

Improved Face Detection Method via Learning Small Faces on Hard Images Based on a Deep Learning Approach


 ,
,  and
and
Abstract
:1. Introduction
2. Related Work
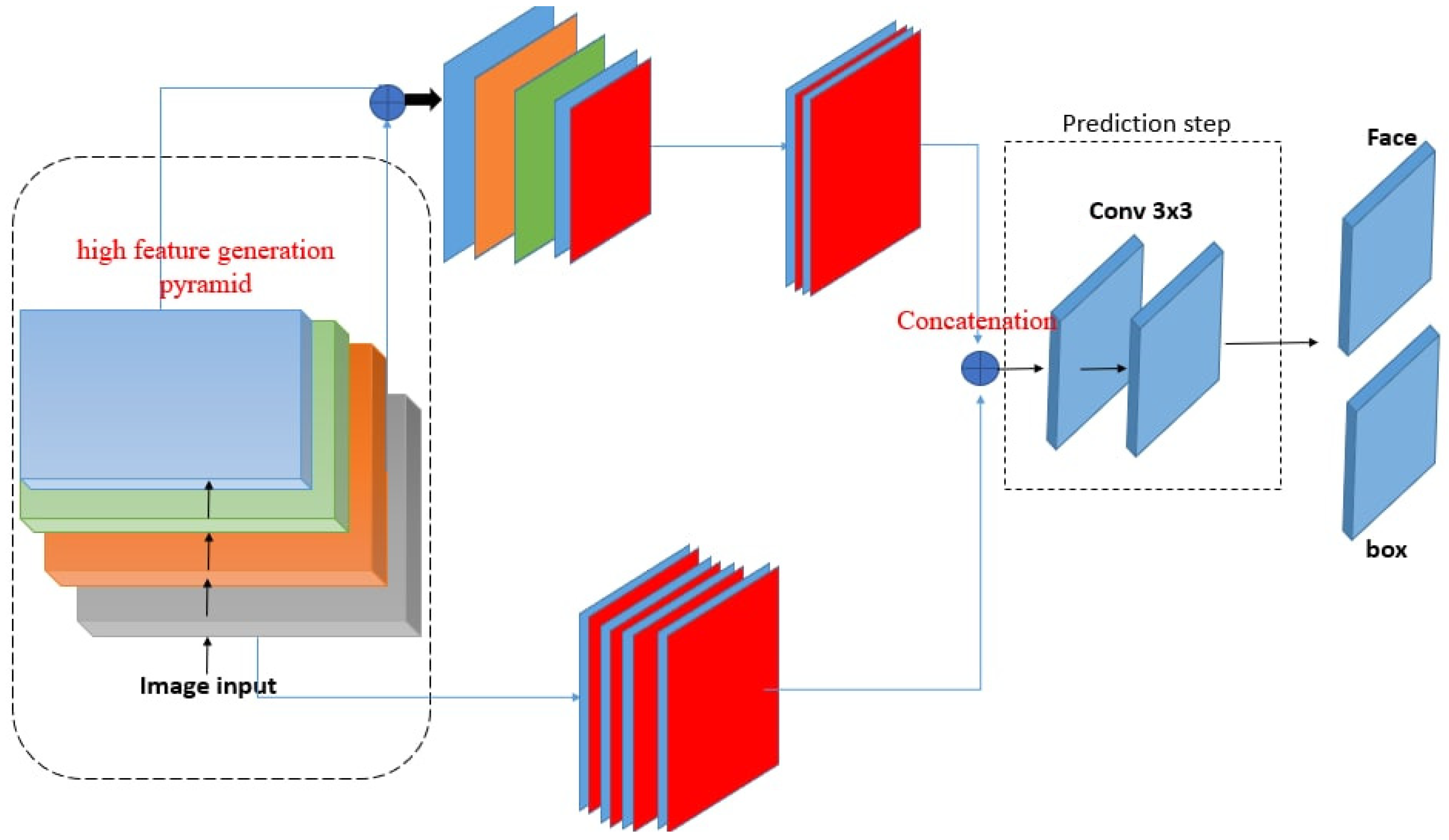
3. Proposed Face Detection Method
3.1. Feature Extraction—Region Offering Network
3.2. High Feature Generation Pyramid (HFGP)
3.3. Low Feature Generation Pyramid (LFGP)
3.4. Prediction Step
3.5. Concatenation
4. Implementation and Results
4.1. Implementation Details
4.2. The Process Speediness
4.3. Evaluation Metrics
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Markuš, N.; Frljak, M.; Pandžić, I.S.; Ahlberg, J.; Forchheimer, R. Fast Localization of Facial Landmark Points. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H. Multi-task Learning of Cascaded CNN for Facial Attribute Classification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Guo, J.; Zhu, X.; Yang, Y.; Yang, F.; Lei, Z.; Li, S.Z. Towards Fast, Accurate and Stable 3D Dense Face Alignment. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Deng, J.; Guo, J.; An, X.; Zhu, Z.; Zafeiriou, S. Masked Face Recognition Challenge: The InsightFace Track Report. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.-C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale-invariant face detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Akmalbek, A.; Djurayev, A. Robust shadow removal technique for improving image enhancement based on segmentation method. IOSR J. Electron. Commun. Eng. 2016, 11, 17–21. [Google Scholar]
- Abdusalomov, A.; Whangbo, T.K.; Djuraev, O. A Review on various widely used shadow detection methods to identify a shadow from images. Int. J. Sci. Res. Publ. 2016, 6, 2250–3153. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the NeurIPS, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kuldoshbay, A.; Abdusalomov, A.; Mukhiddinov, M.; Baratov, N.; Makhmudov, F.; Cho, Y.I. An improvement for the automatic classification method for ultrasound images used on CNN. Int. J. Wavelets Multiresolution Inf. Process. 2022, 20, 2150054. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 17 September 2016. [Google Scholar]
- Wang, H.; Li, Z.; Ji, X.; Wang, Y. Face R-CNN. arXiv 2017, arXiv:1706.01061. [Google Scholar]
- Wang, Y.; Ji, X.; Zhou, Z.; Wang, H.; Li, Z. Detecting Faces Using Region-based Full Convolution Networks. In Proceedings of the Computer Vision and Pattern Recognition (cs. CV), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Najibi, M.; Samangouuei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Datector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Farkhod, A.; Abdusalomov, A.B.; Mukhiddinov, M.; Cho, Y.-I. Development of Real-Time Landmark-Based Emotion Recognition CNN for Masked Faces. Sensors 2022, 22, 8704. [Google Scholar] [CrossRef]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A contextassisted single shot face detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z.; Li, S.Z.; Zou, X. Selective refinement network for high performance face detection. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual shot face detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, C.; Xu, X.; Tu, D. Face detection using improved faster rcnn. arXiv 2018, arXiv:1802.02142. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dang, K.; Sharma, S. Review and comparison of face detection algorithms. In Proceedings of the Cloud Computing, Data Science & Engineering Confluence, 2017 7th International Conference on IEEE, Noida, India, 12–13 January 2017; pp. 629–633. [Google Scholar]
- Valenzuela, W.; Soto, J.E.; Zarkesh-Ha, P.; Figueroa, M. Face Recognition on a Smart Image Sensor Using Local Gradients. Sensors 2021, 21, 2901. [Google Scholar] [CrossRef]
- Setyawan, I.; Timotius, I.K. A Frontal Pose Face Detection and Classification System Based on Haar Wavelet Coefficients and Support Vector Machine. Int. J. Inf. Electron. Eng. 2012, 1, 276. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhu, C.; Zheng, Y.; Luu, K.; Savvides, M. Cms-rcnn: Contextual multi-scale region-based cnn for unconstrained face detection. In Deep Learning for Biometrics; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O.; Cho, J. Automatic Speech Recognition Method Based on Deep Learning Approaches for Uzbek Language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 951–959. [Google Scholar]
- Zhu, C.; Tao, R.; Luu, K.; Savvides, M. Seeing small faces from robust anchor’s perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5127–5136. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. Faceboxes: A cpu real-time face detector with high accuracy. In Proceedings of the IEEE International Joint Conference on Biometrics, Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar]
- Jain, V.; Learned-Miller, E. FDDB: A Benchmark for Face Detection in Unconstrained Settings; Technical Report UMCS-2010-009; University of Massachusetts: Amherst, MA, USA, 2010. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-based Object Detectors with Online Hard Example Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Sydney, Australia, 2019; pp. 91–98, 024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf (accessed on 12 September 2022).
- Abdusalomov, A.B.; Mukhiddinov, M.; Kutlimuratov, A.; Whangbo, T.K. Improved Real-Time Fire Warning System Based on Advanced Technologies for Visually Impaired People. Sensors 2022, 22, 7305. [Google Scholar] [CrossRef] [PubMed]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef] [PubMed]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y.I. Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5. Sensors 2022, 22, 9384. [Google Scholar] [CrossRef]
- Wafa, R.; Khan, M.Q.; Malik, F.; Abdusalomov, A.B.; Cho, Y.I.; Odarchenko, R. The Impact of Agile Methodology on Project Success, with a Moderating Role of Person’s Job Fit in the IT Industry of Pakistan. Appl. Sci. 2022, 12, 10698. [Google Scholar] [CrossRef]
- Umirzakova, S.; Abdusalomov, A.; Whangbo, T.K. Fully Automatic Stroke Symptom Detection Method Based on Facial Features and Moving Hand Differences. In Proceedings of the 2019 International Symposium on Multimedia and Communication Technology (ISMAC), Quezon City, Philippines, 19–21 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic salient object extraction based on locally adaptive thresholding to generate tactile graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Makhmudov, F.; Mukhiddinov, M.; Abdusalomov, A.; Avazov, K.; Khamdamov, U.; Cho, Y.I. Improvement of the end-to-end scene text recognition method for “text-to-speech” conversion. Int. J. Wavelets Multiresolut. Inf. Process. 2020, 18, 2050052. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. An improvement for the foreground recognition method using shadow removal technique for indoor environments. Int. J. Wavelets Multiresolut. Inf. Process. 2017, 15, 1750039. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. Detection and Removal of Moving Object Shadows Using Geometry and Color Information for Indoor Video Streams. Appl. Sci. 2019, 9, 5165. [Google Scholar] [CrossRef] [Green Version]
- Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS). Model. Appl. Sci. 2021, 11, 11091. [Google Scholar] [CrossRef]
- Jakhongir, N.; Abdusalomov, A.; Whangbo, T.K. 3D Volume Reconstruction from MRI Slices based on VTK. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2021; pp. 689–692. [Google Scholar] [CrossRef]
- Ayvaz, U.; Gürüler, H.; Khan, F.; Ahmed, N.; Whangbo, T.; Abdusalomov, A. Automatic Speaker Recognition Using Mel-Frequency Cepstral Coefficients through Machine Learning. CMC-Comput. Mater. Contin. 2022, 71, 5511–5521. [Google Scholar] [CrossRef]
- Avazov, K.; Abdusalomov, A.; Cho, Y.I. Automatic moving shadow detection and removal method for smart city environments. J. Korean Inst. Intell. Syst. 2020, 30, 181–188. [Google Scholar] [CrossRef]
- Khan, F.; Tarimer, I.; Alwageed, H.S.; Karadağ, B.C.; Fayaz, M.; Abdusalomov, A.B.; Cho, Y.-I. Effect of Feature Selection on the Accuracy of Music Popularity Classification Using Machine Learning Algorithms. Electronics 2022, 11, 3518. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Safarov, F.; Rakhimov, M.; Turaev, B.; Whangbo, T.K. Improved Feature Parameter Extraction from Speech Signals Using Machine Learning Algorithm. Sensors 2022, 22, 8122. [Google Scholar] [CrossRef]
- Nodirov, J.; Abdusalomov, A.B.; Whangbo, T.K. Attention 3D U-Net with Multiple Skip Connections for Segmentation of Brain Tumor Images. Sensors 2022, 22, 6501. [Google Scholar] [CrossRef]
- Kutlimuratov, A.; Abdusalomov, A.B.; Oteniyazov, R.; Mirzakhalilov, S.; Whangbo, T.K. Modeling and Applying Implicit Dormant Features for Recommendation via Clustering and Deep Factorization. Sensors 2022, 22, 8224. [Google Scholar] [CrossRef]
- Safarov, F.; Temurbek, K.; Jamoljon, D.; Temur, O.; Chedjou, J.C.; Abdusalomov, A.B.; Cho, Y.-I. Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture. Sensors 2022, 22, 9784. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blur | Expression | Illumination | Occlusion | Pose | ||
|---|---|---|---|---|---|---|
| Normal Blur | Heavy Blur | Severe Expression | Severe Illumination | limited Occlusion | Hard Occlusion | Unusual Pose |
| 0.5 | 1 | 1 | 1 | 0.5 | 1 | 1 |
| Method | mAP | Time |
|---|---|---|
| [A] YOLO3–608 | 33.0 | 51 |
| [B] SSD–321 | 28.0 | 61 |
| [B *] SSD–321 | 28.2 | 22 |
| [C] DSSA-321 | 28.0 | 85 |
| [D] R-FCN | 29.9 | 85 |
| [E] SSD–513 | 31.2 | 125 |
| [E*] SSD–513 | 31.0 | 37 |
| [F] DSSD–513 | 33.2 | 156 |
| [G] FPN FRCN | 36.2 | 172 |
| [H *] CornerNet | 40.5 | 228 |
| RetinaNet | 39.1 | 198 |
| [*] RefineDet | 36.7 | 110 |
| Ours | 41.0 | 84.7 |
| Method | Backbone | Input Size | MultiScale | FPS | Avg. Precision, IoU: | Avg. Precision, Area: | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.5:0.95 | 0.5 | 0.75 | S | M | L | |||||
| two-stage: | ||||||||||
| Faster R-CNN (Ren et al., 2015) | VGG-16 | ~1000 × 600 | False | 7 | 21.9 | 42.7 | - | - | - | - |
| OHEM ++ (Shrivastava et al., 2016) | VGG-16 | ~1000 × 600 | FALSE | 7 | 25.5 | 45.9 | 26.1 | 7.4 | 27.7 | 40.3 |
| R-FCN (Dai et al., 2016) | ResNet-101 | ~1000 × 600 | FALSE | 9 | 29.9 | 51.9 | - | 10.8 | 32.8 | 45.0 |
| CoupleNet (Zhu et al., 2017) | ResNet-101 | ~1000 × 600 | FALSE | 8.2 | 34.4 | 54.8 | 37.2 | 13.4 | 38.1 | 50.8 |
| Faster R-CNN w FPN (Lin et al., 2017a) | Res101-FPN | ~1000 × 600 | FALSE | 6 | 36.2 | 59.1 | 39.0 | 18.2 | 39.0 | 48.2 |
| Deformable R–FCN (Dai et al., 2017) | Inc-Res-v2 | ~1000 × 600 | FALSE | - | 37.5 | 58.0 | 40.8 | 19.4 | 40.1 | 52.5 |
| Mask R-CNN (He et al., 2017) | ResNeXt-101 | ~1280 × 800 | FALSE | 3.3 | 39.8 | 62.3 | 43.4 | 22.1 | 43.2 | 51.2 |
| Fitness–NMS (Tychen–Smith and Petersson 2018) | ResNet-101 | ~1024 × 1024 | True | 5 | 41.8 | 60.9 | 44.9 | 21.5 | 45.0 | 57.5 |
| Cascade R-CNN (Cai and Vasconcelos 2018) | Res101-FPN | ~1280 × 800 | FALSE | 7.1 | 42.8 | 62.1 | 46.3 | 23.7 | 45.5 | 55.2 |
| SNIP (Singh and Davis 2018) | DPN-98 | - | TRUE | - | 45.7 | 67.3 | 51.1 | 29.3 | 48.8 | 57.1 |
| one–stage: | ||||||||||
| SSD300*(Liu et al., 2016) | VGG-16 | 300 × 300 | FALSE | 43 | 25.1 | 43.1 | 25.8 | 6.6 | 25.9 | 41.4 |
| RON384++ (Kong et al., 2017) | VGG-16 | 384 × 384 | FALSE | 15 | 27.4 | 49.5 | 27.1 | - | - | - |
| DSSD321 (Fu et al., 2017) | ResNet-101 | 321 × 321 | FALSE | 9.5 | 28.0 | 46.1 | 29.2 | 7.4 | 28.1 | 47.6 |
| RetinaNet 400(Lin et al., 2017b) | ResNet-101 | ~640 × 400 | FALSE | 12.3 | 31.9 | 49.5 | 34.1 | 11.6 | 35.8 | 48.5 |
| RefineDet320(Zhang et al., 2018) | VGG-16 | 320 × 320 | FALSE | 38.7 | 29.4 | 49.2 | 31.3 | 10.0 | 32.0 | 44.4 |
| RefineDet320(Zhang et al., 2018 | ResNet-101 | 320 × 320 | TRUE | - | 38.6 | 59.9 | 41.7 | 21.1 | 41.5 | 47.6 |
| Ours | VGG-16 | 320 × 320 | FALSE | 33.4 | 33.5 | 52.4 | 35.6 | 14.4 | 37.6 | 47.6 |
| Ours | VGG-16 | 320 × 320 | TRUE | - | 38.9 | 59.1 | 42.4 | 24.4 | 41.5 | 47.6 |
| Ours | ResNet-101 | 320 × 320 | FALSE | 21.7 | 34.3 | 53.5 | 36.5 | 14.8 | 38.8 | 47.9 |
| Ours | ResNet-101 | 320 × 320 | TRUE | - | 39.7 | 60.0 | 43.3 | 25.3 | 42.5 | 48.3 |
| YOLOV3 (Redmon and Farhadi 2018) | DarkNet-53 | 608 × 608 | FALSE | 19.8 | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| SSD512* (Liu et al., 2016) | VGG-16 | 512 × 512 | FALSE | 22 | 28.8 | 48.5 | 30.3 | 10.9 | 31.8 | 43.5 |
| DSSD513 (Fu et al., 2017) | ResNet-101 | 513 × 513 | FALSE | 5.5 | 33.2 | 53.3 | 35.2 | 13.0 | 35.4 | 51.1 |
| RetinaNet500 (Lin et al., 2017b) | ResNet-101 | ~832 × 500 | FALSE | 11.1 | 34.4 | 53.1 | 36.8 | 14.7 | 38.5 | 49.1 |
| RefineDet512 (Zhang et al., 2018) | VGG-16 | 512 × 512 | FALSE | 22.3 | 33.0 | 54.5 | 35.5 | 16.3 | 36.3 | 44.3 |
| RefineDet512 (Zhang et al., 2018) | ResNet-101 | 512 × 512 | TRUE | - | 41.8 | 62.9 | 45.7 | 25.6 | 45.1 | 54.1 |
| CornerNet (Law and Deng 2018) | Hourglass | 512 × 512 | FALSE | 4.4 | 40.5 | 57.8 | 45.3 | 20.8 | 44.8 | 56.7 |
| CornerNet (Law and Deng 2018) | Hourglass | 512 × 512 | TRUE | - | 42.1 | 57.8 | 45.3 | 20.8 | 44.8 | 56.7 |
| Ours | VGG-16 | 512 × 512 | FALSE | 18 | 37.6 | 56.6 | 40.5 | 18.4 | 43.4 | 51.2 |
| Ours | VGG-16 | 512 × 512 | TRUE | - | 42.9 | 62.5 | 47.7 | 28.0 | 47.4 | 52.8 |
| Ours | ResNet-101 | 512 × 512 | FALSE | 15.8 | 38.8 | 59.4 | 41.7 | 20.5 | 43.9 | 53.4 |
| Ours | ResNet-101 | 512 × 512 | TRUE | - | 43.9 | 64.4 | 48.0 | 29.6 | 49.6 | 54.3 |
| RetinaNet800 (Lin et al., 2017b) | Res101–FPN | ~1280 × 800 | FALSE | 5 | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| Ours | VGG-16 | 800 × 800 | FALSE | 11.8 | 41.0 | 59.7 | 45.0 | 22.1 | 46.5 | 53.8 |
| Ours | VGG-16 | 800 × 800 | True | - | 44.2 | 64.6 | 49.3 | 29.2 | 47.9 | 55.1 |
| Algorithm | Precision | Recall | FM | Average |
|---|---|---|---|---|
| Faster R-CNN | 0.834 | 0.939 | 0.902 | 0.891 |
| CoupleNet | 0.968 | 0.881 | 0.921 | 0.923 |
| Mask R-CNN | 0.801 | 0.877 | 0.883 | 0.853 |
| CornerNet | 0.911 | 0.904 | 0.912 | 0.909 |
| YOLOv3 | 0.941 | 0.929 | 0.932 | 0.934 |
| Proposed method | 0.954 | 0.958 | 0.956 | 0.956 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mamieva, D.; Abdusalomov, A.B.; Mukhiddinov, M.; Whangbo, T.K. Improved Face Detection Method via Learning Small Faces on Hard Images Based on a Deep Learning Approach. Sensors 2023, 23, 502. https://doi.org/10.3390/s23010502
Mamieva D, Abdusalomov AB, Mukhiddinov M, Whangbo TK. Improved Face Detection Method via Learning Small Faces on Hard Images Based on a Deep Learning Approach. Sensors. 2023; 23(1):502. https://doi.org/10.3390/s23010502
Chicago/Turabian StyleMamieva, Dilnoza, Akmalbek Bobomirzaevich Abdusalomov, Mukhriddin Mukhiddinov, and Taeg Keun Whangbo. 2023. "Improved Face Detection Method via Learning Small Faces on Hard Images Based on a Deep Learning Approach" Sensors 23, no. 1: 502. https://doi.org/10.3390/s23010502
APA StyleMamieva, D., Abdusalomov, A. B., Mukhiddinov, M., & Whangbo, T. K. (2023). Improved Face Detection Method via Learning Small Faces on Hard Images Based on a Deep Learning Approach. Sensors, 23(1), 502. https://doi.org/10.3390/s23010502