
Design of a Low-Power Embedded System Based on a SoC-FPGA and the Honeybee Search Algorithm for Real-Time Video Tracking

 , , ,
, , ,  ,
,  , , and
, , and
Abstract
:1. Introduction
1.1. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Year | Meta-Heuristic | Heterogeneous Platform | Application |
|---|---|---|---|---|
| Palermo et al. [40] | 2008 | Discrete PSO | SoC-FPGA | Multi-objective Design, space exploration |
| Tsai et al. [41] | 2010 | DNA algorithm | SoC-FPGA | Fire extinguishing |
| Morsi et al. [16] | 2013 | PSO | FPGA | Structural similarity index for video tracking |
| Rodriguez and Moreno [42] | 2015 | GA (genetic algorithm) | FPGA | Motion estimation with particle filter |
| Elkhani et al. [43] | 2018 | Multi-objective binary PSO | CPU-GPU | Feature selection and classification |
| Perez-Cham et al. [34] | 2020 | HSA | CPU-GPU | ZNCC for video tracking |
| Nogueira and Barboza [17] | 2020 | GRASP (greedy randomized adaptive search procedure) | SoC-FPGA, CPU-GPU | Continuous optimization problems |
1.2. Organization
2. Materials and Methods
2.1. Programmable Fabric
2.2. Soft Intellectual Property Cores
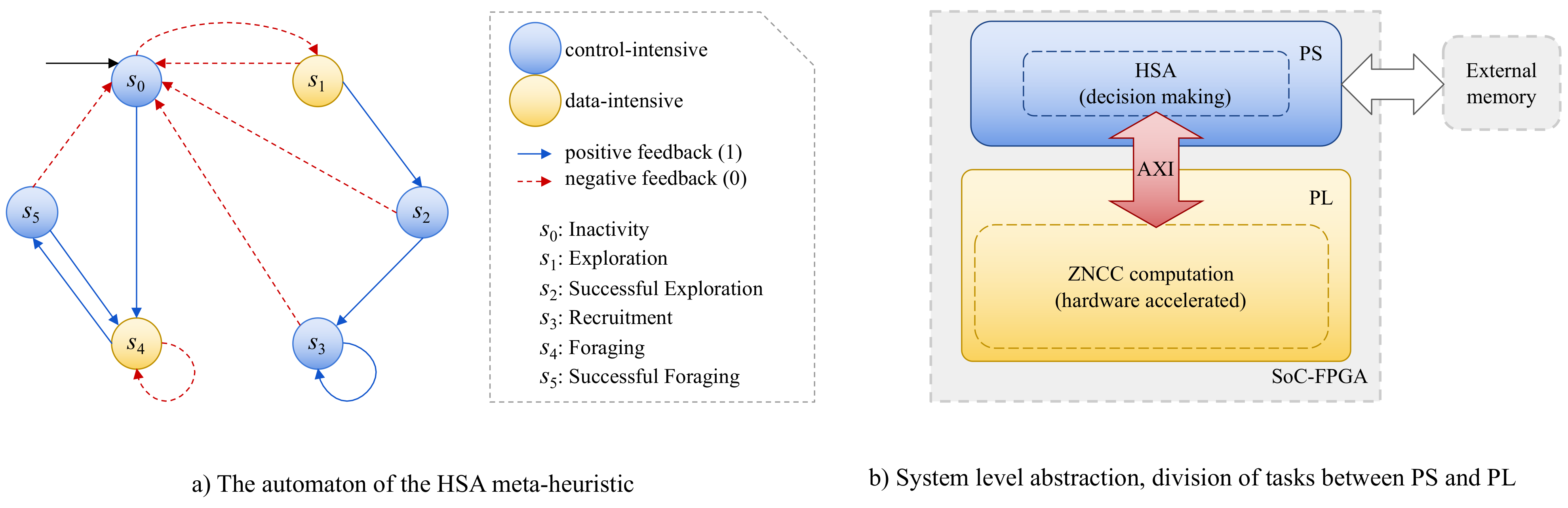
2.3. The Honeybee Search Algorithm Meta-Heuristic
2.3.1. The Evolution Strategy of HSA
2.3.2. Polynomial Mutation
2.3.3. Simulated Binary Crossover
2.3.4. Recruitment Distribution
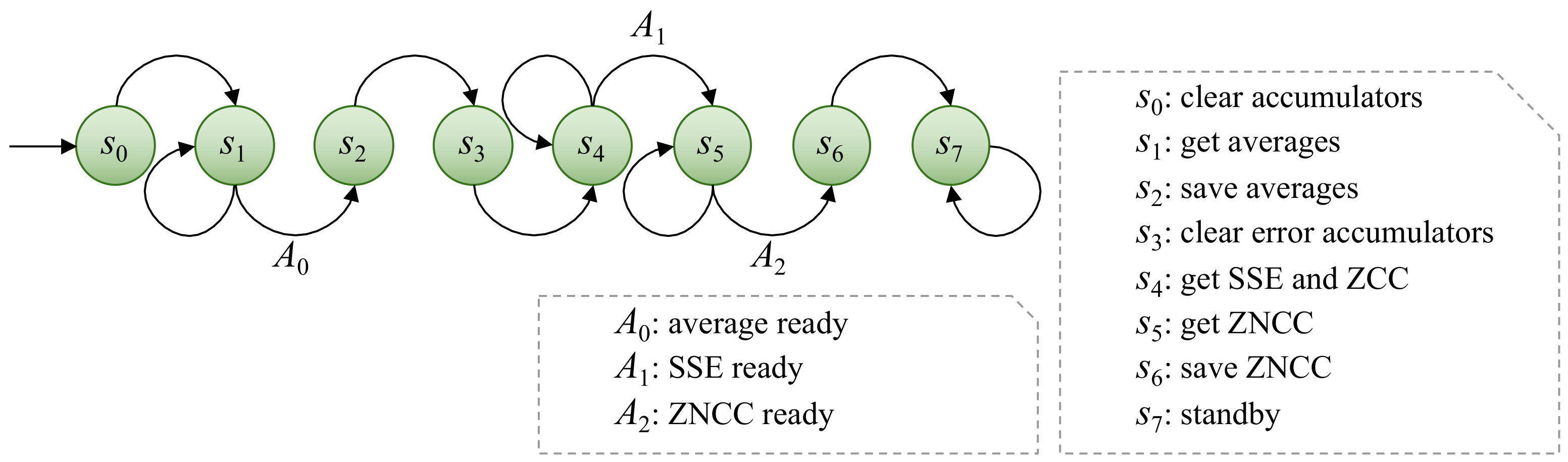
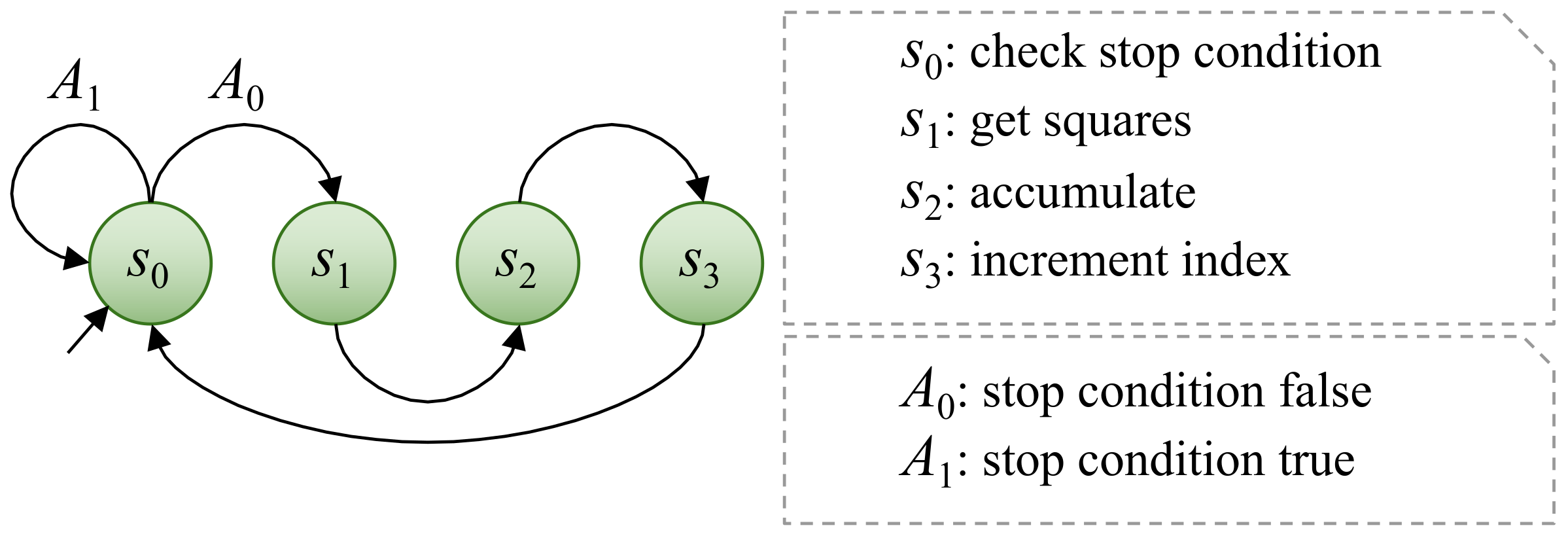
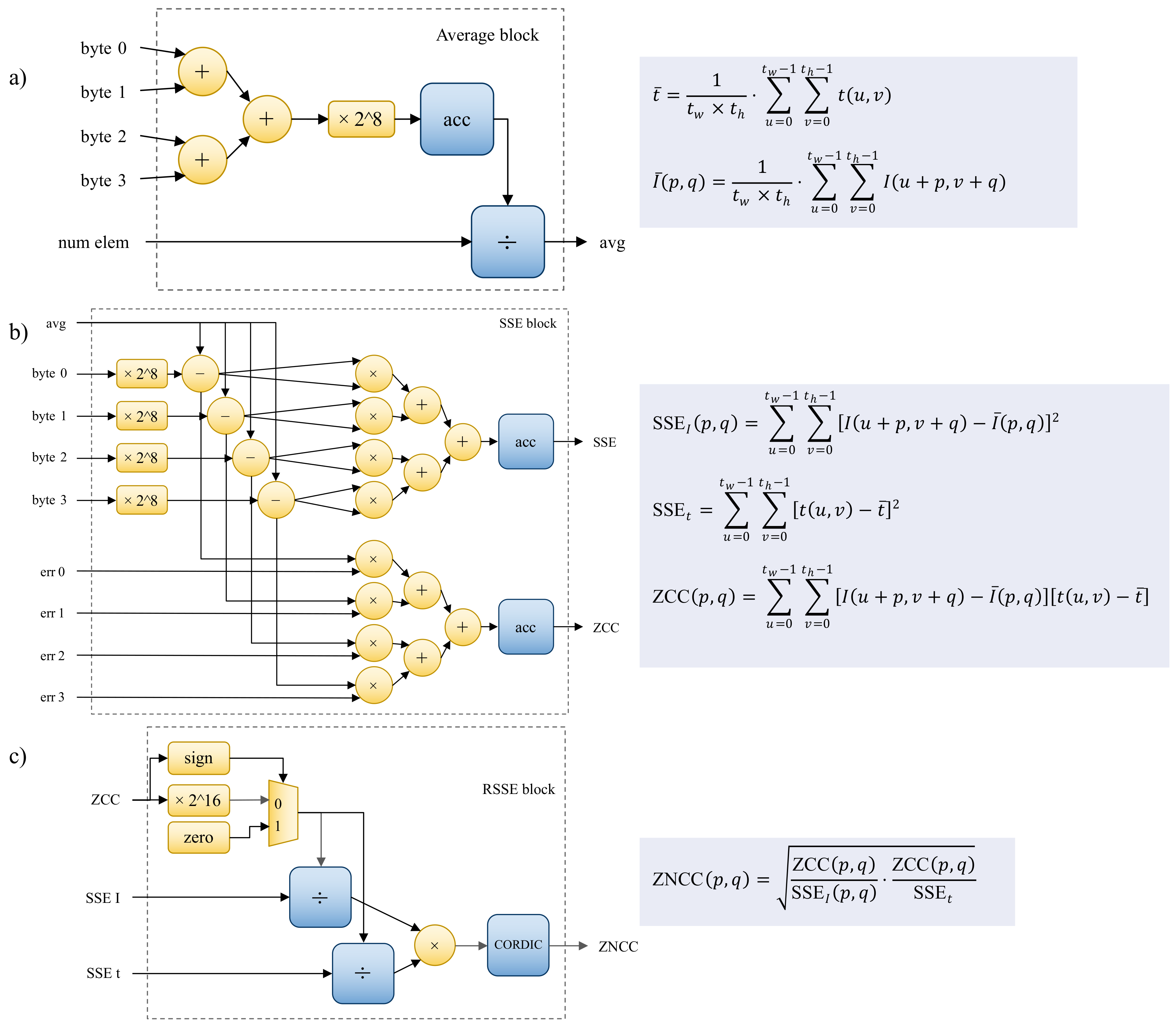
2.3.5. Zero-Mean Normalized Cross-Correlation as Fitness Function
2.4. Evaluation with the Amsterdam Library of Ordinary Videos
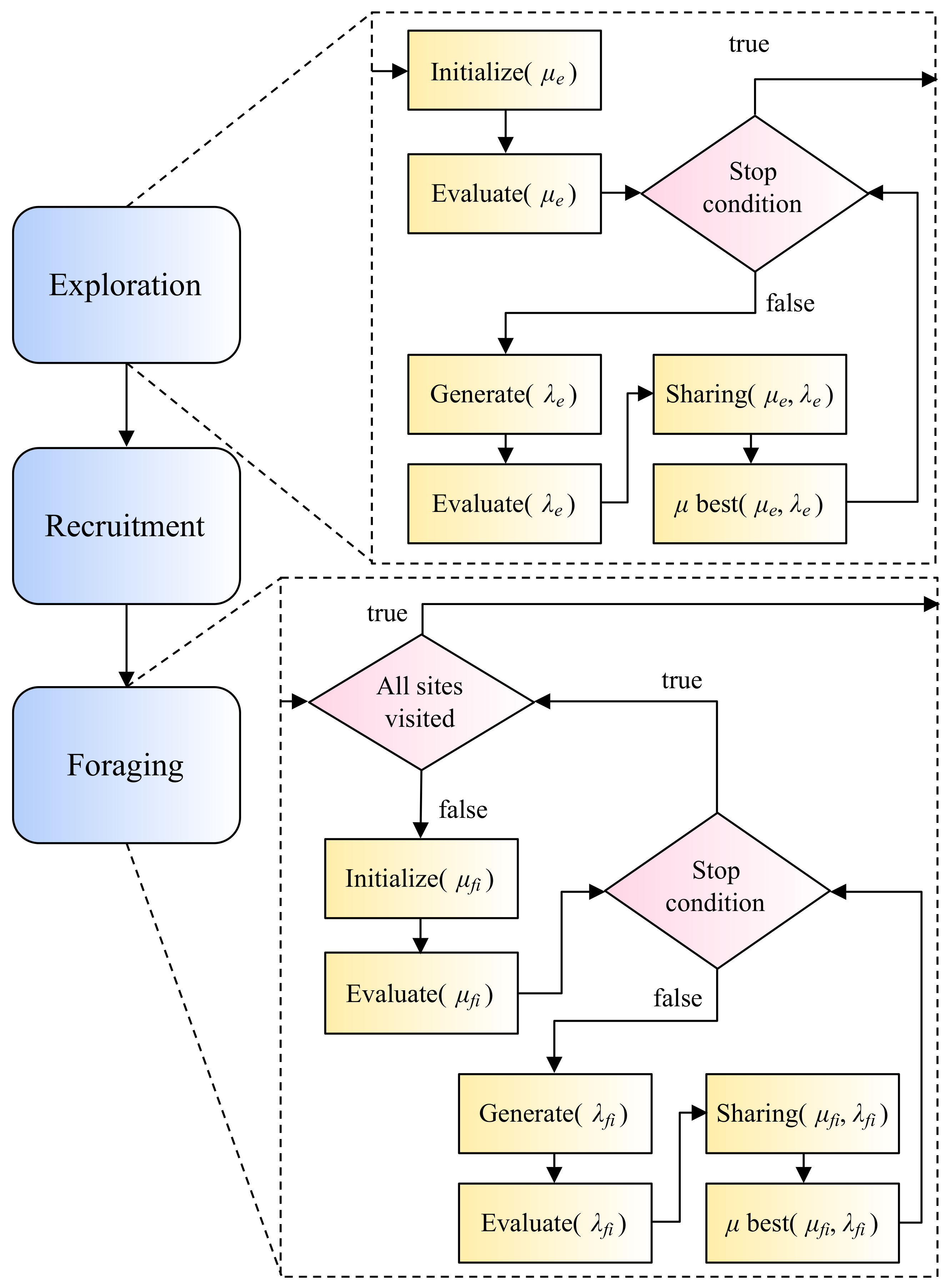
2.5. Proposed Workflow
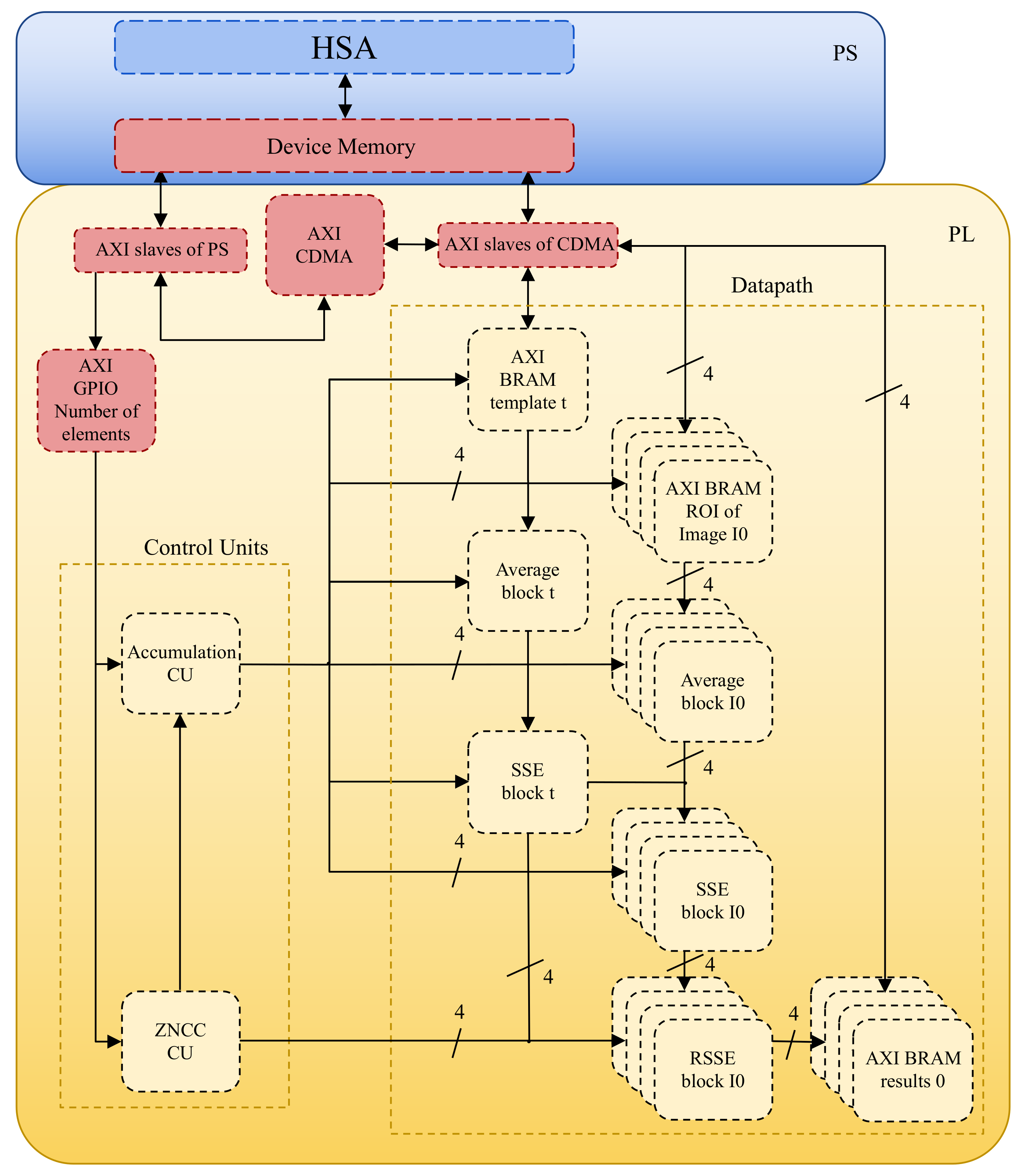
2.6. Processing System and AXI Communication
3. Results
3.1. Proposed Embedded System Design
3.2. Datapath
3.2.1. Control Units
3.2.2. System Overview
3.3. Experiments
3.3.1. Calibration Test with a Static Image
3.3.2. Testing the SoC-FPGA ZNCC-Based System with One Video Using Exhaustive Search
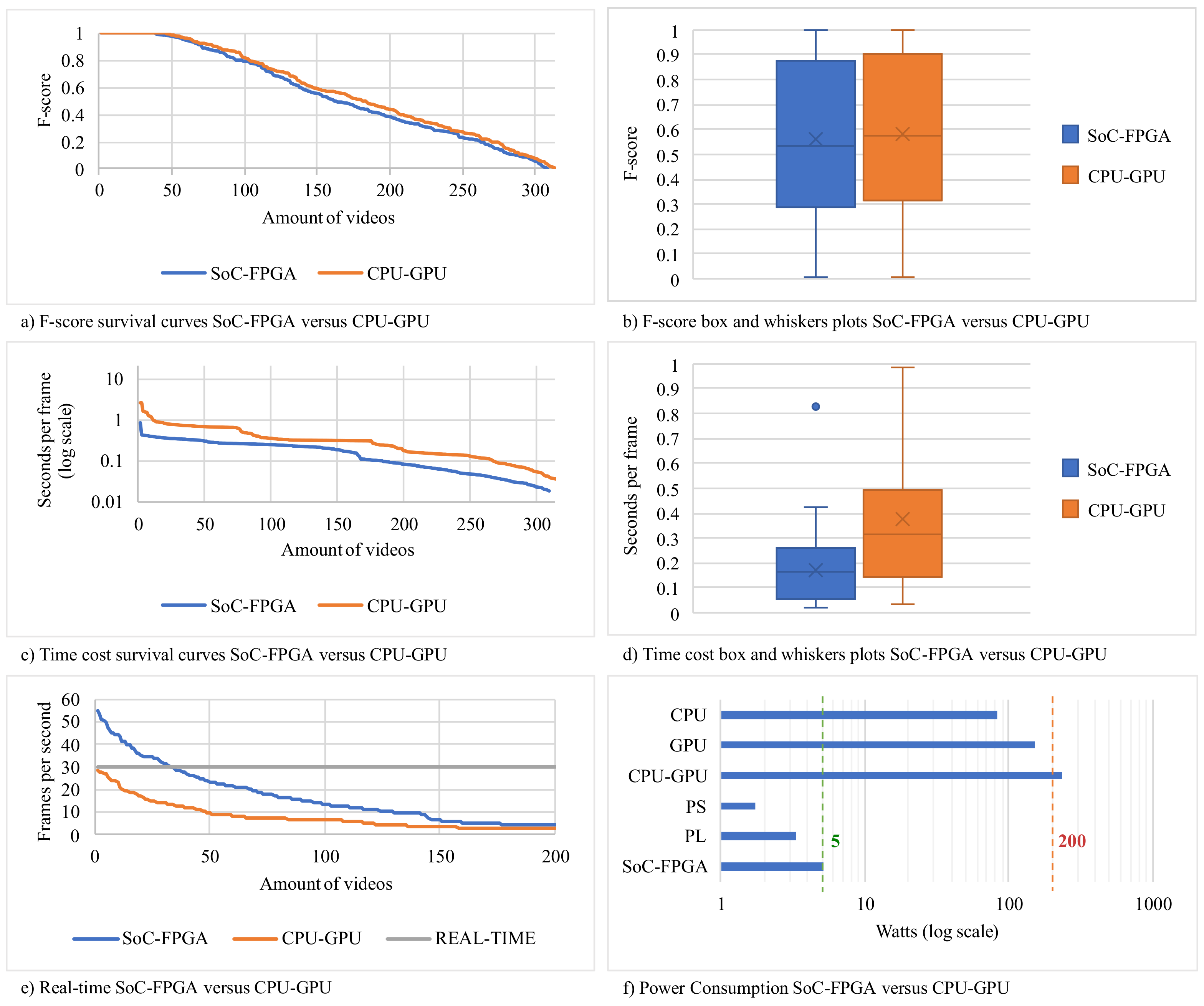
3.3.3. CPU-GPU versus SoC-FPGA Using HSA
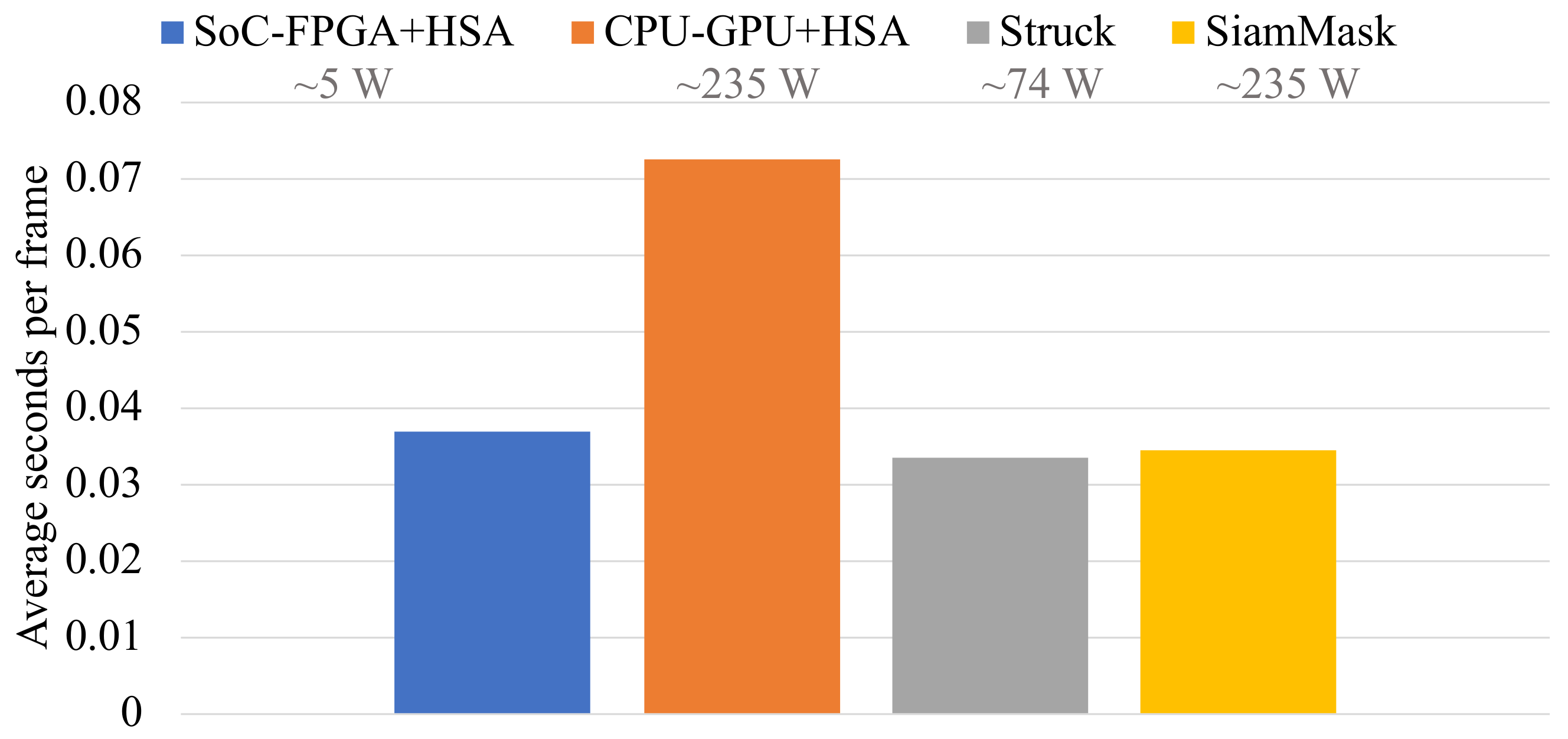
3.3.4. Comparison against State-of-the-Art Trackers in Terms of Time-Costs
4. Discussion
5. Conclusions
- An original workflow was proposed for the design of a low-power embedded system for real-time video tracking, based on an automaton that describes the behavior of a honeybee searching for food [38] and an SoC-FPGA platform. The workflow described in Section 2.5 served to guide the design process of the proposed embedded system. As the niche is still being researched, we hope that other researchers will find this workflow proposal useful in order to suggest similar systems based on meta-heuristics and SoC-FPGA platforms. It is useful to identify which parts of the meta-heuristic are control-intensive and which ones are data-intensive to identify the labors of PS and PL.
- A novel design, implementation, and evaluation of a low-power embedded system that performs real-time video tracking by combining HSA meta-heuristics and an SoC-FPGA platform was presented. Several benefits were observed using HSA in combination with SoC-FPGA for video tracking. The SoC-FPGA allows a greater control of the modules of the atomic operations. In the case of the fitness function (ZNCC), the problem was reassessed to fit the available resources in a bottom-up fashion. The time-costs are lower using an SoC-FPGA, which makes real-time processing possible. Furthermore, SoC-FPGA makes it possible to process a greater frame size in real time. Additionally, SoC-FPGA allows noticeably lower power consumption than CPU-GPU platforms and a greater portability. The experiments demonstrated that HSA can successfully be used to accelerate ZNCC for video tracking using SoC-FPGA without negative effects on accuracy.
- The comparison of our SoC-FPGA HSA-based proposal with a CPU-GPU HSA-based video tracking system [34] in terms of speed, energy consumption, accuracy, as well as portability, allowed the identification of the limitations of the CPU-GPU platform in this context. These limitations were the high time-costs of communication, the limited coordination of GPU components, and the fixed nature of the CPU-GPU architecture. We recommend using CPU-GPU over SoC-FPGA only if the problem requires an exhaustive search and the solution does not require portability and consider using a meta-heuristic over a GPU whenever possible. The greatest reduction in time-costs was observed when HSA was used in combination with SoC-FPGA.The results of the evaluation provide evidence that the combination of SoC-FPGA platforms and meta-heuristics is promising as it enables the creation of portable, energy efficient, fast, and effective systems.
- The results of the comparison with other state-of-the-art video trackers (Struck and SiamMask) showed that our proposal has the advantages of lower power consumption and portability, while maintaining similar processing speeds. On the other hand, Struck and SiamMask deliver outstanding accuracy, but they require high-end mainstream CPU-GPU devices and computers with high energy consumption. In this sense, the proposals of this work demonstrate that studying how to properly exploit the efficiency of the SoC-FPGA platforms in combination with meta-heuristics will bring substantial benefits to video tracking, other computer vision applications, and computational optimization in general.
- To improve the system that was designed to use the full capacity of the SoC-FPGA. The current proposal uses 40% of the LUT components, and 7% of the available DSP blocks. Additionally, we aim to exploit the possibility of reconfiguration, which allows the designer to propose many different designs that solve the same problem but with varying degrees of sequential and parallel behavior.
- To verify whether HSA may be implemented using the PL of the SoC-FPGA. The current proposal uses the PL to compute the fitness function, but the general decision-making process is executed using the PS. Further experiments should be performed to find the advantages and disadvantages of using the PL to run HSA.
- To use other fitness functions to replace or complement ZNCC. The canonical ZNCC tracker is currently not a viable contender against state-of-the-art trackers in terms of accuracy. However, it served as a starting point to study the advantages of using HSA and different heterogeneous systems for video tracking given its relative simplicity in comparison to newer proposals such as Struck [6] and SiamMask [8].
- To use the combination of HSA and SoC-FPGA platforms in other CV applications. The results of using HSA for video tracking showed positive results. This motivates us to study the effect of HSA on other CV applications or on specific variations of the tested problems, for example, in face tracking and detection, or tracking based on infrared image data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ALOV | Amsterdam Library of Ordinary Videos |
| ARM | Advanced RISC Machine |
| AXI | Advanced eXtensible Interface |
| CDMA | Central DMA |
| CLB | Configurable Logic Block |
| CU | Control Unit |
| CPU | Central Processing Unit |
| DMA | Direct Memory Access |
| DSP | Digital Signal Processor |
| ES | Evolution Strategy |
| FPGA | Field-Programmable Gate Array |
| GA | Genetic Algorithms |
| GPU | Graphics Processing Unit |
| GRASP | Greedy Randomized Adaptive Search Procedure |
| HDL | Hardware Description Languages |
| HSA | Honeybee Search Algorithm |
| IOB | Input/Output Blocks |
| LUT | LookUp Table |
| NCC | Normalized Cross-Correlation |
| PL | Programmable Logic |
| PLD | Programmable Logic Devices |
| PS | Processing System |
| PSO | Particle Swarm Optimization |
| RISC | Reduced Instruction Set Computer |
| RMI | Regional Mutual Information |
| RSSE | Root SSE |
| SIMD | Single Instruction, Multiple Data |
| SoC | System-on-Chip |
| SSE | Sum of Squared Errors |
| SRAM | Static RAM |
| ZNCC | Zero-Mean Normalized Cross-Correlation |
References
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: London, UK, 2010. [Google Scholar]
- Maggio, E.; Cavallaro, A. Video Tracking: Theory and Practice; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Kämäräinen, J.K.; Danelljan, M.; Zajc, L.Č.; Lukežič, A.; Drbohlav, O.; et al. The eighth visual object tracking VOT2020 challenge results. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 547–601. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach; Prentice Hall: New York, NY, USA, 2012. [Google Scholar]
- Olague, G.; Hernández, D.E.; Llamas, P.; Clemente, E.; Briseño, J.L. Brain programming as a new strategy to create visual routines for object tracking. Multimed. Tools Appl. 2019, 78, 5881–5918. [Google Scholar] [CrossRef]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asgarizadeh, M.; Pourghassem, H.; Shahgholian, G. Robust object tracking using regional mutual information and normalized cross correlation. In Proceedings of the 2012 Fourth International Conference on Computational Intelligence and Communication Networks, Mathura, India, 3–5 November 2012; pp. 411–415. [Google Scholar]
- Liang, Z.; Liang, C.; Zhang, Y.; Mu, H.; Li, G. Tracking of Moving Target Based on SiamMask for Video SAR System. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Hu, J.L.; Tang, X.W.; Qiu, J.N. Analysis of the influences of sampling bias and class imbalance on performances of probabilistic liquefaction models. Int. J. Geomech. 2017, 17, 04016134. [Google Scholar] [CrossRef]
- Xiao, Y.; Pun, C.M.; Liu, B. Adversarial example generation with adaptive gradient search for single and ensemble deep neural network. Inf. Sci. 2020, 528, 147–167. [Google Scholar] [CrossRef]
- Olague, G.; Hernandez, D.E.; Clemente, E.; Chan-Ley, M. Evolving head tracking routines with brain programming. IEEE Access 2018, 6, 26254–26270. [Google Scholar] [CrossRef]
- Olague, G.; Ibarra-Vázquez, G.; Chan-Ley, M.; Puente, C.; Soubervielle-Montalvo, C.; Martinez, A. A deep genetic programming based methodology for art media classification robust to adversarial perturbations. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 68–79. [Google Scholar]
- Ibarra-Vazquez, G.; Olague, G.; Puente, C.; Chan-Ley, M.; Soubervielle-Montalvo, C. Automated design of accurate and robust image classifiers with brain programming. In Proceedings of the 2021 Genetic and Evolutionary Computation Conference Companion, Lille, France, 10–14 July 2021; pp. 1385–1393. [Google Scholar]
- Ibarra-Vazquez, G.; Olague, G.; Chan-Ley, M.; Puente, C.; Soubervielle-Montalvo, C. Brain Programming is Immune to Adversarial Attacks: Towards Accurate and Robust Image Classification using Symbolic Learning. arXiv 2021, arXiv:2103.01359. [Google Scholar]
- Galoogahi, H.K.; Fagg, A.; Huang, C.; Ramanan, D.; Lucey, S. Need for speed: A benchmark for higher frame rate object tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1125–1134. [Google Scholar]
- Morsi, N.N.; Abdelhalim, M.B.; Shehata, K.A. Efficient hardware implementation of PSO-based object tracking system. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–8 November 2013; pp. 155–158. [Google Scholar]
- Nogueira, B.; Barboza, E. A FPGA-based accelerated architecture for the Continuous GRASP. Computing 2020, 103, 1–20. [Google Scholar] [CrossRef]
- Prongnuch, S.; Wiangtong, T. Heterogeneous computing platform for data processing. In Proceedings of the 2016 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Phuket, Thailand, 24–27 October 2016; pp. 1–4. [Google Scholar]
- Liu, Y.; Zhu, H. A survey of the research on power management techniques for high-performance systems. Softw. Pract. Exp. 2010, 40, 943–964. [Google Scholar] [CrossRef] [Green Version]
- Bean, A. Improving Memory Access Performance for Irregular Algorithms in Heterogeneous CPU/FPGA Systems. Ph.D. Thesis, Imperial College of Science, Technology and Medicine, London, UK, 2016. [Google Scholar]
- Martin, G.; Chang, H. System-on-Chip design. In Proceedings of the 2001 4th International Conference on ASIC, Shanghai, China, 23–25 October 2001; pp. 12–17. [Google Scholar]
- Kaeli, D.R.; Mistry, P.; Schaa, D.; Zhang, D.P. Heterogeneous Computing with OpenCL 2.0; Morgan Kaufmann: Waltham, MA, USA, 2015. [Google Scholar]
- Wolf, W. A decade of hardware/software codesign. Computer 2003, 36, 38–43. [Google Scholar] [CrossRef]
- Al-Zoubi, A.; Tatas, K.; Kyriacou, C. Towards Dynamic Multi-task Schedulling of OpenCL Programs on Emerging CPU-GPU-FPGA Heterogeneous Platforms: A Fuzzy Logic Approach. In Proceedings of the 2018 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Nicosia, Cyprus, 10–13 December 2018; pp. 247–250. [Google Scholar]
- Olague, G.; Puente, C. The honeybee search algorithm for three-dimensional reconstruction. In Proceedings of the Workshops on Applications of Evolutionary Computation, Budapest, Hungary, 10–12 April 2006; pp. 427–437. [Google Scholar]
- Olague, G. Evolutionary Computer Vision: The First Footprints; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Tomassini, M. Evolutionary algorithms. In Towards Evolvable Hardware; Springer: Berlin/Heidelberg, Germany, 1996; pp. 19–47. [Google Scholar]
- Blum, C.; Merkle, D. Swarm Intelligence: Introduction and Applications; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Clerc, M. Particle Swarm Optimization; Wiley: Hoboken, NJ, USA, 2010; Volume 93. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Orr, M.S.; Che, S.; Yilmazer, A.; Beckmann, B.M.; Hill, M.D.; Wood, D.A. Synchronization using remote-scope promotion. ACM SIGARCH Comput. Archit. News 2015, 43, 73–86. [Google Scholar] [CrossRef]
- Tan, Y.; Ding, K. A survey on GPU-based implementation of swarm intelligence algorithms. IEEE Trans. Cybern. 2015, 46, 2028–2041. [Google Scholar] [CrossRef] [PubMed]
- Perez-Cham, O.E.; Puente, C.; Soubervielle-Montalvo, C.; Olague, G.; Aguirre-Salado, C.A.; Nuñez-Varela, A.S. Parallelization of the honeybee search algorithm for object tracking. Appl. Sci. 2020, 10, 2122. [Google Scholar] [CrossRef] [Green Version]
- ARM. AMBA AXI and ACE Protocol Specification; ARM: Cambridge, UK, 2011. [Google Scholar]
- Churiwala, S.; Hyderabad, I. Designing with Xilinx® FPGAs; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Perez-Cham, O.E.; Puente, C.; Soubervielle-Montalvo, C.; Olague, G.; Castillo-Barrera, F.E.; Nunez-Varela, J.; Limon-Romero, J. Automata design for honeybee search algorithm and its applications to 3D scene reconstruction and video tracking. Swarm Evol. Comput. 2021, 61, 100817. [Google Scholar] [CrossRef]
- Schaumont, P.R. A Practical Introduction to Hardware/Software Codesign; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Palermo, G.; Silvano, C.; Zaccaria, V. Discrete particle swarm optimization for multi-objective design space exploration. In Proceedings of the 2008 11th EUROMICRO Conference on Digital System Design Architectures, Methods and Tools, Parma, Italy, 3–5 September 2008; pp. 641–644. [Google Scholar]
- Tsai, C.C.; Huang, H.C.; Lin, S.C. FPGA-based parallel DNA algorithm for optimal configurations of an omnidirectional mobile service robot performing fire extinguishment. IEEE Trans. Ind. Electron. 2010, 58, 1016–1026. [Google Scholar] [CrossRef]
- Rodriguez, A.; Moreno, F. Evolutionary computing and particle filtering: A hardware-based motion estimation system. IEEE Trans. Comput. 2015, 64, 3140–3152. [Google Scholar] [CrossRef] [Green Version]
- Elkhani, N.; Muniyandi, R.C.; Zhang, G. Multi-objective binary PSO with kernel P system on GPU. Int. J. Comput. Commun. Control. 2018, 13, 323–336. [Google Scholar] [CrossRef] [Green Version]
- Xilinx. Zynq-7000 SoC Data Sheet: Overview. 2018. v1.11.1. Available online: https://www.xilinx.com/support/documentation/data_sheets/ds190-Zynq-7000-Overview.pdf (accessed on 30 December 2021).
- Kechiche, L. Hardware acceleration for deep learning of image classification. In Proceedings of the 2021 International Conference of Women in Data Science at Taif University (WiDSTaif), Taif, Saudi Arabia, 30–31 March 2021; pp. 1–5. [Google Scholar]
- Rabiai, M.; Senouci, M.R.; Senouci, A.; Busawon, K.; Laurent, D. A hardware solution to overcome the bandwidth limitation of drone jamming platforms. In Proceedings of the 2020 12th International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP), Porto, Portugal, 20–22 July 2020; pp. 1–4. [Google Scholar]
- Qureshi, M.A.; Munir, A. PUF-IPA: A PUF-based identity preserving protocol for internet of things authentication. In Proceedings of the 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2020; pp. 1–7. [Google Scholar]
- Xilinx. 7 Series FPGAs Data Sheet: Overview. 2020. v2.6.1. Available online: https://www.xilinx.com/support/documentation/data_sheets/ds180_7Series_Overview.pdf (accessed on 30 December 2021).
- Smith, D.J. HDL Chip Design: A Practical Guide for Designing, Synthesizing and Simulating ASICs and FPGAs Using VHDL or Verilog; Doone Publications: Madison, AL, USA, 1998. [Google Scholar]
- Jahanirad, H.; Karam, H. BIST-based Testing and Diagnosis of LUTs in SRAM-based FPGAs. Emerg. Sci. J. 2017, 1, 216–225. [Google Scholar] [CrossRef]
- Volder, J. The CORDIC computing technique. In Proceedings of the 1959 Western Joint Computer Conference, San Francisco, CA, USA, 3–5 March 1959; pp. 257–261. [Google Scholar]
- Xilinx. Divider Generator. 2021. v5.1. Available online: https://www.xilinx.com/support/documentation/ip_documentation/div_gen/v5_1/pg151-div-gen.pdf (accessed on 30 December 2021).
- Boumaza, A.M.; Louchet, J. Dynamic flies: Using real-time parisian evolution in robotics. In Workshops on Applications of Evolutionary Computation; Springer: Cham, Switzerland, 2001; pp. 288–297. [Google Scholar]
- Bitam, S.; Batouche, M.; Talbi, E.G. A survey on bee colony algorithms. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; pp. 1–8. [Google Scholar]
- Deb, K. Multi-objective optimisation using evolutionary algorithms: An introduction. In Multi-Objective Evolutionary Optimisation for Product Design and Manufacturing; Springer: London, UK, 2011; pp. 3–34. [Google Scholar]
- Crist, E. Can an insect speak? The case of the honeybee dance language. Soc. Stud. Sci. 2004, 34, 7–43. [Google Scholar] [CrossRef] [Green Version]
- Deb, K.; Beyer, H.G. Self-adaptive genetic algorithms with simulated binary crossover. Evol. Comput. 2001, 9, 197–221. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, D.E.; Richardson, J. Genetic algorithms with sharing for multimodal function optimization. In Proceedings of the International Conference on Genetic Algorithms, Hillsdale, NJ, USA, October 1987; pp. 41–49. [Google Scholar]
- Khare, V.; Yao, X.; Deb, K. Performance scaling of multi-objective evolutionary algorithms. In International Conference on Evolutionary Multi-Criterion Optimization; Springer: Berlin/Heidelberg, Germany, 2003; pp. 376–390. [Google Scholar]
- Bätz, M.; Richter, T.; Garbas, J.U.; Papst, A.; Seiler, J.; Kaup, A. High dynamic range video reconstruction from a stereo camera setup. Signal Process. Image Commun. 2014, 29, 191–202. [Google Scholar] [CrossRef]
- Lin, C.; Li, Y.; Xu, G.; Cao, Y. Optimizing ZNCC calculation in binocular stereo matching. Signal Process. Image Commun. 2017, 52, 64–73. [Google Scholar] [CrossRef]
- Collett, D. Modelling Survival Data in Medical Research; Chapman & Hall: London, UK, 1994. [Google Scholar]
- Riesgo, T.; Torroja, Y.; De la Torre, E. Design methodologies based on hardware description languages. IEEE Trans. Ind. Electron. 1999, 46, 3–12. [Google Scholar] [CrossRef]
- McFarland, M.C.; Kowalski, T.J. Incorporating bottom-up design into hardware synthesis. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1990, 9, 938–950. [Google Scholar] [CrossRef]
- Mano, M.M. Computer Systems Architecture; Prentice-Hall: Englewood Cliffs, NJ, USA, 1982. [Google Scholar]
- Hopcroft, J.E.; Motwani, R.; Ullman, J.D. Introduction to automata theory, languages, and computation. ACM SIGACT News 2001, 32, 60–65. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, Z. Joint Representation Learning with Deep Quadruplet Network for Real-Time Visual Tracking. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]











| Device Name | Part Number | LUT Count | DSP Slices | Conforms to System Design |
|---|---|---|---|---|
| Z-7030 | XC7Z030 | 78,600 | 400 | Yes ** |
| Z-7035 | XC7Z035 | 171,900 | 900 | Yes |
| Z-7045 * | XC7Z045 | 218,600 | 900 | Yes |
| Z-7100 | XC7Z100 | 277,400 | 2020 | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soubervielle-Montalvo, C.; Perez-Cham, O.E.; Puente, C.; Gonzalez-Galvan, E.J.; Olague, G.; Aguirre-Salado, C.A.; Cuevas-Tello, J.C.; Ontanon-Garcia, L.J. Design of a Low-Power Embedded System Based on a SoC-FPGA and the Honeybee Search Algorithm for Real-Time Video Tracking. Sensors 2022, 22, 1280. https://doi.org/10.3390/s22031280
Soubervielle-Montalvo C, Perez-Cham OE, Puente C, Gonzalez-Galvan EJ, Olague G, Aguirre-Salado CA, Cuevas-Tello JC, Ontanon-Garcia LJ. Design of a Low-Power Embedded System Based on a SoC-FPGA and the Honeybee Search Algorithm for Real-Time Video Tracking. Sensors. 2022; 22(3):1280. https://doi.org/10.3390/s22031280
Chicago/Turabian StyleSoubervielle-Montalvo, Carlos, Oscar E. Perez-Cham, Cesar Puente, Emilio J. Gonzalez-Galvan, Gustavo Olague, Carlos A. Aguirre-Salado, Juan C. Cuevas-Tello, and Luis J. Ontanon-Garcia. 2022. "Design of a Low-Power Embedded System Based on a SoC-FPGA and the Honeybee Search Algorithm for Real-Time Video Tracking" Sensors 22, no. 3: 1280. https://doi.org/10.3390/s22031280
APA StyleSoubervielle-Montalvo, C., Perez-Cham, O. E., Puente, C., Gonzalez-Galvan, E. J., Olague, G., Aguirre-Salado, C. A., Cuevas-Tello, J. C., & Ontanon-Garcia, L. J. (2022). Design of a Low-Power Embedded System Based on a SoC-FPGA and the Honeybee Search Algorithm for Real-Time Video Tracking. Sensors, 22(3), 1280. https://doi.org/10.3390/s22031280