


Conv-Former: A Novel Network Combining Convolution and Self-Attention for Image Quality Assessment

 , ,
, ,
Abstract
:1. Introduction
- (1)
- By carefully designing a deep neural network with the problem to be solved and the input data, it is possible to automatically learn the relationships implicit within the data from the training dataset without the need for tedious manual feature extraction;
- (2)
- Deep neural network models can contain thousands of parameters; thus, deep features can have better differentiation and representation capabilities. Compared with manually extracted features, it has more prominent advantages in extracting multi-level features and contextual information of images;
- (3)
- Deep learning can change the model architecture by simply adjusting the parameters, which enables the network to automatically model itself according to the specific characteristics of the task, with good generalization and efficiency.
- (1)
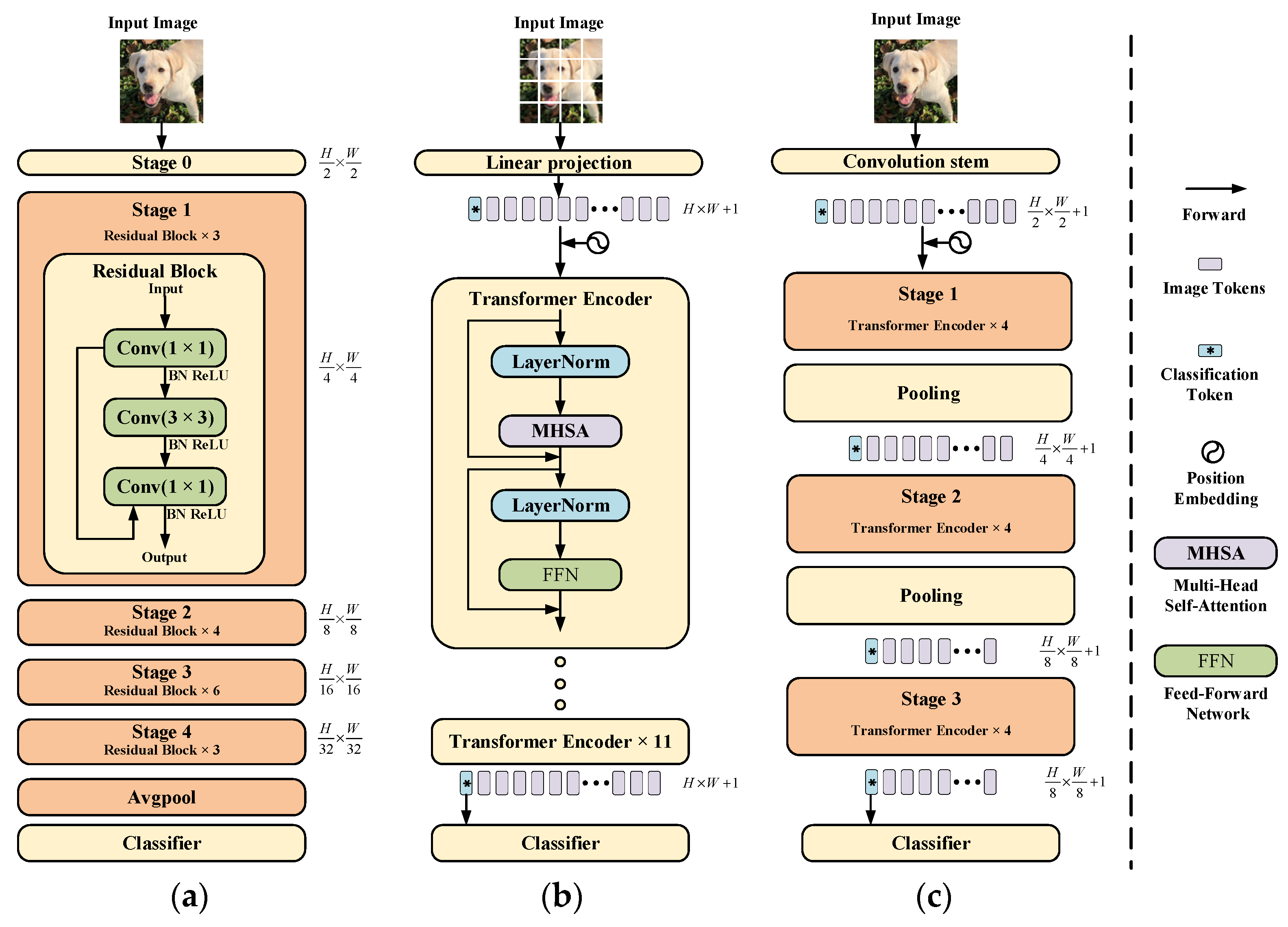
- We designed an end-to-end neural network model called Conv-Former for no-reference image quality assessment. The overall architecture uses a multi-stage architecture similar to that of ResNet-50 to obtain multi-scale features, which can significantly reduce the number of parameters compared to the traditional transformer architecture. At the same time, multi-scale features are more conducive to the extraction of image quality features. This architecture enables the generation of appropriate perceptual mechanisms in image quality assessment to build an accurate IQA model;
- (2)
- In this work, we introduce an effective hybrid architecture for image quality assessment networks that utilize local information from CNNs and global semantic information captured by the transformer to further improve the accuracy of IQA, implemented by replacing the linear layer that generates the qkv matrix with a local information-aware module that is able to further obtain local information in image quality, acquire fine-grained features and obtain detailed and overall information representation in the image. Network analysis experiments also demonstrate that the network outperforms other models for understanding the content of the input images. This enables the neural network to focus better on the subtle differences between images and thus obtain a more accurate image quality score. In order to reduce the image quality information loss in the feature downsampling process under multi-stage architecture, we designed the dual path pooling module to keep more contextual information;
- (3)
- The position embedding of traditional transformer networks cannot adapt to the input of different resolution images and the use of local information perception modules. Therefore, this paper proposes an adaptive 2D position embedding module, which solves the problem that traditional CNN networks cannot input images with different resolutions, and at the same time, the 2D position embedding is more in line with the characteristics of images. It can effectively represent the position information between tokens;
- (4)
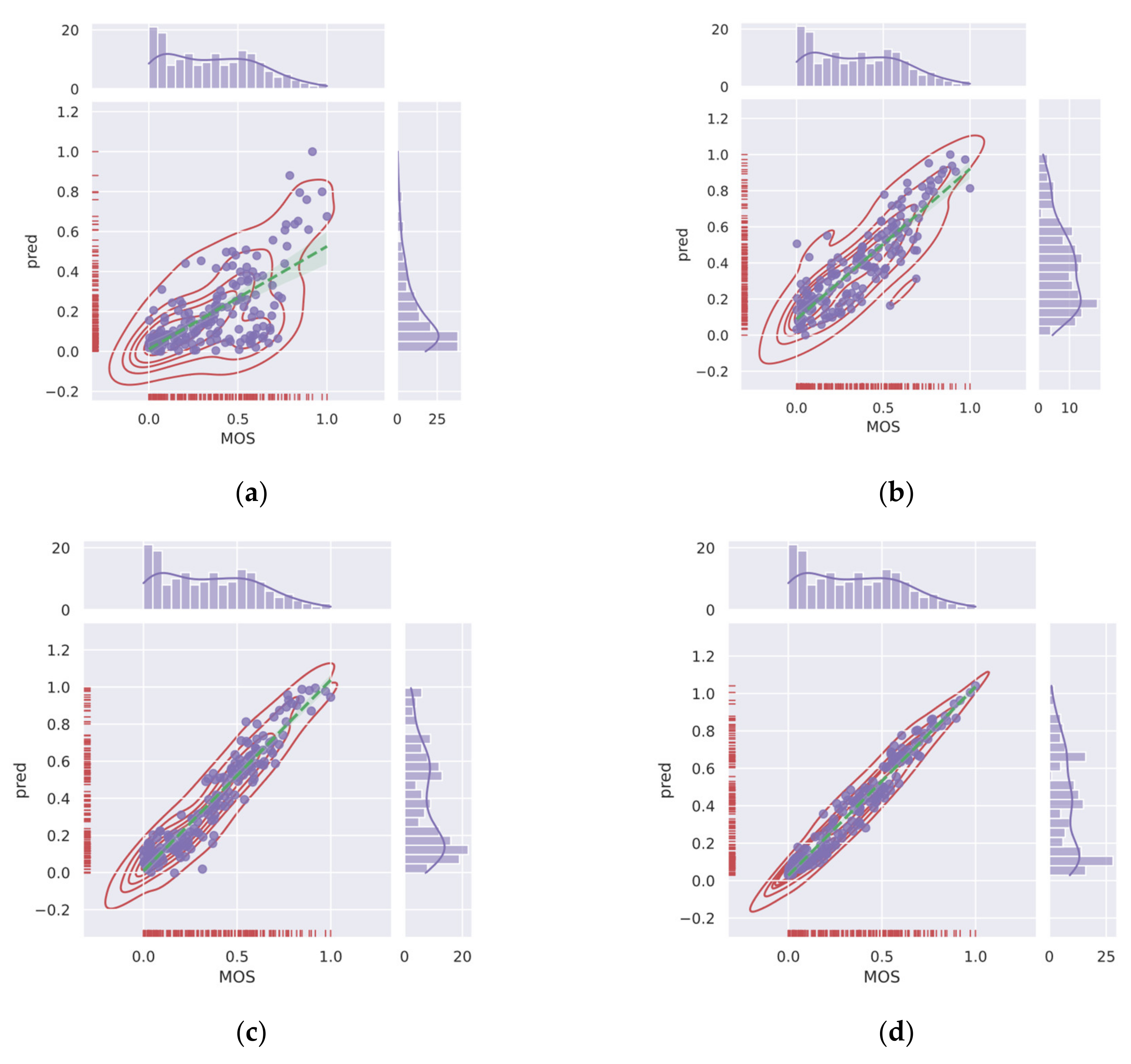
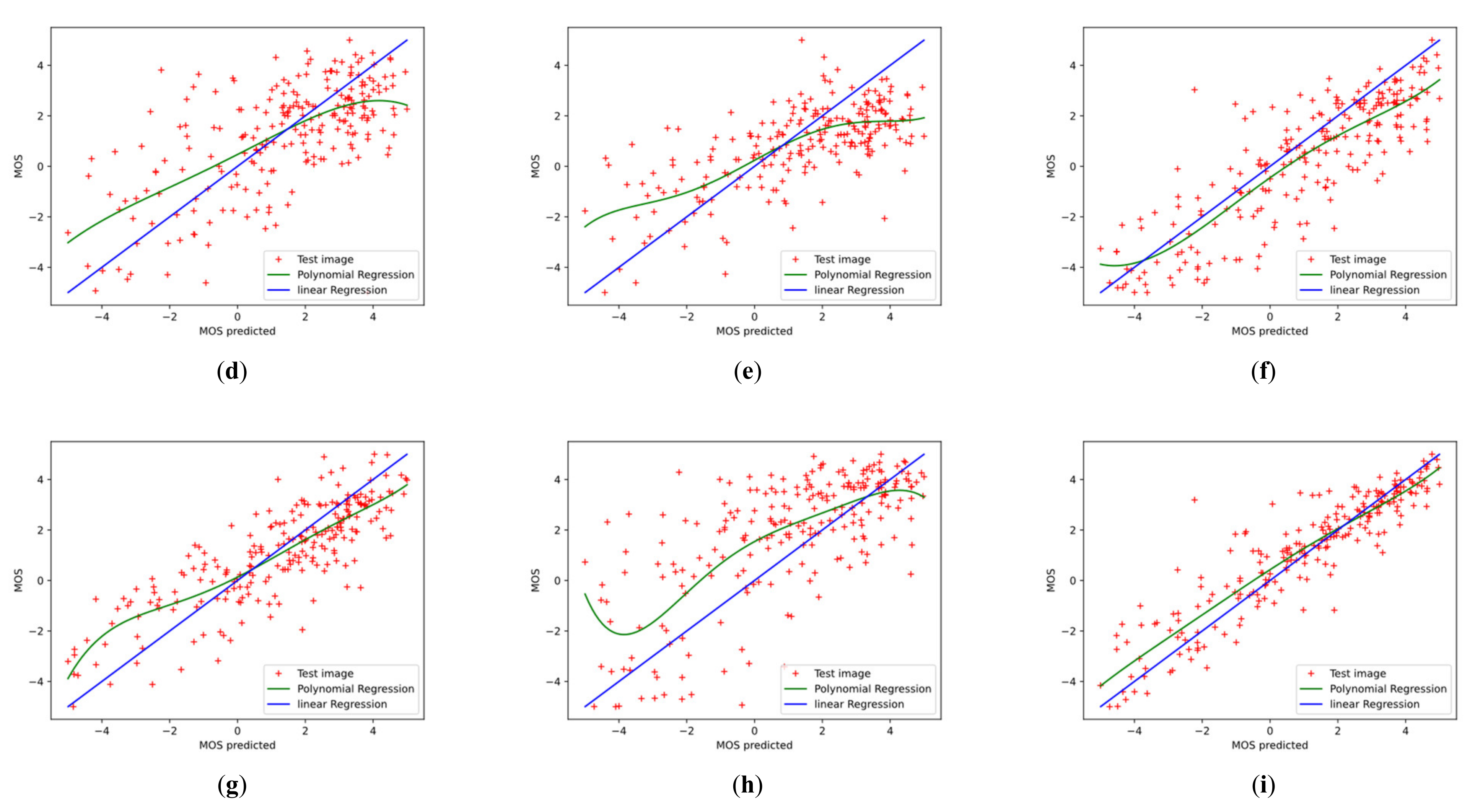
- We experimented with Conv-Former on two different authentic image quality assessment datasets, LIVE Challenge (LIVEC) and KonIQ-10k, as well as on synthetic datasets LIVE, TID2013, and CSIQ, and compared the performance of the algorithm on different distortion types. The extensive experimental results show that Conv-Former has competitive results, which demonstrate the strong fitting performance and generalization capability of our proposed model. As shown in Figure 3, we can find that the results of Conv-Former are more in line with the Mean Opinion Score (MOS).
2. Related Work
2.1. Attention Mechanism in CNN
2.2. No-Reference Image Quality Assessment
3. Proposed Method
3.1. Overview
3.2. Adaptive 2D Position Embedding
3.3. Transformer Block
3.4. Dual Path Pooling
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
- (1)
- Spearman rank-order correlation coefficient (SROCC), SRCC is used to measure the monotonicity of IQA algorithm predictions and is calculated as follows.
- (2)
- The Pearson linear correlation coefficient (PLCC), PLCC is used to assess the accuracy and degree of linear correlation of IQA model predictions.
- (3)
- The root mean square error (RMSE), RMSE is used to assess the consistency of the IQA model’s predictions. It is used to measure the absolute error between the algorithm’s predicted score and the subjective evaluation score and is calculated as follows.
4.3. Implementation Details
4.4. Comparing with the State-of-The Art (SOTA)
4.5. Ablation Studies
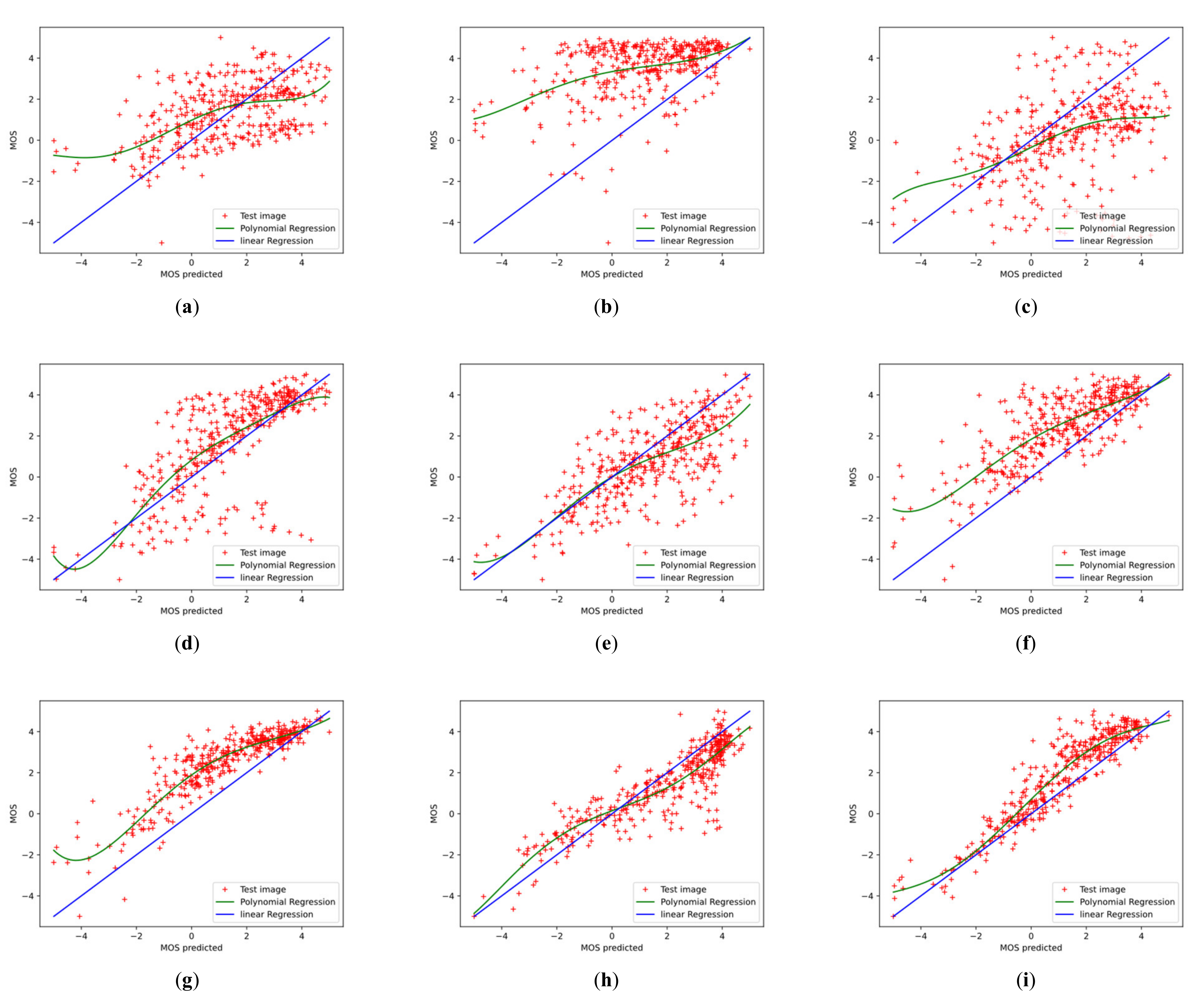
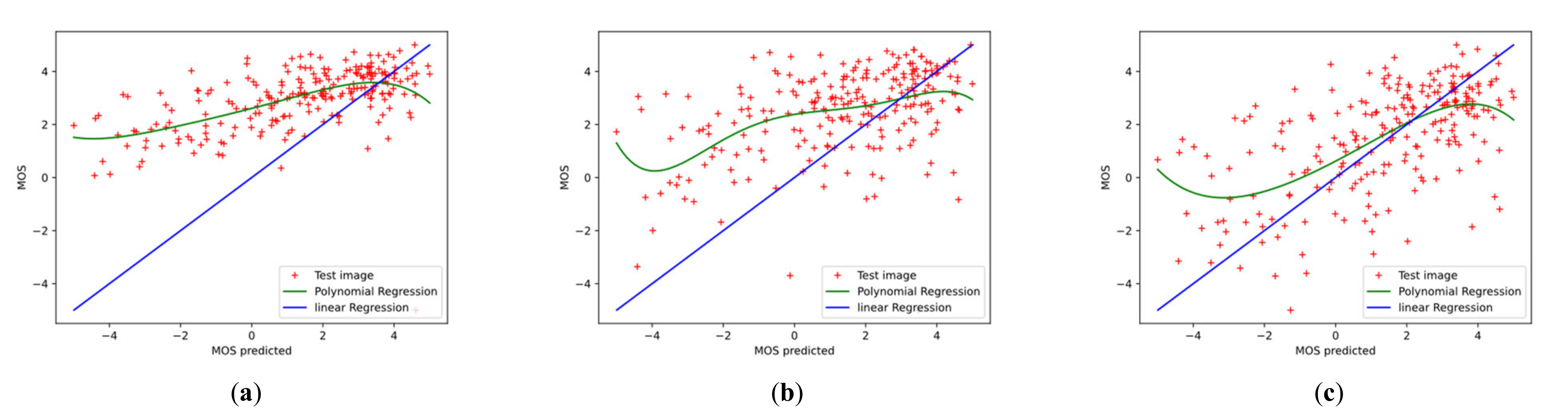
4.6. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Le, Q.-T.; Ladret, P.; Nguyen, H.-T.; Caplier, A. Computational Analysis of Correlations between Image Aesthetic and Image Naturalness in the Relation with Image Quality. J. Imaging 2022, 8, 166. [Google Scholar] [CrossRef] [PubMed]
- Talebi, H.; Milanfar, P. NIMA: Neural Image Assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.T.; Zhao, Y.C.; Lv, H.Y.; Zhang, Y.S.; Liu, H.L.; Bi, G.L. Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sens. 2022, 14, 23. [Google Scholar] [CrossRef]
- Zhang, W.X.; Ma, K.D.; Yan, J.; Deng, D.X.; Wang, Z. Blind Image Quality Assessment Using a Deep Bilinear Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Hui, Q.; Sheng, Y.X.; Yang, L.K.; Li, Q.M.; Chai, L. Reduced-Reference Image Quality Assessment for Single-Image Super-Resolution Based on Wavelet Domain. In Proceedings of the 31st Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 2067–2071. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Xu, J.T.; Ye, P.; Li, Q.H.; Du, H.Q.; Liu, Y.; Doermann, D. Blind Image Quality Assessment Based on High Order Statistics Aggregation. IEEE Trans. Image Process. 2016, 25, 4444–4457. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Kim, J.; Lee, S. Fully Deep Blind Image Quality Predictor. IEEE J. Sel. Top. Signal Process. 2017, 11, 206–220. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12175–12185. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Graves, A.; Mohamed, A.-r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wang, S.; Ma, K.; Yeganeh, H.; Wang, Z.; Lin, W. A patch-structure representation method for quality assessment of contrast changed images. IEEE Signal Process. Lett. 2015, 22, 2387–2390. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X. No-reference quality assessment for contrast-distorted images. IEEE Access 2020, 8, 84105–84115. [Google Scholar] [CrossRef]
- Gu, K.; Lin, W.; Zhai, G.; Yang, X.; Zhang, W.; Chen, C.W. No-reference quality metric of contrast-distorted images based on information maximization. IEEE Trans. Cybern. 2016, 47, 4559–4565. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. A Two-Step Framework for Constructing Blind Image Quality Indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. Blind Image Quality Assessment: From Natural Scene Statistics to Perceptual Quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT Statistics-Based Blind Image Quality Index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef] [Green Version]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind Image Quality Assessment: A Natural Scene Statistics Approach in the DCT Domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised Feature Learning Framework for No-reference Image Quality Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Zhang, P.; Zhou, W.G.; Wu, L.; Li, H.Q. SOM: Semantic Obviousness Metric for Image Quality Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2394–2402. [Google Scholar]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process.-Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 21. [Google Scholar]
- Ghadiyaram, D.; Bovik, A.C. Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans. Image Process. 2015, 25, 372–387. [Google Scholar] [CrossRef] [Green Version]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [Green Version]
- Ponomarenko, N.; Lukin, V.; Zelensky, A.; Egiazarian, K.; Carli, M.; Battisti, F. TID2008—A database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectron. 2009, 10, 30–45. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.-J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Reference Image | Distorted Image | Distorted Type | Score Type | Score Range |
|---|---|---|---|---|---|
| LIVE | 29 | 779 | 5 | DMOS * | [0, 100] |
| TID2013 | 25 | 3000 | 24 | MOS | [0, 9] |
| CSIQ | 30 | 866 | 6 | DMOS | [0, 1] |
| LIVE Challenge | - | 1162 | - | MOS | [0, 100] |
| KonIQ-10k | - | 10,073 | - | MOS | [0, 5] |
| Methods | LIVEC | KonIQ | TID2013 | LIVE | CSIQ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PLCC | SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | SRCC | |
| BRISQUE | 0.629 | 0.608 | 0.681 | 0.665 | 0.694 | 0.604 | 0.935 | 0.939 | 0.829 | 0.746 |
| NIQE | 0.415 | 0.373 | 0.489 | 0.516 | 0.426 | 0.317 | 0.908 | 0.908 | 0.725 | 0.627 |
| DIIVINE | 0.595 | 0.576 | 0.479 | 0.434 | 0.672 | 0.583 | 0.881 | 0.879 | 0.836 | 0.784 |
| HOSA | 0.678 | 0.640 | 0.694 | 0.671 | 0.815 | 0.735 | 0.947 | 0.946 | 0.823 | 0.741 |
| WaDIQaM | 0.680 | 0.671 | 0.805 | 0.797 | 0.787 | 0.761 | 0.963 | 0.954 | 0.973 | 0.955 |
| BIECON | 0.613 | 0.595 | 0.651 | 0.618 | 0.762 | 0.717 | 0.962 | 0.961 | 0.823 | 0.815 |
| SFA | 0.833 | 0.812 | 0.872 | 0.856 | 0.873 | 0.861 | 0.895 | 0.883 | 0.818 | 0.796 |
| PQR | 0.882 | 0.857 | 0.884 | 0.880 | 0.798 | 0.739 | 0.971 | 0.965 | 0.901 | 0.873 |
| DBCNN | 0.869 | 0.851 | 0.884 | 0.875 | - | - | 0.971 | 0.968 | 0.959 | 0.946 |
| SHN | 0.882 | 0.859 | 0.917 | 0.906 | - | - | 0.966 | 0.962 | 0.942 | 0.923 |
| RankIQA | - * | - | - | - | 0.810 | 0.780 | 0.982 | 0.981 | - | - |
| ResNet-ft | 0.849 | 0.819 | - | - | 0.756 | 0.712 | 0.954 | 0.950 | 0.905 | 0.876 |
| TRIQ | - | - | 0.922 | 0.910 | - | - | - | - | - | - |
| MUSIQ | - | - | 0.928 | 0.916 | - | - | - | - | - | - |
| Ours | 0.899 | 0.868 | 0.938 | 0.924 | 0.965 | 0.964 | 0.979 | 0.971 | 0.978 | 0.964 |
| Methods | JPEG | JPEG200 | WN | GB | FF | |
|---|---|---|---|---|---|---|
| PLCC | BRISQUE | 0.971 | 0.940 | 0.989 | 0.965 | 0.894 |
| HOSA | 0.967 | 0.949 | 0.983 | 0.967 | 0.967 | |
| CORNIA | 0.962 | 0.944 | 0.974 | 0.961 | 0.943 | |
| DBCNN | 0.986 | 0.967 | 0.988 | 0.956 | 0.961 | |
| Ours | 0.987 | 0.977 | 0.986 | 0.974 | 0.970 | |
| SRCC | BRISQUE | 0.965 | 0.929 | 0.982 | 0.966 | 0.828 |
| HOSA | 0.954 | 0.935 | 0.975 | 0.954 | 0.954 | |
| CORNIA | 0.947 | 0.924 | 0.958 | 0.951 | 0.921 | |
| DBCNN | 0.972 | 0.955 | 0.980 | 0.935 | 0.930 | |
| Ours | 0.974 | 0.960 | 0.971 | 0.965 | 0.965 |
| Methods | JPEG | JPEG200 | WN | GB | PN | CC | |
|---|---|---|---|---|---|---|---|
| PLCC | BRISQUE | 0.828 | 0.887 | 0.742 | 0.891 | 0.496 | 0.835 |
| HOSA | 0.759 | 0.899 | 0.656 | 0.912 | 0.601 | 0.744 | |
| CORNIA | 0.563 | 0.883 | 0.687 | 0.904 | 0.632 | 0.543 | |
| DBCNN | 0.982 | 0.971 | 0.956 | 0.969 | 0.950 | 0.895 | |
| MEON | 0.979 | 0.925 | 0.958 | 0.946 | - | - | |
| Ours | 0.966 | 0.987 | 0.951 | 0.976 | 0.982 | 0.947 | |
| SRCC | BRISQUE | 0.806 | 0.840 | 0.723 | 0.820 | 0.378 | 0.804 |
| HOSA | 0.733 | 0.818 | 0.604 | 0.841 | 0.500 | 0.716 | |
| CORNIA | 0.513 | 0.831 | 0.664 | 0.836 | 0.493 | 0.462 | |
| DBCNN | 0.940 | 0.953 | 0.948 | 0.947 | 0.940 | 0.870 | |
| MEON | 0.948 | 0.898 | 0.951 | 0.918 | - | - | |
| Ours | 0.969 | 0.980 | 0.975 | 0.945 | 0.965 | 0.924 |
| Train | Test | Methods | ||||||
|---|---|---|---|---|---|---|---|---|
| BRISQUE | M3 | FRIQUEE | CORNIA | HOSA | DB-CNN | Ours | ||
| LIVE | CSIQ | 0.562 | 0.621 | 0.722 | 0.649 | 0.594 | 0.758 | 0.762 |
| TID2013 | 0.358 | 0.344 | 0.461 | 0.360 | 0.361 | 0.524 | 0.563 | |
| LIVEC | 0.337 | 0.226 | 0.411 | 0.443 | 0.463 | 0.567 | 0.572 | |
| CSIQ | LIVE | 0.847 | 0.797 | 0.879 | 0.853 | 0.773 | 0.877 | 0.864 |
| TID2013 | 0.454 | 0.328 | 0.463 | 0.312 | 0.329 | 0.540 | 0.572 | |
| LIVEC | 0.131 | 0.183 | 0.264 | 0.393 | 0.291 | 0.452 | 0.463 | |
| TID2013 | LIVE | 0.790 | 0.873 | 0.755 | 0.846 | 0.846 | 0.891 | 0.894 |
| CSIQ | 0.590 | 0.605 | 0.635 | 0.672 | 0.612 | 0.807 | 0.853 | |
| LIVEC | 0.254 | 0.112 | 0.181 | 0.293 | 0.319 | 0.457 | 0.524 | |
| LIVEC | LIVE | 0.238 | 0.059 | 0.644 | 0.588 | 0.537 | 0.746 | 0.752 |
| CSIQ | 0.241 | 0.109 | 0.592 | 0.446 | 0.336 | 0.697 | 0.711 | |
| TID2013 | 0.280 | 0.058 | 0.424 | 0.403 | 0.399 | 0.424 | 0.417 | |
| Methods | LIVEC | KonIQ | CSIQ | TID2013 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| APE | MS | LIP | DPP | PLCC | SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | SRCC |
| × | ✓ | ✓ | ✓ | 0.871 | 0.856 | 0.922 | 0.913 | 0.972 | 0.953 | 0.958 | 0.945 |
| ✓ | × | ✓ | ✓ | 0.893 | 0.866 | 0.925 | 0.916 | 0.973 | 0.960 | 0.959 | 0.950 |
| ✓ | ✓ | × | ✓ | 0.881 | 0.860 | 0.928 | 0.921 | 0.970 | 0.961 | 0.955 | 0.948 |
| ✓ | ✓ | ✓ | × | 0.890 | 0.862 | 0.933 | 0.923 | 0.975 | 0.963 | 0.963 | 0.960 |
| ✓ | ✓ | × | × | 0.882 | 0.858 | 0.930 | 0.921 | 0.969 | 0.956 | 0.961 | 0.950 |
| ✓ | × | ✓ | × | 0.894 | 0.859 | 0.924 | 0.914 | 0.972 | 0.961 | 0.960 | 0.952 |
| ✓ | × | × | ✓ | 0.878 | 0.854 | 0.929 | 0.918 | 0.965 | 0.953 | 0.949 | 0.938 |
| ✓ | ✓ | ✓ | ✓ | 0.899 | 0.868 | 0.938 | 0.924 | 0.978 | 0.964 | 0.965 | 0.964 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Lv, H.; Zhao, Y.; Liu, H.; Bi, G.; Yin, Z.; Fang, Y. Conv-Former: A Novel Network Combining Convolution and Self-Attention for Image Quality Assessment. Sensors 2023, 23, 427. https://doi.org/10.3390/s23010427
Han L, Lv H, Zhao Y, Liu H, Bi G, Yin Z, Fang Y. Conv-Former: A Novel Network Combining Convolution and Self-Attention for Image Quality Assessment. Sensors. 2023; 23(1):427. https://doi.org/10.3390/s23010427
Chicago/Turabian StyleHan, Lintao, Hengyi Lv, Yuchen Zhao, Hailong Liu, Guoling Bi, Zhiyong Yin, and Yuqiang Fang. 2023. "Conv-Former: A Novel Network Combining Convolution and Self-Attention for Image Quality Assessment" Sensors 23, no. 1: 427. https://doi.org/10.3390/s23010427
APA StyleHan, L., Lv, H., Zhao, Y., Liu, H., Bi, G., Yin, Z., & Fang, Y. (2023). Conv-Former: A Novel Network Combining Convolution and Self-Attention for Image Quality Assessment. Sensors, 23(1), 427. https://doi.org/10.3390/s23010427