

Intra Prediction Method for Depth Video Coding by Block Clustering through Deep Learning


Abstract
:1. Introduction
2. Related Works
2.1. Intra Prediction Methods through Neural Network
2.2. Depth Video Compression
3. Intra Prediction Method by Block Clustering through Deep Learning
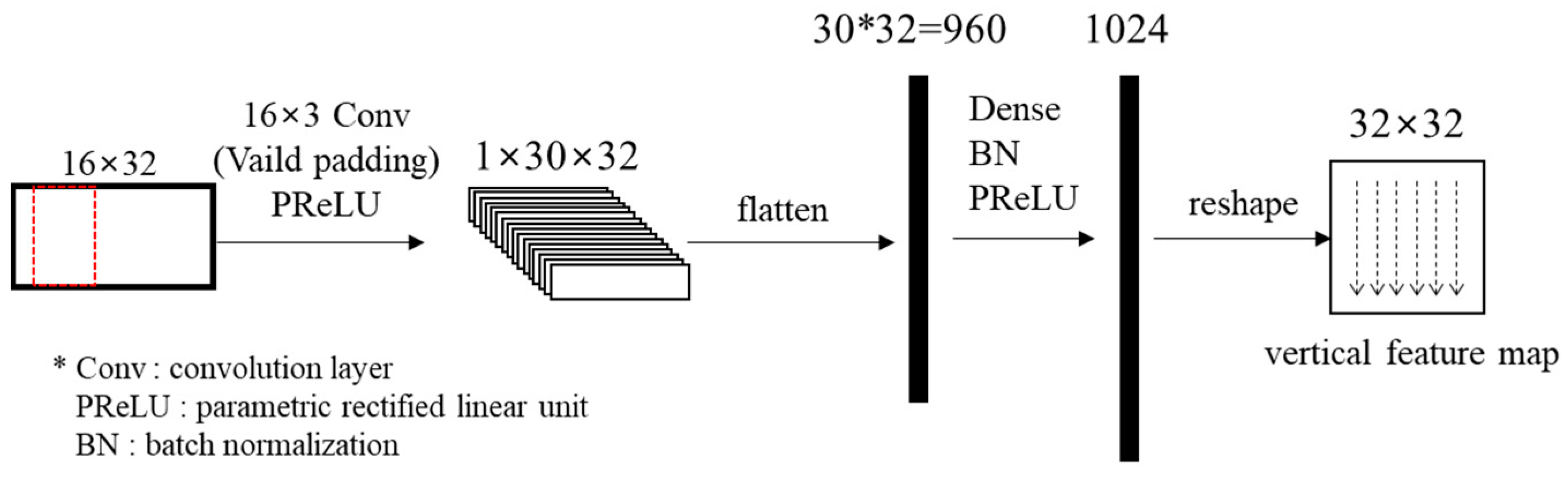
3.1. Spatial Feature Extraction through 1D CNN
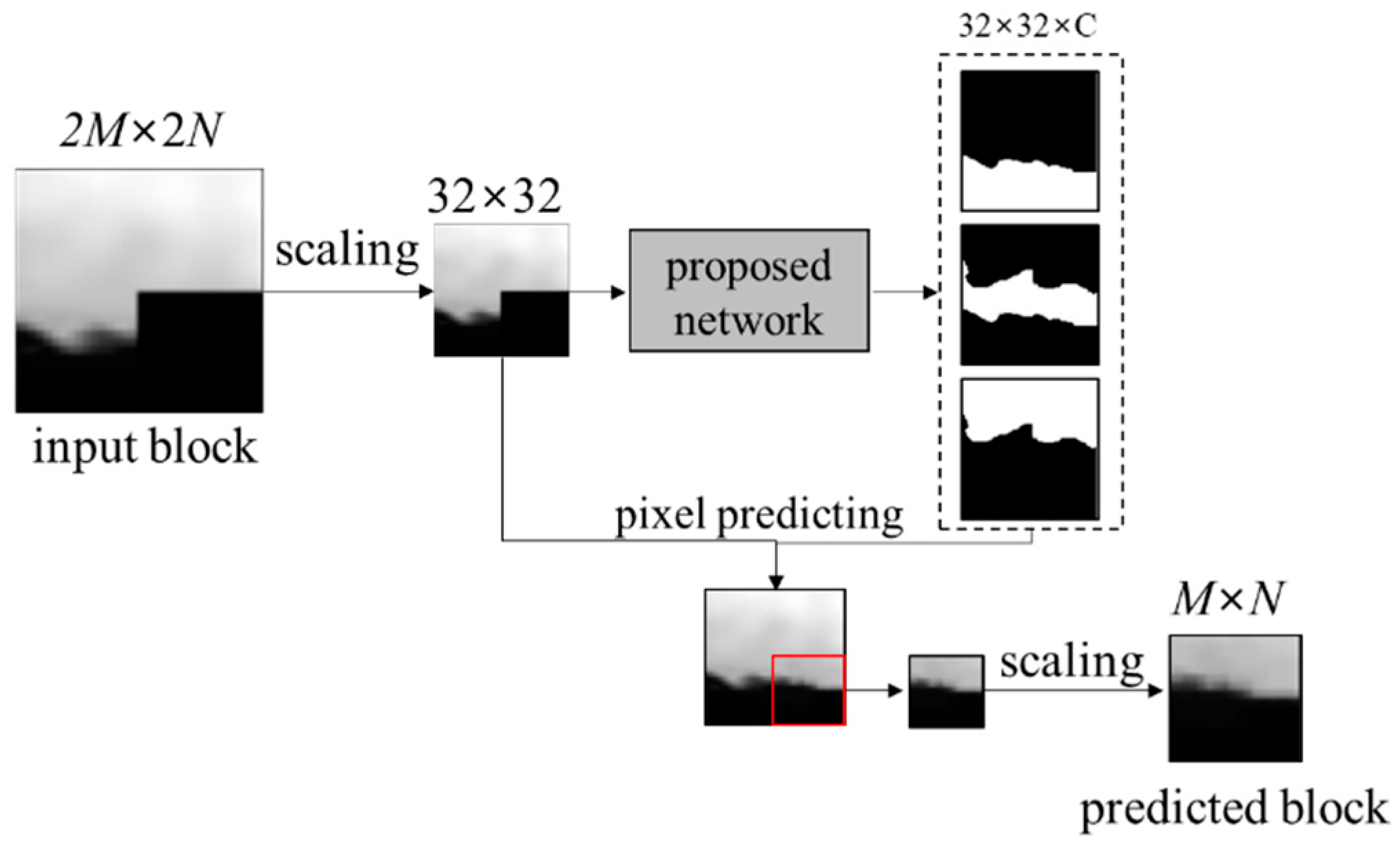
3.2. Block Clustering Network
3.2.1. Spatial Feature Prediction Network
3.2.2. Clustering Network
3.3. Intra Prediction through Block Clustering Network
3.4. Network Training
3.4.1. Dataset for training
3.4.2. Loss Function
4. Simulation Results
4.1. Improvement of Intra Prediction
4.2. Prediction Performances Based on Network Structure
4.3. Improvement of Coding Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust part-based hand gesture recognition using kinect sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Li, R.; Song, J. Large-Scale Gesture Recognition with a Fusion of RGB-D Data Based on the C3D model. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Li, Y.; Ibanez-Guzman, J. Lidar for autonomous driving: The principles, challenges, and trends for automotive lidar and perception systems. IEEE Signal Process. Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]
- Feng, D.; Rosenbaum, L.; Dietmayer, K. Towards Safe Autonomous Driving: Capture Uncertainty in the Deep Neural Network for Lidar 3d Vehicle Detection. In Proceedings of the International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Boyce, J.M.; Doré, R.; Dziembowski, A.; Fleureau, J.; Jung, J.; Kroon, B.; Salahieh, B.; Vadakital, V.K.M.; Yu, L. MPEG immersive video coding standard. Proc. IEEE 2021, 109, 1521–1536. [Google Scholar] [CrossRef]
- Kwon, S.K.; Tamhankar, A.; Rao, K.R. Overview of H.264/MPEG-4 part 10. J. Vis. Commun. Image Represent. 2006, 17, 186–216. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Lee, D.S.; Kim, B.K.; Kwon, S.K. Efficient depth data coding method based on plane modeling for intra prediction. IEEE Access 2021, 9, 29153–29164. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, W.; Xia, S.; Liu, J. Optimized Spatial Recurrent Network for Intra Prediction in Video Coding. In Proceedings of the Visual Communications and Image Processing, Taichung, Taiwan, 9–12 December 2018. [Google Scholar]
- Hu, Y.; Yang, W.; Li, M.; Liu, J. Progressive spatial recurrent neural network for intra prediction. IEEE Trans. Multimed. 2019, 21, 3024–3037. [Google Scholar] [CrossRef] [Green Version]
- Troullinou, E.; Tsagkatakis, G.; Chavlis, S.; Turi, G.F.; Li, W.; Losonczy, A.; Tsakalides, P.; Poirazi, P. Artificial neural networks in action for an automated cell-type classification of biological neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 755–767. [Google Scholar] [CrossRef]
- Kwon, S.N.; Hong, J.K.; Choi, E.K.; Lee, E.J.; Hostallero, D.E.; Kang, W.J.; Lee, B.H.; Jeong, E.R.; Koo, B.K.; Oh, S.I.; et al. Deep learning approaches to detect atrial fibrillation using photoplethysmographic signals: Algorithms development study. JMIR Mhealth Uhealth 2019, 7, e12770. [Google Scholar] [CrossRef] [Green Version]
- Toderici, G.; O’Malley, S.M.; Hwang, S.J.; Vincent, D.; Minnen, D.; Baluja, S.; Covell, M.; Sukthankar, R. Variable Rate Image Compression with Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lu, G.; Zhang, X.; Ouyang, W.; Chen, L.; Gao, Z.; Xu, D. An end-to-end learning framework for video compression. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3292–3308. [Google Scholar] [CrossRef]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Deep Convolutional Autoencoder-Based Lossy Image Compression. In Proceedings of the Picture Coding Symposium, San Francisco, CA, USA, 24–27 June 2018. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-End Optimized Image Compression. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy Image Compression with Compressive Autoencoders. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Schiopu, I.; Liu, Y.; Munteanu, A. CNN-Based Prediction for Lossless Coding of Photographic Images. In Proceedings of the Picture Coding Symposium, San Francisco, CA, USA, 24–27 June 2018. [Google Scholar]
- Schiopu, I.; Munteanu, A. Residual-error prediction based on deep learning for lossless image compression. Electron. Lett. 2018, 54, 1032–1034. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Xu, J.; Xiong, R.; Gao, W. Fully connected network-based intra prediction for image coding. IEEE Trans. Image Process. 2018, 27, 3236–3247. [Google Scholar] [CrossRef]
- Schiopu, I.; Huang, H.; Munteanu, A. CNN-based intra-prediction for lossless HEVC. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1816–1828. [Google Scholar] [CrossRef]
- Brand, F.; Seiler, J.; Kaup, A. Intra-frame coding using a conditional autoencoder. IEEE J. Sel. Top. Signal Process. 2021, 15, 354–365. [Google Scholar] [CrossRef]
- Zhu, L.; Kwong, S.; Zhang, Y.; Wang, S.; Wang, X. Generative adversarial network-based intra prediction for video coding. IEEE Trans. Multimed. 2020, 22, 45–58. [Google Scholar] [CrossRef]
- Zhong, G.; Wang, J.; Hu, J.; Liang, F. A GAN-based video intra coding. Electronics 2021, 10, 132. [Google Scholar] [CrossRef]
- Yeo, W.H.; Kim, B.G. CNN-based fast split mode decision algorithm for versatile video coding (VVC) inter prediction. J. Multimed. Inf. Syst. 2021, 8, 147–158. [Google Scholar] [CrossRef]
- Yokoyama, R.; Tahara, M.; Takeuchi, M.; Sun, H.; Matsuo, Y.; Katto, J. CNN Based Optimal Intra Prediction Mode Estimation in Video Coding. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 4–6 January 2020. [Google Scholar]
- Lee, Y.W.; Kim, J.H.; Choi, Y.J.; Kim, B.G. CNN-Based Approach for Visual Quality Improvement on HEVC. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 12–14 January 2018. [Google Scholar]
- Schwarz, S.; Preda, M.; Baroncini, V.; Budagavi, M.; Cesar, P.; Chou, P.A.; Cohen, R.A.; Krivokuća, M.; Lasserre, S.; Li, Z.; et al. Emerging MPEG standards for point cloud compression. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 133–148. [Google Scholar] [CrossRef] [Green Version]
- Garcia, D.C.; de Queiroz, R.L. Intra-Frame Context-Based Octree Coding for Point-Cloud Geometry. In Proceedings of the IEEE International Conference on Image, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Kathariya, B.; Li, L.; Li, Z.; Alvarez, J.; Chen, J. Scalable Point Cloud Geometry Coding with Binary Tree Embedded Quadtree. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- de Queiroz, R.L.; Chou, P.A. Motion-compensated compression of dynamic voxelized point clouds. IEEE Trans. Image Process. 2017, 26, 3886–3895. [Google Scholar] [CrossRef] [PubMed]
- Nenci, F.; Spinello, L.; Stachniss, C. Effective Compression of Range Data Streams for Remote Robot Operations Using H. 264. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Wang, X.; Şekercioğlu, Y.; Drummond, T.; Frémont, V.; Natalizio, E.; Fantoni, I. Relative pose based redundancy removal: Collaborative RGB-D data transmission in mobile visual sensor networks. Sensors 2018, 18, 2430. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A Large-Scale Hierarchical Multi-View RGB-D Object Dataset. In Proceedings of the International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Lai, K.; Bo, L.; Fox, D. Unsupervised Feature Learning for 3D Scene Labeling. In Proceedings of the International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Versatile Video Coding (VVC). Available online: https://jvet.hhi.fraunhofer.de (accessed on 31 October 2022).
- Ruhnke, M.; Bo, L.; Fox, D.; Burgard, W. Hierarchical Sparse Coded Surface Models. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Choi, S.J.; Zhou, Q.Y.; Koltun, V. Robust Reconstruction of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sun, X.; Ma, H.; Sun, Y.; Liu, M. A novel point cloud compression algorithm based on clustering. IEEE Robot. Autom. Lett. 2019, 4, 2132–2139. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. Layer | From No. | Layer Name | No. Kernel | Shape of Kernel | Stride/ Padding | Activation Function | Output Shape |
|---|---|---|---|---|---|---|---|
| 1 | Input | - | - | - | - | (32,32,1) | |
| 2 | 1 | Top block | - | - | - | - | (16,32,1) |
| 3 | 1 | Left block | - | - | - | - | (32,16,1) |
| 4 | 3 | Transpose | - | - | - | - | (16,32,1) |
| 5 | 2 4 | Conv_1 | 32 | (16,32) | (1,1)/ (0,0) | PReLU | (1,30,32) × 2 |
| 6 | 5 | Dense | 1024 | - | - | PReLU | - |
| 7 | 6 | Reshape | - | - | - | - | (32,32,1) × 2 |
| 8 | 7 | Concatenate | - | - | - | - | (32,32,2) |
| No. Layer | From No. | Layer Name | No. Kernel | Shape of Kernel | Stride/ Padding | Activation Function | Output Shape |
|---|---|---|---|---|---|---|---|
| 1 | Input | - | - | - | - | (32,32,2) | |
| 2 | 1 | Conv_1 | 12 | (3,3) | (1,1)/ (2,2) | PReLU | (32,32,2) |
| 3 | 1 | Conv_2 | 6 | (1,1) | (1,1)/ (0,0) | PReLU | (32,32,2) |
| 4 | 3 | Conv_3 | 6 | (3,3) | (1,1)/ (2,2) | PReLU | (32,32,2) |
| 8 | 7 | Conv_4 | C | (3,3) | (1,1)/ (2,2) | softmax | (32,32,C) |
| Number of Clusters | Prediction Error (MSE) |
|---|---|
| 2 | 0.0804 |
| 3 | 0.0643 |
| 4 | 0.5426 |
| Depth of Fully Connected Layer | Prediction Error (MSE) | No. Parameters of FC Layer | No. Parameters of Whole Network | Processing Time (s) |
|---|---|---|---|---|
| 1 | 0.0643 | 989,184 | 1,017,034 | 0.012 |
| 2 | 0.0629 | 2,043,904 | 2,071,754 | 0.016 |
| 4 | 0.0617 | 4,153,344 | 4,181,194 | 0.022 |
| Depth of CNN Layer | Prediction Error (MSE) | No. Parameters of CNN Layer | No. Parameters of Whole Network | Processing Time (s) |
|---|---|---|---|---|
| 3 | 0.0709 | 18,848 | 1,010,560 | 0.012 |
| 4 | 0.0643 | 25,322 | 1,017,034 | 0.012 |
| 5 | 0.0637 | 31,796 | 1,023,508 | 0.012 |
| 6 | 0.0635 | 38,270 | 1,029,982 | 0.013 |
| Depth Video | RMSE | Intra Prediction Method | |
|---|---|---|---|
| Plane Modeling [8] | Proposed Method | ||
| bedroom | 10 mm | 3.06% | 8.00% |
| 15 mm | 2.79% | 5.74% | |
| basement | 10 mm | 2.96% | 12.45% |
| 15 mm | 2.23% | 10.63% | |
| meeting room | 10 mm | 3.60% | 4.55% |
| 15 mm | 2.65% | 2.64% | |
| kitchen | 10 mm | 3.66% | 3.10% |
| 15 mm | 2.78% | 1.78% | |
| desk | 10 mm | 3.35% | 4.31% |
| 15 mm | 2.51% | 3.19% | |
| pumpkin | 10 mm | 5.83% | 5.28% |
| 15 mm | 5.65% | 3.75% | |
| computer | 10 mm | 6.76% | 6.83% |
| 15 mm | 6.66% | 4.15% | |
| hat | 10 mm | 4.06% | 1.93% |
| 15 mm | 3.76% | 1.97% | |
| Depth Video | Bit Rate | Intra Prediction Method | |
|---|---|---|---|
| Plane Modeling [8] | Proposed Method | ||
| bedroom | 500 kbps | 2.60% | 6.07% |
| 1000 kbps | 2.28% | 4.13% | |
| basement | 500 kbps | 1.05% | 8.04% |
| 1000 kbps | 0.90% | 5.55% | |
| meeting room | 500 kbps | 2.51% | 3.36% |
| 1000 kbps | 2.53% | 3.95% | |
| kitchen | 500 kbps | 12.07% | 3.20% |
| 1000 kbps | 12.70% | 2.45% | |
| desk | 500 kbps | 2.01% | 3.50% |
| 1000 kbps | 2.29% | 3.43% | |
| pumpkin | 500 kbps | 2.84% | 2.14% |
| 1000 kbps | 2.30% | 2.38% | |
| computer | 500 kbps | 4.16% | 3.02% |
| 1000 kbps | 3.15% | 2.82% | |
| hat | 500 kbps | 2.34% | 1.81% |
| 1000 kbps | 2.16% | 1.03% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.-s.; Kwon, S.-k. Intra Prediction Method for Depth Video Coding by Block Clustering through Deep Learning. Sensors 2022, 22, 9656. https://doi.org/10.3390/s22249656
Lee D-s, Kwon S-k. Intra Prediction Method for Depth Video Coding by Block Clustering through Deep Learning. Sensors. 2022; 22(24):9656. https://doi.org/10.3390/s22249656
Chicago/Turabian StyleLee, Dong-seok, and Soon-kak Kwon. 2022. "Intra Prediction Method for Depth Video Coding by Block Clustering through Deep Learning" Sensors 22, no. 24: 9656. https://doi.org/10.3390/s22249656
APA StyleLee, D. -s., & Kwon, S. -k. (2022). Intra Prediction Method for Depth Video Coding by Block Clustering through Deep Learning. Sensors, 22(24), 9656. https://doi.org/10.3390/s22249656