
Low Memory Access Video Stabilization for Low-Cost Camera SoC

Abstract
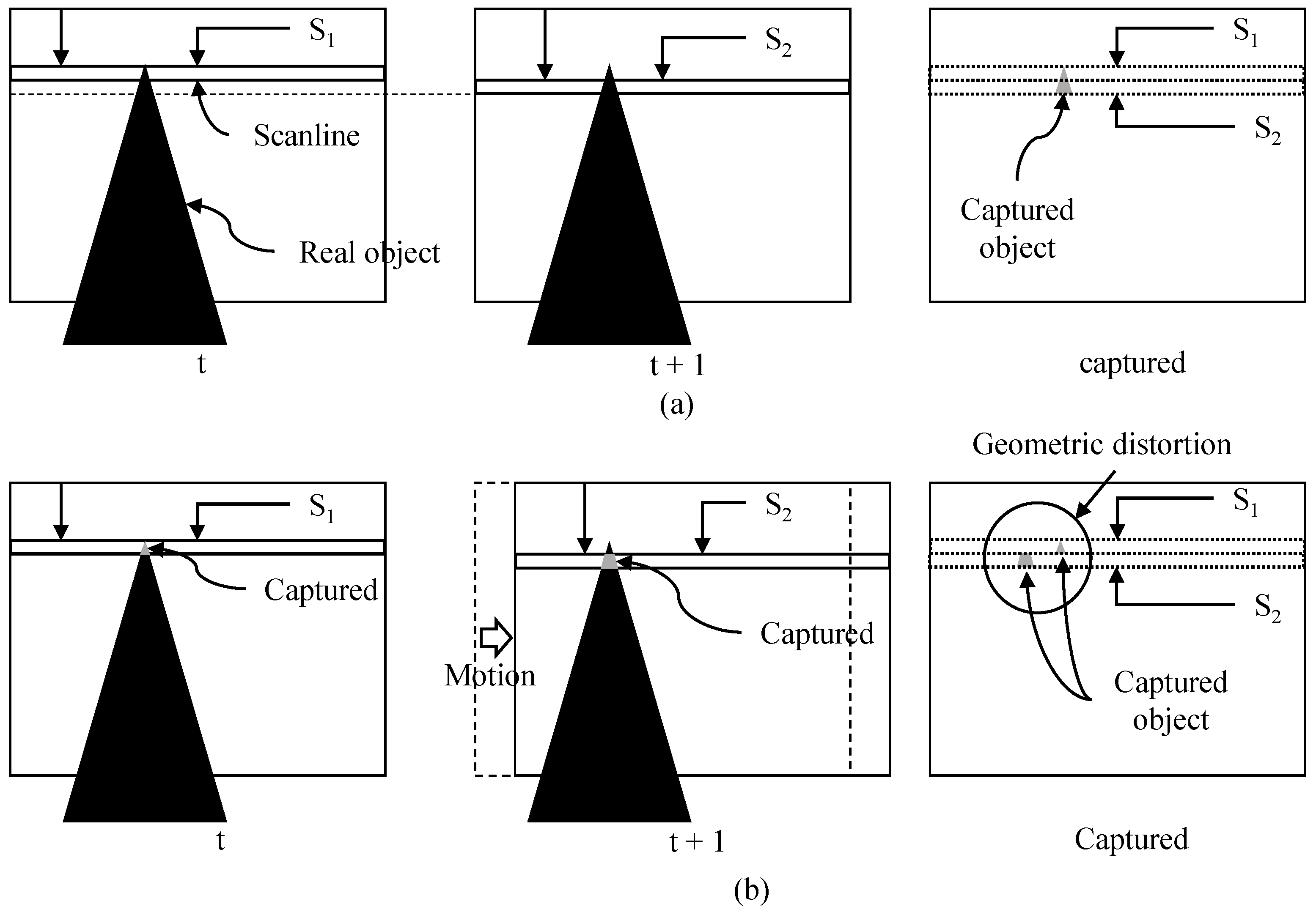
:1. Introduction
2. Review
2.1. Motion Estimation
2.2. Parameter Estimation
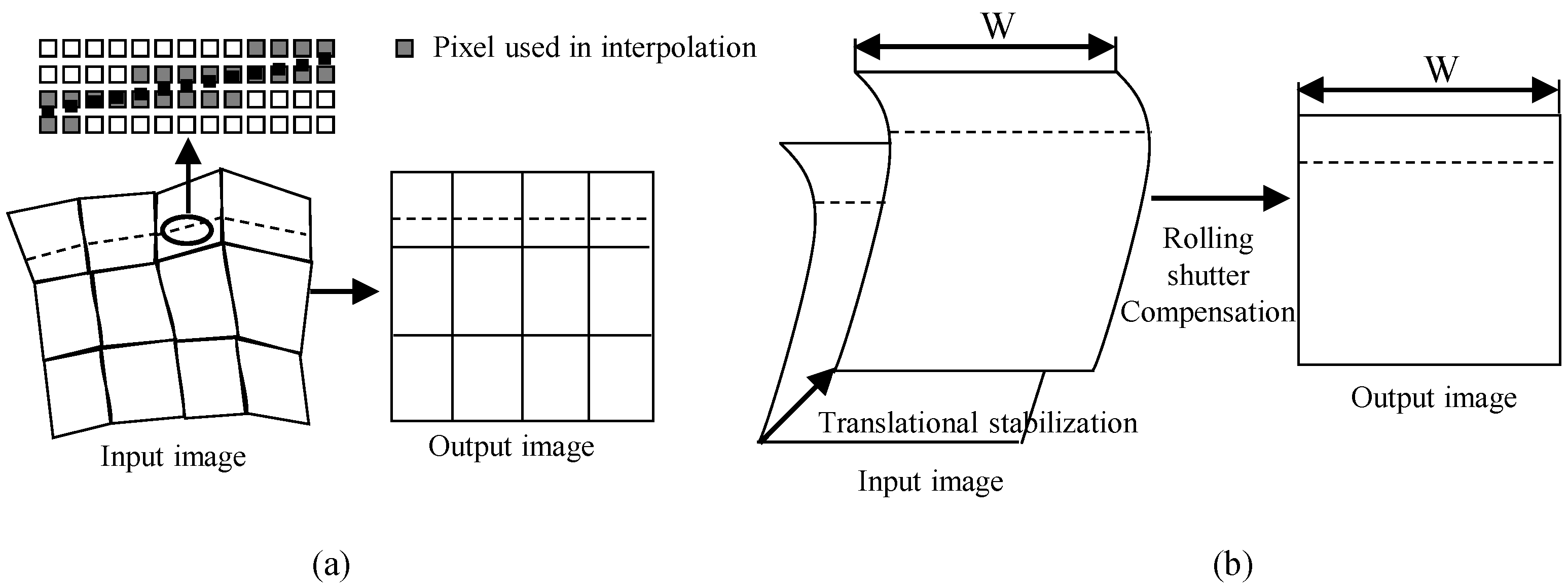
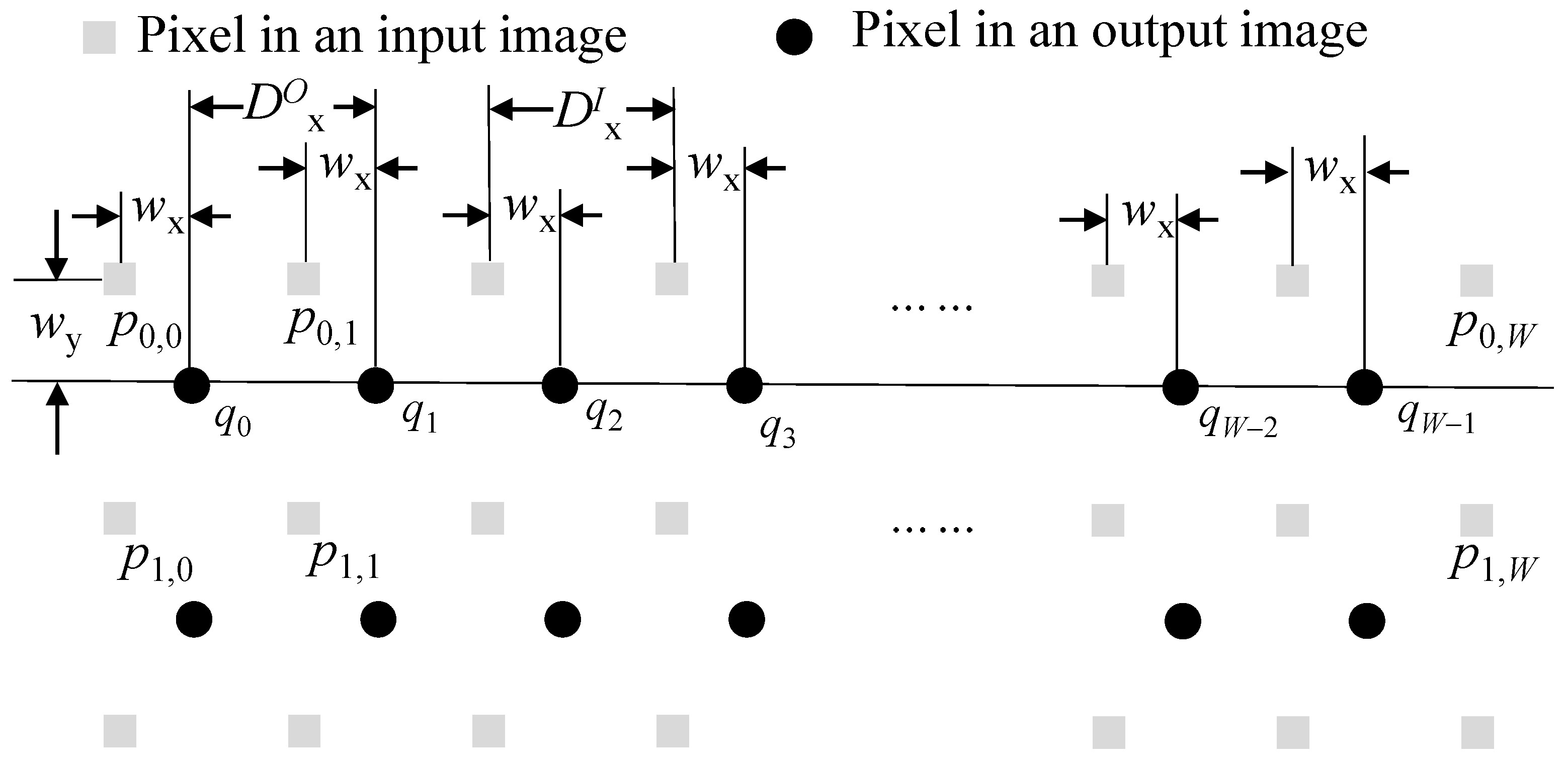
2.3. Image Warping
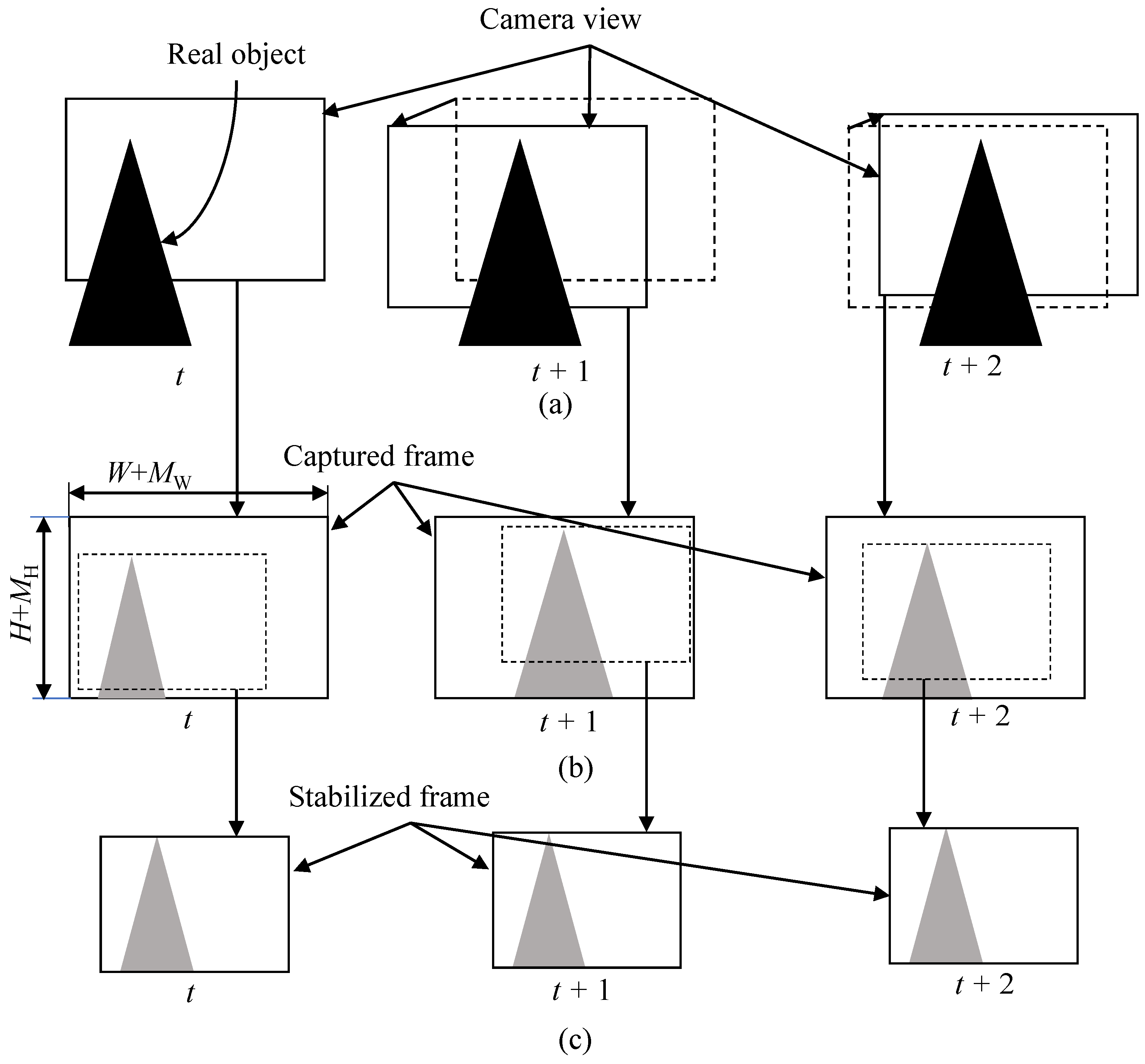
3. Proposed Method for Reducing Memory Access Amount
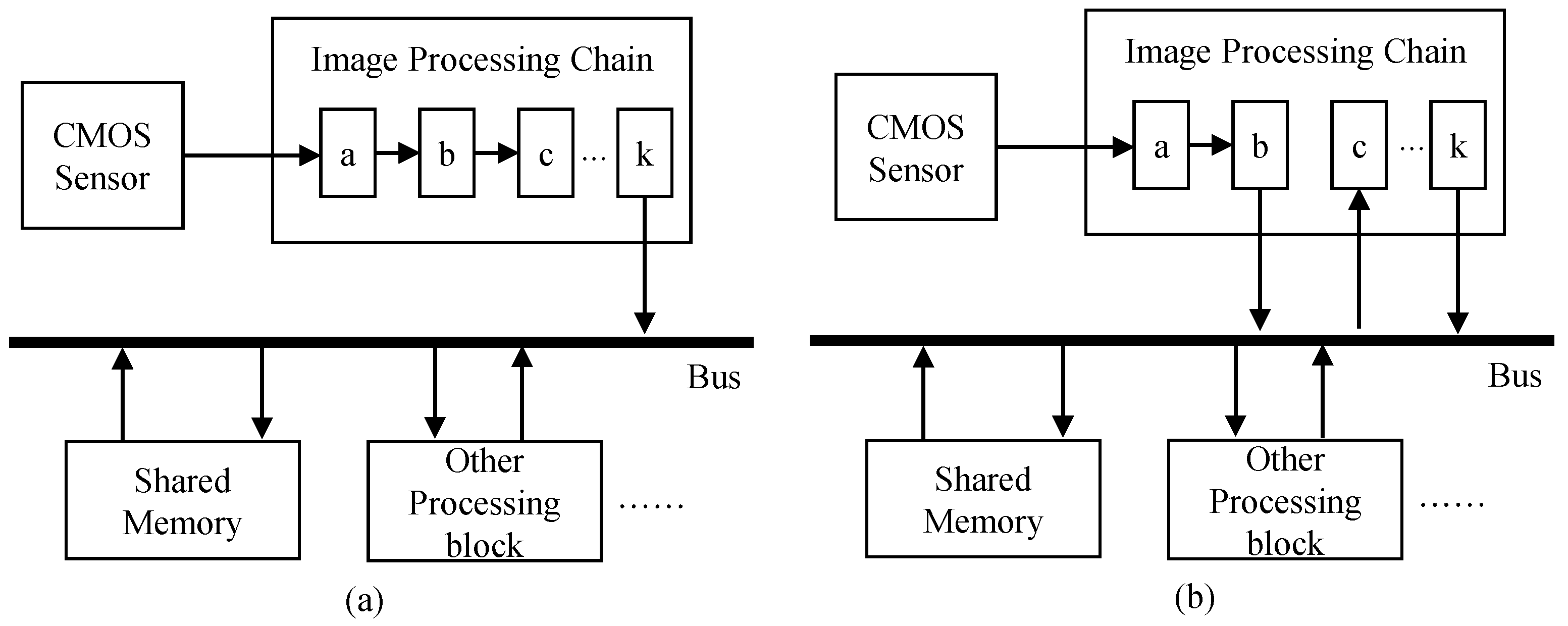
3.1. Camera SoC
3.1.1. Image Processing Chain
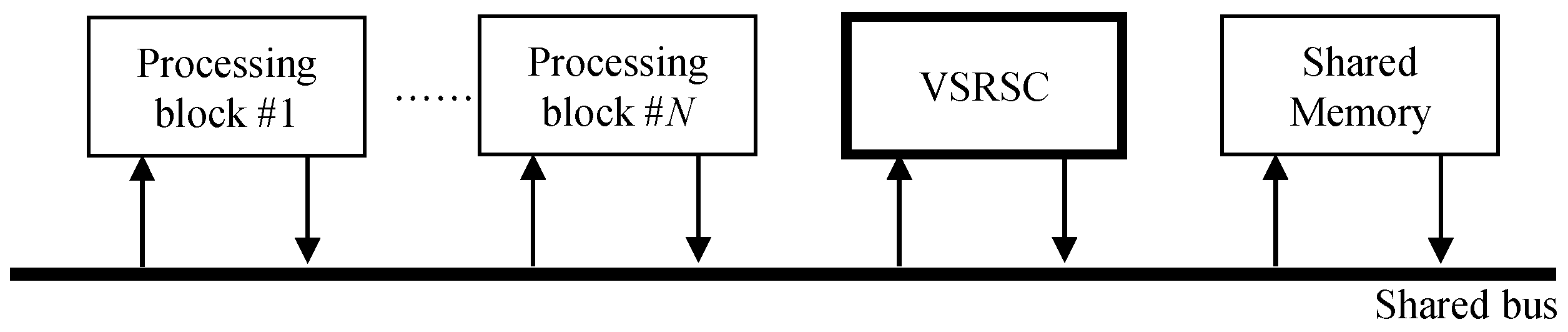
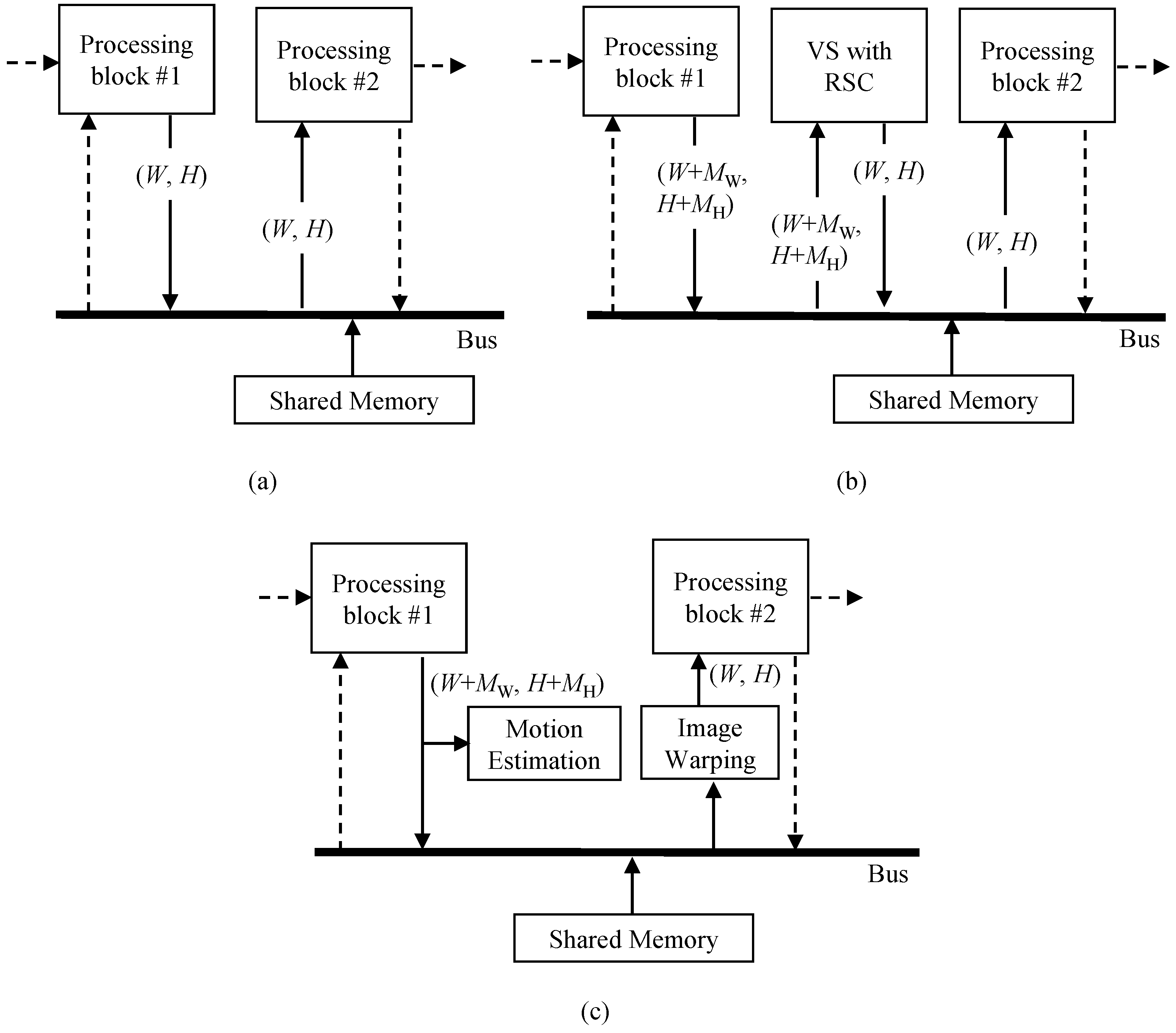
3.1.2. Requirement of VSRSC for Reducing Memory Access Usage
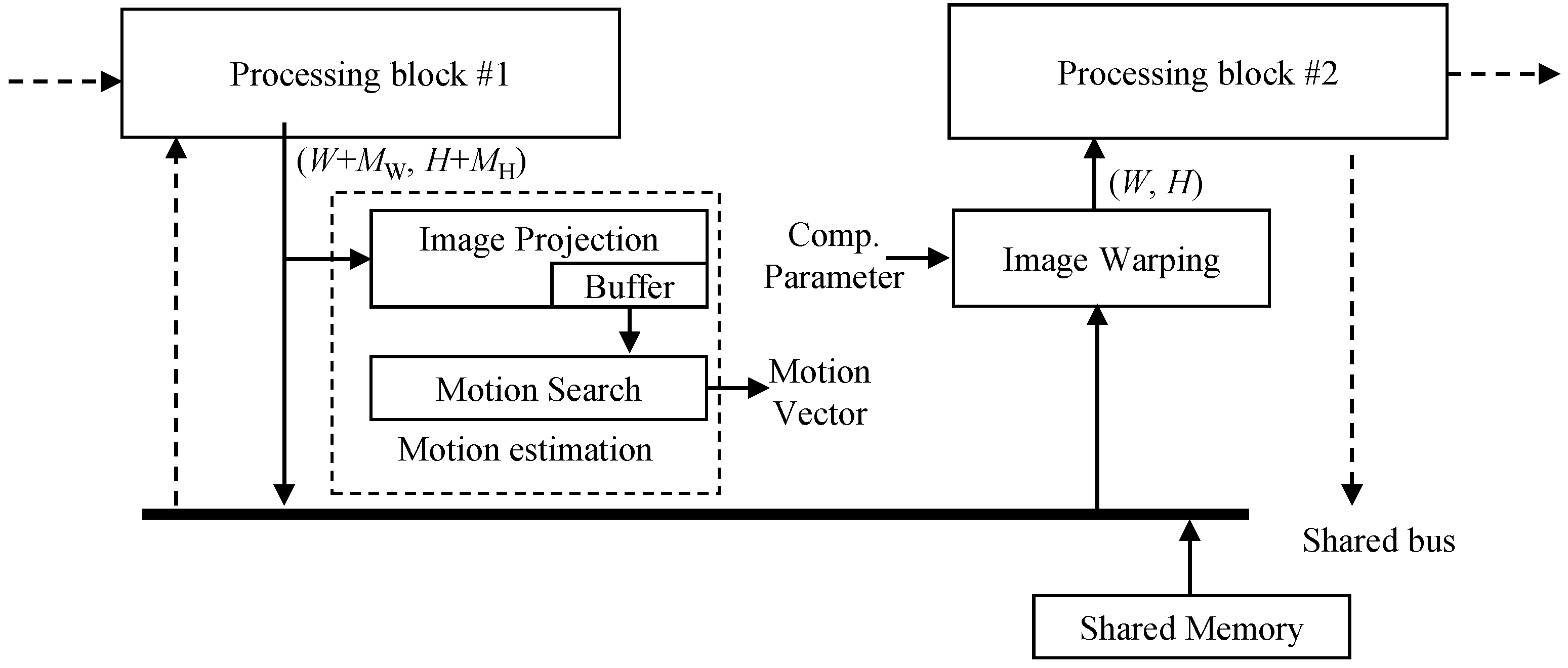
3.1.3. Structure of the Proposed Method for Reducing Memory Access Amount
3.2. Motion Estimation
3.3. Image Warping
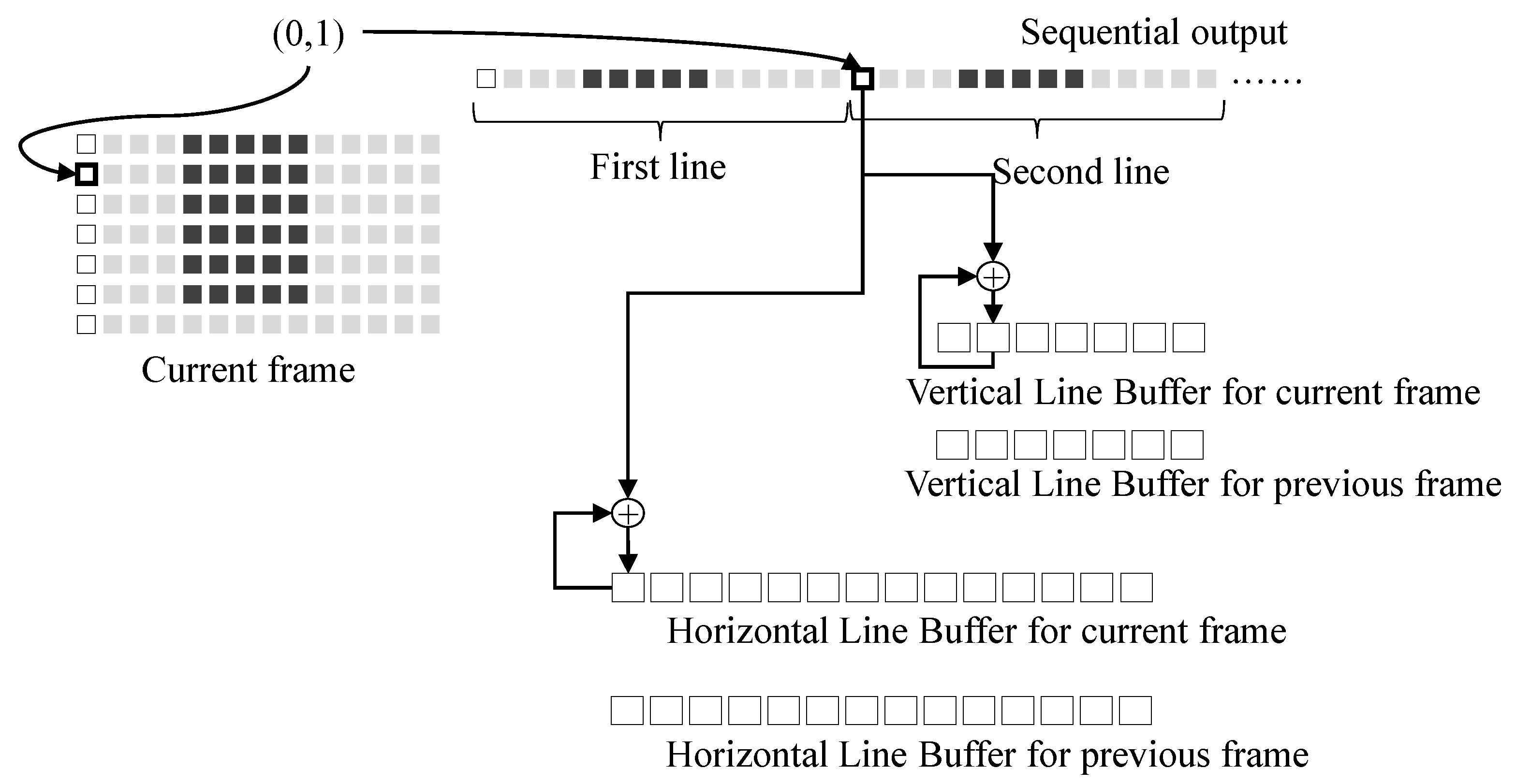
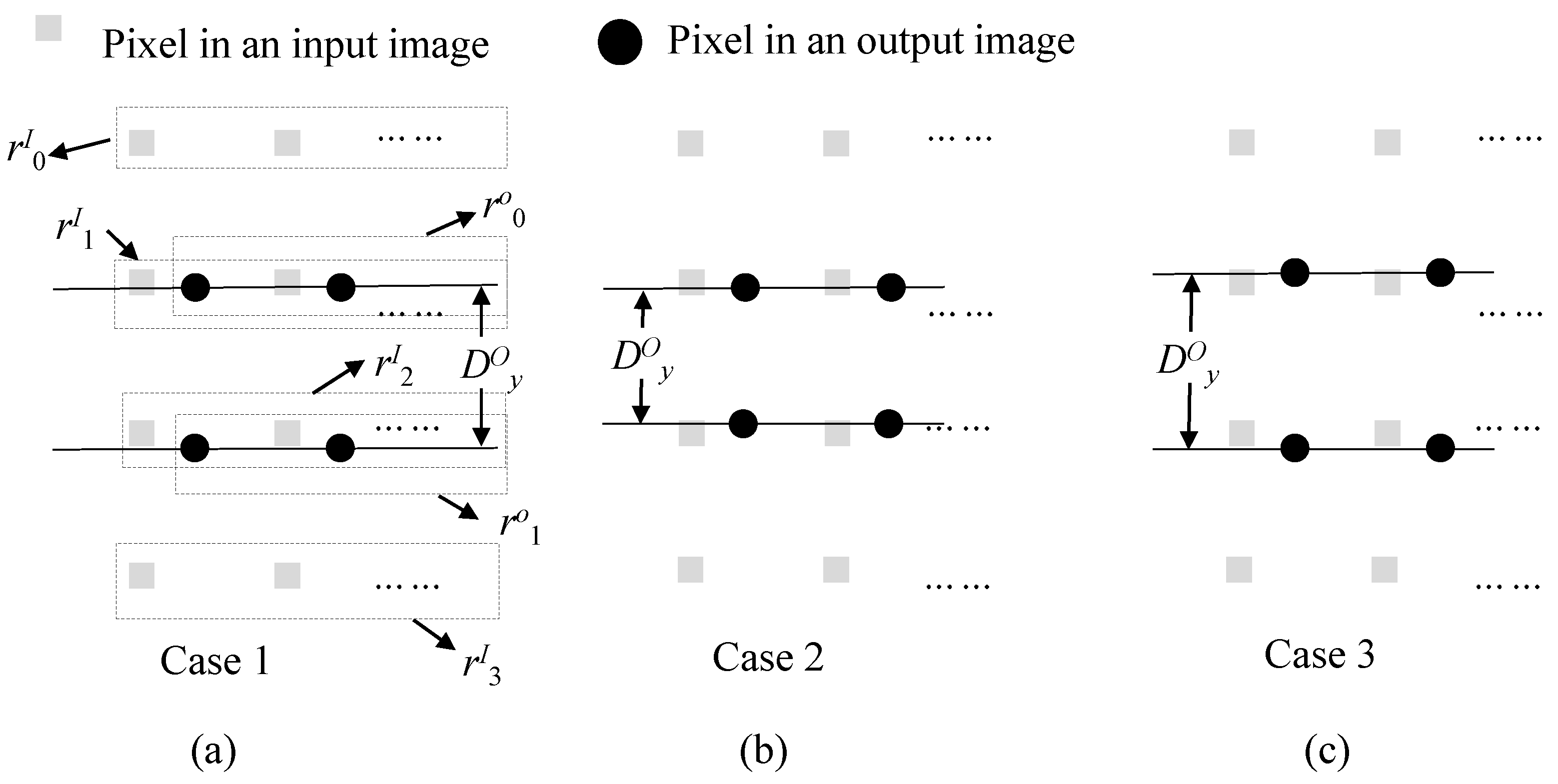
3.3.1. Raster Scan Order Access
3.3.2. Block-Based Access
4. Experimental Results and Analysis
4.1. Comparisons of Memory Access Amount
4.2. Image Quality
4.3. Extra Processing Delay
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Baker, R.J. CMOS: Circuit Design, Layout and Simulation, 3rd ed.; Wiley-IEEE: Hoboken, NJ, USA, 2010; p. 504. [Google Scholar]
- Lee, Y.G.; Kai, G. Fast rolling shutter compensation based on piecewise quadratic approximation of a camera trajectory. Opt. Eng. 2014, 53, 093101. [Google Scholar] [CrossRef]
- Liang, Y.-M.; Tyan, H.-R.; Chang, S.-L.; Liao, H.Y.M.; Chen, S.-W. Video stabilization for a camcorder mounted on a moving vehicle. IEEE Trans. Veh. Technol. 2004, 53, 1636–1648. [Google Scholar] [CrossRef]
- Geyer, C.; Meingast, M.; Sastry, S. Geometric models of rolling-shutter cameras. In Proceedings of the Omnidirectional Vision Camera Networks and Non-Classical Cameras, Beijing, China, 21 October 2005; pp. 12–19. [Google Scholar]
- Bermak, A.; Boussaid, F.; Bouzerdoum, A. A new read-out circuit for low power current and voltage mediated integrating cmos imager. In Proceedings of the IEEE International Workshop on Electronic Design, Test and Applications, Perth, WA, Australia, 28–30 January 2004. [Google Scholar]
- Liang, C.-K.; Chang, L.-W.; Chen, H.H. Analysis and compensation of rolling shutter effect. IEEE Trans. Image Process. 2008, 17, 1323–1330. [Google Scholar] [CrossRef] [PubMed]
- Morimoto, C.; Chellappa, R. Fast electronic digital image stabilization. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; pp. 284–288. [Google Scholar]
- Gleicher, M.L.; Liu, F. Re-cinematography: Improving the camerawork of casual video. ACM Trans. Multimed. Comput. Commun. Appl. 2008, 5, 1–28. [Google Scholar] [CrossRef]
- Liu, F.; Gleicher, M.; Jin, H.; Agarwala, A. Content-preserving warps for 3D video stabilization. ACM Trans. Graph. 2009, 28, 44. [Google Scholar] [CrossRef]
- Baker, S.; Bennett, E.P.; Kang, S.B.; Szeliski, R. Removing rolling shutter wobble. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 2392–2399. [Google Scholar]
- Forssen, P.-E.; Ringaby, E. Rectifying rolling shutter video from hand-held devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 507–514. [Google Scholar]
- Grundmann, M.; Kwatra, V.; Essa, I. Auto-Directed Video Stabilization with Robust L1 Optimal Camera Paths. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 225–232. [Google Scholar]
- Liu, F.; Gleicher, M.; Wang, J.; Jin, H.; Agarwala, A. Subspace video stabilization. ACM Trans. Graph. 2011, 30, 4. [Google Scholar] [CrossRef]
- Ringaby, E.; Forssen, P.-E. Efficient video rectification and stabilization of cell-phones. Int. J. Comput. Vis. 2012, 96, 335–352. [Google Scholar] [CrossRef] [Green Version]
- Grundmann, M.; Kwatra, V.; Castro, D.; Essa, I. Calibration-free rolling shutter removal. In Proceedings of the IEEE International Conference on Computational Photograph 2012, Seattle, WA, USA, 28–29 April 2012; pp. 1–8. [Google Scholar]
- Lee, Y.G. Video stabilization based the human visual system. J. Electron. Imaging 2013, 23, 053009. [Google Scholar] [CrossRef]
- Liu, S.; Yuan, L.; Tan, P.; Sun, J. Bundled camera paths for video stabilization. ACM Trans. Graph. 2013, 32, 78. [Google Scholar]
- Dong, J.; Liu, H. Video stabilization for strict real-time applications. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 716–724. [Google Scholar] [CrossRef]
- Lee, Y.G. Real-time rolling shutter compensation for a complementary metal-oxide semiconductor image sensor. Opt. Eng. 2018, 57, 100501. [Google Scholar] [CrossRef]
- Guilluy, W.; Oudre, L.; Beghdadi, A. Video stabilization: Overview, challenges and perspectives. Signal Process. Image Commun. 2021, 90, 116015. [Google Scholar] [CrossRef]
- Yang, G.-Y.; Lin, J.-K.; Zhang, S.-H.; Shamir, A.; Lu, S.-P.; Hu, S.-M. Deep Online Video Stabilization With Multi-Grid Warping Transformation Learning. IEEE Trans. Image Process. 2019, 28, 2283–2292. [Google Scholar]
- Yu, J.; Ramamoorthi, R. Robust Video Stabilization by Optimization in CNN Weight Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3800–3808. [Google Scholar]
- Zhao, M.; Ling, Q. PWStableNet: Learning Pixel-Wise Warping Maps for Video Stabilization. IEEE Trans. Image Process. 2020, 29, 3582–3595. [Google Scholar] [CrossRef] [PubMed]
- Araneda, L.; Figueroa, M. Real-Time Digital Video Stabilization on an FPGA. In Proceedings of the 2014 17th Euromicro Conference on Digital System Design, Verona, Italy, 27–29 August 2014. [Google Scholar]
- Araneda, L.; Figueroa, M. A compact hardware architecture for digital image stabilization using integral projections. Microprocess. Microsyst. 2016, 39, 987–997. [Google Scholar] [CrossRef]
- Lee, Y.G.; Song, B.C.; Kim, N.H.; Joo, W.H. Low-complexity near-lossless image coder for efficient bus traffic in very large size multimedia SOC. In Proceedings of the ICIP 2009, Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- Lee, Y.G. Fast global motion estimation on single instruction multiple data processors for real-time devices. Electron. Imaging 2019, 58, 113105. [Google Scholar] [CrossRef]
- S2L IP Camera Processor. Available online: https://www.ambarella.com/wp-content/uploads/S2L-Product-Brief-Final.pdf (accessed on 26 January 2022).
- Ramanath, R.; Snyder, W.E.; Yoo, Y.; Drew, M.S. Color image processing pipeline. IEEE Signal Process. Mag. 2005, 22, 34–43. [Google Scholar] [CrossRef]
- Adams, J.E.; Hamilton, J.F. Digital Camera Image Processing Chain Design, 1st ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Cho, C.-Y.; Chen, T.-M.; Wang, W.-S.; Liu, C.-N. Real-Time Photo Sensor Dead Pixel Detection for Embedded Devices. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, OLD, Australia, 6–8 December 2011. [Google Scholar]
- Mughal, W.; Choubey, B. Fixed pattern noise correction for wide dynamic range CMOS image sensor with Reinhard tone mapping operator. In Proceedings of the 2015 Nordic Circuits and Systems Conference (NORCAS): NORCHIP & International Symposium on System-on-Chip (SoC), Oslo, Norway, 26–28 October 2015. [Google Scholar]
- Barnard, K.; Cardei, V.; Funt, B. A comparison of computational color constancy algorithms—Part I: Methodology and experiments with synthesized data. IEEE Trans. Image Process. 2002, 11, 972–983. [Google Scholar] [CrossRef]
- Trussell, H.J.; Hartwig, R.E. Mathematics for demosaicking. IEEE Trans. Image Process. 2002, 11, 485–492. [Google Scholar] [CrossRef]
- Sikora, T. The MPEG-4 video standard verification model. IEEE Trans. Circuits Syst. Video Technol. 1997, 7, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.-K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.-R. Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Memory Bandwidth | |
|---|---|---|
| No VSRSC | ||
| Straightforward method | On average | |
| maximum | ||
| Proposed method Raster scan order | On average | |
| maximum | ||
| Proposed method Block-based (on average) | ||
| Method | Memory Bandwidth | ||
|---|---|---|---|
| Value | Ratio | ||
| No VSRSC | 4,147,200 | 1.00 | |
| Straightforward method | On average | 13,747,968 | 3.32 |
| maximum | 14,183,424 | 3.42 | |
| Proposed method raster scan order | On average | 4,582,656 | 1.11 |
| maximum | 5,018,112 | 1.21 | |
| Proposed method Block-based (on average) | 4,778,752 | 1.15 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.-G. Low Memory Access Video Stabilization for Low-Cost Camera SoC. Sensors 2022, 22, 2341. https://doi.org/10.3390/s22062341
Lee Y-G. Low Memory Access Video Stabilization for Low-Cost Camera SoC. Sensors. 2022; 22(6):2341. https://doi.org/10.3390/s22062341
Chicago/Turabian StyleLee, Yun-Gu. 2022. "Low Memory Access Video Stabilization for Low-Cost Camera SoC" Sensors 22, no. 6: 2341. https://doi.org/10.3390/s22062341
APA StyleLee, Y. -G. (2022). Low Memory Access Video Stabilization for Low-Cost Camera SoC. Sensors, 22(6), 2341. https://doi.org/10.3390/s22062341