
Multi-Path U-Net Architecture for Cell and Colony-Forming Unit Image Segmentation



Abstract
:1. Introduction
2. Materials and Methods
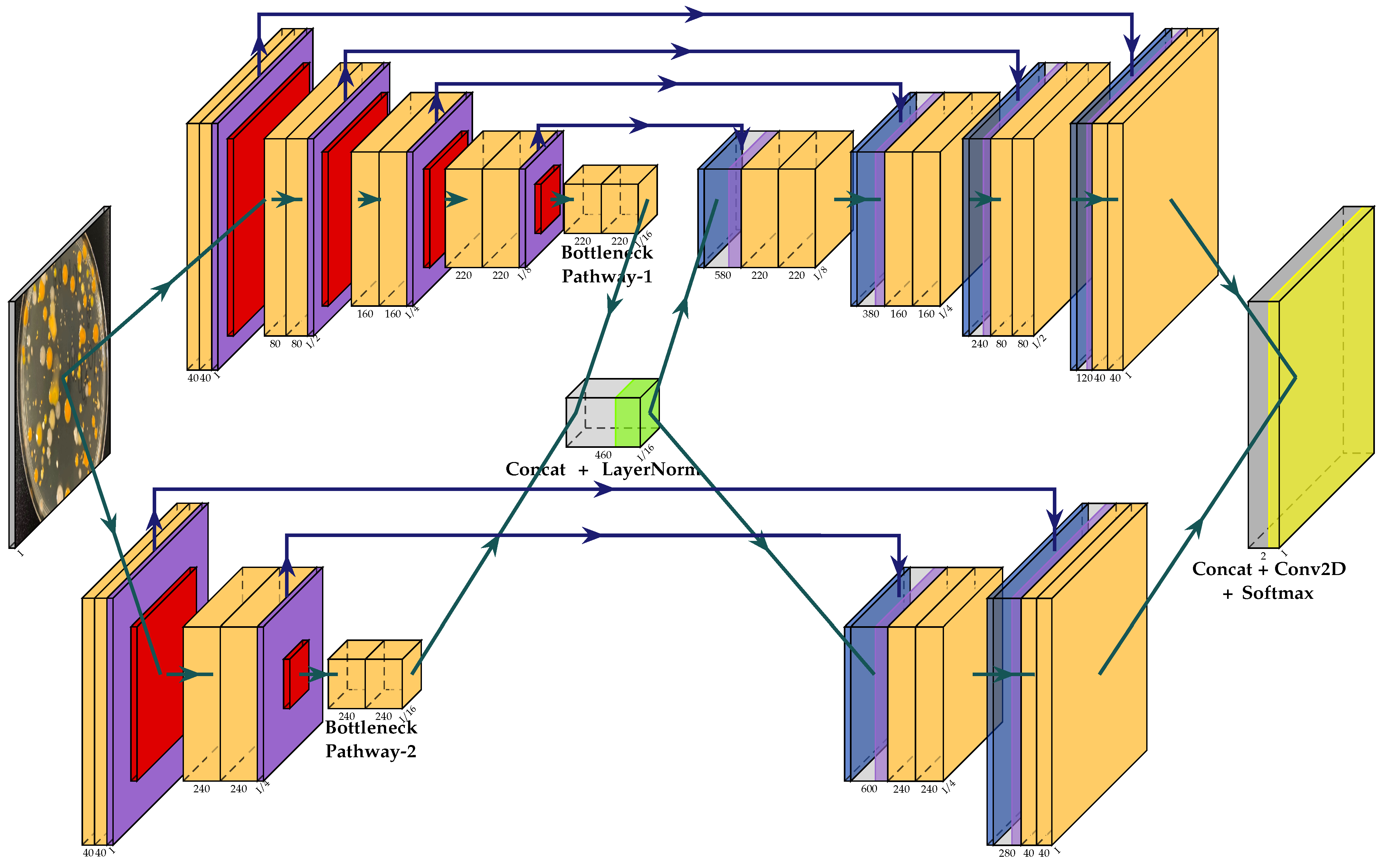
2.1. Multi-Path U-Net
2.2. Spatial Dropout
2.3. Overall Architecture
2.4. Datasets
2.5. Experimental Setup
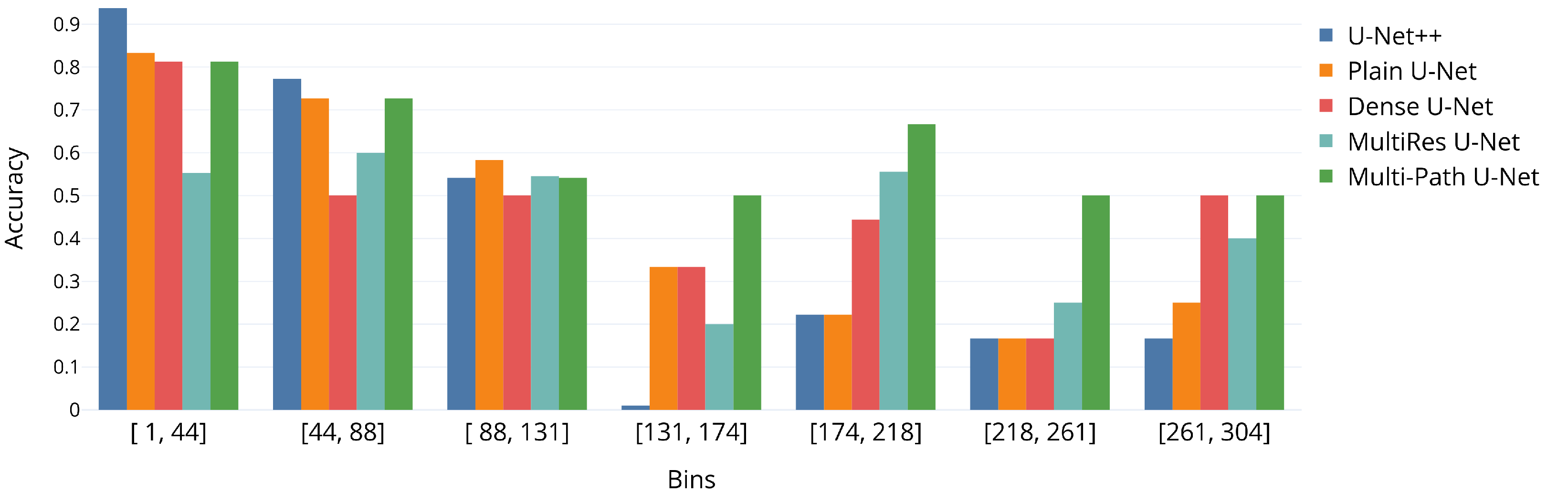
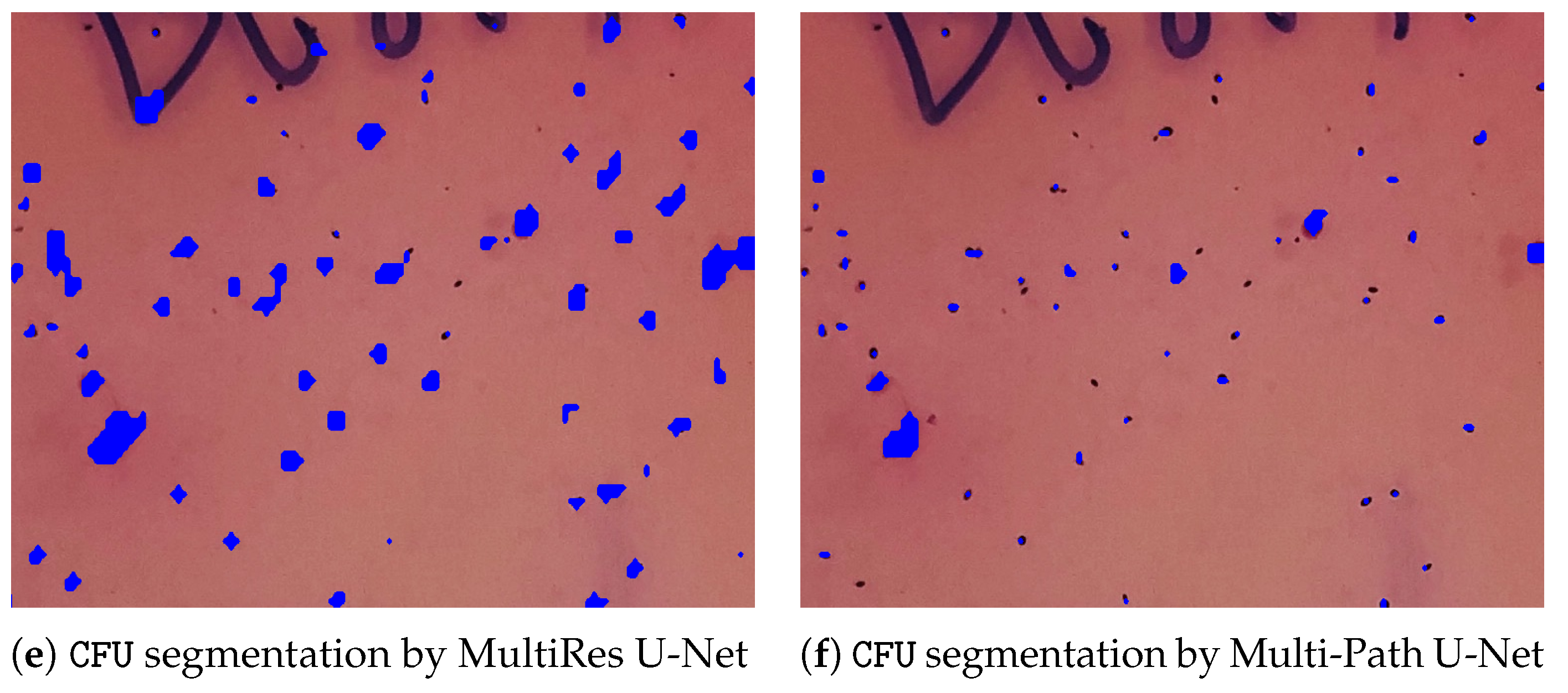
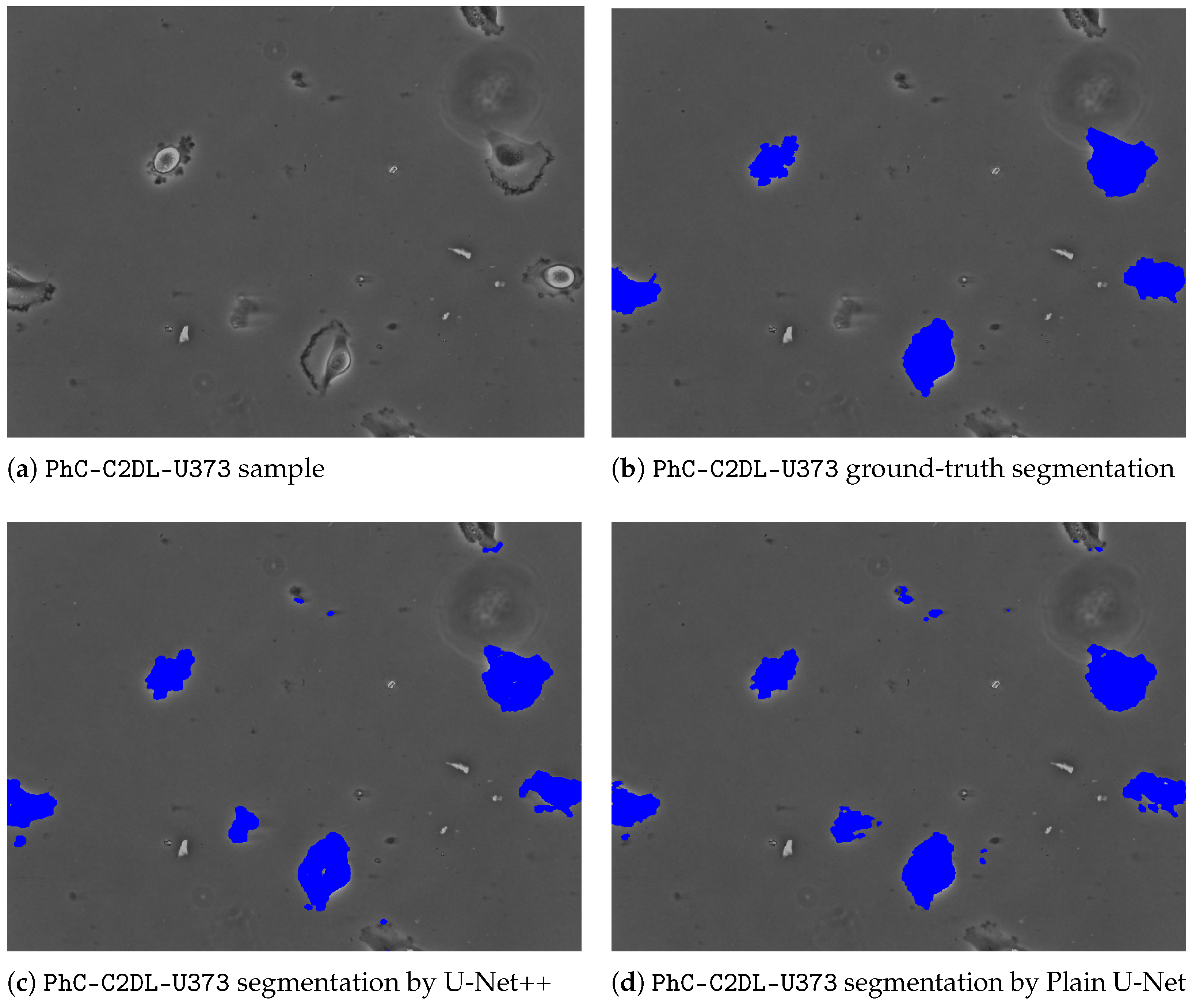
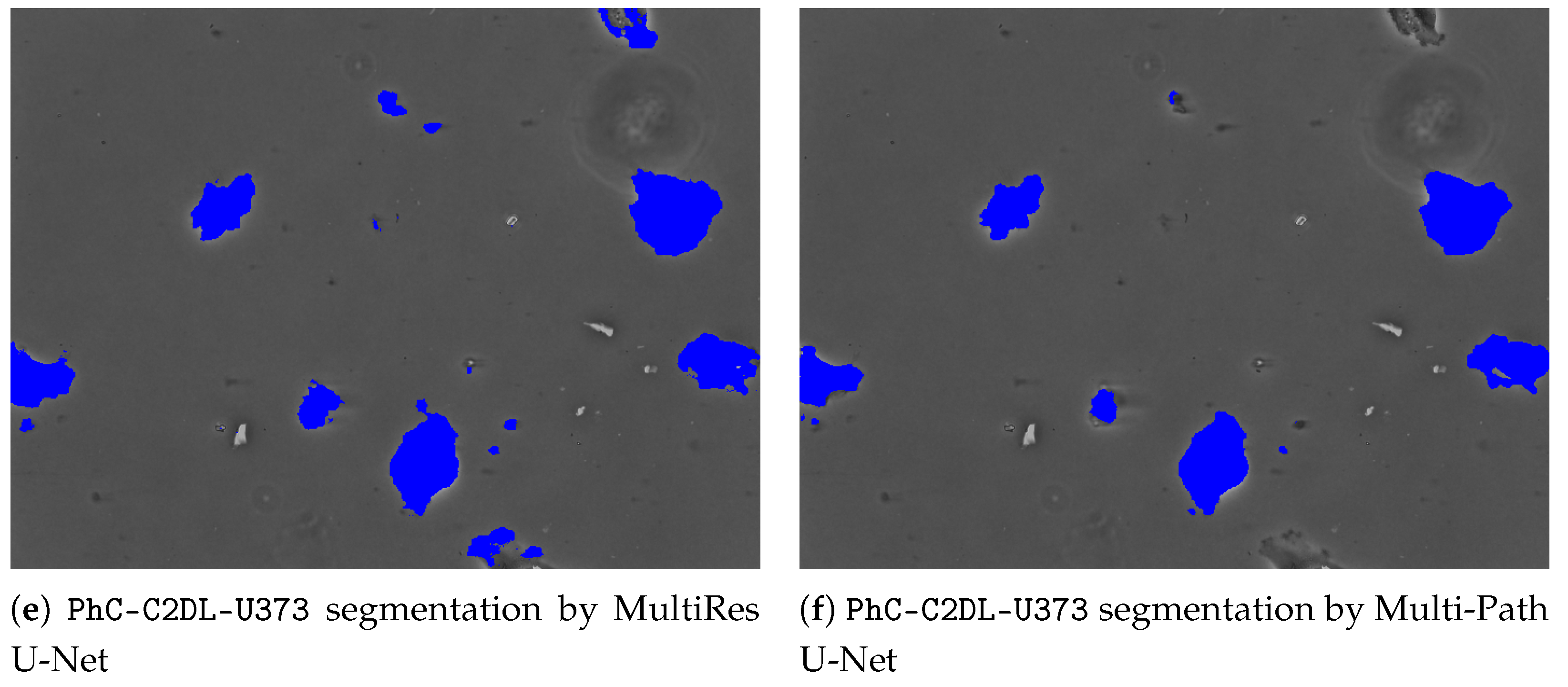
3. Results
4. Discussion
- 1
- Pros of the proposed approach:
- Resilient multi-pathway backbone with individual receptive field pathways.
- Better flow of visual information through a different order of resolutions in each pathway.
- Enhanced generalization performance by means of the pathway wiring, Layer Normalization, and Spatial Dropout.
- Possibility to introduce an implicit multi-GPU parallelization.
- 2
- Cons of the proposed approach:
- Necessity for all pathways to provide consistent and compatible output dimensions at the bottleneck layers.
- Near-linear increase in computational time on a single GPU card.
- Difficulties in the application of gradient-based attribution methods.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. In Deep Learning and Data Labeling for Medical Applications; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 10008, pp. 179–187. [Google Scholar]
- Oskal, K.R.J.; Risdal, M.; Janssen, E.A.M.; Undersrud, E.S.; Gulsrud, T.O. A U-net based approach to epidermal tissue segmentation in whole slide histopathological images. SN Appl. Sci. 2019, 1, 672. [Google Scholar] [CrossRef] [Green Version]
- Ficarra, V.; Novara, G.; Secco, S.; Macchi, V.; Porzionato, A.; De Caro, R.; Artibani, W. Preoperative Aspects and Dimensions Used for an Anatomical (PADUA) Classification of Renal Tumours in Patients who are Candidates for Nephron-Sparing Surgery. Eur. Urol. 2009, 56, 786–793. [Google Scholar] [CrossRef] [PubMed]
- Heller, N.; Sathianathen, N.; Kalapara, A.; Walczak, E.; Moore, K.; Kaluzniak, H.; Rosenberg, J.; Blake, P.; Rengel, Z.; Oestreich, M.; et al. The KiTS19 Challenge Data: 300 Kidney Tumor Cases with Clinical Context, CT Semantic Segmentations, and Surgical Outcomes. 2020. Available online: https://arxiv.org/abs/1904.00445 (accessed on 1 December 2021).
- Vicar, T.; Balvan, J.; Jaros, J.; Jug, F.; Kolar, R.; Masarik, M.; Gumulec, J. Cell segmentation methods for label-free contrast microscopy: Review and comprehensive comparison. BMC Bioinform. 2019, 20, 360. [Google Scholar] [CrossRef] [PubMed]
- Beznik, T.; Smyth, P.; de Lannoy, G.; Lee, J.A. Deep Learning to Detect Bacterial Colonies for the Production of Vaccines. Neurocomputing 2022, 470, 427–431. [Google Scholar] [CrossRef]
- Huang, P.; Lin, C.T.; Li, Y.; Tammemagi, M.C.; Brock, M.V.; Atkar-Khattra, S.; Xu, Y.; Hu, P.; Mayo, J.R.; Schmidt, H.; et al. Prediction of lung cancer risk at follow-up screening with low-dose CT: A training and validation study of a deep learning method. Lancet Digit. Health 2019, 1, e353–e362. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Granada, Spain, 20 September 2018; Volume 11045, pp. 3–11. [Google Scholar] [CrossRef] [Green Version]
- ul Maula Khan, A.; Torelli, A.; Wolf, I.; Gretz, N. AutoCellSeg: Robust automatic colony forming unit (CFU)/cell analysis using adaptive image segmentation and easy-to-use post-editing techniques. Sci. Rep. 2018, 8, 7302. [Google Scholar] [CrossRef] [Green Version]
- Sieuwerts, S.; De Bok, F.; Mols, E.; De Vos, W.; Van Hylckama Vlieg, J. A simple and fast method for determining colony forming units. Lett. Appl. Microbiol. 2008, 47, 275–278. [Google Scholar] [CrossRef]
- Mandal, P.; Biswas, A.; K, C.; Pal, U. Methods for Rapid Detection of Foodborne Pathogens: An Overview. Am. J. Food Technol. 2011, 6, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Brugger, S.D.; Baumberger, C.; Jost, M.; Jenni, W.; Brugger, U.; Mühlemann, K. Automated Counting of Bacterial Colony Forming Units on Agar Plates. PLoS ONE 2012, 7, e33695. [Google Scholar] [CrossRef] [Green Version]
- Yuheng, S.; Hao, Y. Image Segmentation Algorithms Overview. arXiv 2017, arXiv:1707.02051. [Google Scholar]
- Isensee, F.; Maier-Hein, K.H. An attempt at beating the 3D U-Net. arXiv 2019, arXiv:1908.02182. [Google Scholar]
- Zhang, Z.; Liu, Q. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2017, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Dubey, A.; Jain, V. Comparative Study of Convolution Neural Network’s Relu and Leaky-Relu Activation Functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Springer: Singapore, 2019; pp. 873–880. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Gao, H.; Zheng, B.; Pan, D.; Zeng, X. Covariance Self-Attention Dual Path UNet for Rectal Tumor Segmentation. 2021. Available online: https://arxiv.org/abs/2011.02880 (accessed on 1 December 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Hilbert, A.; Madai, V.I.; Akay, E.M.; Aydin, O.U.; Behland, J.; Sobesky, J.; Galinovic, I.; Khalil, A.A.; Taha, A.A.; Wuerfel, J.; et al. BRAVE-NET: Fully Automated Arterial Brain Vessel Segmentation in Patients With Cerebrovascular Disease. Front. Artif. Intell. 2020, 3, 78. [Google Scholar] [CrossRef]
- Liu, H.; Rashid, T.; Ware, J.; Jensen, P.; Austin, T.; Nasrallah, I.; Bryan, R.; Heckbert, S.; Habes, M. Adaptive Squeeze-and-Shrink Image Denoising for Improving Deep Detection of Cerebral Microbleeds. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 265–275. [Google Scholar]
- Ba, L.J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar] [CrossRef] [Green Version]
- Kolařík, M.; Burget, R.; Uher, V.; Říha, K.; Dutta, M.K. Optimized High Resolution 3D Dense-U-Net Network for Brain and Spine Segmentation. Appl. Sci. 2019, 9, 404. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sun, F.; Yang, G.; Zhang, A.; Zhang, Y. Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms 2021, 14, 159. [Google Scholar] [CrossRef]
- Wu, H.; Gu, X. Max-Pooling Dropout for Regularization of Convolutional Neural Networks. In International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Carass, A.; Roy, S.; Gherman, A.; Reinhold, J.C.; Jesson, A.; Arbel, T.; Maier, O.; Handels, H.; Ghafoorian, M.; Platel, B.; et al. Evaluating White Matter Lesion Segmentations with Refined Sørensen-Dice Analysis. Sci. Rep. 2020, 10, 8242. [Google Scholar] [CrossRef] [PubMed]
- Mohseni Salehi, S.S.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 379–387. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 1 December 2021).
- Müller, D.; Kramer, F. MIScnn: A framework for medical image segmentation with convolutional neural networks and deep learning. BMC Med. Imaging 2021, 21, 12. [Google Scholar] [CrossRef] [PubMed]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M.H. Gradient-Based Attribution Methods. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11700, pp. 169–191. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Cardinality | Image Sizes |
|---|---|---|---|
| BF-C2DL-HSC | Cell | 57 | 1010 × 1010 × 3 |
| BF-C2DL-MuSC | Cell | 100 | 1036 × 1070 × 3 |
| PhC-C2DL-U373 | Cell | 36 | 520 × 696 × 3 |
| Fluo-N2DL-HeLa | Cell | 184 | 700 × 1010 × 1 |
| Proprietary CFU | CFU | 150 | 3024 × 3024 × 3 |
| Architecture | Params | Dataset | ||||
|---|---|---|---|---|---|---|
| BF-C2DL-HSC | BF-C2DL-MuSC | PhC-C2DL-U373 | Fluo-N2DL-HeLa | CFU | ||
| U-Net++ | 9.99 M | 0.8272 ± 0.0483 | 0.9189 ± 0.0029 | 0.9554 ± 0.0074 | 0.9763 ± 0.0001 | 0.8866 ± 0.0082 |
| Plain U-Net | 10.20 M | 0.9501 ± 0.0054 | 0.9146 ± 0.0016 | 0.9544 ± 0.0045 | 0.9787 ± 0.0001 | 0.8919 ± 0.0059 |
| Dense U-Net | 9.68 M | 0.9599 ± 0.0029 | 0.9186 ± 0.0020 | 0.9550 ± 0.0055 | 0.9785 ± 0.0001 | 0.8930 ± 0.0053 |
| MultiRes U-Net | 10.03 M | 0.5317 ± 0.0261 | 0.6594 ± 0.0401 | 0.9510 ± 0.0163 | 0.9789 ± 0.0001 | 0.8664 ± 0.0180 |
| Multi-Path U-Net (1) | 10.03 M | 0.9498 ± 0.0062 | 0.9224 ± 0.0016 | 0.9553 ± 0.0048 | 0.9789 ± 0.0001 | 0.9007 ± 0.0044 |
| Multi-Path U-Net (2) | 10.08 M | 0.9604 ± 0.0050 | 0.9238 ± 0.0013 | 0.9612 ± 0.0059 | 0.9796 ± 0.0001 | 0.9025 ± 0.0053 |
| Architecture | Params | Dataset | ||||
|---|---|---|---|---|---|---|
| BF-C2DL-HSC | BF-C2DL-MuSC | PhC-C2DL-U373 | Fluo-N2DL-HeLa | CFU | ||
| U-Net++ | 9.99 M | 0.6554 ± 0.0965 | 0.8389 ± 0.0056 | 0.9161 ± 0.0143 | 0.9594 ± 0.0001 | 0.7784 ± 0.0158 |
| Plain U-Net | 10.20 M | 0.9007 ± 0.0105 | 0.8302 ± 0.0030 | 0.9142 ± 0.0089 | 0.9634 ± 0.0001 | 0.7884 ± 0.0117 |
| Dense U-Net | 9.68 M | 0.9202 ± 0.0057 | 0.8383 ± 0.0038 | 0.9151 ± 0.0108 | 0.9630 ± 0.0001 | 0.7903 ± 0.0104 |
| MultiRes U-Net | 10.03 M | 0.1133 ± 0.0386 | 0.3630 ± 0.0712 | 0.9081 ± 0.0312 | 0.9637 ± 0.0001 | 0.7379 ± 0.0349 |
| Multi-Path U-Net (1) | 10.03 M | 0.9002 ± 0.0121 | 0.8457 ± 0.0030 | 0.9159 ± 0.0094 | 0.9637 ± 0.0002 | 0.8057 ± 0.0086 |
| Multi-Path U-Net (2) | 10.08 M | 0.9214 ± 0.0098 | 0.8487 ± 0.0025 | 0.9267 ± 0.0113 | 0.9648 ± 0.0002 | 0.8090 ± 0.0103 |
| Architecture | Metrics | ||
|---|---|---|---|
| MAE | Accuracy@3 | Accuracy@20 | |
| U-Net++ | 36.81 | 0.9000 | 0.5400 |
| Plain U-Net | 31.49 | 0.9000 | 0.5266 |
| Dense U-Net | 33.96 | 0.8867 | 0.5133 |
| MultiRes U-Net | 44.33 | 0.7750 | 0.4750 |
| Multi-Path U-Net | 29.40 | 0.8933 | 0.6000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jumutc, V.; Bļizņuks, D.; Lihachev, A. Multi-Path U-Net Architecture for Cell and Colony-Forming Unit Image Segmentation. Sensors 2022, 22, 990. https://doi.org/10.3390/s22030990
Jumutc V, Bļizņuks D, Lihachev A. Multi-Path U-Net Architecture for Cell and Colony-Forming Unit Image Segmentation. Sensors. 2022; 22(3):990. https://doi.org/10.3390/s22030990
Chicago/Turabian StyleJumutc, Vilen, Dmitrijs Bļizņuks, and Alexey Lihachev. 2022. "Multi-Path U-Net Architecture for Cell and Colony-Forming Unit Image Segmentation" Sensors 22, no. 3: 990. https://doi.org/10.3390/s22030990
APA StyleJumutc, V., Bļizņuks, D., & Lihachev, A. (2022). Multi-Path U-Net Architecture for Cell and Colony-Forming Unit Image Segmentation. Sensors, 22(3), 990. https://doi.org/10.3390/s22030990