1. Introduction
Recent years have seen the burgeoning development of measurement technology and the application of this technology to wearable devices. With the increasing demand for physical exercise, functionality requirements for wearable devices have become more critical. Even though there are many studies attesting to the positive effects of exercise [
1,
2,
3,
4], most people still ignore the importance of physical exercise. The fact that hypomotility has become the fourth risk factor for global death was indicated by the World Health Organization (WHO). Approximately 60–85% of adults live statically worldwide, and two-thirds of children lack exercise. This situation increases the risk of cardiovascular disease, diabetes, and obesity compared to those who exercise regularly. Additionally, it leads to over two million people deaths every year. From the perspective of health, people who have good cardio respiratory endurance can exercise longer, do not get tired easily, and avoid disease. The central purpose of this study is to extend people’s sports time by exposure to suitable music.
The concept that people who listen to different types of music will change emotions and physical states has been widely accepted. Several studies have shown the relationship between psychology and physiology [
5,
6]. According to Bason et al. [
7], the heart rate changes mainly for the following reasons. First, the heart rate is changed by the external auditory stimulation that leads to the neuron coupling into the cardiac centers of the brain, further arousing the sinus entrainment of rhythms. Another cause of changing the heart rate is the autonomic nervous system (ANS) that controls and sustains homeostasis in our body, such as blood pressure, body temperature, and sleep qualities. It mainly consists of the parasympathetic nervous system (PNS) and sympathetic nervous system (SNS). Additionally, it is typically distinguished by opposing characteristics. For instance, in an emergency state, the SNS increases the heart rate, but on the other hand, the PMS typically retards the heart rate in the static state. Some studies indicate that quality of life can be improved by differenttypes of music, such as raising sleep quality, relieving pressure, supporting exercise, and enhancing brain liveliness [
8,
9,
10]. In summary, we could further infer that there supposedly is a connection between music stimuli and heart rate.
According to the above-mentioned factors, listening to different music genres changes one’s emotions and heart rate, which is a kind of music therapy method. There are some benefits of music therapy, such as socialization, cognition, emotion, and neuron motor function [
11]. Continuing music therapy research has led to many new and fascinating applications in sports and autistic and handicapped fields. According to Van Dyck E et al. [
12], music rhythm can affect running cadence. In other words, the slower rhythm of music brings out a decrease in running cadence; on the other hand, the faster rhythm of music gives rise to an increase in running cadence. Moreover, another significant research of promoting exercise efficiency is proven by Karow et al. [
13]. They provided extensive discussions of the importance of primary selected music. For instance, primary music could make humans more powerful and more stimulated during exercise. Moreover, it could effectively decrease the Rating of Perceived Exertion (RPE), which evaluates the degree of effort that a person feels by themselves. Consequently, music could draw attention away from uncomfortable feelings [
14].
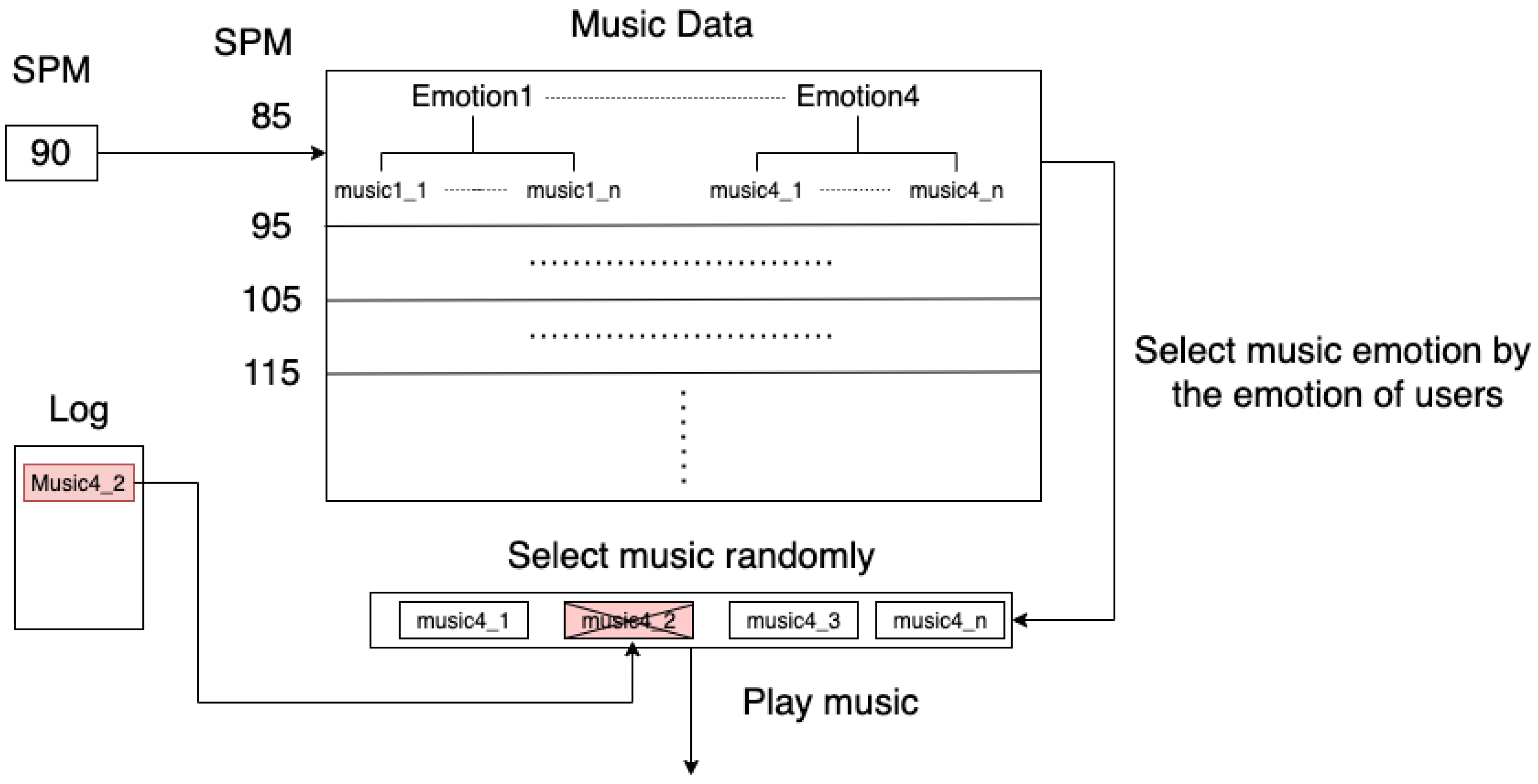
Nowadays, most playlists are supplied by famous sports brands, which causes unfamiliarity to the users. In addition, the playback mode is typically played by sequence or at random. However, we consider that the previous playback mode is not reasonable during exercise and that the playback sequence should be adjusted depending on the different physical situations of each person. As a result, we propose an algorithm to solve the playback mode during exercise. In order to apply it to individuals, we also consider the biological data and fuzzy algorithm [
15]. The fuzzy algorithm is based on the different exercise levels to suggest the canter speed through the biological data of users. We intend to introduce a complete music system consisting of pace match music rhythm, music emotion classification, fuzzy algorithms, and selection music module.
There are many ways to implement emotion classification models. First, simple machine learning models include random forest trees, KNN, and K-means. Although these traditional methods can solve the problem quickly with a small amount of data, they only obtain low accuracy of classification results [
16]. Second, RNN [
17] has a time series algorithm to solve the emotion classification task. However, the disadvantage of its architecture is prone to generating gradient disappearance and gradient explosion. However, the LSTM and GRU improve time series models to avoid the gradient disappearance and gradient explosion, which need additional parameters to control different gates [
17]. To achieve higher accuracy is necessary to overcome the variety of audio in music emotion classification tasks. On the other hand, CNN provides translation-invariant convolution, which can be used to overcome the diversity of audio signals. Thus, we deduce that the model with CNN can improve the classification accuracy in the emotion recognition task based on the characteristics of CNN. From the perspective of practical application, the accelerating technology is more mature than other types, and it brings the possibility of classification with CNN in the audio field.
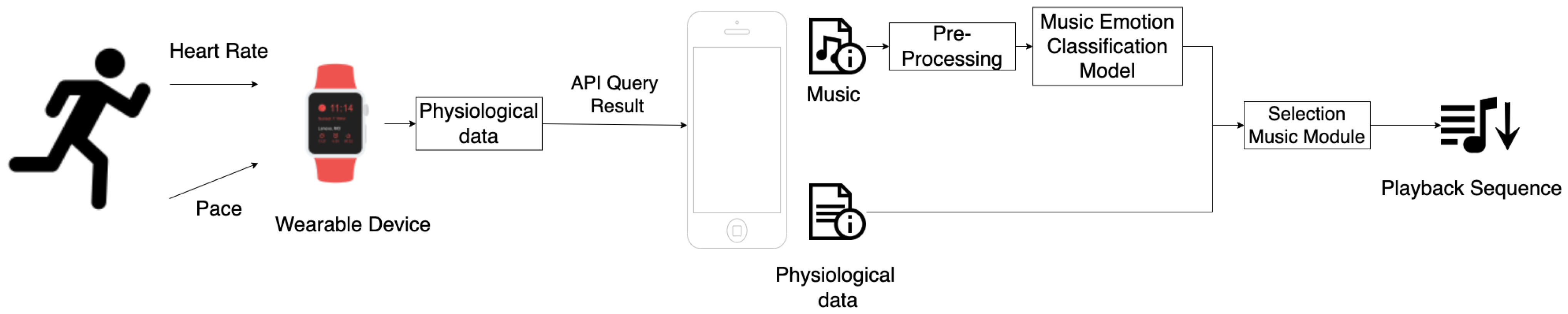
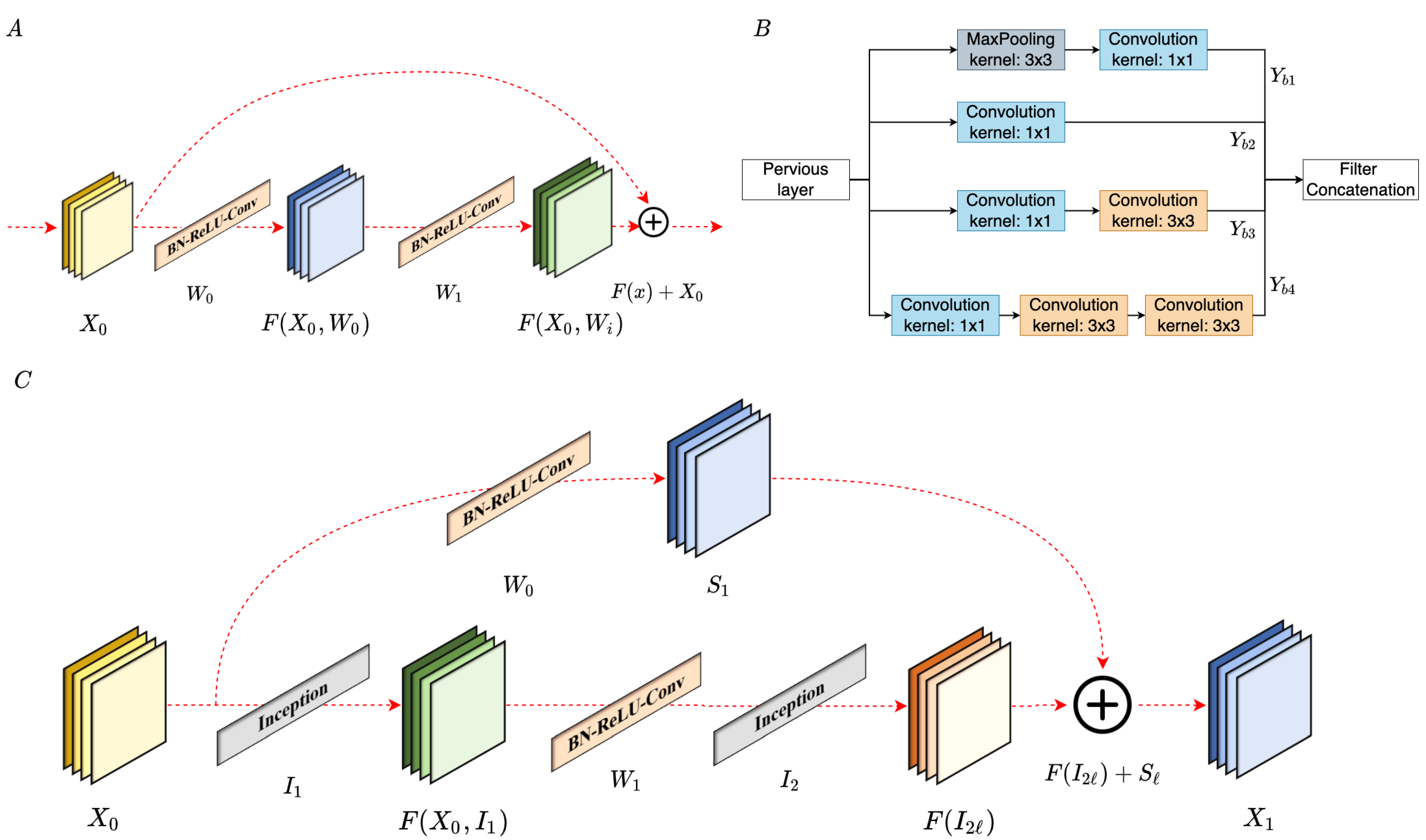
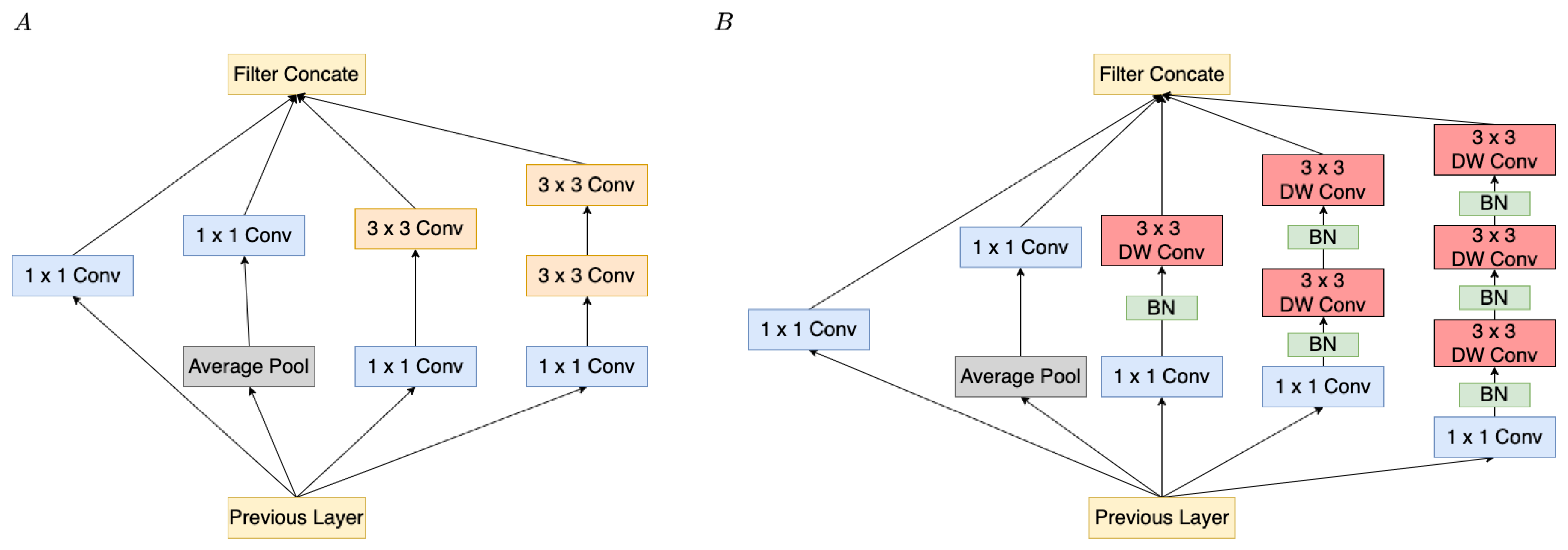
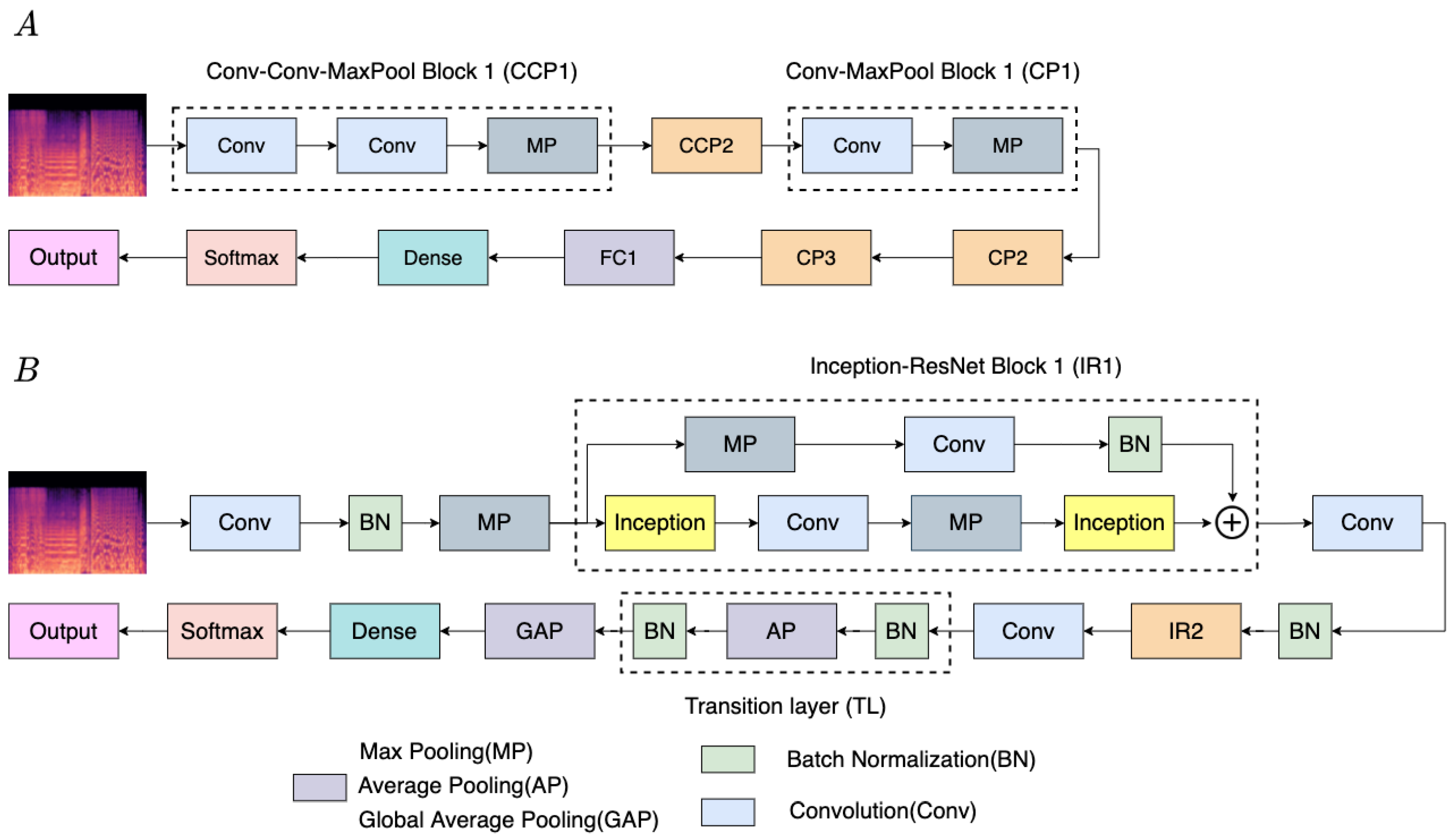
The purpose of this paper is to develop an algorithm for the playback sequence, which adopts CNN-based models for music emotion classification, also considering physiological data adjusting playback sequence immediately, as shown in
Figure 1.
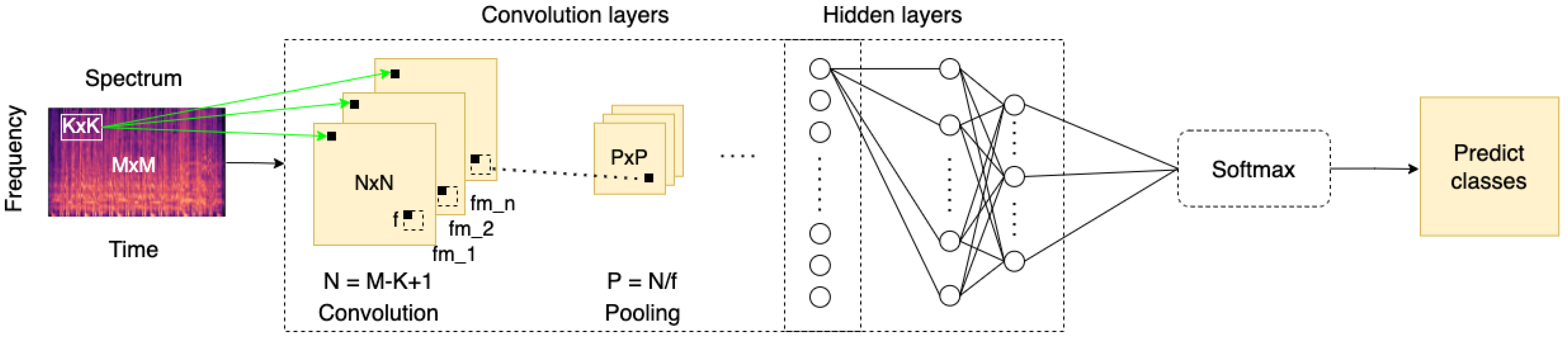
Figure 2 represents the CNN framework for the music emotion classification. In summary, the key contributions of this paper are:
We develop the playlist sequence algorithm concerning physiological data and emotion classification. This innovation can provide the kind of solution that was developed by previous studies.
Develop an emotion classification model with multiple kernel sizes and apply it to our proposed playback sequence system.
The results from our experiment indicate that the accuracy of the classification strategy is superior to that of other past research.
This paper is structured as follows.
Section 2 introduces the existing work on the current research progress of the emotion classification method and summarizes the advantages and disadvantages of the models. Next,
Section 3 provides an overview of the model, including the classification and flow of the selected music module. Then,
Section 4 conducts the experiment of music datasets on smartphones to evaluate the performance of the models. Finally,
Section 5 concludes the research work of this paper and summarizes the overall mentions.
4. Experiment Results
The structure of the section is divided into several subheadings to describe the experiment results in detail. First of all, the dataset description is provided. Next, we illustrate the data preprocessing in our experiments. After that, we compare the proposed model with other research models and analyze the performance. Lastly, we implement the proposed model on the mobile and present the energy consumption of the overall automatic music selection system.
4.1. Dataset
This study utilizes the 4Q emotion [
44] and the Soundtrack [
45] datasets. The sample rate of audio clips is 44.1 kHz in the above datasets, which are described below in detail.
Bi-modal. This dataset consists of 162 songs. Each song clip is of 30 s duration. The emotion category is also annotated into four A-V quadrants by Russell’s model. In this dataset, each emotion category has a different number of music clips, Q1: 52 clips; Q2: 45 clips; Q3: 31 clips, and Q4: 34 clips. In addition, these 162 songs are annotated with four quadrants. The quadrants are Q1 (A+V+), Q2 (A+V−), Q3 (A−V+), and Q4 (A−V−), which correspond to happy, anger, sad, and tender, respectively.
4Q emotion. This dataset [
44] consists of 900 songs, and the duration of each clip is 30 s. In addition, these 900 songs are annotated with four quadrants. The quadrants are Q1 (A+V+), Q2 (A+V−), Q3 (A−V+), and Q4 (A−V−), which correspond to happy, anger, sad, and tender, respectively.
Soundtracks. The dataset [
45] consist of 360 audio samples, which are taken from the background tracks of films with a length of approximately 30 s. Each clip is labeled with a distinct emotion category, such as wrath, sadness, happiness, fear, surprise, valance, energy, and tenderness. A clip may have several tags that have different levels of confidence. In the experiment, in order to clarify the category of dataset, we combine the high and low classes into the same classes. For example, low energy and high energy are in the same emotion category. Consequently, there are nine classes in our experiments.
4.2. Data Preprocessing
Han, Yoonchang et al. [
56] used Mel-spectrogram with 128 Mel filters for the time-frequency representation of the audio. They claimed that the 128 Mel filters contain sufficient spectral characteristics while significantly reducing the feature dimension. Mel-spectrogram is used as the input to the proposed network in this study, which is achieved by adding a logarithmic scale to the frequency axis of the STFT function. To prove if the 128 Mel filters achieve the best accuracy in our task, we implemented the experiment with four different Mel filters. Thus, we set the 30, 60, 90, and 128 Mel filters in the experiments. The parameter determined the shape of the feature vector before the feature extraction process. Specifically, we extracted the Mel-spectrogram with 30, 60, 90, and 128 Mel filters (bins) using the librosa tool [
57], setting the hop length as 1024, frame size as 2048, window function as the Hamming window, and sample rate as 44,100 Hz. When assigning the above parameters, we used the suitable vector of Mel-spectrogram as the input feature.
4.3. Data Augmentation
Data augmentation is a technique for avoiding model overfitting by augmenting the number of data used in model training. There are three different augmentation methods based on the particular qualities of music. The first is time overlapping, which is a useful technique in picture processing. Window shifting of audio signals generates extra data by adjusting the overlap to 50% to enhance the valid data size. Second, background noise was added to the signal, which added a signal-to-noise ratio of 10 dB to implement the augmentation of the data. The last was pitch shifting, which shifts the pitch of audio clips. We lowered the pitch of a waveform by a semitone. Under this process, the slight perturbations increased sample diversity but not impact the original music expression. Consequently, when we finished the data augmentation process, three times the original data remained. The results of augmented data are shown in
Table 3 and
Table 4.
4.4. Training and Other Details
The preprocessing method converts the raw data into Mel-spectrogram, which is described in
Section 4.2. The model utilizes the Mel-spectrogram with 128 × 1100 as input, and it is trained by using the ADAM [
58] optimizer to reduce categorical cross-entropy between predicted and actual labels. Each dataset was trained with 100 epochs and a batch size of 32. The learning rate starts with 0.01 and reduces it by a factor of 0.5 automatically after five epochs if the loss does not decrease. In order to validate the robustness of the model, we adopted k-fold cross-validation to evaluate the performance of the proposed model on the 4Q emotion and the Soundtrack datasets. In all datasets, we separated the data into training, testing, and validation at 80%, 10%, and 10%, respectively. The experiment was developed in Python, and the model was trained by using the Keras, Tensorflow, and Librosa toolkits on NVIDIA RTX-3090 GPU with 24 GB RAM. We measured the inference time of all the models on the iOS mobile device, iPhone 8 Plus, converting the trained model to ML model (.mlmodel).
4.5. Results on the Bi Modal Dataset
This following section describes the performance of the proposed model and classification results. First, comprehensive comparisons with other models, including the number of parameters, accuracy, inference time, and total FLOPs, are provided on Bi-modal dataset and 4Q emotion dataset. The inference time is estimated on iOS mobile devices in this experiment. Afterward, to emphasize the robustness of the proposed model and three available models, we examined the soundtrack dataset consisting of nine classes for testing emotion classification. This study also provides various comparisons with different models to estimate the performance by the following indicators, including total FLOPs, overall parameters, the accuracy, and the result of cross-validation.
Table 5 exhibits the performance of different technologies on the Bi- modal dataset. It can be observed that the proposed method attained an accuracy of 84.91%, which is better than Sarkar et al. (81.03%) [
54], VGGNet (63.79%), Inception v3 (64.15%), and ResNet (77.36%). The results indicate that the proposed model has great advantages of accuracy. Moreover, we implement the architecture proposed by Sarkar et al. and validate the result on the Bi-modal dataset. In the following section, we use the same configuration with Sarkar et al. proposed model to test different datasets and compare them with ours.
4.6. Results on the 4Q Emotion Dataset
Table 6 exhibits the performance of various designs on the 4Q emotion dataset. It can be seen that the proposed method achieved an accuracy of 92.07% on the 4Q emotion dataset. The accuracy is 20.32% and 15.23% higher than those of the SVM with ReliefF (baseline) [
44] and VGG-16, respectively. In comparison with Chaudhary [
59], the accuracy of the proposed model improved by 3.65% and FLOPs of the model were reduced by 68%. In addition, comparing our model with CCP [
54], the accuracy rose by 5.56%, and the training parameters and FLOPs by 89.8% and 89.3%, respectively. The results indicated that the proposed model has significant advantages of computation and accuracy. Furthermore, our approach outperforms VGGNet, Inception, and ResNet in terms of classification accuracy by 15.23%, 9.6%, and 7.21%, respectively. The experimental results indicate that our residual–inception block-based model is effective.
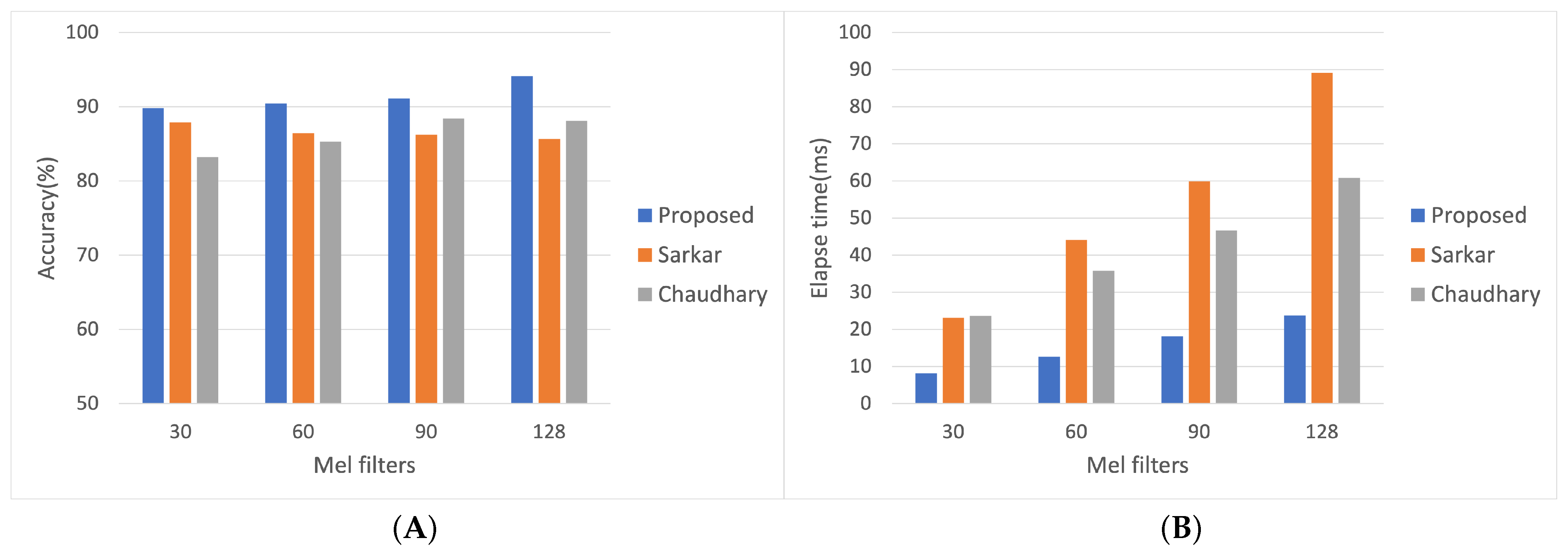
The proposed model has the most remarkable accuracy and the fewest parameters, with lower FLOPs and better accuracy than the others. Classification accuracy comparison between the proposed system and two other architectures is presented in
Figure 8 for emotion classification. It can be observed that the proposed model has higher accuracy than other models at the following four different frame length experiments. The Mel filters of 128 produce the highest classification accuracy compared to the other experiments; the accuracy of different Mel filter sizes with 30, 60, 90, and 128 are 89.76%, 90.42%, 91.11%, and 92.07%, respectively.
4.7. Results on Soundtrack Dataset
We compare the proposed model with some recent models, including three different deep learning models and two traditional classification methods, as shown in
Table 7. Sarri et al. [
60] classified the features with SVM and k-NN on the Soundtrack dataset, fetching an accuracy of 54%. The result is obviously insufficient, so the neural network as the classifier gradually replaces SVM and k-NN. The development of the VGG network replaces the old technique of extracting features, resulting in the accuracy substantially rising by 12%. Moreover, the RNN-based architecture was developed, which can describe dynamic time behavior and possesses the ability to extract the slight changes on the spectrogram. The MCCLSTM [
61] consists of long short-term memory (LSTM) and CNN, and the result demonstrates that it achieves an accuracy of 74.35 %. However, when the accuracy needs to be further improved, the number of parameters needs to be kept low at the same time. The LSTM-based architecture is not easy to implement in low parameters because the LSTM unit parameter requires four times more than the CNN-based architecture. As a result, the CNN-based architecture represents a significant direction of development. Sarkar et al. committed to improving the VGG network and developing the CCP module to replace the original VGG network. There are some benefits of the CCP module, described as follows. First, CCP alleviates the issue of overfitting on small training datasets. Second, the CCP module achieved higher accuracy than the VGG network, which achieved an accuracy of 82.54%. Finally, Chaudhary et al. utilized a different architecture of convolutional layer kernel, fetching an accuracy of 83.98%. In addition, Chaudhary et al. developed architecture through stacking various kernel size convolutions and achieving higher accuracy and lower FLOPs. However, the accuracy is still lower than the proposed models, and FLOPs are higher than ours. According to the experiment results, the accuracy of the proposed model outperforms all the compared models, whether on the 4Q emotion and Soundtrack dataset.
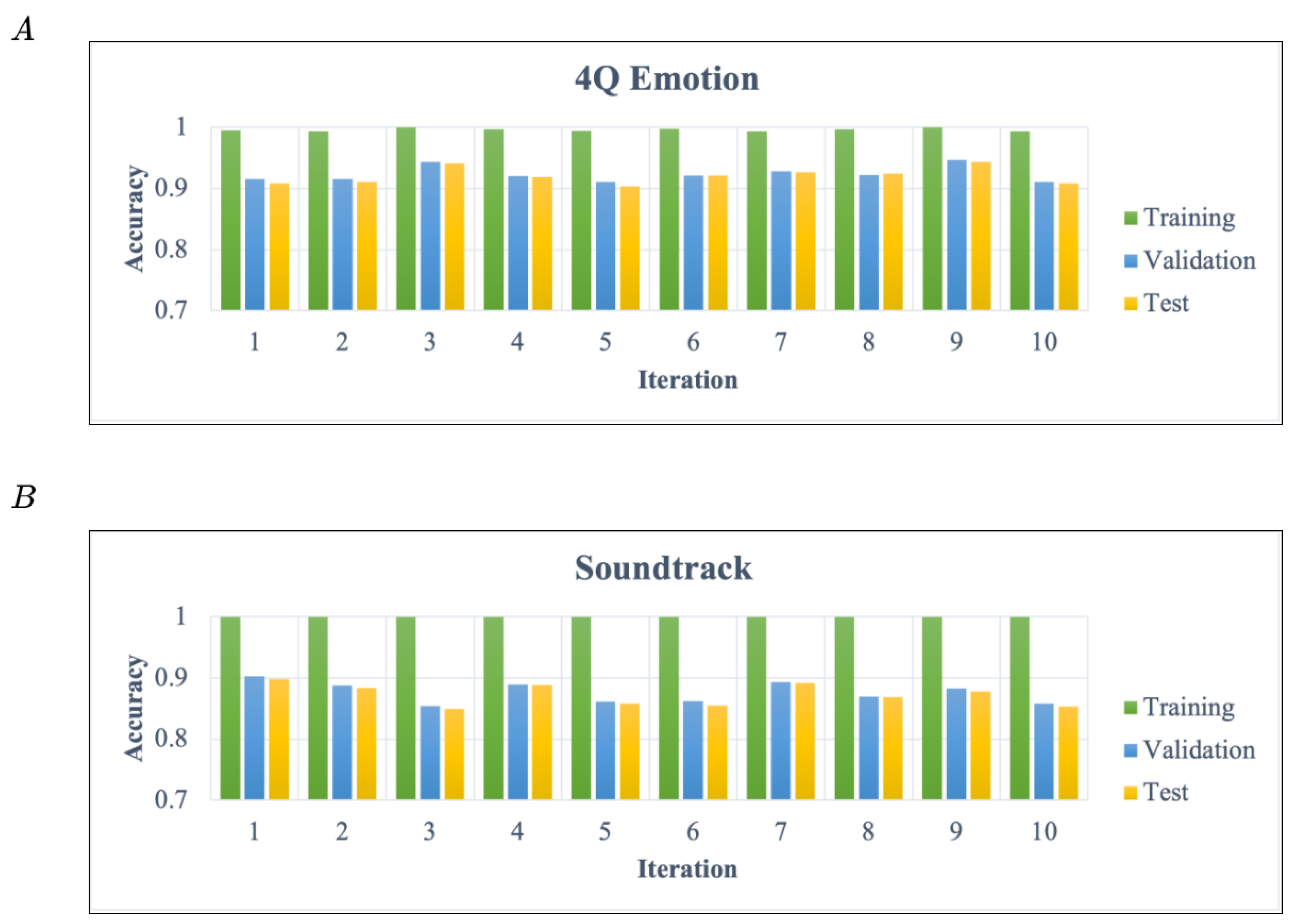
To prove whether the model generalizes well to new data, we performed a 10-fold cross-validation on each dataset.
Figure 9 illustrates the training, testing, and validating accuracy in each iteration. The training, testing, and validation data are 80%, 10%, and 10%, respectively. The experimental results show that the classification results of the different datasets and the new data achieve a competitive level to represent the proposed model possessing generalization ability.
4.8. Runtime of the Developed Application
The strategy of playing music is chosen by the previously mentioned method. In addition, the purpose is to lower energy consumption as much as possible. As we know, the inference process is the most energy-consuming. Therefore, we reduce the usage of the emotion classification model by developing the following algorithm to reduce energy consumption. As a result, we design the algorithm to reduce energy consumption. This main process includes reducing the classification usage and reserving the 10 songs that correspond to the emotion of users, and does not classify all of the music to achieve the lower power consumption. The
Table 8 depicts the energy usage of the proposed system during the process.
5. Conclusions
This paper presented a specific network for detecting music emotions while running the music selection system. The proposed model intends to use the low-level information in log-scaled Mel-spectrograms to make a classification choice. The proposed method is proven competitive with existing deep learning architectures on the 4Q emotion and the Soundtrack datasets. Furthermore, four different numbers of Mel filters are used to generate the input spectrograms. We discovered that the increasing number of Mel filters results in higher classification accuracy as well. Thus, we can deduce that the more Mel filters we set, the more features we obtained. Specifically, the proposed model achieves 84.91%, 92.07%, and 87.24% on Bi-modal, 4Q emotion, and Soundtrack datasets, respectively, higher than other emotion classification models, and the inference time is lower as well. The proposed emotion classifier will be used in the field of music therapy. In addition, this paper designed a selection module based on a set of physiological data of users and music emotional variables for when the user is running. Furthermore, we lessened the energy consumption by reducing the usage of the emotion classification model to ensure that it can execute for a long time on mobiles.
In summary, this study developed an entire system for joggers, solving the problem of playback sequence, which has not considered the present physiological and music emotion during exercise in the previous studies. The entire playback sequence consists of the classifier and music selection module developed based on previous research on music interventions. The classifier can be used as part of the music playback sequence. The system will change music sequence immediately to make users exercise more efficiently, according to the present situation of physiological data.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}