
FOODCAM: A Novel Structured Light-Stereo Imaging System for Food Portion Size Estimation



Abstract
:1. Introduction
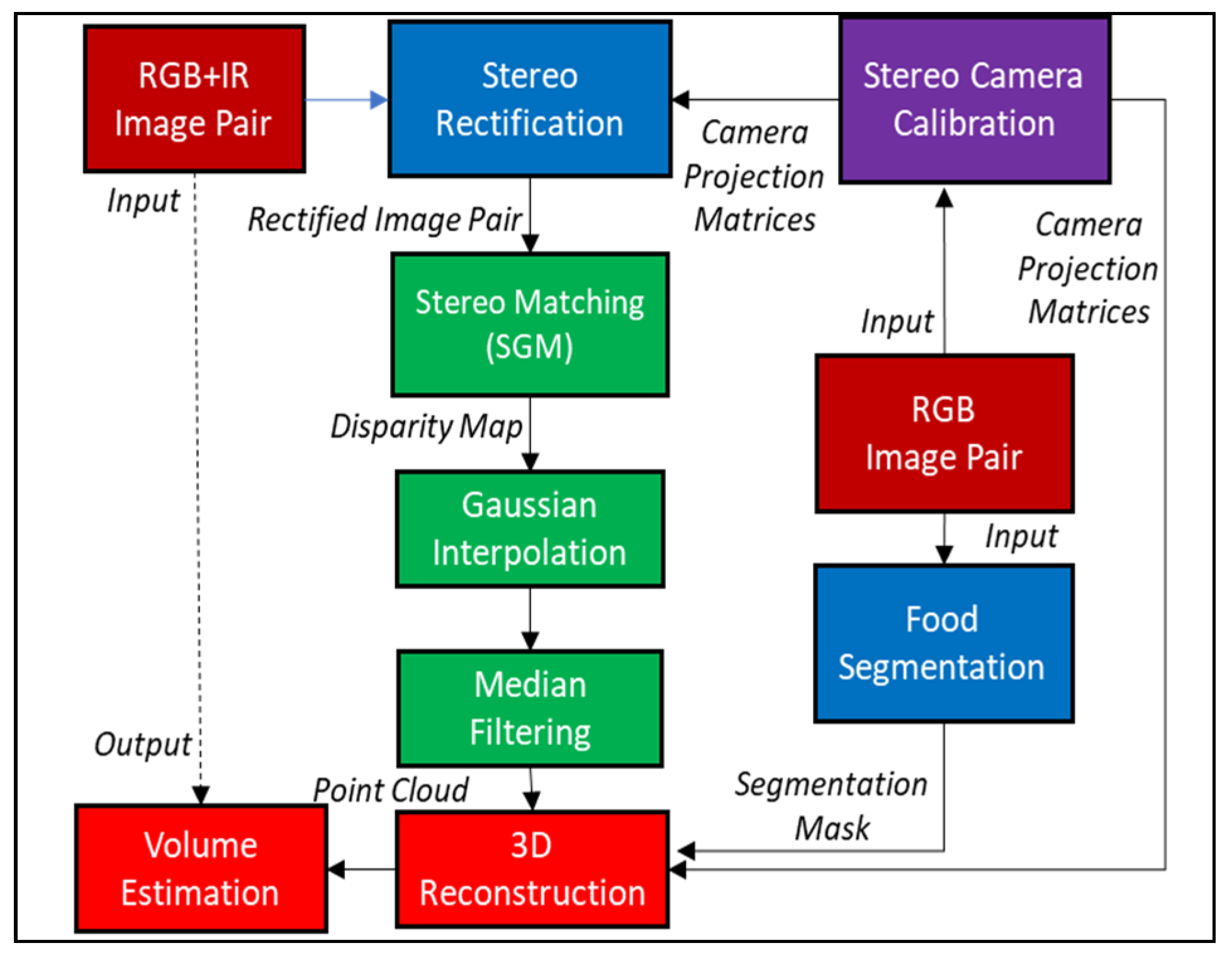
2. Materials and Methods
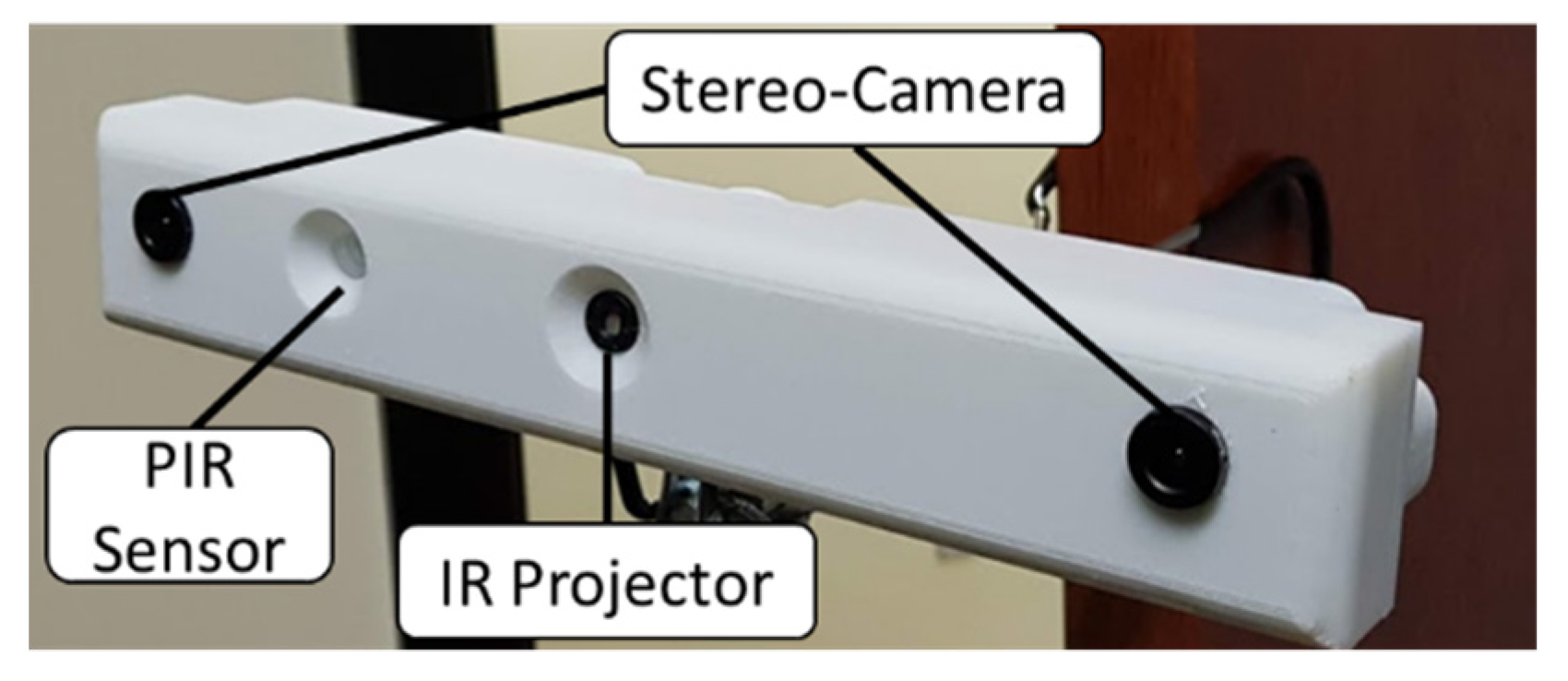
2.1. Device Description
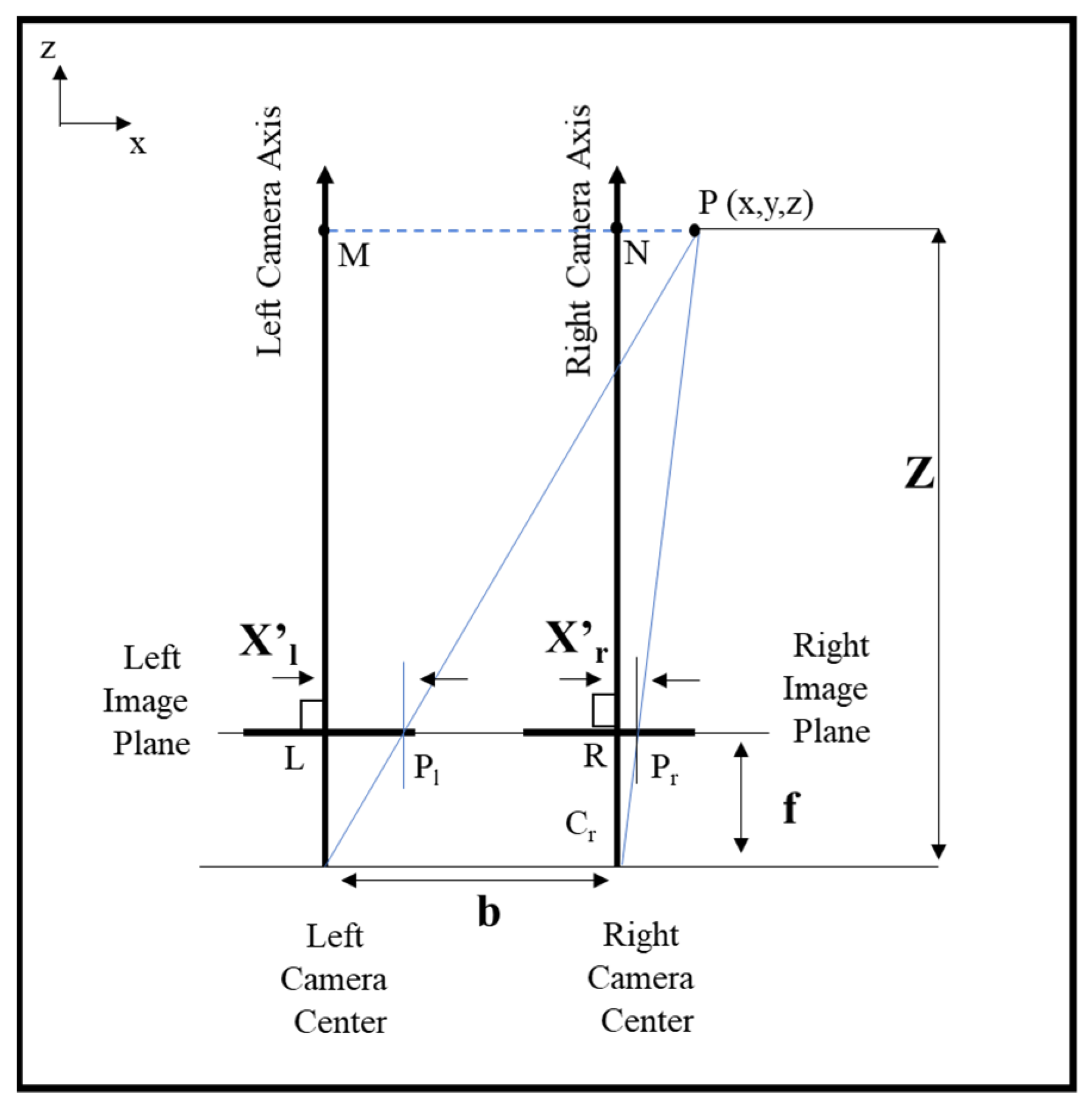
2.2. Design for Specified Spatial Resolution
- z is the depth of the object from the stereo system;
- f is the focal length of the cameras;
- b is the baseline distance between the two cameras; and
- Δd is the disparity resolution.
- Pixel Size for OV5640 = 1.4 μm square;
- Disparity resolution, Δd: 1/5 ×1.4 μm = 0.28 μm; and
- Effective Focal Length = 3.38 mm.
- Pixel resolution: The device was used to capture images of a checkerboard image at different distances from the camera. The checkerboard image had squares of unit size (1 cm sides). From this set of images, the parameters described in Table 2 were determined. The number of pixels in each unit square (pixels/square cm) was determined from the images from which the size of each pixel was calculated (sq. mm/pixel). The size of each 2-dimensional pixel provides the spatial resolution of the camera. This measurement was taken prior to camera calibration. A pixel resolution of around 0.5 mm/pixel was set as a requirement.
- Area: Table 2 also includes the area covered by the FOODCAM as a function of height. The area of overlap of the two cameras is the area covered by the FOODCAM. The area covered by the FOODCAM was practically measured by capturing images at different distances from the floor. An area of at least 106.68 cm × 106.68 cm (3.5 ft. × 3.5 ft.) was set as a requirement.
2.3. Calibration and Stereo Rectification
2.4. Semi-Global Matching
2.5. Gaussian Interpolation and Median Filtering
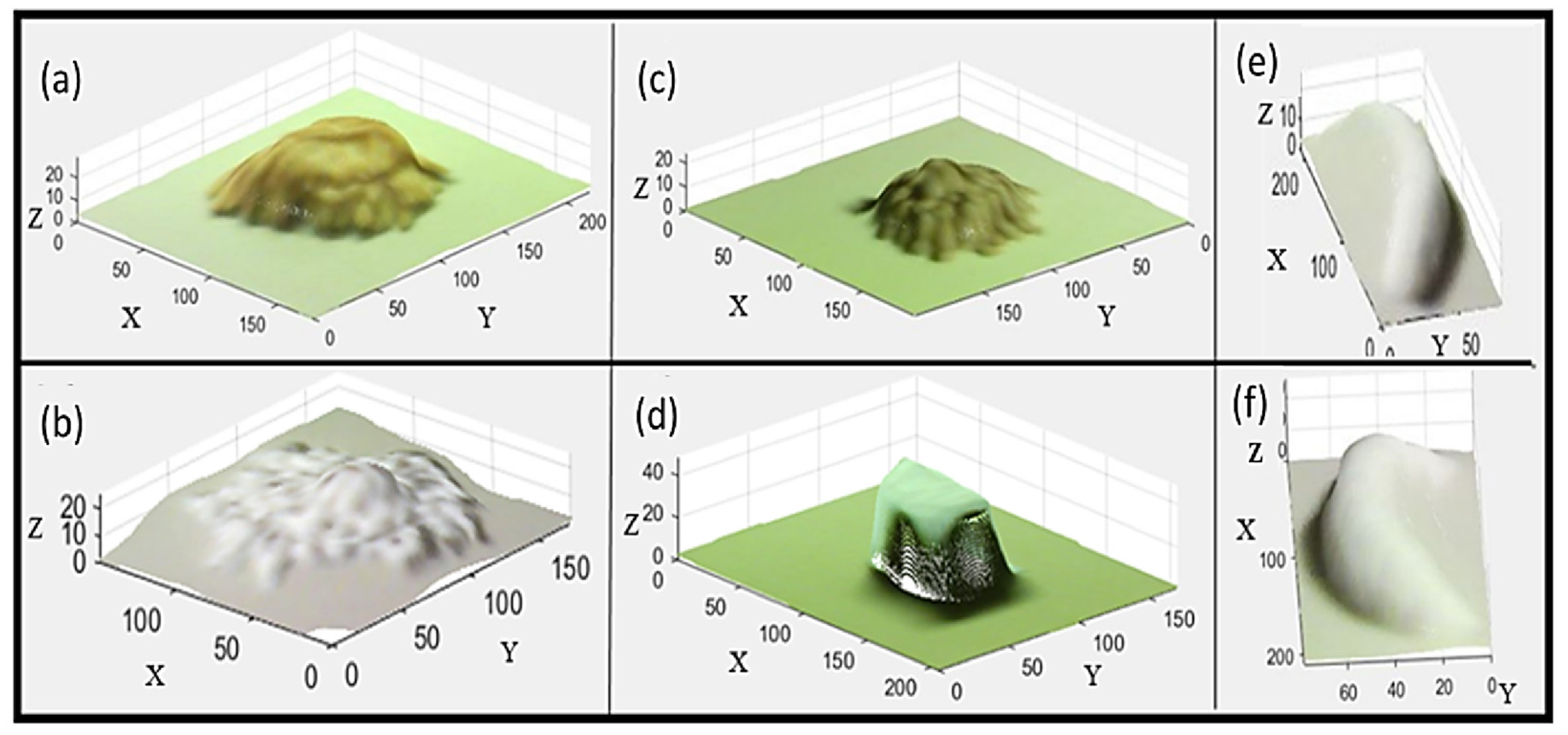
2.6. 3D-Reconstruction
2.7. Volume Estimation (for FOODCAM)
2.8. PMD CamBoard Pico Flexx
3. Results
4. Discussion
- The IR projector provides an artificial texture that facilitates the stereo matching algorithm for food scenes, where major portions of the image may be flat and texture-free (e.g., plate or table surface). In traditional methods, matching accuracy suffers due to ambiguities in matched pixels on such surfaces.
- The problem of matching the structured light from the projector and the light pattern projected in the image, as in the case of structured light reconstruction, is replaced by a more straightforward stereo-correspondence problem, allowing the use of a random projection pattern, and thus, a less expensive projector.
- The projector or the pattern in the proposed method does not need calibration. Any random pattern can be used, thus reducing the cost and complexity of the projector being used.
- The proposed approach does not require any fiducial markers.
- Once the device is calibrated, it can be fixed to a location to monitor food intake. The same calibration parameters can be stored and re-used for that device. In other words, the calibration only needs to be conducted once.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Haglage, A. America’s Most (and Least) Obese States. Yahoo Lifestyle. 6 November 2019. Available online: https://www.yahoo.com/lifestyle/americas-most-and-least-obese-states-192502772.html (accessed on 9 November 2019).
- Preidt, R. Study: Nearly 5 Million American Kids Are Obese. WebMD. 10 October 2019. Available online: https://www.webmd.com/diet/obesity/news/20191010/nearly-5-million-american-kids-are-obese-new-study-finds#1 (accessed on 10 April 2022).
- Garg, S.; Kim, L.; Whitaker, M.; O’Halloran, A.; Cummings, C.; Holstein, R.; Prill, M.; Chai, S.J.; Kirley, P.D.; Alden, N.B.; et al. Hospitalization Rates and Characteristics of Patients Hospitalized with Laboratory-Confirmed Coronavirus Disease 2019—COVID-NET, 14 States, 1–30 March 2020. MMWR. Morb. Mortal. Wkly. Rep. 2020, 69, 458–464. [Google Scholar] [CrossRef]
- Kral, T.V.; Rolls, B.J. Energy density and portion size: Their independent and combined effects on energy intake. Physiol. Behav. 2004, 82, 131–138. [Google Scholar] [CrossRef] [PubMed]
- Almiron-Roig, E.; Navas-Carretero, S.; Emery, P.; Martínez, J.A. Research into food portion size: Methodological aspects and applications. Food Funct. 2017, 9, 715–739. [Google Scholar] [CrossRef]
- Raju, V.B.; Sazonov, E. A Systematic Review of Sensor-Based Methodologies for Food Portion Size Estimation. IEEE Sens. J. 2020, 21, 12882–12899. [Google Scholar] [CrossRef]
- Xu, C.; He, Y.; Khanna, N.; Boushey, C.J.; Delp, E.J. Model-based food volume estimation using 3D pose. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2534–2538. [Google Scholar] [CrossRef] [Green Version]
- Dehais, J.; Anthimopoulos, M.; Shevchik, S.; Mougiakakou, S. Two-View 3D Reconstruction for Food Volume Estimation. IEEE Trans. Multimed. 2016, 19, 1090–1099, 2017. [Google Scholar] [CrossRef] [Green Version]
- Gao, A.; Lo, F.P.-W.; Lo, B. Food volume estimation for quantifying dietary intake with a wearable camera. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks, BSN 2018, Las Vegas, NV, USA, 4–7 March 2018; Volume 2018, pp. 110–113. [Google Scholar] [CrossRef]
- Jia, W.; Yue, Y.; Fernstrom, J.D.; Yao, N.; Sclabassi, R.J.; Fernstrom, M.H.; Sun, M. Imaged based estimation of food volume using circular referents in dietary assessment. J. Food Eng. 2012, 109, 76–86. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCrory, M.; Sun, M.; Sazonov, E.; Frost, G.; Anderson, A.; Jia, W.; Jobarteh, M.L.; Maitland, K.; Steiner-Asiedu, M.; Ghosh, T.; et al. Methodology for Objective, Passive, Image- and Sensor-based Assessment of Dietary Intake, Meal-timing, and Food-related Activity in Ghana and Kenya (P13-028-19). Curr. Dev. Nutr. 2019, 3 (Suppl. 1), nzaa002. [Google Scholar] [CrossRef] [Green Version]
- Mirtchouk, M.; Merck, C.; Kleinberg, S. Automated estimation of food type and amount consumed from body-worn audio and motion sensors. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 451–462. [Google Scholar] [CrossRef]
- Sazonov, E.; Schuckers, S.; Lopez-Meyer, P.; Makeyev, O.; Sazonova, N.; Melanson, E.L.; Neuman, M. Non-invasive monitoring of chewing and swallowing for objective quantification of ingestive behavior. Physiol. Meas. 2008, 29, 525–541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Doulah, A.B.M.S.U.; Farooq, M.; Parton, J.; McCrory, M.A.; Higgins, J.A.; Sazonov, E. Statistical models for meal-level estimation of mass and energy intake using features derived from video observation and a chewing sensor. Sci. Rep. 2019, 9, 45. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.; Zhu, F.; Jiang, C.; Zhang, S.; Boushey, C.J.; Delp, E.J. A comparison of food portion size estimation using geometric models and depth images. In Proceedings of the International Conference on Image Processing, ICIP, Phoenix, AZ, USA, 25–28 September 2016; Volume 2016, pp. 26–30. [Google Scholar] [CrossRef]
- Meyers, A.; Johnston, N.; Rathod, V.; Korattikara, A.; Gorban, A.; Silberman, N.; Guadarrama, S.; Papandreou, G.; Huang, J.; Murphy, K.P. Im2Calories: Towards an automated mobile vision food diary. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 1233–1241. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, Y.; Yue, Y.; Fernstrom, J.D.; Jia, W.; Sun, M. Food volume estimation from a single image using virtual reality technology. In Proceedings of the 2011 IEEE 37th Annual Northeast Bioengineering Conference (NEBEC), Troy, NY, USA, 1–3 April 2011. [Google Scholar] [CrossRef]
- Jia, W.; Yue, Y.; Fernstrom, J.D.; Zhang, Z.; Yang, Y.; Sun, M. 3D localization of circular feature in 2D image and application to food volume estimation. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2012, 2012, 4545–4548. [Google Scholar] [CrossRef] [Green Version]
- Pouladzadeh, P.; Shirmohammadi, S.; Al-Maghrabi, R. Measuring Calorie and Nutrition From Food Image. IEEE Trans. Instrum. Meas. 2014, 63, 1947–1956. [Google Scholar] [CrossRef]
- Boushey, C.J.; Kerr, D.A.; Wright, J.; Lutes, K.D.; Ebert, D.; Delp, E. Use of technology in children’s dietary assessment. Eur. J. Clin. Nutr. 2009, 63, S50–S57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khanna, N.; Boushey, C.J.; Kerr, D.; Okos, M.; Ebert, D.S.; Delp, E.J. An Overview of the Technology Assisted Dietary Assessment Project at Purdue University. In Proceedings of the 2010 IEEE International Symposium on Multimedia, Taichung, Taiwan, 13–15 December 2010; pp. 290–295. [Google Scholar] [CrossRef] [Green Version]
- Puri, M.; Zhu, Z.; Yu, Q.; Divakaran, A.; Sawhney, H. Recognition and volume estimation of food intake using a mobile device. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Dehais, J.; Shevchik, S.; Diem, P.; Mougiakakou, S.G. Food volume computation for self dietary assessment applications. In Proceedings of the 13th IEEE International Conference on BioInformatics and BioEngineering, Chania, Greece, 10–13 November 2013. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, D.; Sun, M.; Zhang, H. A Slice-Based Method for Food Volume Estimation. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, New York, NY, USA, 10–12 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Z.; Xiang, C.-Q.; Chen, T. Automated Binocular Vision Measurement of Food Dimensions and Volume for Dietary Evaluation. Comput. Sci. Eng. 2018, 1. [Google Scholar] [CrossRef]
- Subhi, M.; Ali, S.H.M.; Ismail, A.G.; Othman, M. Food volume estimation based on stereo image analysis. IEEE Instrum. Meas. Mag. 2018, 21, 36–43. [Google Scholar] [CrossRef]
- Li, J.; Liu, G.; Liu, Y. A dynamic volume measurement system with structured light vision. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 251–255. [Google Scholar] [CrossRef]
- Kawasaki, H.; Furukawa, R.; Sagawa, R.; Yagi, Y. Dynamic scene shape reconstruction using a single structured light pattern. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Albitar, C.; Graebling, P.; Doignon, C. Robust Structured Light Coding for 3D Reconstruction. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–6. [Google Scholar] [CrossRef]
- Shang, J.; Duong, M.; Pepin, E.; Zhang, X.; Sandara-Rajan, K.; Mamishev, A.; Kristal, A. A mobile structured light system for food volume estimation. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 201; pp. 100–101. [CrossRef]
- Scharstein, D.; Szeliski, R. High-accuracy stereo depth maps using structured light. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. I-195–I-202. [Google Scholar] [CrossRef]
- What to Expect from a Stereo Vision System. National Instruments-NI Vision 2015 Concepts Help. June 2015. Available online: http://zone.ni.com/reference/en-XX/help/372916T-01/nivisionconcepts/stereo_what_to_expect_from_a_stereo_vision_system/ (accessed on 6 July 2020).
- Heikkila, J.; Silven, O. A four-step camera calibration procedure with implicit image correction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 1106–1112. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Raju, V.; Sazonov, E. Processing of Egocentric Camera Images from a Wearable Food Intake Sensor. In Proceedings of the 2019 SoutheastCon, Huntsville, AL, USA, 11–14 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- AlphaShape. Mathworks Documentation. Available online: https://www.mathworks.com/help/matlab/ref/alphashape.html (accessed on 14 November 2021).
- Raju, V.B.; Sazonov, E. Detection of Oil-Containing Dressing on Salad Leaves Using Multispectral Imaging. IEEE Access 2020, 8, 86196–86206. [Google Scholar] [CrossRef]
- Mattfeld, R.S.; Muth, E.R.; Hoover, A. Measuring the Consumption of Individual Solid and Liquid Bites Using a Table-Embedded Scale during Unrestricted Eating. IEEE J. Biomed. Health Inform. 2017, 21, 1711–1718. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | Stereo Reconstruction | Structured Light Reconstruction |
|---|---|---|
| Number of Viewpoints | Two (stereo camera or 1 camera at two view angles) | One (1 camera and a structured light projector) |
| Advantages | (1) Provides a depth perspective of an object without any information about the surroundings. (2) Eliminates fiducial markers (3) Once cameras are calibrated, the pixel correspondence problem is reduced to a horizontal search | (1) Adds texture to objects. (2) Reduces the number of viewpoints needed. (3) Accurate and dense pixel- correspondences can be automatically produced. |
| Limitations and Disadvantages | (1) Occlusions (2) Correspondence problem in case of texture-less objects | (1) Projector needs to be calibrated, and the pattern must be known. (2) Computations can be slower and time-consuming |
| Height of Camera Installation (cm) | mm/Pixel | Pixels/sq. cm | Area Covered |
|---|---|---|---|
| 60.96 | 0.14 | 4900 | 69.92 cm × 69.92 cm |
| 91.44 | 0.28 | 1296 | 76.2 cm × 76.2 cm |
| 121.92 | 0.40 | 676 | 101.92 cm × 101.92 cm |
| 152.4 | 0.55 | 400 | 112.78 cm × 112.78 cm |
| 182.88 | 0.71 | 196 | 128.02 cm × 124.97 cm |
| 213.36 | 0.83 | 144 | 158.5 cm × 158.5 cm |
| 243.84 | 1 | 100 | 179.83 cm × 182.88 cm |
| 274.32 | 1.2 | 64 | 207.27 cm × 207.27 cm |
| 304.8 | 1.4 | 36 | 236.74 cm × 236.74 cm |
| Food Item | Random Position | Predicted Volume (mL) | Mean Predicted Volume (Mean ± Std. Dev.) | Ground Truth | Mean Error in Volume Estimation (Mean ± Std. Dev.) | |||
|---|---|---|---|---|---|---|---|---|
| Trial 1 | Trial 2 | Trial 3 | Trial 4 | |||||
| Chickpeas | 1 | 77.58 | 75.2526 | 75.2526 | 78.3558 | 75.84 ± 2.07 mL | 100 mL | −24.17 ± 2.01% |
| 2 | 76.0284 | 76.8042 | 74.4768 | 80.6832 | ||||
| 3 | 73.701 | 74.4768 | 73.701 | 73.701 | ||||
| French Fries | 1 | 147.54 | 144.5892 | 146.0646 | 141.6384 | 146.66 ± 3.42 mL | 180 mL | −18.58 ± 1.90% |
| 2 | 140.163 | 151.9662 | 144.5892 | 147.54 | ||||
| 3 | 149.0154 | 151.9662 | 147.54 | 146.0646 | ||||
| Popcorn | 1 | 100.41 | 95.38 | 103.412 | 98.392 | 100.14 ± 3.015 mL | 130 mL | −22.97 ± 2.31% |
| 2 | 95.38 | 103.412 | 102.408 | 104.416 | ||||
| 3 | 98.392 | 97.388 | 102.408 | 100.4 | ||||
| Chocolate Brownie | 1 | 135.44 | 131.81 | 131.81 | 134.5 | 133.90 ± 3.35 mL | 135 mL | −0.81 ± 2.48% |
| 2 | 130.465 | 138.535 | 131.81 | 138.535 | ||||
| 3 | 133.155 | 129.12 | 139.88 | 131.81 | ||||
| Banana | 1 | 96.192 | 97.194 | 98.196 | 99.198 | 100.16 ± 2.65 mL | 120 mL | −16.57 ± 2.20% |
| 2 | 103.206 | 99.198 | 101.202 | 105.21 | ||||
| 3 | 97.194 | 103.206 | 101.202 | 100.2 | ||||
| Mean Absolute Error: | 16.62% | |||||||
| Food Item | Random Position | Predicted Volume (mL) | Mean Predicted Volume (Mean ± Std. Dev.) | Ground Truth | Error in Volume Estimation (Mean ± Std. Dev.) | |||
|---|---|---|---|---|---|---|---|---|
| Trial 1 | Trial 2 | Trial 3 | Trial 4 | |||||
| Chickpeas | 1 | 103.47 | 96.27 | 89.92 | 88.84 | 93.77 ± 5.33 mL | 100 mL | −6.23 ± 5.33% |
| 2 | 101.99 | 100.24 | 86.74 | 91.87 | ||||
| 3 | 92.79 | 94.23 | 89.04 | 89.82 | ||||
| French Fries | 1 | 166.22 | 164.76 | 163.15 | 165.40 | 169.67 ± 8.04 mL | 180 mL | −5.73± 4.46% |
| 2 | 165.65 | 164.85 | 190.07 | 166.98 | ||||
| 3 | 166.07 | 180.80 | 164.98 | 177.18 | ||||
| Popcorn | 1 | 134.61 | 123.65 | 127.80 | 137.74 | 137.53 ± 7.95 mL | 130 mL | 5.79 ± 6.12% |
| 2 | 137.98 | 149.75 | 143.44 | 150.04 | ||||
| 3 | 142.30 | 136.61 | 127.67 | 138.83 | ||||
| Chocolate Brownie | 1 | 141.29 | 137.32 | 142.12 | 136.03 | 143.88 ± 5.46 mL | 135 mL | 6.58 ± 4.04% |
| 2 | 148.91 | 152.29 | 143.86 | 149.20 | ||||
| Banana | 1 | 108.86 | 118.38 | 130.28 | 117.82 | 115.58 ± 9.74 mL | 120 mL | −3.68 ± 8.11% |
| 2 | 126.28 | 118.29 | 125.67 | 124.72 | ||||
| 3 | 102.03 | 103.44 | 101.94 | 109.28 | ||||
| Mean Absolute Error: | 5.60% | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raju, V.B.; Sazonov, E. FOODCAM: A Novel Structured Light-Stereo Imaging System for Food Portion Size Estimation. Sensors 2022, 22, 3300. https://doi.org/10.3390/s22093300
Raju VB, Sazonov E. FOODCAM: A Novel Structured Light-Stereo Imaging System for Food Portion Size Estimation. Sensors. 2022; 22(9):3300. https://doi.org/10.3390/s22093300
Chicago/Turabian StyleRaju, Viprav B., and Edward Sazonov. 2022. "FOODCAM: A Novel Structured Light-Stereo Imaging System for Food Portion Size Estimation" Sensors 22, no. 9: 3300. https://doi.org/10.3390/s22093300
APA StyleRaju, V. B., & Sazonov, E. (2022). FOODCAM: A Novel Structured Light-Stereo Imaging System for Food Portion Size Estimation. Sensors, 22(9), 3300. https://doi.org/10.3390/s22093300