
Proactive Handover Decision for UAVs with Deep Reinforcement Learning




Abstract
:1. Introduction
- Dynamic optimization of the UAV handover decision through the proposed DRL framework with PPO algorithm determined the moment for UAV handover execution and enabled the UAV to maintain stable communication with high data rates.
- Reduction in redundant handovers with the proposed reward function that learns to ignore RSSI fluctuations and maintain connectivity to increase UAV flight time by conserving energy from reduced handover signaling.
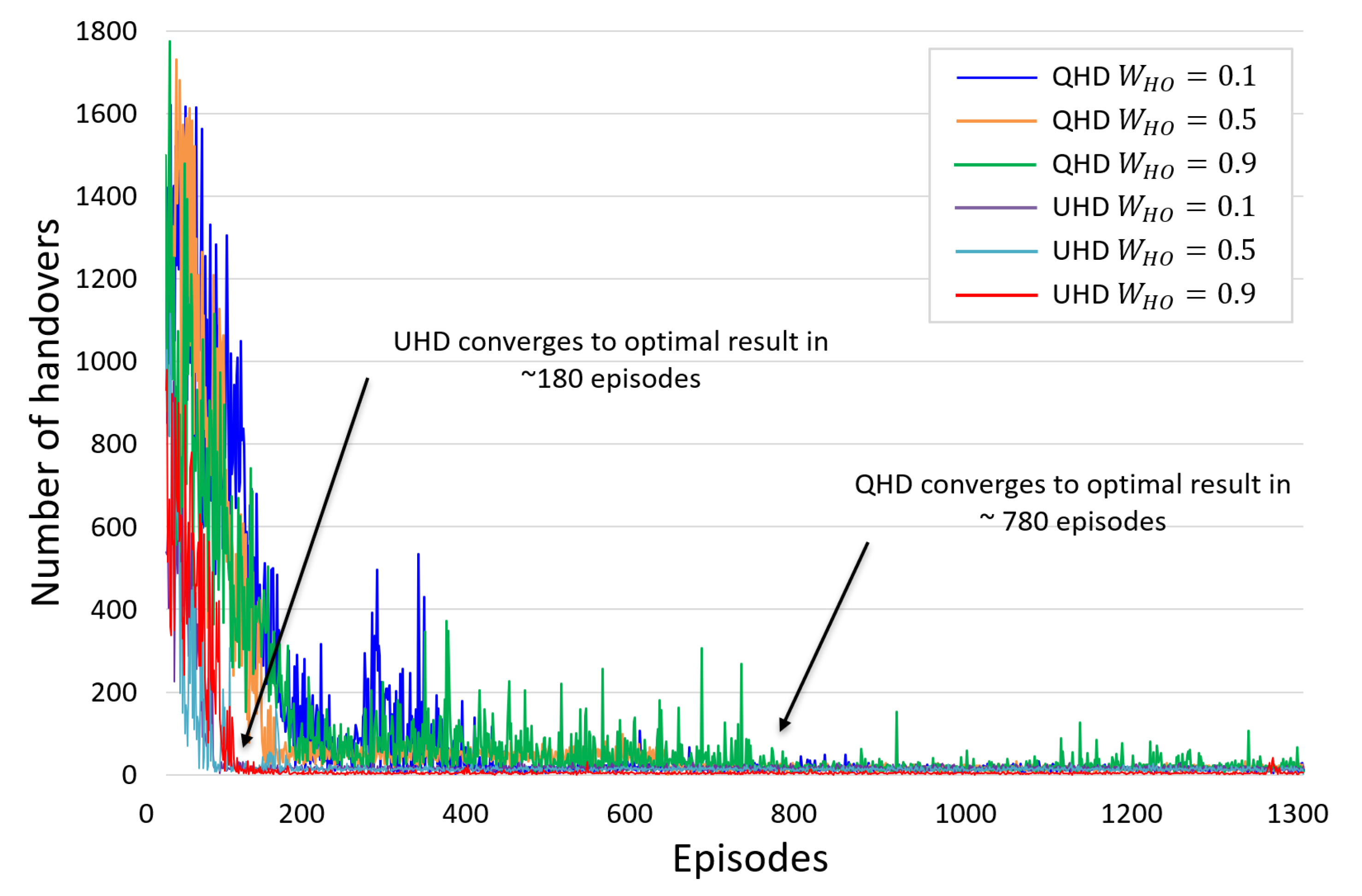
- Accelerated convergence to an optimal handover decision enabled through a simplified reward function and variance control in the PPO algorithm that reduced overall handovers and increased UAV life.
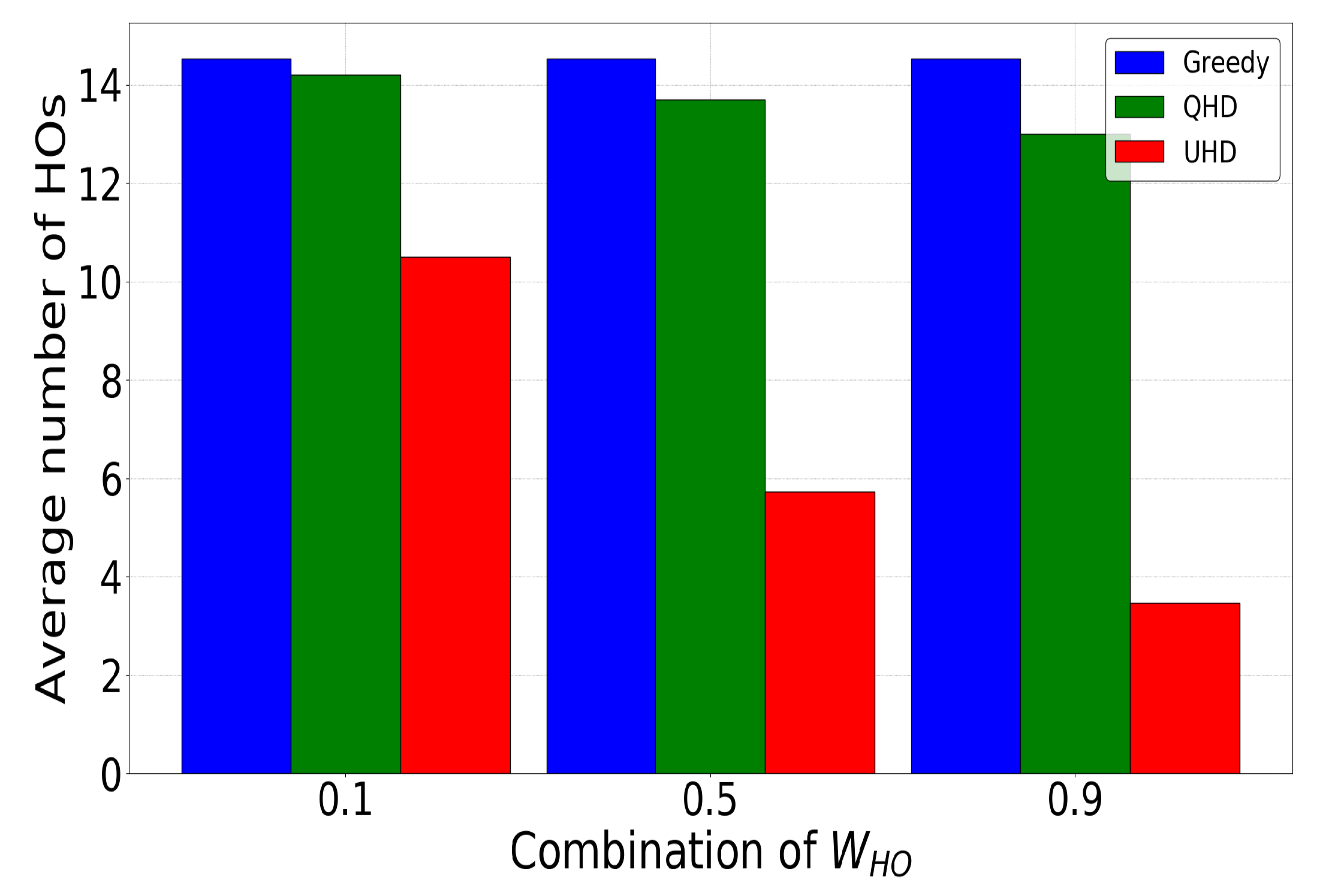
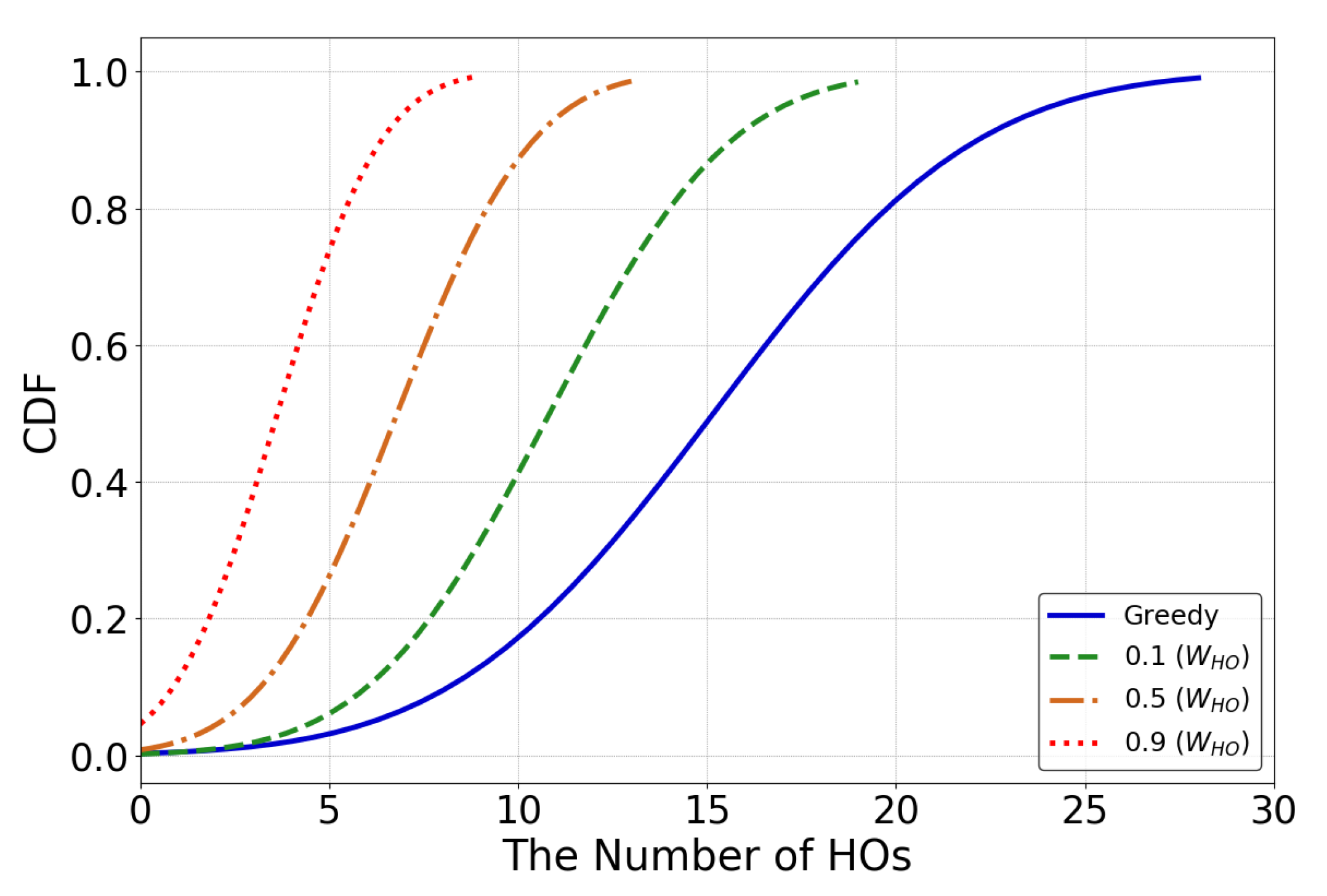
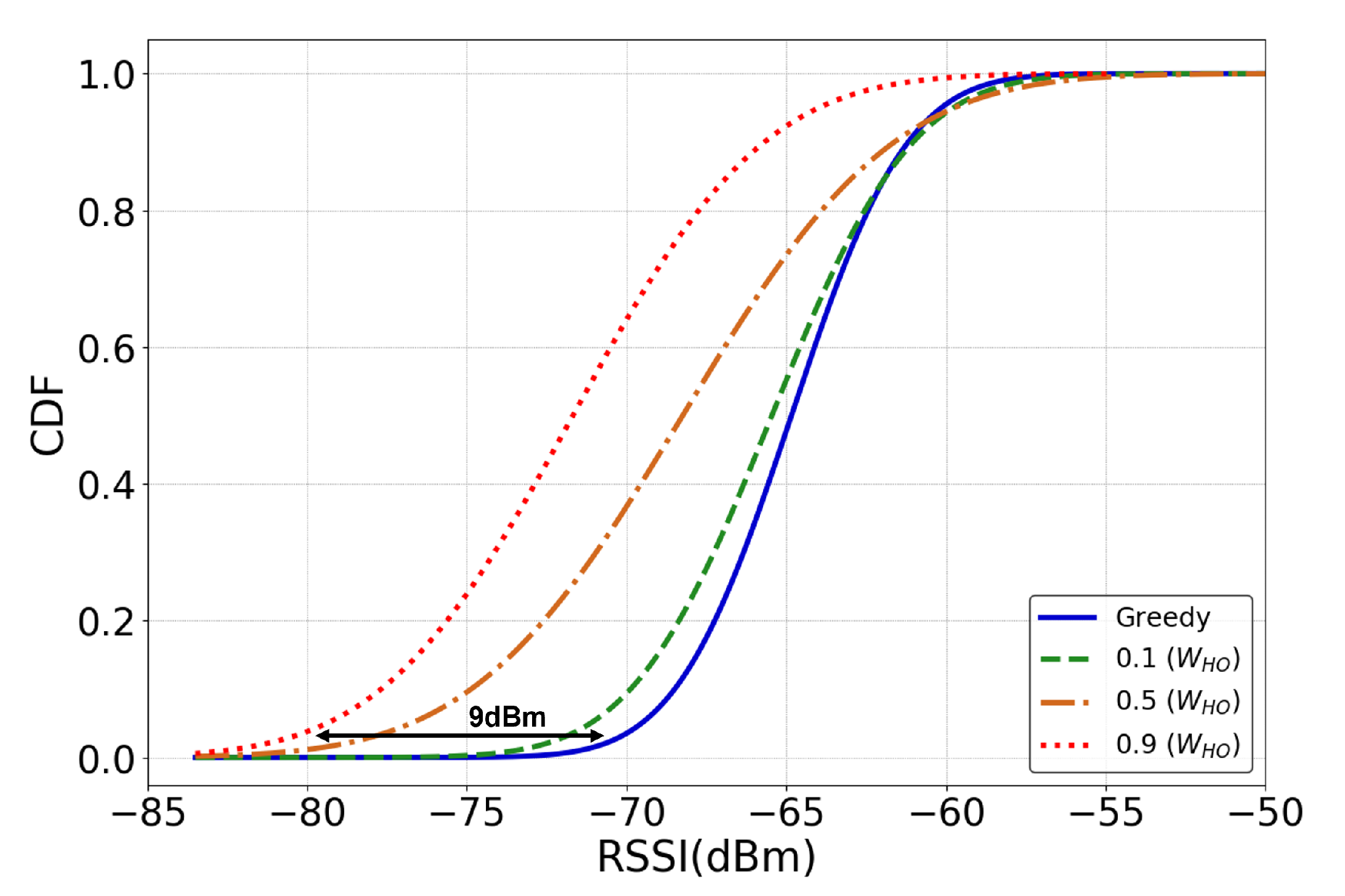
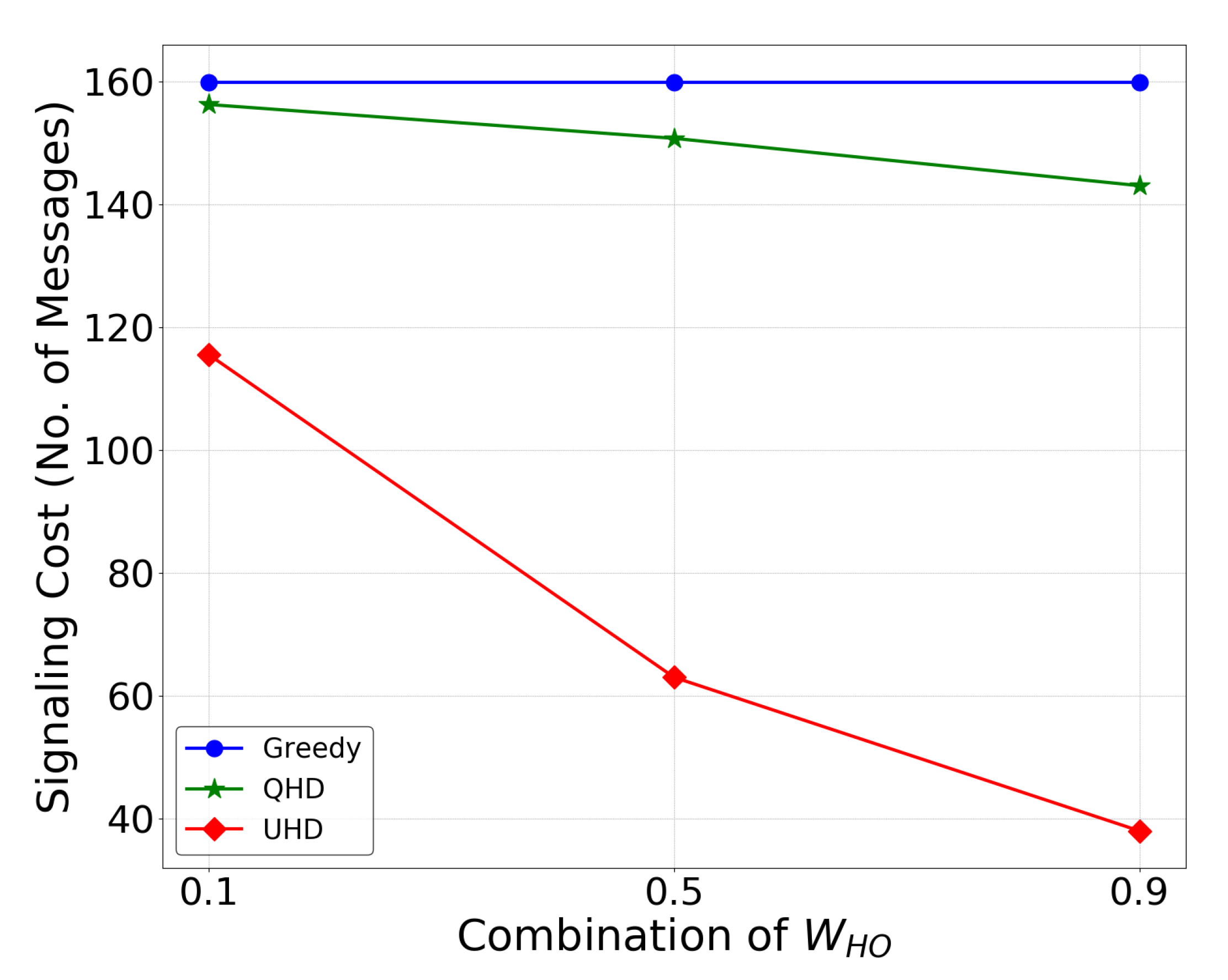
- 3D UAV environment implementation with the DRL framework to evaluate the proposed UHD, and the results showed that UHD outperformed the current greedy approach and QHD by a 76 and 73% reduction in handovers, respectively.
2. Literature Review and Background
2.1. Literature Review
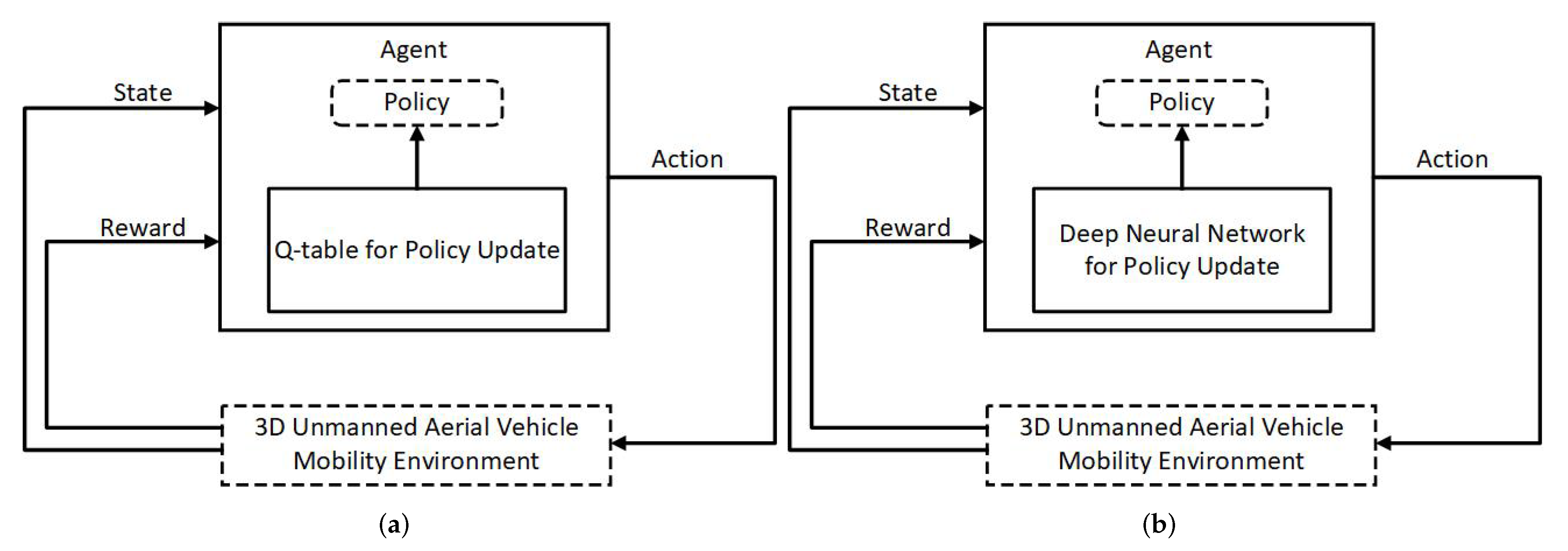
2.2. Deep Reinforcement Learning Background
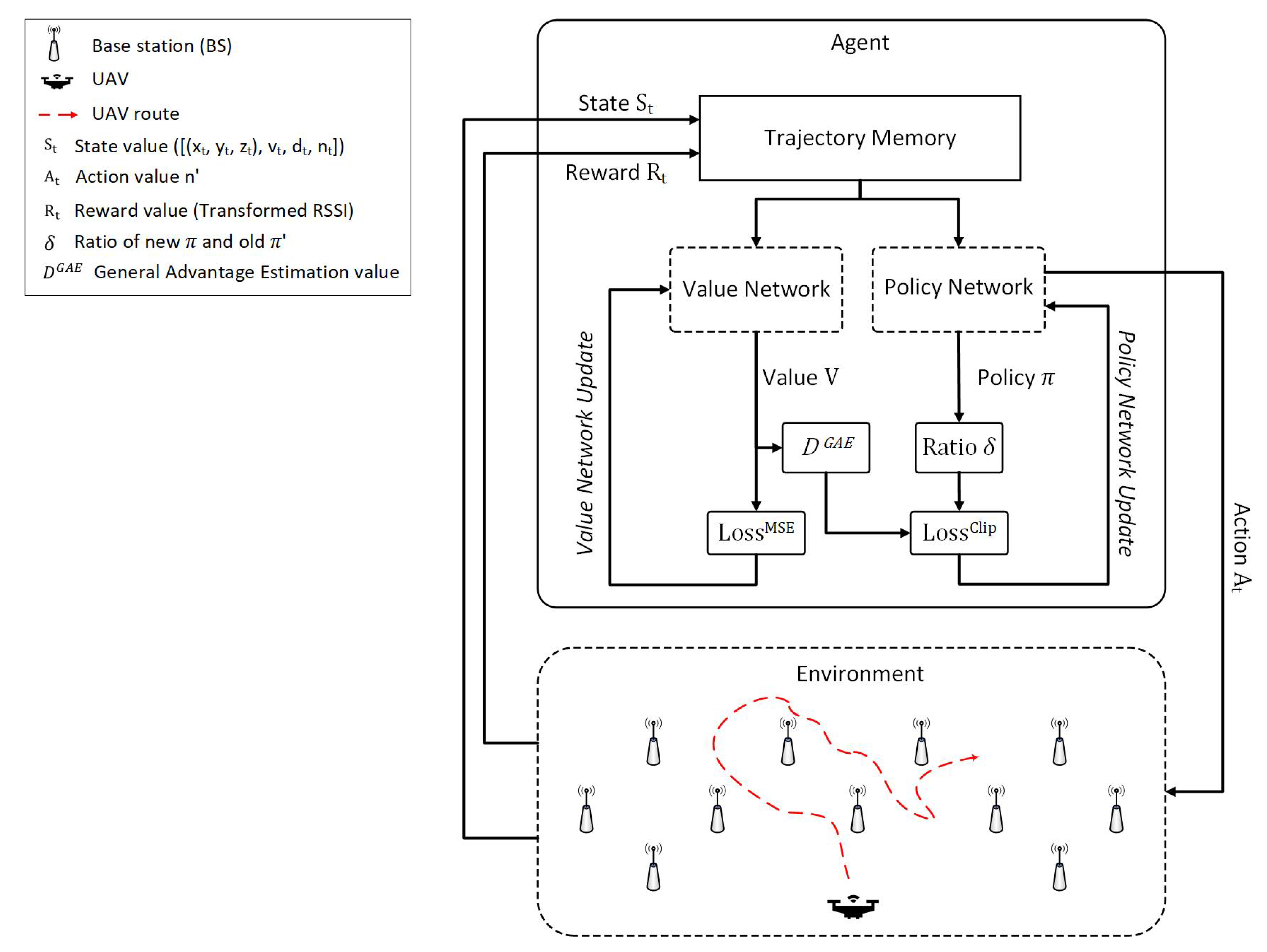
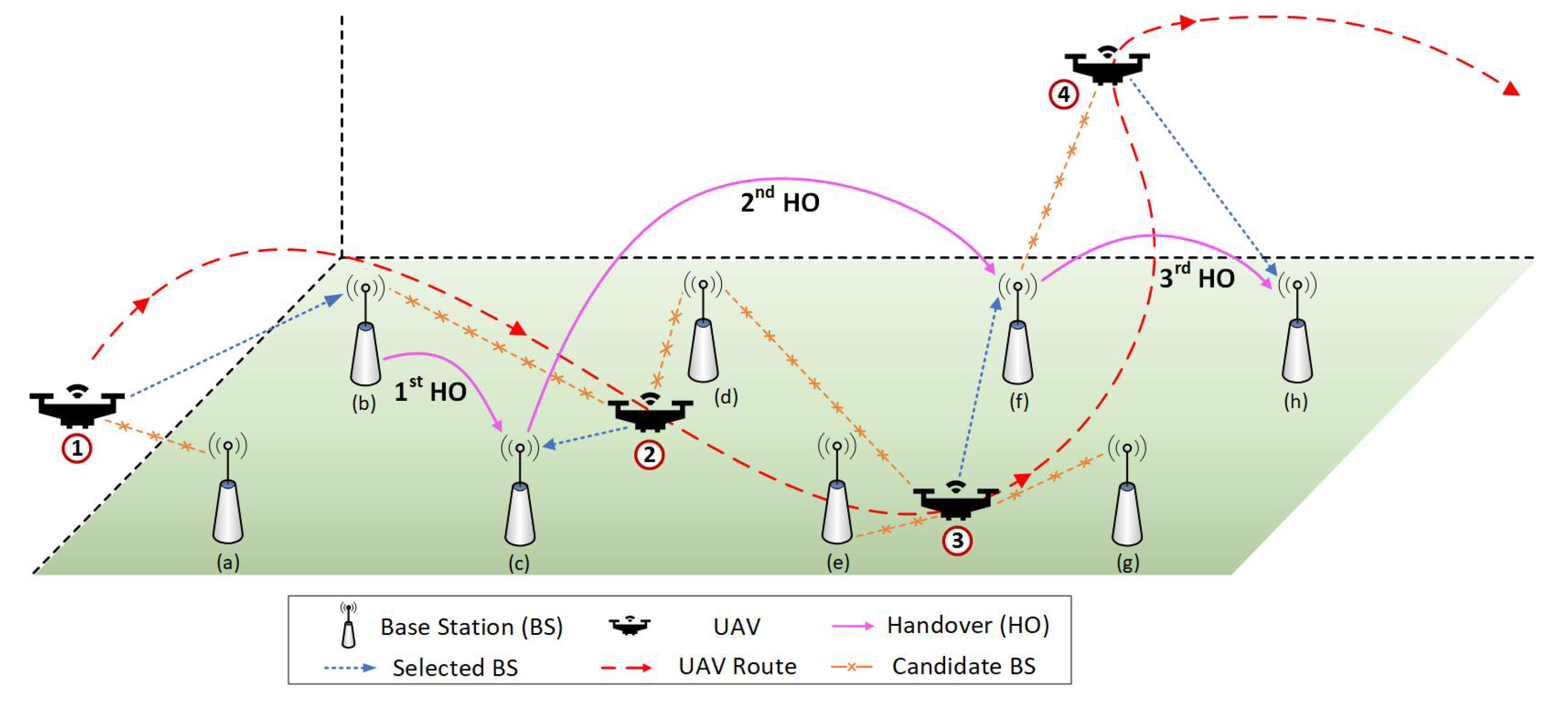
3. UAVs Handover Decision with Deep Reinforcement Learning
| Algorithm 1: UHD training procedure. |
 |
4. Results and Analyses
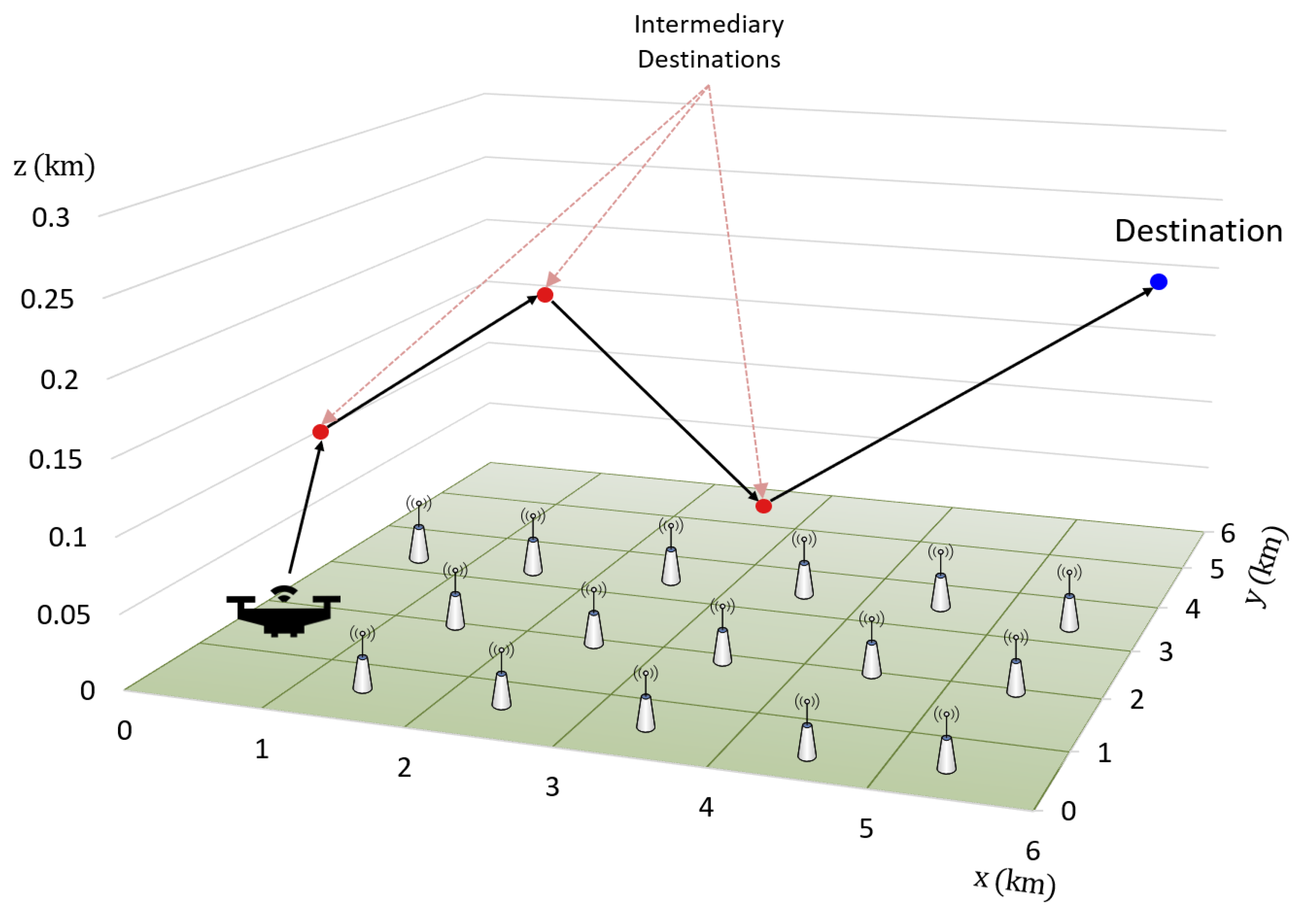
4.1. Implementation
4.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RSSI (dBm) | Signal Strength | Description |
|---|---|---|
| Excellent | Strong signal with maximum data speeds | |
| Good | Strong signal with good data speeds | |
| Fair | Fair but useful, fast and reliable data speeds may be attained | |
| Poor | Performance will drop drastically | |
| No signal | Disconnection |
References
- Abhay, K.; Nadeem, A.; Mahima, M. Mobility Management in LTE Heterogeneous Networks; Springer: Singapore, 2017. [Google Scholar] [CrossRef]
- Lin, X.; Wiren, R.; Euler, S.; Sadam, A.; Määttänen, H.L.; Muruganathan, S.; Gao, S.; Wang, Y.P.E.; Kauppi, J.; Zou, Z.; et al. Mobile Network-Connected Drones: Field Trials, Simulations, and Design Insights. IEEE Veh. Technol. Mag. 2019, 14, 115–125. [Google Scholar] [CrossRef]
- Kim, M.; Lee, W. Adaptive Success Rate-based Sensor Relocation for IoT Applications. KSII Trans. Internet Inf. Syst. (TIIS) 2021, 15, 3120–3137. [Google Scholar]
- Euler, S.; Maattanen, H.L.; Lin, X.; Zou, Z.; Bergström, M.; Sedin, J. Mobility Support for Cellular Connected Unmanned Aerial Vehicles: Performance and Analysis. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Zhang, H.; Zhou, M. Analysis of Handover Probability Based on Equivalent Model for 3D UAV Networks. In Proceedings of the 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 8–11 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Banagar, M.; Dhillon, H.S. Performance Characterization of Canonical Mobility Models in Drone Cellular Networks. IEEE Trans. Wirel. Commun. 2020, 19, 4994–5009. [Google Scholar] [CrossRef]
- Chowdhury, M.M.U.; Saad, W.; Güvenç, I. Mobility Management for Cellular-Connected UAVs: A Learning-Based Approach. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, X.; Khan, T.; Mozaffari, M. Efficient Drone Mobility Support Using Reinforcement Learning. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Jang, Y.; Raza, S.M.; Kim, M.; Choo, H. UAVs Handover Decision using Deep Reinforcement Learning. In Proceedings of the 2022 International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Korea, 3–5 January 2022. [Google Scholar]
- Unity 3D Framework. Available online: https://unity3d.com/unity/whats-new/2019.4.13 (accessed on 27 January 2022).
- Azari, M.M.; Solanki, S.; Chatzinotas, S.; Kodheli, O.; Sallouha, H.; Colpaert, A.; Montoya, J.F.M.; Pollin, S.; Haqiqatnejad, A.; Mostaani, A.; et al. Evolution of Non-Terrestrial Networks From 5G to 6G: A Survey. arXiv 2021, arXiv:2107.06881. Available online: http://xxx.lanl.gov/abs/2107.06881 (accessed on 25 January 2022).
- Khabbaz, M.; Antoun, J.; Assi, C. Modeling and Performance Analysis of UAV-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 8384–8396. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, S.; Kaiwartya, O.; Kashyap, P.K.; Lloret, J.; Song, H. Drone assisted Flying Ad-Hoc Networks: Mobility and Service oriented modeling using Neuro-fuzzy. Ad Hoc Netw. 2020, 106, 102242. [Google Scholar] [CrossRef]
- Fotouhi, A.; Ding, M.; Hassan, M. Flying Drone Base Stations for Macro Hotspots. IEEE Access 2018, 6, 19530–19539. [Google Scholar] [CrossRef]
- Fotouhi, A.; Ding, M.; Hassan, M. DroneCells: Improving spectral efficiency using drone-mounted flying base stations. J. Netw. Comput. Appl. 2021, 174, 102895. [Google Scholar] [CrossRef]
- Chowdhery, A.; Jamieson, K. Aerial Channel Prediction and User Scheduling in Mobile Drone Hotspots. IEEE/ACM Trans. Netw. 2018, 26, 2679–2692. [Google Scholar] [CrossRef]
- Banagar, M.; Dhillon, H.S. 3GPP-Inspired Stochastic Geometry-Based Mobility Model for a Drone Cellular Network. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Banagar, M.; Dhillon, H.S. Fundamentals of Drone Cellular Network Analysis under Random Waypoint Mobility Model. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Tang, J.; Shojaeifard, A.; Chen, Z.; Hu, J.; So, D.K.C.; Wong, K.K. Drone Mobile Networks: Performance Analysis Under 3D Tractable Mobility Models. IEEE Access 2021, 9, 90555–90567. [Google Scholar] [CrossRef]
- Yang, H.; Raza, S.M.; Kim, M.; Le, D.T.; Van Vo, V.; Choo, H. Next Point-of-Attachment Selection Based on Long Short Term Memory Model in Wireless Networks. In Proceedings of the 2020 14th International Conference on Ubiquitous Information Management and Communication (IMCOM), Taichung, Taiwan, 3–5 January 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Jang, B.; Raza, S.M.; Kim, M.; Choo, H. MoGAN: GAN based Next PoA Selection for Proactive Mobility Management. In Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP), Madrid, Spain, 13–16 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, M.; Wang, P.; Chan, C.Y.; Askary, S. A Reinforcement Learning Approach for Intelligent Traffic Signal Control at Urban Intersections. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4242–4247. [Google Scholar] [CrossRef] [Green Version]
- Khoshkholgh, M.G.; Yanikomeroglu, H. RSS-Based UAV-BS 3-D Mobility Management via Policy Gradient Deep Reinforcement Learning. arXiv 2021, arXiv:2103.08034. Available online: http://xxx.lanl.gov/abs/2103.08034 (accessed on 27 January 2022).
- Fakhreddine, A.; Bettstetter, C.; Hayat, S.; Muzaffar, R.; Emini, D. Handover Challenges for Cellular-Connected Drones; DroNet’19; Association for Computing Machinery: New York, NY, USA, 2019; pp. 9–14. [Google Scholar] [CrossRef]
- Christopher J.C.H., W.; Peter, D. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjel, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Machine Learning Research, Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 1928–1937. [Google Scholar]
- John, S.; Filip, W.; Prafulla, D.; Alec, R.; Oleg, K. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. Available online: http://xxx.lanl.gov/abs/1707.06347 (accessed on 27 January 2022).
- Sivanesan, K.; Zou, J.; Vasudevan, S.; Palat, S. Mobility performance optimization for 3GPP LTE HetNets. In Design and Deployment of Small Cell Networks; Anpalagan, A., Bennis, M., Vannithamby, R., Eds.; Cambridge University Press: Cambridge, UK, 2015; pp. 1–30. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2018, arXiv:1506.02438. Available online: http://xxx.lanl.gov/abs/1506.02438 (accessed on 27 January 2022).
- Feng, B.; He, X.; Cheng, J.C.; Zeng, Q.; Sim, C.Y.D. A Low-Profile Differentially Fed Dual-Polarized Antenna With High Gain and Isolation for 5G Microcell Communications. IEEE Trans. Antennas Propag. 2020, 68, 90–99. [Google Scholar] [CrossRef]
- Zafari, F.; Gkelias, A.; Leung, K.K. A Survey of Indoor Localization Systems and Technologies. IEEE Commun. Surv. Tutor. 2019, 21, 2568–2599. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.; Heurtefeux, K.; Mohamed, A.; Harras, K.A.; Hassan, M.M. Mobile Target Coverage and Tracking on Drone-Be-Gone UAV Cyber-Physical Testbed. IEEE Syst. J. 2018, 12, 3485–3496. [Google Scholar] [CrossRef]
- Miguel, A.F.; Chad, T.; Polina, P. Drone Deliveries Logistics, Efficiency, Safety and Last Mile Trade-offs. In Proceedings of the 7th International Conference on Information Systems, Logistics and Supply Chain, Lyon, France, 8–11 July 2018. [Google Scholar]
- Ahmadi, S. Chapter 4—System Operation and UE States. In LTE-Advanced; Ahmadi, S., Ed.; Academic Press: London, UK, 2014; pp. 153–225. [Google Scholar] [CrossRef]









| Parameter | Definition | Value |
|---|---|---|
| N | Total number of UAV states and their corresponding actions during the training | 2,000,000 |
| M | The trajectory memory size that defines the policy update interval | 10,240 |
| Learning rate of PPO that determines the gradient step size | 0.0003 | |
| Cut off threshold for difference between old and new PPO policies | 0.2 | |
| A variable used in the calculation of GAE | 0.9 | |
| Discount rate for the calculation of GAE | 0.9 | |
| Handover indicator function | 1 or 0 | |
| The handover weight value for calculating reward function | 0.1, 0.5, 0.9 | |
| Reward value obtained at step t | – | |
| UAV state at step t | {, , , } | |
| Action by PPO algorithm at step t | Next BS ID () | |
| , , | Position of UAV at step t | (0–6 km, 0–6 km, 0–0.3 km) |
| Direction of UAV movement at step t | vector representation | |
| UAV speed at step t | 54–72 km/h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, Y.; Raza, S.M.; Kim, M.; Choo, H. Proactive Handover Decision for UAVs with Deep Reinforcement Learning. Sensors 2022, 22, 1200. https://doi.org/10.3390/s22031200
Jang Y, Raza SM, Kim M, Choo H. Proactive Handover Decision for UAVs with Deep Reinforcement Learning. Sensors. 2022; 22(3):1200. https://doi.org/10.3390/s22031200
Chicago/Turabian StyleJang, Younghoon, Syed M. Raza, Moonseong Kim, and Hyunseung Choo. 2022. "Proactive Handover Decision for UAVs with Deep Reinforcement Learning" Sensors 22, no. 3: 1200. https://doi.org/10.3390/s22031200
APA StyleJang, Y., Raza, S. M., Kim, M., & Choo, H. (2022). Proactive Handover Decision for UAVs with Deep Reinforcement Learning. Sensors, 22(3), 1200. https://doi.org/10.3390/s22031200