
Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- We introduce an improved version of the Pix2Pix-based conditional adversarial generative (cGAN) model, which can serve to generate a vast amount of iris images with pre-defined iris masks and periocular masks. The size of the generated iris database is unlimited and can be as big as we want.
- Our approach can produce high-quality and diversified iris images, not only increasing the amount of the data.
- The creation of the pre-defined iris masks and periocular masks in our framework is fully parameterized. Therefore, they can be automatically generated. It means the generation process of iris images, iris masks, and periocular masks can be fully automated in the proposed framework, and no human intervention is required. In this proposed framework, since only a small number of images that require annotation are needed, it can be seen as a self-supervised learning framework.
- The proposed framework can be easily extended to image segmentation network training for any specific target object, as long as the shape of the target object can be parameterized. Therefore, the proposed framework has high generalization ability.
2. Related Works
2.1. Boundary-Based Segmentation Technique
2.2. Pixel-Based Segmentation Technique
2.3. Semantic Segmentation Technique
2.4. Generative Adversarial Network (GAN)
3. Proposed Method
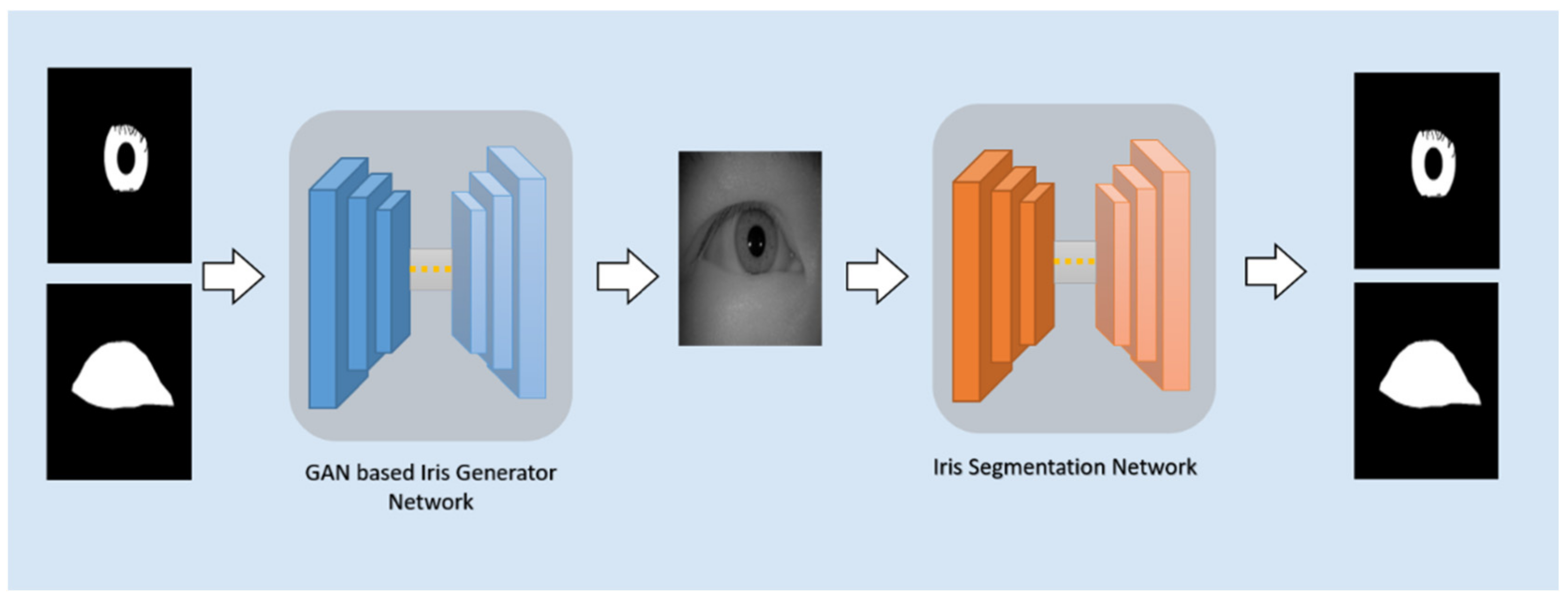
3.1. Framework Overview
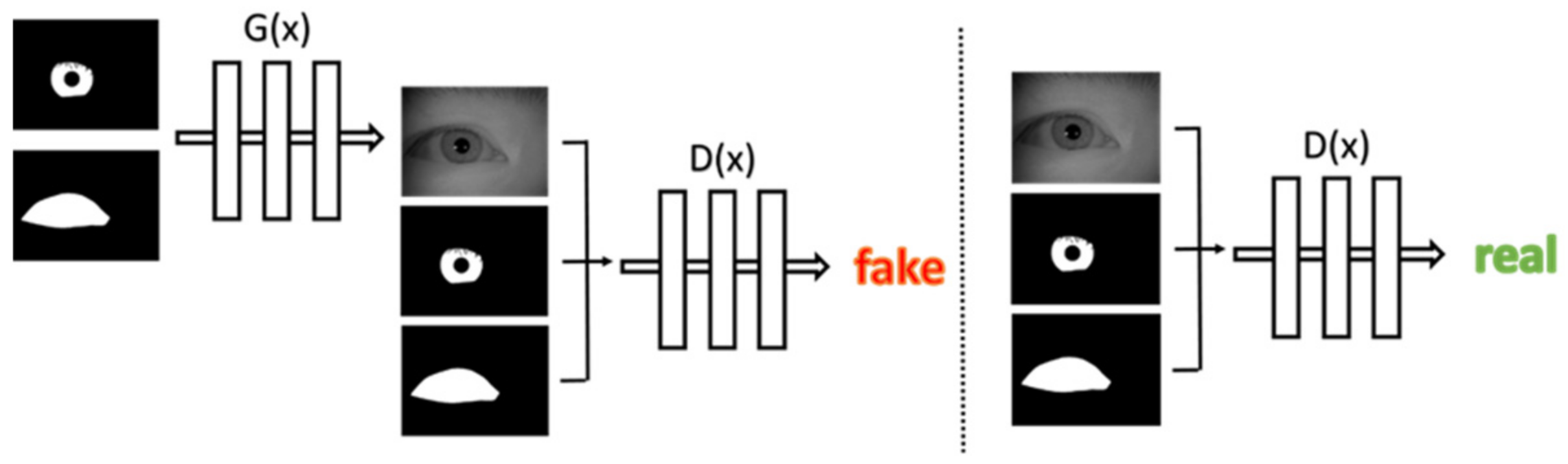
3.2. Iris Image Generation Network
3.3. Objective Function
3.4. Iris Segmentation Network
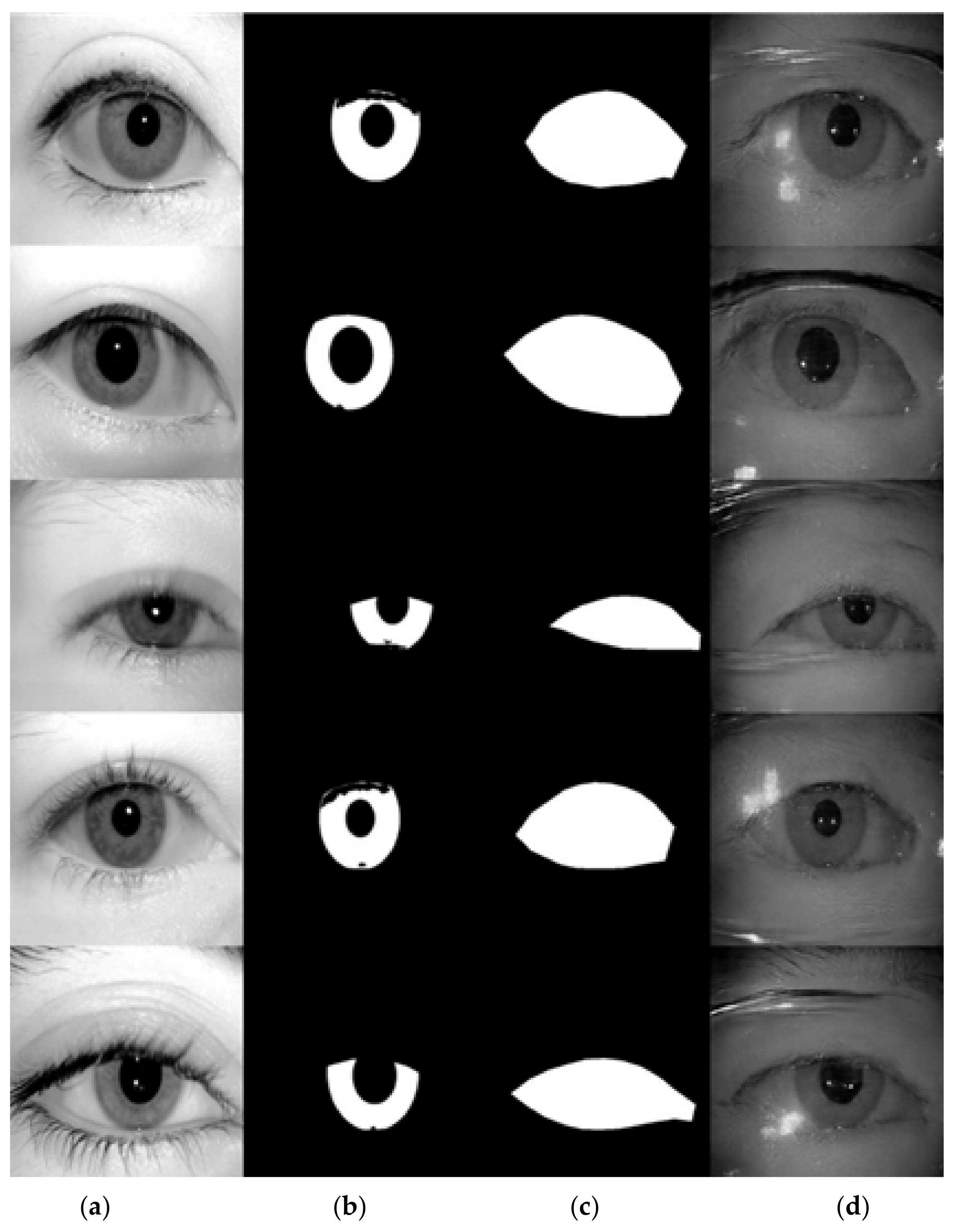
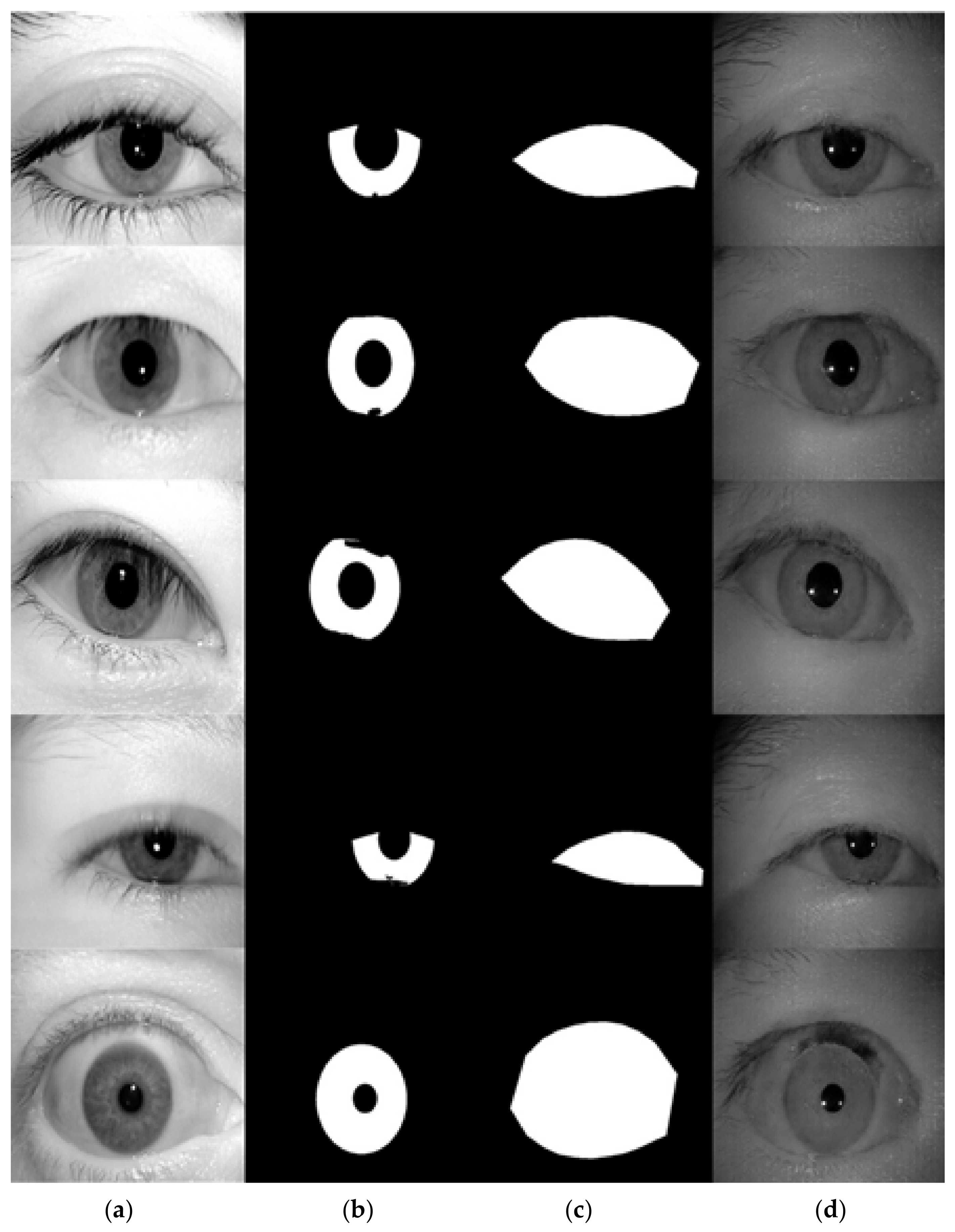
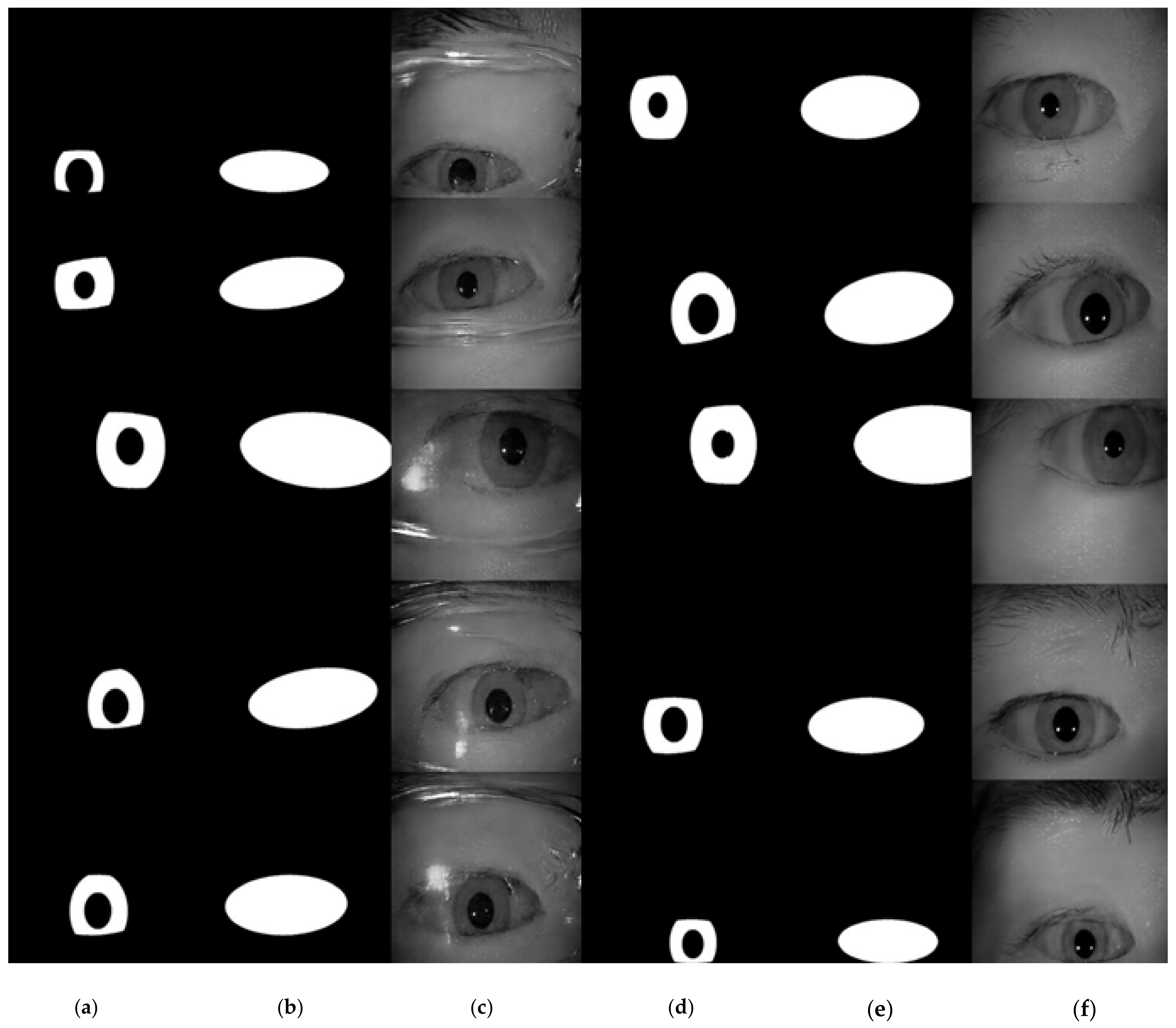
3.5. Automatic Mask Generator
- PupilX: the X-axis coordinate of the pupil center in the iris image
- PupilY: the Y-axis coordinate of the pupil center in the iris image.
- PupilR: the radius of the pupil in the iris image.
- IrisX: the X-axis coordinate of the iris center in the iris image.
- IrisY: the Y-axis coordinate of the iris center in the iris image.
- IrisR: the radius of the iris in the iris image.
- (xOffset, yOffset): a set of vectors representing the displacement of the centers of the eye and the iris.
- xRatio: we use the shape of the ellipse to approximate the shape of eyes. An ellipse can be described by its center position, semi-major and semi-minor axis. The center position is parametrized by (xOffset, yOffset). xRatio is the value computed from the semi-major axis length divided by the iris radius.
- yRatio: the value computed from the semi-minor axis length divided by the iris radius.
- Degree: the angle of rotation of the ellipse.
4. Experimental Results and Discussion
4.1. Experimental Details
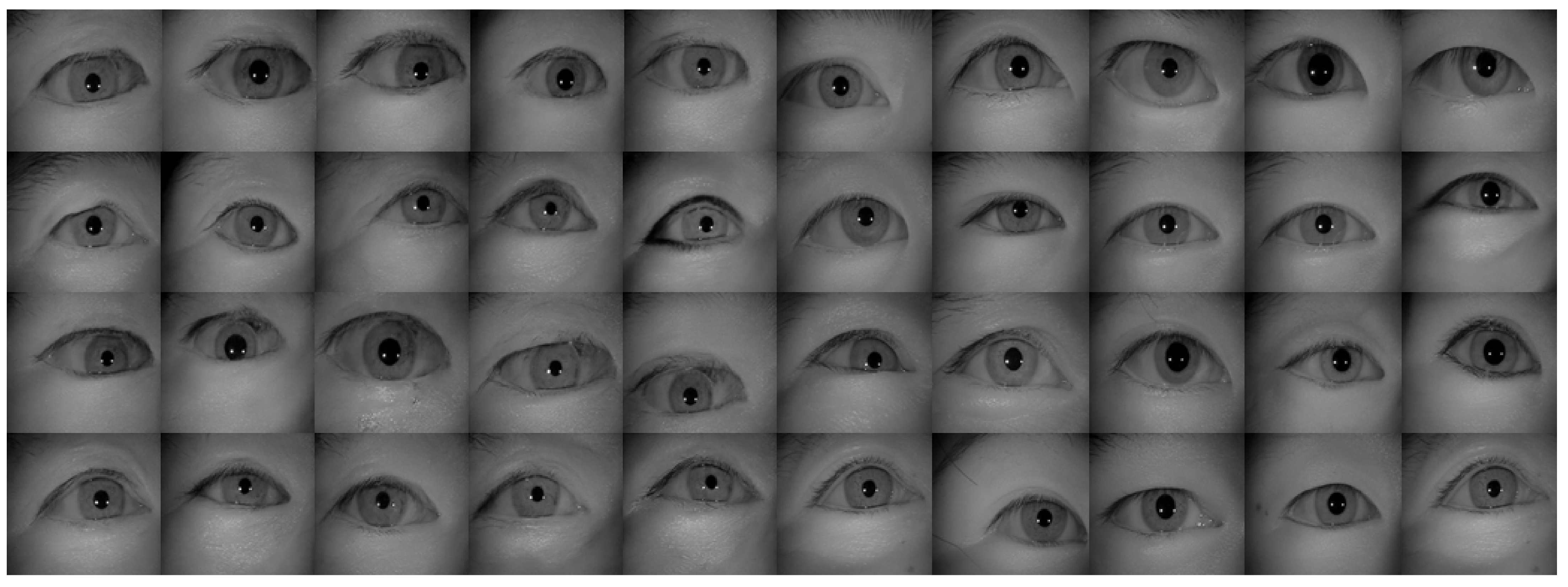
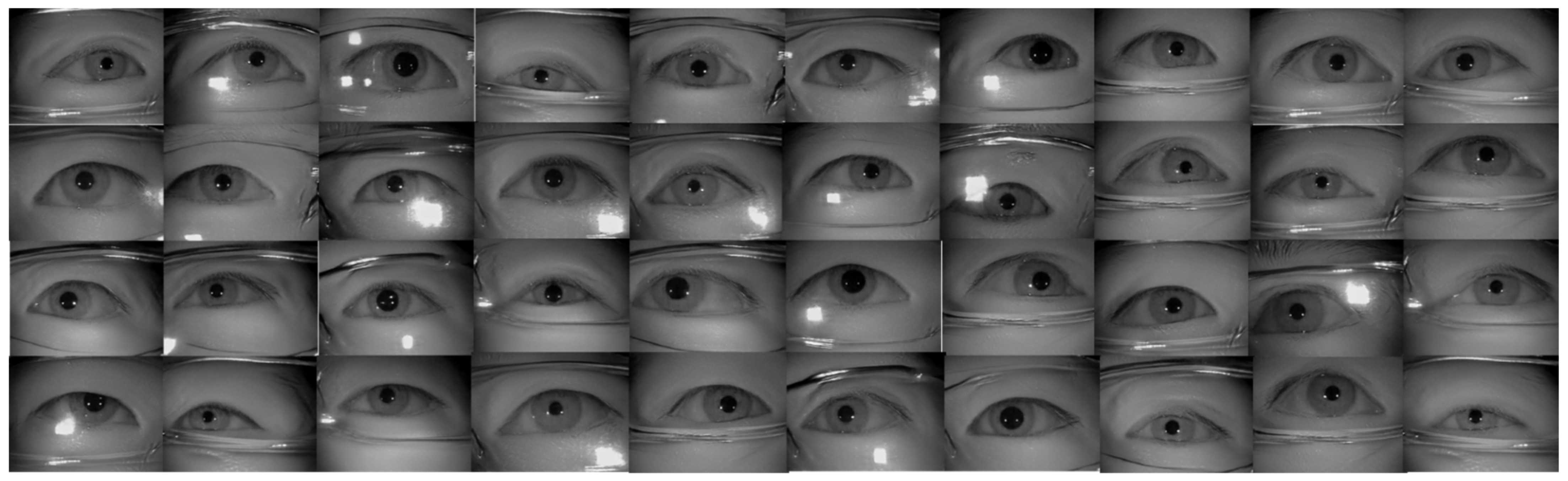
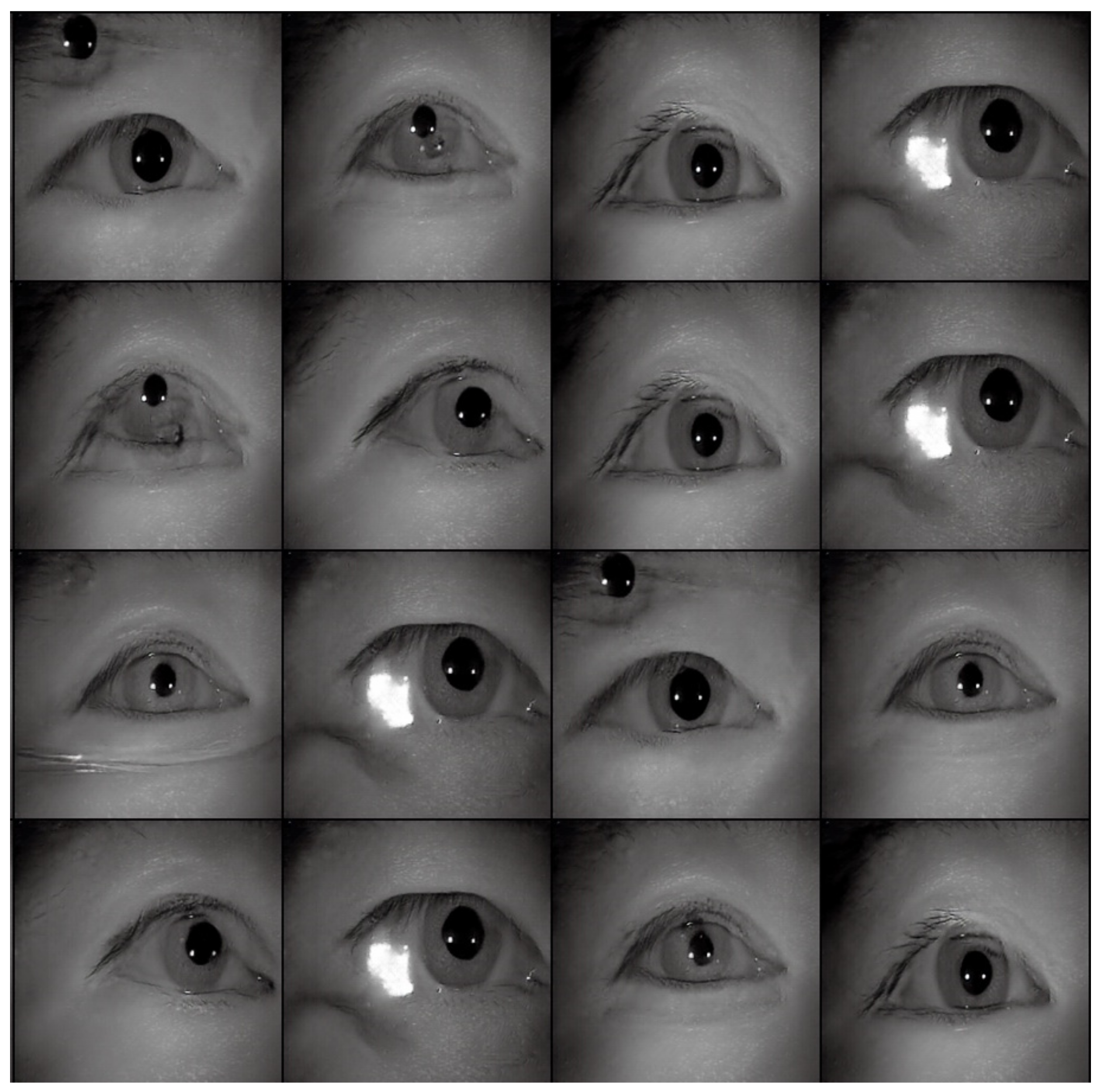
4.2. Iris Databases and Data Augmentation
- Randomly flip horizontally with the probability of 0.5.
- Randomly crop the image with resolution 432 × 576.
- Resize the image to a resolution of 256 × 256.
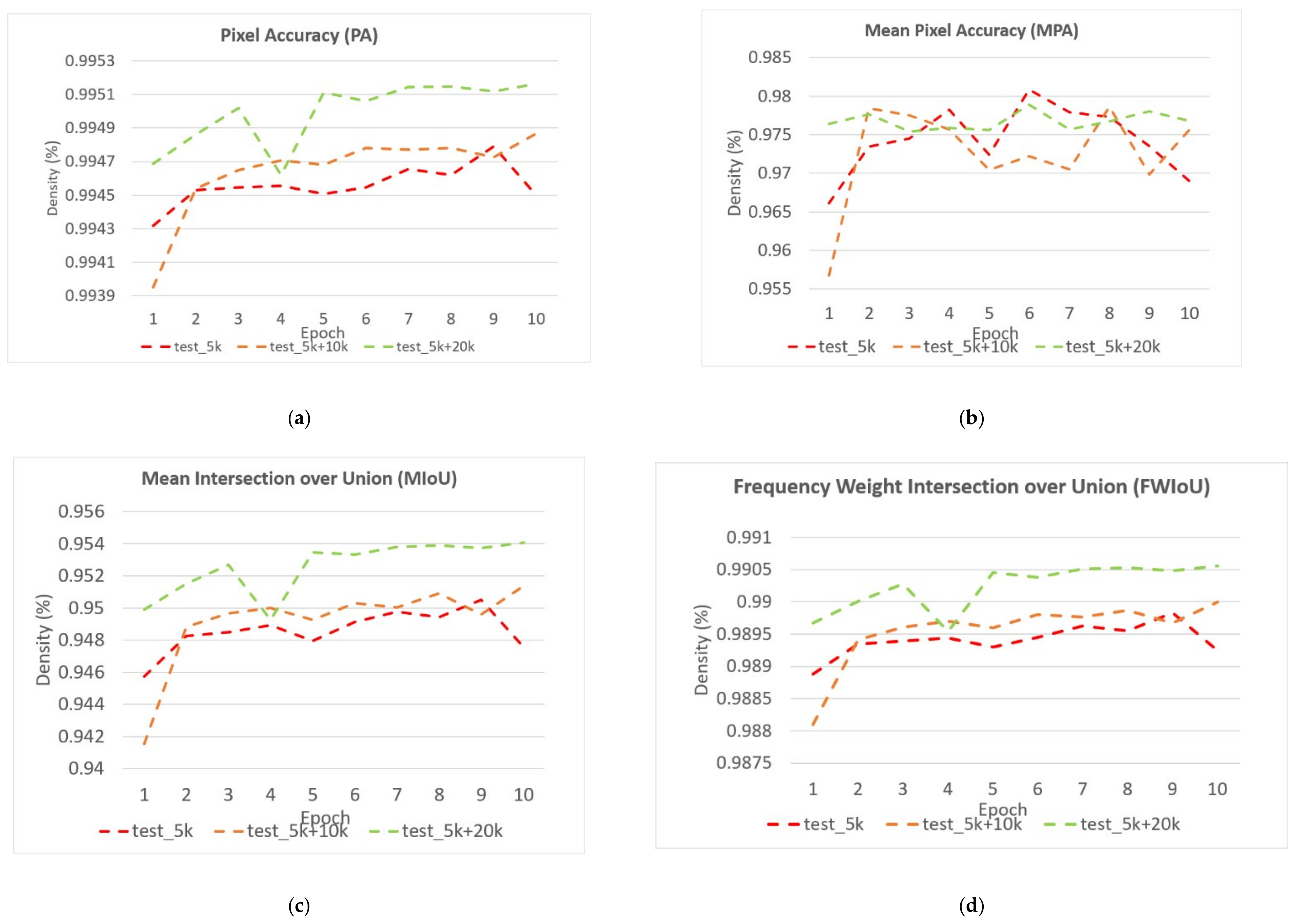
4.3. Performance Evaluation
- mIoU (mean Intersection over Union) is a commonly used metric in semantic segmentation, which is the average ratio of the intersection and union of the two sets of real and predicted values. The values of IoU are limited to the [0, 1] interval, with 1 representing the accurate results (100% accuracy), while 0 indicates 0% accuracy.
- PA (Pixel Accuracy) and mPA (mean Pixel Accuracy) are the percentage of correctly marked pixels to the total pixels and the average over all classes. The value of mPA is in the range of [0, 1]. The closer the value is to one, the higher the accuracy of segmentation is.
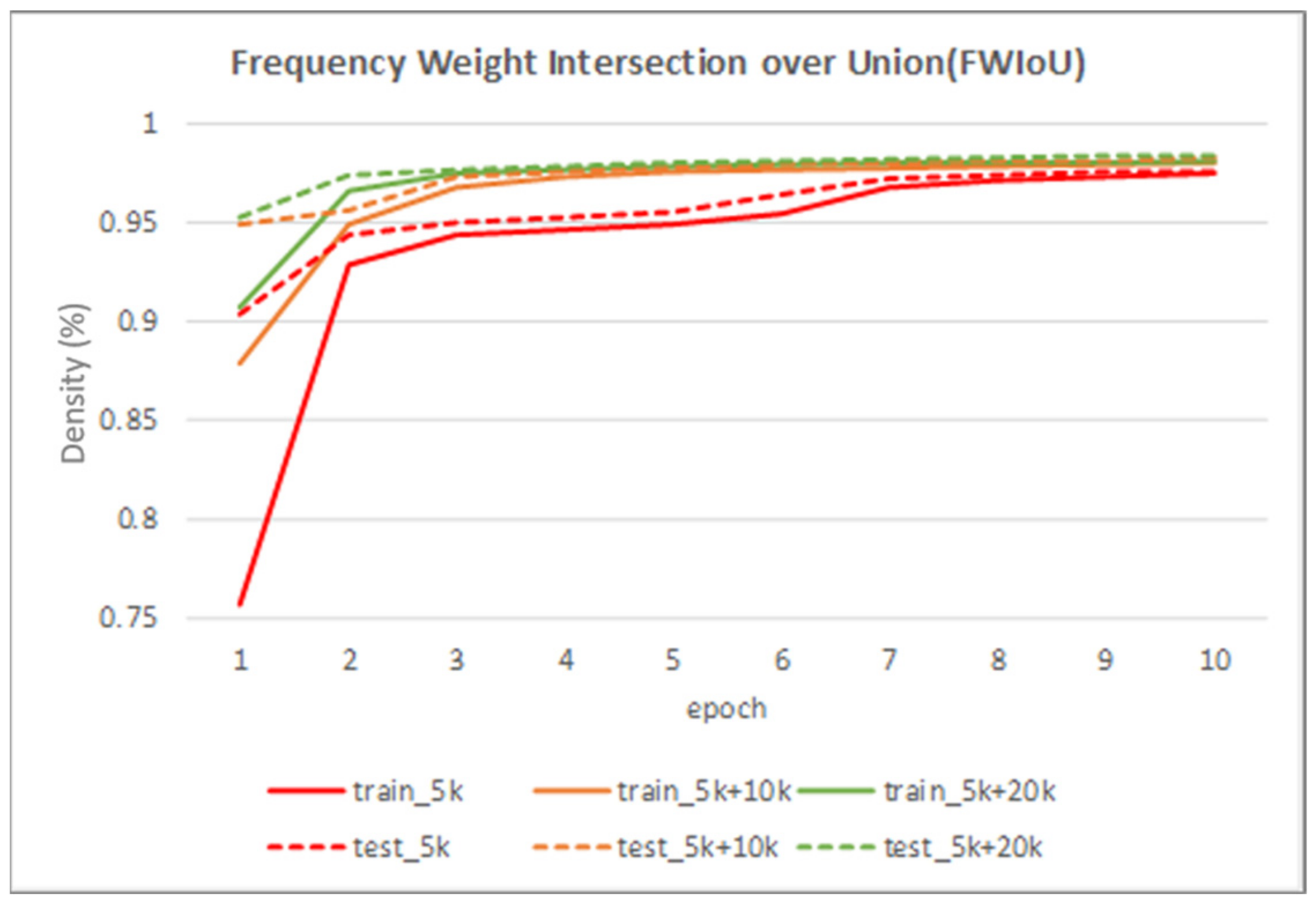
- Frequency Weighted Intersection over Union (FWIoU) is a metric to compensate the impact from the class imbalances issues, which is calculated using Equation (6). The represents the pixels that belong to the category but are predicted to be the category, represents the true positive value, and represents the false positive value.
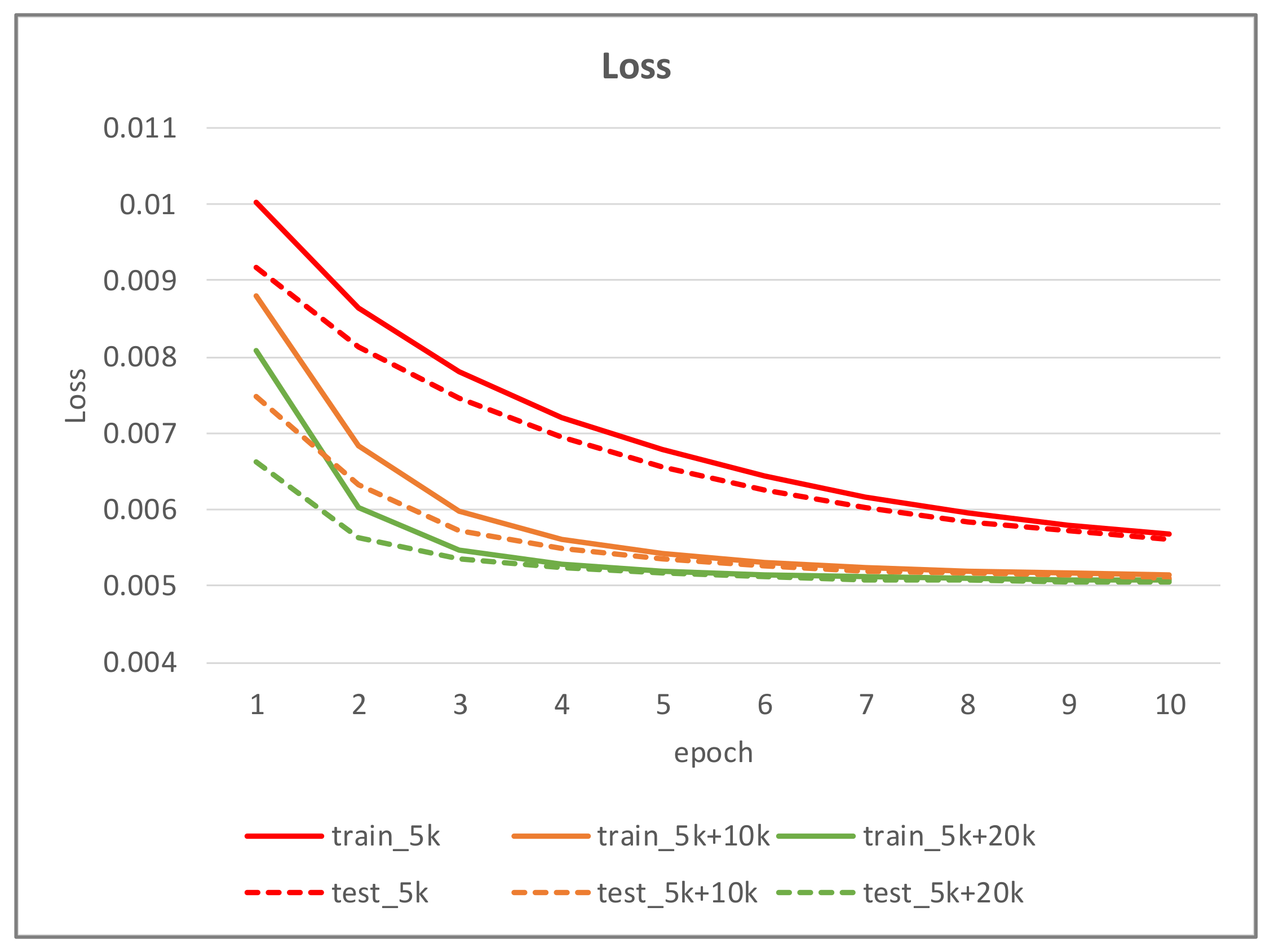
4.4. Experimental Results and Analysis
- The 5000 iris images randomly chosen from CASIA-Iris-Thousands.
- The 15,000 iris images consisted of training set 1 and 10,000 additional iris images produced from the proposed iris image generation network.
- The 25,000 iris images consisted of training set 2 and 10,000 additional iris images generated from the proposed iris image generation network.
4.5. Experimental Results and Analysis on ICE Database
4.6. Comparison with Existing Segmentation Algorithms
4.7. Analysis on Generated Image Quality
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.-H.; Putri, W.R.; Aslam, M.S.; Chang, C.-C.J.S. Robust Iris Segmentation Algorithm in Non-Cooperative Environments Using Interleaved Residual U-Net. Sensors 2021, 21, 1434. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zhu, Y.; Liu, Y.; He, R.; Sun, Z. Joint iris segmentation and localization using deep multi-task learning framework. arXiv 2019, arXiv:1901.11195. [Google Scholar]
- Li, Y.-H.; Savvides, M. Automatic iris mask refinement for high performance iris recognition. In Proceedings of the 2009 IEEE Workshop on Computational Intelligence in Biometrics: Theory, Algorithms, and Applications, Nashville, TN, USA, 30 March–2 April 2009; pp. 52–58. [Google Scholar]
- Li, Y.-H.; Savvides, M. Iris Recognition, Overview. In Biometrics Theory and Application; IEEE & Willey: New York, NY, USA, 2009. [Google Scholar]
- Zhao, Z.; Kumar, A. Towards more accurate iris recognition using deeply learned spatially corresponding features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3809–3818. [Google Scholar]
- Daugman, J. Iris recognition border-crossing system in the UAE. Int. Airpt. Rev. 2004, 8, 49–53. [Google Scholar]
- Al-Raisi, A.N.; Al-Khouri, A.M. Iris recognition and the challenge of homeland and border control security in UAE. Telemat. Inform. 2008, 25, 117–132. [Google Scholar] [CrossRef]
- Daugman, J. 600 million citizens of India are now enrolled with biometric ID. SPIE Newsroom 2014, 7. [Google Scholar] [CrossRef]
- Sansola, A.J.P.D. Postmortem Iris Recognition and Its Application in Human Identification. Master’s Theses, Boston University, Boston, MA, USA, 2015; p. 70. [Google Scholar]
- Gomez-Barrero, M.; Drozdowski, P.; Rathgeb, C.; Patino, J.; Todisco, M.; Nautsch, A.; Damer, N.; Priesnitz, J.; Evans, N.; Busch, C. Biometrics in the Era of COVID-19: Challenges and Opportunities. arXiv 2021, arXiv:2102.09258. [Google Scholar]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef] [Green Version]
- Daugman, J.G. Biometric Personal Identification System Based on Iris Analysis. U.S. Patent 5,291,560, 1 March 1994. [Google Scholar]
- Daugman, J. Statistical Richness of Visual Phase Information: Update on Recognizing Persons by Iris Patterns. Int. J. Comput. Vis. 2001, 45, 25–38. [Google Scholar] [CrossRef]
- Daugman, J. How iris recognition works. In The Essential Guide to Image Processing; Elsevier: Amsterdam, The Netherlands, 2009; pp. 715–739. [Google Scholar]
- Li, Y.-H.; Savvides, M. An automatic iris occlusion estimation method based on high-dimensional density estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 784–796. [Google Scholar] [CrossRef]
- Liu, N.; Li, H.; Zhang, M.; Jing, L.; Sun, Z.; Tan, T. Accurate iris segmentation in non-cooperative environments using fully convolutional networks. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Jalilian, E.; Uhl, A.; Kwitt, R. Domain adaptation for cnn based iris segmentation. In Proceedings of the 2017 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 9–11 September 2015; pp. 1–6. [Google Scholar]
- Bazrafkan, S.; Thavalengal, S.; Corcoran, P. An end to end Deep Neural Network for iris segmentation in unconstrained scenarios. Neural Netw. 2018, 106, 79–95. [Google Scholar] [CrossRef] [Green Version]
- Severo, E.; Laroca, R.; Bezerra, C.S.; Zanlorensi, L.A.; Weingaertner, D.; Moreira, G.; Menotti, D. A benchmark for iris location and a deep learning detector evaluation. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chinsatit, W.; Saitoh, T. CNN-based pupil center detection for wearable gaze estimation system. Appl. Comput. Intell. Soft Comput. 2017, 2017, 8718956. [Google Scholar] [CrossRef] [Green Version]
- Vera-Olmos, F.J.; Malpica, N. Deconvolutional neural network for pupil detection in real-world environments. In Proceedings of the International Work-Conference on the Interplay between Natural and Artificial Computation, Corunna, Spain, 19–23 June 2017; pp. 223–231. [Google Scholar]
- Park, S.; Zhang, X.; Bulling, A.; Hilliges, O. Learning to find eye region landmarks for remote gaze estimation in unconstrained settings. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–10. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colombus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Institute of Automation, Chinese Academy of Science: CASIA-Iris-Thousand Iris Image Database. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp (accessed on 1 October 2021).
- Nava, M.; Guzzi, J.; Chavez-Garcia, R.O.; Gambardella, L.M.; Giusti, A. Learning long-range perception using self-supervision from short-range sensors and odometry. IEEE Robot. Autom. Lett. 2019, 4, 1279–1286. [Google Scholar] [CrossRef] [Green Version]
- Sayed, N.; Brattoli, B.; Ommer, B. Cross and learn: Cross-modal self-supervision. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, Germany, 9–12 October 2018; pp. 228–243. [Google Scholar]
- Jang, E.; Devin, C.; Vanhoucke, V.; Levine, S. Grasp2vec: Learning object representations from self-supervised grasping. arXiv 2018, arXiv:1811.06964. [Google Scholar]
- Owens, A.; Efros, A.A. Audio-visual scene analysis with self-supervised multisensory features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 631–648. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12154–12163. [Google Scholar]
- Huang, R.; Xu, W.; Lee, T.-Y.; Cherian, A.; Wang, Y.; Marks, T. Fx-gan: Self-supervised gan learning via feature exchange. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3194–3202. [Google Scholar]
- Li, Y.-H.; Aslam, M.S.; Harfiya, L.N.; Chang, C.-C. Conditional Wasserstein Generative Adversarial Networks for Rebalancing Iris Image Datasets. IEICE Trans. Inf. Syst. 2021, 104, 1450–1458. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, C.; Muhammad, J.; Wang, Y.; He, Z.; Sun, Z. Towards complete and accurate iris segmentation using deep multi-task attention network for non-cooperative iris recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Ajay, K. An accurate iris segmentation framework under relaxed imaging constraints using total variation model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3828–3836. [Google Scholar]
- Proença, H.; Alexandre, L.A. Iris segmentation methodology for non-cooperative recognition. IEE Proc.-Vis. Image Signal Process. 2006, 153, 199–205. [Google Scholar] [CrossRef] [Green Version]
- Haindl, M.; Krupička, M. Unsupervised detection of non-iris occlusions. Pattern Recognit. Lett. 2015, 57, 60–65. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A.; Singh, A.; Alonso-Fernandez, F.; Bigun, J. IrisSeg: A fast and robust iris segmentation framework for non-ideal iris images. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Hu, Y.; Sirlantzis, K.; Howells, G. Improving colour iris segmentation using a model selection technique. Pattern Recognit. Lett. 2015, 57, 24–32. [Google Scholar] [CrossRef]
- Banerjee, S.; Mery, D. Iris segmentation using geodesic active contours and grabcut. In Proceedings of the Image and Video Technology, Auckland, New Zealand, 23–27 November 2015; pp. 48–60. [Google Scholar]
- Radman, A.; Zainal, N.; Suandi, S.A. Automated segmentation of iris images acquired in an unconstrained environment using HOG-SVM and GrowCut. Digit. Signal Process. 2017, 64, 60–70. [Google Scholar] [CrossRef]
- Rongnian, T.; Shaojie, W. Improving iris segmentation performance via borders recognition. In Proceedings of the 2011 Fourth International Conference on Intelligent Computation Technology and Automation, Shenzhen, China, 28–29 March 2011; pp. 580–583. [Google Scholar]
- Li, Y.-H.; Huang, P.-J.; Juan, Y. An efficient and robust iris segmentation algorithm using deep learning. Mob. Inf. Syst. 2019, 2019, 4568929. [Google Scholar] [CrossRef]
- Hofbauer, H.; Jalilian, E.; Uhl, A.J.P.R.L. Exploiting superior CNN-based iris segmentation for better recognition accuracy. Pattern Recognit. Lett. 2019, 120, 17–23. [Google Scholar] [CrossRef]
- Kerrigan, D.; Trokielewicz, M.; Czajka, A.; Bowyer, K.W. Iris recognition with image segmentation employing retrained off-the-shelf deep neural networks. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–7. [Google Scholar]
- Jalilian, E.; Uhl, A. Iris segmentation using fully convolutional encoder–decoder networks. In Deep Learning for Biometrics; Springer: Berlin/Heidelberg, Germany, 2017; pp. 133–155. [Google Scholar]
- Lian, S.; Luo, Z.; Zhong, Z.; Lin, X.; Su, S.; Li, S. Attention guided U-Net for accurate iris segmentation. J. Vis. Commun. Image Represent. 2018, 56, 296–304. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K.R. FRED-Net: Fully residual encoder–decoder network for accurate iris segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Lozej, J.; Meden, B.; Struc, V.; Peer, P. End-to-end iris segmentation using u-net. In Proceedings of the 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI), San Carlos, Costa Rica, 18–20 July 2018; pp. 1–6. [Google Scholar]
- Wu, X.; Zhao, L. Study on iris segmentation algorithm based on dense U-Net. IEEE Access 2019, 7, 123959–123968. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, X.; Gu, Y.; Liu, Y.; Meng, X.; Li, J. A robust iris segmentation scheme based on improved U-net. IEEE Access 2019, 7, 85082–85089. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Minaee, S.; Abdolrashidi, A. Iris-GAN: Learning to generate realistic iris images using convolutional GAN. arXiv 2018, arXiv:1812.04822. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Yadav, S.; Chen, C.; Ross, A. Synthesizing iris images using RaSGAN with application in presentation attack detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- CASIA-Iris Database. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp (accessed on 1 October 2021).
- Iris Challenge Evaluation (ICE). Available online: https://www.nist.gov/programs-projects/iris-challenge-evaluation-ice (accessed on 1 October 2021).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Processing Syst. 2017, 30. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Average Value | Standard Deviation | Minimum Value | Maximum Value |
|---|---|---|---|---|
| PupilX | 363.18 | 48.78 | 137.65 | 383.09 |
| PupilY | 222.68 | 41.93 | 75 | 383.09 |
| PupilR | 35.87 | 8.03 | 16.86 | 70.39 |
| IrisX | 360.28 | 48.85 | 135.35 | 546.27 |
| IrisY | 222.28 | 42.11 | 70.17 | 384.45 |
| IrisR | 94.57 | 7.41 | 71.31 | 124.97 |
| xOffset | −2.59 | 17.24 | −88.11 | 79.44 |
| yOffset | 8.03 | 9.5 | −29.11 | 51.13 |
| xRatio | 2.08 | 0.16 | 0.054 | 2.7 |
| yRatio | 0.76 | 0.1 | 0.04 | 1.14 |
| Degree | 2.24 | 4.07 | −16.2 | 19.38 |
| Number of Data | PA | mPA | mIoU | FwIoU |
|---|---|---|---|---|
| 5k (real data) | 98.7216% | 95.2517% | 88.9159% | 97.6204% |
| 5k (real data) + 10k (generated data) | 99.0971% | 95.9337% | 91.7642% | 98.2756% |
| 5k (real data) + 20k (generated data) | 99.1622% | 96.9423% | 92.4142% | 98.4049% |
| Model | Number of Data | PA | mPA | mIoU | FwIoU |
|---|---|---|---|---|---|
| U-Net [24] | 5k (real data) | 98.7216% | 95.2517% | 88.9159% | 97.6204% |
| 5k (real data) + 10k (gen. data) | 99.0971% | 95.9337% | 91.7642% | 98.2756% | |
| 5k (real data) + 20k (gen. data) | 99.1622% | 96.9423% | 92.4142% | 98.4049% | |
| FCN [25] | 5k (real data) | 99.4497% | 96.8995% | 94.7542% | 98.9245% |
| 5k (real data) + 10k (gen. data) | 99.4866% | 97.5631% | 95.1388% | 98.9994% | |
| 5k (real data) + 20k (gen. data) | 99.5164% | 97.6801% | 95.4050% | 99.0558% | |
| Deeplab [64] | 5k (real data) | 99.1217% | 96.8730% | 92.0923% | 98.3326% |
| 5k (real data) + 10k (gen. data) | 99.3034% | 97.3882% | 93.4433% | 98.6379% | |
| 5k (real data) + 20k (gen. data) | 99.4051% | 97.3951% | 94.4271% | 98.8472% |
| Network | FID |
|---|---|
| Proposed | 60.25 |
| Minaee and Abdolrashidi [70] | 112.70 |
| Yadav et al. [74] | 110.56 |
| Properties | Proposed | Minaee and Abdolrashidi [70] | Yadav et al. [74] |
|---|---|---|---|
| Is it suitable for Presentation Attack Detection task? | Yes | Yes | Yes |
| Is it suitable for iris segmentation task? | Yes | No | No |
| Can it generate iris images based on specified iris center and radius? | Yes | No | No |
| Can it generate iris images based on specified pupil center and radius? | Yes | No | No |
| Can it generate iris images at any specified coordinate on the whole image? | Yes | No | No |
| Can it generate iris images with or without glasses according to the prior specification? | Yes | No | No |
| Can it generate iris images based on different eyelid shape? | Yes | No | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Putri, W.R.; Liu, S.-H.; Aslam, M.S.; Li, Y.-H.; Chang, C.-C.; Wang, J.-C. Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation. Sensors 2022, 22, 2133. https://doi.org/10.3390/s22062133
Putri WR, Liu S-H, Aslam MS, Li Y-H, Chang C-C, Wang J-C. Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation. Sensors. 2022; 22(6):2133. https://doi.org/10.3390/s22062133
Chicago/Turabian StylePutri, Wenny Ramadha, Shen-Hsuan Liu, Muhammad Saqlain Aslam, Yung-Hui Li, Chin-Chen Chang, and Jia-Ching Wang. 2022. "Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation" Sensors 22, no. 6: 2133. https://doi.org/10.3390/s22062133
APA StylePutri, W. R., Liu, S. -H., Aslam, M. S., Li, Y. -H., Chang, C. -C., & Wang, J. -C. (2022). Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation. Sensors, 22(6), 2133. https://doi.org/10.3390/s22062133