
Novel Meta-Learning Techniques for the Multiclass Image Classification Problem

 , , , and
, , , and 
Abstract
:1. Introduction
- A series of novel approaches for combining the output of a decomposed multiclass (image) classification task under the umbrella of the one-vs.-rest framework for the opinion aggregation module.
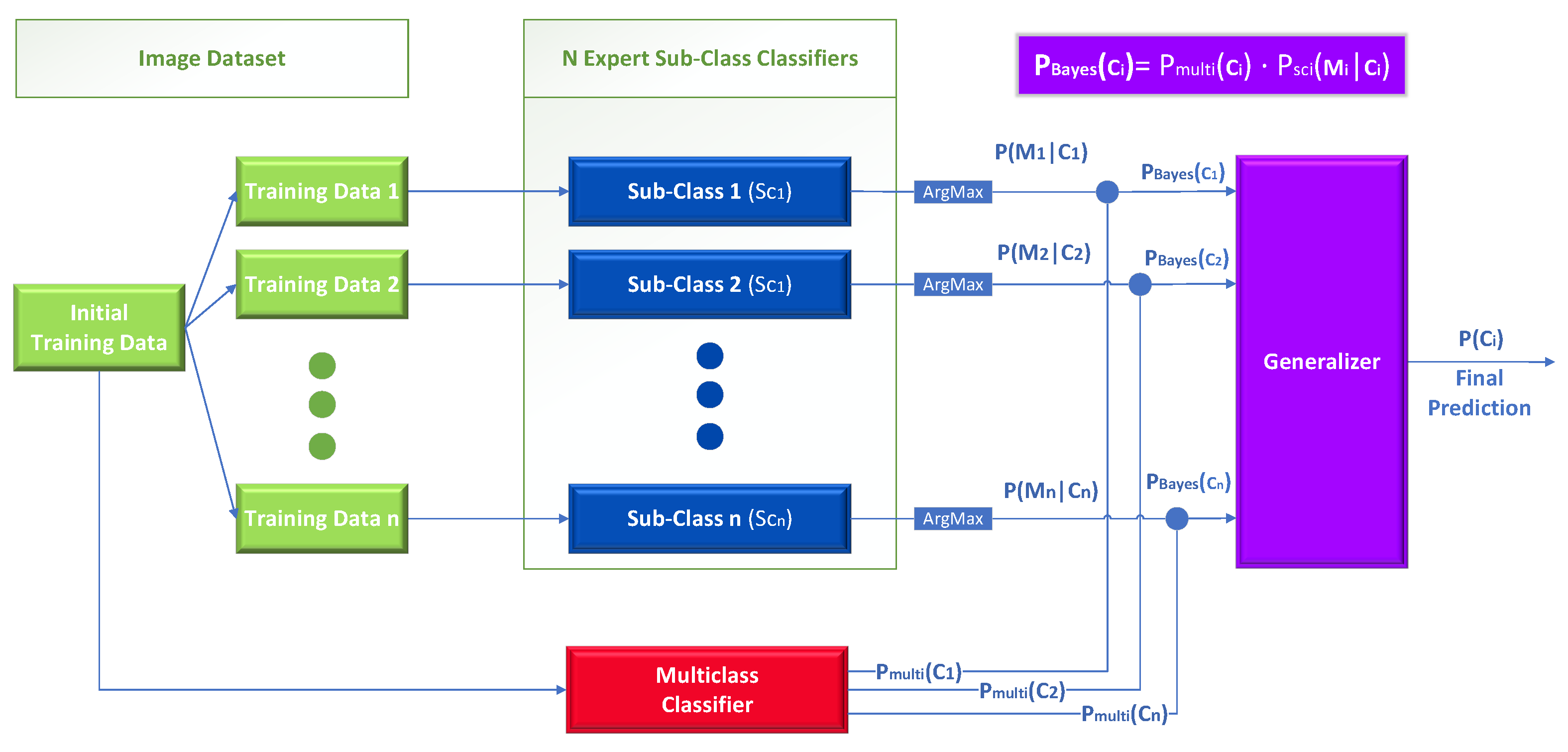
- A novel opinion aggregation method that combines information derived from sub-class classifiers based on the Bayes theorem. The novelty lies within two key parts:
- −
- The first part is the usage of multiple unrelated multicenter datasets to train the expert sub-class classifiers.
- −
- Secondly, on the way, it calculates the inputs of the final meta-learner level using the baseline multiclass classifier along with the output of the expert sub-class classifiers using the Bayes theorem.
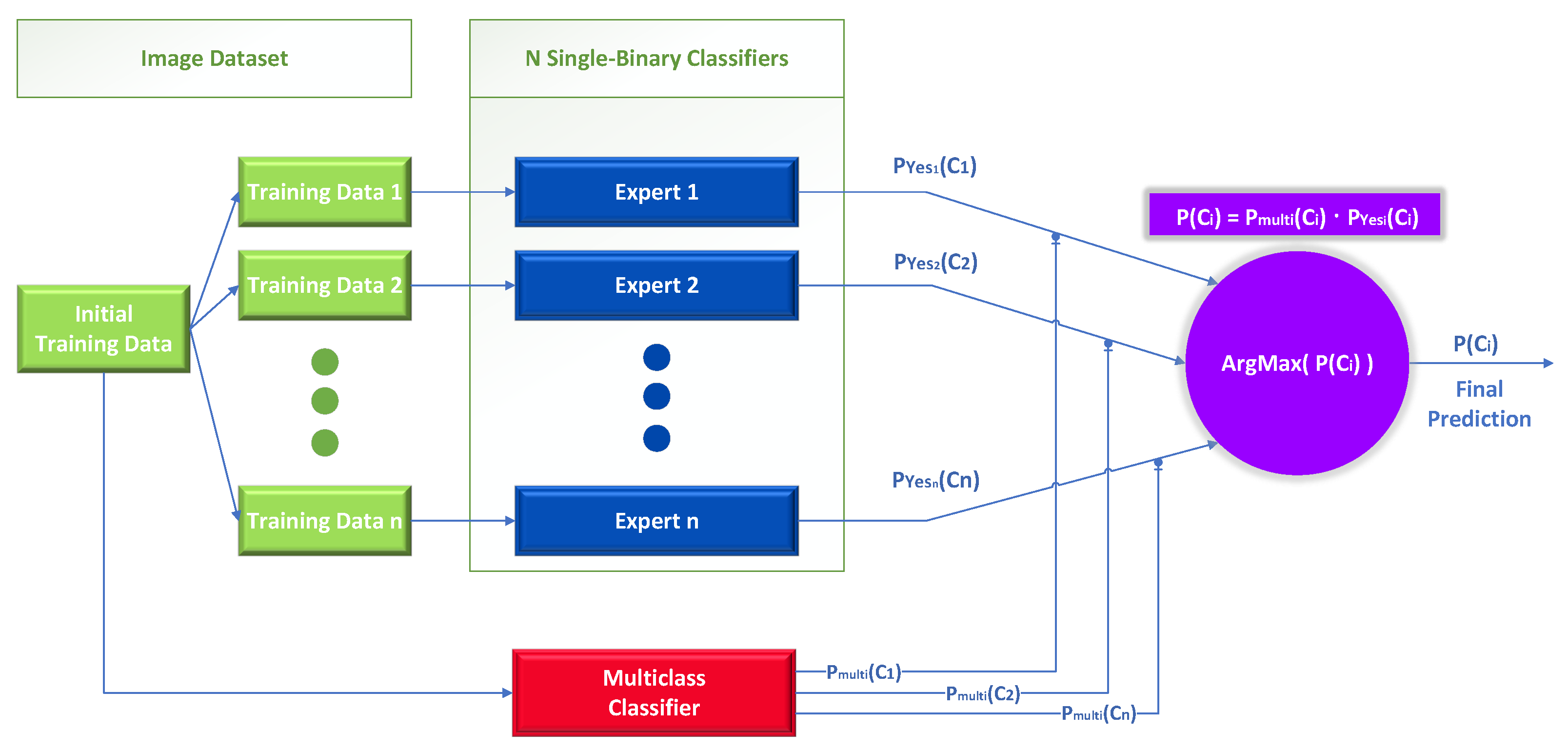
- A novel design for the mixture of expert approaches that incorporates the knowledge of a multiclass classifier as a gating model.
- In addition, we put forward two stack generalization variants with novel characteristics that follow the one-vs.-rest architectural paradigm:
- −
- The first one divides the initial problem into n separate classifiers and uses a generalizer to learn the optimal weight polic y.
- −
- The second one is similar to the first, but it additionally feeds the generalizer with the output of the baseline multiclass classifier.
- We expand on the concept of shared wisdom from data and explore how various datasets (such as hierarchical labeled datasets or even simply related datasets) can be combined to improve accuracy and create a stable network architecture.
- The methods proposed in this study can also be used to train transfer learning models for even more accurate and generalized classifiers or even for different learning tasks.
- Last but not least, this framework can be used to apply a series of black-box optimizations, potentially with varying weights and parameters and based on various intuitions and scenarios of interest.
2. Background
2.1. Ensemble Learning
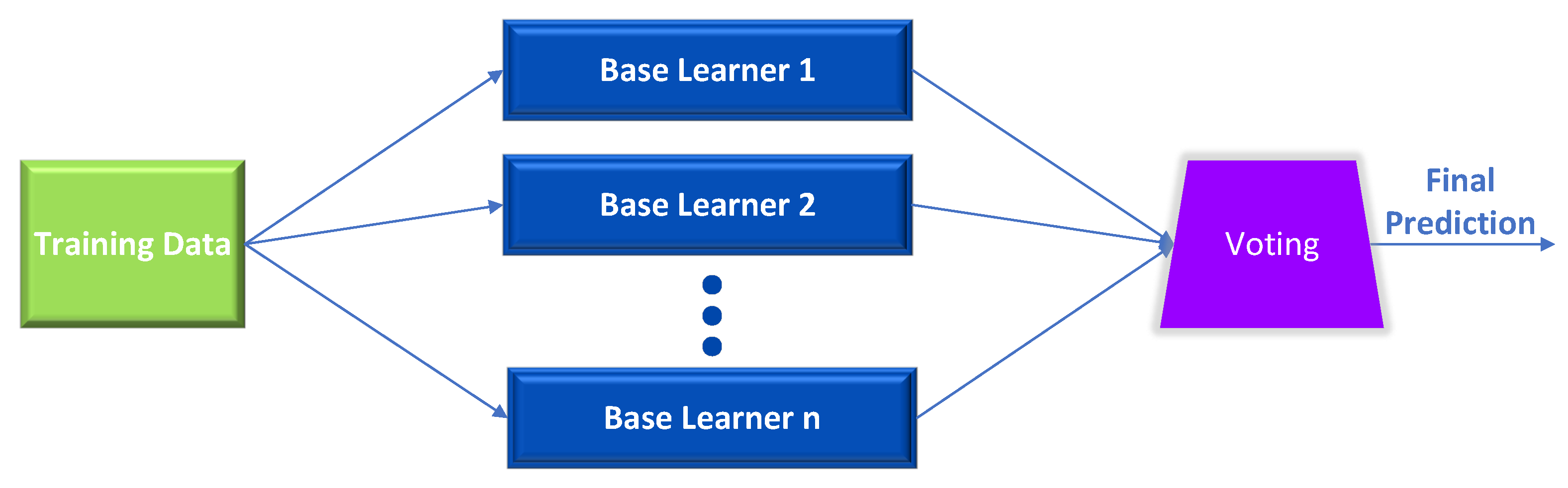
2.2. Voting Ensembles
- Hard Voting: Every classifier will vote for a particular class, and the majority will prevail. In mathematical terms, the desired target label of a set corresponds to the mode of the distribution of independently predicted labels.
- Soft Voting: Each classifier assigns to each data point a probability that it belongs to a particular target class. Predictions are summarized and weighted based on the value of the classifier. Then, the vote is cast for the preferred label with the highest probability after weighting.
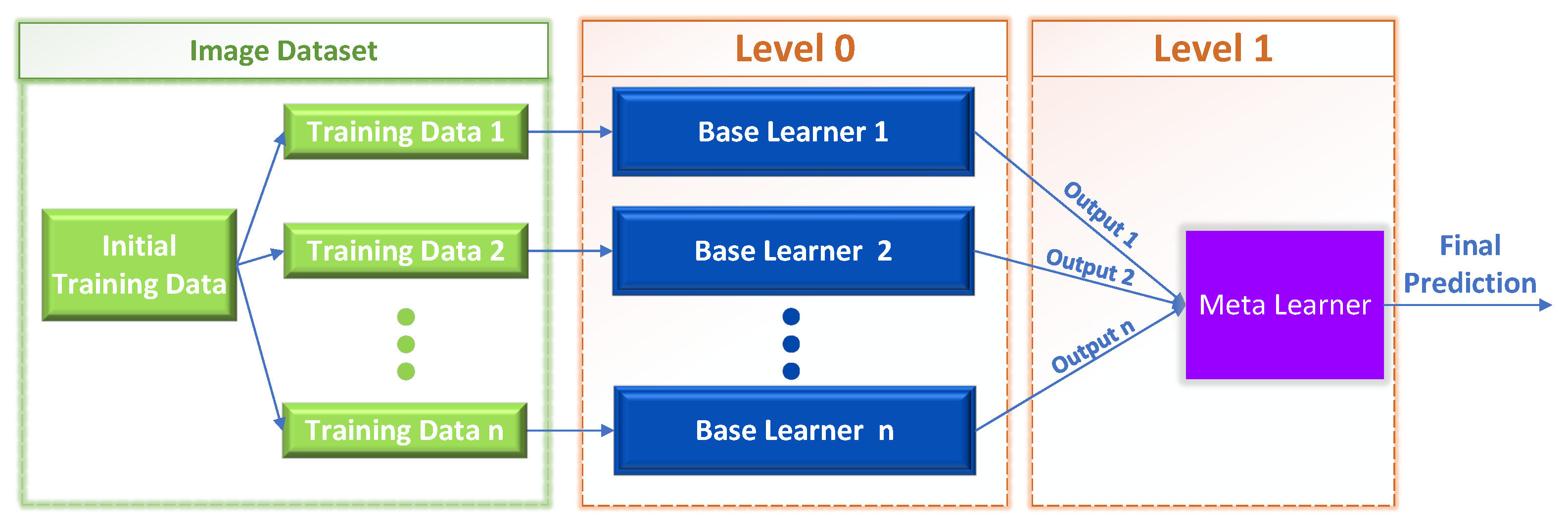
2.3. Meta-Learning Techniques: Stacked Generalization
2.4. Mixture of Experts
- A task is divided into sub-tasks: The first step is to break the predictive modeling problem into smaller chunks. This frequently entails applying domain knowledge to the key problem, determining the task’s natural division, and then deriving an effective approach from sub-solutions.
- Develop an expert for each sub-task: Experts are typically neural network models that predict a numerical value in regression or a class label in classification because the mixture of experts approach was initially developed and studied in the field of artificial neural networks. Each expert is provided with an identical input pattern and tasked with making a prediction.
- Utilize a gating model to decide which expert to consult: The gating network receives the input pattern that was provided to the expert models and outputs the allocation that each expert should make when generating a prediction for the input. Because the MoE effectively learns which portion of the feature space is learned by each ensemble member, the weights generated by the gating network are assigned dynamically based on the input. Simultaneously training the gating network and the experts in neural network models enables the gating network to determine when to trust each expert’s prediction. Traditionally, this training method employed expectation maximization (EM). A “softmax” output from the gating network might provide each expert with a confidence score that is similar to a probability score.
- Pool predictions and gating model output to make a prediction: Lastly, a prediction should be made using a pooling or aggregation strategy, which is carried out by combining expert models. Selecting the expert with the highest output or confidence provided by the gating network could be as straightforward as that. Alternately, a weighted sum prediction that explicitly incorporates each expert’s prediction and the gating network’s confidence estimation could be constructed.
2.5. Related Work
2.5.1. Multiclass Decomposition Techniques
2.5.2. Continual Learning/Incremental Learning
2.5.3. Opinion Aggregation Techniques on the Final Level
2.5.4. Mixture of Expert Models
3. Proposed Meta-Learning Techniques
3.1. Ensemble Approach Based on Bayes Theorem
3.2. Mixture of Experts: Case of One-vs.-Rest Classifiers
3.3. Proposed Combination Strategies
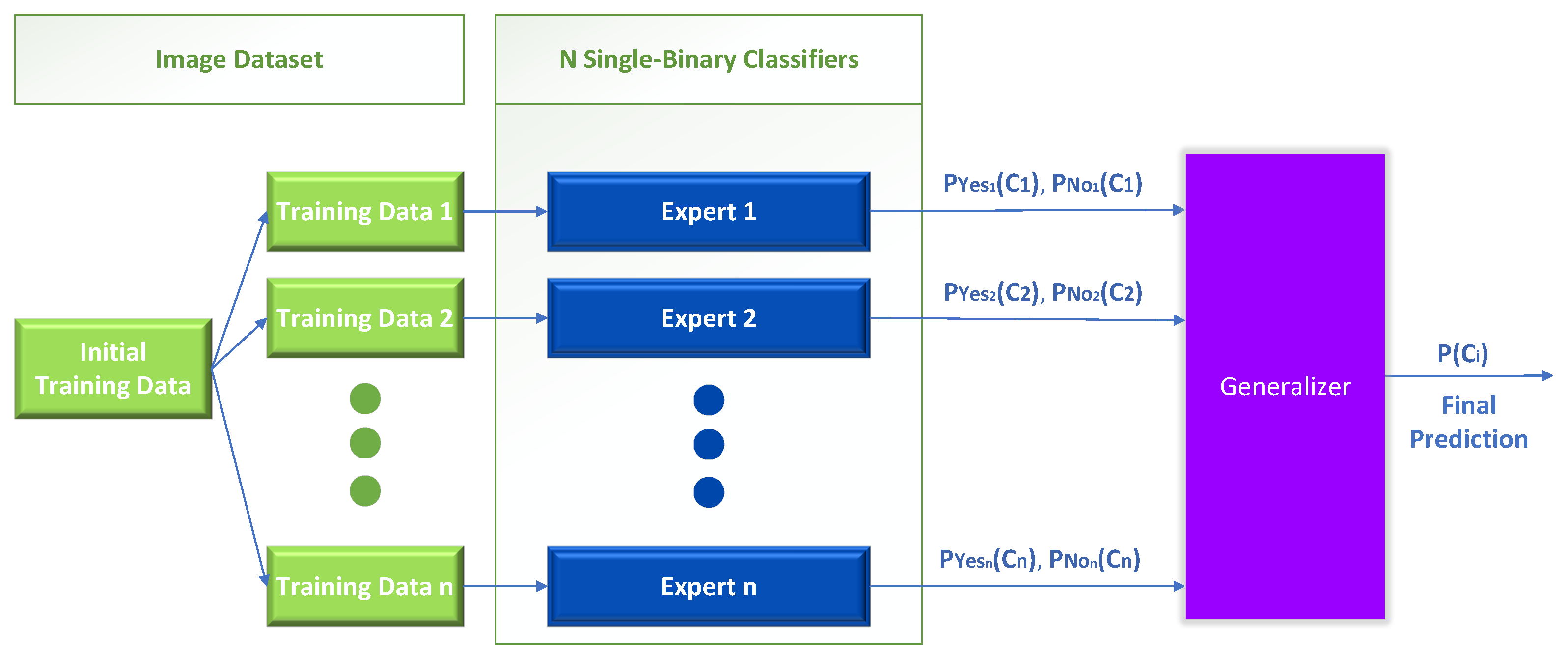
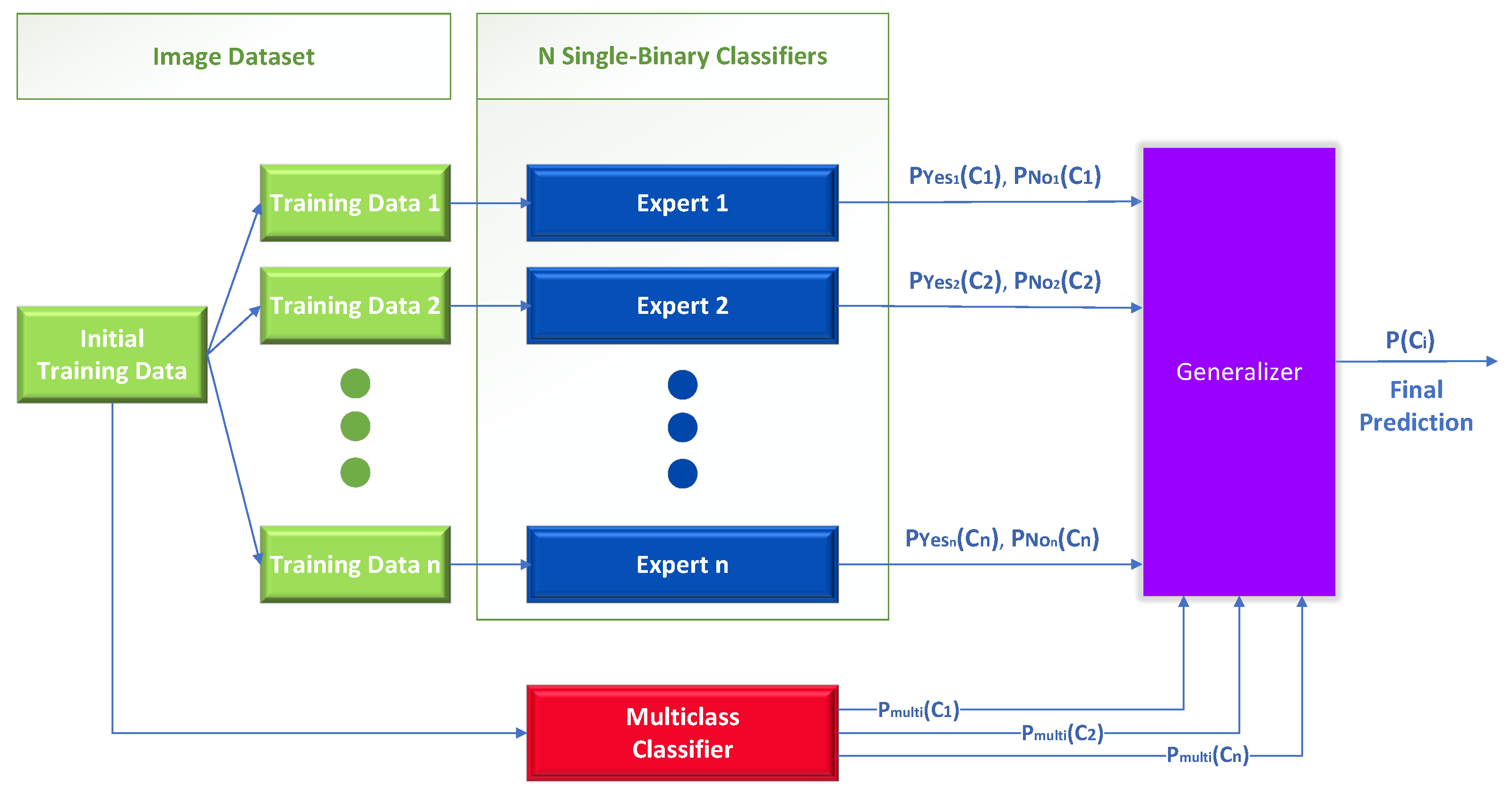
- Level 0: The training data are the inputs to the level 0 learners. Then, the level 0 base learners learn to make predictions for either the initial task or a specified sub-problem, depending on the training data.
- Level 1: The predictions produced by the level 0 learners are used as input to train the single level 1 meta-learner, with the intention to learn from this data to generate the final predictions.
3.3.1. Stack Generalization (IP-Networks Only)
3.3.2. Stack Generalization (IP-Networks + Multiclass CNN )
4. Experimental Evaluation
4.1. Experimental Setup
4.1.1. Datasets
- Plastic: divided into plastic bags, plastic bottles, plastic containers, plastic cups, and cigarette butts.
- Paper: with sub-classes newspaper, paper cups, simple paper, tetrapak, and cardboard.
- Metal: with sub-classes beverage cans, construction scrap, metal containers, other metal, and spray cans.
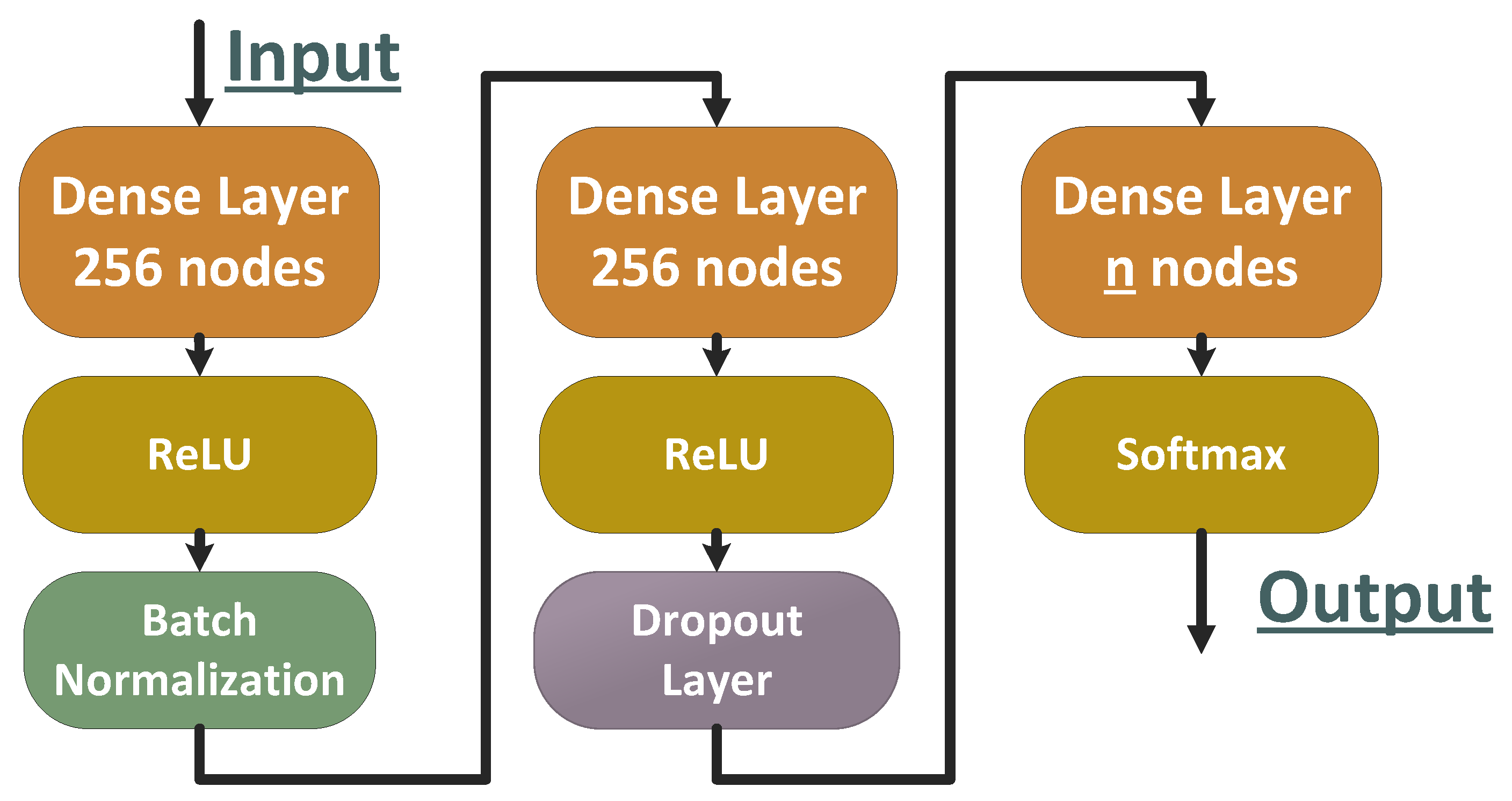
4.1.2. Configuration and Specifications
4.1.3. Evaluation Metrics
4.2. Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar] [CrossRef] [Green Version]
- Nigam, K.; McCallum, A.; Thrun, S.; Mitchell, T.M. Text Classification from Labeled and Unlabeled Documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Goo Lee, S.; Chun, J.; Lee, J. A semantic classification model for e-catalogs. In Proceedings of the IEEE International Conference on e-Commerce Technology (CEC 2004), San Diego, CA, USA, 9 July 2004; pp. 85–92. [Google Scholar]
- Panca, V.; Rustam, Z. Application of machine learning on brain cancer multiclass classification. Aip Conf. Proc. 2017, 1862, 030133. [Google Scholar] [CrossRef] [Green Version]
- Nilsson, N.J.; Sejnowski, T.J.; White, H.; Sejnowski, T.J.; White, H. Learning Machines: Foundations of Trainable Pattern-Classifying Systems; McGraw-Hill: New York, NY, USA, 1965. [Google Scholar]
- Hastie, T.; Tibshirani, R. Classification by Pairwise Coupling. In Proceedings of the Advances in Neural Information Processing Systems; Jordan, M., Kearns, M., Solla, S., Eds.; MIT Press: Cambridge, MA, USA, 1997; Volume 10. [Google Scholar]
- Rifkin, R.; Klautau, A. In Defense of One-Vs-All Classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar]
- Yan, J.; Zhang, Z.; Lin, K.; Yang, F.; Luó, X. A hybrid scheme-based one-vs-all decision trees for multi-class classification tasks. Knowl. Based Syst. 2020, 198, 105922. [Google Scholar] [CrossRef]
- Pawara, P.; Okafor, E.; Groefsema, M.; He, S.; Schomaker, L.; Wiering, M.A. One-vs-One classification for deep neural networks. Pattern Recognit. 2020, 108, 107528. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Tartas, E.B.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs-one and one-vs-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Vogiatzis, A.; Chalkiadakis, G.; Moirogiorgou, K.; Livanos, G.; Papadogiorgaki, M.; Zervakis, M. Dual-Branch CNN for the Identification of Recyclable Materials. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 24–26 August 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Tsellou, A.; Moirogiorgou, K.; Plokamakis, G.; Livanos, G.; Kalaitzakis, K.; Zervakis, M. Aerial video inspection of Greek power lines structures using machine learning techniques. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 21–23 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, H.; Fu, Y.; Wu, F.; Li, X. Memory Efficient Class-Incremental Learning for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5966–5977. [Google Scholar] [CrossRef] [PubMed]
- Vogiatzis, A.; Chalkiadakis, G.; Moirogiorgou, K.; Zervakis, M. A Novel One-vs-Rest Classification Framework for Mutually Supported Decisions by Independent Parallel Classifiers. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 24–26 August 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Yi, Y.; Chen, K.Y.; Gu, H.Y. Mixture of CNN Experts from Multiple Acoustic Feature Domain for Music Genre Classification. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1250–1255. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, S.; Liu, W.; Tao, D. Learning a Mixture of Granularity-Specific Experts for Fine-Grained Categorization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8330–8339. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Wozniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2019, 14, 241–258. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Gandhi, I.; Pandey, M. Hybrid Ensemble of classifiers using voting. In Proceedings of the 2015 International Conference on Green Computing and Internet of Things (ICGCIoT), Greater Noida, India, 8–10 October 2015; pp. 399–404. [Google Scholar]
- Ueda, N.; Nakano, R. Generalization error of ensemble estimators. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; Volume 1, pp. 90–95. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms, 1st ed.; Chapman & Hall/CRC: New York, NY, USA, 2012. [Google Scholar]
- Wolpert, D. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, C.; Chen, C.; Chen, F.; Li, M.; Yang, B.; Yan, Z.; Lv, X. Research on Application of Classification Model Based on Stack Generalization in Staging of Cervical Tissue Pathological Images. IEEE Access 2021, 9, 48980–48991. [Google Scholar] [CrossRef]
- Samyukta, B.; Sreekumar, A.; HariVarshanS, R.; Navaneeth, P.; Vaishnavi. Possibilities of Auto ML in Microsoft Replacing the Jobs of Data Scientists. J. Inf. Technol. Softw. Eng. 2021, 1–4. [Google Scholar] [CrossRef]
- Kearns, M.; Mansour, Y. On the boosting ability of top-down decision tree learning algorithms. J. Comput. Syst. Sci. 1996, 58, 109–128. [Google Scholar] [CrossRef]
- Moirogiorgou, K.; Raptopoulos, F.; Livanos, G.; Orfanoudakis, S.; Papadogiorgaki, M.; Zervakis, M.; Maniadakis, M. Intelligent robotic system for urban waste recycling. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 21–23 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hirata, D.; Takahashi, N. Ensemble learning in CNN augmented with fully connected subnetworks. arXiv 2020, arXiv:2003.08562. [Google Scholar] [CrossRef]
- Shazeer, N.M.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.V.; Hinton, G.E.; Dean, J. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Hogan, B.; Park, J.; Lutio, R. Herbarium 2022-FGVC9. Available online: https://kaggle.com/competitions/herbarium-2022-fgvc9 (accessed on 15 December 2022).
- Zhifei, Z.; Yang, S.; Hairong, Q. Age Progression/Regression by Conditional Adversarial Autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kumsetty, N.V.; Nekkare, A.B.; Kamath, S. TrashBox: Trash Detection and Classification using Quantum Transfer Learning. In Proceedings of the 2022 31st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 27–29 April 2022; pp. 125–130. [Google Scholar] [CrossRef]
- Thung, G.; Yang, M. Classification of Trash for Recyclability Status. CS229 Project Report 2016. Available online: https://cs229.stanford.edu/proj2016/report/ThungYang-ClassificationOfTrashForRecyclabilityStatus-report.pdf (accessed on 15 December 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. Int. Conf. Learn. Represent. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Classes | Total Images | Distribution of Images in Classes |
|---|---|---|---|
| four-class Herbarium | 4 | 19,728 | 4354|5720|3194|6460 |
| eight-class Herbarium | 8 | 38,535 | 4354|4346|5109|4357|4995|5720|3194|6460 |
| UTKFACE | 5 | 24,104 | 10,222|4558|3586|4027|1711 |
| Waste Classification | 3 | 8158 | 1909|4313|1936 |
| Parameters (Million) | FLOPs (Billion) | Time (ms) per Inference Step (GPU) | Depth | |
|---|---|---|---|---|
| Baseline Multiclass | 24.7 | 7.75 | 27 | 107 |
| Bayes Method | (n + 1) · 24.7 | (n + 1) · 7.75 | 163 | 110 |
| Mixture of Experts (without meta learner) | (n + 1) · 24.7 | (n + 1) · 7.75 | 162 | 107 |
| Stacked Generalization (IP only) | n · 24.7 | n · 7.75 | 136 | 110 |
| Stacked Generalization (IP + multiclass) | (n + 1) · 24.7 | (n + 1) · 7.75 | 165 | 110 |
| Four-Class Herbarium Dataset | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Baseline Multiclass | 95.32% | 94.79% | 94.73% | 94.76% |
| Bayes Method | 95.44% | 94.91% | 94.88% | 94.89% |
| Mixture of Experts (without meta learner) | 96.14% | 95.67% | 95.70% | 95.68% |
| Stacked Generalization (IP only) | 96.26% | 95.89% | 95.52% | 95.69% |
| Stacked Generalization (IP + multiclass) | 96.41% | 96.14% | 95.85% | 95.59% |
| Eight-Class Herbarium Dataset | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Baseline Multiclass | 80.59% | 80.58% | 80.45% | 80.07% |
| Bayes Method | 81.68% | 81.49% | 80.89% | 81.13% |
| Mixture of Experts (without meta learner) | 83.71% | 83.58% | 83.56% | 83.32% |
| Stacked Generalization (IP only) | 83.96% | 83.48% | 83.39% | 83.38% |
| Stacked Generalization (IP + multiclass) | 86.48% | 86.08% | 86.00% | 86.01% |
| UTKFACE Dataset | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Baseline Multiclass | 72.77% | 65.55% | 67.33% | 66.04% |
| Bayes Method | 74.86% | 67.64% | 66.68% | 67.00% |
| Mixture of Experts (without meta learner) | 78.64% | 71.09% | 71.27% | 71.07% |
| Stacked Generalization (IP only) | 76.05% | 70.20% | 68.76% | 69.06% |
| Stacked Generalization (IP + multiclass) | 77.41% | 70.69% | 70.06% | 70.19% |
| Waste Classification Dataset | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Baseline Multiclass | 94.24% | 93.04% | 93.94% | 93.46% |
| Bayes Method | 94.44% | 93.34% | 93.94% | 93.63% |
| Mixture of Experts (without meta learner) | 95.18% | 94.14% | 94.81% | 95.18% |
| Stacked Generalization (IP only) | 94.40% | 93.07% | 94.20% | 93.59% |
| Stacked Generalization (IP + multiclass) | 95.26% | 94.13% | 94.99% | 94.55% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vogiatzis, A.; Orfanoudakis, S.; Chalkiadakis, G.; Moirogiorgou, K.; Zervakis, M. Novel Meta-Learning Techniques for the Multiclass Image Classification Problem. Sensors 2023, 23, 9. https://doi.org/10.3390/s23010009
Vogiatzis A, Orfanoudakis S, Chalkiadakis G, Moirogiorgou K, Zervakis M. Novel Meta-Learning Techniques for the Multiclass Image Classification Problem. Sensors. 2023; 23(1):9. https://doi.org/10.3390/s23010009
Chicago/Turabian StyleVogiatzis, Antonios, Stavros Orfanoudakis, Georgios Chalkiadakis, Konstantia Moirogiorgou, and Michalis Zervakis. 2023. "Novel Meta-Learning Techniques for the Multiclass Image Classification Problem" Sensors 23, no. 1: 9. https://doi.org/10.3390/s23010009
APA StyleVogiatzis, A., Orfanoudakis, S., Chalkiadakis, G., Moirogiorgou, K., & Zervakis, M. (2023). Novel Meta-Learning Techniques for the Multiclass Image Classification Problem. Sensors, 23(1), 9. https://doi.org/10.3390/s23010009