


Unsupervised Monocular Visual Odometry for Fast-Moving Scenes Based on Optical Flow Network with Feature Point Matching Constraint



Abstract
:1. Introduction
- We propose an unsupervised visual odometry framework that uses the matched feature points as the supervisory label for the training of the flow network.
- We present an adaptive feature matching selection module to obtain robust pose estimation performance in different motion scenarios, especially in fast-moving scenes.
- Experiments on the KITTI Odometry dataset show a significant accuracy improvement of the proposed approach compared with the traditional and the deep-learning-based visual odometry methods.
2. Related Work
2.1. Traditional Visual Odometry
2.2. Deep-Learning-Based Visual Odometry
3. The Proposed Approach
3.1. System Overview
3.2. Depth Prediction
3.3. Coordinate Mapping
3.4. The Loss Function
- Total flow loss: The total loss of our final training was L = pixel + SSIM [33] + smooth + consis + Matchloss. The pixel, SSIM, smooth and consis losses are the ones from the formula in Zhao’s paper [6]. The last one, Matchloss, is ours and is defined as follows:(,) and (,) are the coordinates of the corresponding points generated by the two methods, respectively. The Euclidean distance between the corresponding point pairs generated by the two methods was added to the loss function to optimize the optical flow network.
- Total depth loss: we followed the method in Monodepth2 [30] to train the deep network. The loss of pixels was , which was defined as follows:where is a photometric reconstruction error, is an unwarped source image, is the warped image and [ ] is the Iverson bracket.
3.5. AvgFlow Estimation and Pose Estimation
4. Experiment
4.1. Implementation Details
4.2. KeyPoint Extraction and Matching
- ORB is the combination of the FAST feature point detection method and the BRIEF [42] feature descriptor. Although its accuracy is less than SURF and SIFT, its advantage is that its feature extraction speed is higher than that of SURF and SIFT.
- By giving values to the feature points in accordance with the local picture structure of the detected keypoints, SIFT primarily achieves rotation invariance by creating a DOG scale space. Although the extraction speed is extremely slow, its advantage is that its feature extraction accuracy is higher than that of many well-known feature extraction algorithms.
- The pyramid image created by SURF, which is an optimized version of SIFT, differs greatly from that created by SIFT. In SIFT, the picture pyramid is obtained by gradually downsampling. However, in SURF, it is mostly created by adjusting the filter’s size. Compared with SIFT, SURF is quicker.
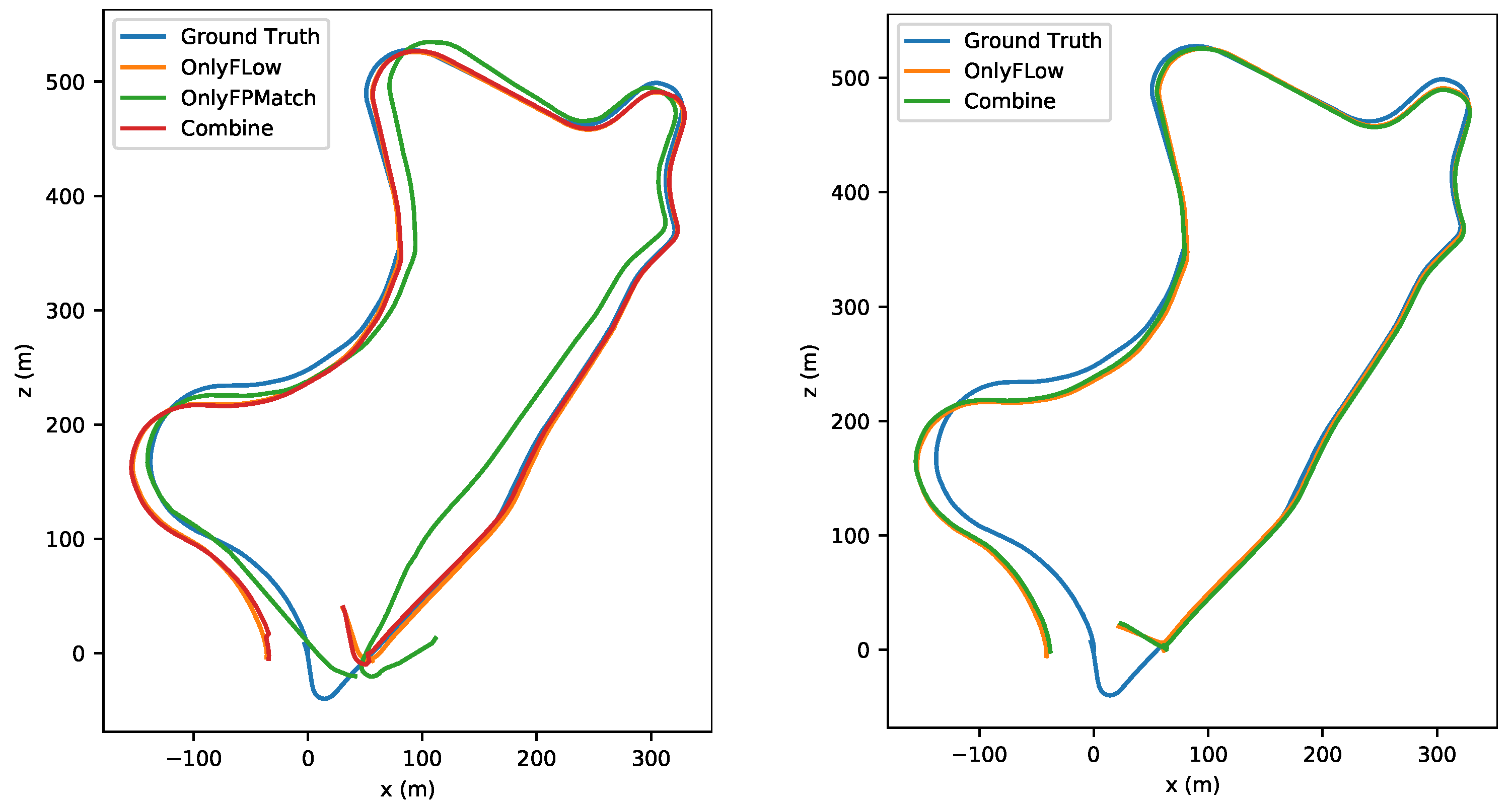
4.3. Performance in Normal Motion Scene
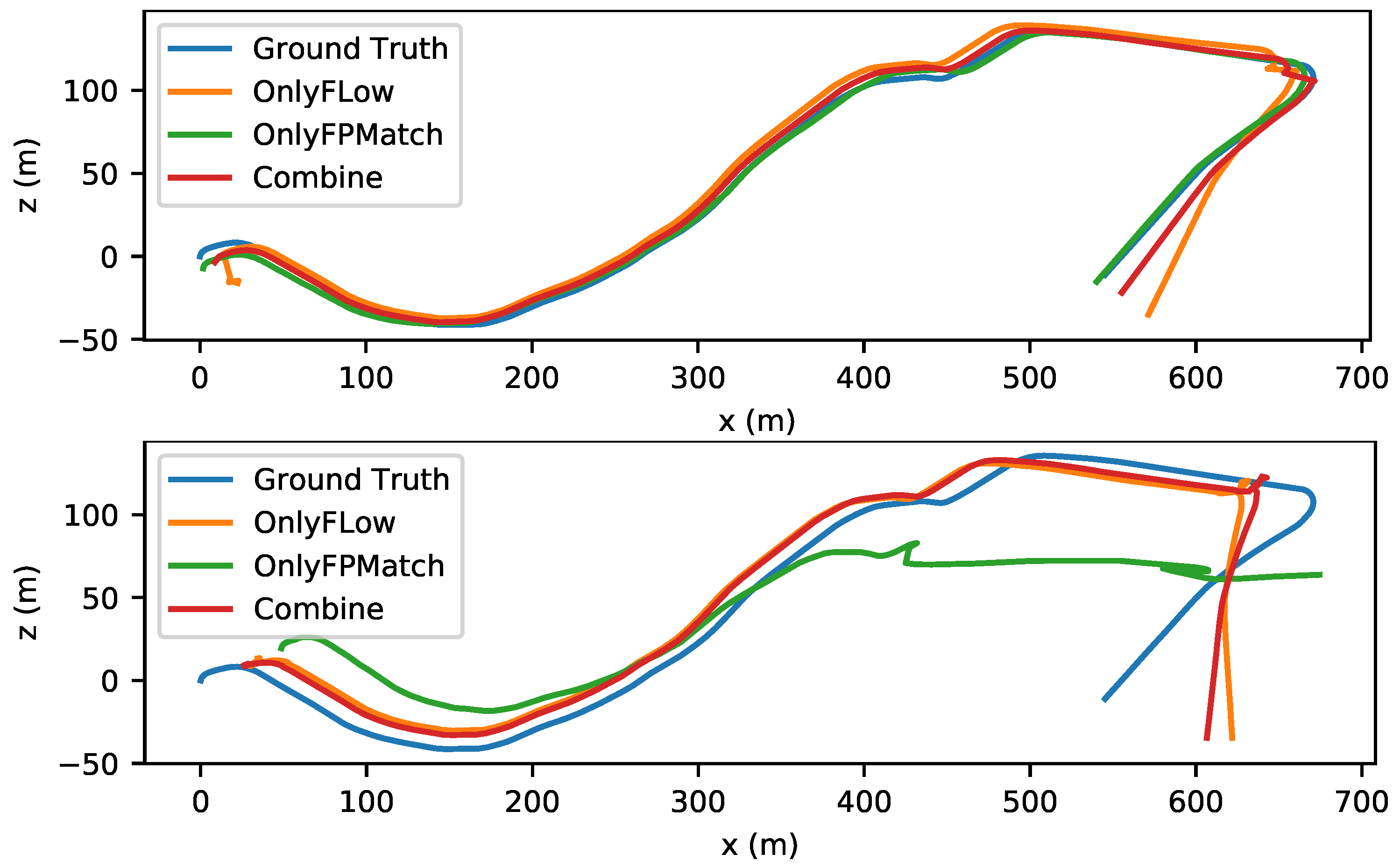
4.4. Performance in Fast-Motion Scenes
- The code for some articles was not open source.
- Experimental data on fast-motion scenes were not mentioned in some articles, so we could not assert their accuracy in fast-moving scenes.
- Even with open-source code, there may be some reasons, such as incomplete code or errors in running steps, which also made it difficult to obtain their accuracy in fast-moving scenes.
4.5. Performance in Small-Amplitude-Motion Scene
4.6. Performance on Medium-Amplitude-Motion Scene
4.7. Performance on Large-Amplitude-Motion Scene
4.8. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. IJCV 2003, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. TRO 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. Adv. Neural Inf. Process. Syst. NeurIPS 2019, 32. [Google Scholar]
- Zhao, W.; Liu, S.; Shu, Y.; Liu, Y.J. Towards better generalization: Joint depth-pose learning without posenet. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Selangor, Malaysia, 2003. [Google Scholar]
- Davide, S.; Friedrich, F. Visual odometry: Part I: The first 30 years and fundamentals. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the IEEE and ACM International Symposium on Mixed and Augmented Reality, Washington, DC, USA, 13–16 November 2007. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. PAMI 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Huang, G.; Mao, Y.; Wang, S.; Kaess, M. EDPLVO: Efficient Direct Point-Line Visual Odometry. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Tian, R.; Zhang, Y.; Zhu, D.; Liang, S.; Coleman, S.; Kerr, D. Accurate and robust scale recovery for monocular visual odometry based on plane geometry. In Proceedings of the International Conference on Robotics and Automation (ICRA), Xi’an, China, 23–27 May 2021. [Google Scholar]
- Company-Corcoles, J.P.; Garcia-Fidalgo, E.; Ortiz, A. MSC-VO: Exploiting Manhattan and Structural Constraints for Visual Odometry. IEEE Robot. Autom. Lett. RAL 2022, 7, 2803–2810. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyska, M.J.; Huo, Y. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef] [PubMed]
- Yao, T.; Qu, C.; Liu, Q.; Deng, R.; Tian, Y.; Xu, J.; Jha, A.; Bao, S.; Zhao, M.; Fogo, A.B.; et al. Compound figure separation of biomedical images with side loss. In Proceedings of the Deep Generative Models, and Data Augmentation, Labelling, and Imperfections: First Workshop, DGM4MICCAI 2021, and First Workshop, DALI 2021, Strasbourg, France, 1 October 2021. [Google Scholar]
- Jin, B.; Cruz, L.; Gonçalves, N. Pseudo RGB-D Face Recognition. IEEE Sensors J. 2022, 22, 21780–21794. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, S.; Wang, X.; Cao, Y.; Xue, F.; Yan, Z.; Zha, H. Self-supervised deep visual odometry with online adaptation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Wang, W.; Hu, Y.; Scherer, S. Tartanvo: A generalizable learning-based vo. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021. [Google Scholar]
- Kuo, X.Y.; Liu, C.; Lin, K.C.; Lee, C.Y. Dynamic attention-based visual odometry. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, C.; Wang, Y.P.; Manocha, D. Motionhint: Self-supervised monocular visual odometry with motion constraints. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Muja, M.; Lowe, D.G. Fast approximate nearest neighbors with automatic algorithm configuration. Int. Conf. Comput. Vis. Theory Appl. 2009, 2, 331–340. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o (n) solution to the pnp problem. Int. J. Comput. Vis. IJCV 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Nekrasov, V.; Dharmasiri, T.; Spek, A.; Drummond, T.; Shen, C.; Reid, I. Real-time joint semantic segmentation and depth estimation using asymmetric annotations. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans Image Process TIP 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Nister, D. An efficient solution to the five-point relative pose problem. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 16–22 June 2003. [Google Scholar]
- Zhang, Z. Determining the epipolar geometry and its uncertainty: A review. Int. J. Comput. Vis. IJCV 1998, 27, 161–195. [Google Scholar] [CrossRef]
- Hartley, R.I. In defence of the 8-point algorithm. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 20–23 June 1995. [Google Scholar]
- Bian, J.W.; Wu, Y.H.; Zhao, J.; Liu, Y.; Zhang, L.; Cheng, M.M.; Reid, I. An evaluation of feature matchers for fundamental matrix estimation. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Li, S.; Wu, X.; Cao, Y.; Zha, H. Generalizing to the open world: Deep visual odometry with online adaptation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Noble, F.K. Comparison of OpenCV’s feature detectors and feature matchers. In Proceedings of the International Conference on Mechatronics and Machine Vision in Practice, Nanjing, China, 28–30 November 2016. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks. In Proceedings of the International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Liang, Z.; Wang, Q.; Yu, Y. Deep Unsupervised Learning Based Visual Odometry with Multi-scale Matching and Latent Feature Constraint. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SURF | SIFT | |
|---|---|---|
| Execution speed (ms) | 20.7 | 33.8 |
| Point A | 1390 | 934 |
| Point B | 1413 | 905 |
| Match numbers | 784 | 495 |
| Accuracy rate (%) | 86 | 88 |
| Seq.09 | Seq.10 | |||
|---|---|---|---|---|
| T (%) | R (/100 m) | T (%) | R (/100 m) | |
| ORB-SLAM2 [4] | 9.31 | 0.26 | 2.66 | 0.39 |
| SfM-Learner [19] | 11.34 | 4.08 | 15.26 | 4.08 |
| Deep-VO-Feat [44] | 9.07 | 3.80 | 9.60 | 3.41 |
| SAEVO [45] | 8.13 | 2.95 | 6.76 | 2.42 |
| CC [21] | 7.71 | 2.32 | 9.87 | 4.47 |
| SC-SfMLearner [5] | 7.60 | 2.19 | 10.77 | 4.63 |
| TrainFlow [6] | 6.93 | 0.44 | 4.66 | 0.62 |
| Ours | 4.29 | 0.43 | 2.46 | 0.49 |
| Seq.09 | Seq.10 | |||
|---|---|---|---|---|
| T (%) | R (/100 m) | T (%) | R (/100 m) | |
| ORB-SLAM2 [4] | 11.12 | 0.33 | 2.97 | 0.36 |
| SfM-Learner [19] | 24.75 | 7.79 | 25.09 | 11.39 |
| Deep-VO-Feat [44] | 20.54 | 6.33 | 16.81 | 7.59 |
| CC [21] | 24.49 | 6.58 | 19.49 | 10.13 |
| SC-SfMLearner [5] | 33.35 | 8.21 | 27.21 | 14.04 |
| TrainFlow [6] | 7.02 | 0.45 | 4.94 | 0.64 |
| Ours | 4.52 | 0.45 | 2.66 | 0.68 |
| Seq.09 | Seq.10 | |||
|---|---|---|---|---|
| T (%) | R (/100 m) | T (%) | R (/100 m) | |
| ORB-SLAM2 [4] | X | X | X | X |
| SfM-Learner [19] | 49.62 | 13.69 | 33.55 | 16.21 |
| Deep-VO-Feat [44] | 41.24 | 10.80 | 24.17 | 11.31 |
| CC [21] | 41.99 | 11.47 | 30.08 | 14.68 |
| SC-SfMLearner [5] | 52.05 | 14.39 | 37.22 | 18.91 |
| TrainFlow [6] | 7.21 | 0.56 | 11.43 | 2.57 |
| Ours | 5.36 | 0.56 | 6.21 | 1.68 |
| Seq.09 | Seq.10 | |||
|---|---|---|---|---|
| T (%) | R (/100 m) | T (%) | R (/100 m) | |
| ORB-SLAM2 [4] | X | X | X | X |
| SfM-Learner [19] | 61.24 | 18.32 | 38.94 | 19.62 |
| Deep-VO-Feat [44] | 42.33 | 11.88 | 25.83 | 11.58 |
| CC [21] | 51.45 | 14.39 | 34.97 | 17.09 |
| SC-SfMLearner [5] | 59.32 | 17.91 | 42.25 | 21.04 |
| TrainFlow [6] | 7.72 | 1.14 | 17.30 | 5.94 |
| Ours | 5.65 | 1.04 | 14.55 | 6.24 |
| Error | Only Flow | Only FPMatch | Combine | |
|---|---|---|---|---|
| 09 (stride = 1) | T error (%) | 4.41 | 3.80 | 4.29 |
| R error (/100 m) | 0.53 | 0.48 | 0.43 | |
| ATE | 17.19 | 15.02 | 14.98 | |
| 09 (stride = 2) | T error (%) | 4.72 | 6.13 | 4.52 |
| R error (/100 m) | 0.50 | 1.03 | 0.45 | |
| ATE | 18.51 | 27.14 | 17.95 | |
| 09 (stride = 3) | T error (%) | 5.39 | 15.10 | 5.36 |
| R error (/100 m) | 0.62 | 15.07 | 0.56 | |
| ATE | 22.12 | 30.39 | 21.58 | |
| 09 (stride = 4) | T error (%) | 5.83 | X (track loss) | 5.65 |
| R error (/100 m) | 1.10 | X (track loss) | 1.04 | |
| ATE | 24.42 | X (track loss) | 23.98 | |
| 10 (stride = 1) | T error (%) | 2.83 | 2.89 | 2.46 |
| R error (/100 m) | 0.65 | 0.63 | 0.49 | |
| ATE | 4.67 | 4.62 | 4.46 | |
| 10 (stride = 2) | T error (%) | 2.77 | 2.77 | 2.66 |
| R error (/100 m) | 0.44 | 1.04 | 0.68 | |
| ATE | 4.72 | 4.93 | 4.39 | |
| 10 (stride = 3) | T error (%) | 5.72 | 4.85 | 6.21 |
| R error (/100 m) | 1.96 | 2.93 | 1.68 | |
| ATE | 15.75 | 9.09 | 8.87 | |
| 10 (stride = 4) | T error (%) | 16.33 | 24.16 | 14.55 |
| R error (/100 m) | 6.39 | 27.14 | 6.24 | |
| ATE | 34.55 | 65.20 | 28.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, Y.; Jiang, X.; Gao, Y.; Fang, Z.; Fujita, H. Unsupervised Monocular Visual Odometry for Fast-Moving Scenes Based on Optical Flow Network with Feature Point Matching Constraint. Sensors 2022, 22, 9647. https://doi.org/10.3390/s22249647
Zhuang Y, Jiang X, Gao Y, Fang Z, Fujita H. Unsupervised Monocular Visual Odometry for Fast-Moving Scenes Based on Optical Flow Network with Feature Point Matching Constraint. Sensors. 2022; 22(24):9647. https://doi.org/10.3390/s22249647
Chicago/Turabian StyleZhuang, Yuji, Xiaoyan Jiang, Yongbin Gao, Zhijun Fang, and Hamido Fujita. 2022. "Unsupervised Monocular Visual Odometry for Fast-Moving Scenes Based on Optical Flow Network with Feature Point Matching Constraint" Sensors 22, no. 24: 9647. https://doi.org/10.3390/s22249647
APA StyleZhuang, Y., Jiang, X., Gao, Y., Fang, Z., & Fujita, H. (2022). Unsupervised Monocular Visual Odometry for Fast-Moving Scenes Based on Optical Flow Network with Feature Point Matching Constraint. Sensors, 22(24), 9647. https://doi.org/10.3390/s22249647