
E2DR: A Deep Learning Ensemble-Based Driver Distraction Detection with Recommendations Model


Abstract
:1. Introduction
2. Related Work on Deep Learning Driver Distraction Detection
2.1. Single-Based Deep Learning Models
2.2. Hybrid-Based Deep Learning Models
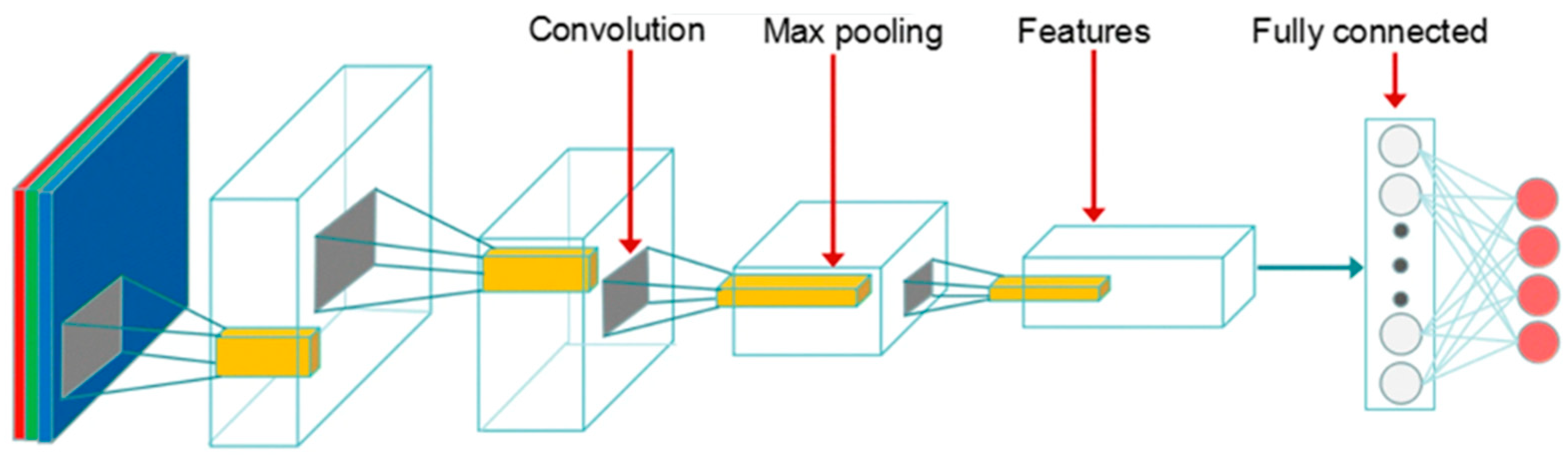
3. Adopted Deep Learning Models
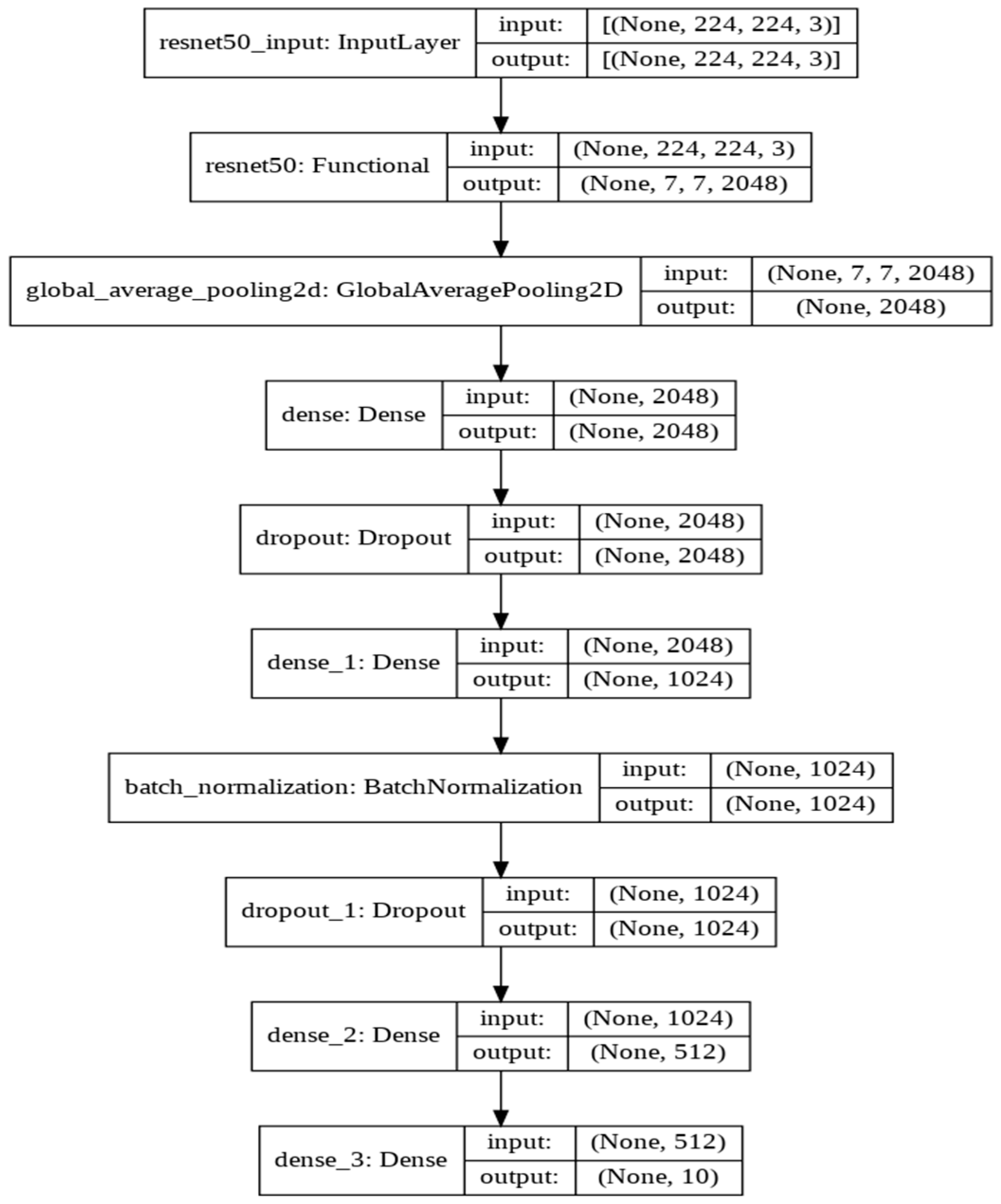
3.1. ResNet50 Model
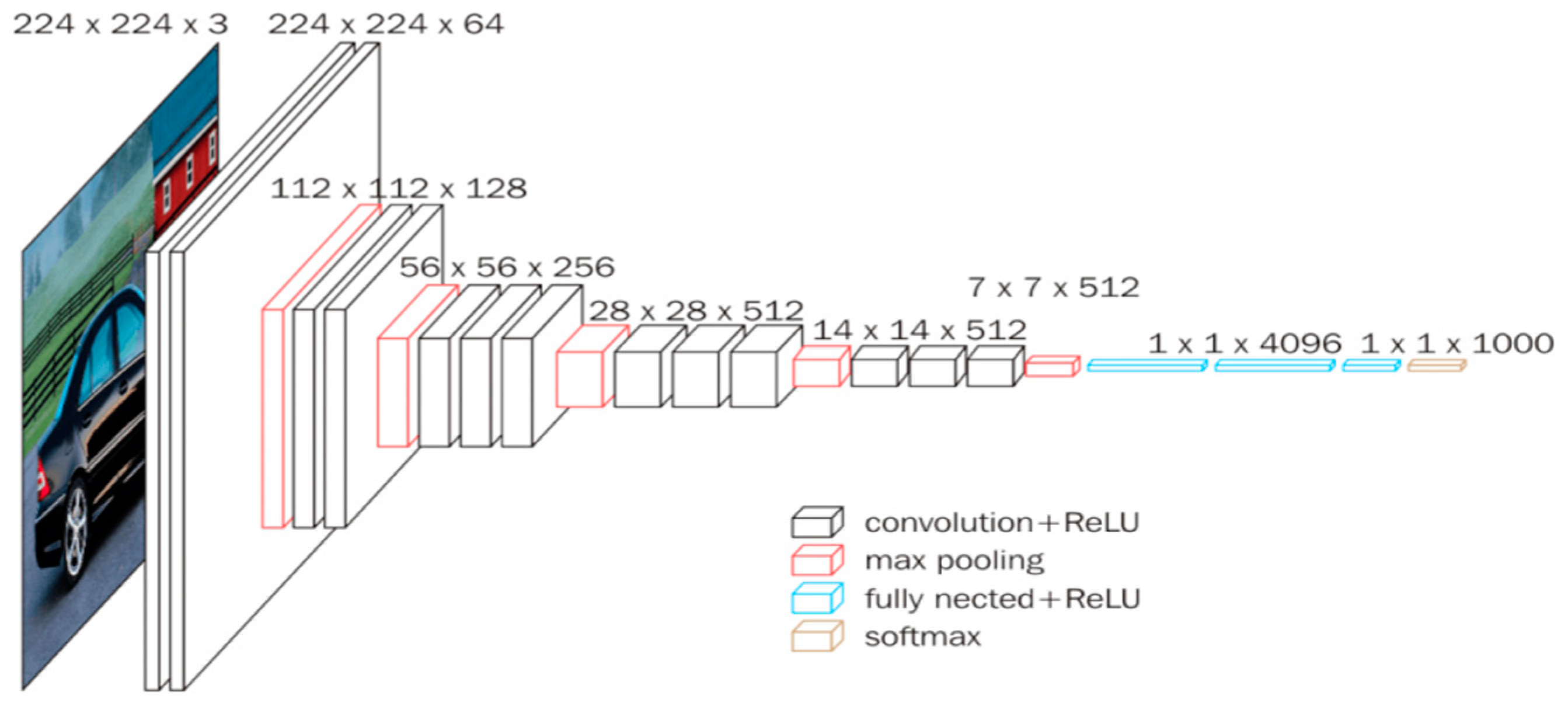
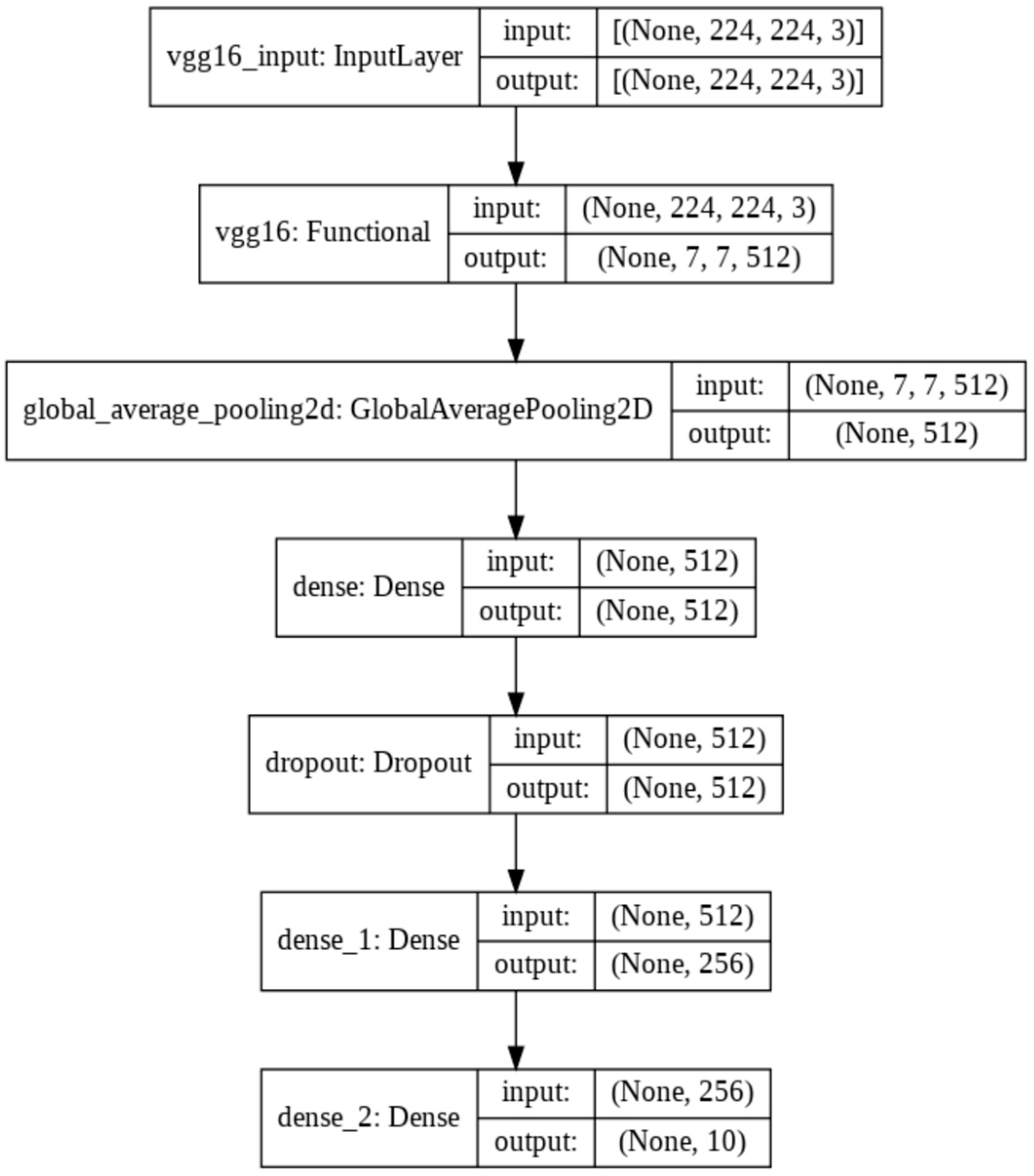
3.2. VGG16 Model
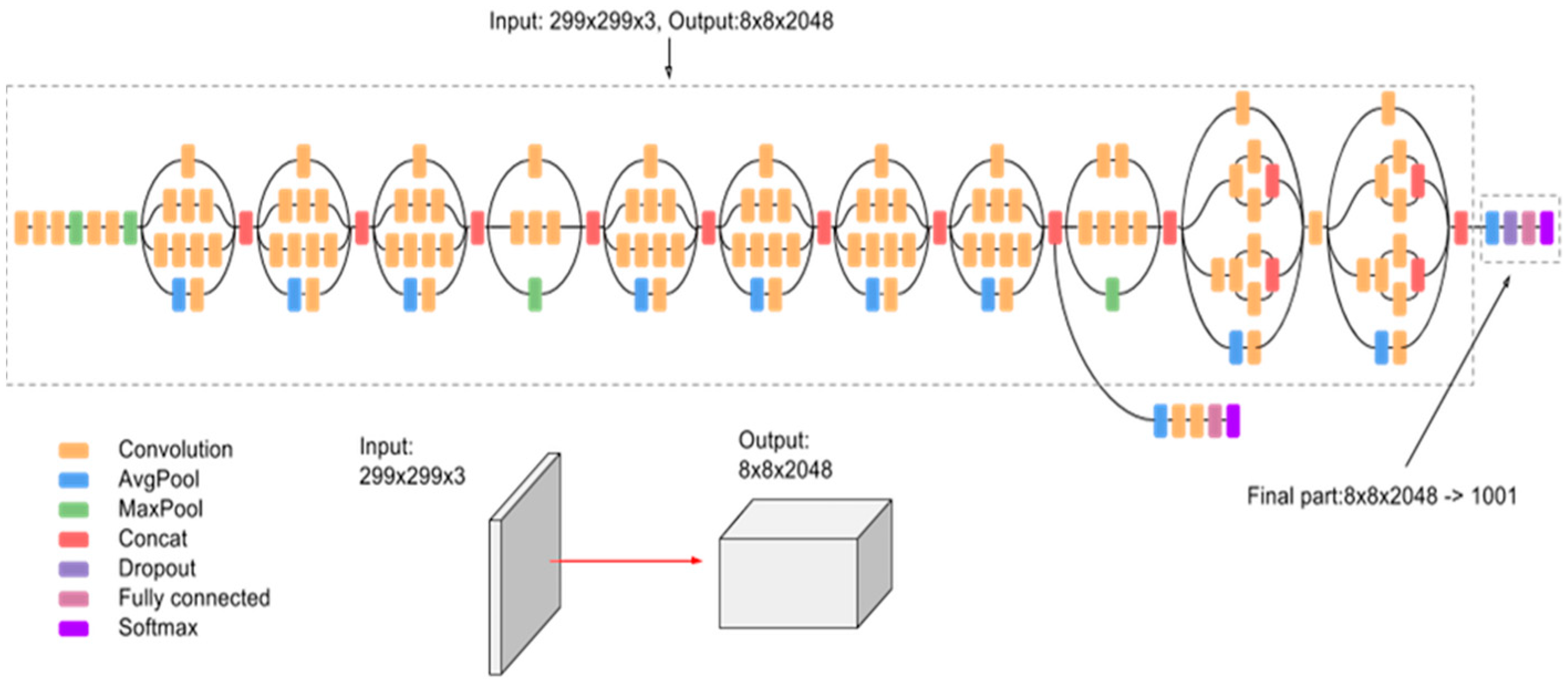
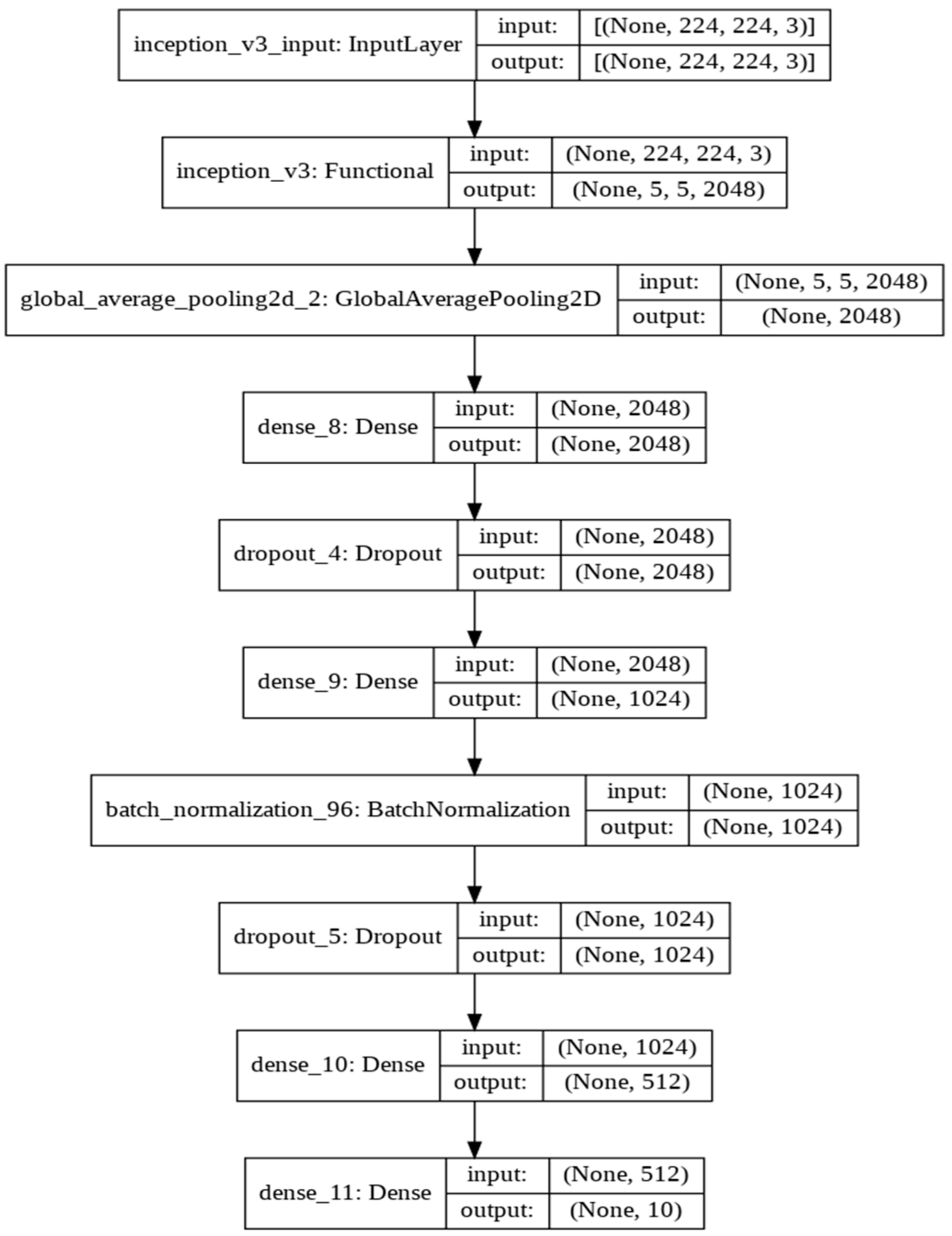
3.3. Inception Model
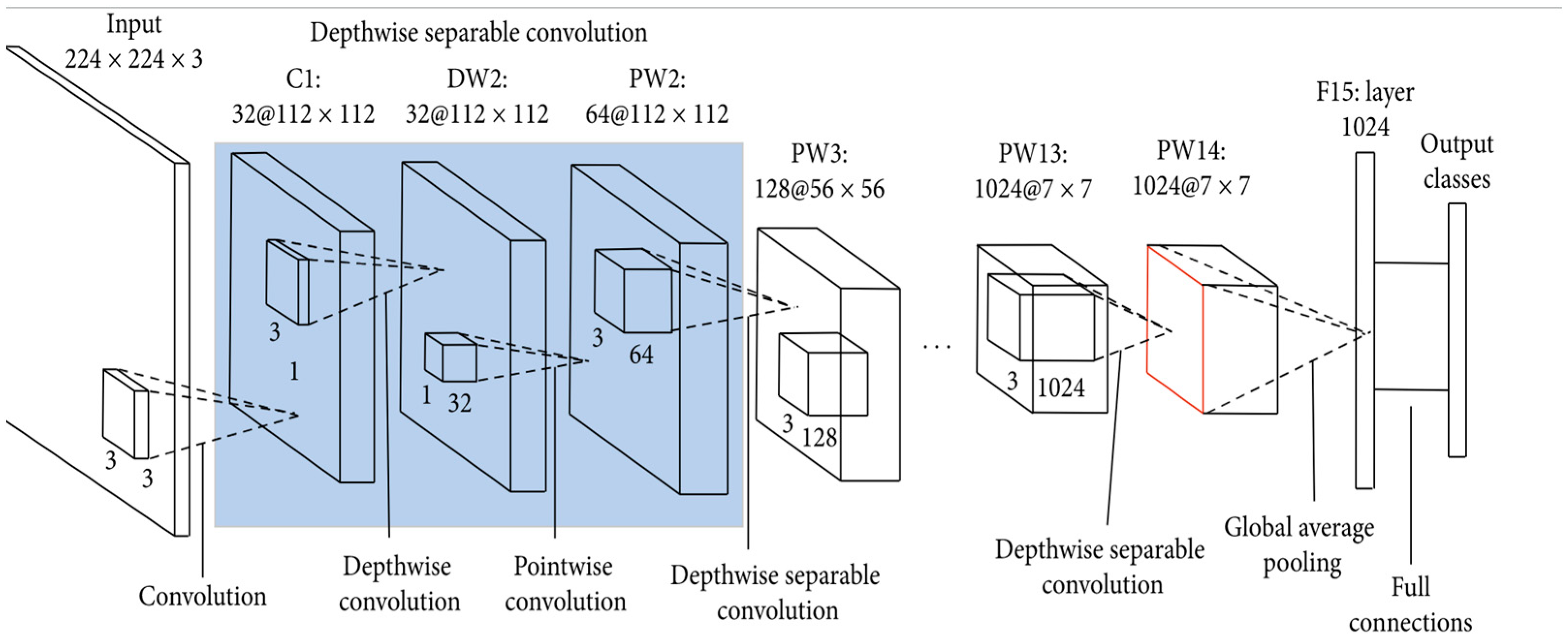
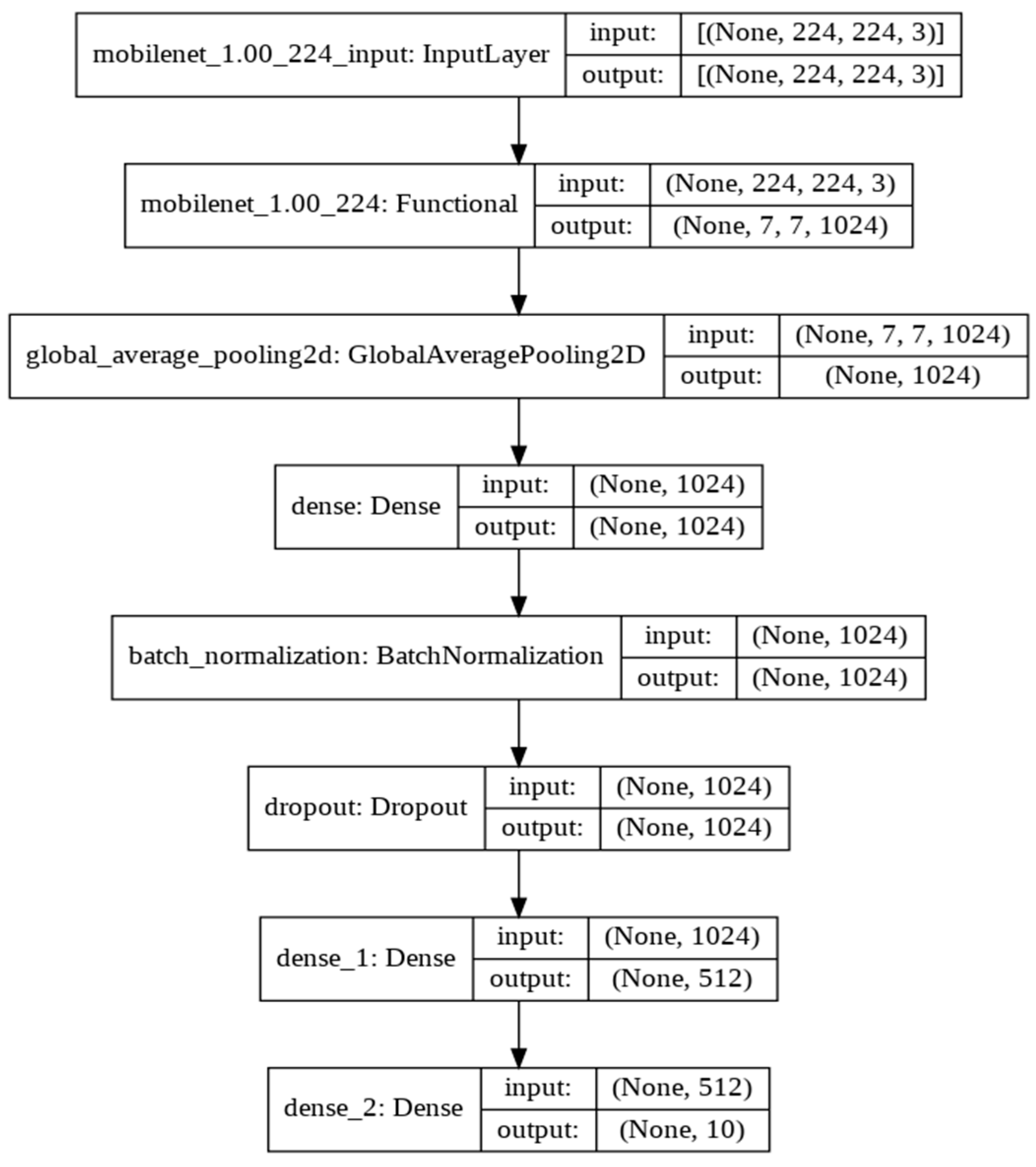
3.4. MobileNet Model
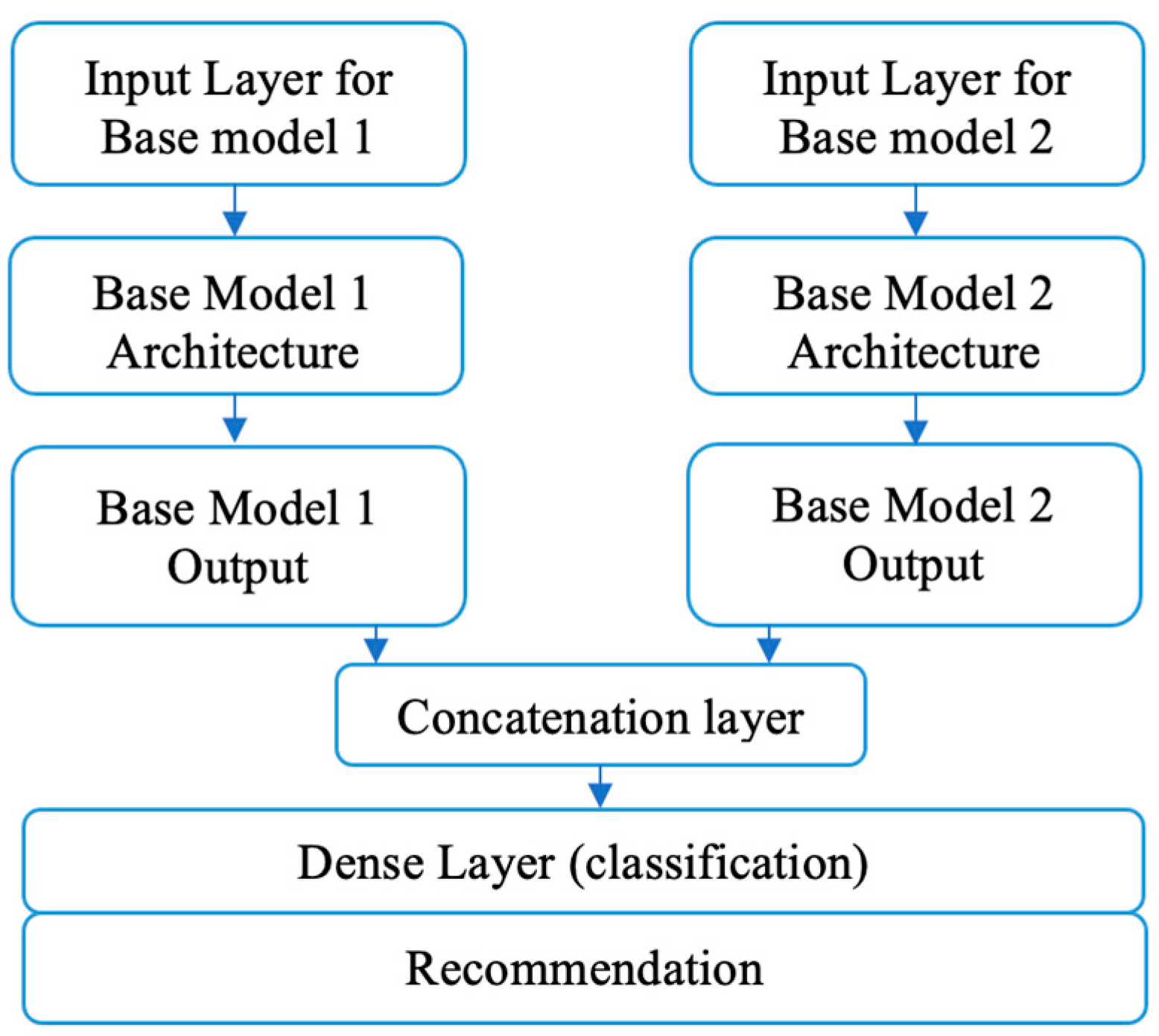
4. The Proposed E2DR Model
4.1. The Ensemble-Based Distraction Detection with Recommendations Model (E2DR)
4.2. E2DR Variants
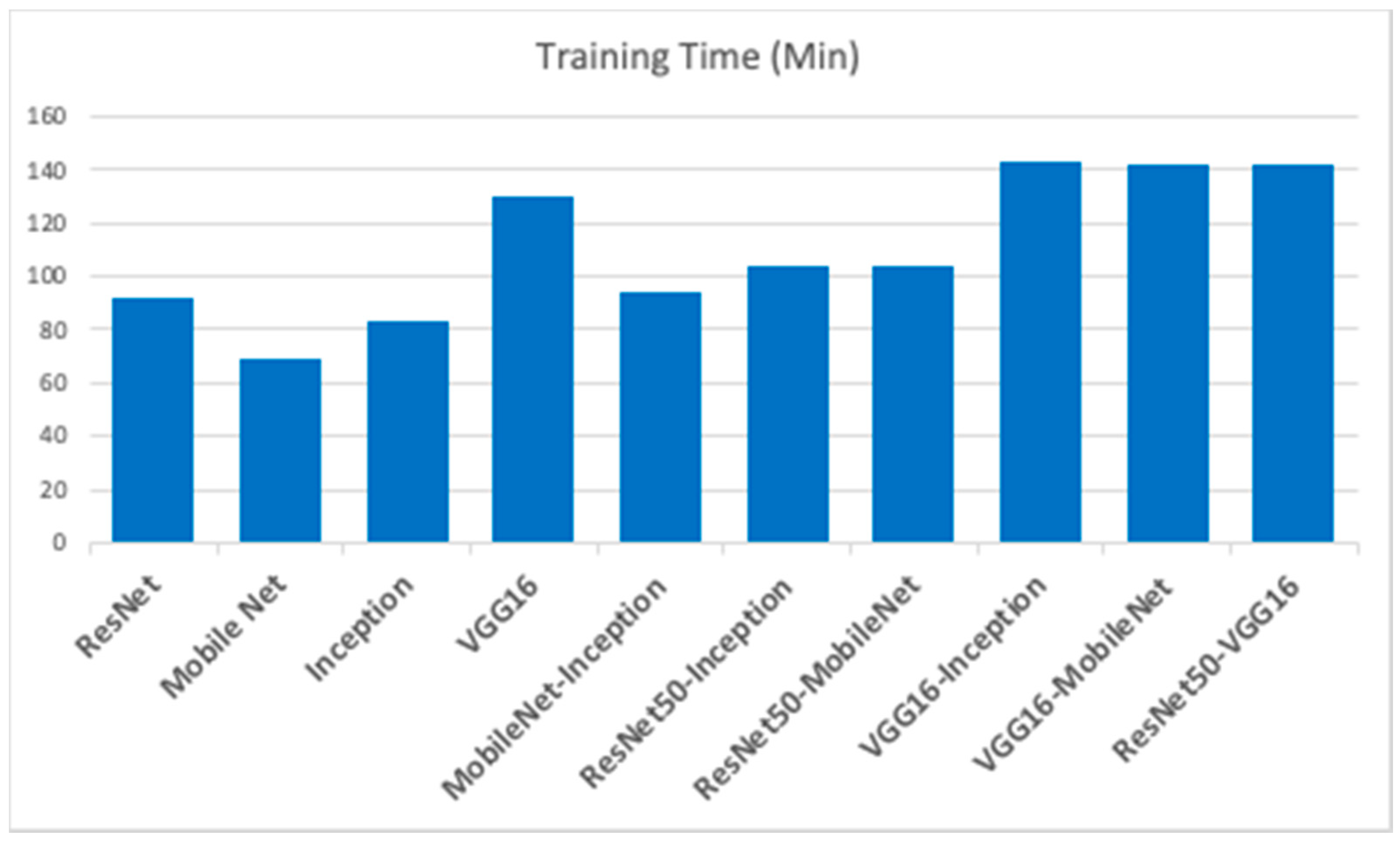
4.3. Computational Complexity
4.4. Adopted Base Model Architectures
4.5. Recommendations
5. Experimental Analysis and Results
5.1. Dataset
5.2. Experimental Setup
5.3. Preprocessing and Splitting Strategy
5.4. Evaluation Metrics
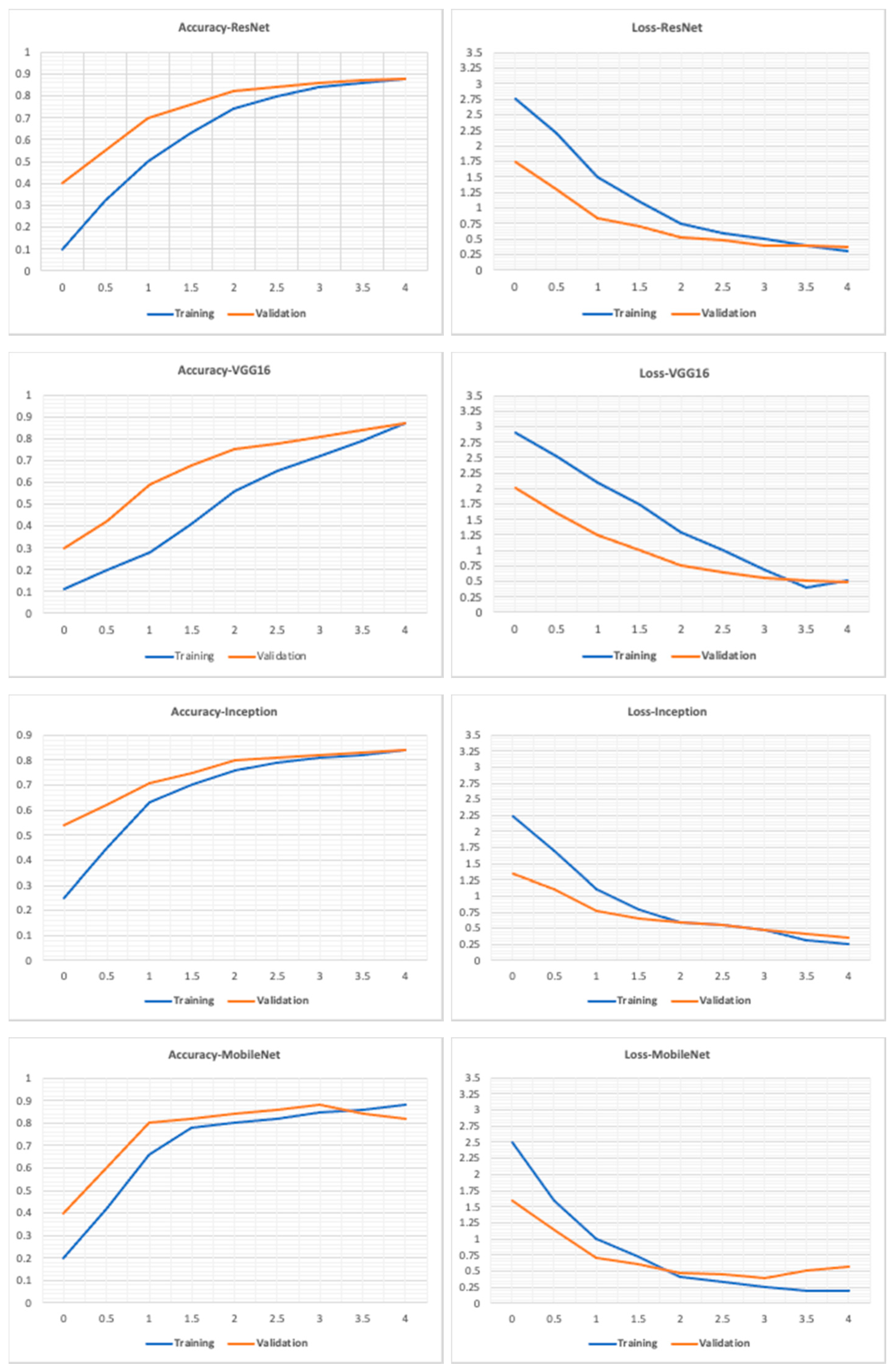
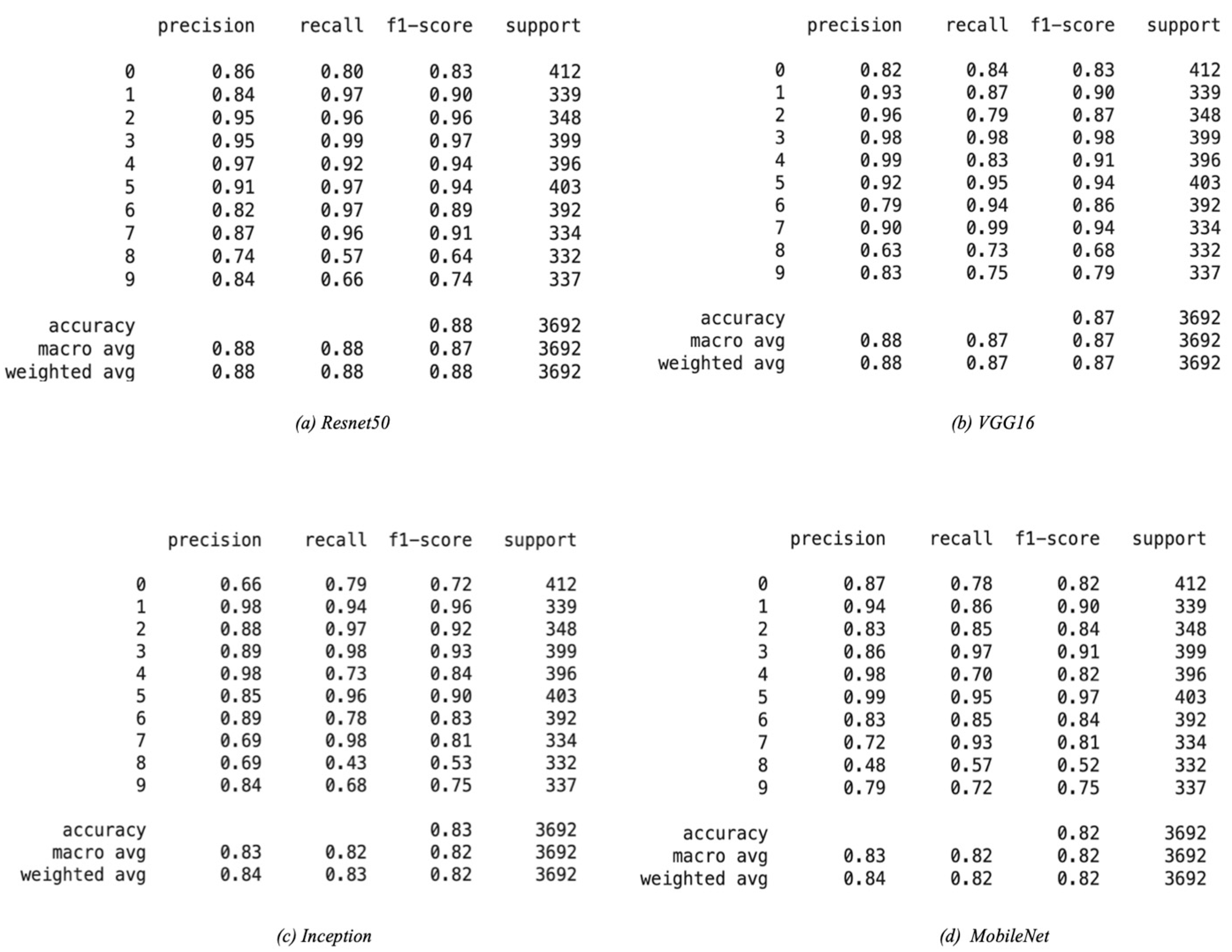
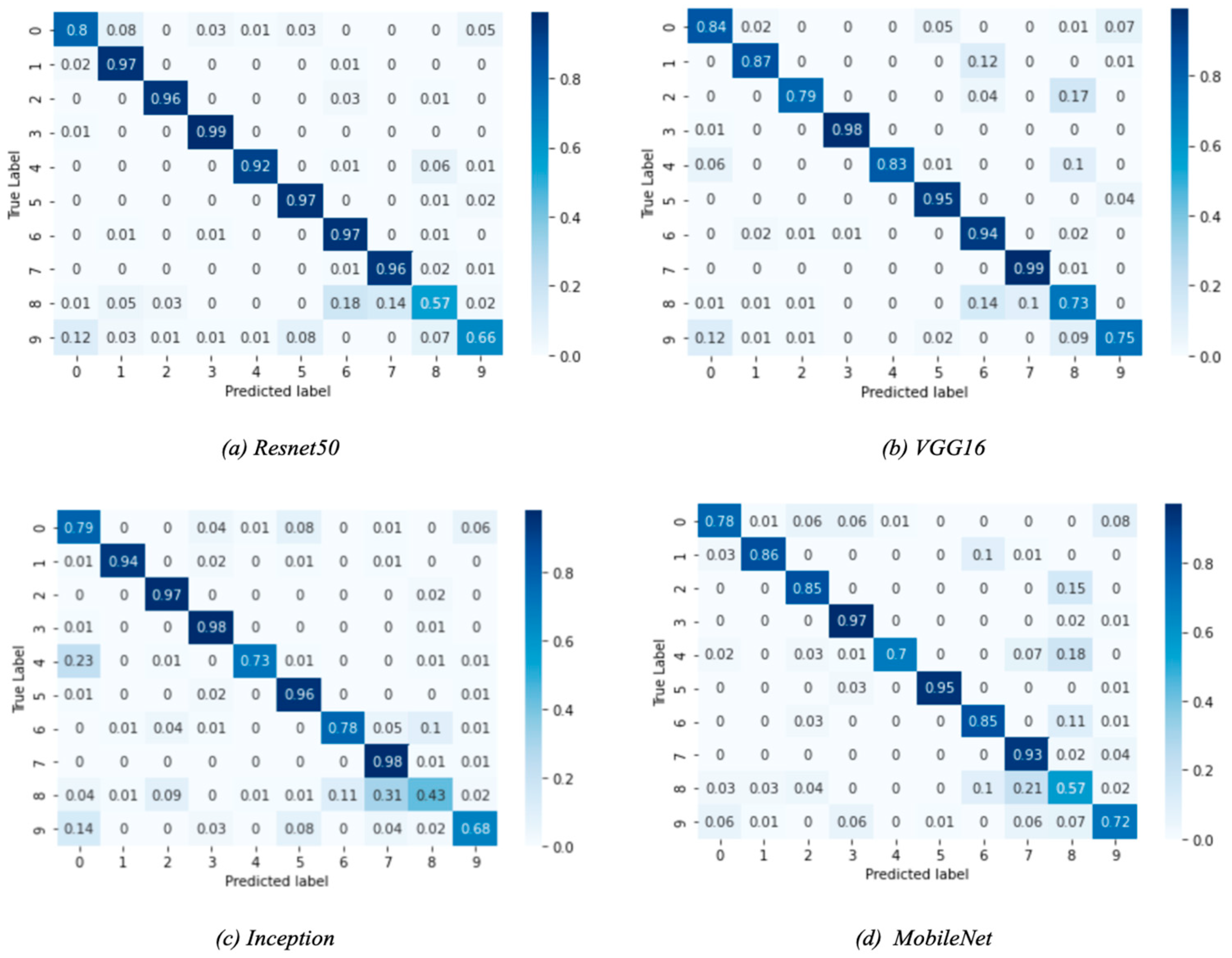
5.5. Performance Evaluation: Base Models
5.6. The E2DR Performance Evaluation
5.6.1. Settings
5.6.2. Results and Discussion
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- The World Health Organization. Global Status Report on Road Safety. 2018. Available online: https://www.who.int/publications/i/item/9789241565684 (accessed on 15 January 2020).
- Yanbin, Y.; Lijuan, Z.; Mengjun, L.; Ling, S. Early warning of traffic accident in Shanghai based on large data set mining. In Proceedings of the 2016 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Changsha, China, 17–18 December 2016; pp. 18–21. [Google Scholar]
- Engstörm, J.; Victor, T.W. Real-Time Distraction Countermeasures. In Driver Distraction: Theory, Effects, and Mitigation; CRC Press: Boca Raton, FL, USA, 2008; pp. 465–483. [Google Scholar]
- Kang, H.B. Various approaches for driver and driving behavior monitoring: A review. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Washington, DC, USA, 2–8 December 2013; pp. 616–623. [Google Scholar]
- Krajewski, J.; Trutschel, U.; Golz, M.; Sommer, D.; Edwards, D. Estimating fatigue from predetermined speech samples trans-mitted by operator communication systems. In Proceedings of the Fifth International Driving Symposium on Human Factors in Driver Assessment, Training and Vehicle Design, Big Sky, MT, USA, 24 June 2009; pp. 468–473. [Google Scholar]
- Alotaibi, M.; Alotaibi, B. Distracted driver classification using deep learning. Signal. Image Video Process. 2019, 14, 617–624. [Google Scholar] [CrossRef]
- Stappen, L.; Rizos, G.; Schuller, B. X-aware: Context-aware human-environment attention fusion for driver gaze prediction in the wild. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual, 25–29 October 2020; pp. 858–867. [Google Scholar]
- Palazzi, A.; Solera, F.; Calderara, S.; Alletto, S.; Cucchiara, R. Learning where to attend like a human driver. IEEE Int. Veh. Symp. 2017, 920–925. [Google Scholar] [CrossRef] [Green Version]
- Methuku, J. In-Car driver response classification using Deep Learning (CNN) based Computer Vision. IEEE Trans. Intell. Veh. 2020. [Google Scholar]
- Jeong, M.; Ko, B.C. Driver’s Facial Expression Recognition in Real-Time for Safe Driving. Sensors 2018, 18, 4270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baheti, B.; Talbar, S.; Gajre, S. Towards Computationally Efficient and Realtime Distracted Driver Detection with Mobile VGG Network. IEEE Transact. Intell. Veh. 2020, 5, 565–574. [Google Scholar] [CrossRef]
- Kumari, M.; Hari, C.; Sankaran, P. Driver Distraction Analysis Using Convolutional Neural Networks. In Proceedings of the 2018 International Conference on Data Science and Engineering (ICDSE), Kochi, India, 7–9 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Lu, M.; Hu, Y.; Lu, X. Driver action recognition using deformable and dilated faster R-CNN with optimized region proposals. Appl. Intell. 2019, 50, 1100–1111. [Google Scholar] [CrossRef]
- Li, P.; Yang, Y.; Grosu, R.; Wang, G.; Li, R.; Wu, Y.; Huang, Z. Driver Distraction Detection Using Octave-Like Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Li, G.; Yan, W.; Li, S.; Qu, X.; Chu, W.; Cao, D. A Temporal-Spatial Deep Learning Approach for Driver Distraction Detection Based on EEG Signals. IEEE Trans. Autom. Sci. Eng. 2021, 1–13. [Google Scholar] [CrossRef]
- Abbas, T.; Ali, S.F.; Khan, A.Z.; Kareem, I. optNet-50: An Optimized Residual Neural Network Architecture of Deep Learning for Driver’s Distraction. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020. [Google Scholar] [CrossRef]
- Xie, Z.; Li, L.; Xu, X. Recognition of driving distraction using driver’s motion and deep learning. IIE Ann. Conf. Proc. 2020, 949–954. [Google Scholar]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. arXiv 2017, arXiv:1706.09498. [Google Scholar]
- Koay, H.; Chuah, J.; Chow, C.-O.; Chang, Y.-L.; Rudrusamy, B. Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification. Sensors 2021, 21, 4837. [Google Scholar] [CrossRef]
- Arvin, R.; Khattak, A.J.; Qi, H. Safety critical event prediction through unified analysis of driver and vehicle volatilities: Application of deep learning methods. Accid. Anal. Prev. 2020, 151, 105949. [Google Scholar] [CrossRef] [PubMed]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.-Y. Driver Activity Recognition for Intelligent Vehicles: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef] [Green Version]
- Varaich, Z.A.; Khalid, S. Recognizing actions of distracted drivers using inception v3 and xception convolutional neural networks. In Proceedings of the 2019 2nd International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 18–20 February 2019; pp. 1–8. [Google Scholar]
- Mao, P.; Zhang, K.; Liang, D. Driver Distraction Behavior Detection Method Based on Deep Learning. IOP Conf. Series. Mater. Sci. Eng. 2020, 782, 22012. [Google Scholar] [CrossRef] [Green Version]
- Mase, J.M.; Chapman, P.; Figueredo, G.P.; Torres, M.T. A Hybrid Deep Learning Approach for Driver Distraction Detection. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 21–23 October 2020. [Google Scholar] [CrossRef]
- Alkinani, M.H.; Khan, W.Z.; Arshad, Q. Detecting Human Driver Inattentive and Aggressive Driving Behavior Using Deep Learning: Recent Advances, Requirements and Open Challenges. IEEE Access 2020, 8, 105008–105030. [Google Scholar] [CrossRef]
- Li, L.; Zhong, B.; Hutmacher, C., Jr.; Liang, Y.; Horrey, W.J.; Xu, X. Detection of driver manual distraction via image-based hand and ear recognition. Accid. Anal. Prevent. 2020, 137, 105432. [Google Scholar] [CrossRef] [PubMed]
- Springer Link. Available online: https://link.springer.com/article/10.1007/s00330-019-06318-1/figures/1 (accessed on 19 March 2021).
- ImageNet. Available online: http://www.image-net.org/ (accessed on 17 March 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Alex, K.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- VGG16—Convolutional Network for Classification and Detection. Available online: https://neurohive.io/en/popular-networks/vgg16/ (accessed on 19 March 2021).
- A Simple Guide to the Versions of the Inception Network. Available online: https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202 (accessed on 19 March 2021).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with con-volutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Bose, S.R.; Kumar, V.S. Efficient inception V2 based deep convolutional neural network for real-time hand action recognition. IET Image Process. 2020, 14, 688–696. [Google Scholar] [CrossRef]
- Szegedy, C.; Vincent, V.; Sergey, I.; Jon, S.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 12 February 2017. [Google Scholar]
- Inception-v3. Available online: https://paperswithcode.com/method/inception-v3 (accessed on 20 March 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Image Classification With MobileNet. Available online: https://medium.com/analytics-vidhya/image-classification-with-mobilenet-cc6fbb2cd470 (accessed on 26 March 2021).
- Kim, W.; Jung, W.-S.; Choi, H.K. Lightweight Driver Monitoring System Based on Multi-Task Mobilenets. Sensors 2019, 19, 3200. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- An Overview on MobileNet: An Efficient Mobile Vision CNN. Available online: https://medium.com/@godeep48/an-overview-on-mobilenet-an-efficient-mobile-vision-cnn-f301141db94d (accessed on 15 July 2021).
- Wolpert, D.H. Stacked generalization. Neural Networks 1992, 5, 241–259. [Google Scholar] [CrossRef]
- ResNet and ResNetV2. Available online: https://keras.io/api/applications/resnet/#resnet50-function (accessed on 17 July 2021).
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second international joint conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- State Farm Distracted Driver Detection. Available online: https://www.kaggle.com/c/state-farm-distracted-driver-detection (accessed on 25 July 2021).
- Close, L.; Kashef, R. Combining Artificial Immune System and Clustering Analysis: A Stock Market Anomaly Detection Model. J. Intell. Learn. Syst. Appl. 2020, 12, 83–108. [Google Scholar] [CrossRef]
- Kashef, R. Enhancing the Role of Large-Scale Recommendation Systems in the IoT Context. IEEE Access 2020, 8, 178248–178257. [Google Scholar] [CrossRef]
- Yeh, T.-Y.; Kashef, R. Trust-Based Collaborative Filtering Recommendation Systems on the Blockchain. Adv. Int. Things 2020, 10, 37–56. [Google Scholar] [CrossRef]
- Ebrahimian, M.; Kashef, R. Detecting Shilling Attacks Using Hybrid Deep Learning Models. Symmetry 2020, 12, 1805. [Google Scholar] [CrossRef]
- Li, M.; Kashef, R.; Ibrahim, A. Multi-Level Clustering-Based Outlier’s Detection (MCOD) Using Self-Organizing Maps. Big Data Cogn. Comput. 2020, 4, 24. [Google Scholar] [CrossRef]
- Tobin, T.; Kashef, R. Efficient Prediction of Gold Prices Using Hybrid Deep Learning. In International Conference on Image Analysis and Recognition; Springer: Cham, The Netherlands, 2020; pp. 118–129. [Google Scholar]
- Ledezma, A.; Zamora, V.; Sipele, O.; Sesmero, M.; Sanchis, A. Implementing a Gaze Tracking Algorithm for Improving Advanced Driver Assistance Systems. Electronics 2021, 10, 1480. [Google Scholar] [CrossRef]
- Liu, D.; Yamasaki, T.; Wang, Y.; Mase, K.; Kato, J. TML: A Triple-Wise Multi-Task Learning Framework for Distracted Driver Recognition. IEEE Access 2021, 9, 125955–125969. [Google Scholar] [CrossRef]
- Kumar, A.; Sangwan, K.S. A Computer Vision Based Approach forDriver Distraction Recognition Using Deep Learning and Genetic Algorithm Based Ensemble. arXiv 2021, arXiv:2107.13355. [Google Scholar]
- Eraqi, H.M.; Abouelnaga, Y.; Saad, M.H.; Moustafa, M.N. Driver Distraction Identification with an Ensemble of Convolutional Neural Networks. J. Adv. Transp. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Gite, S.; Agrawal, H.; Kotecha, K. Early anticipation of driver’s maneuver in semiautonomous vehicles using deep learning. Prog. Artif. Intell. 2019, 8, 293–305. [Google Scholar] [CrossRef]
- Magán, E.; Ledezma, A.; Sesmero, P.; Sanchis, A. Fuzzy Alarm System based on Human-centered Approach. VEHITS 2020, 448–455. [Google Scholar] [CrossRef]
- Sipele, O.; Zamora, V.; Ledezma, A.; Sanchis, A. Advanced Driver’s Alarms System through Multi-agent Paradigm. In Proceedings of the 2018 3rd IEEE International Conference on Intelligent Transportation Engineering(ICITE), Singapore, 3–5 September 2018; pp. 269–275. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Model (Type) | Dataset | Validation | Pros | Cons |
|---|---|---|---|---|---|
| [7] | Deep learning Gaze estimation system | Driver Gaze in the Wild dataset | Accuracy | High performance | It can be only accurate to an extent |
| [8] | Deep learning Gaze estimation driver-assistant system | DR(eye)VE dataset | Ground truth | Provide suggestion | Driver gaze is subjective |
| [9] | Deep learning distracted driver detection | Distracted driver dataset | Accuracy, Recall, Precision, F1 score | Computationally efficient | Few epochs for training |
| [10] | Hierarchical, weighted random forest (WRF) model | The Keimyung University Facial Expression of Drivers (KMU-FED) and the Cohn-Kahnde datasets | Accuracy | Requires low amount of memory and computing operations | Not accurate when the face is rotated |
| [11] | Driver distraction detection using CNNs | State farm dataset and the AUC distracted driver dataset | Accuracy, sensitivity | Computationally efficient | Not enough validation metrics |
| [12] | Deep learning distracted driver detection using pose estimation | AUC Distracted Driver Dataset | Accuracy, Fl score | Pose estimation improves accuracy | Low-resolution images affected training |
| [13] | Driver action recognition using R-CNN | images of different driver actions | Accuracy and log loss | Effective feature representation | Small dataset |
| [14] | Driver Distraction recognition Using Octave-Like CNN | Lilong Distracted Driving Behavior data | Accuracy, training duration | Lightweight network | Not enough validation metrics |
| [15] | Temporal–Spatial Deep Learning driver distraction detection | EEG signals from 24 participants | Precision, Recall, F1 score | Unique approach | Drivers’ individual differences need to be considered |
| [16] | Optimized Residual Neural Network Architecture | The State Farm Distracted Driver dataset | Accuracy, training time | Enhanced model | Only detects head movement |
| [17] | Wearable sensing and deep learning driver distraction detection | Wearable sensing information from 20 participants | Recall, Precision, F1 score | Good potential | Small dataset |
| [18] | Hybrid Distraction detection model using deep learning | State farm dataset | Accuracy | Computationally expensive | Not enough validation |
| [19] | Triple-Wise Multi-Task Learning | AUC Distracted Driver Dataset | Accuracy, sensitivity | High detection accuracy | High computational cost |
| [20] | Safety-critical events prediction | Driving events from 3500 drivers | Accuracy, Recall, Precision, F1 score | Can detect potential car accidents | Hard to get enough data |
| [21] | CNN driver action detection system | 10 drivers’ data with driving activities | Accuracy | Accurate | It does not detect the driver action |
| [22] | CNN driver action detection system | Distracted driver dataset | Accuracy and loss | Computationally simple | Not enough training |
| [23] | Distracted driver behavior detection using deep learning | Self-built dataset of drivers making phone calls and smoking | Recall, Precision, Speed | Real-time | Only trained to detect 2 driver actions |
| [24] | hybrid driver distraction detection model | (AUC) Distracted Driver Dataset | Accuracy and loss | High Performance | Complex |
| [25] | Driver Inattentiveness detection | NA | Accuracy | Comprehensive analysis of deep learning models | Not effective in detecting aggressive behavior |
| [26] | Deep learning manual distraction detection model | 106,677 frames extracted from a video that was taken from 20 participants in a driving simulator | Accuracy, Recall, Precision, F1 score | Novel approach | Only detects manual distraction |
| Class Number | Class | Recommendation |
|---|---|---|
| C0 | Safe driving | - |
| C1 | Texting—Right | “Please avoid texting in all cases or make a stop” |
| C2 | Talking on the phone—Right | “Please use a hands-free device” |
| C3 | Texting—Left | “Please avoid texting in all cases or make a stop” |
| C4 | Talking on the phone—Left | “Please use a hands-free device” |
| C5 | Adjusting Radio | “Please use steering control” |
| C6 | Drinking | “Please keep your hands at the steering wheel or make a stop” |
| C7 | Reaching Behind | “Please keep your eyes on the road make a stop” |
| C8 | Hair and Makeup | “Please make a stop” |
| C9 | Talking to passenger | “Please keep your eyes on the road while talking” |
| Model | Training Accuracy | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| ResNet | 0.89 | 0.88 | 0.88 |
| VGG16 | 0.94 | 0.86 | 0.87 |
| Mobile Net | 0.88 | 0.84 | 0.82 |
| Inception | 0.83 | 0.84 | 0.83 |
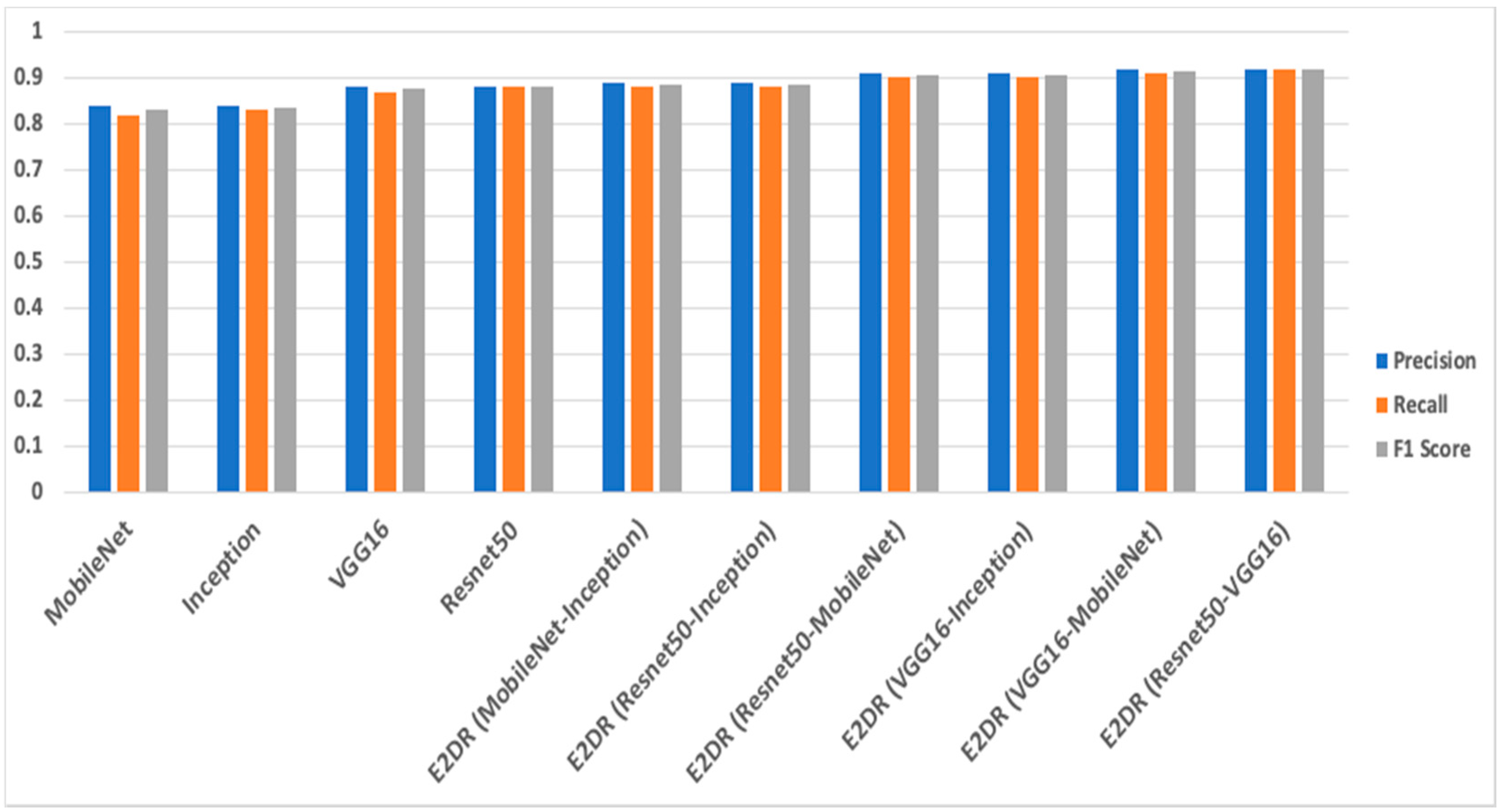
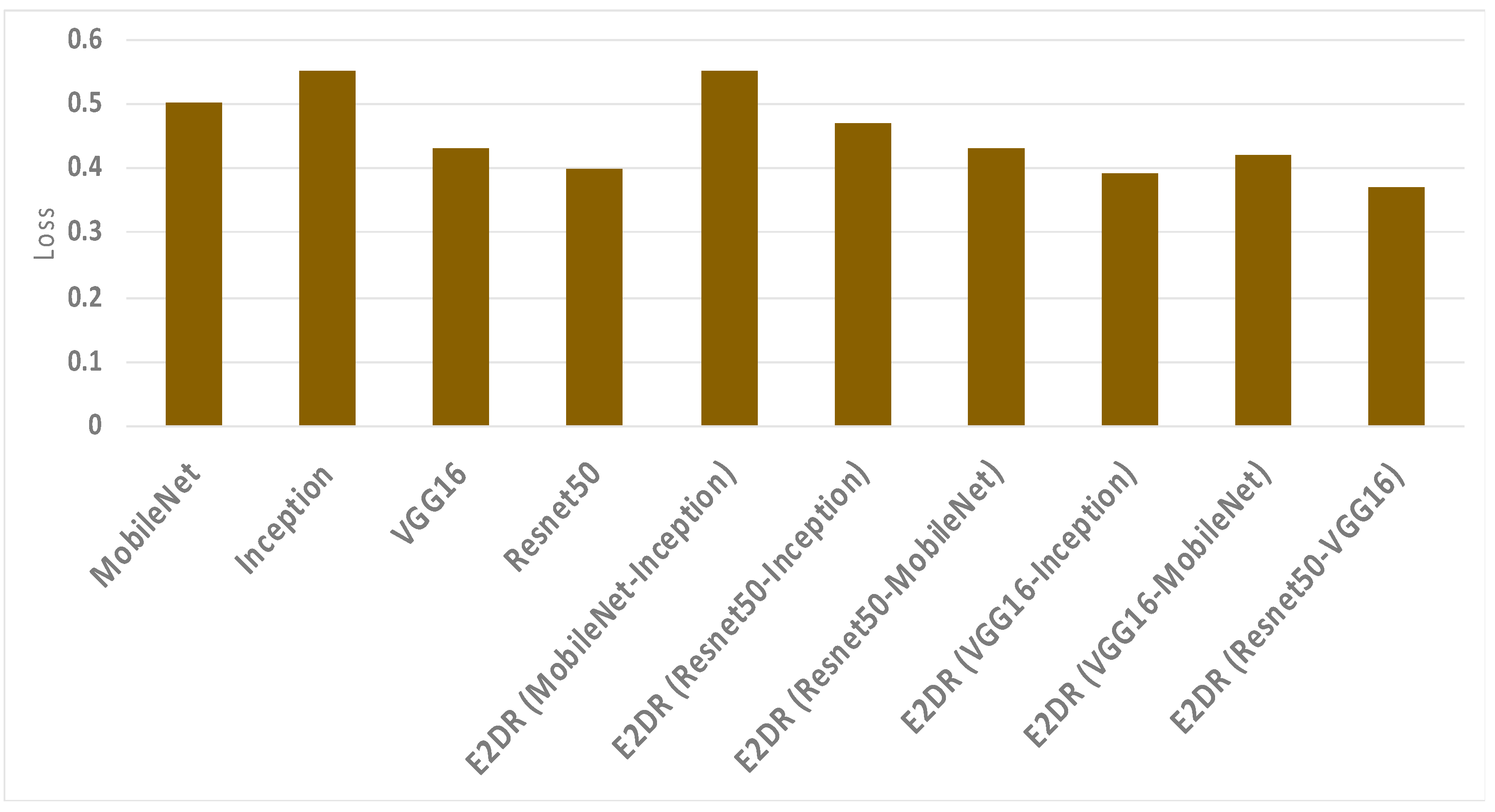
| E2DR Model | Accuracy | Precision | Recall | F1 Score | Loss |
|---|---|---|---|---|---|
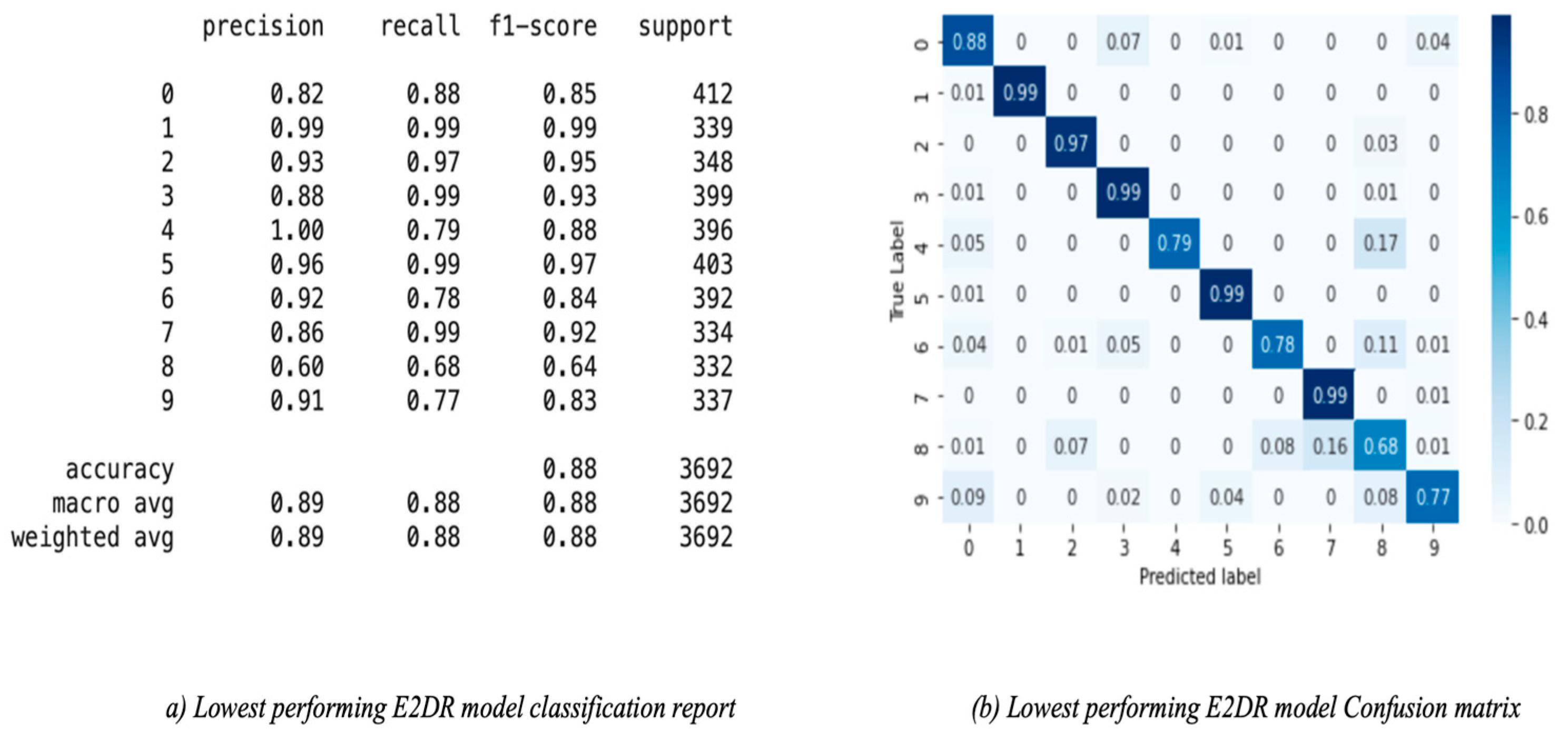
| MobileNet–Inception | 0.88 | 0.89 | 0.88 | 0.88 | 0.55 |
| ResNet50–Inception | 0.88 | 0.89 | 0.88 | 0.88 | 0.47 |
| ResNet50–MobileNet | 0.90 | 0.91 | 0.9 | 0.9 | 0.43 |
| VGG16–Inception | 0.90 | 0.91 | 0.9 | 0.9 | 0.39 |
| VGG16–MobileNet | 0.91 | 0.92 | 0.91 | 0.91 | 0.42 |
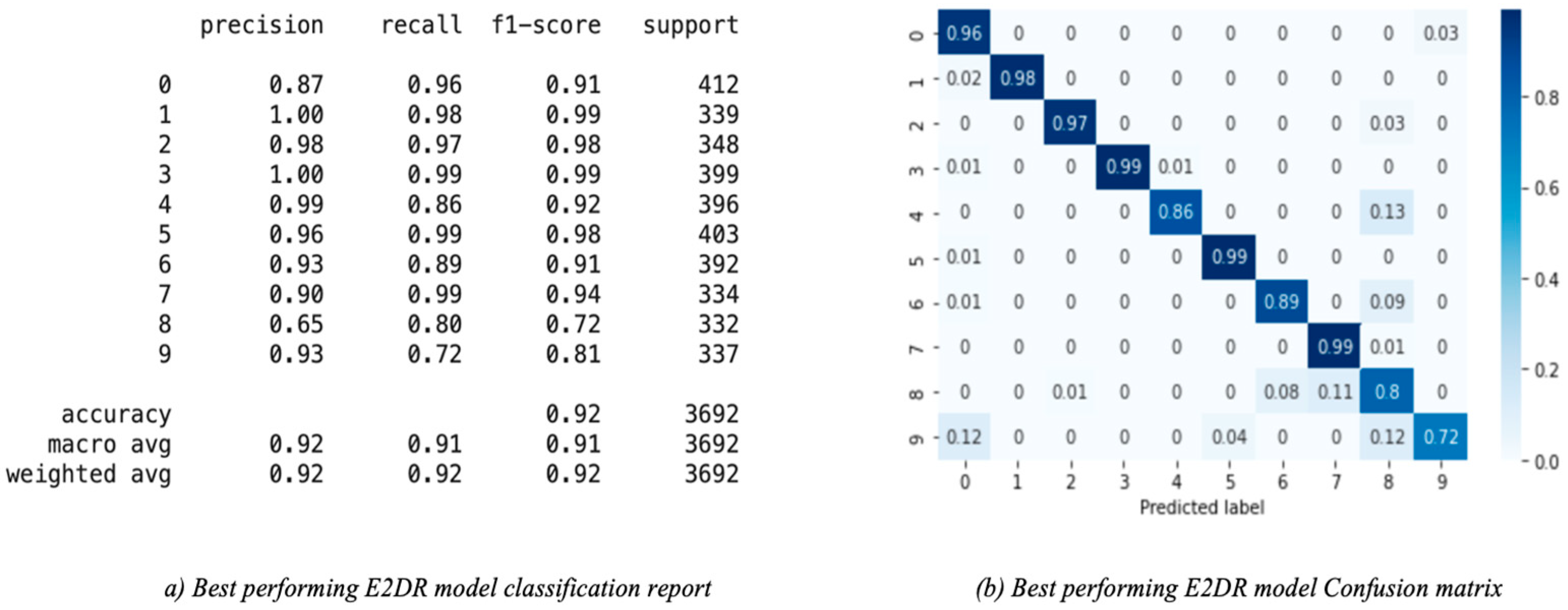
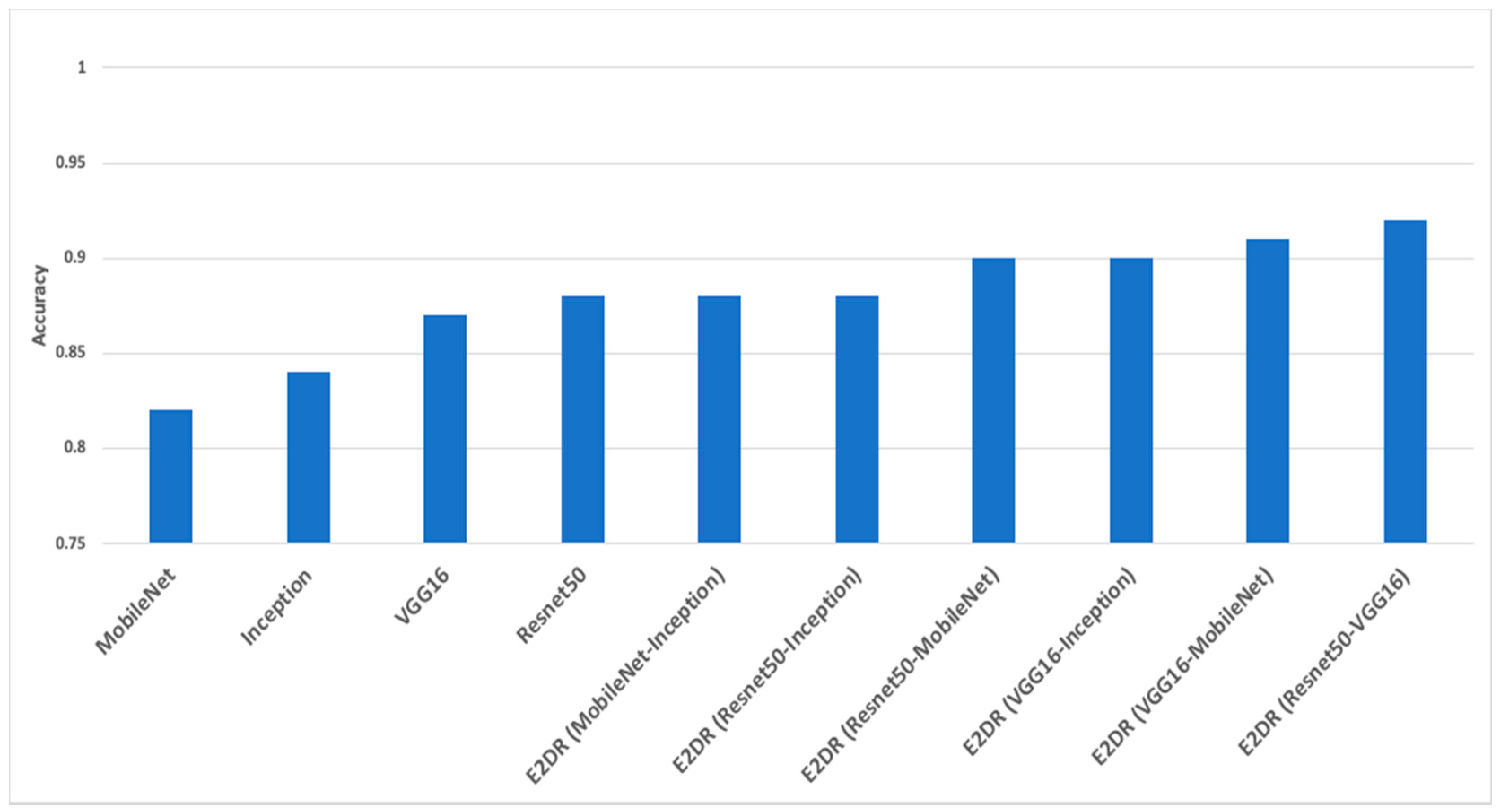
| ResNet50–VGG16 | 0.92 | 0.92 | 0.92 | 0.92 | 0.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aljasim, M.; Kashef, R. E2DR: A Deep Learning Ensemble-Based Driver Distraction Detection with Recommendations Model. Sensors 2022, 22, 1858. https://doi.org/10.3390/s22051858
Aljasim M, Kashef R. E2DR: A Deep Learning Ensemble-Based Driver Distraction Detection with Recommendations Model. Sensors. 2022; 22(5):1858. https://doi.org/10.3390/s22051858
Chicago/Turabian StyleAljasim, Mustafa, and Rasha Kashef. 2022. "E2DR: A Deep Learning Ensemble-Based Driver Distraction Detection with Recommendations Model" Sensors 22, no. 5: 1858. https://doi.org/10.3390/s22051858
APA StyleAljasim, M., & Kashef, R. (2022). E2DR: A Deep Learning Ensemble-Based Driver Distraction Detection with Recommendations Model. Sensors, 22(5), 1858. https://doi.org/10.3390/s22051858