
Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas



Abstract
:1. Introduction
- We integrated the heterogeneous data sources of Intelligent transportation systems for data collected from a particular city in Pakistan and built the hybrid LSTM-GRU model.
- We predicted the traffic speed on the basis of heterogeneous traffic data sources including exogenous data sources, e.g., weather, event and, peak hours.
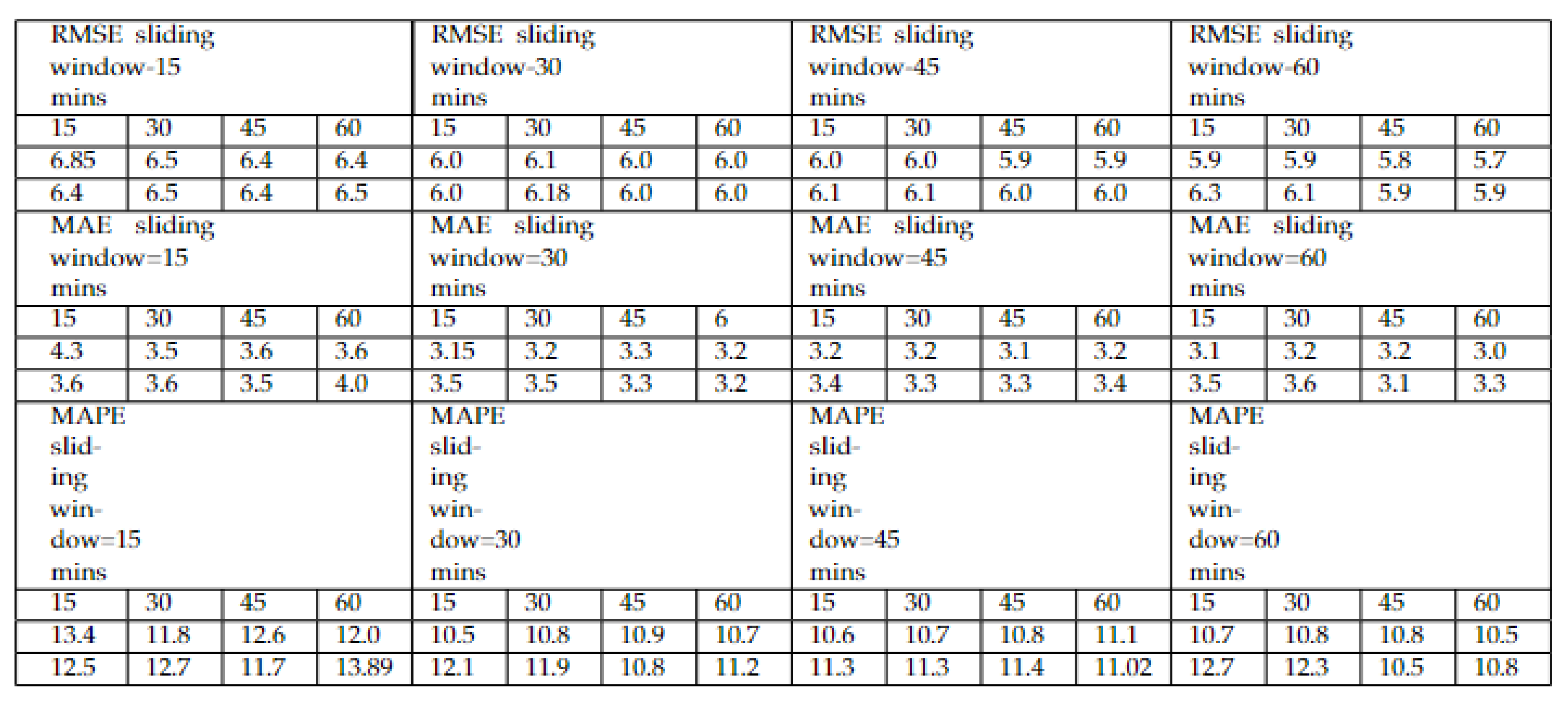
- The Hybrid LSTM-GRU model has been applied on time intervals varying from 15 min to 1 h and the effectiveness of the model has been evaluated.
2. Related Work
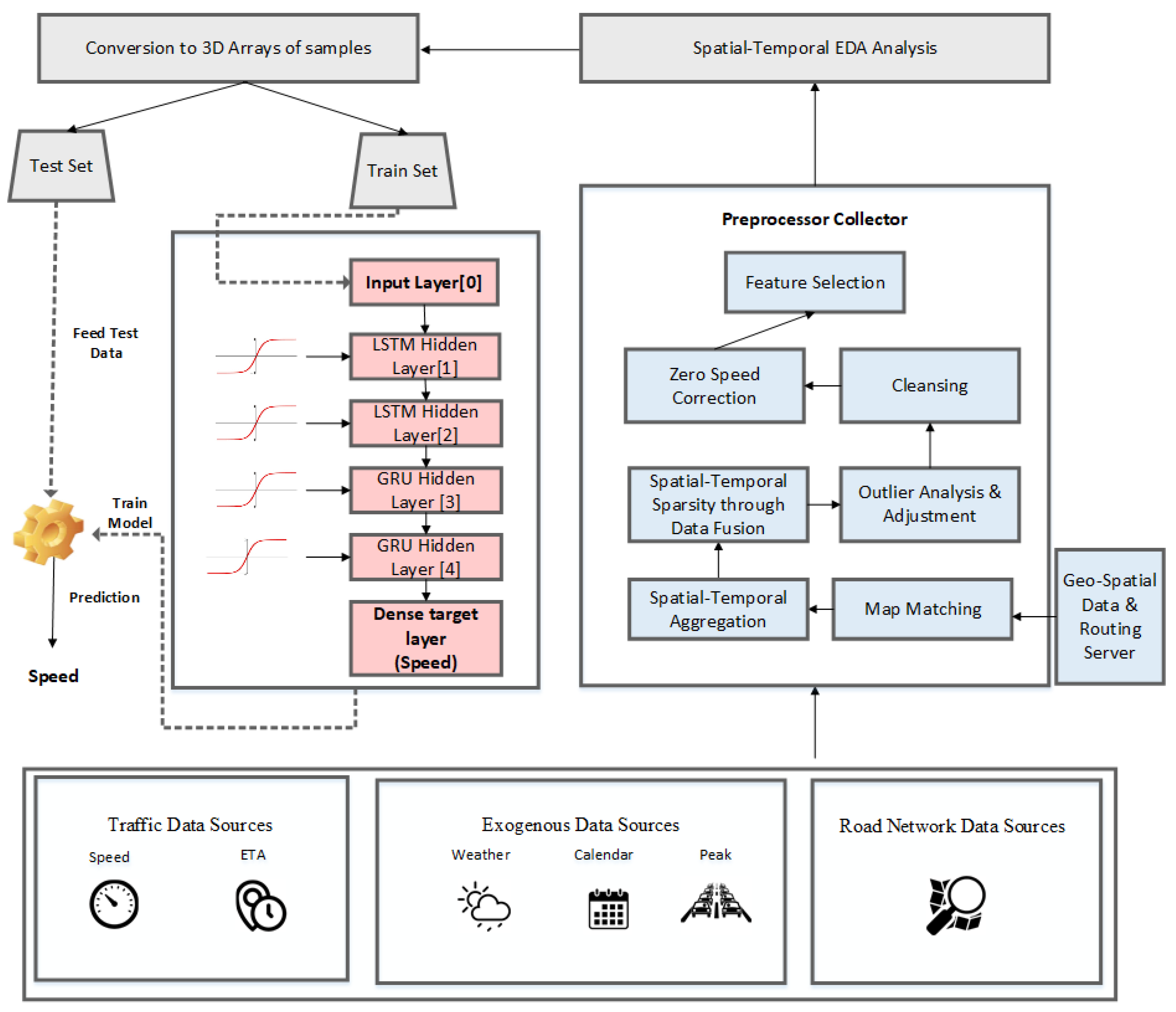
3. Proposed Methodology Based on Hybrid LSTM–GRU Model
3.1. Data Sources
3.1.1. FCD Data Source
- There was an off-road mapping of cars. This could be due to two reasons. Either the car appears offroad because of inherent GPS error or because the car was actually parked somewhere off the road.
- A large number of speed values generated by trackers were zero. This again could be due to two reasons: either the car is parked or stuck in congestion. The congestion data needed to be distinguished from the data related to the parked cars.
- There was duplication of tuples.
- There are missing values causing spatial sparsity. This is because the FCD does not cover all segments of roads of the road network.
| Algorithm 1 Preprocessing and Data Integration Algo |
|
3.1.2. ETA Data Source
3.1.3. OSM Data Source
3.1.4. Calendar Data Source
3.1.5. Weather Data Source
3.2. Data Integration Pipeline
- Map matching of GPS points
- Handling the abnormal behavior of data
- Data generalization and transformation
- Calculating the average speed of road section.
3.3. Model Selection
3.3.1. LSTM
3.3.2. GRU
3.3.3. Hybrid LSTM-GRU Model Description
- Input Gate:
- Forget Gate:
- Output Gate:
- Update Gate:
- Reset Gate:
- Cell Output:
- Cell Input:
3.3.4. Performance Measures for Proposed Hybrid LSTM–GRU Model
- = desired speed
- = predicted speed
- n = number of observations
4. Results and Discussion
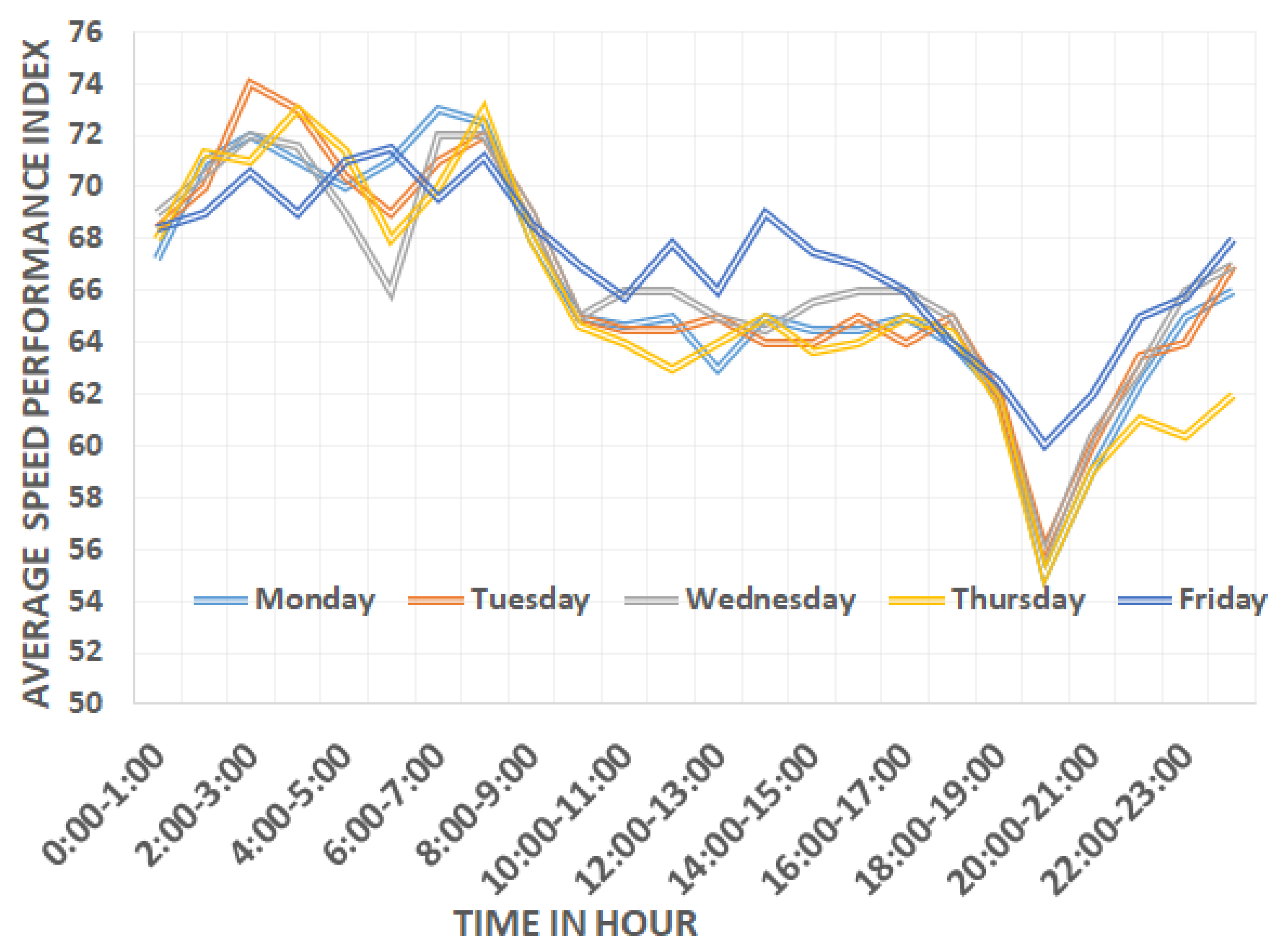
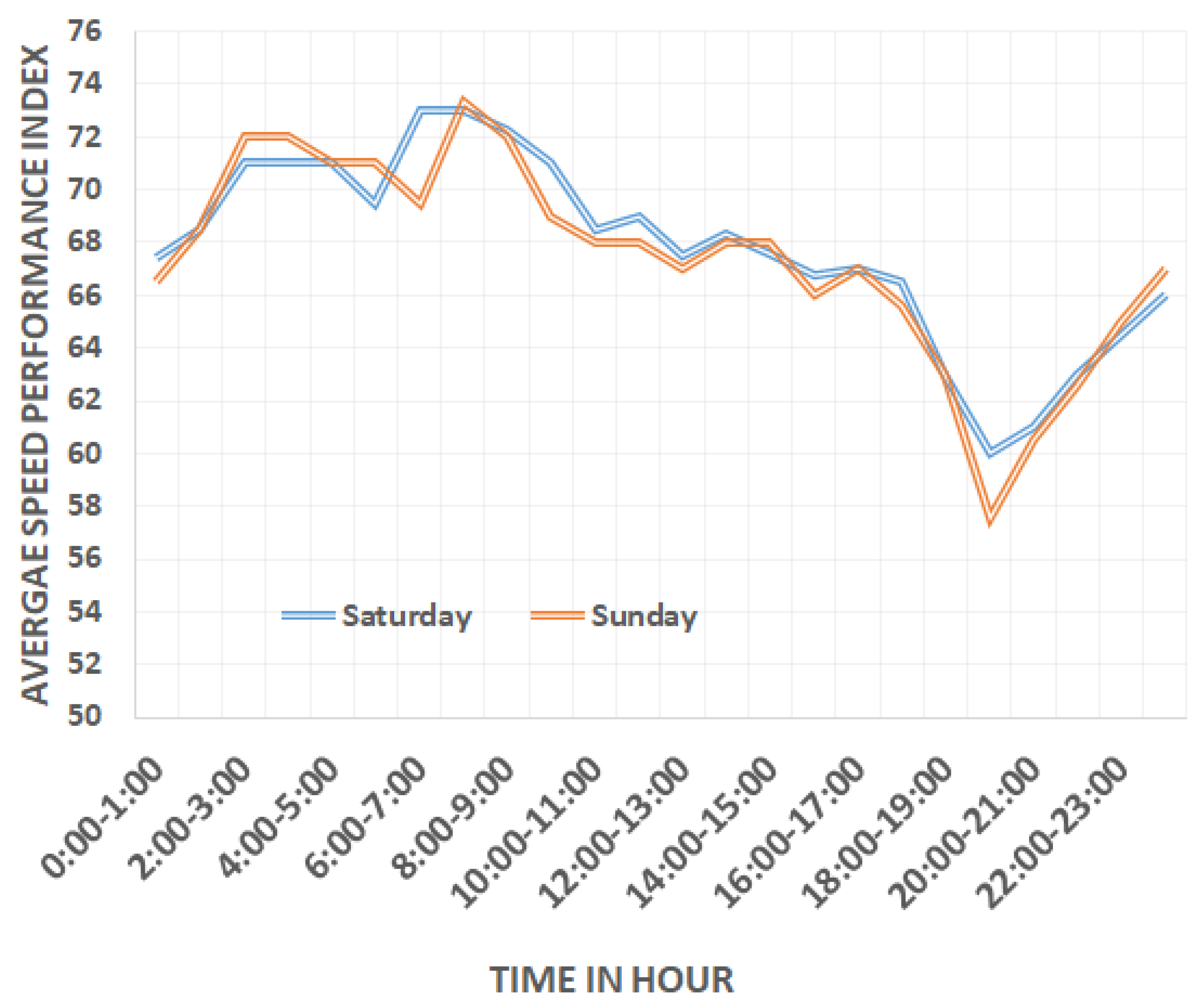
4.1. Exploratory Data Analysis
- = the current speed for the road segment;
- = the permissible max speed for the road segment.
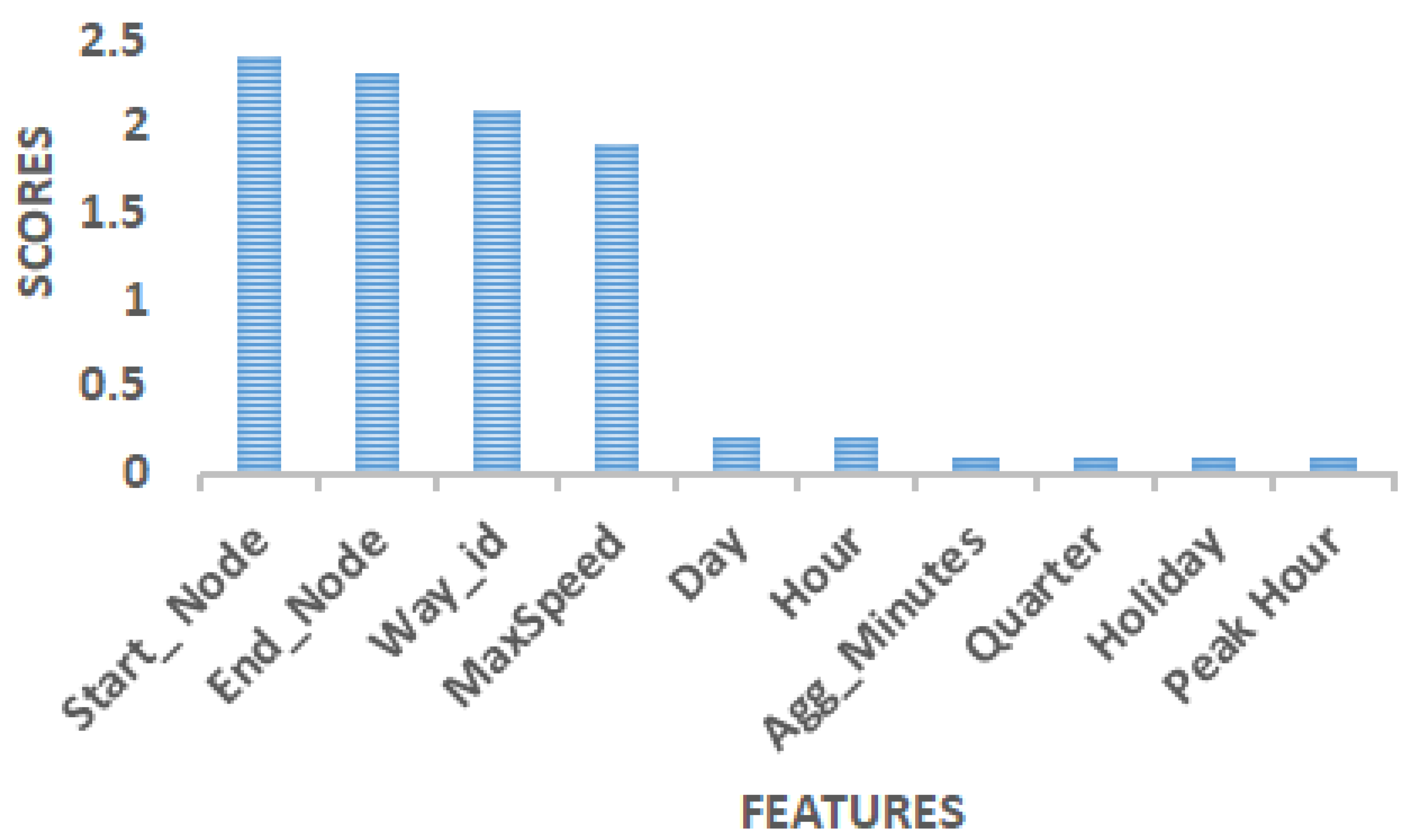
4.2. Feature Selection
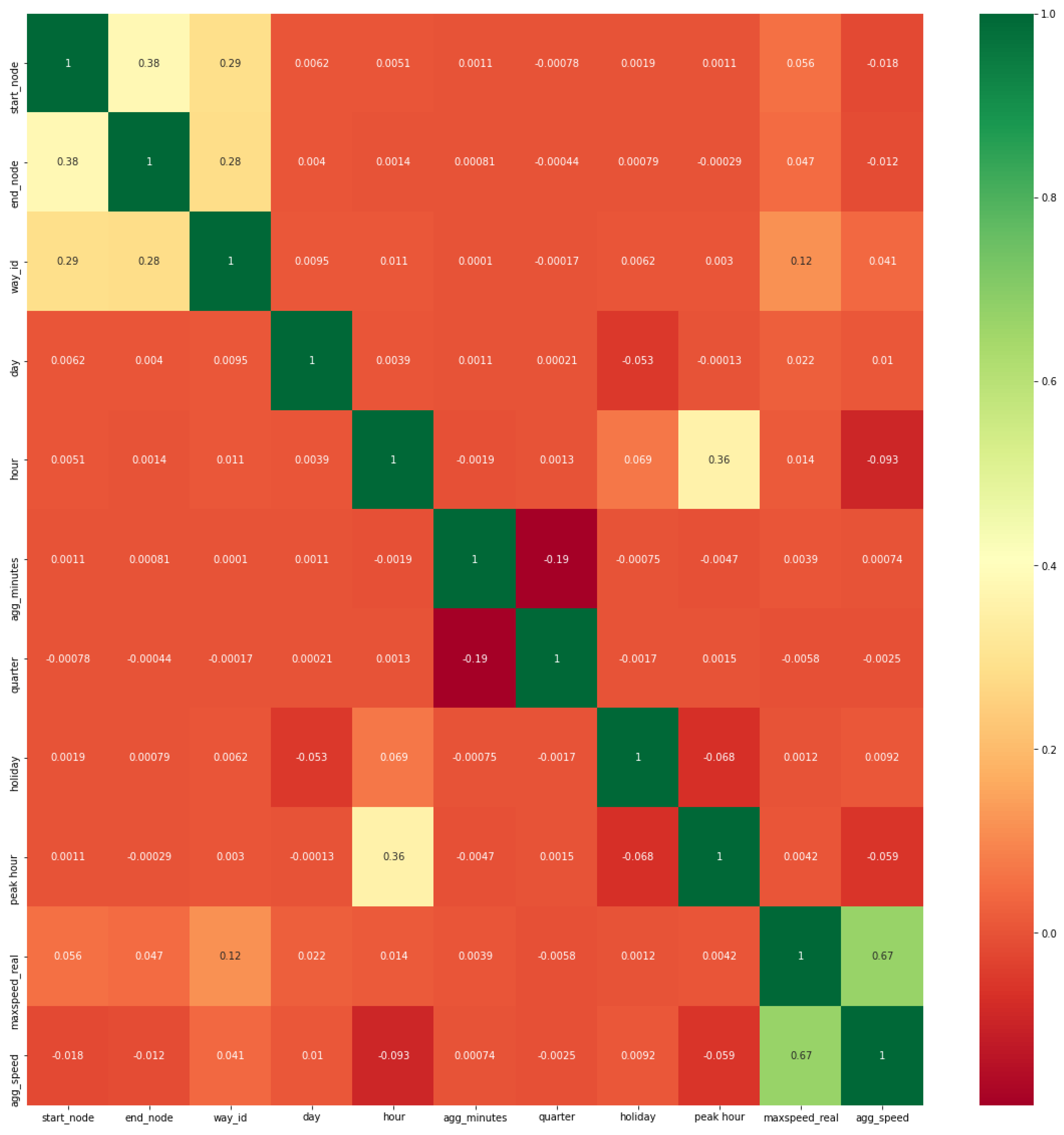
4.2.1. Correlation Feature Selection Technique
- = feature of in hybrid data set.
- j = is a variable.
- = mean of the feature of hybrid data set.
- W = feature of W in hybrid data set.
- = mean of the W feature of hybrid data set.
- = Standard deviation of .
- = Standard deviation of W.
4.2.2. Mutual Information Regression Feature Selection Technique
4.2.3. Heat Map of Hybrid Feature Space
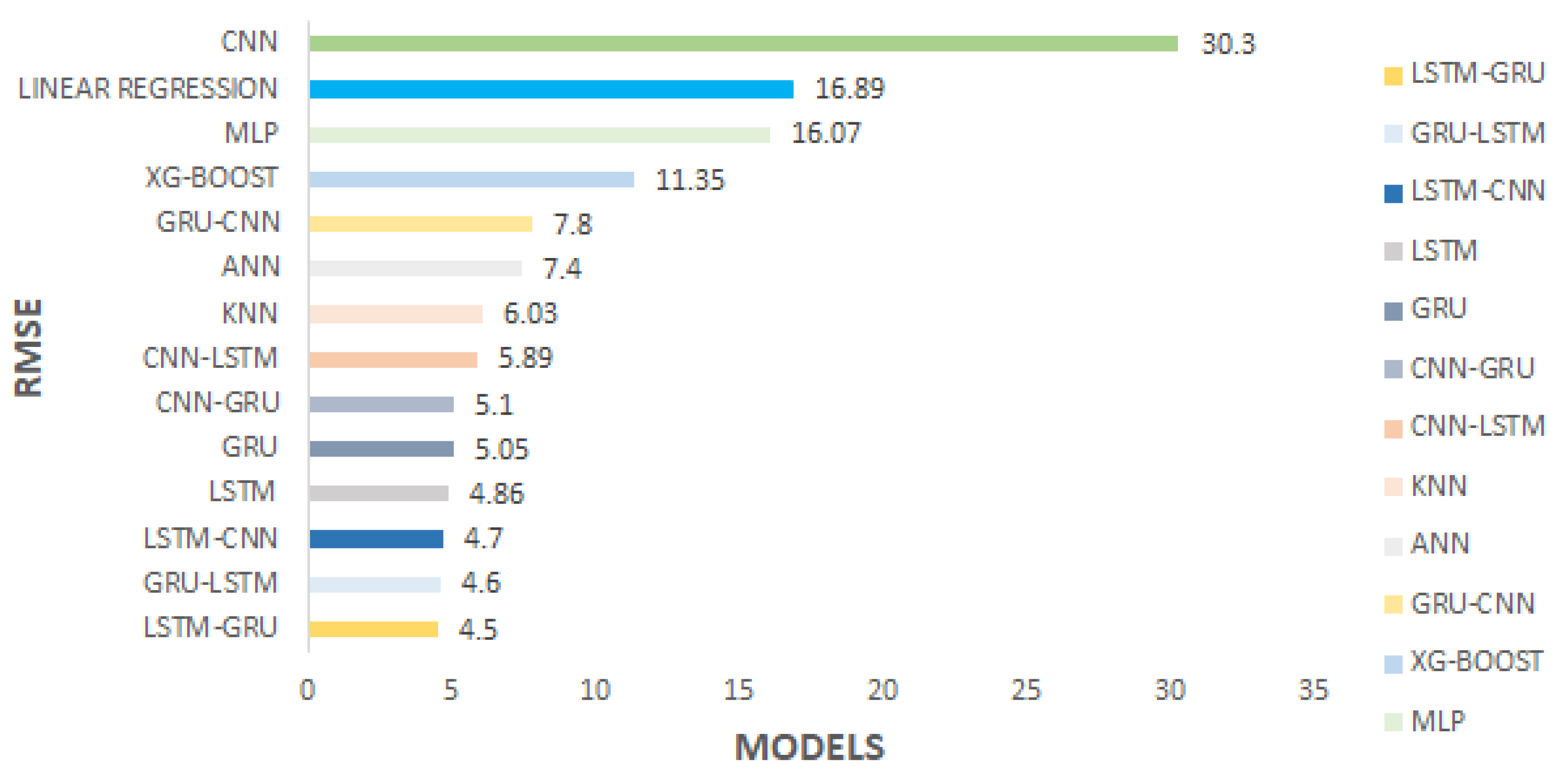
4.3. Hybrid LSTM–GRU Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salanova Grau, J.M.; Mitsakis, E.; Tzenos, P.; Stamos, I.; Selmi, L.; Aifadopoulou, G. Multisource data framework for road traffic state estimation. J. Adv. Transp. 2018, 2018, 9078547. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Chen, H.; Han, Y.; Cheng, T.; Zhang, Y.; Chen, G. A hybrid integrated deep learning model for the prediction of citywide spatio-temporal flow volumes. Int. J. Geogr. Inf. Sci. 2020, 34, 802–823. [Google Scholar] [CrossRef]
- Aitkenhead, M.; Cooper, R. Neural network time series prediction of environmental variables in a small upland headwater in NE Scotland. Hydrol. Process. Int. J. 2008, 22, 3091–3101. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Song, H.; Liu, A. Big data orchestration as a service network. IEEE Commun. Mag. 2017, 55, 94–101. [Google Scholar] [CrossRef]
- Yi, H.; Bui, K.H.N. An automated hyperparameter search-based deep learning model for highway traffic prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5486–5495. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Zou, Y.; Zhang, W.; Wang, Y. An improved fuzzy neural network for traffic speed prediction considering periodic characteristic. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2340–2350. [Google Scholar] [CrossRef]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Bratsas, C.; Koupidis, K.; Salanova, J.M.; Giannakopoulos, K.; Kaloudis, A.; Aifadopoulou, G. A comparison of machine learning methods for the prediction of traffic speed in urban places. Sustainability 2020, 12, 142. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Ma, W.; Pi, X.; Qian, S. A deep learning approach to real-time parking occupancy prediction in transportation networks incorporating multiple spatio-temporal data sources. Transp. Res. Part C Emerg. Technol. 2019, 107, 248–265. [Google Scholar] [CrossRef]
- Impedovo, D.; Dentamaro, V.; Pirlo, G.; Sarcinella, L. TrafficWave: Generative deep learning architecture for vehicular traffic flow prediction. Appl. Sci. 2019, 9, 5504. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lin, H.; Wan, J.; Ma, Z.; Wang, H. MF-TCPV: A Machine Learning and Fuzzy Comprehensive Evaluation-Based Framework for Traffic Congestion Prediction and Visualization. IEEE Access 2020, 8, 227113–227125. [Google Scholar] [CrossRef]
- Chen, X.M.; Zahiri, M.; Zhang, S. Understanding ridesplitting behavior of on-demand ride services: An ensemble learning approach. Transp. Res. Part C Emerg. Technol. 2017, 76, 51–70. [Google Scholar] [CrossRef]
- Candel, A.; Parmar, V.; LeDell, E.; Arora, A. Deep Learning with H2O; H2O.ai Inc.: Mountain View, CA, USA, 2016. [Google Scholar]
- Fang, M.; Tang, L.; Yang, X.; Chen, Y.; Li, C.; Li, Q. FTPG: A Fine-Grained Traffic Prediction Method With Graph Attention Network Using Big Trace Data. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Zhang, S.; Li, S.; Li, X.; Yao, Y. Representation of traffic congestion data for urban road traffic networks based on pooling operations. Algorithms 2020, 13, 84. [Google Scholar] [CrossRef] [Green Version]
- Tan, H.; Wu, Y.; Shen, B.; Jin, P.J.; Ran, B. Short-term traffic prediction based on dynamic tensor completion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2123–2133. [Google Scholar] [CrossRef]
- Shin, D.H.; Chung, K.; Park, R.C. Prediction of Traffic Congestion Based on LSTM Through Correction of Missing Temporal and Spatial Data. IEEE Access 2020, 8, 150784–150796. [Google Scholar] [CrossRef]
- Liu, H.; Xu, H.; Yan, Y.; Cai, Z.; Sun, T.; Li, W. Bus arrival time prediction based on LSTM and spatial-temporal feature vector. IEEE Access 2020, 8, 11917–11929. [Google Scholar] [CrossRef]
- Xu, H.; Ying, J. Bus arrival time prediction with real-time and historic data. Clust. Comput. 2017, 20, 3099–3106. [Google Scholar] [CrossRef]
- Servos, N.; Liu, X.; Teucke, M.; Freitag, M. Travel Time Prediction in a Multimodal Freight Transport Relation Using Machine Learning Algorithms. Logistics 2020, 4, 1. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Li, M.; Lin, X.; Wang, Y.; He, F. Multistep speed prediction on traffic networks: A deep learning approach considering spatio-temporal dependencies. Transp. Res. Part C Emerg. Technol. 2019, 105, 297–322. [Google Scholar] [CrossRef]
- Bogaerts, T.; Masegosa, A.D.; Angarita-Zapata, J.S.; Onieva, E.; Hellinckx, P. A graph CNN-LSTM neural network for short and long-term traffic forecasting based on trajectory data. Transp. Res. Part C Emerg. Technol. 2020, 112, 62–77. [Google Scholar] [CrossRef]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A spatiotemporal correlative k-nearest neighbor model for short-term traffic multistep forecasting. Transp. Res. Part C Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Zhang, K.; Zheng, L.; Liu, Z.; Jia, N. A deep learning based multitask model for network-wide traffic speed prediction. Neurocomputing 2020, 396, 438–450. [Google Scholar] [CrossRef]
- Kong, F.; Li, J.; Lv, Z. Construction of intelligent traffic information recommendation system based on long short-term memory. J. Comput. Sci. 2018, 26, 78–86. [Google Scholar] [CrossRef]
- Aljawarneh, S.; Aldwairi, M.; Yassein, M.B. Anomaly-based intrusion detection system through feature selection analysis and building hybrid efficient model. J. Comput. Sci. 2018, 25, 152–160. [Google Scholar] [CrossRef]
- Cao, M.; Li, V.O.; Chan, V.W. A CNN-LSTM model for traffic speed prediction. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Essien, A.; Petrounias, I.; Sampaio, P.; Sampaio, S. Improving urban traffic speed prediction using data source fusion and deep learning. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Zhang, T.; Jin, J.; Yang, H.; Guo, H.; Ma, X. Link speed prediction for signalized urban traffic network using a hybrid deep learning approach. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2195–2200. [Google Scholar]
- Asif, M.T.; Dauwels, J.; Goh, C.Y.; Oran, A.; Fathi, E.; Xu, M.; Dhanya, M.M.; Mitrovic, N.; Jaillet, P. Spatiotemporal patterns in large-scale traffic speed prediction. IEEE Trans. Intell. Transp. Syst. 2013, 15, 794–804. [Google Scholar] [CrossRef] [Green Version]
- Ye, Q.; Szeto, W.Y.; Wong, S.C. Short-term traffic speed forecasting based on data recorded at irregular intervals. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1727–1737. [Google Scholar] [CrossRef] [Green Version]
- Yao, B.; Chen, C.; Cao, Q.; Jin, L.; Zhang, M.; Zhu, H.; Yu, B. Short-term traffic speed prediction for an urban corridor. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 154–169. [Google Scholar] [CrossRef]
- Li, J.; Guo, F.; Sivakumar, A.; Dong, Y.; Krishnan, R. Transferability improvement in short-term traffic prediction using stacked LSTM network. Transp. Res. Part C Emerg. Technol. 2021, 124, 102977. [Google Scholar] [CrossRef]
- Mena-Oreja, J.; Gozalvez, J. A Comprehensive Evaluation of Deep Learning-Based Techniques for Traffic Prediction. IEEE Access 2020, 8, 91188–91212. [Google Scholar] [CrossRef]
- Yu, D.; Liu, C.; Wu, Y.; Liao, S.; Anwar, T.; Li, W.; Zhou, C. Forecasting short-term traffic speed based on multiple attributes of adjacent roads. Knowl.-Based Syst. 2019, 163, 472–484. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, B.; Zhu, Y. Short-term traffic speed forecasting based on attention convolutional neural network for arterials. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 999–1016. [Google Scholar] [CrossRef]
- Zafar, N.; Ul Haq, I. Traffic congestion prediction based on Estimated Time of Arrival. PloS ONE 2020, 15, e0238200. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Song, Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [PubMed]
- Seber, G.; Lee, A. Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Zaccone, G.; Karim, M.R.; Menshawy, A. Deep Learning with TensorFlow; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Albawi, S.; Mohammed, T.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference On Engineering And Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- George, S.; Santra, A. An improved long short-term memory networks with Takagi-Sugeno fuzzy for traffic speed prediction considering abnormal traffic situation. Comput. Intell. 2020, 36, 964–993. [Google Scholar] [CrossRef]
- Weisstein, E. Hyperbolic Functions. 2003. Available online: https://mathworld.wolfram.com/ (accessed on 1 October 2021).
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In Proceedings of the International Workshop On Artificial Neural Networks, Perth, Western Australia, 27 November–1 December 1995; pp. 195–201. [Google Scholar]
- Sunny, M.; Maswood, M.; Alharbi, A. Deep Learning-Based Stock Price Prediction Using LSTM and Bi-Directional LSTM Model. In Proceedings of the 2020 2nd Novel Intelligent And Leading Emerging Sciences Conference (NILES), Giza, Egypt, 24–26 October 2020; pp. 87–92. [Google Scholar]
- Zhang, R.; Bai, L.; Zhang, J.; Tian, L.; Li, R.; Liu, Z. Convolutional LSTM networks for vibration-based defect identification of the composite structure. In Proceedings of the 2020 International Conference On Sensing, Measurement & Data Analytics In The Era Of Artificial Intelligence (ICSMD), Xi’an, China, 15–17 October 2020; pp. 390–395. [Google Scholar]
- Hyndman, R.; Koehler, A. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Chai, T.; Draxler, R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Zhang, Q. Quality Assessment of Speckle Patterns by Estimating RMSE. In International Digital Imaging Correlation Society; Springer: New York, NY, USA, 2017; pp. 71–74. [Google Scholar]
- He, F.; Yan, X.; Liu, Y.; Ma, L. A traffic congestion assessment method for urban road networks based on speed performance index. Procedia Eng. 2016, 137, 425–433. [Google Scholar] [CrossRef] [Green Version]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Ponomarev, S.; Dur, J.; Wallace, N.; Atkison, T. Evaluation of random projection for malware classification. In Proceedings of the 2013 IEEE Seventh International Conference On Software Security And Reliability Companion, Gaithersburg, MD, USA, 18–20 June 2013; pp. 68–73. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nature of Attributes | Data Type |
|---|---|
| Day | integer |
| Hour | integer |
| Startnode | integer |
| Endnode | integer |
| aggminutes | 15 min time interval |
| Weather | char |
| maxspeed-real | integer |
| aggSpeed | integer |
| Holiday | boolean |
| Model | Hyperparameters | Values |
|---|---|---|
| XGBOOST | objective | linear |
| n-estimators | 4000 | |
| ANN | input dimension | 10 |
| activation function | relu | |
| loss function | RMSE | |
| optimizere | adam | |
| epoch | 100 | |
| batch-size | 512 | |
| KNN | K | 20 |
| loss | RMSE | |
| MLP | activation function | relu |
| loss function | RMSE | |
| hidden-layer-size | 100 | |
| optimizer | SGD | |
| learning rate | 0.001 | |
| LSTM-GRU | Batch Size | 512 |
| Learning Rate | 0.001 | |
| No of epochs | 10 | |
| No of Hidden Layers | 04 | |
| Hidden Units | 256 | |
| Dropout Ratio | 0.2 | |
| Activation Function | tanh | |
| Output-Units | 1 | |
| Output-Type | Single Label | |
| Output-Layer-Activation-Function | linear | |
| Optimizer | Adam | |
| Loss Function | mean squared error |
| Features | Scores |
|---|---|
| 14,218.665540 | |
| 52.788980 | |
| 19,974.123749 | |
| 487.561578 | |
| 24,238.112125 | |
| 0.380622 | |
| 25.339737 | |
| 620.959742 | |
| 9876.836458 | |
| 3,227,692.593161 |
| Model | RMSE | MAE | MAPE |
|---|---|---|---|
| 4.86 | 2.13 | 6.95 | |
| 5.05 | 2.29 | 7.7 | |
| 30.3 | 25.96 | 64.10 | |
| 4.7 | 23.9 | 7.9 | |
| 5.89 | 3.53 | 11.47 | |
| 4.6 | 2.08 | 6.85 | |
| 4.5 | 2.03 | 6.67 | |
| 5.1 | 2.4 | 8.4 | |
| 7.8 | 4.5 | 14.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zafar, N.; Haq, I.U.; Chughtai, J.-u.-R.; Shafiq, O. Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas. Sensors 2022, 22, 3348. https://doi.org/10.3390/s22093348
Zafar N, Haq IU, Chughtai J-u-R, Shafiq O. Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas. Sensors. 2022; 22(9):3348. https://doi.org/10.3390/s22093348
Chicago/Turabian StyleZafar, Noureen, Irfan Ul Haq, Jawad-ur-Rehman Chughtai, and Omair Shafiq. 2022. "Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas" Sensors 22, no. 9: 3348. https://doi.org/10.3390/s22093348
APA StyleZafar, N., Haq, I. U., Chughtai, J. -u. -R., & Shafiq, O. (2022). Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas. Sensors, 22(9), 3348. https://doi.org/10.3390/s22093348