1. Introduction
The growing rate of the elderly population has been a central topic in the last decade and will remain relevant for the coming decades; the lifespan of people has become longer than it has ever been. Such development will undoubtedly impact economic and societal systems, including healthcare services. In Europe, for example, the ratio between people of working age and those aged above 65 years was 4:1 in 2001 [
1]. It is estimated that by 2050 there will be fewer than two persons of working age for each elderly person [
1]. Not only is the ratio estimated to change significantly, but also the number and severity of illnesses. The EU accounted for more than 9.1 million cases of individuals older than 60 years with dementia in 2018, which was only 5.9 million in 2000 [
2]. Thus, if the age-explicit predominance of dementia increases at the same speed, the growing ageing population will translate into an increased number of dementia cases. It is thus expected that by the year 2050, there will be approximately one million new cases of dementia every year that need health support [
3]. Professional care-giving institutions and practitioners would quickly be overwhelmed with the growing number of patients at different stages in their disease. Aware of these challenges, health care professionals are becoming increasingly open to using technology that supports them in performing their work [
4].
A new set of technologies, titled Active and Assisted Living (AAL) technologies, have emerged in response to these challenges. They refer to all products and services that are designed to support individuals in retaining or enhancing their independence and well-being [
5,
6]. The main goal of this collection of diverse technologies is to offer an automatic and accurate alternative to classical data gathering techniques (e.g., through recurrent questionnaires) used for further decision making and thus assist healthcare professionals in efficiently monitoring the elderly.
Existing AAL approaches rely on deploying several sensors inside the house to enable ageing-in-place. Nevertheless, adopting this approach appears intrusive and, in some cases, expensive for older adults. The intrusiveness is generally related to solutions that consider sensors intervening in the daily activities or violating privacy constraints. The subjects are thus less accepting toward these solutions [
6,
7]. On the other hand, solutions based on background sensors may appear to be a viable alternative. However, the costs of their purchase, installation, and maintenance remain a major obstacle. The Casa Vecchia [
8] project conducted in the rural areas of Austria highlighted this issue. The authors stressed the economic aspect of AAL solutions based on smart technologies. According to the authors, the price of basic solutions starts from 150€ and could rise to 90,000€ for the most sophisticated solutions without considering installation and maintenance costs. The latter also contributes to the high intrusiveness of such kinds of solutions.
A promising sub-field of AAL relies on the indirect monitoring of daily activities through energy data generated by the explicit usage of electric devices [
5]. These daily activities are direct indicators of daily routines and well-being. Moreover, they could also assist in recognising the beginning of cognitive impairments that start with difficulties in performing complex instrumental tasks and continue to a total loss of the ability to perform basic daily tasks [
9]. Mainly, difficulties in performing daily activities translate into deviations in the usage patterns of hand-operated appliances, reflected in the recorded energy data. The described approaches benefit from the extensive deployment campaigns of smart-meter worldwide. These campaigns provide an already available infrastructure that can be–compared to sensors that would have to be installed additionally–easily used whenever needed. These approaches also benefit from the non-intrusiveness of smart-metering technology. The occupants will not perceive any changes since no additional installation or maintenance tasks are necessary. Instead, occupants conduct their regular routines with no differences. Nonetheless, these approaches can not be attainable without Non-intrusive Load Monitoring (NILM), a set of techniques interacting with the smart meter to identify the power consumption of different appliances.
A primary challenge in monitoring daily routines (and identifying significant deviations) is to design systems considering the heterogeneity and complexity of daily routines. Moreover, scholars gave little attention to evaluating state-of-the-art NILM models in AAL applications. We suggest a new framework for activity monitoring based on custom user-profiles and deep NILM models to address these gaps. Furthermore, we propose an interactive framework by exchanging feedback with external agents such as health care professionals or family members. The key objective of our work is to provide them with a tool that can take over basic monitoring means which currently require manual efforts (such as frequent phone calls or visits). This is particularly relevant for the case of rural areas and older relatives living alone. When the technology works appropriately, phone calls and personal visits can focus on social and relationship aspects rather than daily activities monitoring. The contributions of the presented work fall in two main points: (1) The proposition of a new activity monitoring framework based on the usage time of hand-operated appliances inferred from energy data, and (2) the discussion of two case studies of houses occupied by older adults from the REFIT dataset where we evaluate the whole proposed pipeline including NILM approaches and their influence on activity monitoring.
The remainder of the paper proceeds as follows:
Section 2 gives a brief overview of existing work on activity monitoring using NILM.
Section 3 describes the details of the proposed framework and its different modules.
Section 4 presents the data used as well as the methodology adopted to evaluate our contribution where the results are illustrated in
Section 5.
Section 6 analyzes the obtained results and reveals the main findings of our work.
Section 7 concludes by presenting the main limitations of the current work and suggestions for future enhancements.
3. Proposed Framework
Modelling and tracking human behaviour is a complex process that includes several aspects. In the scope of our contribution, we consider three main aspects. First, individuals have different routines and lifestyles, which highlights the importance of defining a custom daily profile, for each user, based on a pre-recorded historical energy consumption. This profile is the base for scoring a new day and deciding its normality. Demonstrative examples are different sleeping, eating, and waking up times. Second, human routines are subject to change. The profile must thus be adaptable to this dynamic character of human behaviour. In this regard, we differentiate between variations and deviations in the behaviour [
16]. Variations are just new habits and routines adopted by the subjects. These new variations need to be included in the profile of the user. On the other hand, deviations are categorical changes in the routines translating into a potential abnormal pattern. An illustrative scenario for this case is cooking breakfast. A change in the breakfast time for several consequent days is considered a variation. However, the sudden cancellation of breakfast time would be a deviation that should be reported to an external agent for further decision-making. In this case, the role of the external agent is to confirm the abnormality of this cancellation through further investigations. Third, we use the feedback provided to update the profile in the case of misidentified anomalies. It would allow overcoming the non-availability of annotated energy datasets specifying anomalous events. The possibility of continuous integration of feedback from an external agent (e.g., health care professional or family member) would also help to improve future predictions and gather data labels in real-time.
The overall architecture of the proposed framework is illustrated in
Figure 1. It is composed of three modules having independent tasks: a load disaggregation module, an activity monitoring module, as well as a feedback management module. In real implementations, the load disaggregation and activity monitoring modules can run locally within the household in the case of privacy-concerned users. In this regard, cost efficient implementations can be achieved through extending existing open source solutions. They can come as extra-modules to the OpenHAB (
https://www.openhab.org/, accessed on 30 December 2021) platform, for example, as it already contains a load disaggregation module developed in a previous work of the authors [
15]. Moreover, due to the sensitivity of the data, the communication with the external agent in real scenarios should be protected and secured using advanced smart grid security schemes (such as [
41]), providing both low communication and computation costs.
The load disaggregation module is responsible for identifying features relative to the activation of different appliances. As an input, it uses the aggregate power of the whole household obtained with a single metering point, the smart electrical meter. The consumption of individual appliances is inferred afterward using load disaggregation techniques on an hourly basis. For active appliances, a summary of the current activation is extracted containing both contextual information (e.g., temporal information, weather information, other sensors information) and operational information (e.g., max power consumption). The operational information is related to the operational characteristics of the appliances. The goal from using these pieces of information is to confirm that the device used for monitoring an activity is not defective. For demonstration purposes, we only use the temporal data as contextual information in the remainder of the manuscript represented by: the start time of use, duration of use, the day of the week, and day of the month.
The activity monitoring module relies on the features created by the load disaggregation module to generate recurrent reports and anomalies that are transferred to an external agent to intervene whenever required. In regard to the first considered aspect (i.e., the heterogeneous routines of individuals), we suggest a two-phase functional mode for this module. The first phase is an observation phase in which the framework only enables module one and uses its outputs to build a custom consumption profile of the occupant. After this period, the framework becomes fully operational and can detect anomalies automatically.
The observation phase is based on passive monitoring where only daily reports are generated, and activity patterns are saved. For each day during this period, the daily routines are recorded for a set of pre-defined activities considering two levels. The first level is the activity level that is modeled using activity curves [
42] taking into consideration two main aspects: the time of performing an activity and its duration. We argue that the combination of these two pieces of temporal information constitutes an interesting tool for monitoring the activities on a daily basis as they summarise the human interaction with the appliances represented by the ON event and the OFF event. Both features characterising an activity are inferred based on appliances involved in the activity where the mapping between the activities and appliances is pre-defined. The second level is the appliance level that can be represented, for example, using self-similarity measures [
43]. The activity curves represent activity distributions along a given day where the probability distribution is defined as the normalised time an individual spends on an activity during a given period [
42]. The duration of an activity during this specific period is the aggregation of the time spent on each related appliance. As previously mentioned, the custom user profile is constructed during this phase where the distribution of each activity is saved in a database of observations ∑. A summary representing the profile of the occupant can be extracted by aggregating the observations using the mean. It is worth mentioning that a more elaborated summary of the daily distributions would consider hierarchical aggregation based on different temporal levels. For example, an interesting approach would be to aggregate according to day time first (morning, afternoon, evening, night) or day of the week resulting in hierarchical activity curves.
During the second phase (i.e., the monitoring phase), the curve of each activity is calculated for the current day. At the end of the day, these curves are compared to the database of distributions recorded during the observation phase. The comparison measure used is the Jensen–Shannon Divergence (
JSD) calculated as per Equation (
1), which serves to measure the similarity between two or more distributions:
The
are weights attributed to different observed days. In our case, they are used to give more importance to distances related to days where the external agent provided feedback. In particular, if
is the number of days where the external agent provided feedback and
is the number of days with no feedback, the
is calculated as follows:
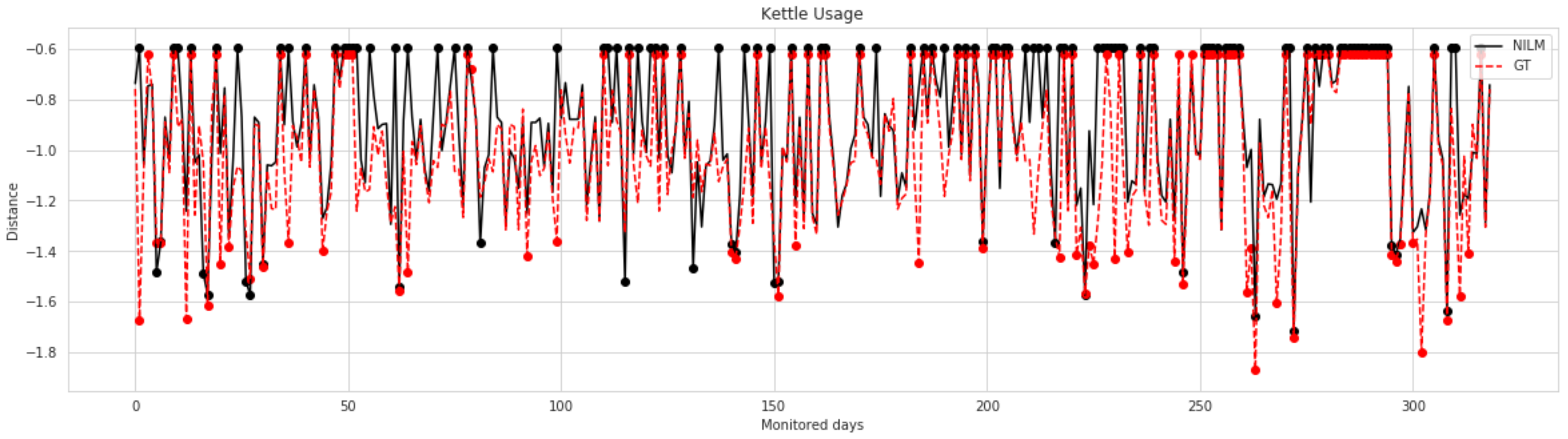
The comparison procedure relies on the Inter-quantile Rule (IQR) to decide about the normality of the current day. The distance between each observed day and the rest of the data is calculated to estimate the distribution of the distance in the case of the normal days. The IQR is calculated as the difference between the third and first quantile . Under the assumption of normal distribution, the interval [, ] contains 99.7% of the data. Thus, if the values of the distance of the current day fall inside this interval, it is considered a normal day with no deviations. On the other hand, if it falls outside of this interval, the current day is considered anomalous, and the activations of appliances related to the activity are further analysed.
Appliance anomaly detection is performed only in days that were classified as anomalous (see
Figure 2) to provide a meaning-full interpretation of the causes behind the anomaly and provide detailed report about the events of the considered day. For this purpose, we suggest the use of a similarity-based approach [
43] that relies on the calculation of self similarity matrices encoding the similarity (distance) of each observed activation to other historical activations. A threshold measure is used to decide if an activation is a variation (i.e., a small change in the routines) or a deviation (i.e., an anomaly) from the normal consumption pattern. The threshold, in this case, is also calculated using the inter-quantile range rule. More precisely, the threshold is directly deduced from the self-similarity matrices using the inter-quantile range rule.
Anomalous days result in notifying an external agent for further decision-making. The communication with the external agent is performed in an asynchronous mode. The notifications are sent to the external agent who has the choice to provide feedback or not to the framework. The framework continues thus to be functional even for days where the feedback was not received. In this case, it considers that the reports provided are correct and updates its historical data accordingly. This update allows the framework to consider recent patterns when evaluating a new day in order to take into consideration seasonal change in the routines. In the opposite case (i.e., if the feedback is received), if the agent finds the anomaly irrelevant, they can forward their decision to the framework. For interpretable feedback, we propose four classes of notifications: (1) Abnormal usage time which is related to an abnormal activation of an appliance during the day, (2) usage during the night, and (3) absence of activity during a day. Providing interpretable information about the anomalies would help to guide the external agent in establishing diagnosis.
The feedback provided by the external agent is integrated in the framework through an update of the database of historical consumption. The new activations are added to the existing database of historical events using a forgetting (vanishing) factor that favours the replacement of old and unlabelled entries. The replacement procedure is straightforward. It takes into consideration two main metrics: (1) how old the information is, (2) the distance to the rest of the historical data, and (3) external agent feedback. If all the days included in the observation database have feedback, the framework will choose the oldest most divergent day to be replaced. The replacement of a day i operates on two levels. First, the self-similarity matrices are updated by replacing the line i and row i with distance measures related to the current day. Second, the activity curve of the day i is tagged as having feedback and being replaced by the current day distribution.
6. Discussion
The manuscript at hand proposed a new activity monitoring framework using NILM and suggested an evaluation protocol that considers different modules of the framework. Accordingly, the evaluation results, on two case studies from a publicly available dataset, were presented to simulate a realistic scenario.
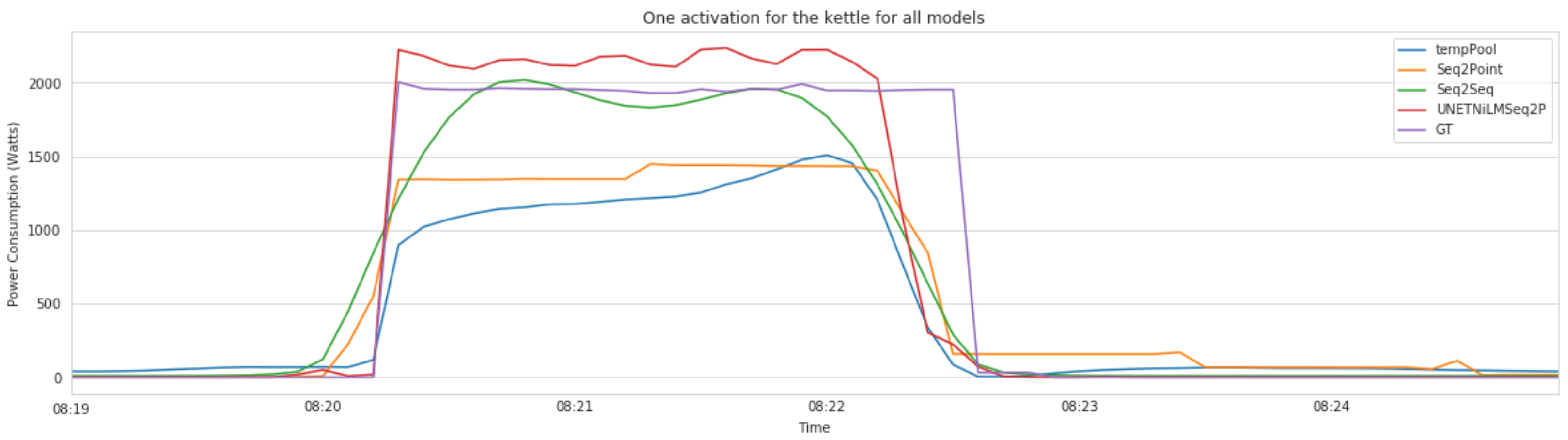
The evaluation of the first module relative to the load disaggregation using both classical and deep approaches revealed that NILM models provide good results in identifying the kettle’s activations and power consumption. Notably, deep models provided the best performance for this module. Compared to classical models, deep baselines demonstrated their competitiveness, confirming findings from recent literature [
32]. Even with the unseen scenario, these models yielded acceptable performance. This finding provides encouraging evidence to transfer learning from available houses not relative to adults living alone. Moreover, advanced models, such as the UNET, demonstrated very competitive performance in estimating power consumption. The authors argue that the UNET model is particularly interesting since it performs both power and state predictions (multi-task model) with uncertainty estimation. Unfortunately, in its current version, the proposed framework does not benefit from the uncertainty generated by the model. Nonetheless, the authors plan to include it in future versions.
The evaluation of the second component relative to the activity monitoring also yielded acceptable performance. The activity curves demonstrated good representativeness of the overall activity patterns. Nevertheless, we argue that they are more suitable for activities that rely on frequently used appliances during a single day. We stress that it could be the case that they are less effective in activities inferred based on less frequently used appliances, such as the washing machine. A more elaborated version of the proposed framework would rely on hierarchical activity curves, including other temporal dimensions such as the day of the week. Adapting established methods for activity monitoring or combining them demonstrated good results but remains subject to future improvements. The activity monitoring of older adults remains a sensitive health care service that requires more robust and elaborated models to help mitigate the number of errors. Moreover, using two case studies demonstrated that the definition of anomalous behaviour remains difficult and dependent on the context.
On the other hand, the evaluation of the activity monitoring module considering both real data and NILM predictions allowed to assess the propagated error that was estimated to be around 10% for the f1-measure. This difference shows encouraging results for using deep NILM models in activity monitoring and demonstrates that more elaborated models (both NILM and monitoring models) would help to mitigate this error. The presented case studies also highlighted the sensitivity of this module to the data recorded during the observation phase.
The proposed framework showed potential for benefiting from the new electrical grid in active and assisted living. To the best of the authors’ knowledge, this is the first application of deep NILM models in activity monitoring with an explicit assessment of their effect on the activity monitoring algorithms. Nevertheless, a source of limitation in the proposed solution is its high dependency on the data recorded during the observation phase that must represent the average occupant’s routine. Moreover, the scope of this study was limited in terms of the set of monitored activities. The authors intend to consider a more extensive set of activities with more appliances in future work. Furthermore, we argue that gaining a deeper understanding of the challenges imposed by the problem can only be enabled with more established datasets. More particularly, a significant obstacle in evaluating the applicability of NILM in activity monitoring is the non-availability of annotated data. The authors overcame this problem by introducing abnormal synthetic usage and annotating available suspicious usage time. The generated data allowed the evaluation of the proposed framework on data from two different houses. However, this aspect remains the main limitation for the evaluation protocol adopted in the experimental setup and a major obstacle towards the generalizability of these results. We urge the need to establish more elaborated datasets to develop more complex scenarios and more extensive evaluations of activity monitoring approaches based on NILM.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}