
Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning




Abstract
:1. Introduction
2. Literature Review
3. Modeling
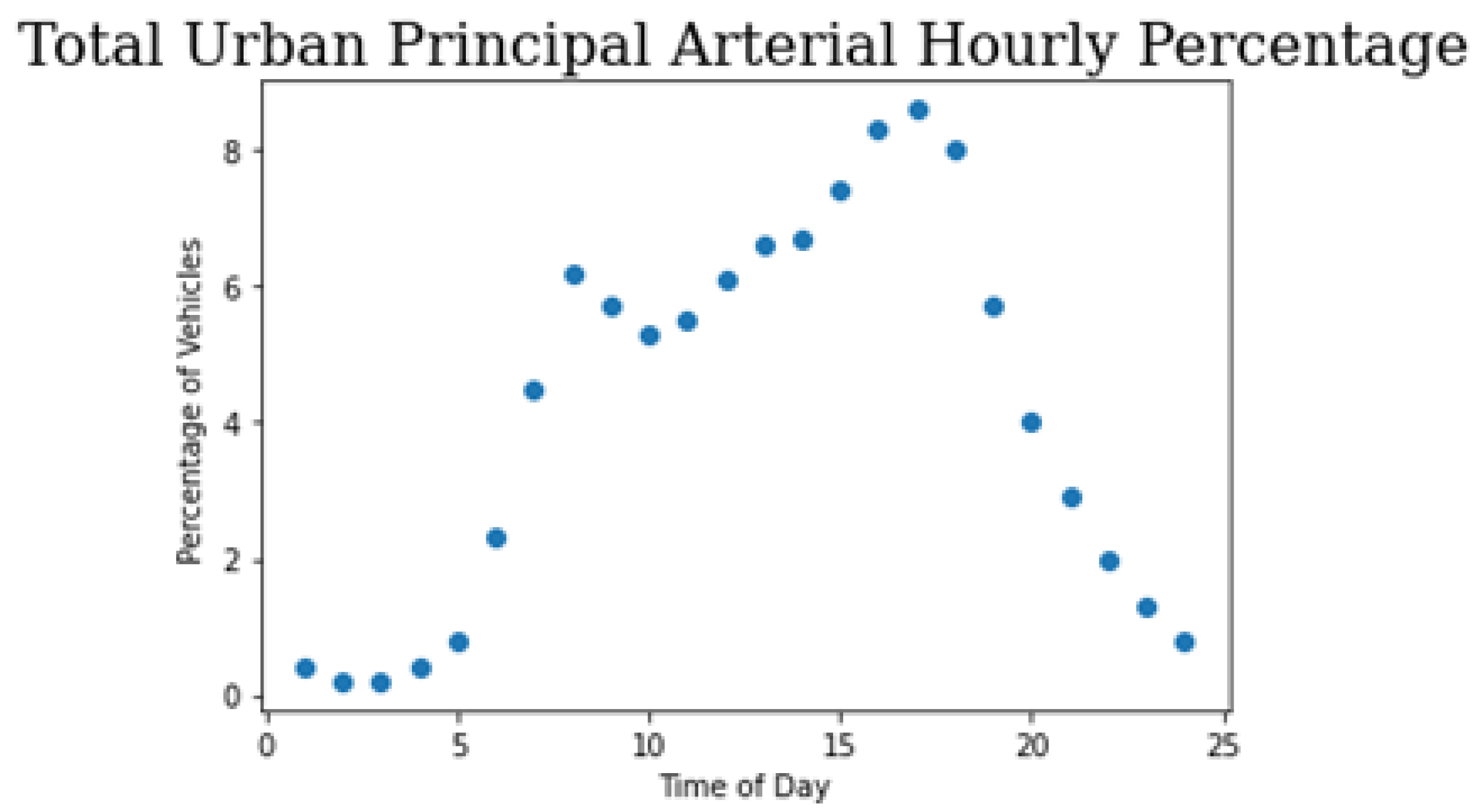
3.1. Validation Modeling
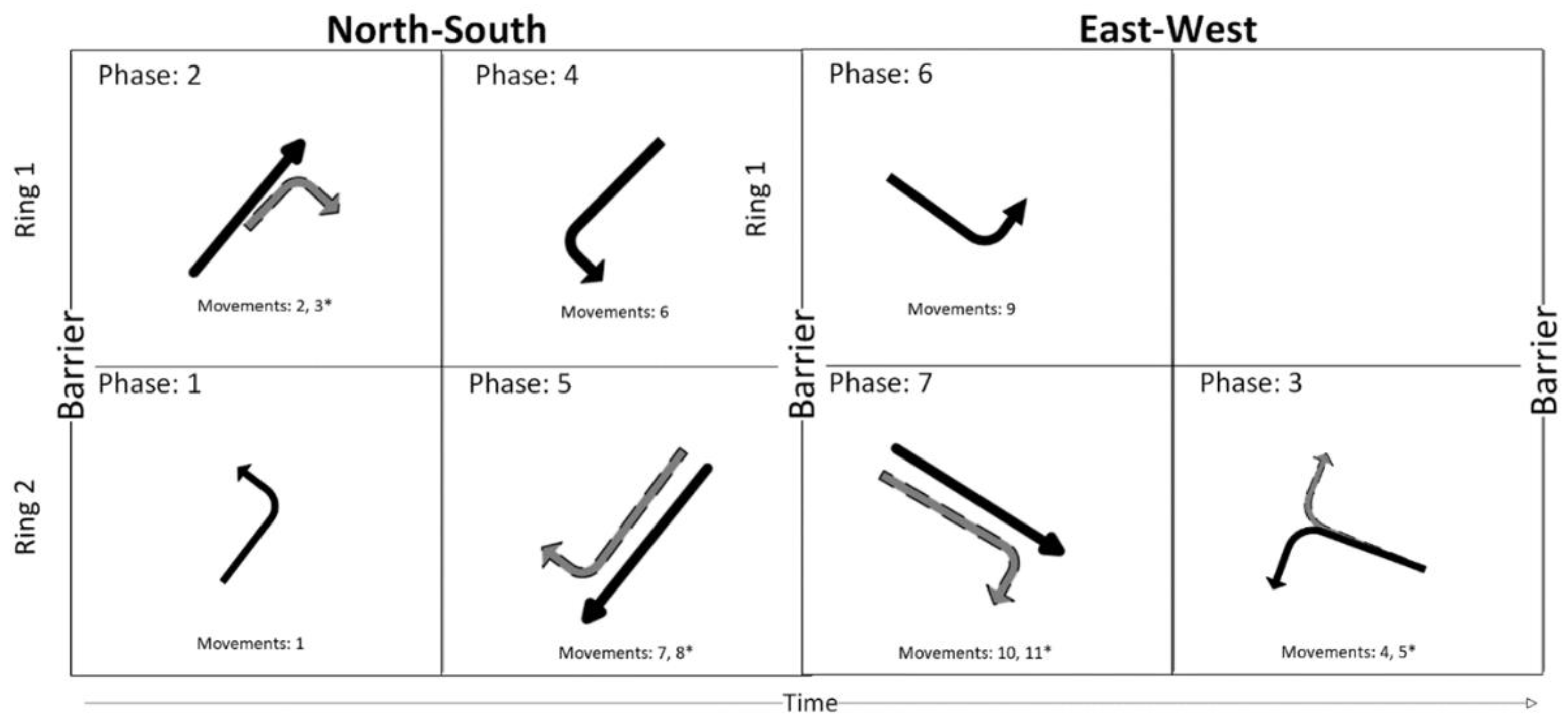
3.2. Training Environment Modeling
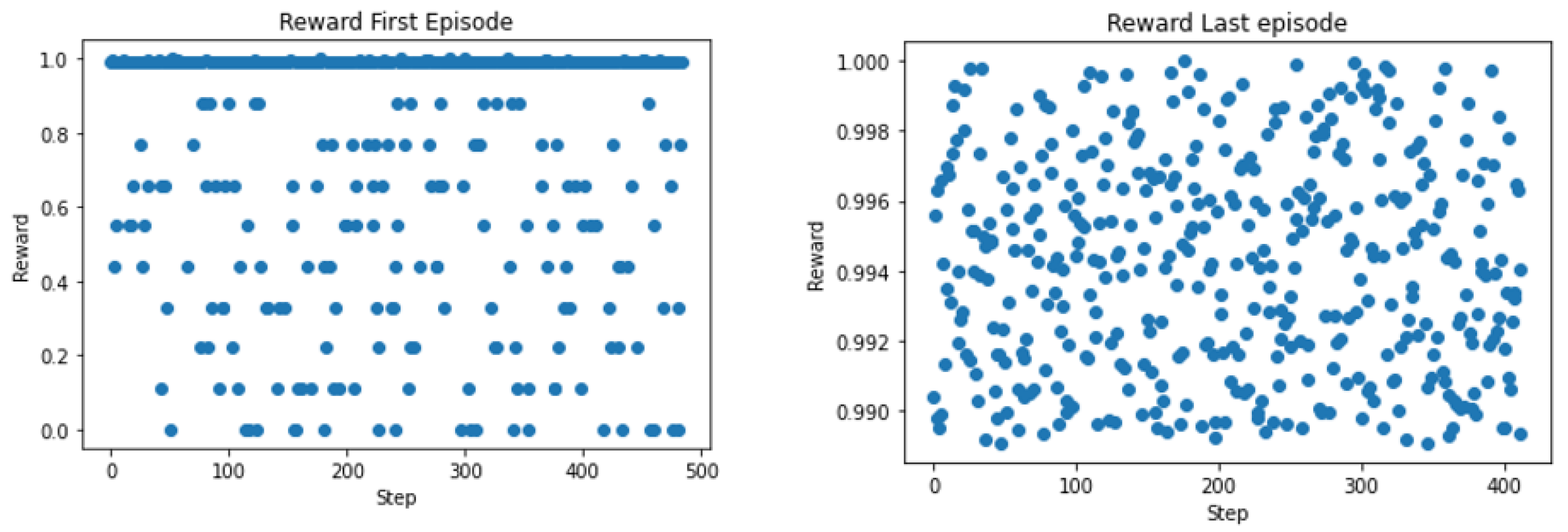
4. Optimization of Taxi Dispatcher
| Algorithm 1 Q Learning Algorithm | |
| 1: | Initialize Q-table of size (states, actions) |
| 2: | Choose reward discount, learning rate and exploration rate |
| 3: | Do |
| 4: | Choose random number between 0 and 1 |
| 5: | If random number is less than exploration rate |
| 6: | Choose random action |
| 7: | Else |
| 8: | Choose maximum Q-action |
| 9: | Perform chosen action |
| 10: | Observe |
| 11: | Update Q entry based on previously defined Q-update |
| 12: | Until |
| 13: | Reward threshold is achieved |
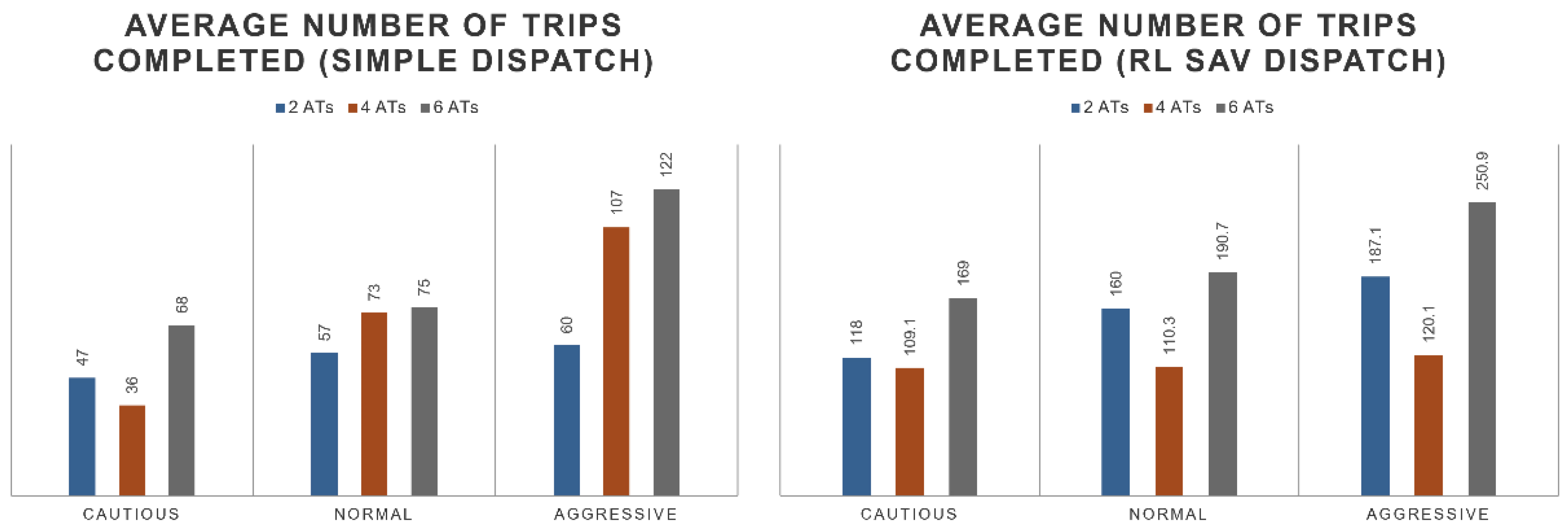
5. Simulation
6. Conclusions, Limitations, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Horváth, M.T.; Lu, Q.; Tettamanti, T.; Török, Á.; Szalay, Z. Vehicle-in-the-Loop (VIL) and Scenario-in-the-Loop (SCIL) Automotive Simulation Concepts from the Perspectives of Traffic Simulation and Traffic Control. Transp. Telecommun. 2019, 20, 153–161. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Wu, J.; Zhu, C.; Hu, K. A Study on Public Adoption of Robo-Taxis in China. J. Adv. Transp. 2020, 2020, 8877499. [Google Scholar] [CrossRef]
- Meurer, J.; Pakusch, C.; Stevens, G.; Randall, D.; Wulf, V. A Wizard of Oz Study on Passengers’ Experiences of a Robo-Taxi Service in Real-Life Settings. In Proceedings of the 2020 ACM Designing Interactive Systems Conference, Eindhoven, The Netherlands, 6–10 July 2020; pp. 1365–1377. [Google Scholar]
- Ambadipudi, A.; Heineke, K.; Kampshoff, P.; Shao, E. Gauging the Disruptive Power of Robo-Taxis in Autonomous Driving. In Automotive & Assembly; McKinsey and Company: Atlanta, GA, USA, 2017. [Google Scholar]
- Jerath, K.; Brennan, S.N. Analytical Prediction of Self-Organized Traffic Jams as a Function of Increasing ACC Penetration. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1782–1791. [Google Scholar] [CrossRef]
- Wu, J.; Huang, L.; Cao, J.; Li, M.; Wang, X. Research on grid-Based Traffic Simulation Platform. In Proceedings of the 2006 IEEE Asia-Pacific Conference on Services Computing (APSCC’06), Guangzhou, China, 12–15 December 2006; pp. 411–420. [Google Scholar]
- Jordan, W.C. Transforming Personal Mobility; WorldPress: San Francisco, CA, USA, 2012. [Google Scholar]
- Alessandrini, A.; Cattivera, A.; Holguin, C.; Stam, D. CityMobil2: Challenges and Opportunities of Fully Automated Mobility. In Road Vehicle Automation; Springer: Berlin/Hildeberg, Germany, 2014; pp. 169–184. [Google Scholar]
- Moorthy, A.; De Kleine, R.; Keoleian, G.; Good, J.; Lewis, G. Shared Autonomous Vehicles as a Sustainable Solution to the Last Mile Problem: A Case Study of Ann Arbor-Detroit Area. SAE Int. J. Passeng. Cars-Electron. Electr. Syst. 2017, 10, 328–336. [Google Scholar] [CrossRef]
- City of Arlington. Milo Pilot Program Closeout Report. 2017. Available online: https://www.urbanismnext.org/resources/milo-pilot-program-closeout-report (accessed on 1 October 2022).
- abc 7 News. California’s First Driverless Bus Hits the Road in San Ramon.2018. Available online: https://www.bishopranch.com/californias-first-driverless-bus-hits-the-road-in-san-ramon/ (accessed on 1 October 2022).
- abc 15 News Arizona. Waymo Expanding Driverless Vehicle Rides to Downtown Phoenix. Available online: https://www.abc15.com/news/region-phoenix-metro/central-phoenix/waymo-expanding-driverless-vehicle-rides-to-downtown-phoenix (accessed on 1 October 2022).
- SMART Columbus 2022. Available online: https://smart.columbus.gov/ (accessed on 1 October 2022).
- Guvenc, L.; Guvenc, B.A.; Li, X.; Doss, A.C.A.; Meneses-Cime, K.; Gelbal, S.Y. Simulation Environment for Safety Assessment of CEAV Deployment in Linden. arXiv 2020, arXiv:2012.10498. [Google Scholar]
- Community of Caring. Self-Driving Shuttle, Linden LEAP. 2020. Available online: https://callingallconnectors.org/announcements/self-driving-shuttle-linden-leap-coming-soon/ (accessed on 1 October 2022).
- Smith, B.W. Human Error as a Cause of Vehicle Crashes; Centre for Internet and Society: Bangalore, India, 2013. [Google Scholar]
- NSTC, USDOT. Ensuring American Leadership in Automated Vehicle Technologies: Automated Vehicles 4.0; NSTC, USDOT: Washington, DC, USA, 2020.
- US DOT. Preparing for the Future of Transportation: Automated Vehicles 3.0. 2018. Available online: https://www.transportation.gov/av/3 (accessed on 1 October 2022).
- NCLS. Autonomous Vehicles|Self-Driving Vehicles Enacted Legislation. In Proceedings of the National Conference of State Legislatures, Indianapolis, IN, USA, 10–13 August 2020. [Google Scholar]
- Narayanan, S.; Chaniotakis, E.; Antoniou, C. Shared Autonomous Vehicle Services: A Comprehensive Review. Transp. Res. Part C Emerg. Technol. 2020, 111, 255–293. [Google Scholar] [CrossRef]
- Gurumurthy, K.M.; Kockelman, K. Modeling Americans’ Autonomous Vehicle Preferences: A Focus on Dynamic Ride-Sharing, Privacy & Long-Distance Mode Choices. Technol. Forecast. Soc. Chang. 2020, 150, 119792. [Google Scholar] [CrossRef]
- Webb, J.; Wilson, C.; Kularatne, T. Will People Accept Shared Autonomous Electric Vehicles? A Survey before and after Receipt of the Costs and Benefits. Econ. Anal. Policy 2019, 61, 118–135. [Google Scholar] [CrossRef]
- Stoiber, T.; Schubert, I.; Hoerler, R.; Burger, P. Will Consumers Prefer Shared and Pooled-Use Autonomous Vehicles? A Stated Choice Experiment with Swiss Households. Transp. Res. Part D Transp. Environ. 2019, 71, 265–282. [Google Scholar] [CrossRef]
- Philipsen, R.; Brell, T.; Ziefle, M. Carriage Without a Driver—User Requirements for Intelligent Autonomous Mobility Services. In Proceedings of the Advances in Human Aspects of Transportation; Stanton, N., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 339–350. [Google Scholar]
- Fagnant, D.J.; Kockelman, K.M. The Travel and Environmental Implications of Shared Autonomous Vehicles, Using Agent-Based Model Scenarios. Transp. Res. Part C Emerg. Technol. 2014, 40, 1–13. [Google Scholar] [CrossRef]
- Friedrich, B. Verkehrliche Wirkung autonomer Fahrzeuge. In Autonomes Fahren: Technische, Rechtliche und Gesellschaftliche Aspekte; Maurer, M., Gerdes, J.C., Lenz, B., Winner, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 331–350. [Google Scholar] [CrossRef]
- International Transport Forum. Urban Mobility System Upgrade. Int. Transp. Forum Policy Pap. 2015, 6, 1–36. [Google Scholar] [CrossRef]
- Bischoff, J.; Maciejewski, M. Autonomous Taxicabs in Berlin—A Spatiotemporal Analysis of Service Performance. Transp. Res. Procedia 2016, 19, 176–186. [Google Scholar] [CrossRef]
- Bischoff, J.; Maciejewski, M.; Nagel, K. City-Wide Shared Taxis: A Simulation Study in Berlin. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 275–280. [Google Scholar] [CrossRef] [Green Version]
- Martinez, L.M.; Viegas, J.M. Assessing the Impacts of Deploying a Shared Self-Driving Urban Mobility System: An Agent-Based Model Applied to the City of Lisbon, Portugal. Int. J. Transp. Sci. Technol. 2017, 6, 13–27. [Google Scholar] [CrossRef]
- Vosooghi, R.; Puchinger, J.; Jankovic, M.; Vouillon, A. Shared Autonomous Vehicle Simulation and Service Design. Transp. Res. Part C Emerg. Technol. 2019, 107, 15–33. [Google Scholar] [CrossRef] [Green Version]
- Gurumurthy, K.M.; Kockelman, K.M. Analyzing the Dynamic Ride-Sharing Potential for Shared Autonomous Vehicle Fleets Using Cellphone Data from Orlando, Florida. Comput. Environ. Urban Syst. 2018, 71, 177–185. [Google Scholar] [CrossRef]
- Masoud, N.; Jayakrishnan, R. Autonomous or Driver-Less Vehicles: Implementation Strategies and Operational Concerns. Transp. Res. Part E Logist. Transp. Rev. 2017, 108, 179–194. [Google Scholar] [CrossRef]
- Alazzawi, S.; Hummel, M.; Kordt, P.; Sickenberger, T.; Wieseotte, C.; Wohak, O. Simulating the Impact of Shared, Autonomous Vehicles on Urban Mobility—A Case Study of Milan. In Proceedings of the SUMO 2018—Simulating Autonomous and Intermodal Transport Systems, Berlin-Adlershof, Germany, 14–16 May 2018; Wießner, E., Lücken, L., Hilbrich, R., Flötteröd, Y.P., Erdmann, J., Bieker-Walz, L., Behrisch, M., Eds.; EPiC Series in Engineering. EasyChair: Stockport, UK, 2018; Volume 2, pp. 94–110. [Google Scholar] [CrossRef] [Green Version]
- Cime, K.M.; Cantas, M.R.; Fernandez, P.; Guvenc, B.A.; Guvenc, L.; Joshi, A.; Fishelson, J.; Mittal, A. Assessing the Access to Jobs by Shared Autonomous Vehicles in Marysville, Ohio: Modeling, Simulating and Validating. SAE Int. J. Adv. Curr. Pract. Mobil. 2021, 3, 2509–2515. [Google Scholar]
- MORPC. Mid-Ohio Open Data. Available online: https://www.morpc.org/tool-resource/mid-ohio-open-data/ (accessed on 1 October 2022).
- ODOT. Ohio Traffic Forecasting Manual (Module 2): Traffic Forecasting Methodologies. Available online: https://transportation.ohio.gov/static/Programs/StatewidePlanning/Modeling-Forecasting/Vol-2-ForecastingMethodologies.pdf (accessed on 1 October 2022).
- Olstam, J.J.; Tapani, A. Comparison of Car-Following Models; Swedish National Road and Transport Research Institute: Linköping, Sweden, 2004; Volume 960.
- Sukennik, P.; Group, P. Micro-Simulation Guide for Automated Vehicles. COEXIST 2018, 3, 1–33. [Google Scholar]
- Mehmet, S. Smart Columbus Launches Three Mobility Technology Pilots; Intelligent Transport: Kent, United Kingdom, 2020. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Himite, B.; Patmalnieks, V. Traffic Simulator. Available online: https://traffic-simulation.de/ (accessed on 1 October 2022).
- Treiber, M.; Hennecke, A.; Helbing, D. Derivation, Properties, and Simulation of a Gas-Kinetic-Based, Nonlocal Traffic Model. Phys. Rev. E 1999, 59, 239. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.Y.R.; Lai, C.Y.; Cheng, K.T.T. Fundamentals of Algorithms. In Electronic Design Automation; Elsevier: Amsterdam, The Netherlands, 2009; pp. 173–234. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Guvenc, L.; Aksun-Guvenc, B.; Zhu, S.; Gelbal, S.Y. Autonomous Road Vehicle Path Planning and Tracking Control, 1st ed.; Wiley/IEEE Press: New York, NY, USA, 2021; ISBN 978-1-119-74794-9. [Google Scholar]
- Wang, H.; Tota, A.; Aksun-Guvenc, B.; Guvenc, L. Real Time Implementation of Socially Acceptable Collision Avoidance of a Low Speed Autonomous Shuttle Using the Elastic Band Method. IFAC Mechatron. J. 2018, 50, 341–355. [Google Scholar] [CrossRef]
- Ma, F.; Yang, Y.; Wang, J.; Li, X.; Wu, G.; Zhao, Y.; Wu, L.; Aksun-Guvenc, B.; Güvenç, L. Eco-Driving-Based Cooperative Adaptive Cruise Control of Connected Vehicles Platoon at Signalized Intersections. Transp. Res. Part D Transp. Environ. 2021, 92, 102746. [Google Scholar] [CrossRef]
- Emirler, M.T.; Wang, H.; Aksun Guvenc, B.; Guvenc, L. Automated Robust Path Following Control based on Calculation of Lateral Deviation and Yaw Angle Error. In Proceedings of the ASME Dynamic Systems and Control Conference, DSC 2015, Columbus, OH, USA, 28–30 October 2015. [Google Scholar]
- Aksun Guvenc, B.; Guvenc, L. Robust Steer-by-wire Control based on the Model Regulator. In Proceedings of the Joint IEEE Conference on Control Applications and IEEE Conference on Computer Aided Control Systems Design, Glasgow, UK, 18–20 September 2002; pp. 435–440. [Google Scholar]
- Aksun Guvenc, B.; Guvenc, L. The Limited Integrator Model Regulator and its Use in Vehicle Steering Control. Turk. J. Eng. Environ. Sci. 2002, 26, 473–482. [Google Scholar]
- Aksun Guvenc, B.; Guvenc, L.; Ozturk, E.S.; Yigit, T. Model Regulator Based Individual Wheel Braking Control. In Proceedings of the IEEE Conference on Control Applications, Istanbul, Turkey, 23–25 June 2003. [Google Scholar]
- Demirel, B.; Guvenc, L. Parameter Space Design of Repetitive Controllers for Satisfying a Mixed Sensitivity Performance Requirement. IEEE Trans. Autom. Control. 2010, 55, 1893–1899. [Google Scholar] [CrossRef] [Green Version]
- Guvenc, L.; Srinivasan, K. Force Controller Design and Evaluation for Robot Assisted Die and Mold Polishing. J. Mech. Syst. Signal Process. 1995, 9, 31–49. [Google Scholar] [CrossRef]
- Orun, B.; Necipoglu, S.; Basdogan, C.; Guvenc, L. State Feedback Control for Adjusting the Dynamic Behavior of a Piezo-actuated Bimorph AFM Probe. Rev. Sci. Instrum. 2009, 80, 063701. [Google Scholar] [CrossRef] [Green Version]
- Guvenç, L.; Srinivasan, K. Friction Compensation and Evaluation for a Force Control Application. J. Mech. Syst. Signal Process. 1994, 8, 623–638. [Google Scholar] [CrossRef]
- Cebi, A.; Guvenc, L.; Demirci, M.; Kaplan Karadeniz, C.; Kanar, K.; Guraslan, E. A Low Cost, Portable Engine ECU Hardware-In-The-Loop Test System, Mini Track of Automotive Control. In Proceedings of the IEEE International Symposium on Industrial Electronics Conference, Dubrovnik, Croatia, 20–23 June 2005. [Google Scholar]
- Liu, Z.; Li, J.; Wu, K. Context-Aware Taxi Dispatching at City-Scale Using Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1996–2009. [Google Scholar] [CrossRef]
- Haliem, M.; Mani, G.; Aggarwal, V.; Bhargava, B. A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching Using Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7931–7942. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| s0,i | Minimum distance between vehicle i and i − 1 |
| v0,i | Maximum velocity of vehicle i |
| θ | Acceleration smoothness |
| Ti | Reaction time of vehicle i |
| ai | ith vehicle’s comfortable acceleration |
| bi | ith vehicle’s comfortable deceleration |
| s* | Desired distance between vehicles i and i − 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meneses-Cime, K.; Aksun Guvenc, B.; Guvenc, L. Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning. Sensors 2022, 22, 8317. https://doi.org/10.3390/s22218317
Meneses-Cime K, Aksun Guvenc B, Guvenc L. Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning. Sensors. 2022; 22(21):8317. https://doi.org/10.3390/s22218317
Chicago/Turabian StyleMeneses-Cime, Karina, Bilin Aksun Guvenc, and Levent Guvenc. 2022. "Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning" Sensors 22, no. 21: 8317. https://doi.org/10.3390/s22218317
APA StyleMeneses-Cime, K., Aksun Guvenc, B., & Guvenc, L. (2022). Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning. Sensors, 22(21), 8317. https://doi.org/10.3390/s22218317