
Pedestrian Detection Using Integrated Aggregate Channel Features and Multitask Cascaded Convolutional Neural-Network-Based Face Detectors



Abstract
:1. Introduction
- A novel pedestrian detector integrating the multitask cascaded CNN and ACF is proposed;
- Improved detection performance for significantly occluded pedestrians and beyond is achieved;
- Robustness of the proposed detector in terms of datasets and beyond is achieved.
2. Materials and Methods
2.1. The Proposed Detector
2.2. Modules of the Proposed Integrated Detector
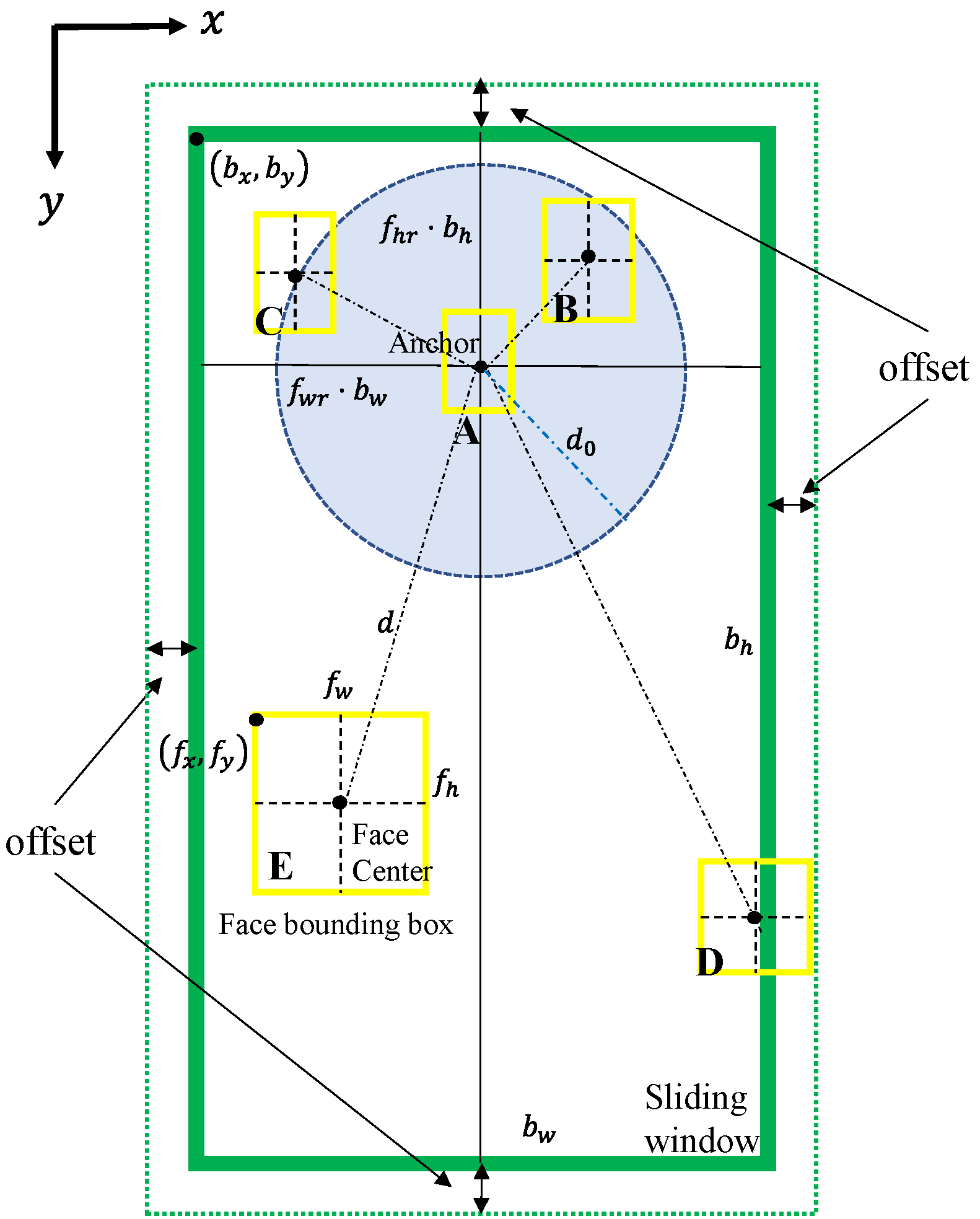
2.2.1. Sliding Window
2.2.2. Face Detector
2.2.3. Score Combination
2.2.4. Face Score Transformation
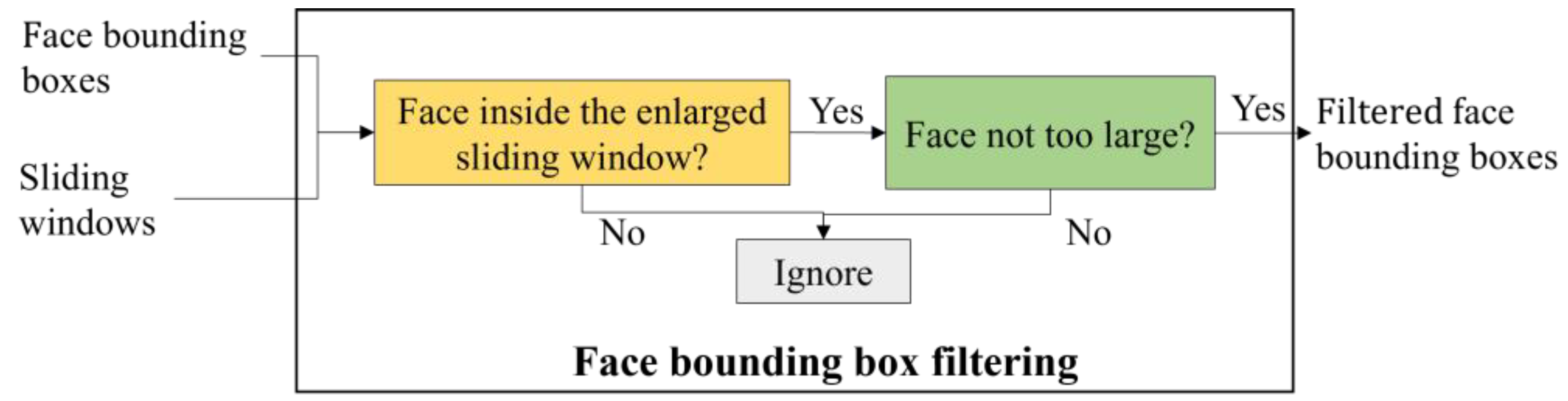
2.2.5. Face Bounding Box Filtering
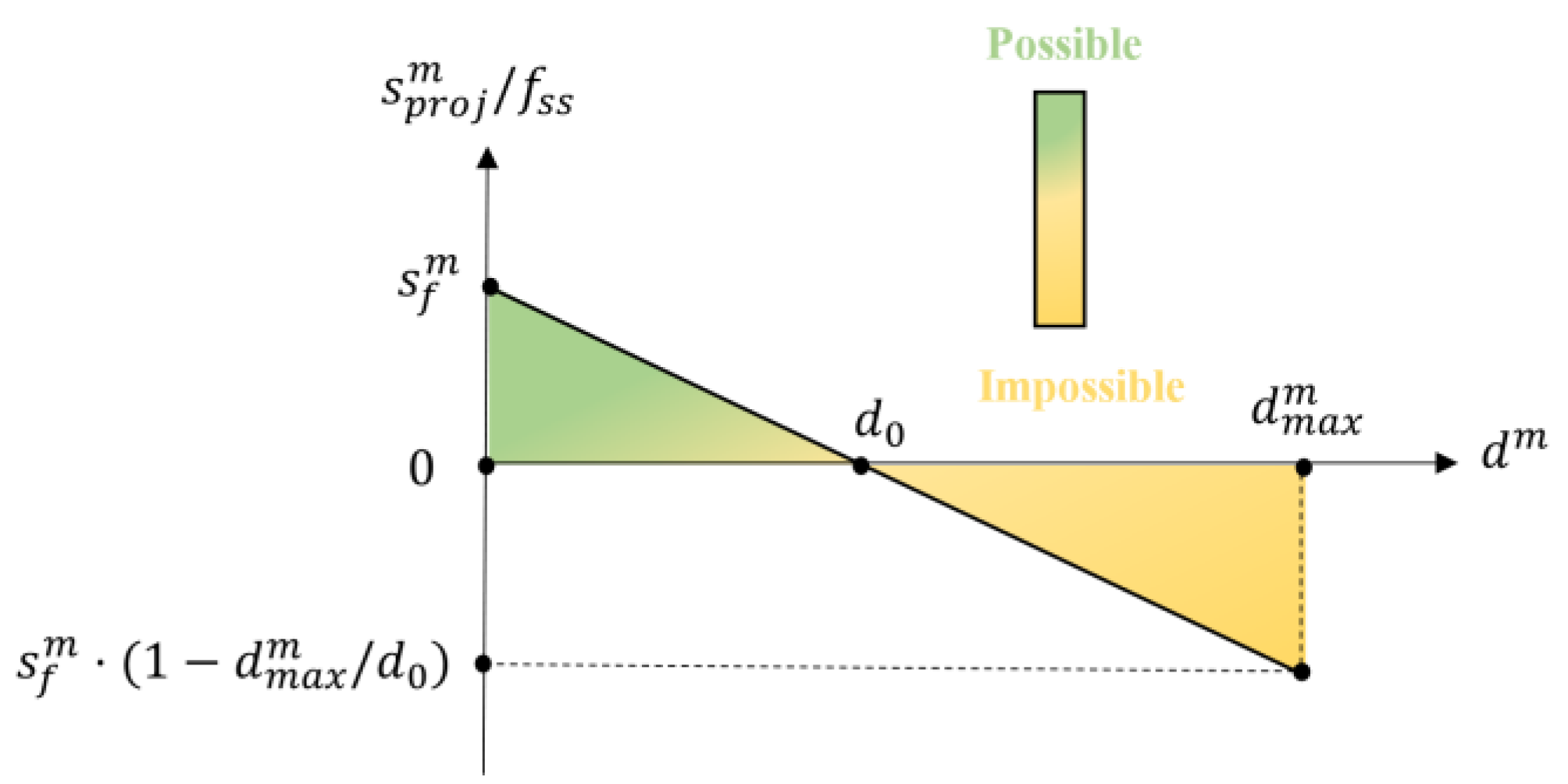
2.2.6. Score Scaling and Assigning
2.2.7. ACF Detector
| Algorithm 1: Procedure used by the integrated detector | |
| Input | A sliding window , face bounding boxes face scores . |
| Settings | , , set , , , , , , and . |
| Output | Qualified , . |
| Step 1 | For each : If Equations (2)–(7) are fulfilled: |
| Step 2 | Send to the cascading decision trees. |
| Step 3 | If is implemented: If : Output ; else if (default threshold): Output . |
3. Experiments Analysis and Results
- INRIA pedestrian dataset [13]: The test dataset contains 288 positive color images with 589 labeled human bodies. These images were shot at around eye-level. Most of these human bodies have an upright orientation with some extent of occlusion.
- Caltech pedestrian dataset [25]: This dataset consists of approximately 250,000 frames, 640 × 480 in size, and a total of 350,000 annotated bounding boxes. The standard test set with 4024 images and corresponding new annotations [26] were used in subsequent experiments. Each image contains about 1.4 persons.
- Citypersons dataset [27]: The validation set contains 500 high-resolution images, 1024 × 2048 in size, and a total of 3938 persons. Each validation image contains about 7.9 persons.
- ETHZ dataset [28]: This dataset is a collection of 8 video sequences from busy inner-city locations with annotated human bodies. We assessed two representative sequences from this dataset, namely the BAHNHOF sequence and the Sunny Day sequence. As the pretrained ACF detector cannot classify human bodies with very small sizes, ground truths with widths and heights smaller than 32 and 80 pixels, respectively, were filtered out from the image sequences. After this, the BAHNHOF sequence had 999 images with 3341 ground truths and the Sunny Day sequence had 354 images with 1560 ground truths.
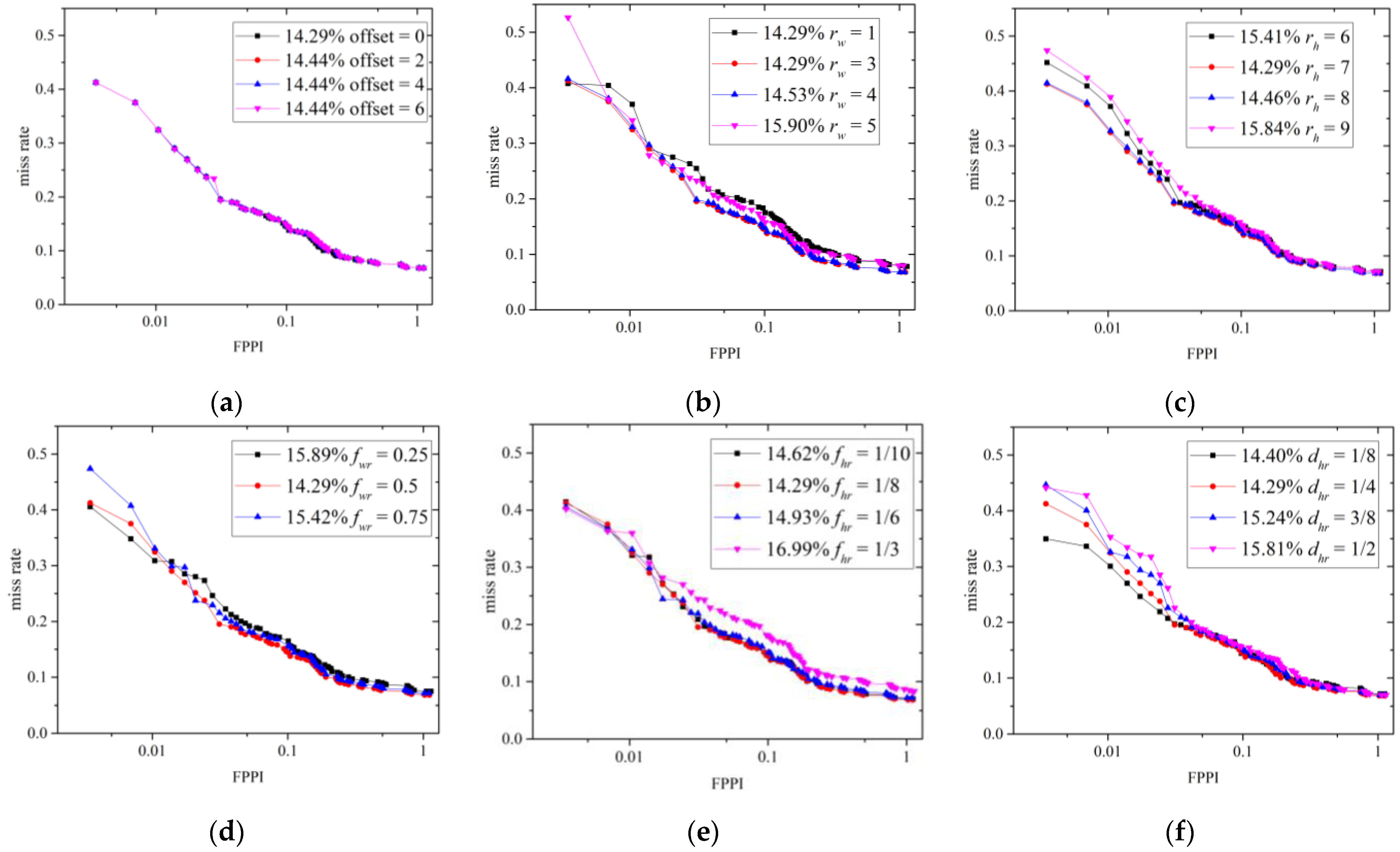
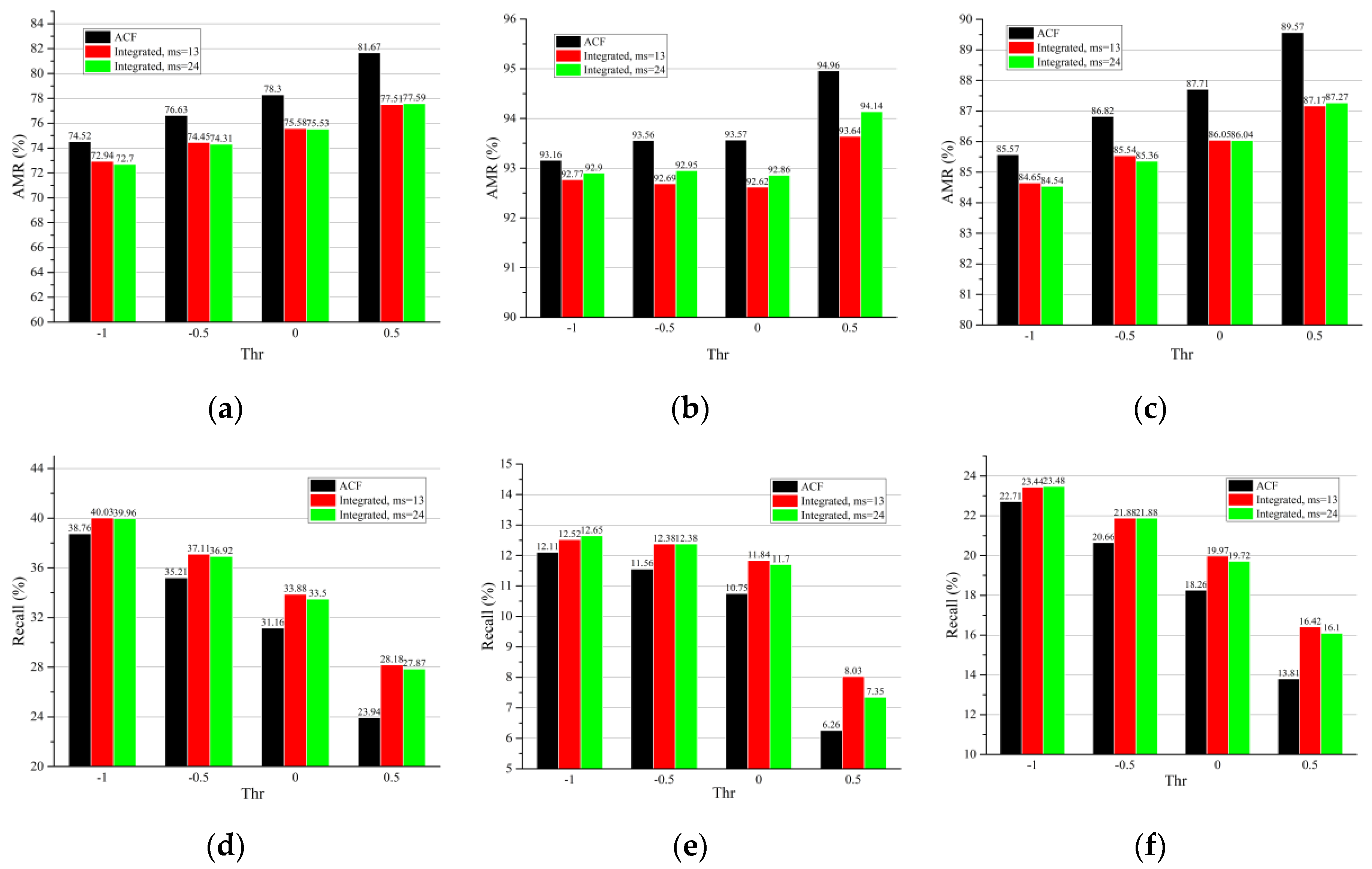
3.1. Parameter Design
3.2. Evaluation
3.2.1. Comparison with the State-of-the-Art Detectors
3.2.2. Evaluation of Robustness
3.2.3. Detection Speed
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bastian, B.T.; Jiji, C.V. Integrated feature set using aggregate channel features and histogram of sparse codes for human detection. Multimed. Tools Appl. 2020, 79, 2931–2944. [Google Scholar] [CrossRef]
- Kim, K.; Oh, C.; Sohn, K. Personness estimation for real-time human detection on mobile devices. Expert Syst. Appl. 2017, 72, 130–138. [Google Scholar] [CrossRef]
- Seemanthini, K.; Manjunath, S. Human detection and tracking using HOG for action recognition. Procedia Comput. Sci. 2018, 132, 1317–1326. [Google Scholar]
- Shen, J.; Zuo, X.; Yang, W.; Prokhorov, D.; Mei, X.; Ling, H. Differential features for pedestrian detection: A Taylor series perspective. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2913–2922. [Google Scholar] [CrossRef]
- You, M.; Zhang, Y.; Shen, C.; Zhang, X. An Extended Filtered Channel Framework for Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1640–1651. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Di Capite, M.; Kayhanian, H.; Waddingham, W.; Alexander, D.C.; Jansen, M.; Kwong, F.N.K. Tertiary lymphoid structures (TLS) identification and density assessment on H&E-stained digital slides of lung cancer. PLoS ONE 2021, 16, e0256907. [Google Scholar]
- Freeman, W.T.; Roth, M. Orientation histograms for hand gesture recognition. In Proceedings of the International Workshop on Automatic Face and Gesture Recognition, Zurich, Switzerland, 26–28 June 1995. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Matching shapes. In Proceedings of the Proceedings Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Mohan, A.; Papageorgiou, C.; Poggio, T. Example-based object detection in images by components. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 349–361. [Google Scholar] [CrossRef] [Green Version]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vision 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ke, N.Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral channel features. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A Weighted Variational Model for Simultaneous Reflectance and Illumination Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, Z.-Q.; Bian, H.; Hu, D.; Cheng, W.; Glotin, H. Pedestrian detection based on fast R-CNN and batch normalization. In Proceedings of the International Conference on Intelligent Computing, Liverpool, UK, 7–10 August 2017. [Google Scholar]
- Rahman, M.A. Face Detection Using Viola-Jones Algorithm. Available online: https://www.mathworks.com/matlabcentral/fileexchange/50077-face-detection-using-viola-jones-algorithm (accessed on 27 March 2022).
- Pennisi, A. Fast Face Detector. Available online: https://github.com/apennisi/fast_face_detector.git (accessed on 2 March 2022).
- Justin, P. MTCNN Face Detection v1.2.3. Available online: https://github.com/matlab-deep-learning/mtcnn-face-detection/releases/tag/v1.2.3 (accessed on 14 September 2021).
- Bin, Y.; Yan, J.; Lei, Z.; Li, S.Z. Aggregate channel features for multi-view face detection. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014. [Google Scholar]
- Doll, P. Piotr’s Computer Vision Matlab Toolbox. Available online: https://github.com/pdollar/toolbox (accessed on 3 April 2022).
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How Far Are We from Solving Pedestrian Detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; Van Gool, L. A mobile vision system for robust multi-person tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; Lecun, Y. Pedestrian Detection with Unsupervised Multi-stage Feature Learning. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Liang, L.; Liang, X.; He, K. Is Faster R-CNN Doing Well for Pedestrian Detection? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 0 | 549 | 319 | 93.21 | 14.29 |
| 2 | 549 | 322 | 93.21 | 14.44 |
| 4 | 549 | 322 | 93.21 | 14.44 |
| 6 | 549 | 322 | 93.21 | 14.44 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 1 | 549 | 319 | 93.21 | 14.29 |
| 3 | 549 | 319 | 93.21 | 14.29 |
| 4 | 549 | 314 | 93.21 | 14.53 |
| 5 | 542 | 308 | 92.02 | 15.90 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 6 | 547 | 321 | 92.87 | 15.41 |
| 7 | 549 | 319 | 93.21 | 14.29 |
| 8 | 549 | 316 | 93.21 | 14.46 |
| 9 | 547 | 308 | 92.87 | 15.84 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 0.25 | 545 | 328 | 92.53 | 15.89 |
| 0.5 | 549 | 319 | 93.21 | 14.29 |
| 0.75 | 547 | 317 | 92.87 | 15.42 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 1/10 | 548 | 321 | 93.04 | 14.62 |
| 1/8 | 549 | 319 | 93.21 | 14.29 |
| 1/6 | 547 | 316 | 92.87 | 14.93 |
| 1/3 | 540 | 327 | 91.68 | 16.99 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| 1/8 | 547 | 323 | 92.87 | 14.40 |
| 1/4 | 549 | 319 | 93.21 | 14.29 |
| 3/8 | 548 | 322 | 93.04 | 15.24 |
| 1/2 | 548 | 330 | 93.04 | 15.81 |
| TP | FP | |
|---|---|---|
| ACF | 543 | 328 |
| Integrated detector | 549 | 319 |
| Method | Deep-Model-Based Body Detector | AMR (%) |
|---|---|---|
| HOG + SVM [13] | No | 45.18 |
| DPM [16] | No | 19.96 |
| ConvNet [29] | No | 17.1 |
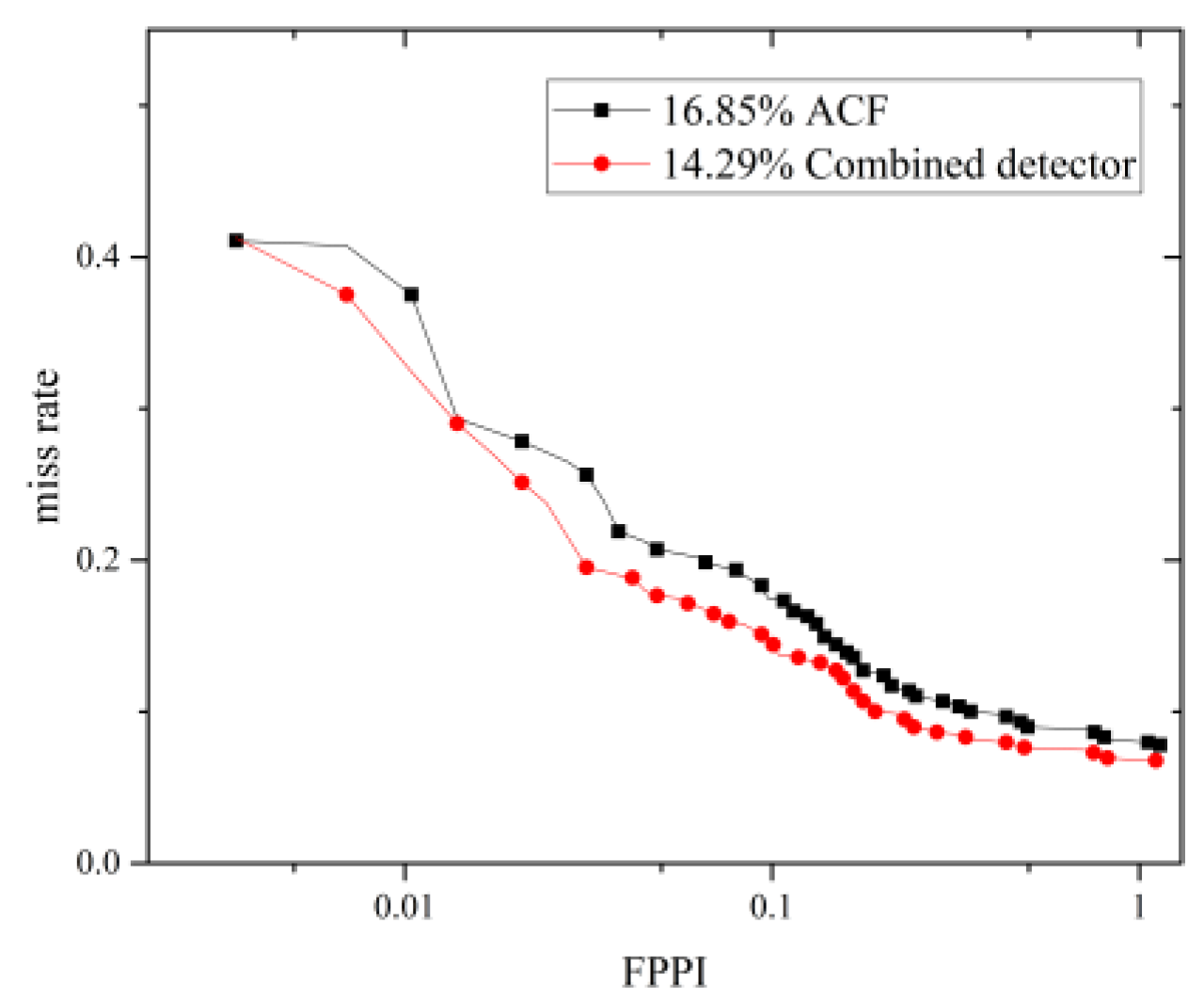
| ACF [14] | No | 16.85 |
| YOLOv3 [18] | Yes | 14.75 |
| ACF + HSC [1] | No | 14.38 |
| Integrated detector (proposed) | No (except for face detection) | 14.29 |
| FRCNN [19] | Yes | 14 |
| FRCNN + BN [19] | Yes | 12 |
| SAR R-CNN [30] | Yes | 8.04 |
| RPN-BF [31] | Yes | 6.9 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| ACF | 2736 | 1900 | 81.89 | 48.79 |
| Integrated detector | 2743 | 1867 | 82.10 | 46.04 |
| TP | FP | R (%) | AMR (%) | |
|---|---|---|---|---|
| ACF | 1250 | 91 | 80.13 | 31.90 |
| Integrated detector | 1268 | 84 | 81.28 | 28.82 |
| Thr 1 | −1 | −0.5 | 0 | 0.5 |
|---|---|---|---|---|
| ACF | 24.41 | 24.41 | 27.77 | 89.01 |
| Integrated detector (ms 2 = 24) | 24.39 | 24.14 | 27.77 | 88.89 |
| Method | Proposed | Proposed 1 | DPM | ACF | HOG + SVM | YOLOv3 |
|---|---|---|---|---|---|---|
| Time cost (s) | 22.99 + 51.33 | 22.99 + 45.24 | 505.26 | 17.13 | 45.98 | 467.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Barmpoutis, P.; Stathaki, T. Pedestrian Detection Using Integrated Aggregate Channel Features and Multitask Cascaded Convolutional Neural-Network-Based Face Detectors. Sensors 2022, 22, 3568. https://doi.org/10.3390/s22093568
Yuan J, Barmpoutis P, Stathaki T. Pedestrian Detection Using Integrated Aggregate Channel Features and Multitask Cascaded Convolutional Neural-Network-Based Face Detectors. Sensors. 2022; 22(9):3568. https://doi.org/10.3390/s22093568
Chicago/Turabian StyleYuan, Jing, Panagiotis Barmpoutis, and Tania Stathaki. 2022. "Pedestrian Detection Using Integrated Aggregate Channel Features and Multitask Cascaded Convolutional Neural-Network-Based Face Detectors" Sensors 22, no. 9: 3568. https://doi.org/10.3390/s22093568
APA StyleYuan, J., Barmpoutis, P., & Stathaki, T. (2022). Pedestrian Detection Using Integrated Aggregate Channel Features and Multitask Cascaded Convolutional Neural-Network-Based Face Detectors. Sensors, 22(9), 3568. https://doi.org/10.3390/s22093568