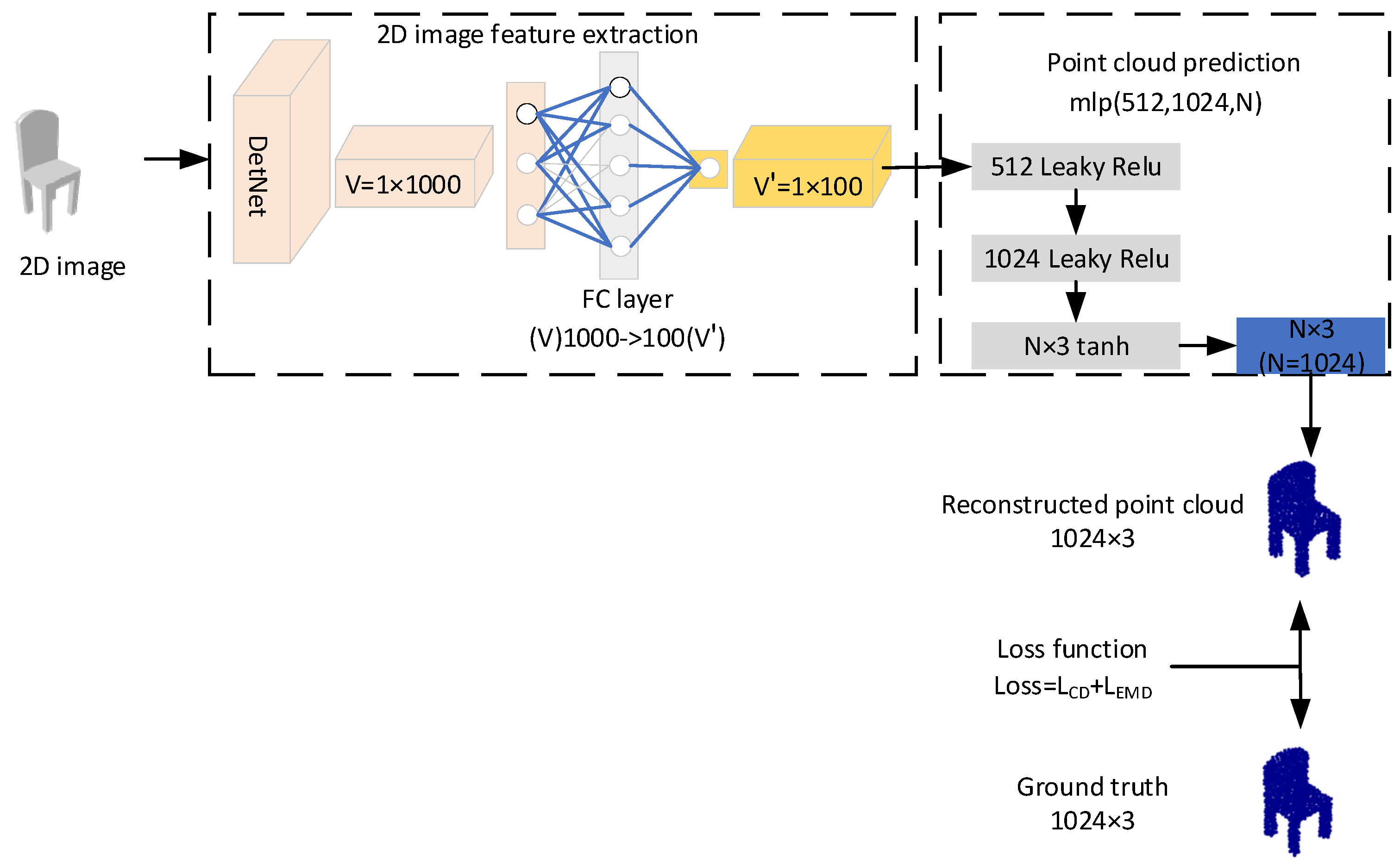
3. Approach
3.1. Architecture of 3D-SSRecNet
3.2. 2D Image Feature Extraction
3.3. Point Could Prediction
3.4. Loss Function
4. Experiment
4.1. Experiment on ShapeNet
4.2. Experiment on Pix3D
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garrido, D.; Rodrigues, R.; Augusto Sousa, A.; Jacob, J.; Castro Silva, D. Point Cloud Interaction and Manipulation in Virtual Reality. In Proceedings of the 2021 5th International Conference on Artificial Intelligence and Virtual Reality (AIVR), Kumamoto, Japan, 23–25 July 2021; pp. 15–20. [Google Scholar]
- Eppel, S.; Xu, H.; Wang, Y.R.; Aspuru-Guzik, A. Predicting 3D shapes, masks, and properties of materials inside transparent containers, using the TransProteus CGI dataset. Digit. Discov. 2021, 1, 45–60. [Google Scholar] [CrossRef]
- Xu, T.X.; Guo, Y.C.; Lai, Y.K.; Zhang, S.H. TransLoc3D: Point Cloud based Large-scale Place Recognition using Adaptive Receptive Fields. arXiv 2021, arXiv:2105.11605v3. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2463–2471. [Google Scholar] [CrossRef] [Green Version]
- Mandikal, P.; Navaneet, K.L.; Agarwal, M.; Babu, R.V. 3D-LMNet: Latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image. arXiv 2018, arXiv:1807.07796. [Google Scholar]
- Li, B.; Zhang, Y.; Zhao, B.; Shao, H. 3D-ReConstnet: A Single-View 3D-Object Point Cloud Reconstruction Network. IEEE Access 2020, 1, 99. [Google Scholar] [CrossRef]
- Gwak, J.; Choy, C.B.; Chandraker, M.; Garg, A.; Savarese, S. Weakly supervised 3D reconstruction with adversarial con-straint. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 263–272. [Google Scholar]
- Yang, B.; Wen, H.; Wang, S.; Clark, R.; Markham, A.; Trigoni, N. 3D Object Reconstruction from a Single Depth View with Adversarial Learning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 679–688. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: A Backbone network for Object Detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Yu, Q.; Yang, C.; Wei, H. Part-Wise AtlasNet for 3D point cloud reconstruction from a single image. Knowl. Based Syst. 2022, 242, 108395. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendon-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2012, 43, 55–81. [Google Scholar] [CrossRef]
- Cheikhrouhou, O.; Mahmud, R.; Zouari, R.; Ibrahim, M.; Zaguia, A.; Gia, T.N. One-Dimensional CNN Approach for ECG Arrhythmia Analysis in Fog-Cloud Environments. IEEE Access 2021, 9, 103513–103523. [Google Scholar] [CrossRef]
- Kimothi, S.; Thapliyal, A.; Akram, S.V.; Singh, R.; Gehlot, A.; Mohamed, H.G.; Anand, D.; Ibrahim, M.; Noya, I.D. Big Data Analysis Framework for Water Quality Indicators with Assimilation of IoT and ML. Electronics 2022, 11, 1927. [Google Scholar] [CrossRef]
- Tahir, R.; Sargano, A.B.; Habib, Z. Voxel-Based 3D Object Reconstruction from Single 2D Image Using Variational Autoencoders. Mathematics 2021, 9, 2288. [Google Scholar] [CrossRef]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2Vox: Context-Aware 3D Reconstruction from Single and Multi-View Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Han, Z.; Qiao, G.; Liu, Y.-S.; Zwicker, M. SeqXY2SeqZ: Structure Learning for 3D Shapes by Sequentially Predicting 1D Occupancy Segments from 2D Coordinates. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 607–625. [Google Scholar]
- Peng, K.; Islam, R.; Quarles, J.; Desai, K. TMVNet: Using Transformers for Multi-View Voxel-Based 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 222–230. [Google Scholar]
- Kniaz, V.V.; Knyaz, V.A.; Remondino, F.; Bordodymov, A.; Moshkantsev, P. Image-to-voxel model translation for 3d scene reconstruction and segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 105–124. [Google Scholar]
- Siddique, A.; Lee, S. Sym3DNet: Symmetric 3D Prior Network for Single-View 3D Reconstruction. Sensors 2022, 22, 518. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Xu, M.; Xie, H.; Perry, S.; Xia, J. Single-View 3D Object Reconstruction from Shape Priors in Memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3151–3160. [Google Scholar] [CrossRef]
- Chen, H.; Zuo, Y. 3D-ARNet: An accurate 3D point cloud reconstruction network from a single-image. Multimedia Tools Appl. 2021, 81, 12127–12140. [Google Scholar] [CrossRef]
- Pumarola, A.; Popov, S.; Moreno-Noguer, F.; Ferrari, V. C-flow: Conditional generative flow models for images and 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7949–7958. [Google Scholar]
- Hafiz, A.M.; Bhat, R.U.A.; Parah, S.A.; Hassaballah, M. SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images. arXiv 2021, arXiv:2106.15325. [Google Scholar]
- Ping, G.; Esfahani, M.A.; Chen, J.; Wang, H. Visual enhancement of single-view 3D point cloud reconstruction. Comput. Graph. 2022, 102, 112–119. [Google Scholar] [CrossRef]
- Wang, E.; Sun, H.; Wang, B.; Cao, Z.; Liu, Z. 3D-FEGNet: A feature enhanced point cloud generation network from a single image. IET Comput. Vis. 2022. [Google Scholar] [CrossRef]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2974–2983. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Feature Map Size | Parameters (Convolution Kernel Size, Number of Output Channels) |
|---|---|---|
| Stage 5 | 16 × 16 | |
| Stage 6 | 16 × 16 | |
| 1 × 1 | 16 × 16 average pool, 1000-d fully connected layer |
| Class | Softsign | Softplus | Leaky ReLU | ELU | Softsign | Softplus | Leaky ReLU | ELU |
|---|---|---|---|---|---|---|---|---|
| Airplane | 2.60 | 2.38 | 2.37 | 2.38 | 3.05 | 2.72 | 2.68 | 2.72 |
| Bench | 3.69 | 3.58 | 3.55 | 3.51 | 3.34 | 3.27 | 3.18 | 3.15 |
| Cabinet | 5.19 | 5.09 | 4.9 | 4.77 | 4.28 | 4.21 | 4.03 | 3.91 |
| Car | 3.58 | 3.57 | 3.57 | 3.56 | 2.85 | 2.85 | 2.85 | 2.84 |
| Chair | 4.45 | 4.48 | 4.40 | 4.35 | 4.30 | 4.36 | 4.23 | 4.17 |
| Lamp | 5.04 | 5.21 | 4.97 | 4.99 | 6.36 | 6.75 | 6.23 | 6.19 |
| Monitor | 5.00 | 4.84 | 4.73 | 4.72 | 4.96 | 4.77 | 4.50 | 4.49 |
| Rifle | 2.52 | 2.58 | 2.49 | 2.45 | 3.69 | 3.98 | 3.48 | 3.48 |
| Sofa | 4.57 | 4.62 | 4.52 | 4.44 | 3.82 | 3.89 | 3.73 | 3.71 |
| Speaker | 6.26 | 6.26 | 5.99 | 5.94 | 5.58 | 5.65 | 5.27 | 5.23 |
| Table | 4.86 | 4.83 | 4.40 | 4.35 | 4.75 | 4.74 | 4.21 | 4.16 |
| Telephone | 3.75 | 3.71 | 3.57 | 3.52 | 3.41 | 3.52 | 3.06 | 3.05 |
| Vessel | 3.85 | 3.77 | 3.77 | 3.72 | 4.20 | 4.26 | 3.98 | 3.96 |
| Class | PSGN | 3D-LMNet | SE-MD | 3D-VENet | 3D-ARNet | 3D-Reconstnet | 3D-FEGNet | Ours |
|---|---|---|---|---|---|---|---|---|
| Airplane | 3.74 | 3.34 | 3.11 | 3.09 | 2.98 | 2.42 | 2.36 | 2.38 |
| Bench | 4.63 | 4.55 | 4.34 | 4.26 | 4.44 | 3.57 | 3.60 | 3.51 |
| Cabinet | 6.98 | 6.09 | 5.89 | 5.49 | 6.01 | 4.66 | 4.84 | 4.77 |
| Car | 5.2 | 4.55 | 4.52 | 4.30 | 4.27 | 3.59 | 3.57 | 3.56 |
| Chair | 6.39 | 6.41 | 6.47 | 5.76 | 5.94 | 4.41 | 4.35 | 4.35 |
| Lamp | 6.33 | 7.10 | 7.08 | 6.07 | 6.47 | 5.03 | 5.13 | 4.99 |
| Monitor | 6.15 | 6.40 | 6.36 | 5.76 | 6.08 | 4.61 | 4.67 | 4.72 |
| Rifle | 2.91 | 2.75 | 2.81 | 2.67 | 2.65 | 2.51 | 2.45 | 2.45 |
| Sofa | 6.98 | 5.85 | 5.69 | 5.34 | 5.54 | 4.58 | 4.56 | 4.44 |
| Speaker | 8.75 | 8.10 | 7.92 | 7.28 | 7.65 | 5.94 | 6.00 | 5.94 |
| Table | 6.00 | 6.05 | 5.62 | 5.46 | 5.68 | 4.41 | 4.42 | 4.35 |
| Telephone | 4.56 | 4.63 | 4.51 | 4.20 | 4.10 | 3.59 | 3.50 | 3.52 |
| Vessel | 4.38 | 4.37 | 4.24 | 4.22 | 4.15 | 3.81 | 3.75 | 3.72 |
| Mean | 5.62 | 5.4 | 5.27 | 4.92 | 5.07 | 4.09 | 4.09 | 4.05 |
| Class | PSGN | 3D-LMNet | SE-MD | 3D-VENet | 3D-ARNet | 3D-Reconstnet | 3D-FEGNet | Ours |
|---|---|---|---|---|---|---|---|---|
| Airplane | 6.38 | 4.77 | 4.78 | 3.56 | 3.12 | 2.80 | 2.67 | 2.72 |
| Bench | 5.88 | 4.99 | 4.61 | 4.09 | 3.93 | 3.22 | 3.75 | 3.15 |
| Cabinet | 6.04 | 6.35 | 6.37 | 4.69 | 4.81 | 3.84 | 4.75 | 3.91 |
| Car | 4.87 | 4.10 | 4.11 | 3.57 | 3.38 | 2.87 | 3.40 | 2.84 |
| Chair | 9.63 | 8.02 | 6.53 | 6.11 | 5.45 | 4.24 | 4.52 | 4.17 |
| Lamp | 16.17 | 15.80 | 12.11 | 9.97 | 7.60 | 6.40 | 6.11 | 6.19 |
| Monitor | 7.59 | 7.13 | 6.74 | 5.63 | 5.58 | 4.38 | 4.88 | 4.49 |
| Rifle | 8.48 | 6.08 | 5.89 | 4.06 | 3.39 | 3.63 | 2.91 | 3.48 |
| Sofa | 7.42 | 5.65 | 5.21 | 4.80 | 4.49 | 3.83 | 4.56 | 3.71 |
| Speaker | 8.70 | 9.15 | 7.86 | 6.78 | 6.59 | 5.26 | 6.24 | 5.23 |
| Table | 8.40 | 7.82 | 6.14 | 6.10 | 5.23 | 4.26 | 4.62 | 4.16 |
| Telephone | 5.07 | 5.43 | 5.11 | 3.61 | 3.25 | 3.06 | 3.39 | 3.05 |
| Vessel | 6.18 | 5.68 | 5.25 | 4.59 | 4.05 | 3.99 | 4.09 | 3.96 |
| Mean | 7.75 | 7.00 | 6.21 | 5.20 | 4.68 | 3.98 | 4.30 | 3.93 |
| Class | Softsign | Softplus | Leaky ReLU | ELU | Softsign | Softplus | Leaky ReLU | ELU |
|---|---|---|---|---|---|---|---|---|
| Chair | 5.70 | 5.57 | 5.58 | 5.52 | 6.32 | 6.13 | 6.08 | 6.05 |
| Sofa | 6.22 | 6.26 | 6.09 | 6.04 | 5.12 | 5.24 | 4.92 | 4.90 |
| Table | 7.73 | 7.32 | 7.03 | 6.88 | 8.66 | 8.20 | 7.60 | 7.59 |
| Class | PSGN | 3D-LMNet | 3D-ARNet | 3D-ReconstNet | 3D-FEGNet | Ours |
|---|---|---|---|---|---|---|
| Chair | 8.05 | 7.35 | 7.22 | 5.59 | 5.66 | 5.52 |
| Sofa | 8.45 | 8.18 | 8.13 | 6.14 | 6.23 | 6.04 |
| Table | 10.85 | 11.2 | 10.31 | 7.04 | 7.58 | 6.88 |
| Mean | 9.12 | 8.91 | 8.55 | 6.26 | 6.49 | 6.15 |
| Class | PSGN | 3D-LMNet | 3D-ARNet | 3D-ReconstNet | 3D-FEGNet | Ours |
|---|---|---|---|---|---|---|
| Chair | 12.55 | 9.14 | 7.94 | 5.99 | 8.24 | 6.05 |
| Sofa | 9.16 | 7.22 | 6.69 | 5.02 | 6.77 | 4.90 |
| Table | 15.16 | 12.73 | 10.42 | 7.60 | 11.40 | 7.59 |
| Mean | 12.29 | 9.70 | 8.35 | 6.20 | 8.80 | 6.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Zhu, S.; Lu, Y. A Single Stage and Single View 3D Point Cloud Reconstruction Network Based on DetNet. Sensors 2022, 22, 8235. https://doi.org/10.3390/s22218235
Li B, Zhu S, Lu Y. A Single Stage and Single View 3D Point Cloud Reconstruction Network Based on DetNet. Sensors. 2022; 22(21):8235. https://doi.org/10.3390/s22218235
Chicago/Turabian StyleLi, Bin, Shiao Zhu, and Yi Lu. 2022. "A Single Stage and Single View 3D Point Cloud Reconstruction Network Based on DetNet" Sensors 22, no. 21: 8235. https://doi.org/10.3390/s22218235
APA StyleLi, B., Zhu, S., & Lu, Y. (2022). A Single Stage and Single View 3D Point Cloud Reconstruction Network Based on DetNet. Sensors, 22(21), 8235. https://doi.org/10.3390/s22218235