4.1. System Model
As shown in
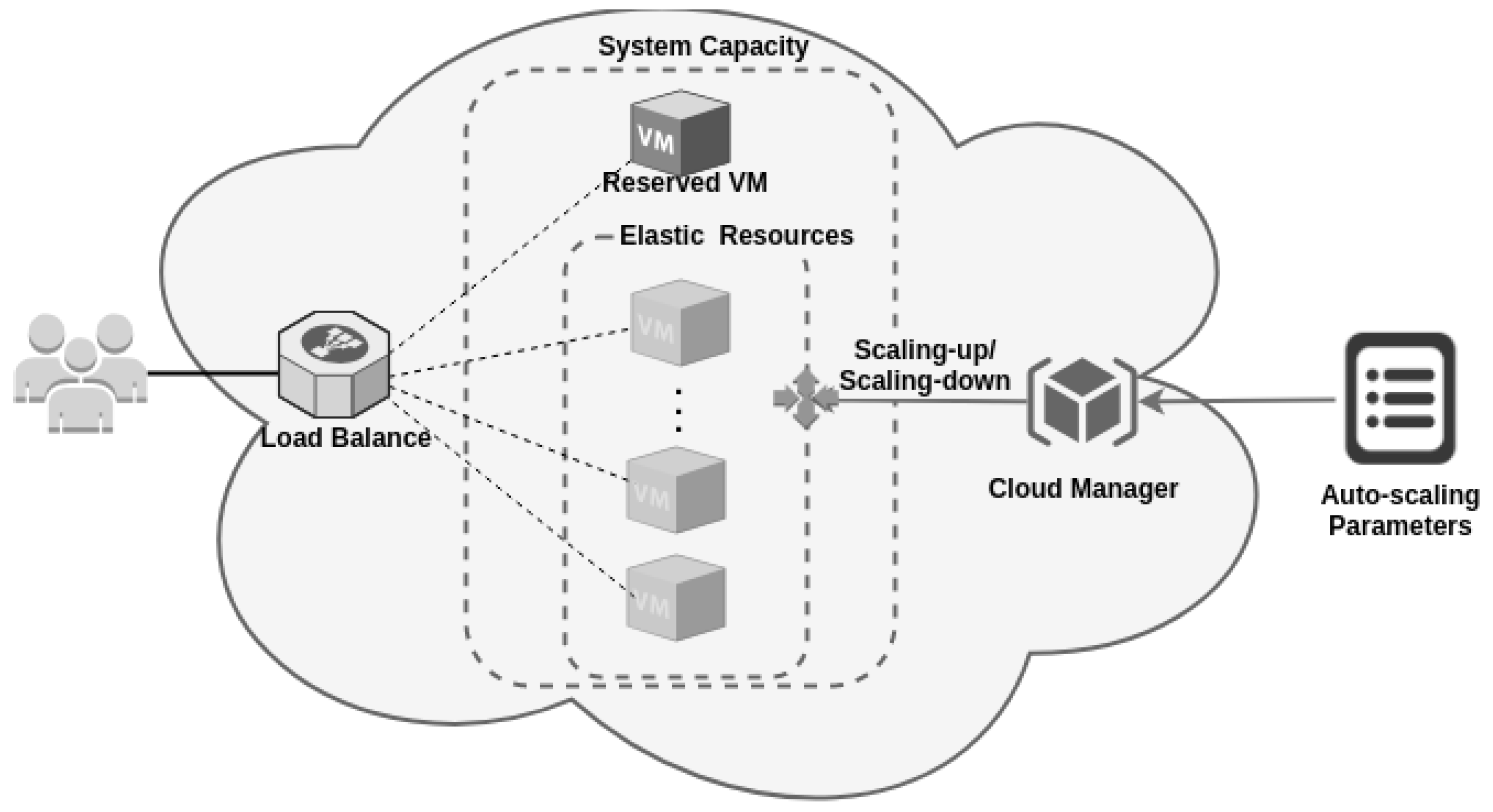
Section 3, proper configuration of public cloud-based systems requires fine-tuning of various configuration parameters at the service provider. The modeling of this type of system must take all these parameters into account. Some of the parameters are directly related to cloud elasticity, such as scaling up or scaling down threshold or number of VMs allocated to each threshold. Other parameters are derived from the contract with the provider.
The choice of the previous configurations also has effects on the modeling of the system. Setting the VM type changes the expected average times for processing a request and affects the time to instantiate a new VM dynamically. Processing time is also affected by the number of concurrent jobs running on the system. The model in
Figure 2 took all these factors into account. The description of the places and transitions of the model can be seen in
Table 2. In comparison, the attributes of the immediate and timed transitions can be seen in
Table 3.
Table 2 presents the description of places and transitions of the system configuration. In this table are both the values directly defined by the user, such as the THR_SCALING_UP, and the time values that are a consequence of choosing the VM type, which is SERVICE_TIME and INSTANTIATION_TIME.
Table 4 has model variables that represent system characteristics such as workload (represented by the ARRIVAL variable) and the number of jobs waiting in the queue. Additionally, the characteristics of the immediate and timed transitions are listed in
Table 3.
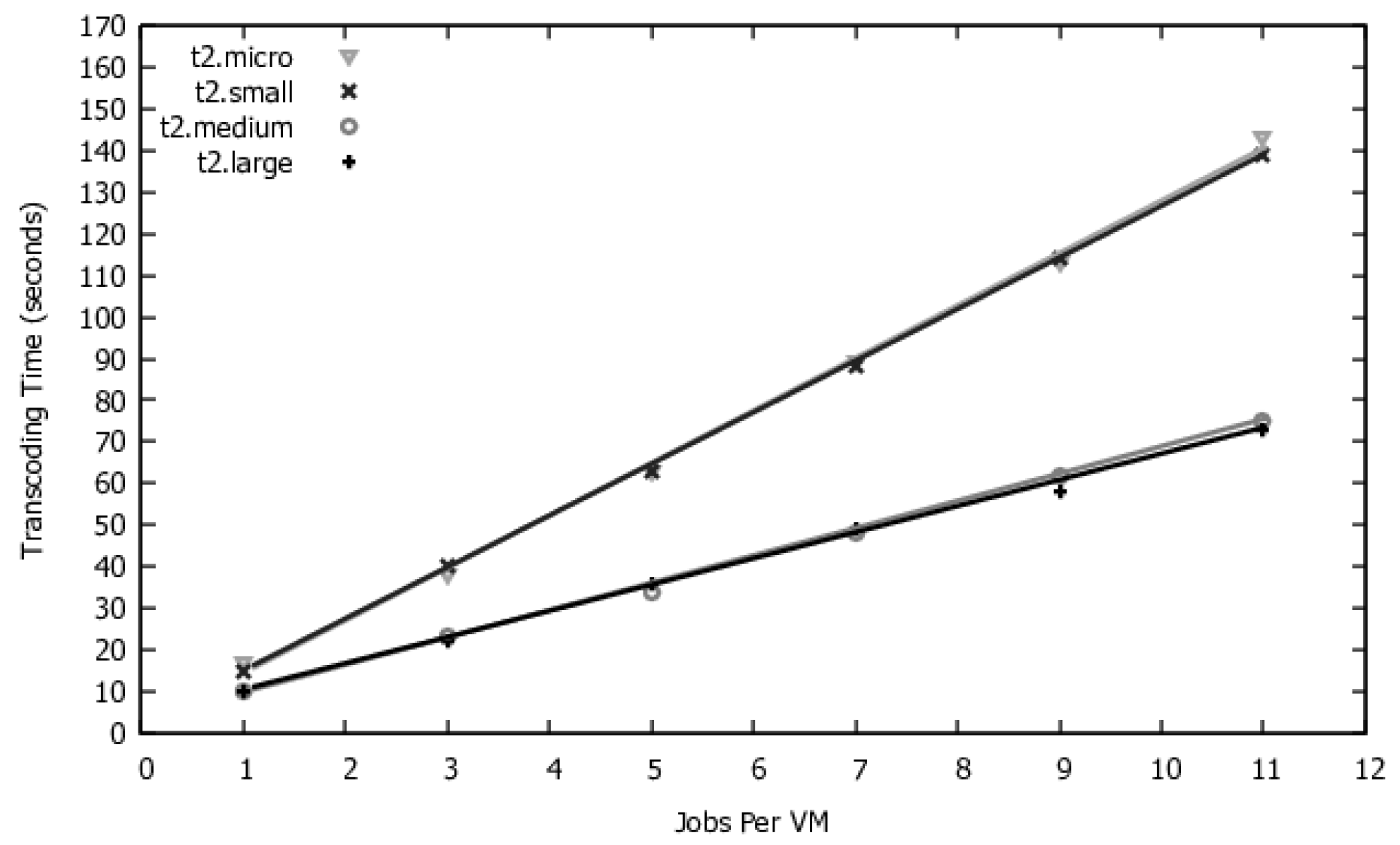
The values of the timed transitions must be obtained for each VM type. The average processing time and instantiation time must be obtained for each type of application by the system administrator and are obtained through controlled measurements of requests in the system.
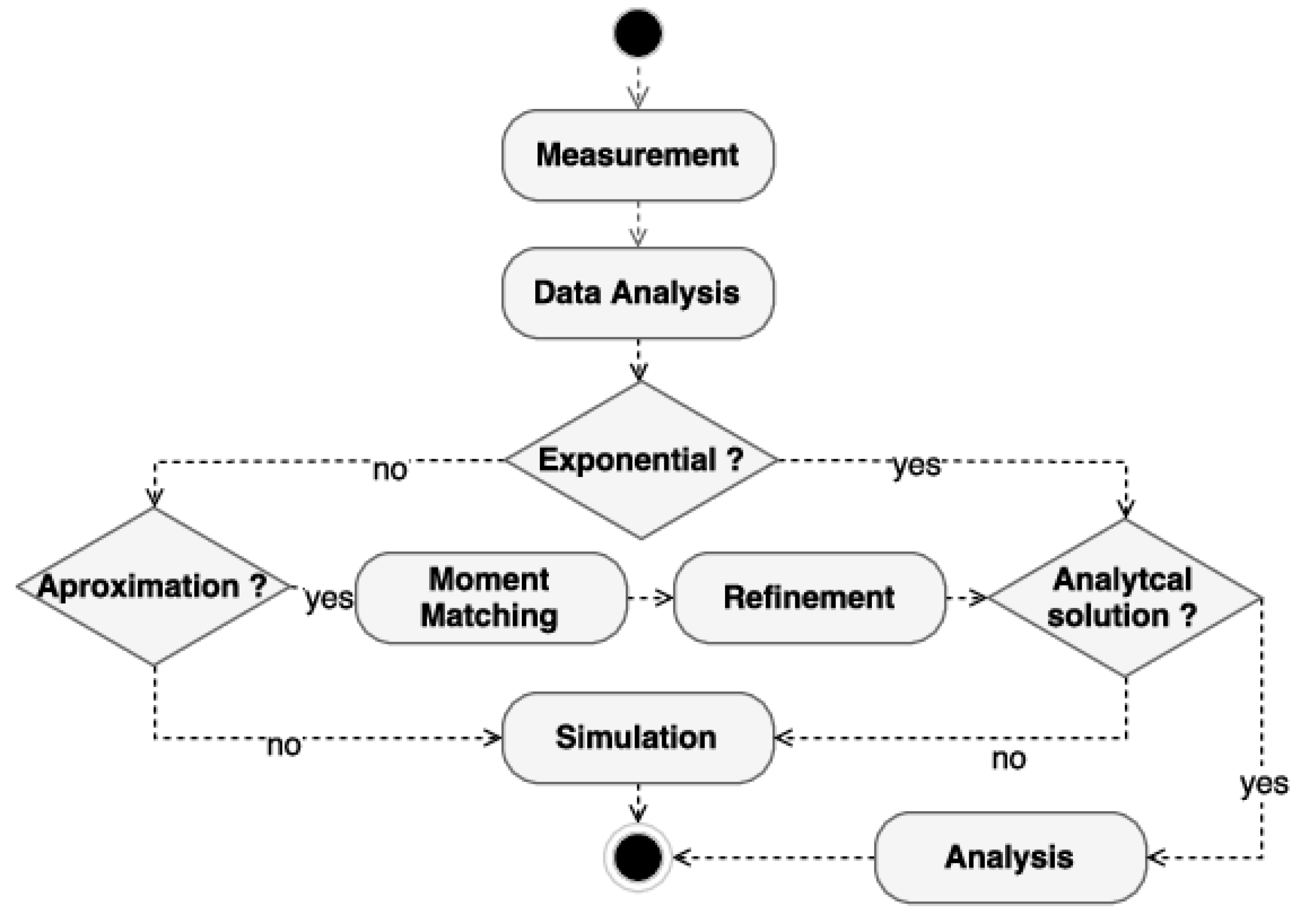
The mean time values obtained must be evaluated as to the type of distribution, which will be used to choose the model evaluation method. A methodology for identifying the type of assessment can be seen in
Figure 3. The data collected for these average times must be submitted to data analysis to identify the possibility of using analytical solutions or if the model will only be run by simulation. The model can be run looking for analytical solutions if the model has exponentially distributed time transitions and does not suffer from a state-space explosion, which can occur with large systems with many VMs or many jobs per VM. The state-space explosion can generate a model with high execution time, making its use unfeasible for optimization, which will need to run the model with different values countless times.
If it is not exponential, the feasibility of using moment matching to use sets of exponentials to represent another distribution can be verified [
22]. The sub-model that represents the distribution must refine the original model and generate an alternative model composed only of exponential distributions. This alternative must also be the target of verifying the feasibility of use regarding the explosion of state space. Suppose it is not possible to evaluate the model composed of exponential transitions. In that case, it is still possible to run the model by simulation, which, although does not present punctual results as the numerical analysis, presents results within good enough confidence intervals for practical applications. Therefore, modeling the model with SPN can be suitable for several different configurations, and the chosen evaluation method should be carefully checked.
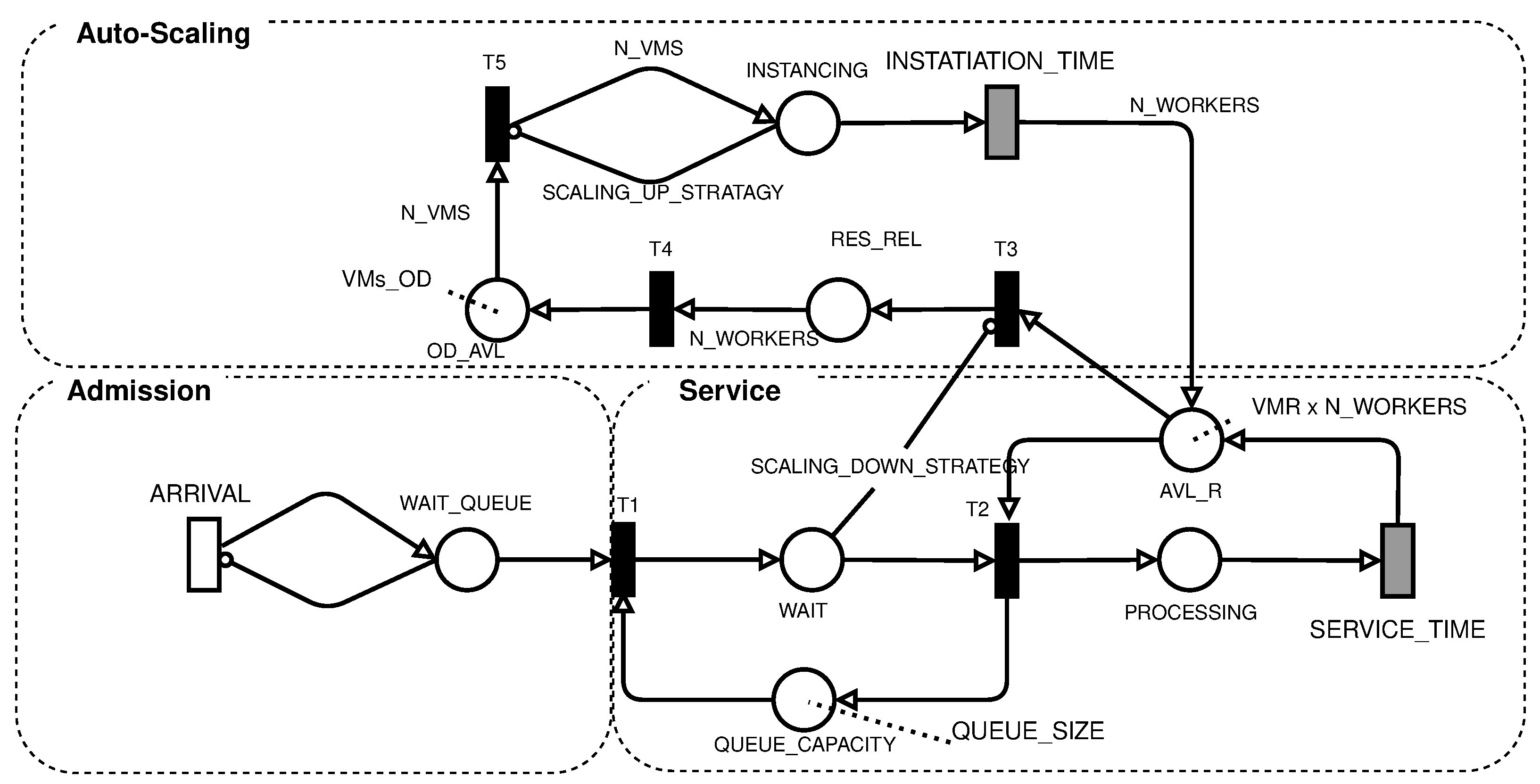
The proposed SPN model of cloud-based systems with auto-scaling is shown in
Figure 2, being composed of three subnetworks: admission, service, and auto-scaling. The admission subnet generates the workload and represents the time between requests. It is composed of an ARRIVAL transition, which is a single server transition and has the expected mean arrival time value, and the
WAIT_QUEUE place, which represents a request that is ready to enter the system.
The service subnet is responsible for receiving the requests from the admission subnet and forwarding the request to an available VM that will carry out the processing. This subnet starts with firing the T1 transition, which occurs whenever there is capacity in the QUEUE_CAPACITY load balancer. The FCFS load balancer starts with the number of tokens equal to QUEUE_SIZE, which is the maximum capacity of the system. This capacity is reduced as new requests enter the system and are waiting in the WAIT place. Requests in WAIT are used to check the system’s occupancy level, and you can increase or decrease the number of VMs by scaling up AND scaling down strategies, respectively.
The T2 transition fires whenever there are requests waiting and computational resources available; that is, there are tokens in AVL_R. The initial number of tokens in ACL_R is equal to the amount of reserved VMs multiplied by the amount of concurrent work that each of these virtual machines can perform (VMR x N_WORKERS). After firing T2, the request will be processed in place PROCESSING. The number of tokens in PROCESSING represents the number of requests being processed simultaneously. The processing time is given by the SERVICE_TIME transition, which represents the processing time allocated to the request.
The SERVICE_TIME timed transition obeys infinite server semantics. Each request is processed independently of the other. The time required to process a request depends on the amount of concurrent work. Usually, processing simultaneous requests in a single VM can take more time per request than just one request. Therefore, the time used in this request should be measured under similar workload conditions.
The number of tokens in AVL_R and PROCESSING is changed by the auto-scaling subnet, never being less than the initial value. The scaling up is performed whenever the SCALING_UP_STRATAGY condition is satisfied. The change in the model is performed by firing the T5 transition. The amount of VMs added to each scaling up of the threshold of the condition is given by the variable N_VMS and is conditioned by the capacity of available resources in place OD_AVL. The capacity in OD_AVL in public clouds can be considered unlimited due to the large capacity of large cloud providers, whereas in private clouds, the capacity depends on the installed infrastructure.
The firing of
T5 depends on the
SCALING_UP_STRATAGY (
1) condition, which defines the multiplicity of the inhibiting arc. This condition enables the T5 transition whenever the number of tokens in the INSTANCING place is less than the value resulting from this condition. The condition value (
1) checks if the number of requests waiting (
WAIT) is greater than the threshold
THR_SCALING_UP multiplied by the number of VMs in the instantiation process and those already running (
INSTANCING,
AVL_R, and
PROCESSING). If this condition is true, the arc multiplicity will become the number of VMs in instantiation added to 1, enabling
T5. On the other hand, the multiplicity of the inhibiting arc is zero, disabling the
T5 transition.
The number of VMs to be instantiated is equal to the N_VMS parameter; these tokens are deposited in the INSTANCING place and they wait for the time given by the infinite server INSTATIATION_TIME transition. This time depends on the type of VM used and also on the cloud environment used. After firing INSTATIATION_TIME for each VM, the N_WORKERS capacity is deposited in ACL_R, increasing the number of resources available to process the requests. It is important to note that the scaling up mechanism is dependent on the THR_SCALING_UP variable, which is defined by the user in both the cloud management system and the model.
The mechanism for destroying VMs on demand is controlled by condition (
2) in the
SCALING_DOWN_STRATEGY arc. It changes the enabling of the
T3 transition. This mechanism aims to save resources when the current amount of VMs on demand is no longer sufficient. Condition (
2) evaluates if there was the instantiation of VMs on demand. If any VMs were instantiated, then the arc will compare the number of requests in WAIT with the total running capacity,
ACL_R,
PROCESSING, and
RELEASE_RESOURCE multiplied by the value of
THR_SCALING_DOWN. If
T3 fires, it will gather the resources of the VM on-demand in
RELEASE_RESOURCE, which represents the wait for the completion of the work being carried out by the VM. When the scaling down on-demand VM ends its processes,
T4 is enabled, which returns the on-demand resources leased from the cloud.
4.2. Model Metrics
The purpose of the model is to generate metrics of interest that allow evaluating the performance and cost of a certain configuration of a cloud system. We generate metrics for throughput, average response time, and cost. The throughput is calculated by the expected number of tokens in
PROCESSING multiplied by the service time rate, as presented in Equation (
3). For an Erlang distribution, throughput can be calculated as presented in Equation (
4).
The average response time of the system can be calculated using Little’s law. This metric takes into account the number of jobs in the system and the inter-job arrival rate (
ARRIVAL). For this model, the application of Little’s law results in Equation (
5), in which the effective arrival rate was considered, that is, disregarding the fraction of the arrival rate that may have been discarded.
Finally, we present the infrastructure cost, which depends on the used portion of on-demand VMs used (ON_DEMAND_USE) in Equation (
6). The sum of reserved and on-demand VMs can be obtained by Equation (
7). This equation considers the cost over some time T (in years). The annual cost of reserved and on-demand VMs are, respectively,
and
.
Table 5 presents the model metrics as they should be used in the Mercury tool.
The model and some metrics presented in this section are adaptations of those found in our previous work [
43]. In this work, we use the model for use in systems with response times that are not exclusively exponential. We adopt Erlang time distribution in our use case and present Equation (
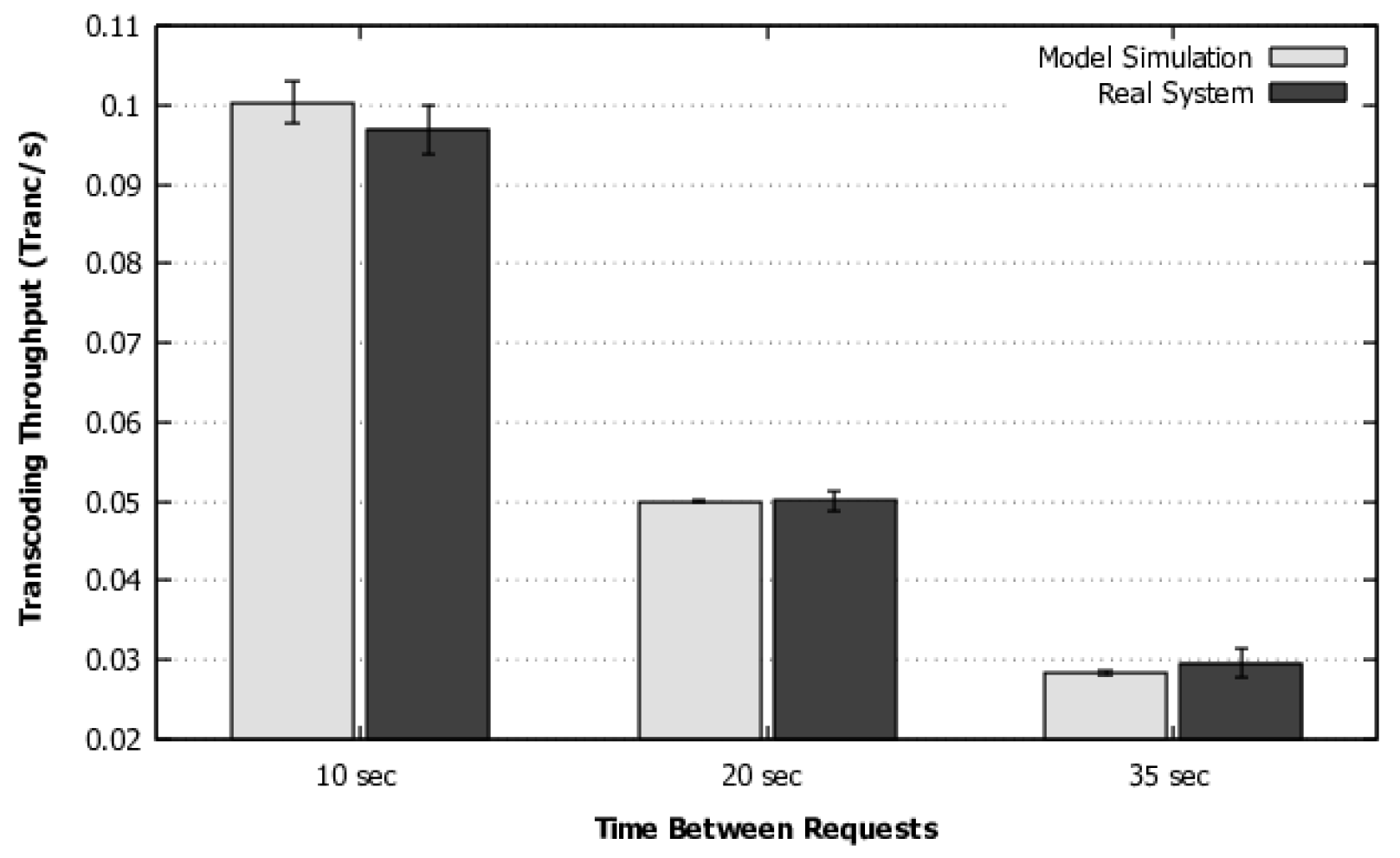
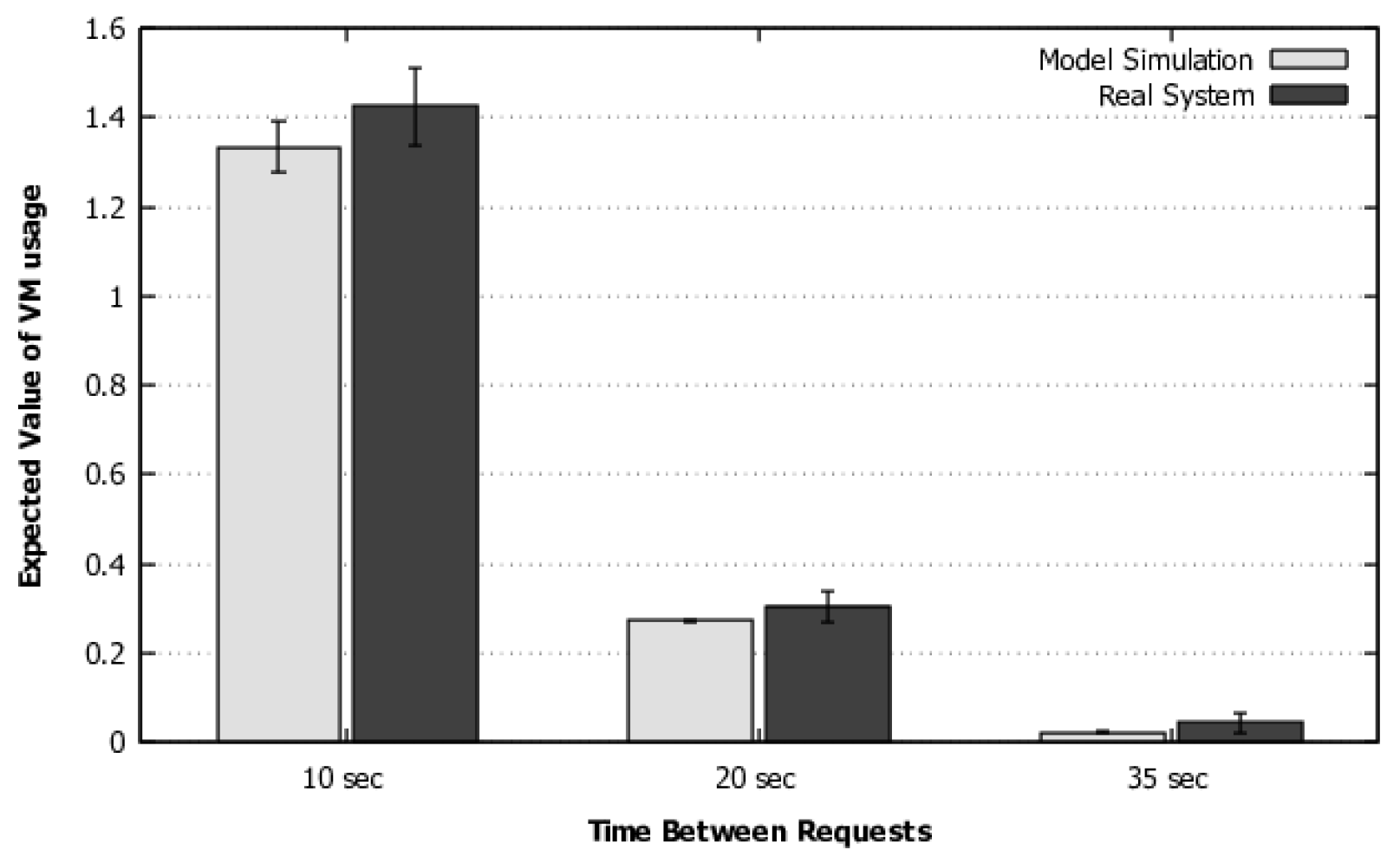
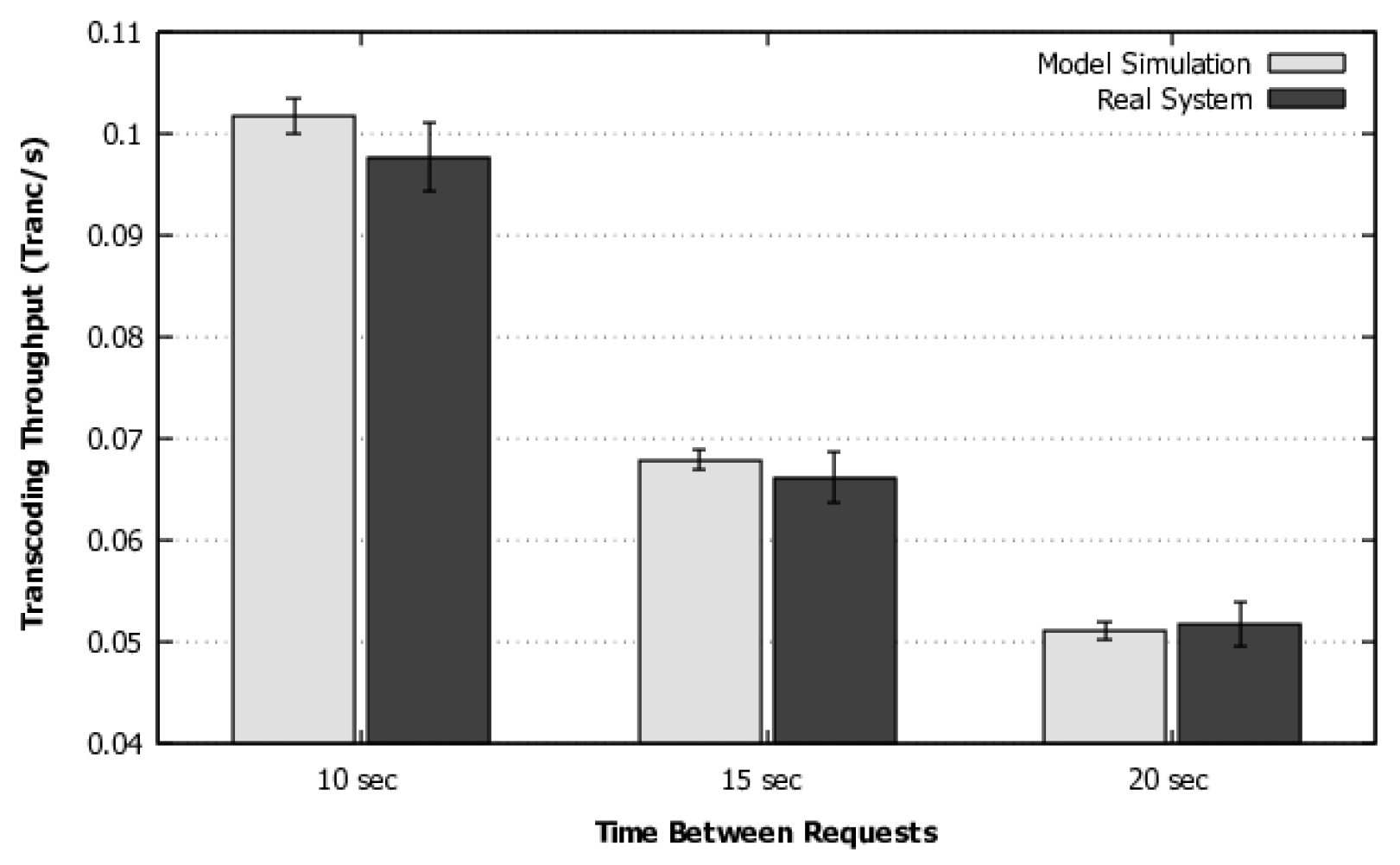
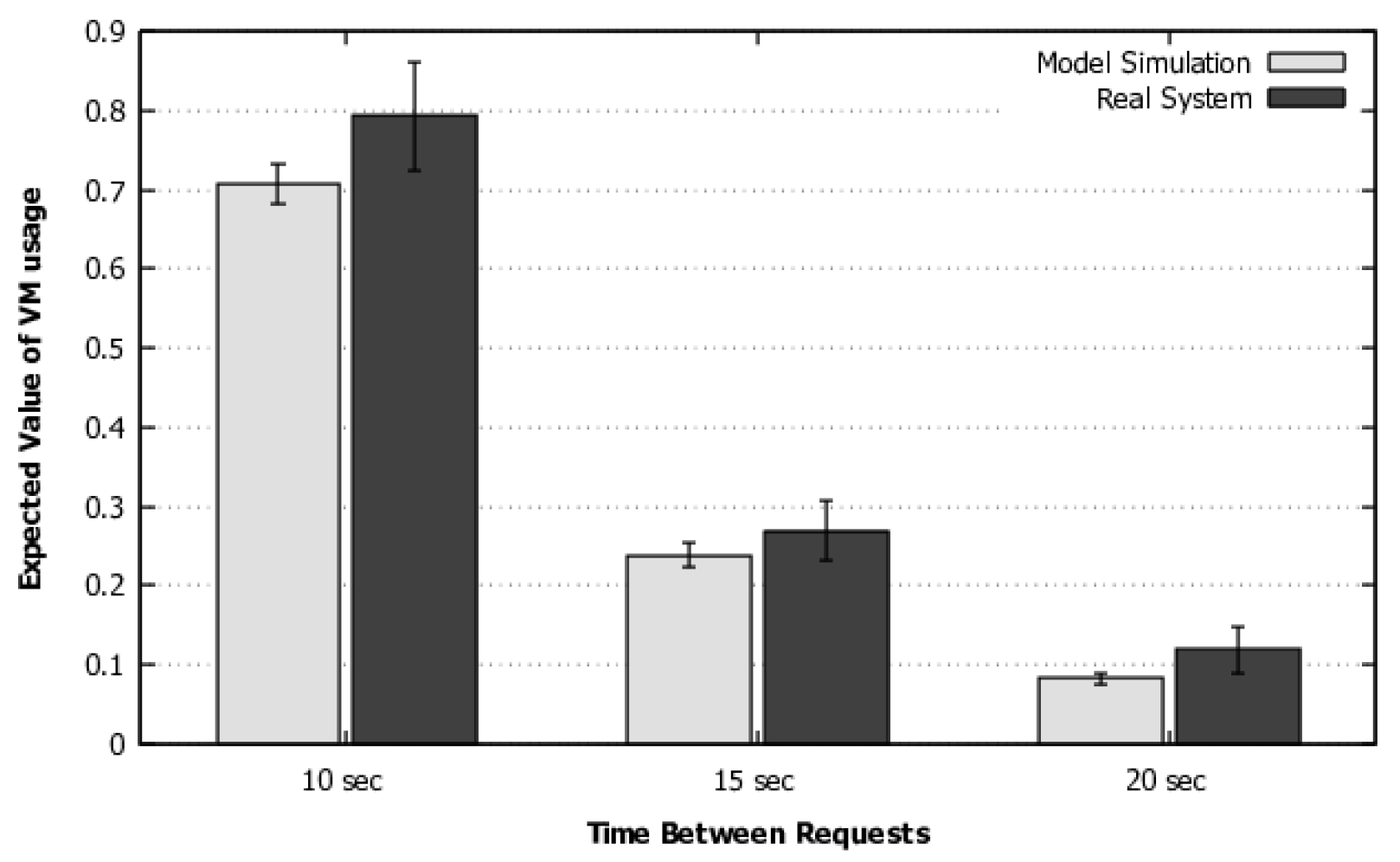
4) to calculate the flow rate in systems with this distribution. In addition, we have added a methodology and a flowchart to guide the use of the model for larger systems with multiple requests or a large number of resources acting simultaneously. This methodology also contemplates the model execution and customization options with phase-type distributions when the transition times are not exponentially distributed. A more sophisticated validation was also performed, which includes a more complex workload and simulation, as will be discussed in detail in
Section 5.1.
The model and metrics presented in this section allow the systems manager to assess the impact on the performance and cost of a system hosted in the cloud from the variation of elasticity configuration parameters, contracts, and types of VM used.
4.3. Optimization Algorithm
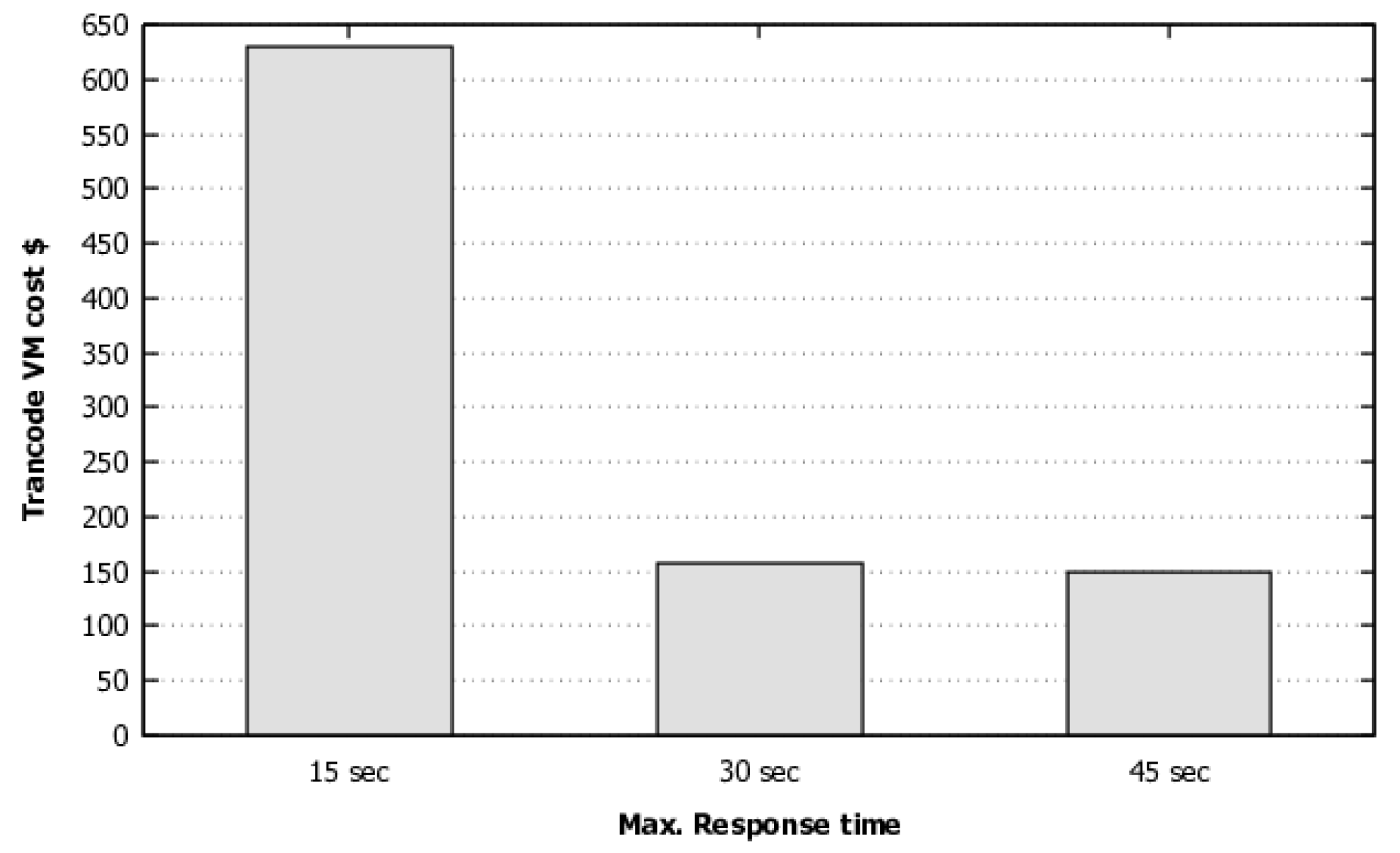
The models have several parameters and possibilities of combinations of parameter values. These combinations present different values for the metrics of the model. The model explores the space solutions through the individual variation of each value of the parameters. Searching for an optimized configuration is an exhaustive task and, in many cases, impractical. Therefore, we use optimization mechanisms. This section explores the space of possible solutions for the public and private cloud systems. We seek to identify the values configured in each parameter to achieve a configuration that respects the SLA and optimizes the cost. This process uses the GRASP optimization algorithm, which was adapted to search for the model’s variables and adopt the cost metric of the model as the objective function.
The optimization algorithm used receives as input the model, the parameters that must be configured, the ranges of variation of each parameter, the constraints of performance metrics (throughput and average minimum response time), the workload that the system is subjected to, and the values associated with the chosen cloud. After that, the algorithm generates solutions from the set of possibilities that optimize the cost.
This work adopts GRASP as the metaheuristic to search for good-quality solutions. This metaheuristic was presented in 1989 in [
50]. GRASP is an iterative, semi-greedy metaheuristic also possessing randomness. The GRASP implementation was developed in three algorithms. Algorithm 1 is a generic high-level representation of GRASP that follows the strategy defined in [
50]. Algorithms 2 and 3 are applications of this work to implement cost optimization of the SPN model previously presented.
GRASP creates a process capable of escaping from local minimum and performing a robust search in the solution space [
51]. This type of optimization method produces good-quality solutions for difficult combinatorial optimization problems.
In GRASP, each iteration consists of two phases: the construction and the local search. The construction creates a solution at random; if the solution is not acceptable, a repair may be applied. During the local search, the neighborhood of the generated solution will be investigated until finding a local minimum.
The high-level GRASP is presented in pseudocode in Algorithm 1. This algorithm receives, as parameters, the number of iterations (
) and the seed (
) for random generation. Furthermore, the first solution is defined as infinite at the algorithm initialization, ensuring that the first solution replaces the first one. Initially, random greedy solutions are constructed and are refined by the local search. We want, in this study, to minimize the cost; thus, if the found solution has the lowest cost than the previous lowest
, it will be replaced in line 5 of Algorithm [
50,
52].
| Algorithm 1: Greedy randomized adaptive search procedure—GRASP. |
![Sensors 22 01221 i001]() |
The first phase consists of random construction of greedy feasible solutions (line 3), where every possible element belonging to each parameter will be evaluated from the model with an initial configuration. The best elements concerning cost will be inserted in the restricted candidates’ list (RCL). Later, the RCL elements will be randomly chosen to make a solution. According to the problem, the choice of RCL elements is defined by the greediness parameter, which is set to a value between 0 and 1. The choice of value 1 means “pure greedy” algorithm because the algorithm will always choose the best element of the RCL. On the other hand, 0 means “purely random”. In our study, the greediness parameter is 0.8, which allows a random element to be chosen from the 20% top-tier elements at the RCL [
50,
52].
The solution generated in the construction will not necessarily be optimal, even locally. The local search (line 4) phase searches for local minimum interactively. It successively changes the previous solution for a lower cost local. The speed and effectiveness of local search depend on several aspects, such as the nature of the problem, the neighborhood structure, and the search technique. This phase can greatly benefit from the quality of the solution found in the construction phase [
51].
Several techniques are used in the local search, such as the variable neighborhood search (VNS) and its variation (VND), which have been applied in several studies in the literature [
51,
52,
53,
54]. VNS is based on the principle of systematically exploring multiple neighborhoods combined with a disturbance movement (known as
shaking) to escape from great locations. VND is a variation of VNS, in which the shaking phase is excluded and is usually deterministic. Both approaches take advantage of the search in more neighborhoods up to a maximum number of searches
k. We use VND in local searches in this work.
We use Algorithm 1 for optimization; it has two phases, construction and local search. The construction phase should generate a good semi-greasy solution, which, applied to the model, selects a value within a finite range of elements for each parameter. These elements form a valid configuration that meets the SLA for which it minimizes the cost and respects the constraints.
Our application of the construction phase in the model can be seen in Algorithm 2. It receives as input the stochastic model, the parameters with possible internal values (example: number of reserved VMs, which can vary from 1 to 30; or VM types that can be t2.micro, t2.large, each with its service and instantiation time for the load of expected work, etc.),
that will determine the size of the candidate restricted list (RCL),
which will be used to increase the variability of solutions [
55], the expected workload for the system, and the SLA of mean response time and throughput.
| Algorithm 2: Greedy randomized construction for SPN model. |
![Sensors 22 01221 i002]() |
Line 2 generates a candidate solution from the random choice of all possible values for each parameter. The semi-greedy method will select the parameters from line 5 to line 11; the variable
i will define which parameter will be chosen in the iteration. Line 7 will randomly select part of the possible values for the
i parameter; if
is 1, all possible values will be chosen, and if it is 0.5, half of the values, with a minimum of 1. This strategy increases the variability of the solutions generated in the construction phase [
55].
must also select only the possible values for the parameter; in the case of the public cloud, the value of the threshold of destruction must not be greater than or equal to the instantiation threshold.
After obtaining the values of the
i parameter to be tested, line 8 will replace each in the candidate solution and evaluate the model, obtaining the cost variation from each value. Next, the parameters are ordered from the lowest to the greater incremental cost and they return a list with the parameters ordered by the cost variation. It is important to note that the model evaluation is performed through the Mercury API call [
56] and the solution given by simulation.
The ramdomRCL function on line 9 receives the list with the values and costs sorted from lowest to highest and then selects a value randomly within the candidate restricted list (RCL). The RCL is composed of the best in the list. Its size is given by , where “1” denotes “for all elements” and “0” for “only 1”. It is important to note that this is the main random component of GRASP to avoid local minimum. The selected element of the RCL will be used as the value for the i parameter of the solution (line 10).
This process will be repeated for all parameters until the solution is composed. The results are inserted into the model and simulated by the Mercury API, where the metrics throughput, average response time, and cost will be generated. The feasibility of the configuration found in the previous steps is verified by the function of line 13, in which it is verified if the presented solution presents metrics to the minimum required SLA. If not, the initial solution is discarded, and another one will be generated.
Local search VND will use the local search and will change the search center to each iteration. This proposal aims to improve the quality of solutions while changing a point with lower local costs. Algorithm 3 presents this strategy applied to the model. It receives the model; the solution of the construction phase; , which will define the range of variation; and the maximum number of searches within the local search.
Lines 1 and 2 start the variables used in the model in the same way as the simple local search. However, this algorithm’s maximum execution will not be determined by the maximum number of iterations other than the simple local search. Instead, the maximum amount of execution is determined by the maximum amount of no improvements, given by the variable . The iteration control variable i will be restarted with each improvement and also restarting a new neighborhood.
Line 4 will perform a simple local search from the neighborhood of
; if it finds a viable new solution that minimizes the solution (condition of line 5), the new solution will be the minimum so that the local search neighborhood will be the new solution and will also restart the iteration variable (line 7). If the solution does not improve, a new iteration will be performed and a new local search will be performed. Note that the variability of solutions that do not find improvement is due to the random aspect of the
function. Another important aspect is the successive changes of neighborhoods in the conditions of improvement.
| Algorithm 3: Local search VND. |
![Sensors 22 01221 i003]() |
The presented algorithms allow the configuration of the number of iterations parameters in general (Algorithm 1) and in the local search (Algorithm 3). This parameter will define the quality of the solution found and the time to find this value. The more iterations, the longer it will take to execute and will tend to present solutions with lower cost. It is important to note that the execution of this optimization should only be performed with a change in the SLA or system characteristics, such as response time or average VM instantiation time.



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}