
Transmission Line Vibration Damper Detection Using Multi-Granularity Conditional Generative Adversarial Nets Based on UAV Inspection Images

Abstract
:1. Introduction
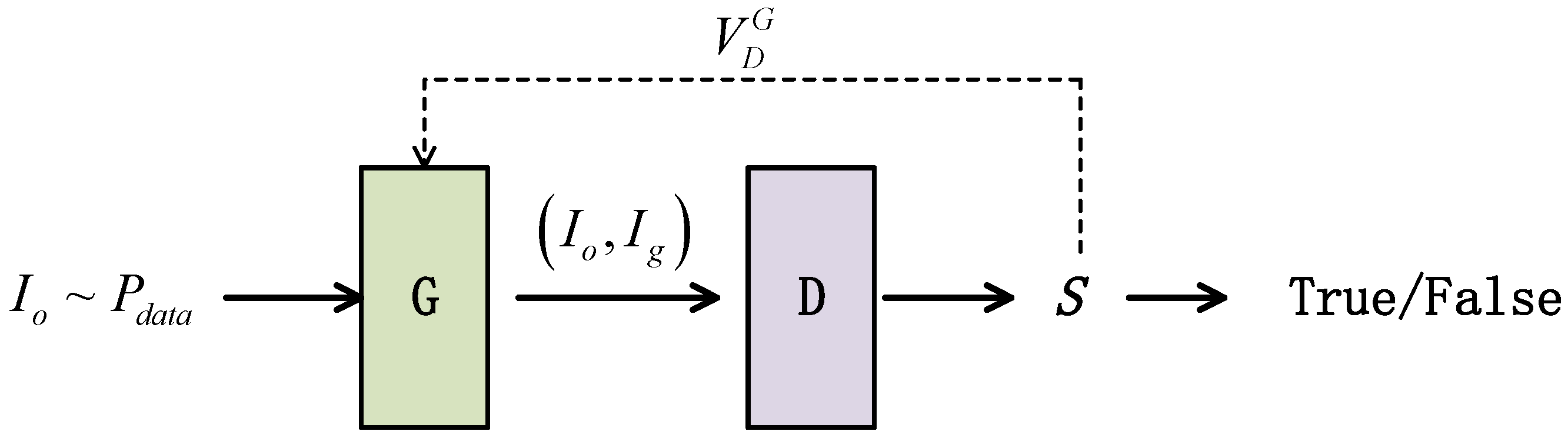
- On the basis of an improved conditional generative adversarial network, we proposed a framework for vibration damper detection image generation named DamperGAN. The framework contains a two-stage generator and a multi-scale discriminator.
- In order to generate high-resolution vibration damper detection images, we used a coarse-to-fine generation method. At the same time, an attention mechanism and a penalty mechanism based on Monte Carlo search were introduced into the generator to provide enough semantic information for image generation to improve the edge information of the image.
- In order to improve the high-resolution images generated by the discriminator, we proposed a multi-level discriminator structure based on the parameter sharing mechanism, so that the entire discriminator pays attention to both semantic information and underlying feature information.
- Aiming to address the problem of no public dataset in the field of vibration damper detection, we established a dataset named DamperGenSet that is based on real optical images from UAV aerial photography. Through comparison with the experimental results of multiple state-of-the-art models on the DamperGenSet dataset, we prove that our proposed DamperGAN has certain advantages.

2. Related Work
2.1. Damper Detection
2.2. Image Generation
2.3. Research Summary
- Detection using traditional image processing algorithms is limited by the quality of the input image and the rationality of operator selection. If the background information in the image is too complex, the vibration damper will not be obvious enough, and importantly, the plated feature information will be weakened by the background. This makes it difficult for the feature operator to fully output the completed vibration damper information. The advantage of the traditional method is that the calculation speed is fast and the resource occupancy rate is low. In simple scenarios with high real-time requirements, it is still the most effective detection method.
- CNN-based methods are currently the most accurate solutions in the field of vibration damper detection. We only require a sufficient amount of training data to obtain an excellent end-to-end detection model. However, there is not yet a fully public vibration damper dataset. Nevertheless, such methods require higher computing power for operating equipment. We want to provide a solution that runs in real time on edge devices such as drones.
- The image generation algorithm led by GAN provides us with new solutions. CGAN uses the idea of adversarial learning to output high-quality images with a simple network structure. At the same time, auxiliary conditions can help us define the semantic information in the image. However, the current research work still has the problem of the image not being delicate enough, and there is no research work on the CGAN-based class of vibration dampers for transmission lines.
3. Basic Knowledge of GAN
4. DamperGAN
4.1. Overall Framework
4.2. Multi-Granularity Generator
4.2.1. Penalty Mechanism
4.2.2. Attention Mechanism
4.2.3. Objective Function
4.3. Multi-Level Discriminator
4.3.1. Multitasking Mechanism
4.3.2. Objective Function
| Algorithm 1. The training process of DamperGAN. |
| Input: Real damper image dataset ; Generator ; Discriminator ; g-steps, the training step of the generator; d-steps, the training step of the discriminators. |
| Output: , generator after training. |
| 1: Initialize generator and discriminator with random weights; |
| 2: repeat |
| 3: for g-steps, perform |
| 4: generate fake images; |
| 5: Calculate the penalty value via Equation (6); |
| 6: Minimize Equation (9) to update the parameters of the generator ; |
| 7: end for |
| 8: for d-steps, perform |
| 9: Use to generate fake images ; |
| 10: Use real images and fake images to update the discriminator parameters by minimizing Equation (10); |
| 11: end for |
| 12: until DamperGAN completes convergence |
| 13: return |
4.4. Network Structure
5. Experiments and Analysis
5.1. Experiment Description
5.1.1. Dataset
5.1.2. Experiment Configuration
5.2. The Baselines
5.3. Qualitative Evaluation
5.4. Quantitative Evaluation
5.4.1. Inception Score (IS) and Fréchet Inception Distance (FID)
5.4.2. Structural Similarity (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Sharpness Difference (SD)
5.5. Sensitivity Analysis
5.5.1. Two-Stage Generation
5.5.2. Monte Carlo Search
5.5.3. Multi-Level Discriminator
5.5.4. Number of Epochs
5.5.5. Minimum Training Data Experiment
5.6. Computational Complexity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bao, W.; Ren, Y.; Wang, N.; Hu, G.; Yang, X. Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sens. 2021, 13, 4134. [Google Scholar] [CrossRef]
- Wu, H.; Xi, Y.; Fang, W.; Sun, X.; Jiang, L. Damper detection in helicopter inspection of power transmission line. In Proceedings of the 2014 4th International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 18–20 September 2014; pp. 628–632. [Google Scholar] [CrossRef]
- Ma, Y.; Li, Q.; Chu, L.; Zhou, Y.; Xu, C. Real-Time Detection and Spatial Localization of Insulators for UAV Inspection Based on Binocular Stereo Vision. Remote Sens. 2021, 13, 230. [Google Scholar] [CrossRef]
- Hinas, A.; Roberts, J.M.; Gonzalez, F. Vision-Based Target Finding and Inspection of a Ground Target Using a Multirotor UAV System. Sensors 2017, 17, 2929. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Han, W.; Chen, H.; Li, G.; Tang, J. Recognizing Zucchinis Intercropped with Sunflowers in UAV Visible Images Using an Improved Method Based on OCRNet. Remote Sens. 2021, 13, 2706. [Google Scholar] [CrossRef]
- Popescu, D.; Stoican, F.; Stamatescu, G.; Chenaru, O.; Ichim, L. A Survey of Collaborative UAV–WSN Systems for Efficient Monitoring. Sensors 2019, 19, 4690. [Google Scholar] [CrossRef] [Green Version]
- Zhi, Y.; Fu, Z.; Sun, X.; Yu, J. Security and Privacy Issues of UAV: A Survey. Mob. Netw. Appl. 2020, 25, 95. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Dimou, A.; Zarpalas, D.; Méndez, M.; de la Iglesia, D.; González, I.; Mercier, J.-P.; et al. Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors 2021, 21, 2824. [Google Scholar] [CrossRef]
- Hassanzadeh, A.; Zhang, F.; van Aardt, J.; Murphy, S.P.; Pethybridge, S.J. Broadacre Crop Yield Estimation Using Imaging Spectroscopy from Unmanned Aerial Systems (UAS): A Field-Based Case Study with Snap Bean. Remote Sens. 2021, 13, 3241. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, X.; Li, W.; Chen, S. Automatic Power Line Inspection Using UAV Images. Remote Sens. 2017, 9, 824. [Google Scholar] [CrossRef] [Green Version]
- Pan, L.; Xiao, X. Image recognition for on-line vibration monitoring system of transmission line. In Proceedings of the 2009 9th International Conference on Electronic Measurement & Instruments, Beijing, China, 16–19 August 2009; pp. 3-1078–3-1081. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. Available online: https://arxiv.org/abs/1411.1784 (accessed on 5 February 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural network. In Proceedings of the 25th Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Song, W.; Zuo, D.; Deng, B.; Zhang, H.; Xue, K.; Hu, H. Corrosion defect detection of earthquake hammer for high voltage transmission line. Chin. J. Sci. Instrum. 2016, 37, 113–117. [Google Scholar]
- Yang, H.; Guo, T.; Shen, P.; Chen, F.; Wang, W.; Liu, X. Anti-vibration hammer detection in UAV image. In Proceedings of the 2017 2nd International Conference on Power and Renewable Energy (ICPRE), Chengdu, China, 20–23 September 2017; pp. 204–207. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, X.; Zhang, Y.; Zhao, L. A method of identifying rust status of dampers based on image processing. IEEE Trans. Instrum. Meas. 2020, 69, 5407–5417. [Google Scholar] [CrossRef]
- Liu, Y.; Wen, S.; Chen, Z.; Zhang, D. Research of the Anti-vibration Hammer Resetting Robot Based on Machine Vision. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3708–3712. [Google Scholar] [CrossRef]
- Miao, S.; Sun, W.; Zhang, H. Intelligent visual method based on wavelet moments for obstacle recognition of high voltage transmission line deicer robot. Jiqiren (Robot) 2010, 32, 425–431. [Google Scholar] [CrossRef]
- Jin, L.; Yan, S.; Liu, Y. Vibration damper recognition based on Haar-Like features and cascade AdaBoost classifier. J. Syst. Simul. 2012, 24, 60–63. [Google Scholar]
- Liu, Y.; Jin, L. Vibration Damper Recognition of Transmission System Based on Unmanned Aerial Vehicles. In Proceedings of the 2011 Asia-Pacific Power and Energy Engineering Conference, Wuhan, China, 25–28 March 2011; pp. 1–3. [Google Scholar] [CrossRef]
- Guo, J.; Xie, J.; Yuan, J.; Jiang, Y.; Lu, S. Fault Identification of Transmission Line Shockproof Hammer Based on Improved YOLO V4. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Applications (ICAA), Nanjing, China, 25–27 June 2021; pp. 826–833. [Google Scholar] [CrossRef]
- Zhang, K.; Hou, Q.; Huang, W. Defect Detection of Anti-vibration Hammer Based on Improved Faster R-CNN. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 889–893. [Google Scholar] [CrossRef]
- Bao, W.; Ren, Y.; Liang, D.; Yang, X.; Xu, Q. Defect Detection Algorithm of Anti-vibration Hammer Based on Improved Cascade R-CNN. In Proceedings of the 2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 294–297. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhen, Z.; Zhang, L.; Qi, Y.; Kong, Y.; Zhang, K. Insulator Detection Method in Inspection Image Based on Improved Faster R-CNN. Energies 2019, 12, 1204. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z. Improved YOLOv3 Network for Insulator Detection in Aerial Images with Diverse Background Interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-Time Detection of Outdoor High Voltage Insulators Using UAV Imaging. IEEE Trans. Power Deliv. 2020, 35, 1599–1601. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Li, C. A Visual Detection Method for Foreign Objects in Power Lines Based on Mask R-CNN. International J. Ambient. Comput. Intell. (IJACI) 2020, 11, 34–47. [Google Scholar] [CrossRef]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder With Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Cheng, L.; Liao, R.; Yang, L.; Zhang, F. An Optimized Infrared Detection Strategy for Defective Composite Insulators According to the Law of Heat Flux Propagation Considering the Environmental Factors. IEEE Access 2018, 6, 38137–38146. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. ICLR. arXiv 2014, arXiv:1312.6114. Available online: https://arxiv.org/abs/1312.6114v10 (accessed on 5 February 2022).
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.; Wierstra, D. DRAW: A Recurrent Neural Network for Image Generation. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 1462–1471. Available online: http://proceedings.mlr.press/v37/gregor15.html (accessed on 30 August 2021).
- Yan, X.; Yang, J.; Sohn, K.; Lee, H. Attribute2Image: Conditional Image Generation from Visual Attributes. In Computer Vision–ECCV 2016. Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Amsterdam, The Netherlands, 2016; Volume 9908. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.L.; Du, Y.M.; Liu, Y.W.; Li, J.X.; Ma, Y.W. Image recognition with conditional deep convolutional generative adversarial networks. Zidonghua Xuebao/Acta Autom. Sin. 2018, 44, 855–864. [Google Scholar] [CrossRef]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:1606.00704. Available online: https://arxiv.org/abs/1606.00704v3 (accessed on 5 February 2022).
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 2180–2188. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1947–1962. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Gupta, A.; Li, F.-F. Image Generation from Scene Graphs. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1219–1228. [Google Scholar] [CrossRef] [Green Version]
- Chiaroni, F.; Rahal, M.; Hueber, N.; Dufaux, F. Hallucinating A Cleanly Labeled Augmented Dataset from A Noisy Labeled Dataset Using GAN. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3616–3620. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Springenberg, J.T.; Tatarchenko, M.; Brox, T. Learning to Generate Chairs, Tables and Cars with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 692–705. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2021, 29, 2367–2381. [Google Scholar] [CrossRef]
- Ronneberger, O. Invited Talk: U-Net Convolutional Networks for Biomedical Image Segmentation. In Bildverarbeitung für die Medizin 2017, Informatik aktuell; Maier-Hein, G., Fritzschej, K., Deserno, G., Lehmann, T., Handels, H., Tolxdorff, T., Eds.; Springer Vieweg: Berlin/Heidelberg, Germany, 2017; Volume 12. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. Available online: https://arxiv.org/abs/1607.08022v3 (accessed on 5 February 2022).
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar] [CrossRef]
- Chen, Q.; Koltun, V. Photographic image synthesis with cascaded refinement networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1520–1529. [Google Scholar] [CrossRef] [Green Version]
- Regmi, K.; Borji, A. Cross-view image synthesis using conditional gans. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3501–3510. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Xu, D.; Sebe, N.; Wang, Y.; Corso, J.J.; Yan, Y. Multi-channel attention selection gan with cascaded semantic guidance for cross-view image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2412–2421. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, L.; Li, L.; Li, K.; Li, F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep Multi-Scale Video Prediction Beyond Mean Square Error. arXiv 2016, arXiv:1511.05440. Available online: https://arxiv.org/abs/1511.05440v6 (accessed on 5 February 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Layer Information | Input | Output |
|---|---|---|---|
| Down-Sample | CONV-(N64, K7 × 7, S1, P3), IN, ReLU | (512, 512, 3) | (512, 512, 64) |
| CONV-(N128, K3 × 3, S2, P1), IN, ReLU | (512, 512, 64) | (256, 256, 128) | |
| CONV-(N256, K3 × 3, S2, P1), IN, ReLU | (256, 256, 128) | (128, 128, 256) | |
| CONV-(N512, K3 × 3, S2, P1), IN, ReLU | (128, 128, 256) | (64, 64, 512) | |
| CONV-(N1024, K3 × 3, S2, P1), IN, ReLU | (64, 64, 512) | (32, 32, 1024) | |
| Residual Block | CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| CONV-(N1024, K3 × 3, S1, P1), IN, ReLU | (32, 32, 1024) | (32, 32, 1024) | |
| Up-Sample | CONV-(N512, K3 × 3, S0.5, P1), IN, ReLU | (32, 32, 1024) | (64, 64, 512) |
| CONV-(N256, K3 × 3, S0.5, P1), IN, ReLU | (64, 64, 512) | (128, 128, 256) | |
| CONV-(N128, K3 × 3, S0.5, P1), IN, ReLU | (128, 128, 256) | (256, 256, 128) | |
| CONV-(N64, K3 × 3, S0.5, P1), IN, ReLU | (256, 256, 128) | (512, 512, 64) | |
| CONV-(N3, K7 × 7, S1, P3), IN, ReLU | (512, 512, 64) | (512, 512, 3) |
| Network | Layer Information | Input | Output |
|---|---|---|---|
| Input Layer | CONV-(N64, K4 × 4, S2, P2), Leaky ReLU | (512, 512, 3) | (256, 256, 64) |
| CONV-(N128, K4 × 4, S2, P2), IN, ReLU | (256, 256, 64) | (128, 128, 128) | |
| CONV-(N256, K4 × 4, S2, P2), IN, ReLU | (128, 128, 128) | (64, 64, 256) | |
| CONV-(N512, K4 × 4, S2, P2), IN, ReLU | (64, 64, 256) | (32, 32, 512) |
| Model | InsuGenSet | |
|---|---|---|
| IS | FID | |
| Pix2Pix | 3.25 | 57.45 |
| CRN | 3.04 | 57.68 |
| X-Fork | 3.37 | 56.90 |
| X-Seq | 3.61 | 56.42 |
| SelectionGAN | 3.75 | 56.08 |
| DamperGAN | 3.83 | 55.31 |
| Model | InsuGenSet | FPS | ||
|---|---|---|---|---|
| SSIM | PSNR | SD | ||
| Pix2Pix | 0.29 | 15.91 | 17.41 | 160 |
| CRN | 0.27 | 15.53 | 17.12 | 187 |
| X-Fork | 0.38 | 16.37 | 18.21 | 85 |
| X-Seq | 0.45 | 17.34 | 18.58 | 72 |
| SelectionGAN | 0.63 | 26.83 | 20.61 | 66 |
| DamperGAN | 0.70 | 28.14 | 22.13 | 63 |
| IS | FID | FPS | |
|---|---|---|---|
| Single generator | 3.28 | 56.84 | 82 |
| Two-stage generator | 3.83 | 55.31 | 63 |
| Three-stage generator | 4.25 | 54.96 | 37 |
| MCS | SSIM | PSNR | SD | FPS |
|---|---|---|---|---|
| Not introduced | 0.57 | 26.28 | 19.30 | 75 |
| N = 1 | 0.63 | 26.84 | 20.46 | 70 |
| N = 3 | 0.68 | 27.60 | 21.37 | 67 |
| N = 5 | 0.70 | 28.14 | 22.13 | 63 |
| N = 7 | 0.72 | 28.47 | 22.54 | 58 |
| N = 9 | 0.73 | 28.62 | 23.02 | 51 |
| SSIM | PSNR | SD | FPS | |
|---|---|---|---|---|
| Single discriminator | 0.60 | 26.48 | 19.84 | 71 |
| Two-level discriminator | 0.65 | 27.26 | 20.62 | 67 |
| Three-level discriminator | 0.70 | 28.14 | 22.13 | 63 |
| Four-level discriminator | 0.72 | 28.53 | 22.79 | 58 |
| Number of Epochs | SSIM | PSNR | SD | FPS |
|---|---|---|---|---|
| 50 | 0.32 | 16.72 | 17.84 | 65 |
| 100 | 0.58 | 18.56 | 19.05 | 64 |
| 150 | 0.64 | 24.47 | 21.31 | 63 |
| 200 | 0.70 | 28.14 | 22.13 | 63 |
| 250 | 0.68 | 27.92 | 21.86 | 61 |
| The Amount of Training Set | SSIM | PSNR | SD |
|---|---|---|---|
| 2500 (100%) | 0.70 | 28.14 | 22.13 |
| 2250 (90%) | 0.68 | 27.82 | 21.94 |
| 2000 (80%) | 0.65 | 25.86 | 20.25 |
| 1750 (70%) | 0.62 | 25.15 | 19.93 |
| 1500 (60%) | 0.56 | 23.83 | 17.42 |
| Model | Param. | Training Time (h) |
|---|---|---|
| Pix2Pix | 47 M | 14.92 |
| CRN | 36 M | 10.88 |
| X-Fork | 62 M | 16.30 |
| X-Seq | 70 M | 18.57 |
| SelectionGAN | 78 M | 20.06 |
| DamperGAN | 82 M | 22.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Li, Y.; Zhao, Z. Transmission Line Vibration Damper Detection Using Multi-Granularity Conditional Generative Adversarial Nets Based on UAV Inspection Images. Sensors 2022, 22, 1886. https://doi.org/10.3390/s22051886
Chen W, Li Y, Zhao Z. Transmission Line Vibration Damper Detection Using Multi-Granularity Conditional Generative Adversarial Nets Based on UAV Inspection Images. Sensors. 2022; 22(5):1886. https://doi.org/10.3390/s22051886
Chicago/Turabian StyleChen, Wenxiang, Yingna Li, and Zhengang Zhao. 2022. "Transmission Line Vibration Damper Detection Using Multi-Granularity Conditional Generative Adversarial Nets Based on UAV Inspection Images" Sensors 22, no. 5: 1886. https://doi.org/10.3390/s22051886
APA StyleChen, W., Li, Y., & Zhao, Z. (2022). Transmission Line Vibration Damper Detection Using Multi-Granularity Conditional Generative Adversarial Nets Based on UAV Inspection Images. Sensors, 22(5), 1886. https://doi.org/10.3390/s22051886