
Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection


Abstract
:1. Introduction
2. Methods
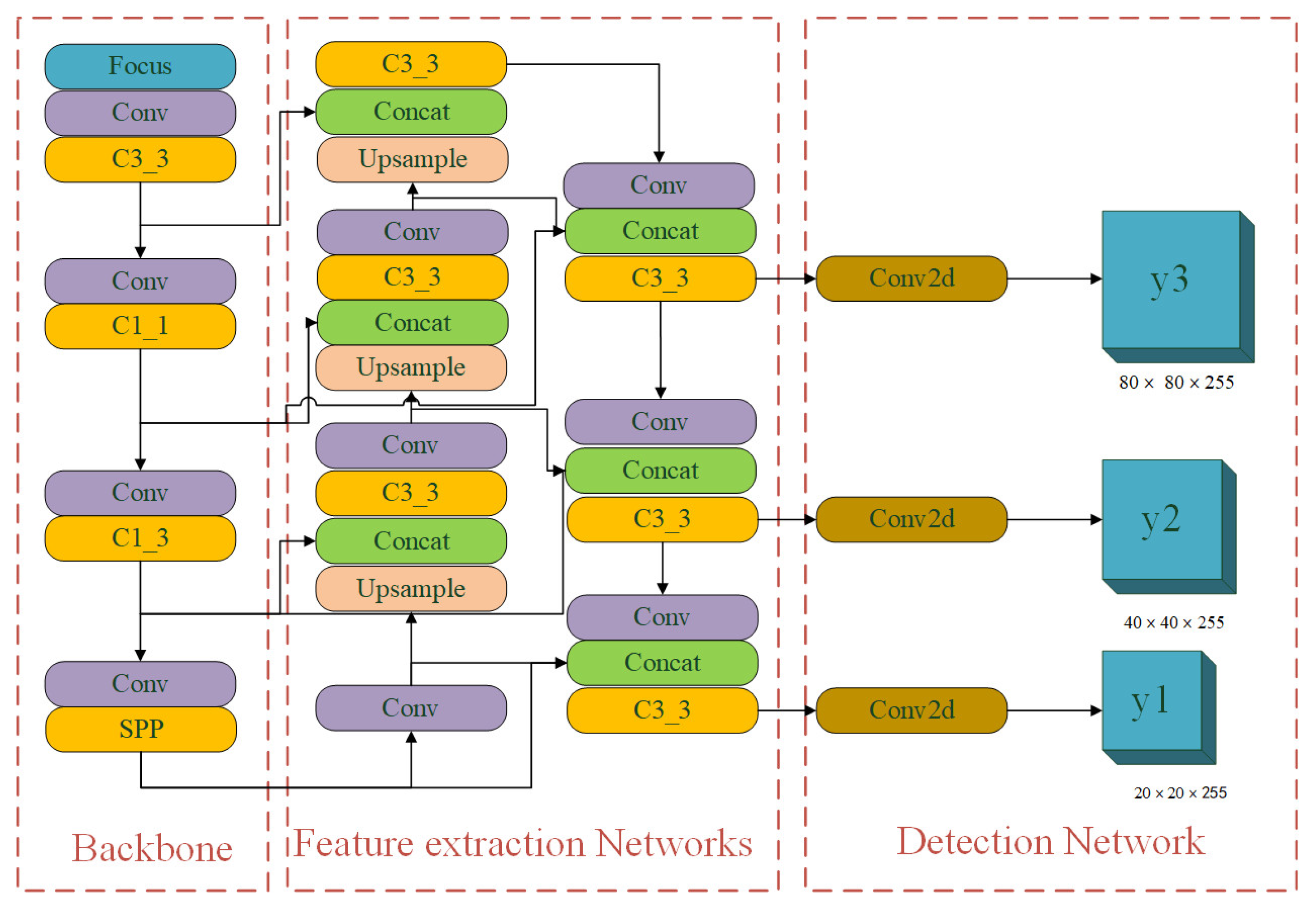
2.1. Introduction to Algorithm and Network Structure
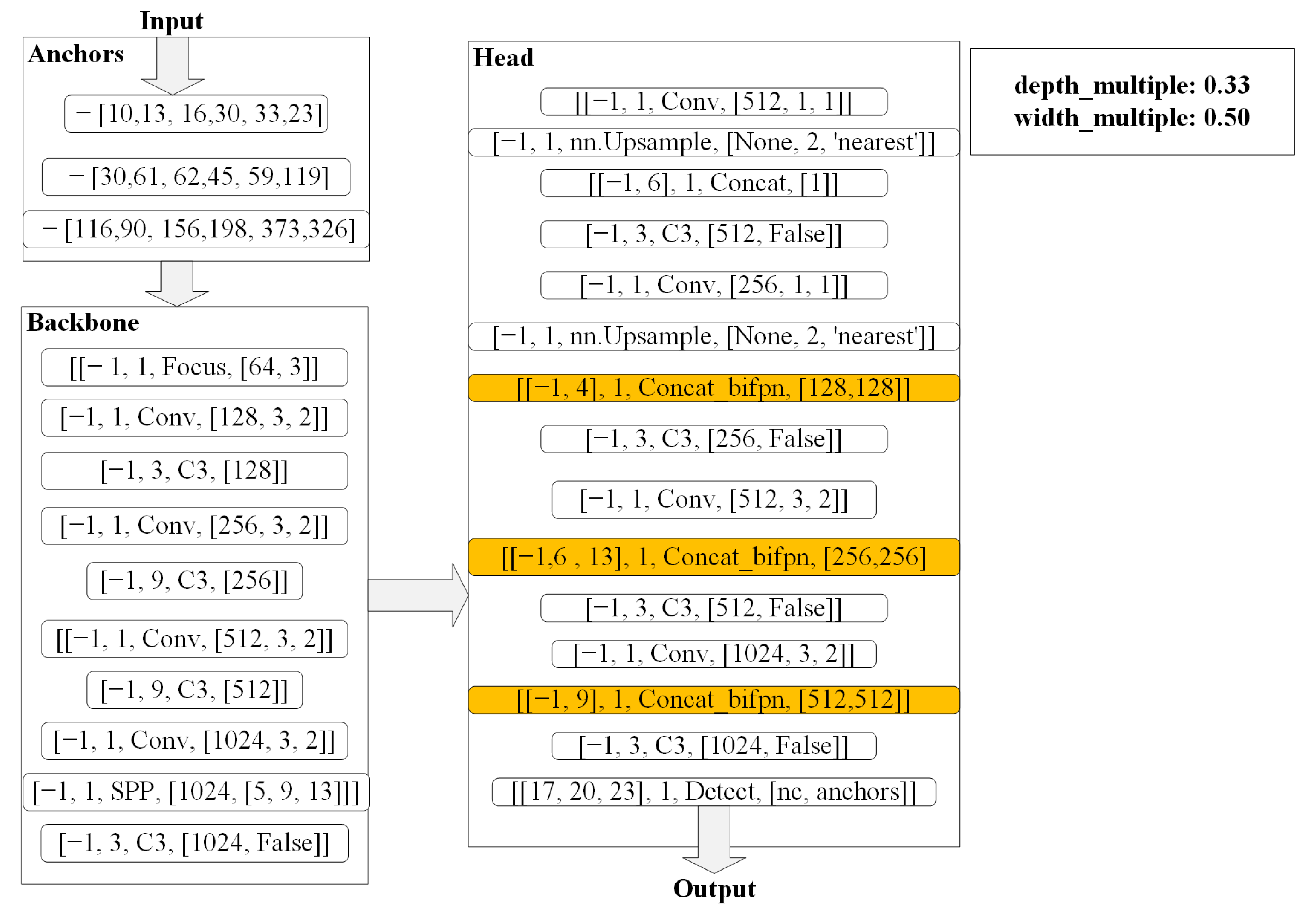
2.2. Feature Extraction Networks of the BV-YOLOv5S Model
2.3. Improved Focal Loss Function of BV-YOLOv5S Model
3. Experiment
3.1. Experiment Environment and Evaluation Index
3.1.1. Experiment Environment
3.1.2. Evaluation Metrics
- (1)
- Precision, Recall, F1-score evaluation indicators
- (2)
- Detection rate
- (3)
- PR curve, [email protected] evaluation indicators
3.2. Data Collection and Processing
3.3. Data Collection and Processing
4. Results and Discussion
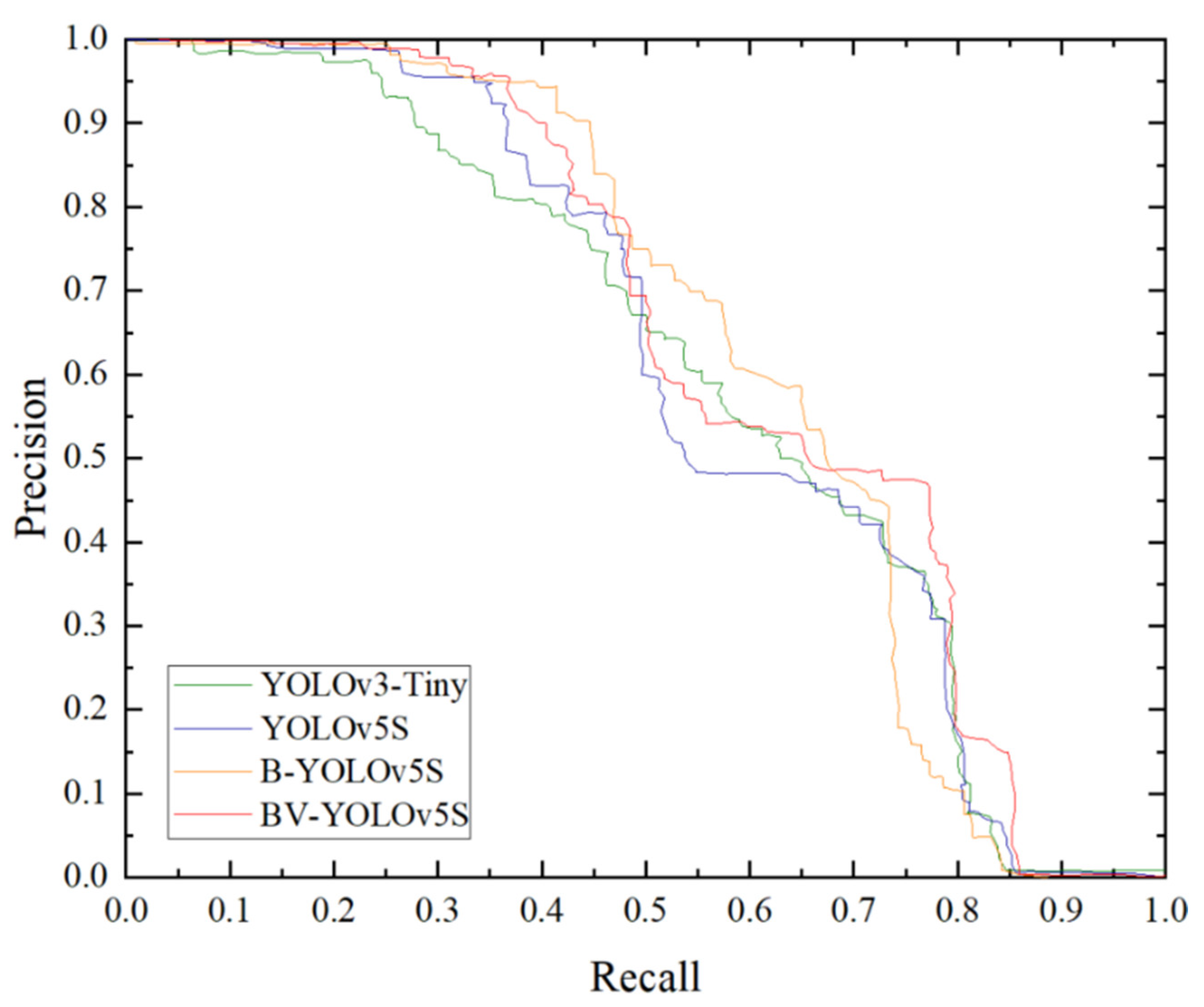
4.1. Evaluation Metrics
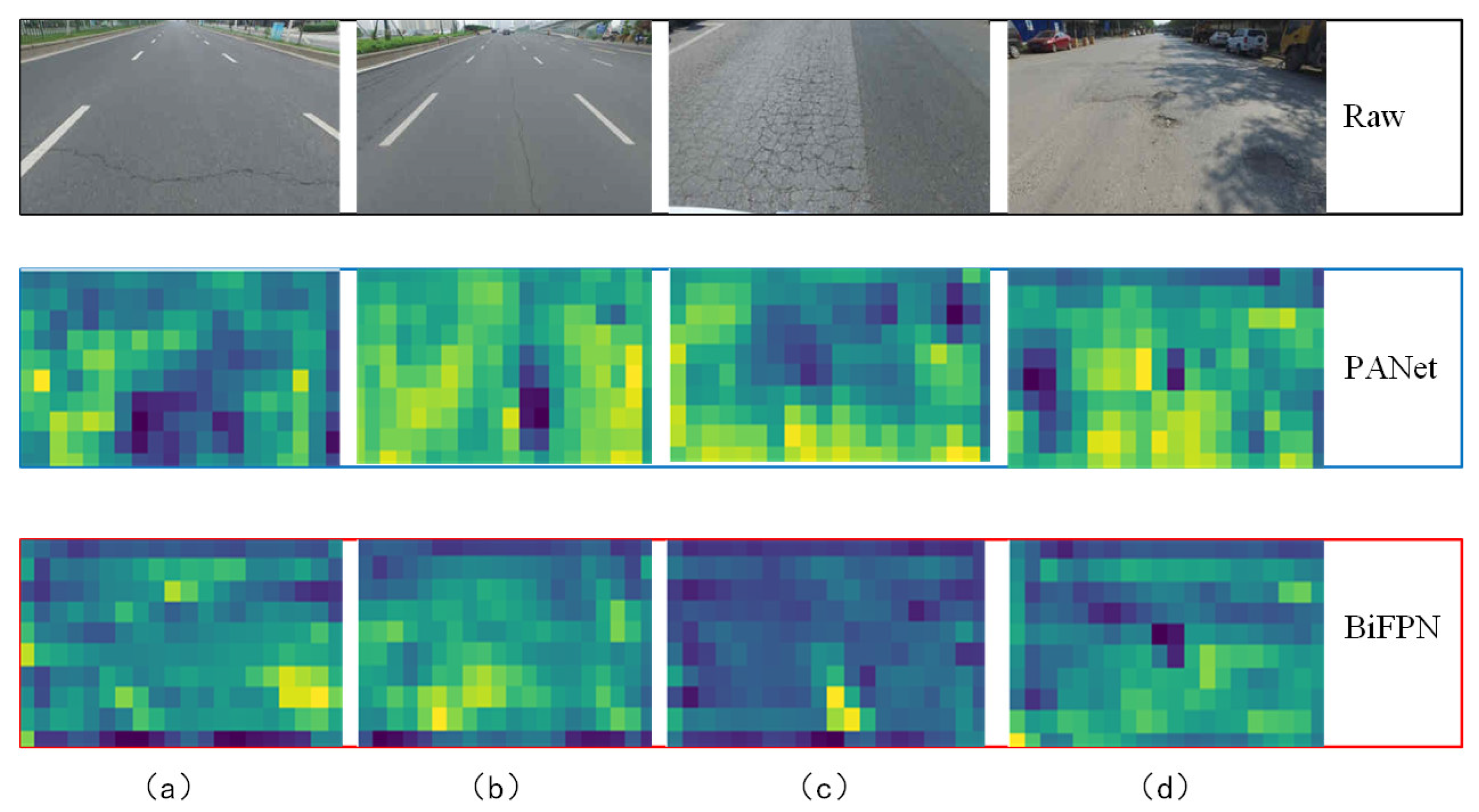
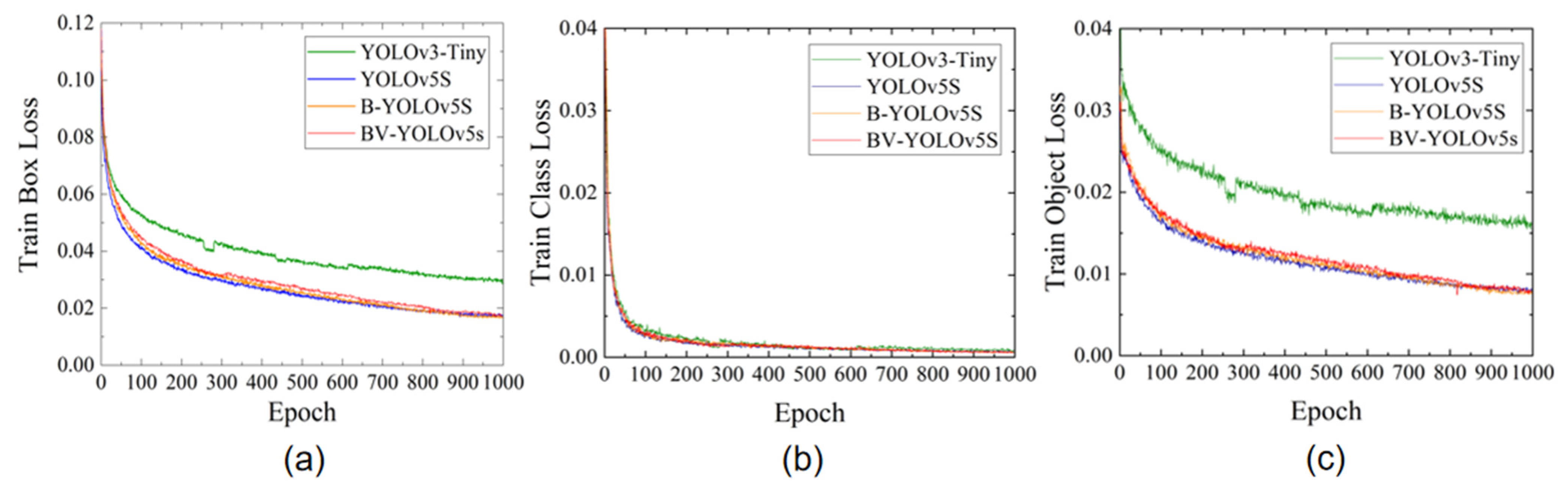
4.2. Discussion of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- CIA. Roadways—The World Factbook. Available online: www.cia.gov (accessed on 12 July 2021).
- CIA. Public Road Length—2017 Miles by Functional System. Available online: www.cia.gov/the-world-factbook (accessed on 2 February 2019).
- The Times of India. Deadly pits: Potholes Claimed 11,386 Lives during 2013–2016. Available online: https://timesofindia.indiatimes.com/india/deadly-pits-potholes-claimed-11386-lives-during-2013-16/articleshow/60774243.cms (accessed on 21 September 2017).
- Greg Colemanlaw. Accidents and Injuries Caused by Bad Road Conditions. Available online: https://www.gregcolemanlaw.com/bad-road-damages-and-effects.html (accessed on 1 January 2022).
- Pasha, A.; Mansourian, A.; Ravanshadnia, M. Evaluation of Work Zone Road User Cost of Pavements Based on Rehabilitation Strategy Approach. J. Transp. Eng. Part B Pavements 2021, 147, 4021015. [Google Scholar] [CrossRef]
- Hosseini, A.; Faheem, A.; Titi, H.; Schwandt, S. Evaluation of the long-term performance of flexible pavements with respect to production and construction quality control indicators. Constr. Build. Mater. 2020, 230, 116998. [Google Scholar] [CrossRef]
- Kumar, P.; Sharma, A.; Kota, S.R. Automatic Multiclass Instance Segmentation of Concrete Damage Using Deep Learning Model. IEEE Access 2021, 9, 90330–90345. [Google Scholar] [CrossRef]
- Majidifard, H.; Adu-Gyamfi, Y.; Buttlar, W.G. Deep machine learning approach to develop a new asphalt pavement condition index. Constr. Build. Mater. 2020, 247, 118513. [Google Scholar] [CrossRef]
- JTG H20-2007; Chinese Highway Technical Condition Evaluation Standard. Ministry of Transportation: Beijing, China, 2007.
- Hoang, N.-D.; Nguyen, Q.-L. Automatic Recognition of Asphalt Pavement Cracks Based on Image Processing and Machine Learning Approaches: A Comparative Study on Classifier Performance. Math. Probl. Eng. 2018, 2018, 6290498. [Google Scholar] [CrossRef]
- Radopoulou, S.C.; Brilakis, I. Automated Detection of Multiple Pavement Defects. J. Comput. Civ. Eng. 2017, 31, 4016057. [Google Scholar] [CrossRef] [Green Version]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Wang, W.; Shui, P. Parameter Estimation and Two-Stage Segmentation Algorithm for the Chan-Vese Model. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 201–204, ISBN 1-4244-0480-0. [Google Scholar]
- Subirats, P.; Dumoulin, J.; Legeay, V.; Barba, D. Automation of Pavement Surface Crack Detection using the Continuous Wavelet Transform. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3037–3040, ISBN 1-4244-0480-0. [Google Scholar]
- Li, B.; Wang, K.C.P.; Zhang, A.; Fei, Y.; Sollazzo, G. Automatic Segmentation and Enhancement of Pavement Cracks Based on 3D Pavement Images. J. Adv. Transp. 2019, 2019, 1813763. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Nguyen, Q.-L. A novel method for asphalt pavement crack classification based on image processing and machine learning. Eng. Comput. 2019, 35, 487–498. [Google Scholar] [CrossRef]
- Salari, E.; Bao, G. Pavement Distress Detection and Severity Analysis. Adv. Eng. Inform. 2011, 7877, 25–27. [Google Scholar]
- Moghadas Nejad, F.; Zakeri, H. A comparison of multi-resolution methods for detection and isolation of pavement distress. Expert Syst. Appl. 2011, 38, 2857–2872. [Google Scholar] [CrossRef]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3708–3712, ISBN 978-1-4673-9961-6. [Google Scholar]
- Aswath, M.; Raj, S.J.; Mohanaprasad, K. Real-Time Pothole Detection with Onboard Sensors and Camera on Vehicles. In Futuristic Communication and Network Technologies; Sivasubramanian, A., Shastry, P.N., Hong, P.C., Eds.; Springer: Singapore, 2022; pp. 479–488. ISBN 978-981-16-4624-9. [Google Scholar]
- Hoang, N.-D.; Huynh, T.-C.; Tran, V.-D. Computer Vision-Based Patched and Unpatched Pothole Classification Using Machine Learning Approach Optimized by Forensic-Based Investigation Metaheuristic. Complexity 2021, 2021, 3511375. [Google Scholar] [CrossRef]
- Riid, A.; Lõuk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System. Appl. Sci. 2019, 9, 4829. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.T.; Nguyen, L.T.; Afanasiev, A.D.; Pham, L.T. Classification of Road Pavement Defects Based on Convolution Neural Network in Keras. Aut. Control Comp. Sci. 2022, 56, 17–25. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Ping, P.; Yang, X.; Gao, Z. A Deep Learning Approach for Street Pothole Detection. In Proceedings of the 2020 IEEE Sixth International Conference on Big Data Computing Service and Applications (BigDataService), Oxford, UK, 3–6 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 198–204, ISBN 978-1-7281-7022-0. [Google Scholar]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Han, J. MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies 2021, 14, 1426. [Google Scholar] [CrossRef]
- Park, S.-S.; Tran, V.-T.; Lee, D.-E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229. [Google Scholar] [CrossRef]
- Baek, J.-W.; Chung, K. Pothole Classification Model Using Edge Detection in Road Image. Appl. Sci. 2020, 10, 6662. [Google Scholar] [CrossRef]
- Pena-Caballero, C.; Kim, D.; Gonzalez, A.; Castellanos, O.; Cantu, A.; Ho, J. Real-Time Road Hazard Information System. Infrastructures 2020, 5, 75. [Google Scholar] [CrossRef]
- Ahmed, K.R. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors 2021, 21, 8406. [Google Scholar] [CrossRef] [PubMed]
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 January 2021).
- Tan, M.; Pang, R.; Le, V.Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Cheng, Y.; Chen, C.; Gan, Z. Enhanced Single Shot MultiBox Detector for Pedestrian Detection. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–7. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497v3. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Ma, D.; Fang, H.; Wang, N.; Xue, B.; Dong, J.; Wang, F. A real-time crack detection algorithm for pavement based on CNN with multiple feature layers. Road Mater. Pavement Des. 2021, 10338, 1–17. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. -Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z.; Xu, H. Insulator Faults Detection in Aerial Images from High-Voltage Transmission Lines Based on Deep Learning Model. Appl. Sci. 2021, 11, 4647. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wu, S.; Li, X.; Wang, X. IoU-Aware Single-Stage Object Detector for Accurate Localization. Image Vis. Comput. 2019, 97, 103911. Available online: http://arxiv.org/pdf/1912.05992v4 (accessed on 1 February 2022). [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An annotated image dataset for automatic road damage detection using deep learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Maguire, M.; Dorafshan, S.; Thomas, R.J. SDNET2018: A Concrete Crack Image Dataset for Machine Learning Applications. 2018. Available online: https://digitalcommons.usu.edu/all_datasets/48 (accessed on 1 February 2022).
- Adibhatla, V.A.; Chih, H.-C.; Hsu, C.-C.; Cheng, J.; Abbod, M.F.; Shieh, J.-S. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once. Math. Biosci. Eng. 2021, 18, 4411–4428. [Google Scholar] [CrossRef] [PubMed]
- Jing, Y.; Ren, Y.; Liu, Y.; Wang, D.; Yu, L. Automatic Extraction of Damaged Houses by Earthquake Based on Improved YOLOv5: A Case Study in Yangbi. Remote Sens. 2022, 14, 382. [Google Scholar] [CrossRef]
- Wang, Y.; Hua, C.; Ding, W.; Wu, R. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Processing 2022, 288, 30. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Based YOLO for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2799–2808, ISBN 978-1-6654-0191-3. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Dataset | Lateral Cracking | Longitudinal Cracking | Alligator Cracking | Pothole |
|---|---|---|---|---|
| Number | 1350 | 1050 | 1400 | 1800 |
| Model | [email protected] | Precision | Recall | F1-Score | FPS |
|---|---|---|---|---|---|
| YOLOv3-Tiny | 0.594 | 0.737 | 0.573 | 0.646 | 167 |
| YOLOv5S | 0.605 | 0.859 | 0.549 | 0.670 | 238 |
| B-YOLOv5S | 0.626 | 0.876 | 0.561 | 0.684 | 278 |
| BV-YOLOv5S | 0.635 | 0.864 | 0.590 | 0.701 | 263 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, F.-J.; Jiao, S.-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. https://doi.org/10.3390/s22093537
Du F-J, Jiao S-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors. 2022; 22(9):3537. https://doi.org/10.3390/s22093537
Chicago/Turabian StyleDu, Fu-Jun, and Shuang-Jian Jiao. 2022. "Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection" Sensors 22, no. 9: 3537. https://doi.org/10.3390/s22093537
APA StyleDu, F.-J., & Jiao, S.-J. (2022). Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors, 22(9), 3537. https://doi.org/10.3390/s22093537