
Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances


 ,
,
Abstract
:1. Introduction
- (i)
- Firstly, we give an overview of the background of the human activity recognition research field, including the traditional and novel applications where the research community is focusing, the sensors that are utilized in these applications, as well as widely-used publicly available datasets.
- (ii)
- Then, after briefly introducing the popular mainstream deep learning algorithms, we give a review of the relevant papers over the years using deep learning in human activity recognition using wearables. We categorize the papers in our scope according to the algorithm (autoencoder, CNN, RNN, etc.). In addition, we compare different DL algorithms in terms of the accuracy of the public dataset, pros and cons, deployment, and high-level model selection criteria.
- (iii)
- We provide a comprehensive systematic review on the current issues, challenges, and opportunities in the HAR domain and the latest advancements towards solutions. At last, honorably and humbly, we make our best to shed light on the possible future directions with the hope to benefit students and young researchers in this field.
2. Methodology
2.1. Research Question
2.2. Research Scope
2.3. Taxonomy of Human Activity Recognition
3. Related Work
4. Human Activity Recognition Overview
4.1. Applications
4.1.1. Wearables in Fitness and Lifestyle
4.1.2. Wearables in Healthcare and Rehabilitation
4.1.3. Wearables in Human Computer Interaction (HCI)
4.2. Wearable Sensors
4.2.1. Inertial Measurement Unit (IMU)
4.2.2. Electrocardiography (ECG) and Photoplethysmography (PPG)
4.2.3. Electromyography (EMG)
4.2.4. Mechanomyography (MMG)
4.3. Major Datasets
5. Deep Learning Approaches
5.1. Autoencoder
5.2. Deep Belief Network (DBN)
5.3. Convolutional Neural Network (CNN)
5.4. Recurrent Neural Network (RNN)
5.5. Deep Reinforcement Learning (DRL)
5.6. Generative Adversarial Network (GAN)
5.7. Hybrid Models
5.8. Summary and Selection of Suitable Methods
6. Challenges and Opportunities
- What are the challenges in data acquisition? How do we resolve them?
- What are the challenges in label acquisition? What are the current methods?
- What are the challenges in modeling? What are potential solutions?
- What are the challenges in model deployment? What are potential opportunities?
6.1. Challenges in Data Acquisition
6.1.1. The Need for More Data
6.1.2. Data Quality and Missing Data
6.1.3. Privacy Protection
6.2. Challenges in Label Acquisition
6.2.1. Shortage of Labeled Data
6.2.2. Issues of In-the-Field Dataset
6.3. Challenges in Modeling
6.3.1. Data Segmentation
6.3.2. Semantically Complex Activity Recognition
6.3.3. Model Generalizability
6.3.4. Model Robustness
6.4. Challenges in Model Deployment
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vogels, E.A. About One-in-five Americans Use a Smart Watch or Fitness Tracker. Available online: https://www.pewresearch.org/fact-tank/2020/01/09/about-one-in-five-americans-use-a-smart-watch-or-fitness-tracker/ (accessed on 10 February 2022).
- Research, M. Wearable Devices Market by Product Type (Smartwatch, Earwear, Eyewear, and others), End-Use Industry (Consumer Electronics, Healthcare, Enterprise and Industrial, Media and Entertainment), Connectivity Medium, and Region—Global Forecast to 2025. Available online: https://www.meticulousresearch.com/product/wearable-devices-market-5050 (accessed on 10 February 2022).
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Schäfer, A.M.; Zimmermann, H.G. Recurrent Neural Networks Are Universal Approximators. In Artificial Neural Networks—ICANN 2006; Kollias, S.D., Stafylopatis, A., Duch, W., Oja, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 632–640. [Google Scholar]
- Zhou, D.X. Universality of deep convolutional neural networks. Appl. Comput. Harmon. Anal. 2020, 48, 787–794. [Google Scholar] [CrossRef] [Green Version]
- Wearable Technology Database. Available online: https://data.world/crowdflower/wearable-technology-database (accessed on 10 February 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. 2016. Available online: http://www.deeplearningbook.org (accessed on 10 February 2022).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction. 2018. Available online: http://www.incompleteideas.net/book/the-book-2nd.html (accessed on 10 February 2022).
- Transparent Reporting of Systematic Reviews and Meta-Analyses. Available online: http://www.prisma-statement.org/ (accessed on 10 February 2022).
- Kiran, S.; Khan, M.A.; Javed, M.Y.; Alhaisoni, M.; Tariq, U.; Nam, Y.; Damasevicius, R.; Sharif, M. Multi-Layered Deep Learning Features Fusion for Human Action Recognition. Comput. Mater. Contin. 2021, 69, 4061–4075. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges, and Opportunities. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human activity recognition with smartphone and wearable sensors using deep learning techniques: A review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Booth, F.W.; Roberts, C.K.; Laye, M.J. Lack of exercise is a major cause of chronic diseases. Compr. Physiol. 2011, 2, 1143–1211. [Google Scholar]
- Bauman, A.E.; Reis, R.S.; Sallis, J.F.; Wells, J.C.; Loos, R.J.; Martin, B.W. Correlates of physical activity: Why are some people physically active and others not? Lancet 2012, 380, 258–271. [Google Scholar] [CrossRef]
- Diaz, K.M.; Krupka, D.J.; Chang, M.J.; Peacock, J.; Ma, Y.; Goldsmith, J.; Schwartz, J.E.; Davidson, K.W. Fitbit®: An accurate and reliable device for wireless physical activity tracking. Int. J. Cardiol. 2015, 185, 138–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.; Pande, A.; Mohapatra, P.; Han, J.J. Using Deep Learning for Energy Expenditure Estimation with wearable sensors. In Proceedings of the 2015 17th International Conference on E-health Networking, Application Services (HealthCom), Boston, MA, USA, 14–17 October 2015; pp. 501–506. [Google Scholar] [CrossRef]
- Brown, V.; Moodie, M.; Herrera, A.M.; Veerman, J.; Carter, R. Active transport and obesity prevention–a transportation sector obesity impact scoping review and assessment for Melbourne, Australia. Prev. Med. 2017, 96, 49–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bisson, A.; Lachman, M.E. Behavior Change with Fitness Technology in Sedentary Adults: A Review of the Evidence for Increasing Physical Activity. Front. Public Health 2017, 4, 289. [Google Scholar] [CrossRef] [Green Version]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia (MM), Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 1307–1310. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human Activity Recognition with Smartphone Sensors Using Deep Learning Neural Networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar] [CrossRef]
- Wang, L.; Gjoreski, H.; Ciliberto, M.; Mekki, S.; Valentin, S.; Roggen, D. Benchmarking the SHL Recognition Challenge with Classical and Deep-Learning Pipelines. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers (UbiComp), Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 1626–1635. [Google Scholar] [CrossRef]
- Li, S.; Li, C.; Li, W.; Hou, Y.; Cook, C. Smartphone-sensors Based Activity Recognition Using IndRNN. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, (UbiComp), Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 1541–1547. [Google Scholar] [CrossRef]
- Jeyakumar, J.V.; Lee, E.S.; Xia, Z.; Sandha, S.S.; Tausik, N.; Srivastava, M. Deep Convolutional Bidirectional LSTM Based Transportation Mode Recognition. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers (UbiComp), Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 1606–1615. [Google Scholar] [CrossRef]
- Wang, K.; He, J.; Zhang, L. Attention-based Convolutional Neural Network for Weakly Labeled Human Activities Recognition with Wearable Sensors. IEEE Sens. J. 2019, 19, 7598–7604. [Google Scholar] [CrossRef] [Green Version]
- Hammerla, N.Y.; Fisher, J.M.; Andras, P.; Rochester, L.; Walker, R.; Plotz, T. PD Disease State Assessment in Naturalistic Environments Using Deep Learning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI), Austin, TX, USA, 25–30 January 2015; pp. 1742–1748. [Google Scholar]
- Eskofier, B.M.; Lee, S.I.; Daneault, J.; Golabchi, F.N.; Ferreira-Carvalho, G.; Vergara-Diaz, G.; Sapienza, S.; Costante, G.; Klucken, J.; Kautz, T.; et al. Recent machine learning advancements in sensor-based mobility analysis: Deep learning for Parkinson’s disease assessment. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Lake Buena Vista (Orlando), FL, USA, 16–20 August 2016; pp. 655–658. [Google Scholar] [CrossRef]
- Zhang, A.; Cebulla, A.; Panev, S.; Hodgins, J.; De la Torre, F. Weakly-supervised learning for Parkinson’s Disease tremor detection. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 143–147. [Google Scholar] [CrossRef]
- Mohammadian Rad, N.; Van Laarhoven, T.; Furlanello, C.; Marchiori, E. Novelty Detection Using Deep Normative Modeling for IMU-BasedAbnormal Movement Monitoring in Parkinson’s Disease and Autism Spectrum Disorders. Sensors 2018, 18, 3533. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.B.; Lee, W.W.; Kim, A.; Lee, H.J.; Park, H.Y.; Jeon, H.S.; Kim, S.K.; Jeon, B.; Park, K.S. Wrist sensor-based tremor severity quantification in Parkinson’s disease using convolutional neural network. Comput. Biol. Med. 2018, 95, 140–146. [Google Scholar] [CrossRef]
- Um, T.T.; Pfister, F.M.J.; Pichler, D.; Endo, S.; Lang, M.; Hirche, S.; Fietzek, U.; Kulić, D. Data Augmentation of Wearable Sensor Data for Parkinson’s Disease Monitoring Using Convolutional Neural Networks. In Proceedings of the 19th ACM International Conference on Multimodal Interaction (ICMI), Glasgow, UK, 13–17 November 2017; ACM: New York, NY, USA, 2017; pp. 216–220. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Nemati, E.; Vatanparvar, K.; Nathan, V.; Ahmed, T.; Rahman, M.M.; McCaffrey, D.; Kuang, J.; Gao, J.A. Listen2Cough: Leveraging End-to-End Deep Learning Cough Detection Model to Enhance Lung Health Assessment Using Passively Sensed Audio. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–22. [Google Scholar] [CrossRef]
- Zhang, S.; Nemati, E.; Ahmed, T.; Rahman, M.M.; Kuang, J.; Gao, A. A Novel Multi-Centroid Template Matching Algorithm and Its Application to Cough Detection. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine Biology Society (EMBC), Guadalajara, Mexico, 31 October–4 November 2021; pp. 7598–7604. [Google Scholar] [CrossRef]
- Nemati, E.; Zhang, S.; Ahmed, T.; Rahman, M.M.; Kuang, J.; Gao, A. CoughBuddy: Multi-Modal Cough Event Detection Using Earbuds Platform. In Proceedings of the 2021 IEEE 17th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, S.; Nemati, E.; Dinh, M.; Folkman, N.; Ahmed, T.; Rahman, M.; Kuang, J.; Alshurafa, N.; Gao, A. CoughTrigger: Earbuds IMU Based Cough Detection Activator Using An Energy-efficient Sensitivity-prioritized Time Series Classifier. arXiv 2021, arXiv:2111.04185. [Google Scholar]
- Gao, Y.; Long, Y.; Guan, Y.; Basu, A.; Baggaley, J.; Ploetz, T. Towards Reliable, Automated General Movement Assessment for Perinatal Stroke Screening in Infants Using Wearable Accelerometers. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 12:1–12:22. [Google Scholar] [CrossRef] [Green Version]
- Ghandeharioun, A.; Fedor, S.; Sangermano, L.; Ionescu, D.; Alpert, J.; Dale, C.; Sontag, D.; Picard, R. Objective assessment of depressive symptoms with machine learning and wearable sensors data. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 325–332. [Google Scholar] [CrossRef]
- Phinyomark, A.; Scheme, E. EMG Pattern Recognition in the Era of Big Data and Deep Learning. Big Data Cogn. Comput. 2018, 2, 21. [Google Scholar] [CrossRef] [Green Version]
- Meattini, R.; Benatti, S.; Scarcia, U.; De Gregorio, D.; Benini, L.; Melchiorri, C. An sEMG-Based Human–Robot Interface for Robotic Hands Using Machine Learning and Synergies. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 1149–1158. [Google Scholar] [CrossRef]
- Parajuli, N.; Sreenivasan, N.; Bifulco, P.; Cesarelli, M.; Savino, S.; Niola, V.; Esposito, D.; Hamilton, T.J.; Naik, G.R.; Gunawardana, U.; et al. Real-time EMG based pattern recognition control for hand prostheses: A review on existing methods, challenges and future implementation. Sensors 2019, 19, 4596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Samuel, O.W.; Asogbon, M.G.; Geng, Y.; Al-Timemy, A.H.; Pirbhulal, S.; Ji, N.; Chen, S.; Fang, P.; Li, G. Intelligent EMG pattern recognition control method for upper-limb multifunctional prostheses: Advances, current challenges, and future prospects. IEEE Access 2019, 7, 10150–10165. [Google Scholar] [CrossRef]
- Zhao, H.; Ma, Y.; Wang, S.; Watson, A.; Zhou, G. MobiGesture: Mobility-aware hand gesture recognition for healthcare. Smart Health 2018, 9–10, 129–143. [Google Scholar] [CrossRef]
- Shin, S.; Sung, W. Dynamic hand gesture recognition for wearable devices with low complexity recurrent neural networks. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 2274–2277. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Xue, Q.; Waghmare, A.; Meng, R.; Jain, S.; Han, Y.; Li, X.; Cunefare, K.; Ploetz, T.; Starner, T.; et al. FingerPing: Recognizing Fine-grained Hand Poses Using Active Acoustic On-body Sensing. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI’18), Montreal, QC, Canada, 21–26 April 2018; ACM: New York, NY, USA, 2018; pp. 437:1–437:10. [Google Scholar] [CrossRef]
- Pacchierotti, C.; Salvietti, G.; Hussain, I.; Meli, L.; Prattichizzo, D. The hRing: A wearable haptic device to avoid occlusions in hand tracking. In Proceedings of the 2016 IEEE Haptics Symposium (HAPTICS), Philadelphia, PA, USA, 8–11 April 2016; pp. 134–139. [Google Scholar] [CrossRef]
- Sundaram, S.; Kellnhofer, P.; Li, Y.; Zhu, J.Y.; Torralba, A.; Matusik, W. Learning the signatures of the human grasp using a scalable tactile glove. Nature 2019, 569, 698–702. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.; Kim, K. Development of a wearable HCI controller through sEMG & IMU sensor fusion. In Proceedings of the 2016 13th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Sofitel Xian on Renmin Square, Xi’an, China, 19–22 August 2016; pp. 83–87. [Google Scholar] [CrossRef]
- Kalantarian, H.; Alshurafa, N.; Le, T.; Sarrafzadeh, M. Monitoring eating habits using a piezoelectric sensor-based necklace. Comput. Biol. Med. 2015, 58, 46–55. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, Y.; Nguyen, D.T.; Xu, R.; Sen, S.; Hester, J.; Alshurafa, N. NeckSense: A Multi-Sensor Necklace for Detecting Eating Activities in Free-Living Conditions. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Chen, T.; Li, Y.; Tao, S.; Lim, H.; Sakashita, M.; Zhang, R.; Guimbretiere, F.; Zhang, C. NeckFace: Continuously Tracking Full Facial Expressions on Neck-Mounted Wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–31. [Google Scholar] [CrossRef]
- Giorgi, G.; Martinelli, F.; Saracino, A.; Sheikhalishahi, M. Try Walking in My Shoes, if You Can: Accurate Gait Recognition Through Deep Learning. In Computer Safety, Reliability, and Security; Tonetta, S., Schoitsch, E., Bitsch, F., Eds.; Springer: Cham, Switzerland, 2017; pp. 384–395. [Google Scholar]
- Shi, Y.; Manco, M.; Moyal, D.; Huppert, G.; Araki, H.; Banks, A.; Joshi, H.; McKenzie, R.; Seewald, A.; Griffin, G.; et al. Soft, stretchable, epidermal sensor with integrated electronics and photochemistry for measuring personal UV exposures. PLoS ONE 2018, 13, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Chung, S.; Lim, J.; Noh, K.J.; Gue Kim, G.; Jeong, H.T. Sensor Positioning and Data Acquisition for Activity Recognition using Deep Learning. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018; pp. 154–159. [Google Scholar] [CrossRef]
- Laput, G.; Xiao, R.; Harrison, C. ViBand: High-Fidelity Bio-Acoustic Sensing Using Commodity Smartwatch Accelerometers. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology (UIST’16), Tokyo, Japan, 16–19 October 2016; ACM: New York, NY, USA, 2016; pp. 321–333. [Google Scholar] [CrossRef]
- Laput, G.; Harrison, C. Sensing Fine-Grained Hand Activity with Smartwatches. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI’19), Glasgow, UK, 4–9 May, 2019; ACM: New York, NY, USA, 2019; pp. 338:1–338:13. [Google Scholar] [CrossRef]
- Electromyography. Electromyography—Wikipedia, The Free Encyclopedia. 2010. Available online: https://en.wikipedia.org/wiki/Electromyography (accessed on 10 March 2020).
- Zia ur Rehman, M.; Waris, A.; Gilani, S.O.; Jochumsen, M.; Niazi, I.K.; Jamil, M.; Farina, D.; Kamavuako, E.N. Multiday EMG-based classification of hand motions with deep learning techniques. Sensors 2018, 18, 2497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Triwiyanto, T.; Pawana, I.P.A.; Purnomo, M.H. An improved performance of deep learning based on convolution neural network to classify the hand motion by evaluating hyper parameter. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1678–1688. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Huang, Q.; Wang, D.; Gao, L. A CNN-SVM combined model for pattern recognition of knee motion using mechanomyography signals. J. Electromyogr. Kinesiol. 2018, 42, 136–142. [Google Scholar] [CrossRef] [PubMed]
- Meagher, C.; Franco, E.; Turk, R.; Wilson, S.; Steadman, N.; McNicholas, L.; Vaidyanathan, R.; Burridge, J.; Stokes, M. New advances in mechanomyography sensor technology and signal processing: Validity and intrarater reliability of recordings from muscle. J. Rehabil. Assist. Technol. Eng. 2020, 7, 2055668320916116. [Google Scholar] [CrossRef] [Green Version]
- Khalifa, S.; Lan, G.; Hassan, M.; Seneviratne, A.; Das, S.K. Harke: Human activity recognition from kinetic energy harvesting data in wearable devices. IEEE Trans. Mob. Comput. 2017, 17, 1353–1368. [Google Scholar] [CrossRef]
- Cha, Y.; Kim, H.; Kim, D. Flexible piezoelectric sensor-based gait recognition. Sensors 2018, 18, 468. [Google Scholar] [CrossRef] [Green Version]
- Massé, F.; Gonzenbach, R.R.; Arami, A.; Paraschiv-Ionescu, A.; Luft, A.R.; Aminian, K. Improving activity recognition using a wearable barometric pressure sensor in mobility-impaired stroke patients. J. Neuroeng. Rehabil. 2015, 12, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Barna, A.; Masum, A.K.M.; Hossain, M.E.; Bahadur, E.H.; Alam, M.S. A study on human activity recognition using gyroscope, accelerometer, temperature and humidity data. In Proceedings of the 2019 International conference on electrical, computer and communication engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Salehzadeh, A.; Calitz, A.P.; Greyling, J. Human activity recognition using deep electroencephalography learning. Biomed. Signal Process. Control 2020, 62, 102094. [Google Scholar] [CrossRef]
- Ramos-Garcia, R.I.; Tiffany, S.; Sazonov, E. Using respiratory signals for the recognition of human activities. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Lake Buena Vista (Orlando), FL, USA, 16–20 August 2016; pp. 173–176. [Google Scholar]
- Filippoupolitis, A.; Takand, B.; Loukas, G. Activity recognition in a home setting using off the shelf smart watch technology. In Proceedings of the 2016 15th International Conference on Ubiquitous Computing and Communications and 2016 International Symposium on Cyberspace and Security (IUCC-CSS), Granada, Spain, 14–16 December 2016; pp. 39–44. [Google Scholar]
- Jin, Y.; Gao, Y.; Zhu, Y.; Wang, W.; Li, J.; Choi, S.; Li, Z.; Chauhan, J.; Dey, A.K.; Jin, Z. SonicASL: An Acoustic-based Sign Language Gesture Recognizer Using Earphones. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–30. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I. Transfer learning for improved audio-based human activity recognition. Biosensors 2018, 8, 60. [Google Scholar] [CrossRef] [Green Version]
- Hamid, A.; Brahim, A.; Mohammed, O. A survey of activity recognition in egocentric lifelogging datasets. In Proceedings of the 2017 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 19–20 April 2017; pp. 1–8. [Google Scholar]
- Ryoo, M.S.; Matthies, L. First-Person Activity Recognition: What Are They Doing to Me? In Proceedings of the2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2730–2737. [Google Scholar]
- Alharbi, R.; Stump, T.; Vafaie, N.; Pfammatter, A.; Spring, B.; Alshurafa, N. I can’t be myself: Effects of wearable cameras on the capture of authentic behavior in the wild. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–40. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, R.; Tolba, M.; Petito, L.C.; Hester, J.; Alshurafa, N. To Mask or Not to Mask? Balancing Privacy with Visual Confirmation Utility in Activity-Oriented Wearable Cameras. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Wang, J.; Shou, W.; Ngo, T.; Sadick, A.M.; Wang, X. Computer vision techniques in construction: A critical review. Arch. Comput. Methods Eng. 2021, 28, 3383–3397. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate Activity Recognition in a Home Setting. In Proceedings of the 10th International Conference on Ubiquitous Computing (UbiComp’08), Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar] [CrossRef]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart Devices Are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems (SenSys’15), Seoul, Korea, 1–4 November 2015; pp. 127–140. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B.; Tunçel, O. Comparative Study on Classifying Human Activities with Miniature Inertial and Magnetic Sensors. Pattern Recogn. 2010, 43, 3605–3620. [Google Scholar] [CrossRef]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In International Workshop on Ambient Assisted Living; Springer: Berlin/Heidelberg, Germany, 2014; pp. 91–98. [Google Scholar]
- Banos, O.; Villalonga, C.; Garcia, R.; Saez, A.; Damas, M.; Holgado-Terriza, J.A.; Lee, S.; Pomares, H.; Rojas, I. Design, implementation and validation of a novel open framework for agile development of mobile health applications. Biomed. Eng. Online 2015, 14, S6. [Google Scholar] [CrossRef] [Green Version]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen,, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef] [Green Version]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J.M. Towards Physical Activity Recognition Using Smartphone Sensors. In Proceedings of the 2013 IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 2013 IEEE 10th International Conference on Autonomic and Trusted Computing, DC, USA, 18–21 December 2013; pp. 80–87. [Google Scholar] [CrossRef] [Green Version]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A Daily Activity Dataset for Ubiquitous Activity Recognition Using Wearable Sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing (UbiComp’12), Pittsburgh, PA, USA, 5–8 September 2012; pp. 1036–1043. [Google Scholar] [CrossRef]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing Detailed Human Context in the Wild from Smartphones and Smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Kawaguchi, N.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Inoue, S.; Kawahara, Y.; Sumi, Y.; Nishio, N. HASC Challenge: Gathering Large Scale Human Activity Corpus for the Real-world Activity Understandings. In Proceedings of the 2nd Augmented Human International Conference, (AH’11), Tokyo, Japan, 13 March 2011; pp. 27:1–27:5. [Google Scholar] [CrossRef]
- Weiss, G.M.; Lockhart, J.W.; Pulickal, T.T.; McHugh, P.T.; Ronan, I.H.; Timko, J.L. Actitracker: A Smartphone-Based Activity Recognition System for Improving Health and Well-Being. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 682–688. [Google Scholar] [CrossRef]
- Bruno, B.; Mastrogiovanni, F.; Sgorbissa, A. A public domain dataset for ADL recognition using wrist-placed accelerometers. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; pp. 738–743. [Google Scholar] [CrossRef]
- Zhang, Z.; Pi, Z.; Liu, B. TROIKA: A General Framework for Heart Rate Monitoring Using Wrist-Type Photoplethysmographic Signals During Intensive Physical Exercise. IEEE Trans. Biomed. Eng. 2015, 62, 522–531. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial Sensors. ACM Comput. Surv. 2014, 46, 33:1–33:33. [Google Scholar] [CrossRef]
- Kyritsis, K.; Tatli, C.L.; Diou, C.; Delopoulos, A. Automated analysis of in meal eating behavior using a commercial wristband IMU sensor. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 2843–2846. [Google Scholar] [CrossRef]
- Chauhan, J.; Hu, Y.; Seneviratne, S.; Misra, A.; Seneviratne, A.; Lee, Y. BreathPrint: Breathing Acoustics-based User Authentication. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys’17), Niagara Falls, NY, USA, 19–23 June 2017; pp. 278–291. [Google Scholar] [CrossRef]
- Zappi, P.; Lombriser, C.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Tröster, G. Activity Recognition from On-body Sensors: Accuracy-power Trade-off by Dynamic Sensor Selection. In Proceedings of the 5th European Conference on Wireless Sensor Networks (EWSN’08), Bologna, Italy, 30 January–1 February 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 17–33. [Google Scholar]
- Bachlin, M.; Plotnik, M.; Roggen, D.; Maidan, I.; Hausdorff, J.M.; Giladi, N.; Troster, G. Wearable Assistant for Parkinson’s Disease Patients with the Freezing of Gait Symptom. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 436–446. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: www.cs.ucr.edu/eamonn/timeseriesdata/ (accessed on 10 February 2022).
- Bagnall, A.; Dau, H.A.; Lines, J.; Flynn, M.; Large, J.; Bostrom, A.; Southam, P.; Keogh, E. The UEA multivariate time series classification archive. arXiv 2018, arXiv:1811.00075. [Google Scholar]
- Liu, J.; Wang, Z.; Zhong, L.; Wickramasuriya, J.; Vasudevan, V. uWave: Accelerometer-based personalized gesture recognition and its applications. In Proceedings of the 2009 IEEE International Conference on Pervasive Computing and Communications, Galveston, TX, USA, 9–13 March 2009; pp. 1–9. [Google Scholar] [CrossRef]
- Gjoreski, H.; Ciliberto, M.; Wang, L.; Ordonez Morales, F.J.; Mekki, S.; Valentin, S.; Roggen, D. The University of Sussex-Huawei Locomotion and Transportation Dataset for Multimodal Analytics with Mobile Devices. IEEE Access 2018, 6, 42592–42604. [Google Scholar] [CrossRef]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR Time Series Archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Siddiqui, N.; Chan, R.H.M. A wearable hand gesture recognition device based on acoustic measurements at wrist. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 4443–4446. [Google Scholar] [CrossRef]
- Wang, H.; Li, L.; Chen, H.; Li, Y.; Qiu, S.; Gravina, R. Motion recognition for smart sports based on wearable inertial sensors. In EAI International Conference on Body Area Networks; Springer: Cham, Switzerland, 2019; pp. 114–124. [Google Scholar]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Moya Rueda, F.; Grzeszick, R.; Fink, G.A.; Feldhorst, S.; Ten Hompel, M. Convolutional neural networks for human activity recognition using body-worn sensors. Informatics 2018, 5, 26. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [Green Version]
- Kim, E. Interpretable and accurate convolutional neural networks for human activity recognition. IEEE Trans. Ind. Informatics 2020, 16, 7190–7198. [Google Scholar] [CrossRef]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Layer-Wise Training Convolutional Neural Networks With Smaller Filters for Human Activity Recognition Using Wearable Sensors. IEEE Sens. J. 2021, 21, 581–592. [Google Scholar] [CrossRef]
- Sun, J.; Fu, Y.; Li, S.; He, J.; Xu, C.; Tan, L. Sequential human activity recognition based on deep convolutional network and extreme learning machine using wearable sensors. J. Sens. 2018, 2018, 8580959. [Google Scholar] [CrossRef]
- Ballard, D.H. Modular Learning in Neural Networks. In Proceedings of the Sixth National Conference on Artificial Intelligence, AAAI’87, Washington, DC, USA, 13–17 July 1987; Volume 1, pp. 279–284. [Google Scholar]
- Varamin, A.A.; Abbasnejad, E.; Shi, Q.; Ranasinghe, D.C.; Rezatofighi, H. Deep auto-set: A deep auto-encoder-set network for activity recognition using wearables. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, New York, NY, USA, 2–7 November 2018; pp. 246–253. [Google Scholar]
- Malekzadeh, M.; Clegg, R.G.; Haddadi, H. Replacement autoencoder: A privacy-preserving algorithm for sensory data analysis. In Proceedings of the 2018 IEEE/ACM Third International Conference on Internet-of-Things Design and Implementation (IoTDI), Orlando, FL, USA, 17–20 April 2018; pp. 165–176. [Google Scholar]
- Jia, G.; Lam, H.K.; Liao, J.; Wang, R. Classification of Electromyographic Hand Gesture Signals using Machine Learning Techniques. Neurocomputing 2020, 401, 236–248. [Google Scholar] [CrossRef]
- Rubio-Solis, A.; Panoutsos, G.; Beltran-Perez, C.; Martinez-Hernandez, U. A multilayer interval type-2 fuzzy extreme learning machine for the recognition of walking activities and gait events using wearable sensors. Neurocomputing 2020, 389, 42–55. [Google Scholar] [CrossRef]
- Gavrilin, Y.; Khan, A. Across-Sensor Feature Learning for Energy-Efficient Activity Recognition on Mobile Devices. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Li, Y.; Shi, D.; Ding, B.; Liu, D. Unsupervised Feature Learning for Human Activity Recognition Using Smartphone Sensors. In Mining Intelligence and Knowledge Exploration; Prasath, R., O’Reilly, P., Kathirvalavakumar, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 99–107. [Google Scholar]
- Almaslukh, B.; AlMuhtadi, J.; Artoli, A. An effective deep autoencoder approach for online smartphone-based human activity recognition. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 160. [Google Scholar]
- Mohammed, S.; Tashev, I. Unsupervised deep representation learning to remove motion artifacts in free-mode body sensor networks. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Eindhoven, The Netherlands, 9–12 May 2017; pp. 183–188. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting Sensory Data Against Sensitive Inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems (W-P2DS’18), Porto, Portugal, 23–26 April 2018; pp. 2:1–2:6. [Google Scholar] [CrossRef] [Green Version]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Mobile Sensor Data Anonymization. In Proceedings of the International Conference on Internet of Things Design and Implementation, (IoTDI’19), Montreal, QC, Canada, 15–18 April 2019; pp. 49–58. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Luo, H.; Wang, Q.; Zhao, F.; Ye, L.; Zhang, Y. A Human Activity Recognition Algorithm Based on Stacking Denoising Autoencoder and LightGBM. Sensors 2019, 19, 947. [Google Scholar] [CrossRef] [Green Version]
- Bai, L.; Yeung, C.; Efstratiou, C.; Chikomo, M. Motion2Vector: Unsupervised learning in human activity recognition using wrist-sensing data. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 537–542. [Google Scholar]
- Saeed, A.; Ozcelebi, T.; Lukkien, J.J. Synthesizing and Reconstructing Missing Sensory Modalities in Behavioral Context Recognition. Sensors 2018, 18, 2967. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, C.; Wang, Z.; Wang, X.; Li, Y. Hand gesture recognition using sparse autoencoder-based deep neural network based on electromyography measurements. In Nano-, Bio-, Info-Tech Sensors, and 3D Systems II; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10597, p. 105971D. [Google Scholar]
- Balabka, D. Semi-supervised learning for human activity recognition using adversarial autoencoders. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 685–688. [Google Scholar]
- De Andrade, F.H.C.; Pereira, F.G.; Resende, C.Z.; Cavalieri, D.C. Improving sEMG-Based Hand Gesture Recognition Using Maximal Overlap Discrete Wavelet Transform and an Autoencoder Neural Network. In XXVI Brazilian Congress on Biomedical Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 271–279. [Google Scholar]
- Chung, E.A.; Benalcázar, M.E. Real-Time Hand Gesture Recognition Model Using Deep Learning Techniques and EMG Signals. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Munoz-Organero, M.; Ruiz-Blazquez, R. Time-elastic generative model for acceleration time series in human activity recognition. Sensors 2017, 17, 319. [Google Scholar] [CrossRef] [Green Version]
- Centeno, M.P.; van Moorsel, A.; Castruccio, S. Smartphone Continuous Authentication Using Deep Learning Autoencoders. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017; pp. 147–1478. [Google Scholar] [CrossRef]
- Vu, C.C.; Kim, J. Human motion recognition by textile sensors based on machine learning algorithms. Sensors 2018, 18, 3109. [Google Scholar] [CrossRef] [Green Version]
- Chikhaoui, B.; Gouineau, F. Towards automatic feature extraction for activity recognition from wearable sensors: A deep learning approach. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 693–702. [Google Scholar]
- Wang, L. Recognition of human activities using continuous autoencoders with wearable sensors. Sensors 2016, 16, 189. [Google Scholar] [CrossRef] [PubMed]
- Jun, K.; Choi, S. Unsupervised End-to-End Deep Model for Newborn and Infant Activity Recognition. Sensors 2020, 20, 6467. [Google Scholar] [CrossRef] [PubMed]
- Akbari, A.; Jafari, R. Transferring activity recognition models for new wearable sensors with deep generative domain adaptation. In Proceedings of the 18th International Conference on Information Processing in Sensor Networks, Montreal, QC, Canada, 16–18 April 2019; pp. 85–96. [Google Scholar]
- Khan, M.A.A.H.; Roy, N. Untran: Recognizing unseen activities with unlabeled data using transfer learning. In Proceedings of the 2018 IEEE/ACM Third International Conference on Internet-of-Things Design and Implementation (IoTDI), Orlando, FL, USA, 17–20 April 2018; pp. 37–47. [Google Scholar]
- Akbari, A.; Jafari, R. An autoencoder-based approach for recognizing null class in activities of daily living in-the-wild via wearable motion sensors. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3392–3396. [Google Scholar]
- Prabono, A.G.; Yahya, B.N.; Lee, S.L. Atypical sample regularizer autoencoder for cross-domain human activity recognition. Inf. Syst. Front. 2021, 23, 71–80. [Google Scholar] [CrossRef]
- Garcia, K.D.; de Sá, C.R.; Poel, M.; Carvalho, T.; Mendes-Moreira, J.; Cardoso, J.M.; de Carvalho, A.C.; Kok, J.N. An ensemble of autonomous auto-encoders for human activity recognition. Neurocomputing 2021, 439, 271–280. [Google Scholar] [CrossRef]
- Valarezo, A.E.; Rivera, L.P.; Park, H.; Park, N.; Kim, T.S. Human activities recognition with a single writs IMU via a Variational Autoencoder and android deep recurrent neural nets. Comput. Sci. Inf. Syst. 2020, 17, 581–597. [Google Scholar] [CrossRef]
- Sigcha, L.; Costa, N.; Pavón, I.; Costa, S.; Arezes, P.; López, J.M.; De Arcas, G. Deep learning approaches for detecting freezing of gait in Parkinson’s disease patients through on-body acceleration sensors. Sensors 2020, 20, 1895. [Google Scholar] [CrossRef] [Green Version]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct Dataset: Recognition of Activities of Daily Living using Smartphones. In Proceedings of the ICT4AgeingWell, Rome, Italy, 21–22 April 2016; pp. 143–151. [Google Scholar]
- Abu Alsheikh, M.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. arXiv 2015, arXiv:1511.04664. [Google Scholar]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Gu, W.; Wang, G.; Zhang, Z.; Mao, Y.; Xie, X.; He, Y. High Accuracy Drug-Target Protein Interaction Prediction Method based on DBN. In Proceedings of the 2020 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 28–30 July 2020; pp. 58–62. [Google Scholar]
- Lefevre, F. A DBN-based multi-level stochastic spoken language understanding system. In Proceedings of the 2006 IEEE Spoken Language Technology Workshop, Palm Beach, Aruba, 10–13 December 2006; pp. 78–81. [Google Scholar]
- Zhang, C.; He, Y.; Yuan, L.; Xiang, S. Analog circuit incipient fault diagnosis method using DBN based features extraction. IEEE Access 2018, 6, 23053–23064. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Luo, D. Real-Time Activity Recognition on Smartphones Using Deep Neural Networks. In Proceedings of the 2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), Beijing, China, 10–14 August 2015; pp. 1236–1242. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Luo, D. Recognizing Human Activities from Raw Accelerometer Data Using Deep Neural Networks. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 865–870. [Google Scholar] [CrossRef]
- Radu, V.; Lane, N.D.; Bhattacharya, S.; Mascolo, C.; Marina, M.K.; Kawsar, F. Towards Multimodal Deep Learning for Activity Recognition on Mobile Devices. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, (UbiComp’16), Heidelberg, Germany, 12–16 September 2016; pp. 185–188. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A. Human Activity Recognition based on Deep Belief Network Classifier and Combination of Local and Global Features. J. Inf. Syst. Telecommun. 2021, 9, 33. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, N.; Wang, H.; Ding, X.; Ye, X.; Chen, G.; Cao, Y. iHear Food: Eating Detection Using Commodity Bluetooth Headsets. In Proceedings of the 2016 IEEE First International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Washington, DC, USA, 27–29 June 2016; pp. 163–172. [Google Scholar] [CrossRef]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Sani, S.; Massie, S.; Wiratunga, N.; Cooper, K. Learning deep and shallow features for human activity recognition. In International Conference on Knowledge Science, Engineering and Management; Springer: Berlin/Heidelberg, Germany, 2017; pp. 469–482. [Google Scholar]
- Matsui, S.; Inoue, N.; Akagi, Y.; Nagino, G.; Shinoda, K. User adaptation of convolutional neural network for human activity recognition. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, August 28–2 September 2017; pp. 753–757. [Google Scholar]
- Akbari, A.; Jafari, R. Transition-Aware Detection of Modes of Locomotion and Transportation Through Hierarchical Segmentation. IEEE Sens. J. 2020, 21, 3301–3313. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, W.; Wang, Q. A strain gauge based locomotion mode recognition method using convolutional neural network. Adv. Robot. 2019, 33, 254–263. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Deep convolutional neural networks for human activity recognition with smartphone sensors. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 46–53. [Google Scholar]
- Huang, W.; Zhang, L.; Gao, W.; Min, F.; He, J. Shallow Convolutional Neural Networks for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Huang, W.; Min, F.; He, J.; Song, A. Deep neural networks for sensor-based human activity recognition using selective kernel convolution. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Dong, M.; Han, J.; He, Y.; Jing, X. HAR-Net: Fusing Deep Representation and Hand-Crafted Features for Human Activity Recognition. In Signal and Information Processing, Networking and Computers; Sun, S., Fu, M., Xu, L., Eds.; Springer: Singapore, 2019; pp. 32–40. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar]
- Gholamrezaii, M.; AlModarresi, S.M.T. A time-efficient convolutional neural network model in human activity recognition. Multimed. Tools Appl. 2021, 80, 19361–19376. [Google Scholar] [CrossRef]
- Xu, Y.; Qiu, T.T. Human Activity Recognition and Embedded Application Based on Convolutional Neural Network. J. Artif. Intell. Technol. 2021, 1, 51–60. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M. Activity recognition for cognitive assistance using body sensors data and deep convolutional neural network. IEEE Sens. J. 2018, 19, 8413–8419. [Google Scholar] [CrossRef]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar]
- Jordao, A.; Torres, L.A.B.; Schwartz, W.R. Novel approaches to human activity recognition based on accelerometer data. Signal Image Video Process. 2018, 12, 1387–1394. [Google Scholar] [CrossRef]
- Grzeszick, R.; Lenk, J.M.; Rueda, F.M.; Fink, G.A.; Feldhorst, S.; ten Hompel, M. Deep neural network based human activity recognition for the order picking process. In Proceedings of the 4th International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 21–22 September 2017; pp. 1–6. [Google Scholar]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual Attention Network for multimodal human activity recognition using wearable sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Murakami, K.; Taguchi, H. Gesture Recognition Using Recurrent Neural Networks. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, (CHI’91), New Orleans, LA, USA, 27 April–2 May 1991; pp. 237–242. [Google Scholar] [CrossRef] [Green Version]
- Vamplew, P.; Adams, A. Recognition and anticipation of hand motions using a recurrent neural network. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 6, p. 2904. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Jung, E.M.; Kung, J.; Mukhopadhyay, S. Reram crossbar based recurrent neural network for human activity detection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 939–946. [Google Scholar]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, S.; Zhang, X.; Yao, L.; Yue, L.; Qian, B.; Li, X. EEG-based motion intention recognition via multi-task RNNs. In Proceedings of the 2018 SIAM International Conference on Data Mining, San Diego, CA, USA, 3–5 May 2018; pp. 279–287. [Google Scholar]
- Carfi, A.; Motolese, C.; Bruno, B.; Mastrogiovanni, F. Online human gesture recognition using recurrent neural networks and wearable sensors. In Proceedings of the 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Nanjing, China, 27–31 August 2018; pp. 188–195. [Google Scholar]
- Tamamori, A.; Hayashi, T.; Toda, T.; Takeda, K. An investigation of recurrent neural network for daily activity recognition using multi-modal signals. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1334–1340. [Google Scholar]
- Tamamori, A.; Hayashi, T.; Toda, T.; Takeda, K. Daily activity recognition based on recurrent neural network using multi-modal signals. APSIPA Trans. Signal Inf. Process. 2018, 7, e21. [Google Scholar] [CrossRef] [Green Version]
- Uddin, M.Z.; Hassan, M.M.; Alsanad, A.; Savaglio, C. A body sensor data fusion and deep recurrent neural network-based behavior recognition approach for robust healthcare. Inf. Fusion 2020, 55, 105–115. [Google Scholar] [CrossRef]
- Alessandrini, M.; Biagetti, G.; Crippa, P.; Falaschetti, L.; Turchetti, C. Recurrent Neural Network for Human Activity Recognition in Embedded Systems Using PPG and Accelerometer Data. Electronics 2021, 10, 1715. [Google Scholar] [CrossRef]
- Zheng, L.; Li, S.; Zhu, C.; Gao, Y. Application of IndRNN for human activity recognition: The Sussex-Huawei locomotion-transportation challenge. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 869–872. [Google Scholar] [CrossRef]
- Bailador, G.; Roggen, D.; Tröster, G.; Triviño, G. Real time gesture recognition using continuous time recurrent neural networks. In BodyNets; Citeseer: Princeton, NJ, USA, 2007; p. 15. [Google Scholar]
- Wang, X.; Liao, W.; Guo, Y.; Yu, L.; Wang, Q.; Pan, M.; Li, P. Perrnn: Personalized recurrent neural networks for acceleration-based human activity recognition. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Khatiwada, P.; Subedi, M.; Chatterjee, A.; Gerdes, M.W. Automated Human Activity Recognition by Colliding Bodies Optimization-based Optimal Feature Selection with Recurrent Neural Network. arXiv 2020, arXiv:2010.03324. [Google Scholar]
- Lv, M.; Xu, W.; Chen, T. A hybrid deep convolutional and recurrent neural network for complex activity recognition using multimodal sensors. Neurocomputing 2019, 362, 33–40. [Google Scholar] [CrossRef]
- Ketykó, I.; Kovács, F.; Varga, K.Z. Domain adaptation for semg-based gesture recognition with recurrent neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Frasconi, P.; Schmidhuber, J.; Elvezia, C. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term D Ependencies* Sepp Hochreiter Fakult at f ur Informatik. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.24.7321&rep=rep1&type=pdf (accessed on 5 November 2021).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Czuszyński, K.; Rumiński, J.; Kwaśniewska, A. Gesture recognition with the linear optical sensor and recurrent neural networks. IEEE Sens. J. 2018, 18, 5429–5438. [Google Scholar] [CrossRef]
- Zhu, Y.; Luo, H.; Chen, R.; Zhao, F.; Su, L. DenseNetX and GRU for the Sussex-Huawei locomotion-transportation recognition challenge. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, Virtual, 12–17 September 2020; pp. 373–377. [Google Scholar] [CrossRef]
- Okai, J.; Paraschiakos, S.; Beekman, M.; Knobbe, A.; de Sá, C.R. Building robust models for human activity recognition from raw accelerometers data using gated recurrent units and long short term memory neural networks. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2486–2491. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, X.Q.; Xu, L.; He, F.X.; Tian, Z.; She, W.; Liu, W. Harmonic Loss Function for Sensor-Based Human Activity Recognition Based on LSTM Recurrent Neural Networks. IEEE Access 2020, 8, 135617–135627. [Google Scholar] [CrossRef]
- Jangir, M.K.; Singh, K. HARGRURNN: Human activity recognition using inertial body sensor gated recurrent units recurrent neural network. J. Discret. Math. Sci. Cryptogr. 2019, 22, 1577–1587. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rivera, P.; Valarezo, E.; Choi, M.T.; Kim, T.S. Recognition of human hand activities based on a single wrist imu using recurrent neural networks. Int. J. Pharm. Med. Biol. Sci. 2017, 6, 114–118. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Li, C.; Xie, C.; Zhang, B.; Chen, C.; Han, J. Deep Fisher discriminant learning for mobile hand gesture recognition. Pattern Recognit. 2018, 77, 276–288. [Google Scholar] [CrossRef] [Green Version]
- Tao, D.; Wen, Y.; Hong, R. Multicolumn bidirectional long short-term memory for mobile devices-based human activity recognition. IEEE Internet Things J. 2016, 3, 1124–1134. [Google Scholar] [CrossRef]
- Zebin, T.; Sperrin, M.; Peek, N.; Casson, A.J. Human activity recognition from inertial sensor time-series using batch normalized deep LSTM recurrent networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Barut, O.; Zhou, L.; Luo, Y. Multitask LSTM Model for Human Activity Recognition and Intensity Estimation Using Wearable Sensor Data. IEEE Internet Things J. 2020, 7, 8760–8768. [Google Scholar] [CrossRef]
- Qin, Y.; Luo, H.; Zhao, F.; Wang, C.; Wang, J.; Zhang, Y. Toward Transportation Mode Recognition Using Deep Convolutional and Long Short-Term Memory Recurrent Neural Networks. IEEE Access 2019, 7, 142353–142367. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Wu, Y.; Zheng, B.; Zhao, Y. Dynamic gesture recognition based on LSTM-CNN. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 2446–2450. [Google Scholar] [CrossRef]
- Friedrich, B.; Lübbe, C.; Hein, A. Combining LSTM and CNN for mode of transportation classification from smartphone sensors. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, Virtual Event, 12–17 September 2020; pp. 305–310. [Google Scholar] [CrossRef]
- Senyurek, V.Y.; Imtiaz, M.H.; Belsare, P.; Tiffany, S.; Sazonov, E. A CNN-LSTM neural network for recognition of puffing in smoking episodes using wearable sensors. Biomed. Eng. Lett. 2020, 10, 195–203. [Google Scholar] [CrossRef]
- Mutegeki, R.; Han, D.S. A CNN-LSTM approach to human activity recognition. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 362–366. [Google Scholar] [CrossRef]
- Ahmad, W.; Kazmi, B.M.; Ali, H. Human activity recognition using multi-head CNN followed by LSTM. In Proceedings of the 2019 15th International Conference on Emerging Technologies (ICET), Peshawar, Pakistan, 2–3 December 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Deep, S.; Zheng, X. Hybrid model featuring CNN and LSTM architecture for human activity recognition on smartphone sensor data. In Proceedings of the 2019 20th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Gold Coast, Australia, 5–7 December 2019; pp. 259–264. [Google Scholar] [CrossRef]
- Gao, J.; Gu, P.; Ren, Q.; Zhang, J.; Song, X. Abnormal gait recognition algorithm based on LSTM-CNN fusion network. IEEE Access 2019, 7, 163180–163190. [Google Scholar] [CrossRef]
- Saha, S.S.; Sandha, S.S.; Srivastava, M. Deep Convolutional Bidirectional LSTM for Complex Activity Recognition with Missing Data. In Human Activity Recognition Challenge; Springer: Berlin/Heidelberg, Germany, 2021; pp. 39–53. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A.; Thongkum, P. Placement Effect of Motion Sensors for Human Activity Recognition using LSTM Network. In Proceedings of the 2021 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunication Engineering, Cha-am, Thailand, 3–6 March 2021; pp. 273–276. [Google Scholar] [CrossRef]
- Chéron, G.; Leurs, F.; Bengoetxea, A.; Draye, J.; Destrée, M.; Dan, B. A dynamic recurrent neural network for multiple muscles electromyographic mapping to elevation angles of the lower limb in human locomotion. J. Neurosci. Methods 2003, 129, 95–104. [Google Scholar] [CrossRef]
- Gupta, R.; Dhindsa, I.S.; Agarwal, R. Continuous angular position estimation of human ankle during unconstrained locomotion. Biomed. Signal Process. Control 2020, 60, 101968. [Google Scholar] [CrossRef]
- Hioki, M.; Kawasaki, H. Estimation of finger joint angles from sEMG using a recurrent neural network with time-delayed input vectors. In Proceedings of the 2009 IEEE International Conference on Rehabilitation Robotics, Kyoto, Japan, 23–26 June 2009; pp. 289–294. [Google Scholar] [CrossRef]
- Bu, N.; Fukuda, O.; Tsuji, T. EMG-based motion discrimination using a novel recurrent neural network. J. Intell. Inf. Syst. 2003, 21, 113–126. [Google Scholar] [CrossRef]
- Cheron, G.; Cebolla, A.M.; Bengoetxea, A.; Leurs, F.; Dan, B. Recognition of the physiological actions of the triphasic EMG pattern by a dynamic recurrent neural network. Neurosci. Lett. 2007, 414, 192–196. [Google Scholar] [CrossRef]
- Zeng, M.; Gao, H.; Yu, T.; Mengshoel, O.J.; Langseth, H.; Lane, I.; Liu, X. Understanding and improving recurrent networks for human activity recognition by continuous attention. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; pp. 56–63. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Qian, H.; Pan, S.J.; Da, B.; Miao, C. A Novel Distribution-Embedded Neural Network for Sensor-Based Activity Recognition. IJCAI 2019, 2019, 5614–5620. [Google Scholar]
- Kung-Hsiang (Steeve), H. Introduction to Various Reinforcement Learning Algorithms. Part I (Q-Learning, SARSA, DQN, DDPG). 2018. Available online: https://towardsdatascience.com/introduction-to-various-reinforcement-learning-algorithms-i-q-learning-sarsa-dqn-ddpg-72a5e0cb6287 (accessed on 13 July 2012).
- Seok, W.; Kim, Y.; Park, C. Pattern recognition of human arm movement using deep reinforcement learning. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 917–919. [Google Scholar] [CrossRef]
- Zheng, J.; Cao, H.; Chen, D.; Ansari, R.; Chu, K.C.; Huang, M.C. Designing deep reinforcement learning systems for musculoskeletal modeling and locomotion analysis using wearable sensor feedback. IEEE Sens. J. 2020, 20, 9274–9282. [Google Scholar] [CrossRef]
- Bhat, G.; Deb, R.; Chaurasia, V.V.; Shill, H.; Ogras, U.Y. Online human activity recognition using low-power wearable devices. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. Available online: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 5 November 2021).
- Farnia, F.; Ozdaglar, A. Gans may have no nash equilibria. arXiv 2020, arXiv:2002.09124. [Google Scholar]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv 2015, arXiv:1511.06390. [Google Scholar]
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv 2016, arXiv:1606.01583. [Google Scholar]
- Shi, J.; Zuo, D.; Zhang, Z. A GAN-based data augmentation method for human activity recognition via the caching ability. Internet Technol. Lett. 2021, 4, e257. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Gu, Y.; Xiao, Y.; Pan, H. SensoryGANs: An Effective Generative Adversarial Framework for Sensor-based Human Activity Recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks, IJCNN 2018, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kawaguchi, N.; Yang, Y.; Yang, T.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Inoue, S.; Kawahara, Y.; et al. HASC2011corpus: Towards the Common Ground of Human Activity Recognition. In Proceedings of the 13th International Conference on Ubiquitous Computing (UbiComp’11), Beijing, China, 17–21 September 2011; pp. 571–572. [Google Scholar] [CrossRef] [Green Version]
- Alharbi, F.; Ouarbya, L.; Ward, J.A. Synthetic sensor data for human activity recognition. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Chan, M.H.; Noor, M.H.M. A unified generative model using generative adversarial network for activity recognition. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 8119–8128. [Google Scholar] [CrossRef]
- Li, X.; Luo, J.; Younes, R. ActivityGAN: Generative adversarial networks for data augmentation in sensor-based human activity recognition. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, Virtual Event Mexico, 12–17 September 2020; pp. 249–254. [Google Scholar]
- Shi, X.; Li, Y.; Zhou, F.; Liu, L. Human activity recognition based on deep learning method. In Proceedings of the 2018 International Conference on Radar (RADAR), Brisbane, QLD, Australia, 27–31 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Abedin, A.; Rezatofighi, H.; Ranasinghe, D.C. Guided-GAN: Adversarial Representation Learning for Activity Recognition with Wearables. arXiv 2021, arXiv:2110.05732. [Google Scholar]
- Sanabria, A.R.; Zambonelli, F.; Dobson, S.; Ye, J. ContrasGAN: Unsupervised domain adaptation in Human Activity Recognition via adversarial and contrastive learning. Pervasive Mob. Comput. 2021, 78, 101477. [Google Scholar] [CrossRef]
- Challa, S.K.; Kumar, A.; Semwal, V.B. A multibranch CNN-BiLSTM model for human activity recognition using wearable sensor data. Vis. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Huang, C.; Wang, S.; Tan, M.; Long, G.; Wang, C. Multi-modality Sensor Data Classification with Selective Attention. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, (IJCAI-18). International Joint Conferences on Artificial Intelligence Organization, Stockholm, Sweden, 13–19 July 2018; pp. 3111–3117. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Sheng, Q.Z.; Li, X.; Gu, T.; Tan, M.; Wang, X.; Wang, S.; Ruan, W. Compressive representation for device-free activity recognition with passive RFID signal strength. IEEE Trans. Mob. Comput. 2017, 17, 293–306. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Wang, X.; Zhang, W.; Zhang, S.; Liu, Y. Know your mind: Adaptive cognitive activity recognition with reinforced CNN. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 896–905. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep learning models for real-time human activity recognition with smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep residual bidir-LSTM for human activity recognition using wearable sensors. Math. Probl. Eng. 2018, 2018, 7316954. [Google Scholar] [CrossRef]
- Ullah, M.; Ullah, H.; Khan, S.D.; Cheikh, F.A. Stacked lstm network for human activity recognition using smartphone data. In Proceedings of the 2019 8th European workshop on visual information processing (EUVIP), Roma, Italy, 28–31 October 2019; pp. 175–180. [Google Scholar]
- Hernández, F.; Suárez, L.F.; Villamizar, J.; Altuve, M. Human activity recognition on smartphones using a bidirectional lstm network. In Proceedings of the 2019 XXII Symposium on Image, Signal Processing and Artificial Vision (STSIVA), Bucaramanga, Colombia, 24–26 April 2019; pp. 1–5. [Google Scholar]
- Cheng, X.; Zhang, L.; Tang, Y.; Liu, Y.; Wu, H.; He, J. Real-time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices. arXiv 2020, arXiv:2006.03259. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Che, T.; Li, Y.; Jacob, A.P.; Bengio, Y.; Li, W. Mode regularized generative adversarial networks. arXiv 2016, arXiv:1612.02136. [Google Scholar]
- Gao, Y.; Jin, Y.; Chauhan, J.; Choi, S.; Li, J.; Jin, Z. Voice In Ear: Spoofing-Resistant and Passphrase-Independent Body Sound Authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Steven Eyobu, O.; Han, D.S. Feature Representation and Data Augmentation for Human Activity Classification Based on Wearable IMU Sensor Data Using a Deep LSTM Neural Network. Sensors 2018, 18, 2892. [Google Scholar] [CrossRef] [Green Version]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Data augmentation using synthetic data for time series classification with deep residual networks. In Proceedings of the International Workshop on Advanced Analytics and Learning on Temporal Data, ECML PKDD, Dublin, Ireland, 10–14 September 2018. [Google Scholar]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-CGAN: Conditional Generative Adversarial Network for Data Augmentation in Noisy Time Series with Irregular Sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar]
- Alzantot, M.; Chakraborty, S.; Srivastava, M. SenseGen: A deep learning architecture for synthetic sensor data generation. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.; Tong, C.; Haresamudram, H.; Gao, Y.; Abowd, G.D.; Lane, N.D.; Plötz, T. IMUTube: Automatic Extraction of Virtual on-Body Accelerometry from Video for Human Activity Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Gowda, M. When Video Meets Inertial Sensors: Zero-Shot Domain Adaptation for Finger Motion Analytics with Inertial Sensors. In Proceedings of the International Conference on Internet-of-Things Design and Implementation (IoTDI’21), Charlottesvle, VA, USA, 18–21 May 2021; pp. 182–194. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, Z.; Fang, C.; Bui, T.; Berg, T.L. Visual to sound: Generating natural sound for videos in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3550–3558. [Google Scholar]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of The 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Volume 48, pp. 1060–1069. [Google Scholar]
- Zhang, S.; Alshurafa, N. Deep Generative Cross-Modal on-Body Accelerometer Data Synthesis from Videos. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, (UbiComp-ISWC’20), Virtual, 12–17 September 2020; pp. 223–227. [Google Scholar] [CrossRef]
- Rahman, M.; Ali, N.; Bari, R.; Saleheen, N.; al’Absi, M.; Ertin, E.; Kennedy, A.; Preston, K.L.; Kumar, S. mDebugger: Assessing and Diagnosing the Fidelity and Yield of Mobile Sensor Data. In Mobile Health: Sensors, Analytic Methods, and Applications; Rehg, J.M., Murphy, S.A., Kumar, S., Eds.; Springer: Cham, Switzerland, 2017; pp. 121–143. [Google Scholar] [CrossRef]
- Cao, W.; Wang, D.; Li, J.; Zhou, H.; Li, L.; Li, Y. BRITS: Bidirectional Recurrent Imputation for Time Series. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6775–6785. [Google Scholar]
- Luo, Y.; Cai, X.; Zhang, Y.; Xu, J. Multivariate Time Series Imputation with Generative Adversarial Networks. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 1596–1607. [Google Scholar]
- Rolnick, D.; Veit, A.; Belongie, S.J.; Shavit, N. Deep Learning is Robust to Massive Label Noise. arXiv 2017, arXiv:1705.10694. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Briggs, C.; Fan, Z.; Andras, P. A review of privacy-preserving federated learning for the Internet-of-Things. Fed. Learn. Syst. 2021, 21–50. [Google Scholar]
- Sozinov, K.; Vlassov, V.; Girdzijauskas, S. Human activity recognition using federated learning. In Proceedings of the 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, VIC, Australia, 11–13 December 2018; pp. 1103–1111. [Google Scholar] [CrossRef]
- Li, C.; Niu, D.; Jiang, B.; Zuo, X.; Yang, J. Meta-HAR: Federated Representation Learning for Human Activity Recognition. In Proceedings of the Web Conference 2021 (WWW’21); Association for Computing Machinery: Ljubljana, Slovenia, 2021; pp. 912–922. [Google Scholar] [CrossRef]
- Xiao, Z.; Xu, X.; Xing, H.; Song, F.; Wang, X.; Zhao, B. A federated learning system with enhanced feature extraction for human activity recognition. Knowl. Based Syst. 2021, 229, 107338. [Google Scholar] [CrossRef]
- Tu, L.; Ouyang, X.; Zhou, J.; He, Y.; Xing, G. FedDL: Federated Learning via Dynamic Layer Sharing for Human Activity Recognition. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra Portugal, 15–17 November 2021; pp. 15–28. [Google Scholar] [CrossRef]
- Bettini, C.; Civitarese, G.; Presotto, R. Personalized Semi-Supervised Federated Learning for Human Activity Recognition. arXiv 2021, arXiv:2104.08094. [Google Scholar]
- Gudur, G.K.; Perepu, S.K. Resource-constrained federated learning with heterogeneous labels and models for human activity recognition. In Proceedings of the Deep Learning for Human Activity Recognition: Second International Workshop, DL-HAR 2020, Kyoto, Japan, 8 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1370, p. 57. [Google Scholar]
- Bdiwi, R.; de Runz, C.; Faiz, S.; Cherif, A.A. Towards a New Ubiquitous Learning Environment Based on Blockchain Technology. In Proceedings of the 2017 IEEE 17th International Conference on Advanced Learning Technologies (ICALT), Timisoara, Romania, 3–7 July 2017; pp. 101–102. [Google Scholar] [CrossRef]
- Bdiwi, R.; De Runz, C.; Faiz, S.; Cherif, A.A. A blockchain based decentralized platform for ubiquitous learning environment. In Proceedings of the 2018 IEEE 18th International Conference on Advanced Learning Technologies (ICALT), Mumbai, India, 9–13 July 2018; pp. 90–92. [Google Scholar] [CrossRef]
- Shrestha, A.K.; Vassileva, J.; Deters, R. A Blockchain Platform for User Data Sharing Ensuring User Control and Incentives. Front. Blockchain 2020, 3, 48. [Google Scholar] [CrossRef]
- Chen, Z.; Fiandrino, C.; Kantarci, B. On blockchain integration into mobile crowdsensing via smart embedded devices: A comprehensive survey. J. Syst. Archit. 2021, 115, 102011. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pham, Q.V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated learning meets blockchain in edge computing: Opportunities and challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Zhang, S.; Liu, M.; Daly, E.; Battalio, S.; Kumar, S.; Spring, B.; Rehg, J.M.; Alshurafa, N. SyncWISE: Window Induced Shift Estimation for Synchronization of Video and Accelerometry from Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Fridman, L.; Brown, D.E.; Angell, W.; Abdic, I.; Reimer, B.; Noh, H.Y. Automated Synchronization of Driving Data Using Vibration and Steering Events. Pattern Recognit. Lett. 2015, 75, 9–15. [Google Scholar] [CrossRef] [Green Version]
- Zeng, M.; Yu, T.; Wang, X.; Nguyen, L.T.; Mengshoel, O.J.; Lane, I. Semi-supervised convolutional neural networks for human activity recognition. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 522–529. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Yao, L.; Zhang, D.; Chang, X.; Long, G.; Wang, S. Distributionally Robust Semi-Supervised Learning for People-Centric Sensing. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3321–3328. [Google Scholar] [CrossRef] [Green Version]
- Gudur, G.K.; Sundaramoorthy, P.; Umaashankar, V. ActiveHARNet: Towards On-Device Deep Bayesian Active Learning for Human Activity Recognition. In Proceedings of the The 3rd International Workshop on Deep Learning for Mobile Systems and Applications, (EMDL’19), Seoul, Korea, 21 June 2019; pp. 7–12. [Google Scholar] [CrossRef]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Alharbi, R.; Vafaie, N.; Liu, K.; Moran, K.; Ledford, G.; Pfammatter, A.; Spring, B.; Alshurafa, N. Investigating barriers and facilitators to wearable adherence in fine-grained eating detection. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 407–412. [Google Scholar] [CrossRef]
- Nakamura, K.; Yeung, S.; Alahi, A.; Fei-Fei, L. Jointly Learning Energy Expenditures and Activities Using Egocentric Multimodal Signals. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6817–6826. [Google Scholar] [CrossRef] [Green Version]
- Plötz, T.; Guan, Y. Deep Learning for Human Activity Recognition in Mobile Computing. Computer 2018, 51, 50–59. [Google Scholar] [CrossRef]
- Qian, H.; Pan, S.J.; Miao, C. Weakly-supervised sensor-based activity segmentation and recognition via learning from distributions. Artif. Intell. 2021, 292, 103429. [Google Scholar] [CrossRef]
- Kyritsis, K.; Diou, C.; Delopoulos, A. Modeling Wrist Micromovements to Measure In-Meal Eating Behavior from Inertial Sensor Data. IEEE J. Biomed. Health Inform. 2019. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Zhang, L.; Liu, Z.; Liu, K.; Li, X.; Liu, Y. Lasagna: Towards Deep Hierarchical Understanding and Searching over Mobile Sensing Data. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, (MobiCom’16), New York, NY, USA, 3–7 October 2016; pp. 334–347. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 74:1–74:16. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chang, V.; Chakrabortty, R.K.; Ryan, M. Deep learning for Heterogeneous Human Activity Recognition in Complex IoT Applications. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Incremental Learning to Personalize Human Activity Recognition Models: The Importance of Human AI Collaboration. Sensors 2019, 19, 5151. [Google Scholar] [CrossRef] [Green Version]
- Qian, H.; Pan, S.J.; Miao, C.; Qian, H.; Pan, S.; Miao, C. Latent Independent Excitation for Generalizable Sensor-based Cross-Person Activity Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11921–11929. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant Risk Minimization. arXiv 2020, arXiv:1907.02893. [Google Scholar]
- Konečnỳ, J.; McMahan, B.; Ramage, D. Federated optimization: Distributed optimization beyond the datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Information Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Ahad, M.A.R.; Antar, A.D.; Ahmed, M. Sensor-based human activity recognition: Challenges ahead. In IoT Sensor-Based Activity Recognition; Springer: Berlin/Heidelberg, Germany, 2021; pp. 175–189. [Google Scholar]
- Abedin, A.; Ehsanpour, M.; Shi, Q.; Rezatofighi, H.; Ranasinghe, D.C. Attend and Discriminate: Beyond the State-of-the-Art for Human Activity Recognition Using Wearable Sensors. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–22. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Tu, N.A.; Kim, D.S. Physical Activity Recognition with Statistical-Deep Fusion Model Using Multiple Sensory Data for Smart Health. IEEE Internet Things J. 2021, 8, 1533–1543. [Google Scholar] [CrossRef]
- Hanif, M.; Akram, T.; Shahzad, A.; Khan, M.; Tariq, U.; Choi, J.; Nam, Y.; Zulfiqar, Z. Smart Devices Based Multisensory Approach for Complex Human Activity Recognition. Comput. Mater. Contin. 2022, 70, 3221–3234. [Google Scholar] [CrossRef]
- Pires, I.M.; Pombo, N.; Garcia, N.M.; Flórez-Revuelta, F. Multi-Sensor Mobile Platform for the Recognition of Activities of Daily Living and Their Environments Based on Artificial Neural Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, (IJCAI-18). International Joint Conferences on Artificial Intelligence Organization, Stockholm, Sweden, 13–19 July 2018; pp. 5850–5852. [Google Scholar] [CrossRef] [Green Version]
- Sena, J.; Barreto, J.; Caetano, C.; Cramer, G.; Schwartz, W.R. Human activity recognition based on smartphone and wearable sensors using multiscale DCNN ensemble. Neurocomputing 2021, 444, 226–243. [Google Scholar] [CrossRef]
- Xia, S.; Chandrasekaran, R.; Liu, Y.; Yang, C.; Rosing, T.S.; Jiang, X. A Drone-Based System for Intelligent and Autonomous Homes. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems (SenSys’21), Coimbra, Portugal, 15–17 November 2021; pp. 349–350. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Lane, N.D.; Georgiev, P.; Qendro, L. DeepEar: Robust Smartphone Audio Sensing in Unconstrained Acoustic Environments Using Deep Learning. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp’15), Osaka, Japan, 7–11 September 2015; pp. 283–294. [Google Scholar] [CrossRef] [Green Version]
- Cao, Q.; Balasubramanian, N.; Balasubramanian, A. MobiRNN: Efficient Recurrent Neural Network Execution on Mobile GPU. In Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications (EMDL’17), Niagara Falls, NY, USA, 23 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. DeepSense: A Unified Deep Learning Framework for Time-Series Mobile Sensing Data Processing. In Proceedings of the 26th International Conference on World Wide Web; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland (WWW’17), Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Lane, N.D. Sparsification and Separation of Deep Learning Layers for Constrained Resource Inference on Wearables. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems CD-ROM, (SenSys’16), Stanford, CA, USA, 14–16 November 2016; pp. 176–189. [Google Scholar] [CrossRef]
- Edel, M.; Köppe, E. Binarized-BLSTM-RNN based Human Activity Recognition. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Bhat, G.; Tuncel, Y.; An, S.; Lee, H.G.; Ogras, U.Y. An Ultra-Low Energy Human Activity Recognition Accelerator for Wearable Health Applications. ACM Trans. Embed. Comput. Syst. 2019, 18, 1–22. [Google Scholar] [CrossRef]
- Wang, L.; Thiemjarus, S.; Lo, B.; Yang, G.Z. Toward a mixed-signal reconfigurable ASIC for real-time activity recognition. In Proceedings of the 2008 5th International Summer School and Symposium on Medical Devices and Biosensors, Hong Kong, China, 1–3 June 2008; pp. 227–230. [Google Scholar] [CrossRef]
- Islam, B.; Nirjon, S. Zygarde: Time-Sensitive On-Device Deep Inference and Adaptation on Intermittently-Powered Systems. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Xia, S.; Nie, J.; Jiang, X. CSafe: An Intelligent Audio Wearable Platform for Improving Construction Worker Safety in Urban Environments. In Proceedings of the 20th International Conference on Information Processing in Sensor Networks (Co-Located with CPS-IoT Week 2021), (IPSN’21), Nashville, TN, USA, 18–21 May 2021; pp. 207–221. [Google Scholar] [CrossRef]
- Xia, S.; de Godoy Peixoto, D.; Islam, B.; Islam, M.T.; Nirjon, S.; Kinget, P.R.; Jiang, X. Improving Pedestrian Safety in Cities Using Intelligent Wearable Systems. IEEE Internet Things J. 2019, 6, 7497–7514. [Google Scholar] [CrossRef]
- de Godoy, D.; Islam, B.; Xia, S.; Islam, M.T.; Chandrasekaran, R.; Chen, Y.C.; Nirjon, S.; Kinget, P.R.; Jiang, X. PAWS: A Wearable Acoustic System for Pedestrian Safety. In Proceedings of the 2018 IEEE/ACM Third International Conference on Internet-of-Things Design and Implementation (IoTDI), Orlando, FL, USA, 17–20 April 2018; pp. 237–248. [Google Scholar] [CrossRef]
- Nie, J.; Hu, Y.; Wang, Y.; Xia, S.; Jiang, X. SPIDERS: Low-Cost Wireless Glasses for Continuous In-Situ Bio-Signal Acquisition and Emotion Recognition. In Proceedings of the 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), Sydney, NSW, Australia, 21–24 April 2020; pp. 27–39. [Google Scholar] [CrossRef]
- Nie, J.; Liu, Y.; Hu, Y.; Wang, Y.; Xia, S.; Preindl, M.; Jiang, X. SPIDERS+: A light-weight, wireless, and low-cost glasses-based wearable platform for emotion sensing and bio-signal acquisition. Pervasive Mob. Comput. 2021, 75, 101424. [Google Scholar] [CrossRef]
- Hu, Y.; Nie, J.; Wang, Y.; Xia, S.; Jiang, X. Demo Abstract: Wireless Glasses for Non-contact Facial Expression Monitoring. In Proceedings of the 2020 19th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Sydney, NSW, Australia, 21–24 April 2020; pp. 367–368. [Google Scholar] [CrossRef]
- Chandrasekaran, R.; de Godoy, D.; Xia, S.; Islam, M.T.; Islam, B.; Nirjon, S.; Kinget, P.; Jiang, X. SEUS: A Wearable Multi-Channel Acoustic Headset Platform to Improve Pedestrian Safety: Demo Abstract; Association for Computing Machinery: New York, NY, USA, 2016; pp. 330–331. [Google Scholar] [CrossRef]
- Xia, S.; de Godoy, D.; Islam, B.; Islam, M.T.; Nirjon, S.; Kinget, P.R.; Jiang, X. A Smartphone-Based System for Improving Pedestrian Safety. In Proceedings of the 2018 IEEE Vehicular Networking Conference (VNC), Taipei, Taiwan, 5–7 December 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Lane, N.D.; Georgiev, P. Can Deep Learning Revolutionize Mobile Sensing? In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications (HotMobile’15), Santa Fe, NM, USA, 12–13 February 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 117–122. [Google Scholar] [CrossRef] [Green Version]











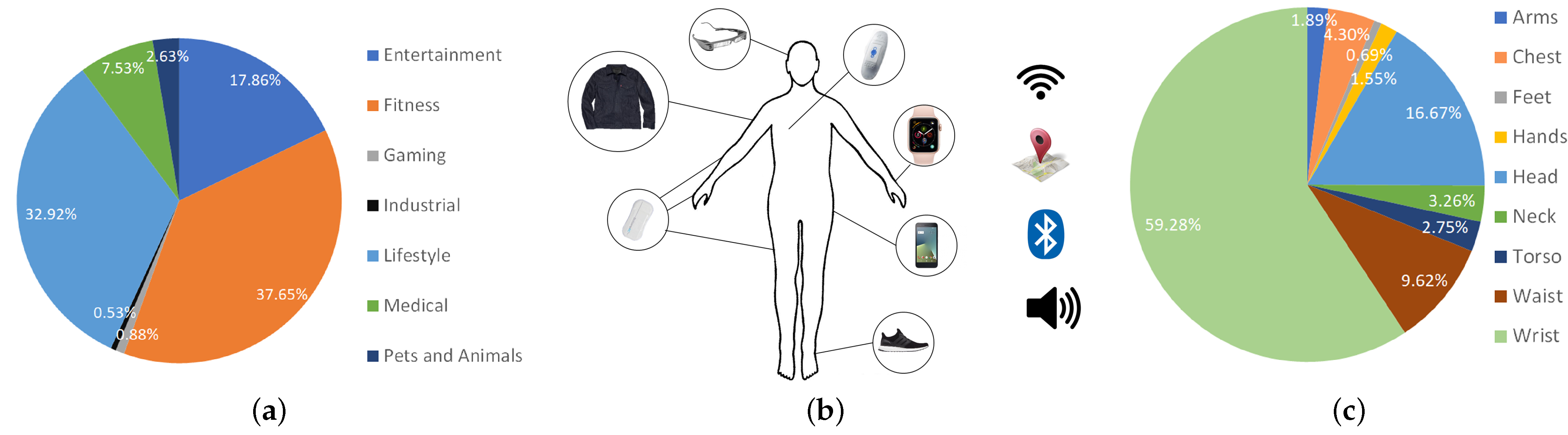{kind=link}
{kind=link}
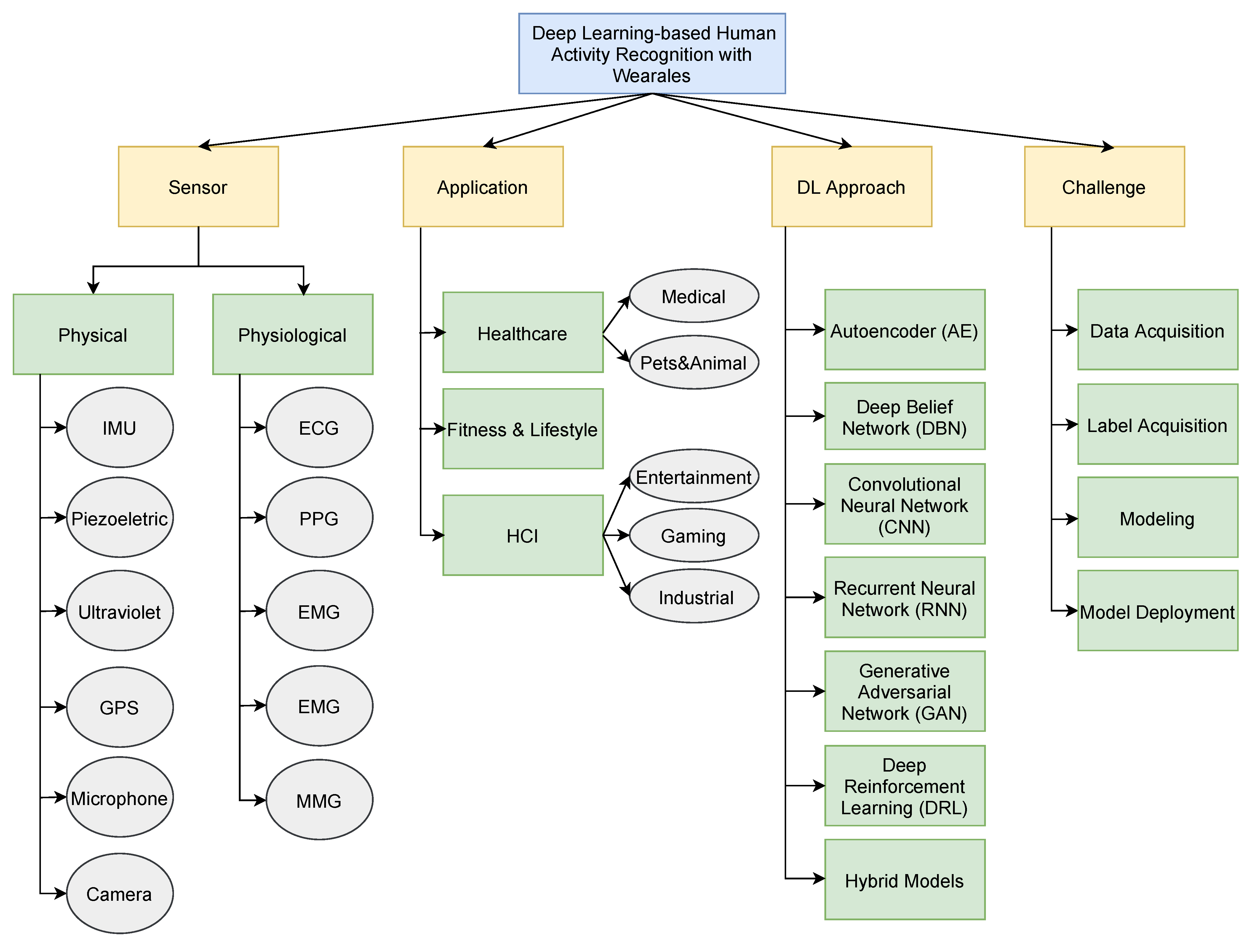{kind=link}
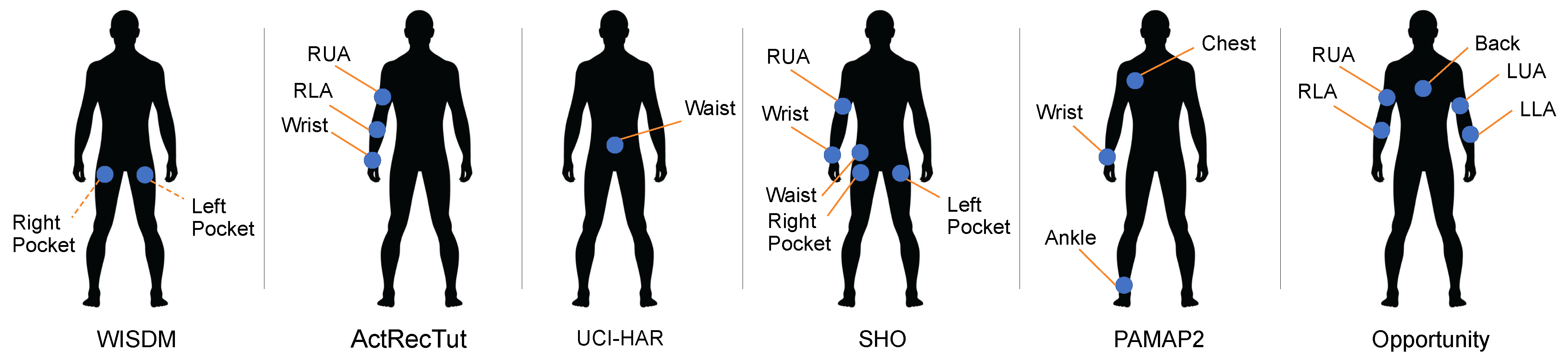{kind=link}
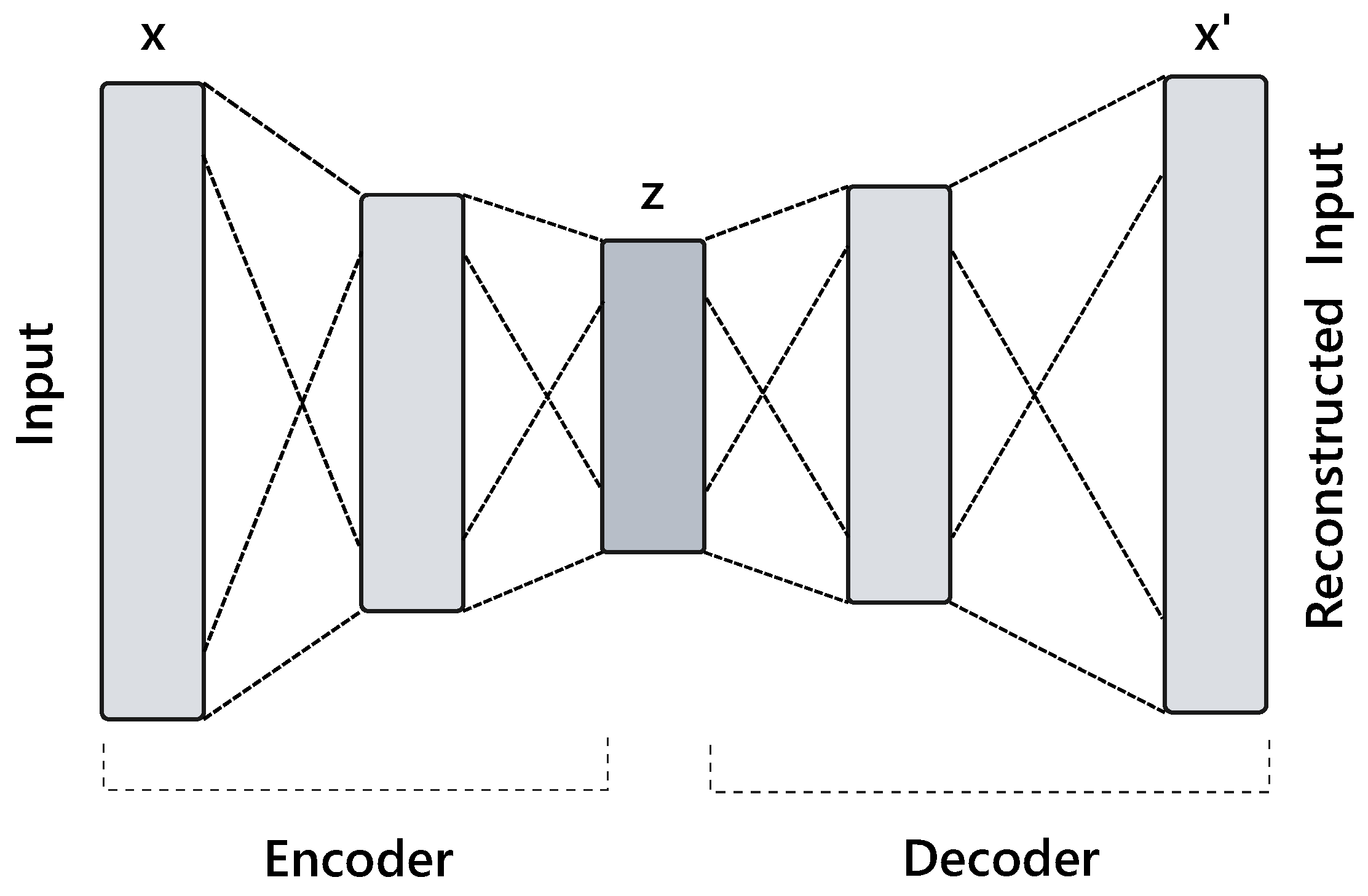{kind=link}
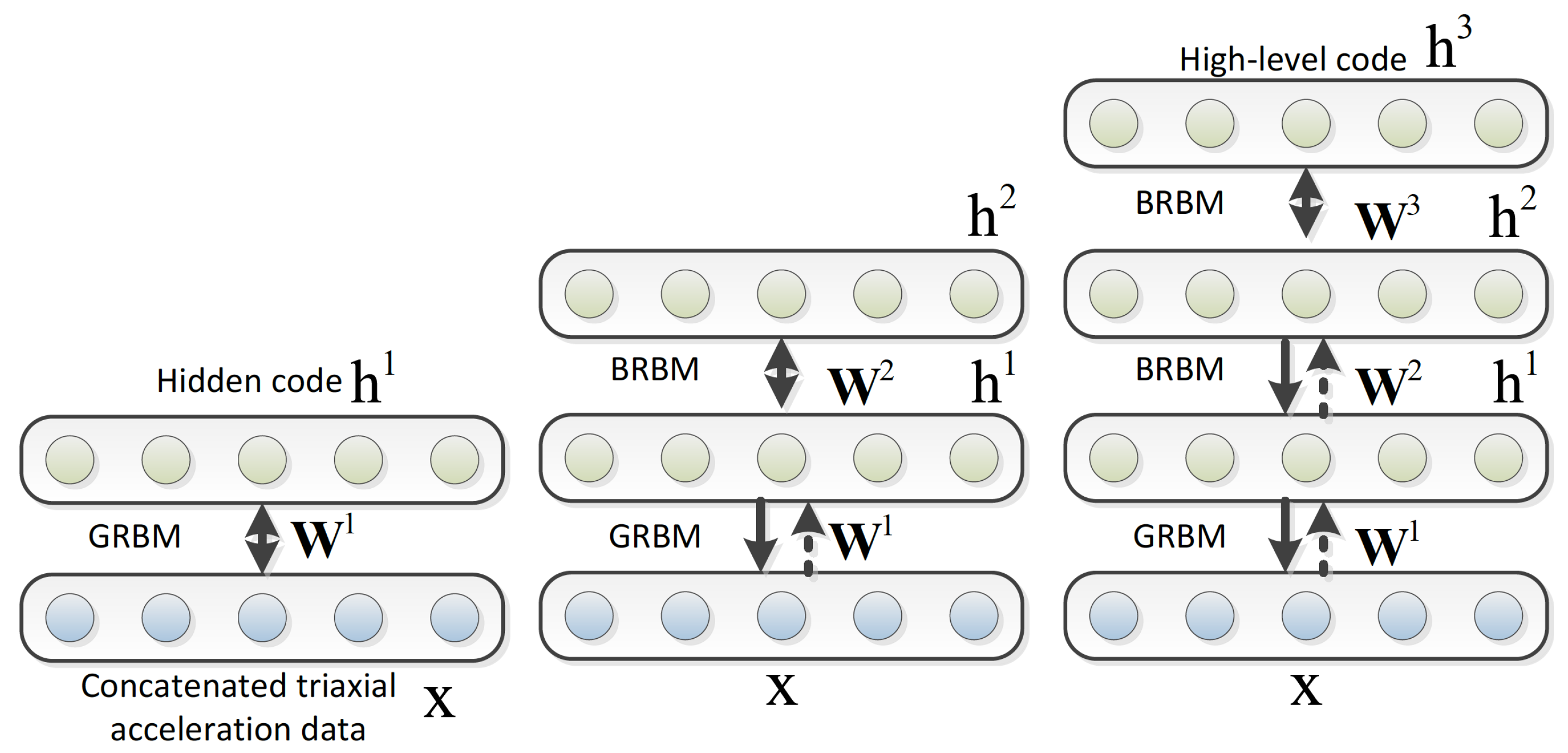{kind=link}
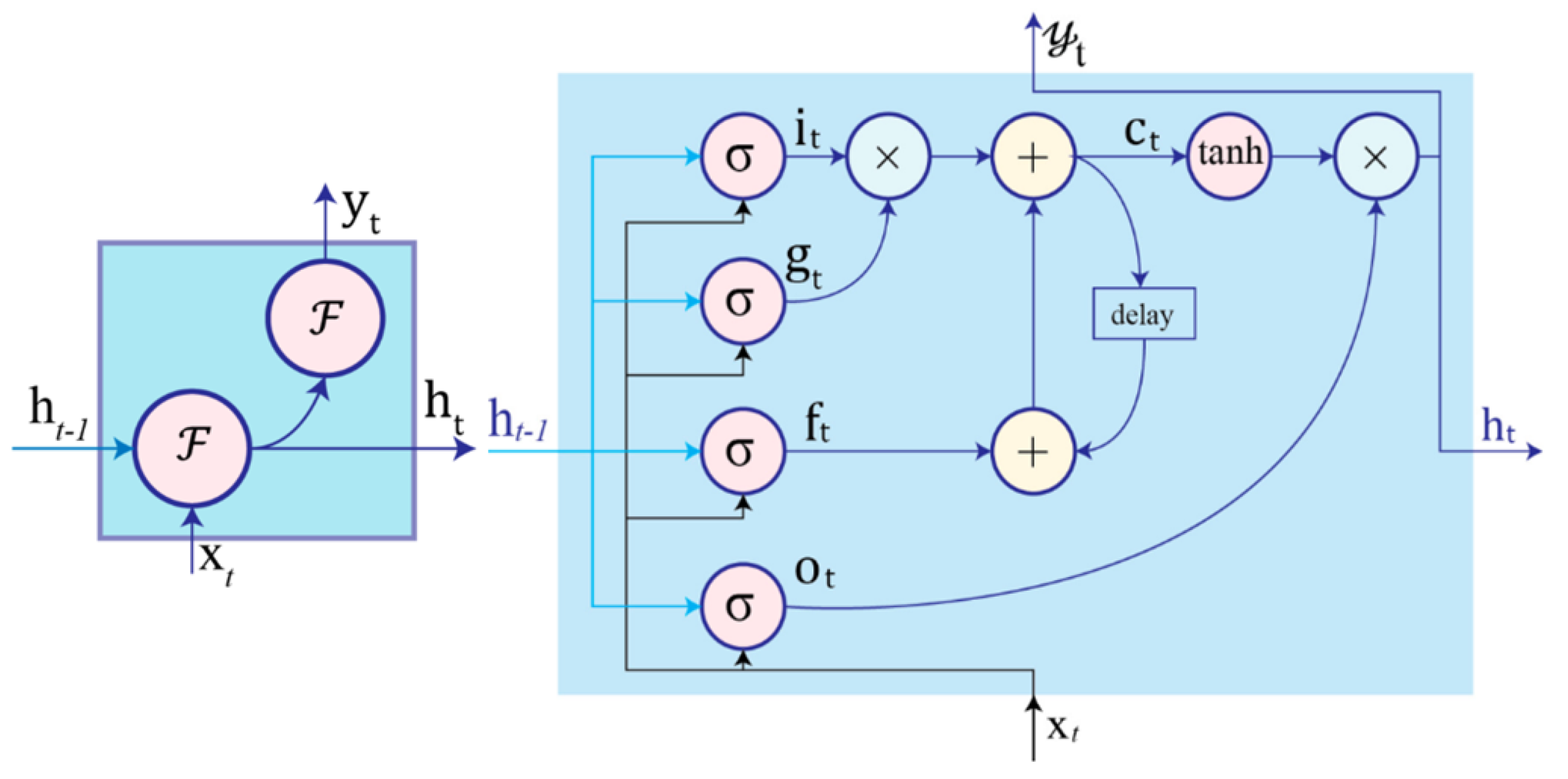{kind=link}
{kind=link}
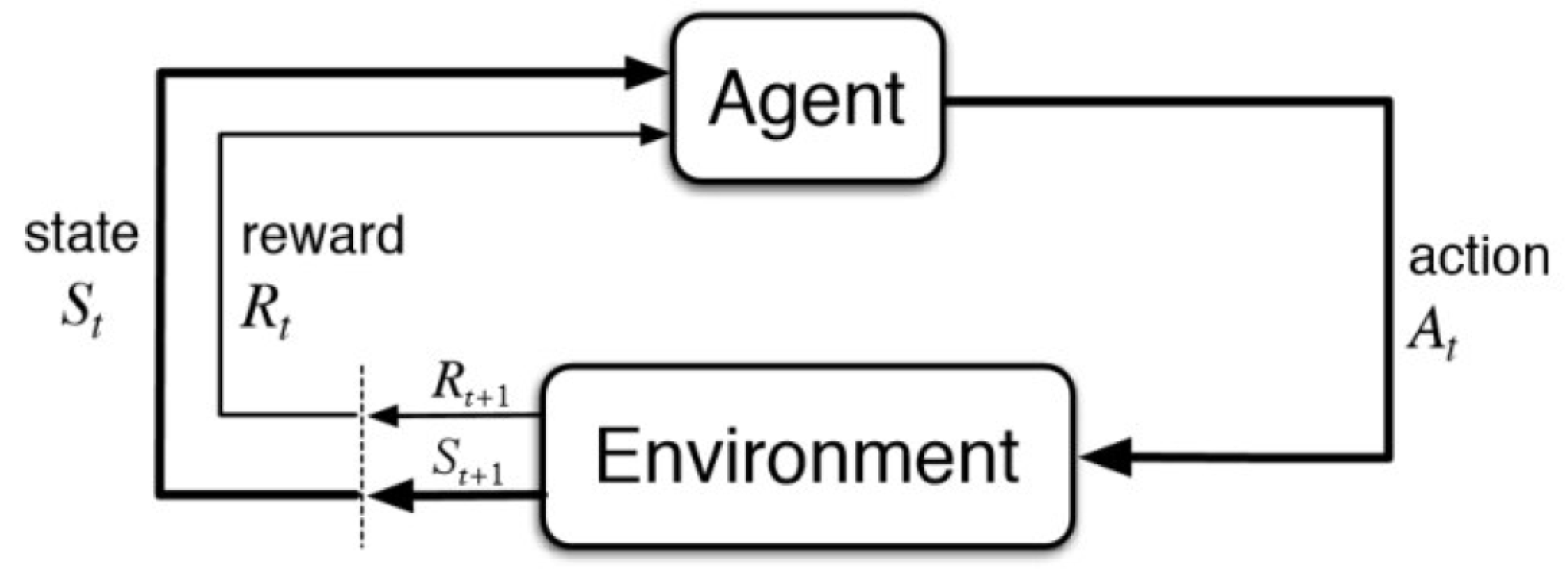{kind=link}
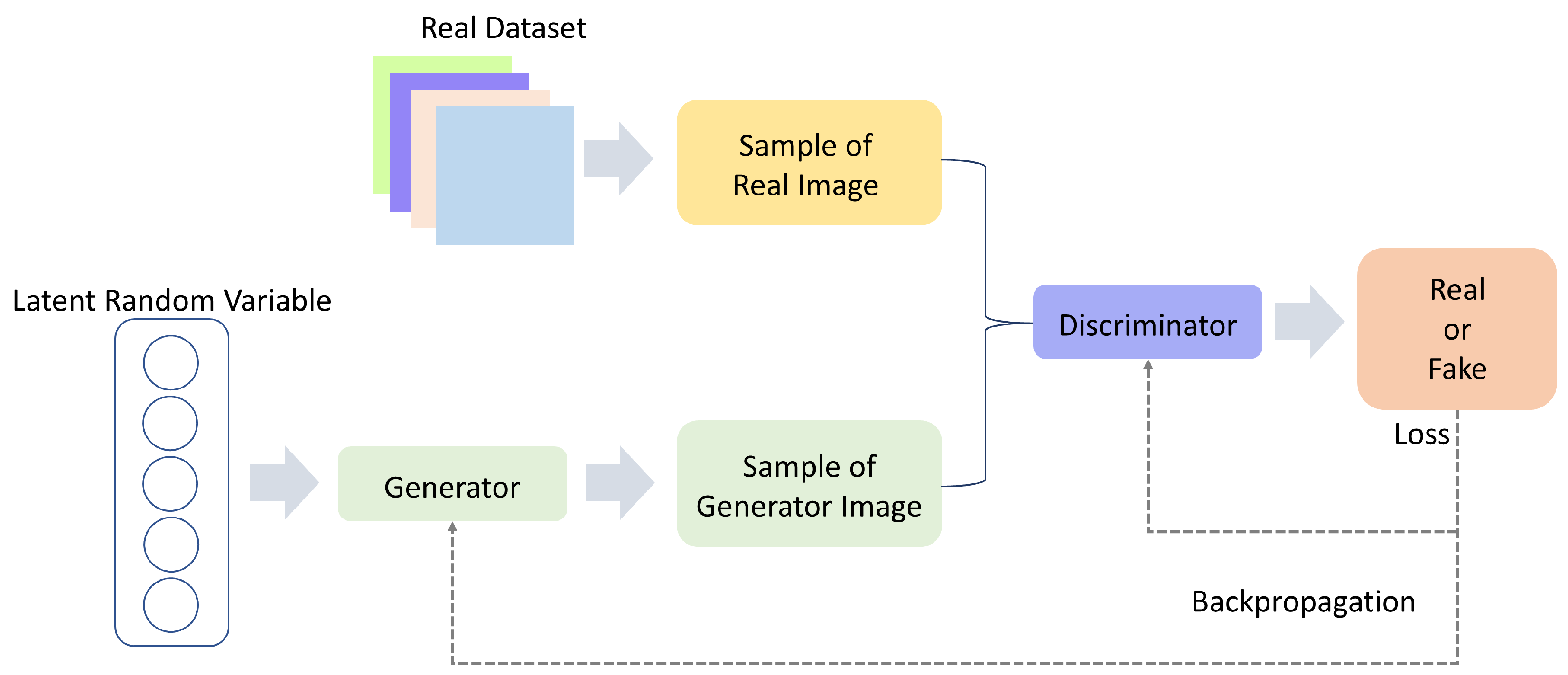{kind=link}
| Dataset | Application | Sensor | # Classes | Spl. Rate | Citations/yr |
|---|---|---|---|---|---|
| WISDM [81] | Locomotion | 3D Acc. | 6 | 20 Hz | 217 |
| ActRecTut [100] | Hand gestures | 9D IMU | 12 | 32 Hz | 153 |
| UCR(UEA)-TSC [105,106] | 9 datasets (e.g., uWave [107]) | Vary | Vary | Vary | 107 |
| UCI-HAR [82] | Locomotion | Smartphone 9D IMU | 6 | 50 Hz | 78 |
| Ubicomp 08 [83] | Home activities | Proximity sensors | 8 | N/A | 69 |
| SHO [84] | Locomotion | Smartphone 9D IMU | 7 | 50 Hz | 52 |
| UTD-MHAD1/2 [85] | Locomotion & activities | 3D Acc. & 3D Gyro. | 27 | 50 Hz | 39 |
| HHAR [86] | Locomotion | 3D Acc. | 6 | 50–200 Hz | 37 |
| Daily & Sports Activities [87] | Locomotion | 9D IMU | 19 | 25 Hz | 37 |
| MHEALTH [88,89] | Locomotion & gesture | 9D IMU & ECG | 12 | 50 Hz | 33 |
| Opportunity [90] | Locomotion & gesture | 9D IMU | 16 | 50 Hz | 32 |
| PAMAP2 [91] | Locomotion & activities | 9D IMU & HR monitor | 18 | 100 Hz | 32 |
| Daphnet [104] | Freezing of gait | 3D Acc. | 2 | 64 Hz | 30 |
| SHL [108] | Locomotion & transportation | 9D IMU | 8 | 100 Hz | 23 |
| SARD [92] | Locomotion | 9D IMU & GPS | 6 | 50 Hz | 22 |
| Skoda Checkpoint [103] | Assembly-line activities | 3D Acc. | 11 | 98 Hz | 21 |
| UniMiB SHAR [93] | Locomotion & gesture | 9D IMU | 12 | N/A | 20 |
| USC-HAD [94] | Locomotion | 3D ACC. & 3D Gyro. | 12 | 100 Hz | 20 |
| ExtraSensory [95] | Locomotion & activities | 9D IMU & GPS | 10 | 25–40 Hz | 13 |
| HASC [96] | Locomotion | Smartphone 9D IMU | 6 | 100 Hz | 11 |
| Actitracker [97] | Locomotion | 9D IMU & GPS | 5 | N/A | 6 |
| FIC [101] | Feeding gestures | 3D Acc. | 6 | 20 Hz | 5 |
| WHARF [98] | Locomotion | Smartphone 9D IMU | 16 | 50 Hz | 4 |
| Study | Architecture | Kernel Conv. | Application | # Classes | Sensors | Dataset |
|---|---|---|---|---|---|---|
| [26] | C-P-FC-S | 1 × 3, 1 × 4, 1 × 5 | locomotion activities | 3 | S1 | Self |
| [171] | C-P-C-P-S | 4 × 4 | locomotion activities | 6, 12 | S1 | UCI, mHealth |
| [22] | C-P-FC-FC-S | 1 × 20 | daily activities, locomotion activities | - | - | Skoda, Opportunity, Actitracker |
| [172] | C-P-C-P-FC-S | 5 × 5 | locomotion activities | 6 | S1 | WISDM |
| [173] | C-P-C-P-C-FC | locomotion activities | 12 | S5 | mHealth | |
| [174] | C-P-C-P-FC-FC-S | - | daily activities, locomotion activities | 12 | S1, S2, S3 ECG | mHealth |
| [175] | C-P-C-P-C-P-S | 12 × 2 | daily activities including brush teeth, comb hair, get up from bed, etc | 12 | S1, S2, S3 | WHARF |
| [23] | C-P-C-P-C-P-S | 12 × 2 | locomotion activities | 8 | S1 | Self |
| [113] | C-P-C-P-U-FC-S, U: unification layer | 1 × 3, 1 × 5 | daily activities, hand gesture | 18 (Opp) 12 (hand) | S1, S2 (1 for each) | Opportunity Hand Gesture |
| [63] | C-C-P-C-C-P-FC | 1 × 8 | hand motion classification | 10 | S4 | Rami EMG Dataset |
| [114] | C-C-P-C-C- P-FC-FC-S (one branch for each sensor) | 1 × 5 | daily activities, locomotion activities, industrial ordering picking recognition task | 18 (Opp) 12 (PAMAP2) | S1, S2, S3 | Opportunity, PAMAP2, Order Picking |
| [163] | C-P-C-P-C-P- FC-FC-FC-S | 1 × 4, 1 × 10, 1 × 15 | locomotion activities | 6 | S1, S2, S3 | Self |
| Model | F1-Score (%) | Accuracy (%) |
|---|---|---|
| CNN [252] | 92.93 | 92.71 |
| Res-LSTM [253] | 91.50 | 91.60 |
| Stacked-LSTM [254] | – | 93.13 |
| CNN-LSTM [215] | – | 92.13 |
| Bidir-LSTM [255] | – | 92.67 |
| Residual-BiLSTM [253] | 93.5 | 93.6 |
| LSTM-CNN [211] | – | 95.78 |
| CNN-GRU [248] | – | 96.20 |
| CNN-GRU [247] | 94.54 | 94.58 |
| CNN-LSTM [247] | 94.76 | 94.80 |
| CNN-BiLSTM [247] | 96.31 | 96.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. https://doi.org/10.3390/s22041476
Zhang S, Li Y, Zhang S, Shahabi F, Xia S, Deng Y, Alshurafa N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors. 2022; 22(4):1476. https://doi.org/10.3390/s22041476
Chicago/Turabian StyleZhang, Shibo, Yaxuan Li, Shen Zhang, Farzad Shahabi, Stephen Xia, Yu Deng, and Nabil Alshurafa. 2022. "Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances" Sensors 22, no. 4: 1476. https://doi.org/10.3390/s22041476
APA StyleZhang, S., Li, Y., Zhang, S., Shahabi, F., Xia, S., Deng, Y., & Alshurafa, N. (2022). Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors, 22(4), 1476. https://doi.org/10.3390/s22041476