1. Introduction
With the advent of the 5G era, the demand and application of mobile traffic and wireless networks have increased dramatically. This huge demand has driven the convergence of multiple traditional and emerged communications technologies to form the 5G mobile communications system. 5G mobile communication systems employ new technologies and new network architectures that enable them to go beyond traditional communications and meet the needs of different types of devices and users [
1]. As defined by the International Telecommunication Union (ITU), 5G mobile communication system considers three common scenarios with specific service requirements: eMBB, mMTC, and URLLC [
2,
3,
4]. EMBB is a scenario with ultra-high transmission data rate and mobility guarantee under wide coverage, it helps ensure consistent user experience [
5], mMTC mainly deals with the scalable connectivity to a massive number of MTC devices and sensors with diverse quality of service (Qos) requirements [
6]. URLLC is mainly faced with application scenarios with latency-sensitive and high-reliability requirements for delay and reliability [
7]. With NS techniques, a 5G network can be divided into multiple logical networks on a separate physical network for services with different requirements. The origin of NS technology can be traced back to the infrastructure as a service (IAAs) cloud computing model [
8]. With this model, different tenants can share the compute resources, network resources, and storage resources, thus creating different isolated and fully functional virtual networks on a common infrastructure. NS manages physical and virtual resources based on emerging technologies such as software defined network (SDN) and network function virtualization (NFV), so that they can be provided to specific services [
9,
10,
11], enabling 5G networks to provide different types of services to customers with different needs [
12,
13], and the network slice assumes a static resource pool for each slice to ensure the performance isolation between different types of slices [
13,
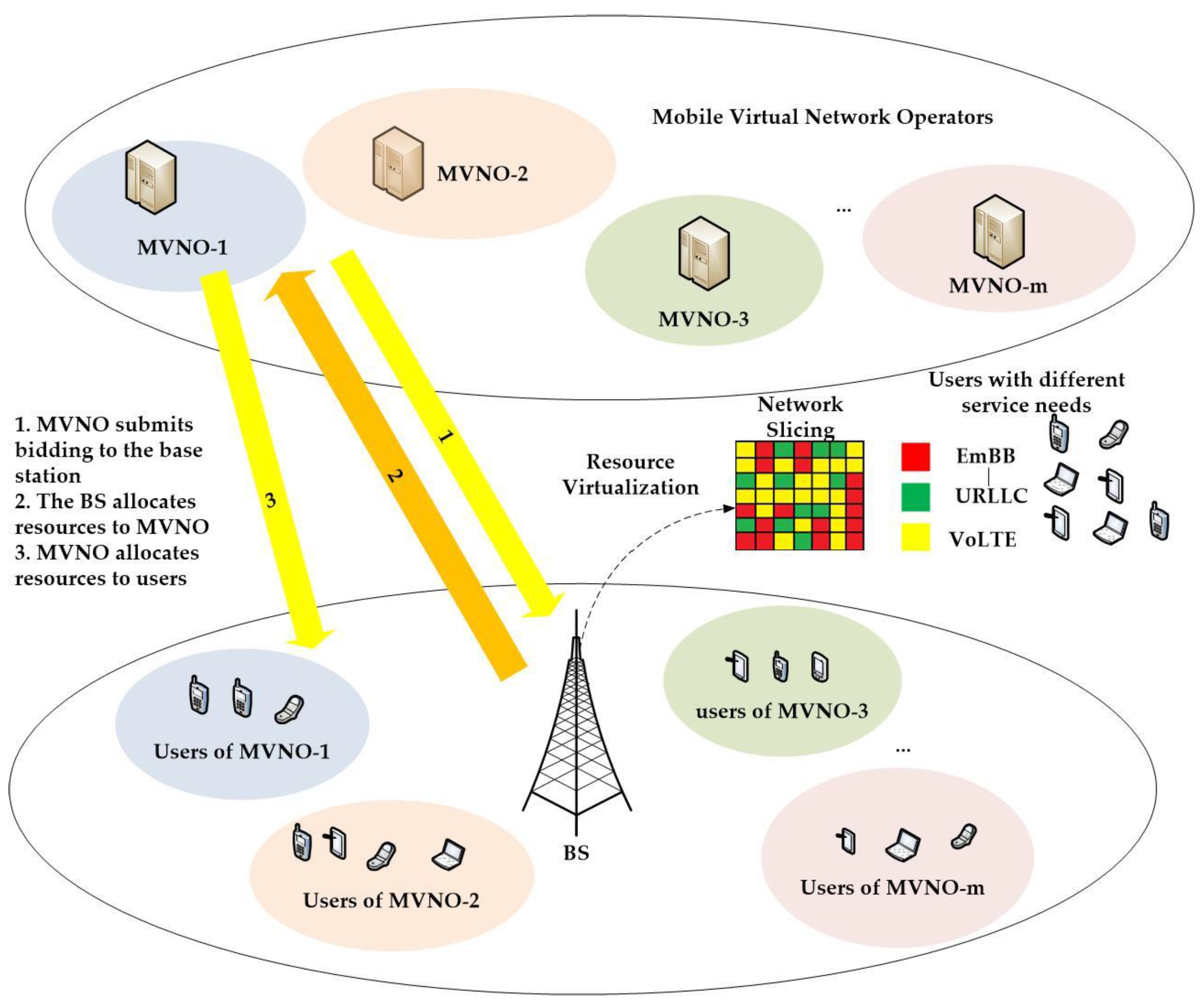
14]. Wireless NS technology divides the existing mobile network operators (MNOs) into two functionally distinct entities: InPs and MVNOs. Each InPs has a certain physical wireless network, including physical infrastructure and physical resources [
15]. MVNOs divide the physical wireless network under their own InPs to get each MVNOs exclusive virtual wireless network and rent the physical resources owned by the InPs to provide specific services or meet specific service demands for their own MUs. In this way, the sharing of physical resources can effectively reduce operating expenses and enable more flexible network operations. Additionally, resources allocated to their own MUs must meet strict service level agreements (SLAs). And in resource allocation, the actual needs of users are often determined by the way they request [
16].
In the actual network resource allocation problem, users’ statuses are often fluctuating, and operators are not aware of parts of users’ information such as channel conditions. Therefore, how MVNO optimally allocates resources for users is a key issue of this research. To solve these optimization problems, recently, some studies have proposed new approaches such as game theory approaches [
17], linear programming approaches [
18], etc. In this paper, we mainly adopt the approach of using DRL combined with bidding to solve such optimization problems. For this optimization problem of resource allocation, many algorithms have been proposed in the literature in recent years. In this paper, some algorithms (some heuristic algorithms) are considered when selecting algorithms. Due to their own characteristics, they can not guarantee to obtain the global optimal solution when solving the problem that will produce a huge state space, with poor convergence and high complexity, and the setting of parameters during simulation will have a great impact on the experimental results. The optimization problem considered in this paper has many unknown parameter variables (such as channel state and user information), which produces a huge state space. Fortunately, the emerging DRL is considered a promising technique to solve this complex control problem. Therefore, this paper attempts to use DRL joint bidding to solve the proposed optimization problem. It is found that DRL is very suitable for the scenarios and optimization problems to be considered. Actions with a high matching degree can be set in the environment, and states and rewards can be mapped to DRL, which can be trained to get better strategies. The emerging DRL is considered a promising technique to solve this complex control problem [
19]. Ref. [
20] use a DRL algorithm to solve this optimization problem and get good results. This new intelligent algorithm can learn knowledge that is not available through traditional methods by big data training, and uses trial-and-error search methods to interact dynamically with the environment in real time, which enables unprecedented automation and optimization of resource allocation [
21]. It is also a good approach to treat the resource allocation problem as a resource game issue, which needs to consider the dynamic competing behaviors of users to maximize the overall satisfaction of users [
22].
At present, a lot of research work has been done based on these two methods. Ref. [
23] used an allocation strategy of orthogonal and multiplexed subchannels to ensure the isolation of inter-slice and solved the problem of minimizing system power in the bidirectional transmission link. Ref. [
24] proposed a new auction-based shared resource and revenue optimization model. Ref. [
25] proposed a stochastic game model to solve the dynamic resource allocation problem of multi-user virtual enterprise networks and proposed a blind approximate based great likelihood estimation algorithm to solve the model, thus overcoming the cost of information exchange and computation, but the model does not consider user-specific demands. Ref. [
26] mathematically analyzes the joint optimization of access control and bandwidth allocation for multiple BS and multiple NS scenarios. However, the solution is based on the assumption that different users have the same fixed demand rate, which is unlikely to be found in practice. Ref. [
27] proposed an LSTM-based prediction scheme, and use a power allocation algorithm based on DRL to solve this problem. But in practical scenarios, different types of user demands need to be considered when solving the network resource allocation problem. Ref. [
28] proposed an optimization framework based on a resource pricing strategy to maximize resource efficiency and customer profit by studying the relationship between profit maximization and resource efficiency. Ref. [
29] proposed an AC priority algorithm to meet the high demand and high priority slice to improve the overall resource demand satisfaction rate, ref. [
30] used game theory to analyze the relationship between InPs and users to optimize the allocation problem and solve the communication problem during peak hours. Ref. [
31] used communication games and learning mechanisms to solve the distributed problem of wireless NS resources, but without considering the deployment of users with different types of demand. Ref. [
32] proposed an online resource management for inter-slice genetic slicing policy optimizer, but it ignores the relationship between the required resources on the different types of slices and the SLA. Ref. [
33] proposed a novel channel information absent Q-learning (CIAQ) algorithm to speed up the training, but this algorithm is only an auxiliary method for solving the resources allocation problem. Reference [
34] considered the problem of allocating different types of resources (bandwidth, cache, backhaul capacity) to network service tenants based on user demand and proposed a mathematical solution, but when the simulation parameters are increased proportionally, the optimization problem will become difficult to solve. Ref. [
35] uses a DRL method to control the energy of the UAV scene. Ref. [
36] proposed a DNAF-based DQL merging method that improves the convergence speed of the algorithm. Ref. [
37] proposed an HA-DRL algorithm, that uses heuristic functions to optimize the exploration of action space.
The bidding methods and the DRL methods have been proposed in the above literature to solve the resource allocation problems of BS to different users. But some methods do not consider that users are with different specific needs, and the resource allocation to users has the problem of poor service quality or waste of resources for a proportion of users, moreover, some solutions simply consider the service satisfaction rate of users and ignore the total bandwidth of BS. Some solutions simply consider the user’s service satisfaction rate and ignore the total bandwidth utilization rate of the BS, which also results in the waste of wireless network resources. To solve the challenges and problems mentioned above, this paper proposes a two-tier resource allocation model considering both the BS resource utilization and user service satisfaction rate. In fact, this paper decomposes a single objective optimization problem into two-level sub-objective optimization problems, and creatively uses DRL to solve the two-level resource allocation optimization problem considering the inconsistency between the upper and lower value spaces. The upper tier model is for MVNOs to request resources from the BS by bidding, and this paper uses a combination of bidding and Dueling DQN to solve the optimization problem of this upper tier model. Likewise, the lower tier model is for MVNOs to allocate the resources which are received from the BS to its contained users and set the service satisfaction rate of the users, the same as the upper tier, the lower tier model is optimized using Dueling DQN. The main contributions of this paper are as follows.
(1) First, a two tier resource allocation problem in wireless NS is proposed. The upper tier MVNOs will submit bid prices to the InP for wireless resources. The InP will further allocate physical resources to the MVNOs based on the bid values of the MVNOs. Each MVNO will then use the wireless resources allocated by the network to serve its mobile subscribers.
(2) Second, the algorithm based on Dueling DQN and joint bidding is used to solve the upper tier resource allocation optimization problem. In this paper, the utility of each MVNO is obtained by calculating the downlink transmission rate of the user after obtaining the bandwidth, and the utility function of the whole system is denoted as the weighted sum of the upper tier benefits and the lower layer utility function. This ensures that the BS resources are allocated to the maximum extent possible to meet the service demand of the users more efficiently.
(3) Third, this paper shows the process of mathematical analysis of the proposed two-tier model and algorithm with its corresponding parameters for problem solving, and shows how bidding can be used in conjunction with Dueling DQN with the corresponding parameters. The penalty function is proposed to prevent the MVNO from overbidding, and the evaluation function to represent the revenue of the MVNO. This paper considers a radio access network scenario with multiple users sharing aggregated bandwidth under a single BS, where users are randomly located within the range of the BS and have different service demands, the BS does not have direct access to the channel information and service demand information of the users, and each MVNO manages the users in a sub-region. In future research work, it can take into consideration changes in user location and changes in service demand, in order to get closer to the actual communication scenario.
The rest of the paper consists of the following:
Section 2 presents the two-tier model proposed in this paper with its mathematical analysis process.
Section 3 presents the solution algorithm and the relevant mathematical background, and details the process of corresponding parameters when using the Dueling DQN and DQN algorithm in the two-tier model. The simulation process and results are given in
Section 4, and a comparative analysis is performed.
Section 5 concludes the paper and gives an expectation.
3. DRL-Based Joint Bidding Resource Allocation Algorithm
3.1. Deep Reinforcement Learning
DQN is a typical DRL algorithm, it is advantageous for solving high computational problems and decision problems. In DRL, there will be an agent to control the learning process. The intelligent agent attempts to generate a lot of new data through constant trial-and-error interaction with the environment, and then learns a set of policies based on this data that enables it to maximize the cumulative expected reward while finding the best action for a given state. We can model the agent’s interaction with the environment as a Markov decision process .
The parameters are explained as follows: is the state space containing the current state and the new state ; is the action space containing the current action and the new action ; the policy determines how state is mapped to the action; is the reward function obtained by performing the action under the state according to the policy ; is the transfer probability and is a discount factor.
Additionally, the state value function
can be obtained according to
under the state
.
Similarly, the action value function
obtained by executing the action
under the state
according to the policy
.
The process of interaction between the intelligent body and the environment is as follows: the agent gets an observation as a state
from the environment and inputs
to the neural network to get all
, then uses the ϵ-greedy strategy selects an action and makes a decision from
, and the environment will give a reward and the next observation based on this action. Finally, the agent is updated according to the reward given by the environment using Equation (17).
DQN is based on DL with the addition of neural networks with parameters
for parameter updating and action selection. The Q-value function network is updated in real time and the target Q-value function network is updated every certain number of iterations.
denotes the value function with parameters
, the optimal parameters
will be obtained by minimizing the TD error squared according to Equation (18) to let
.
The target Q-value of the network of target Q-value functions is
Also, the loss function defined in
DQN is
While Dueling DQN improves on the network structure of DQN, Dueling DQN divides the Q value into two parts, one for the state value function, and one for the advantage function, denoted as:
is unconcerned with action a, and only one status value is returned, while
is related to action and state,
can be expressed in more detail as:
The parameters
in the formula are shared by the two function networks, and
and
are their exclusive parameters. In order to increase the identification of the two functions, the dominant function is generally centralized, that is:
3.2. Two Tier Slicing Resource Allocation Algorithm Based on Dueling DQN and Joint Bidding
In actual communication, due to various factors, the channel information and service demands of users are private. In order to better meet the user demand and to maximize the utilization rate of physical resources in the BS, MVNO is added between the BS and users. The MVNOs collect the users’ demand information and channel status, then bid and obtain resources from the BS, finally allocate resources to users connected to it. This paper mapped the above problem to a Markov decision process, uses the framework of bidding for the upper tier model in the allocation process, and uses the DRL for both two tiers to solve the optimization problem, get the optimal solution by iterative training.
Algorithm 1 uses the DQN joint with the framework of bidding to solve the optimization problem for the upper tier model. After initializing the bidding pool
B, the parameters in the neural net within the DQN (such as (
and
N). In the simulation, each MVNO obtains the bidding range to establish a bidding pool
B, the total maximum and minimum demand resources of the users of the MVNO are first estimated, which is represented by the maximum and minimum value of the sum of the expected rates (set by SLA) of all users connected to it. It is used to indicate the maximum rate requirement of each MVNO if the service requirement of each user is the service type with the maximum rate. After converting the rate requirement to the maximum and minimum bid value according to a specific ratio, the bid pool
B can be established. The upper tier uses the bid pool
B as the action space, and the maximum lower tier action corresponding to each upper tier action is found in the lower tier and stored in table
A.
| Algorithm 1 DQN and Joint Bidding Algorithm for Upper Tier Bandwidth Allocation |
| 1: | Initialize the Bidding pool B of MVNO and corresponding lower tier action selection table A; |
| 2: | Initialize the action-value function , target action-value function the replay memory D to capacity N |
| 3: | Each MVNO estimates the maximum total needed rate and minimum total needed
rate of linked users, then create the Bidding pool B; |
| 4: | For in B do |
| 5: |
Find the lower tier optimal allocation action and store it in table A; |
| 6: | end for |
| 7: | Random choose an action i.e., bidding value and BS distributes to each MVNO according to (2); |
| 8: | Repeat |
| 9: |
For t = 1, to T, do |
| 10: | Calculate the ratio of the allocated bandwidth to its required minimum rate, and take it as the current state S = s of the last iteration; |
| 11: | For m = 1 to M, do |
| 12: |
Each MVNO m allocates optimal bandwidth to its users according to table A; |
| 13: |
Each MVNO m calculates the by (9) and (10); |
| 14: |
Each MVNO m calculates the penalty by (4); |
| 15: |
Each MVNO m and calculates the profit by (3) and get the reward ; |
| 16: |
End for |
| 17: | Calculate the total system utility F according to (5); |
| 18: | Calculate the total reward r; |
| 19: | Choose an action i.e., bidding value according to the policy of DQN; |
| 20: | InP distributes to each MVNO according to (2); |
| 21: | Get the state S = s’ after the selection action of this iteration; |
| 22: | #Train DQN |
| 23: | The agent i.e., each MVNO inputs into the DQN; |
| 24: | The agent stores transition in D; |
| 25: | The agent sample random minibatch of transitions from D; |
| 26: | Set |
| 27: | The agent perform a gradient descent step on with respect to the network parameters θ; |
| 28: | Every steps reset ; |
| 29: |
End for |
| 30: | Until The predefined maximum number of iterations has been completed. |
Before starting the iteration, an upper tier action needs to be randomly selected to generate the initial state. The components of the iteration process include: getting the current state , selecting the action according to the policy in the current state and generating the state , calculating the utility function , and calculating the reward . At the beginning of each iteration, the current state is available. In combination with the DQN algorithm, the actions in each iteration are selected according to the DQN policy, the ϵ-greedy policy, randomly selected an action or selected a better action according to . The action of each iteration contains the bids of each MVNO in this iteration . The InP receives the bids from MVNOs and divides the bandwidth resources proportionally to each MVNO bandwidth according to Equation (2). Each MVNO will allocate bandwidth to each user and count the rate sum of each user, each MVNO can get the ratio of the allocated bandwidth to its required minimum rate, and take it as the next state . The MVNO also constructs an action space when allocating bandwidth to users, and the optimal lower-tier action corresponding to each upper-tier action can be found based on table A. Then, the MVNO derives a discount function from Equation (4) and calculates the profit value in this iteration from Equation (3) based on the sum of and . When all MVNOs in this iteration have performed the above actions, the total utility function and the total reward of the system in this iteration is counted.
Finally, the , , and generated by this iteration are input into the DQN and trained. In DQN, the agent stores the transition of each iteration into the experience pool , then takes a small random transition from the experience pool for training the parameters of the Q-value net, finally updates the parameters of the target Q-value net by the loss function .
Algorithm 2 uses the Dueling DQN algorithm to solve the optimization problem of the lower-level model. As in Algorithm 1, the parameters (
, and
N) in the Dueling DQN neural network are first initialized and each MVNO creates its lower tier action space
after receiving the resources
allocated from the BS. Before each iteration, each MVNO will randomly select an action
from its lower action space and execute it. The action
first divides its resources into resource blocks for three services, then allocates resources
to users which are connected to it, then count the number of packets successfully received
by the user and denote it as state
. Then start the iteration, the agent i.e., MVNO will get the current state
, and choose an action
according to the policy of the Dueling DQN policy, the ϵ-greedy policy, randomly selects an action or selected a better action according to
, after the allocation process, MVNO counts the state
, utility function
and reward
, finally, input the
into the Dueling DQN and train the neural network until the predefined maximum number of iterations has been completed.
| Algorithm 2 Dueling DQN Algorithm for Lower Tier Bandwidth Allocation |
| 1: | Initialize the action-value function , target action-value function the replay memory D to capacity N |
| 2: | Each MVNO receives a bandwidth from the BS; |
| 3: | Each MVNO creates an action space ; |
| 4: | Form = 1 to M, do |
| 5: | MVNO randomly chooses an action and performs ; |
| 6: | MVNO allocates the bandwidth to users which are connected with it; |
| 7: | Calculate the as state ; |
| 8: | For t = 1, to T, do |
| 9: | The agent gets the current state ; |
| 10: | Choose an action according to the policy of Dueling DQN; |
| 11: | Calculate the total system utility according to (15); |
| 12: | Calculate the total reward; |
| 13: | The agent allocates the bandwidth to users and calculates the state after the selection action of this iteration as ; |
| 14: | #Train Dueling DQN |
| 15: | The agent i.e., each MVNO inputs into the Dueling DQN; |
| 16: | The agent store transition in D; |
| 17: | The agent sample random minibatch of transitions from D; |
| 18: | Set |
| 19: | The agent perform a gradient descent step on with respect to the network parameters θ, and ; |
| 20: | Every steps reset ; |
| 21: | End for |
| 22: | End for |
4. Simulation Results and Discuss
Compared with the latest published literature in recent years, as
Table 1, this paper considers the sliced bandwidth resources as a two tier resource allocation process, and ensures the service quality of users’ multiple service requirements. Through the simulation, we get good results by using the DRL joint bidding.
4.1. Simulation Parameters
In the scenario considered in this paper, the maximum aggregated bandwidth provided by a single BS is 10 MHz, and the minimum specification of the bandwidth resource block is set to
= 0.2 MHz, three types of services (i.e., VoLTE, eMBB, and URLLC) and four MVNOs are provided to the subscribers, and 100 registered subscribers are randomly present within an approximate circle of 40 m radius around the BS. The transmission power of the users is 20 dBm, and the transmit power of the BS is 46 dBm. The noise spectral density of the channel is −174 dBm/Hz under the given channel model. The minimum rate constraint for VoLTE service is 51 kbs, the minimum rate constraint for eMBB service is 0.1 Gb/s, and the minimum rate constraint for URLLC service is 0.01 Gb/s. The detailed simulation parameters are shown in the following
Table 2.
The simulation sets up 100 users randomly distributed in a single BS coverage area, and the users have three different service demand types (i.e., VoLTE, eMBB, and URLLC), and the service demand of each user is also random. An MVNO is set up to pre-allocate the BS resources between the BS and the users, and the users are connected to different MVNOs according to their locations. To demonstrate the feasibility and advantages of the proposed resource allocation algorithm, the following work is carried out in this paper.
Firstly, the proposed model based on bidding and a two tier Dueling DQN algorithm is simulated through the python platform and simulated with a Double DQN algorithm, DQN algorithm. and Q-Learning algorithm. After getting the data of the four algorithms plotted graphs and comparing, it is concluded that the algorithm proposed in this paper is feasible and has some advantages over the other three algorithms in this paper. The following is the curve and comparative analysis after plotting some data obtained from this simulation.
In the process of simulation for the training network parameters set the reward is calculated as:
The upper tier reward = 4 + (SE − 230) * 0.1 + (profit − 185) * 0.1 (if the Qoe of eMBB ≥ 0.975, the Qoe of Volte ≥ 0.98, the Qoe of URLLC ≥ 0.95, the SE ≥ 220 and the profit ≥ 185). In the preceding conditions, if SE is not satisfied, the reward = 4; if profit is larger than 170 but also not satisfied the conditions, the reward = (the Qoe of URLLC − 0.7) * 10; and if the Qoe of URLLC also not satisfied, reward = (the Qoe of URLLC − 0.7) * 6; if just satisfied the first condition, reward = 0, and if each condition is no satisfied, reward = −5.
The lower tier rewards are a bit simpler to set up and are part of the rewards that consist of the upper tier: reward = 4 + (SE − 280) * 0.1 (if the Qoe of eMBB ≥ 0.96, the Qoe of Volte ≥ 0.98, the Qoe of URLLC ≥ 0.95, the SE ≥ 280); reward = 4 (if SE not satisfied); reward = (the Qoe of URLLC − 0.7) * 10(if the Qoe of URLLC is not satisfied); reward = −5 (if each conditions is not satisfied).
In particular, in the upper model, we evaluated the method of joint bidding of Doble DQN and Dueling DQN, and compared it with the results of traditional DQN, Double DQN, Dueling DQN, and Q-learning. In the experiment, the learning rates of various algorithms are set to 0.01. And the importance weight of the optimization objective obtained by formula (6) and formula (15) is set to , , . The learning rate of the Dueling DQN network is set to 0.01, and the choice of Gama value was experimentally set to 0.95.
In the whole simulation process, 100 user locations are randomly distributed, with the BS location as the origin, and 4 MVNOs manage four areas, respectively, and collect their service demands. In this paper, as
Table 3, the service types of the users connected by MVNO-0 include 11 eMBB services, 9 VoLTE services, and 7 URLLC services; the service types of the users connected by MVNO-1 include 11 eMBB services, 8 VoLTE services, and 7 URLLC services; the service types of the users connected by MVNO-2 include 8 eMBB services, 6 VoLTE services, and 13 URLLC services. 6 VoLTE services and 13 URLLC services; MVNO-3 connected users’ service types include 2 eMBB services, 8 VoLTE services, and 7 URLLC services.
4.2. Simulation Results and Discuss
The resource allocation algorithm based on bidding and two-tier DRL proposed in this paper is divided into two tiers.
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show the optimization curves of the QoE of three types of services and SE using the proposed algorithm in the lower tier.
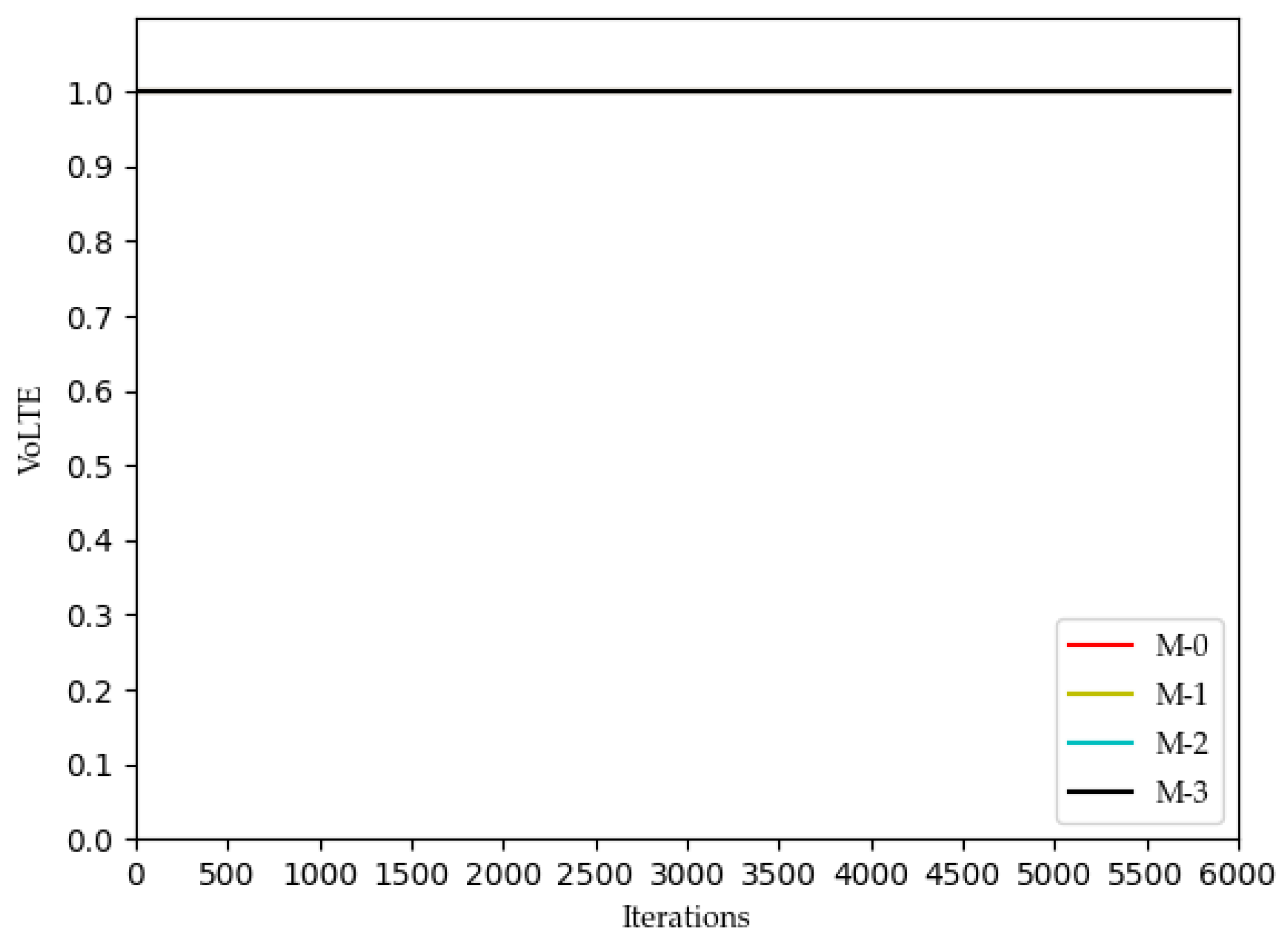
We can see from
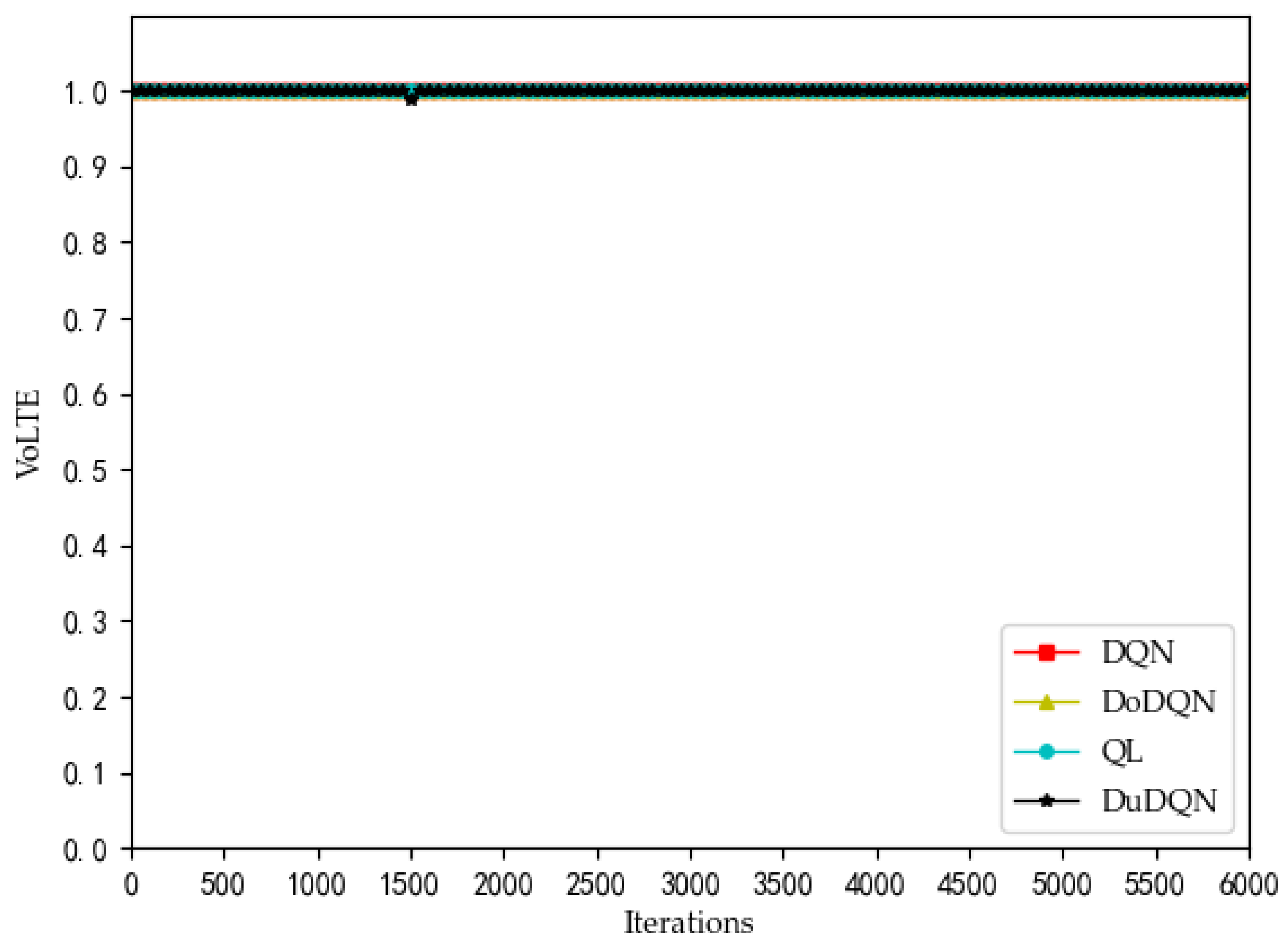
Figure 2 that the QoE of VoLTE service reaches 1 without optimization, because the required rate requirement is very small (51 kbs). Providing a small part of the bandwidth for this service can meet its requirements. From
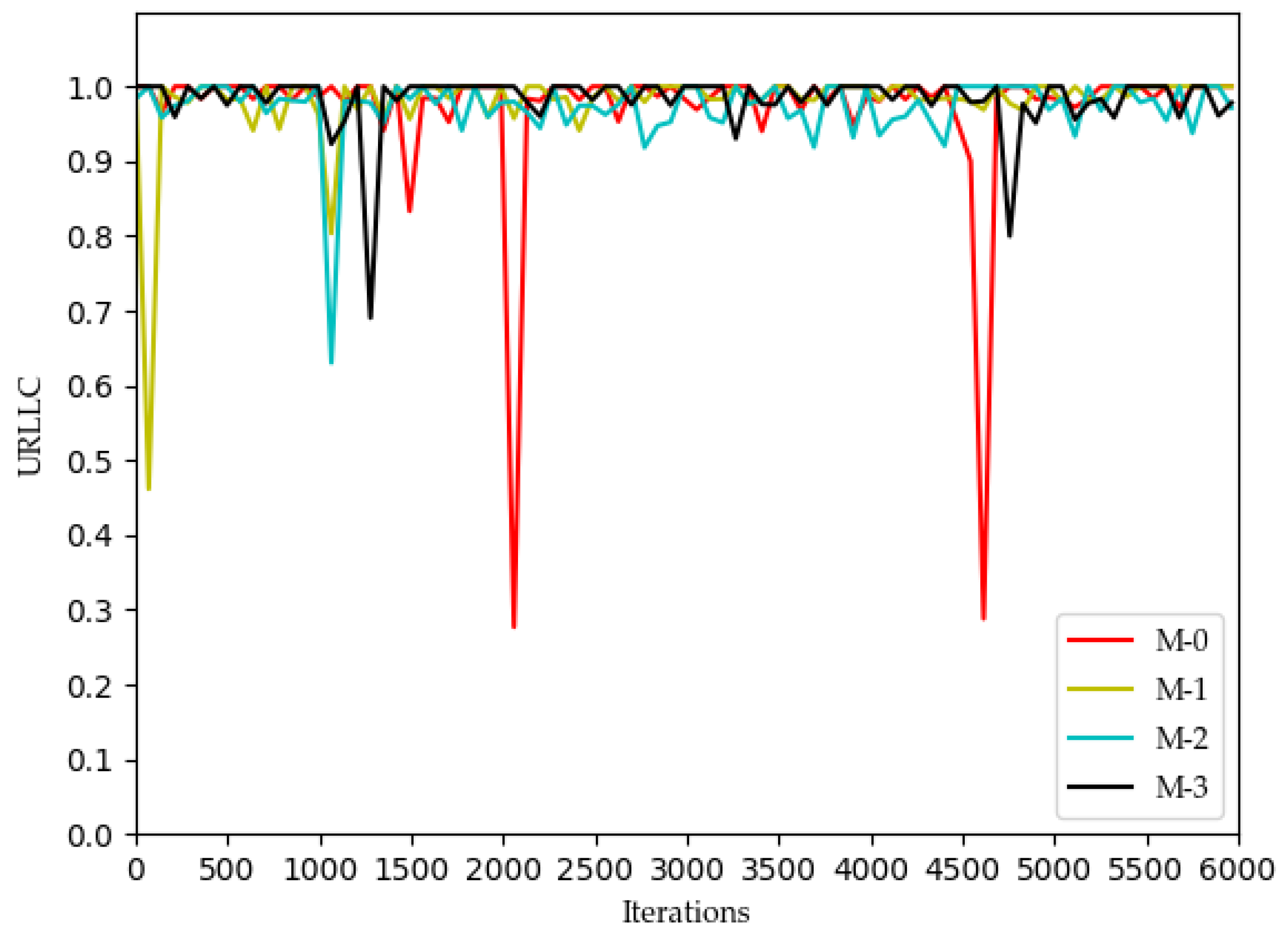
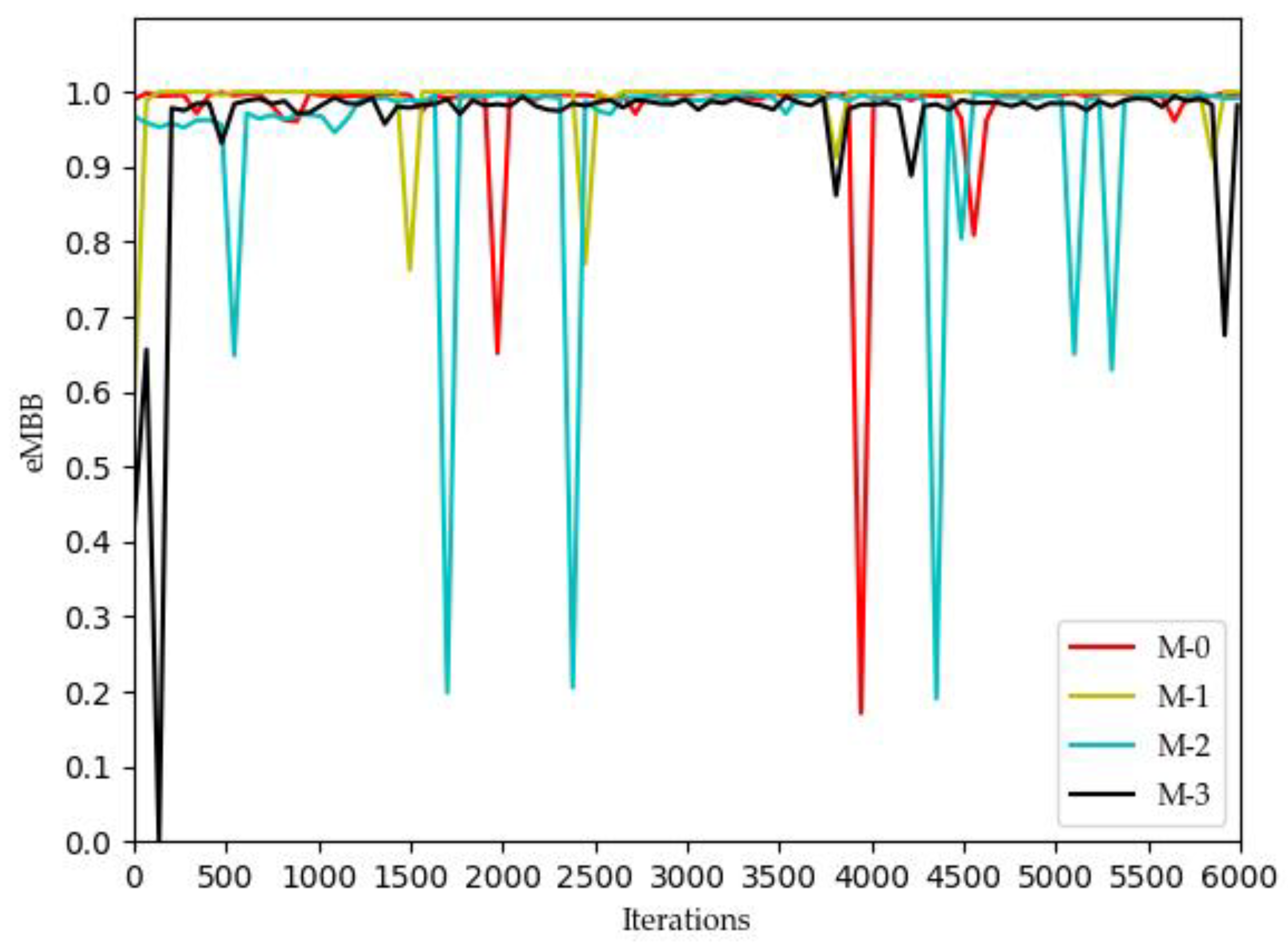
Figure 3 and
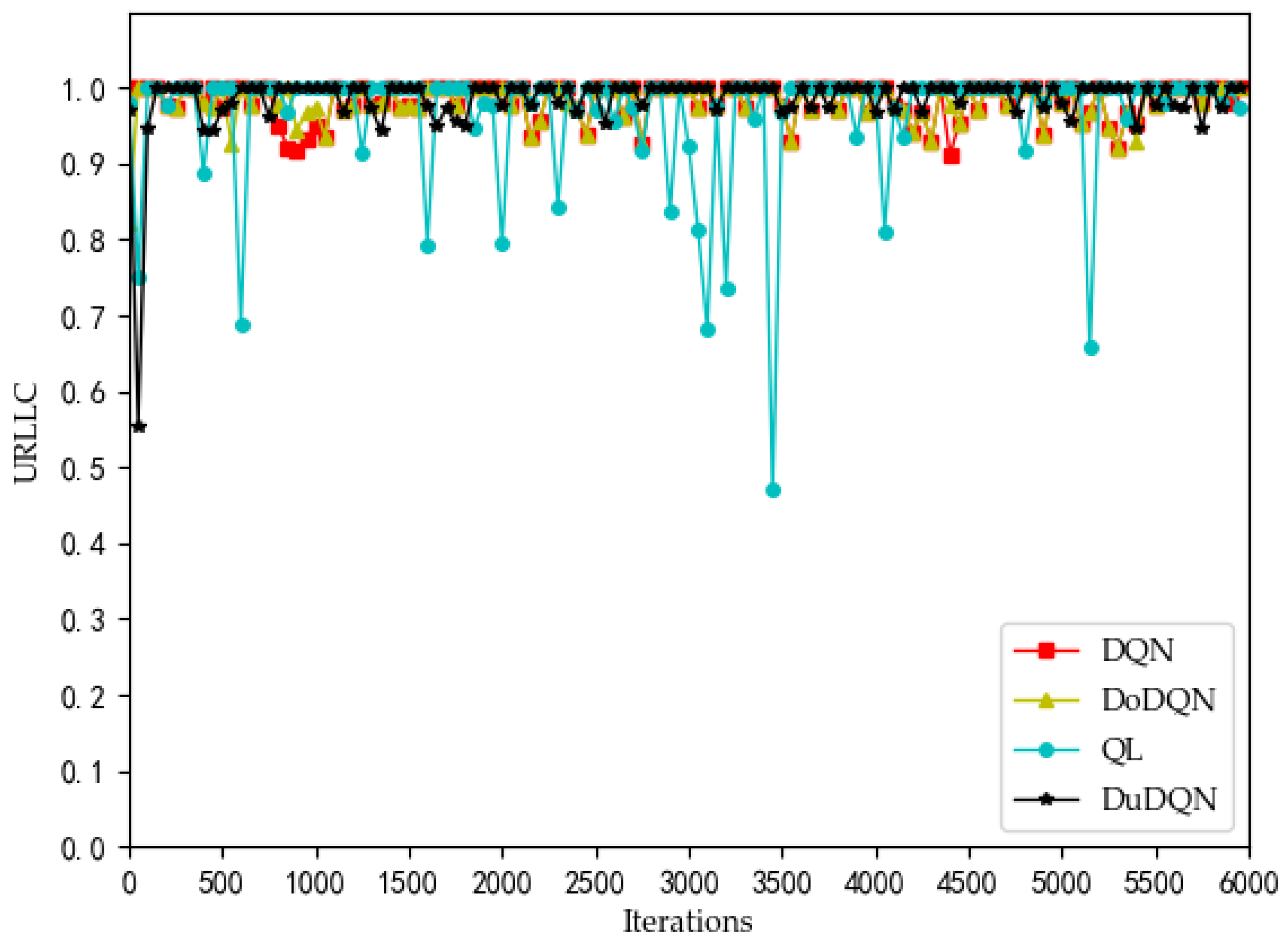
Figure 4, the QoE of URLLC and eMBB services fluctuate because the rate requirements of these two services are large (0.1 Gbs and 1 Gbs). Nevertheless, the QoE of these two services is maintained between 0.96 and 1.0. Some abnormal values in subsequent iterations are trial and error attempts made by dueling the DQN algorithm to prevent over optimization.
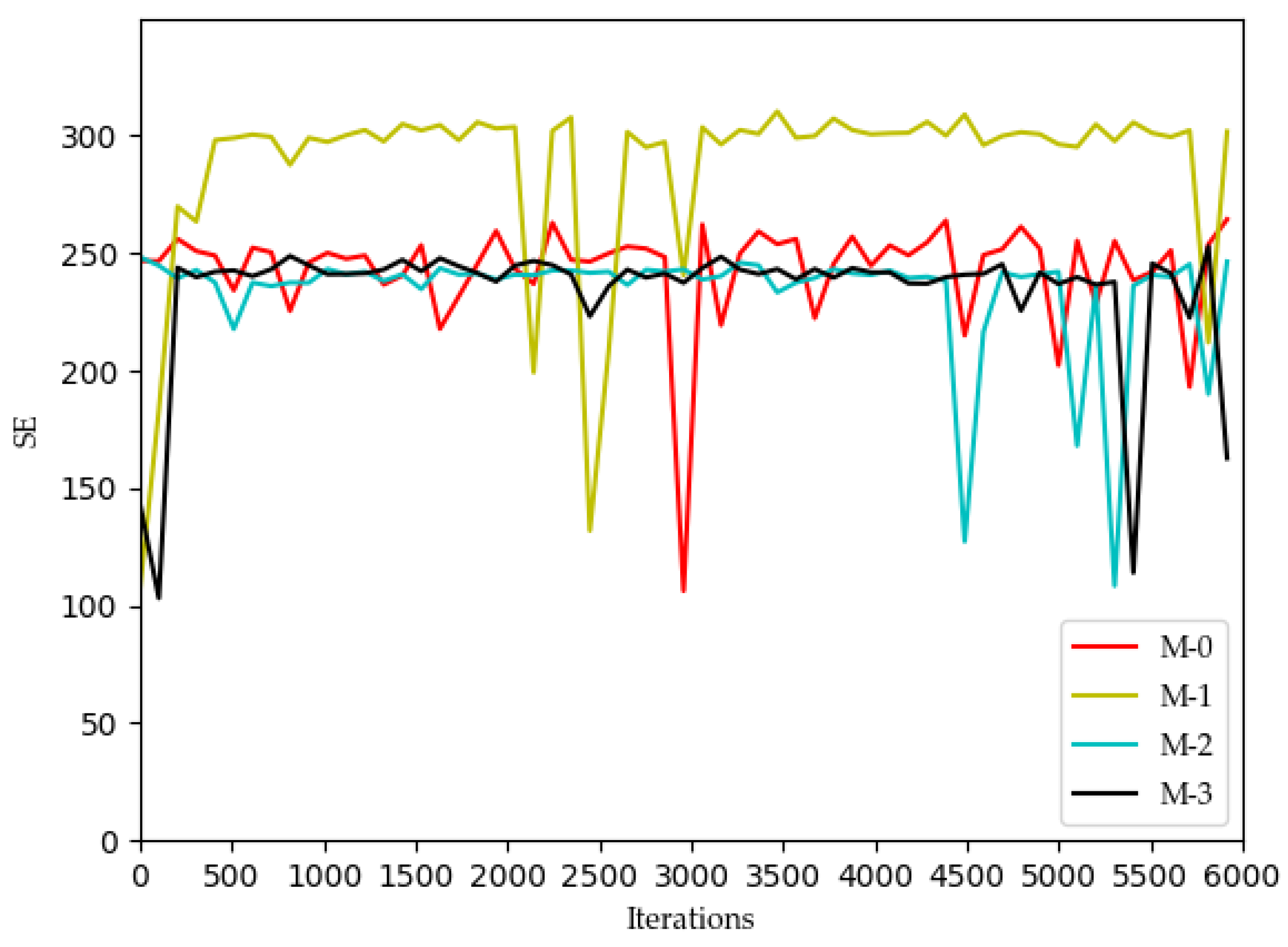
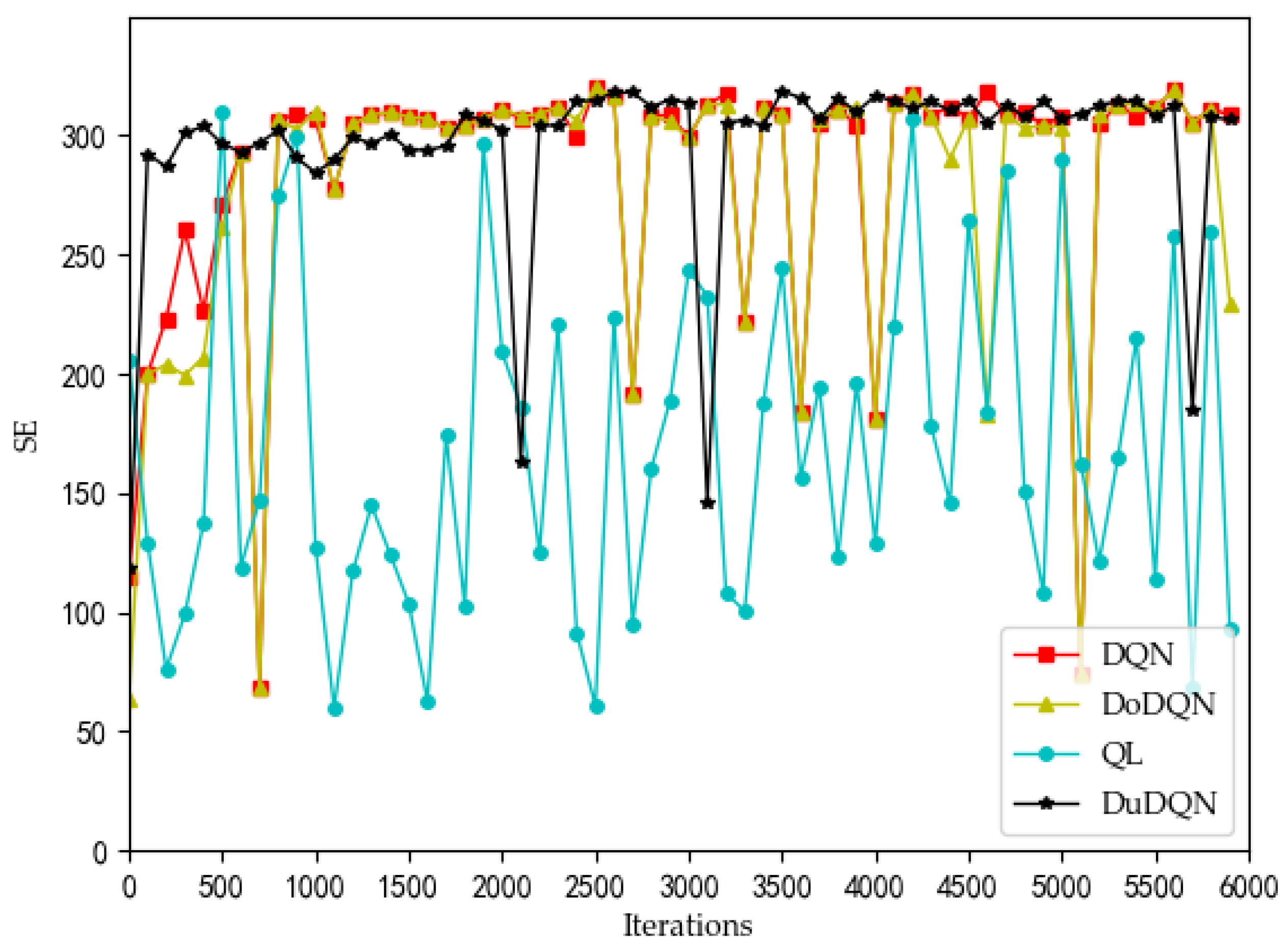
It can be seen in
Figure 5 and
Figure 6 that the curves of the SE graph are significantly different from the curves of the QoE graphs of the other three services, and the SE curve has a strong correlation with the system utility curve compared to the three service curves.
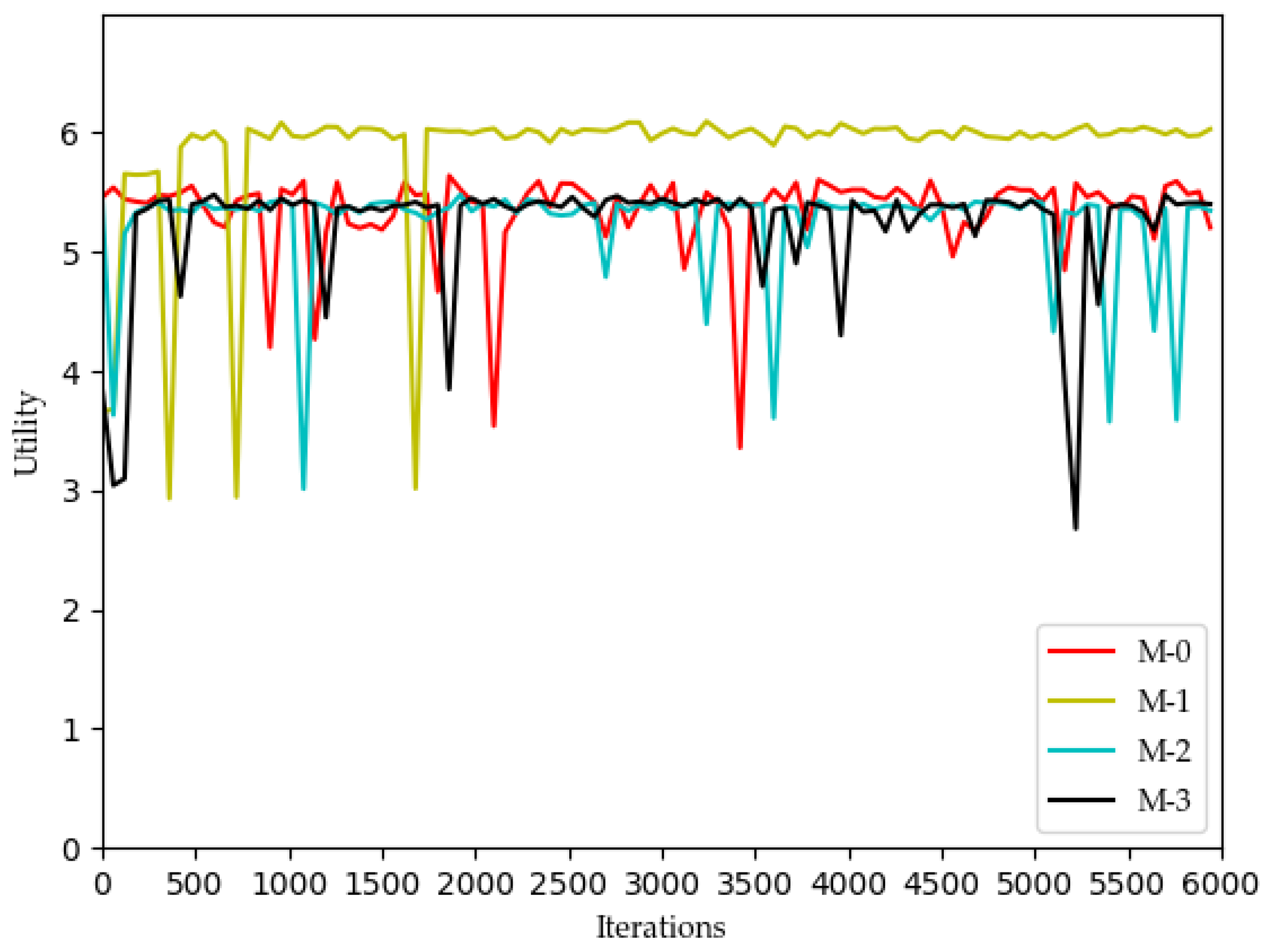
However, for each MVNO, its system utility functions and SE shows significant optimization with increasing iterations, which confirms that using the Dueling DQN algorithm is a suitable choice for the model optimization problem proposed in this paper. In MVNO-1, for example, the SE curve fluctuates a lot before 400 iterations, and after 400 iterations, the SE curve has converged to the maximum value of 300 and tends to be stable, with a few low values after more than 400 iterations but does not affect the overall trend. The reason for this phenomenon is that the training neural net parameters were set to be replaced every 200 iterations during the simulation. The neural net parameters were in a relatively poor state when the training was first performed using DQN, and most of the assigned actions obtained from the initial neural net parameters and strategy selection were randomly selected actions in the action space, so the curve showed substantial fluctuations at the beginning. When the number of iterations reaches 400 and the neural net parameters in the Dueling DQN algorithm reach better, the subsequent choices of the allocations all appear to be better choices.
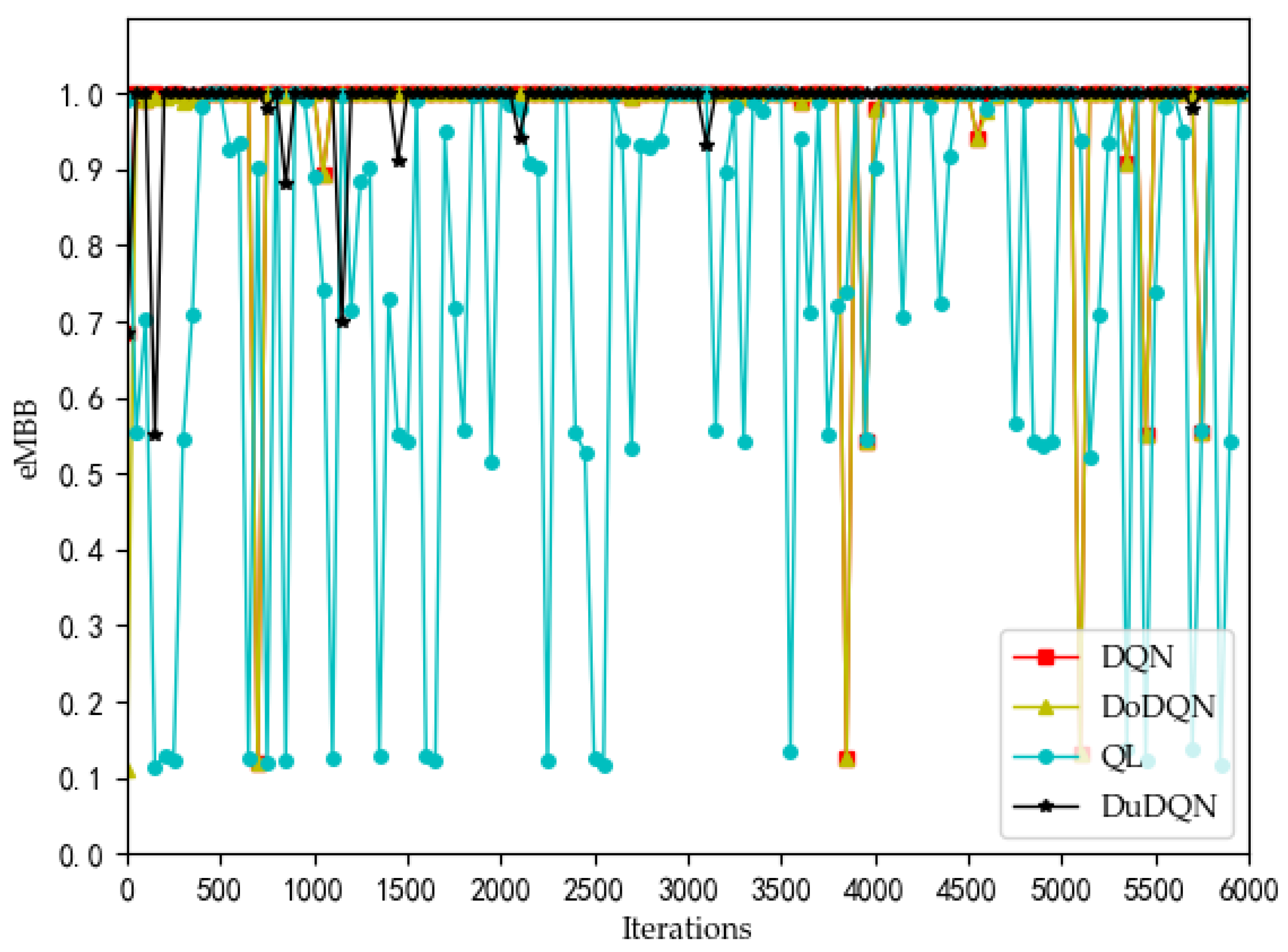
Analyzing the curves of QoE for three service types (
Figure 7,
Figure 8 and
Figure 9), it can be seen that for VoLTE service, the QoE values of all three methods are stable at 100%. For URLLC service and eMBB service, the QoE values of four algorithms show some fluctuations of low values, but all three methods are basically stable at 100%. However, the QoE curves of the three services obtained by the Dueling DQN algorithm are more stable and less volatile than the other three algorithms. It can be observed from the curves of system utility and SE (
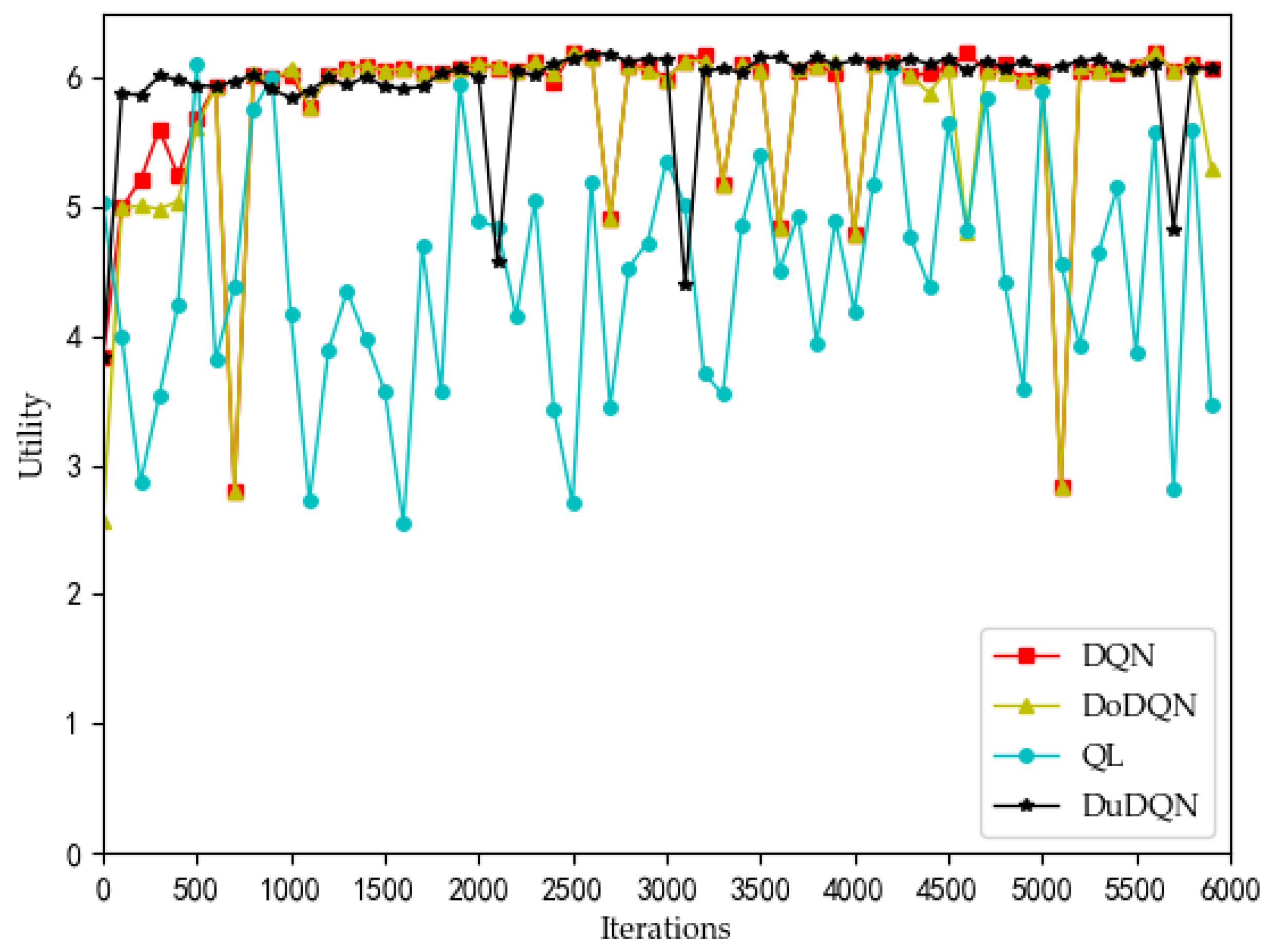
Figure 10 and
Figure 11) that the DRL algorithms have a significant improvement over the QL algorithm.
For the curves of SE and system utility, the curves using the Dueling DQN algorithm have higher values than the curves of the other methods, and the curves converge and stabilize at the highest values (SE > 300, utility > 6). After 2200 iterations, the actual simulation data show that the SE obtained by the Dueling DQN algorithm is about 1% higher than that of the DQN algorithm, about 2.7% higher than the Double DQN algorithm, and about 76% higher than the QL algorithm.
And utility has also been slightly improved.
These four algorithms have obvious optimization for the whole system, and the SE and utility curves have obvious optimization trends. Through comparison, it is concluded that the curve obtained by the Dueling DQN algorithm is more stable than other centralized algorithms. Especially after 2200 iterations, the curve obtained by the Dueling DQN algorithm rarely fluctuates greatly, and even its average value converges to a relatively high value, which shows that using the Dueling DQN algorithm to solve the optimization problem of the lower model is a very effective method.
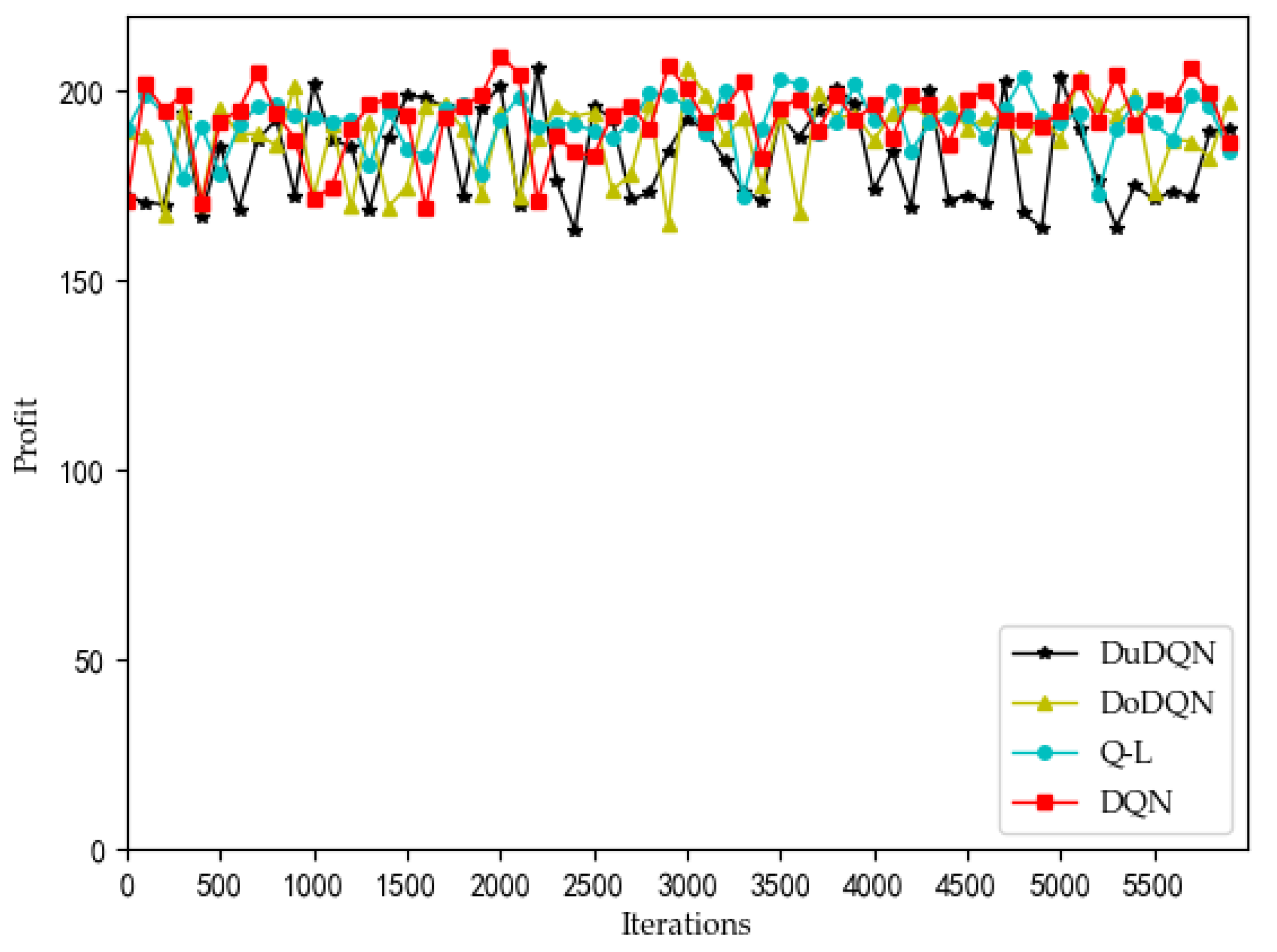
Figure 12 and
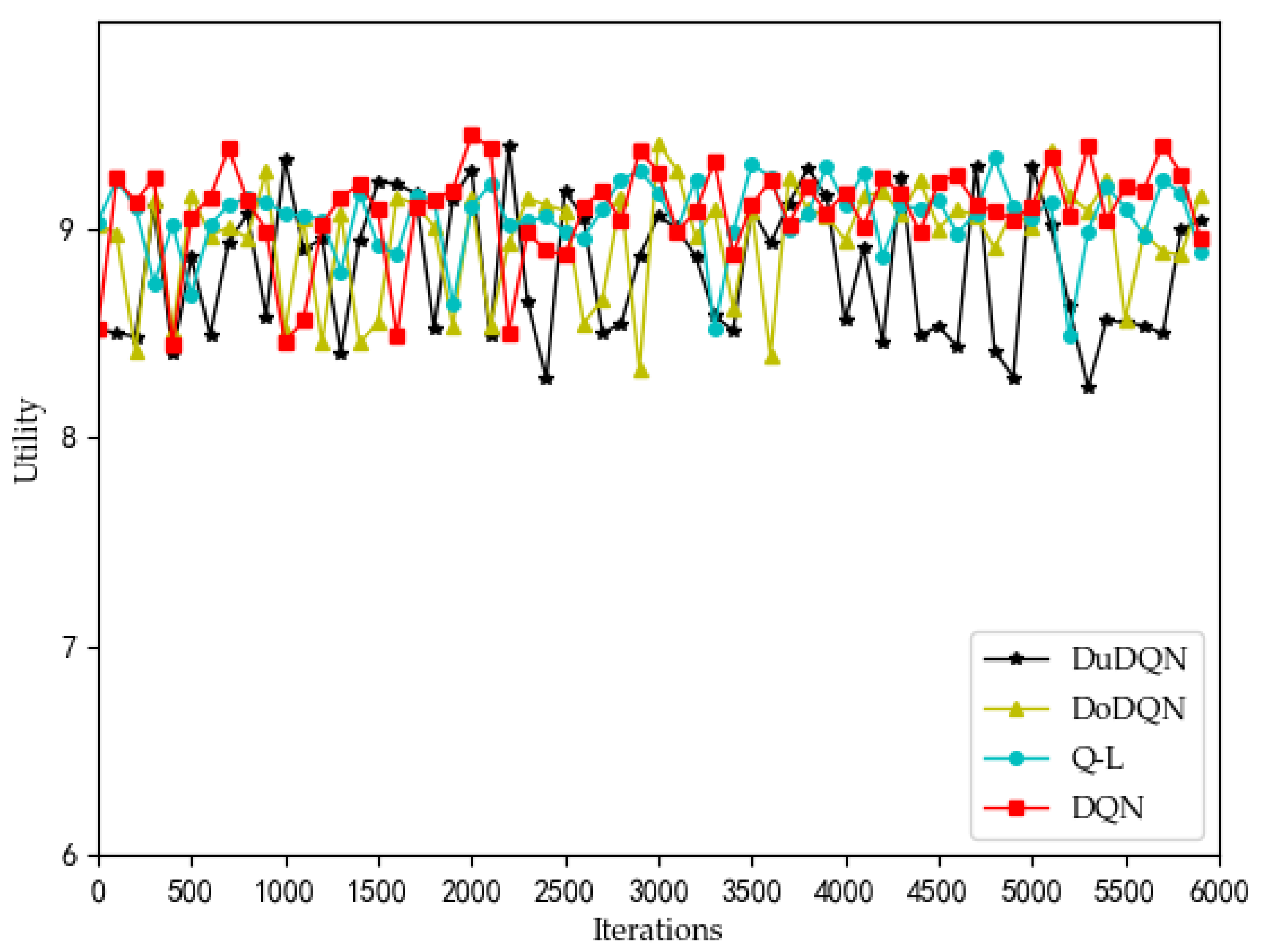
Figure 13 show the comparison of profit and utility of the upper model using different algorithms.
It can be seen from the line graph that the optimization effect of the upper model using the DQN algorithm (red curve) is the best. After the number of iterations reaches 3500, the profit of MVNO and the utility function of the system gradually converge to about 200 and 9, respectively. The second is the QL algorithm, whose curve is significantly higher than that of the other two algorithms, but after 3500 iterations, it is more volatile than that of the DQN algorithm. The two curves obtained by the Double DQN and Dueling DQN algorithm perform worse. As the advantages of the DQN algorithm over the other three algorithms cannot be clearly seen from the line graph, the violin graph is used to analyze and compare the data.
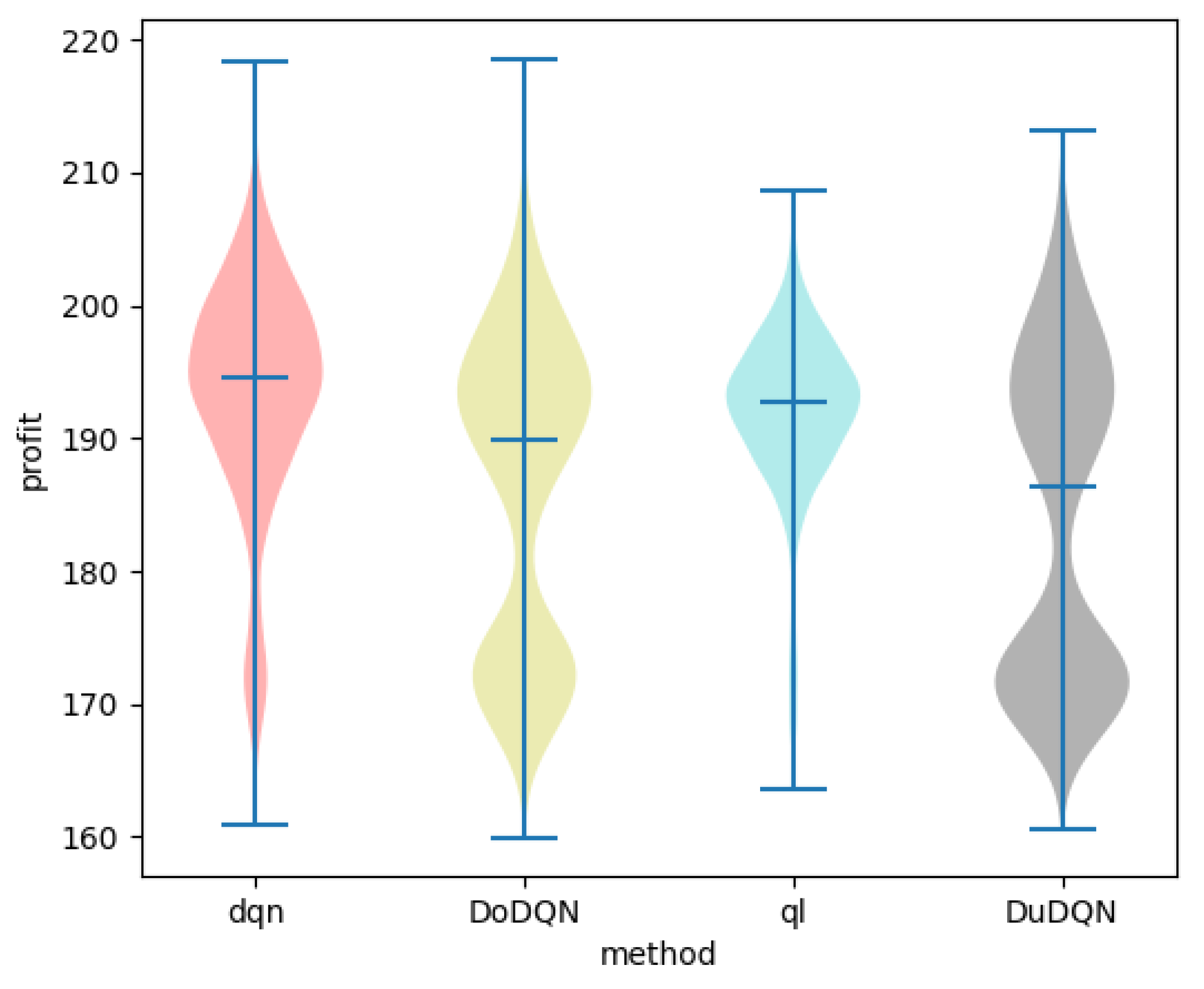
In the violin diagram, the wider the blue width is, the higher the ratio of the value here is. The middle line represents the mean value, and the upper and lower lines represent the maximum and minimum values.
It is obvious from
Figure 14 and
Figure 15 that, the system utility and MVNO benefit obtained by using the DQN algorithm are better than the other algorithms. The average values of Se and utility obtained by the DQN algorithm are the largest, and the values obtained are concentrated in a relatively high range, which is about 5.4% higher than Double DQN and about 2.6% higher than Dueling DQN. The reason may be that Double DQN and Dueling DQN improved by the DQN algorithm pay too much attention to the behavior of trial and error, but reduce the optimization effect of the system.
In general, it can be seen from
Table 4, that the algorithm proposed in this paper is better than the comparison method in optimization performance, convergence speed, and convergence stability.
4.3. The Complexity Analysis
In terms of time complexity, the algorithm proposed in this paper needs to generate the state after the interaction between the environment and MVNO in each iteration, so it is difficult to obtain the operation time required by the algorithm in each iteration. However, the preset number of iterations in this paper is 6000.
From the perspective of spatial complexity, the spatial complexity of the DRL algorithm is obtained according to the number of neural network parameters, real-time addition Ca, and real-time multiplication cm that needs to be stored. The DRL algorithm used in this paper uses
hidden full connection layers, and each hidden layer is set with
neural units.
The neural network set up in this paper uses the Relu activation function, the number of hidden layers
, and the number of neurons in the two hidden layers
, Therefore, according to formula (22) and formula (25)–(27), we can get the spatial complexity:
Therefore, it can be deduced that the complexity of the proposed algorithm is low. in addition, from the results, it can be seen that the proposed algorithm can converge at a faster speed and get the optimization results.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}