
From SLAM to Situational Awareness: Challenges and Survey

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- What are the components of a robot’s situational awareness system?
- What has been achieved so far, and what challenges remain?
- What could the future direction of Situational Awareness be?
- Comprehensive review of the state-of-the-art approaches: we conduct a thorough analysis of the latest research related to enhancing situational awareness for mobile robotic platforms, covering computer vision, deep learning, and SLAM techniques.
- Identification and analysis of the challenges: we classify and discuss the reviewed approaches according to the proposed definition of situational awareness for mobile robots and highlight their current limitations for achieving complete autonomy in mobile robotics.
- Proposals for future research directions: we provide valuable insights and suggestions for future research directions and open problems that need to be addressed to develop efficient and effective situational awareness systems for mobile robotic platforms.
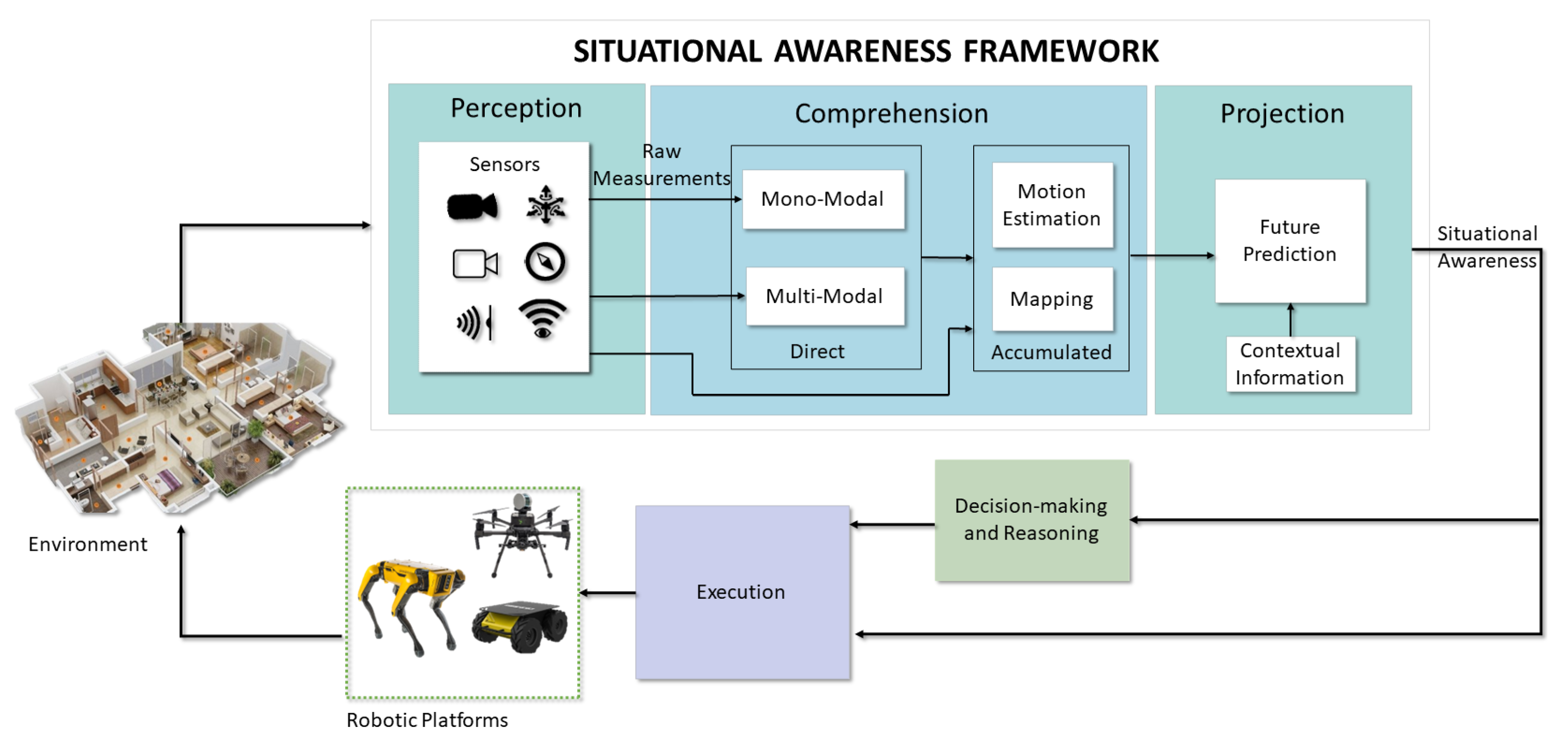
2. Situational Perception
3. Direct Situational Comprehension
3.1. Monomodal
3.2. Multimodal
4. Accumulated Situational Comprehension
4.1. Motion Estimation
4.2. Motion Estimation and Mapping
4.2.1. Filtering
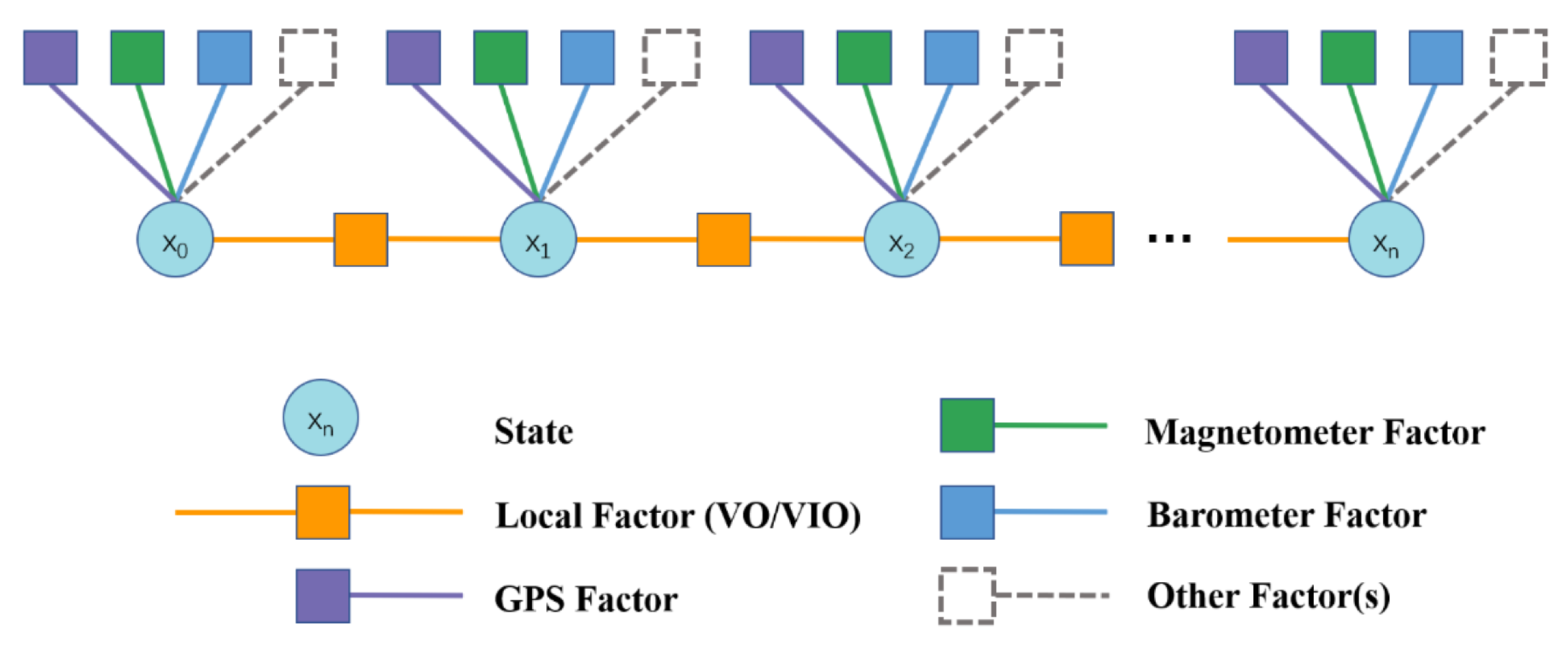
4.2.2. Metric Factor Graphs


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
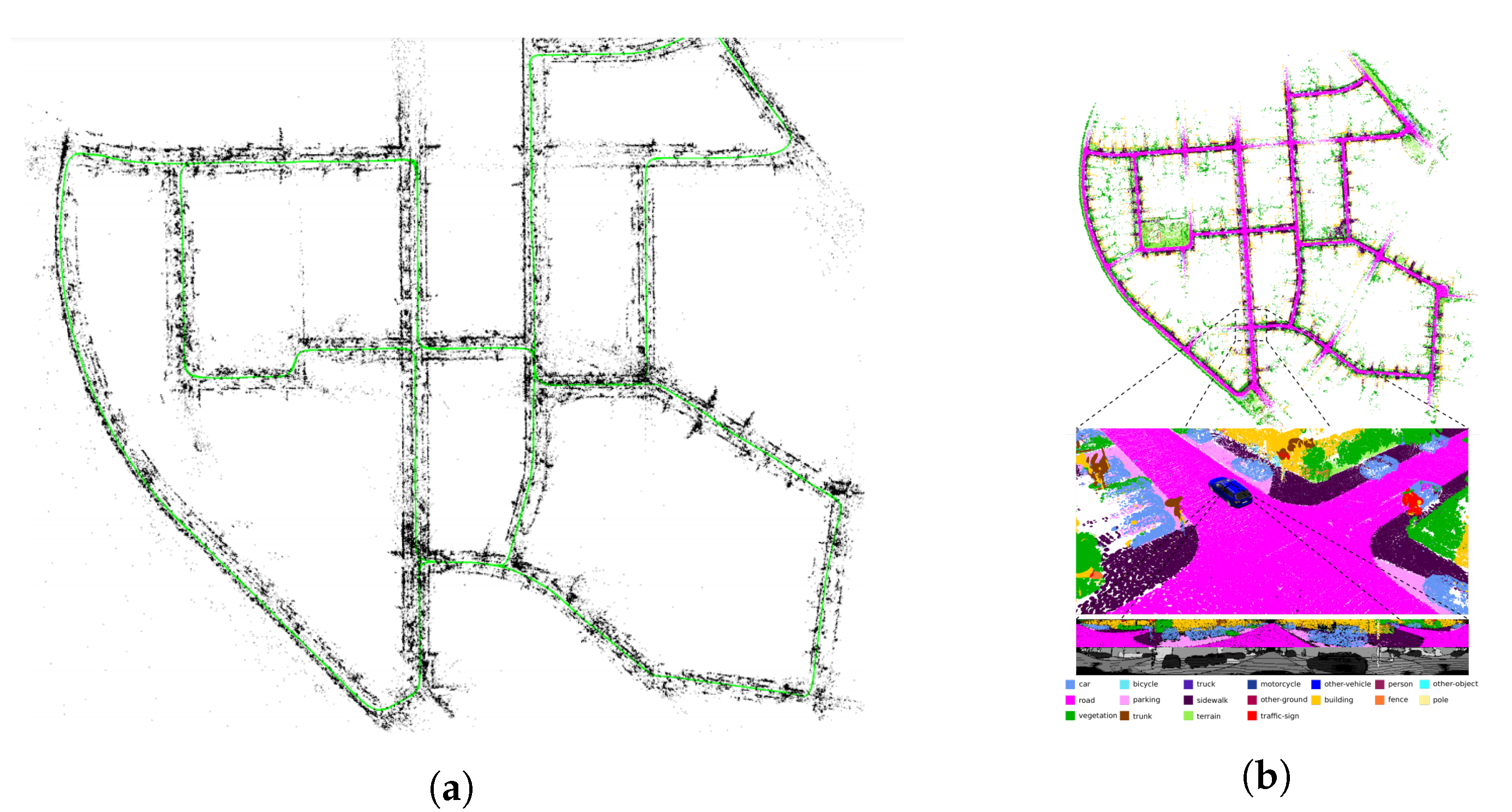{kind=link}
{kind=link}
{kind=link}
| Classification | Sensors | Method | Dataset | Limitations |
|---|---|---|---|---|
| Metric factor graphs |
| ORB-SLAM [128] | The New College Dataset [183] |
|
| DSO [157], LDSO [131] | TUM RGB-D [184], TUM-Mono [185], EuRoC Mav [186], Kitti Odometry [187] |
| ||
| LSD-SLAM [132], DPPTAM [133] | TUM RGB-D [184] | |||
| DSM [134] | EuRoC Mav [186] | |||
| Semi-Direct VO [137] | EuRoC Mav [186], TUM Mono [185] |
| ||
| MagicVO [140], DeepVO [141] | Kitti Odometry [187] |
| ||
| ORB-SLAM2 [161] | TUM RGB-D [184], EuRoC Mav [186], Kitti Odometry [187] |
| |
| ORB-SLAM3 [162] | TUM VI [188], EuRoC Mav [186] |
| |
| VINS-Mono [160] | EuRoC Mav [186] |
| |
| SVO-Multi [154] | EuRoC Mav [186], TUM RGB-D [184], ICL-NUIM [189] |
| ||
| CPA-SLAM [136] | TUM RGB-D [184], ICL-NUIM [189] |
| |
| Metric–semantic factor graphs |
| Monocular Object SLAM [190] | TUM RGB-D [184] |
|
| QuadricSLAM [191] | TUM RGB-D [184] |
| ||
| CubeSLAM [192] | TUM RGB-D [184], ICL-NUIM [189] |
| ||
| DynaSLAM [190] | TUM RGB-D [184], Kitti Odometry [187] |
| |
| VDO-SLAM [193] | Kitti Odometry [187], Oxford Multimotion [194] |
| |
| Kimera [195] | EuRoC Mav [186] |
|
| Classification | Sensors | Method | Dataset | Limitations |
|---|---|---|---|---|
| Metric Factor Graphs |
| Cartographer [171] | Deutsches Museum [171] |
|
| LOAM [173], FLOAM [174] | Kitti [187] |
| |
| SUMA [175] | Kitti [187] |
| ||
| LIMO [176] | Kitti [187] |
| |
| HDL-SLAM [180] | Kitti [187] |
| |
| Metric–semantic factor graphs |
| LeGO-LOAM [196] | Kitti [187] |
|
| SA-LOAM [171] | Kitti [187], Semantic-Kitti [197], Ford Campus [198] |
| ||
| SUMA++ [182] | Kitti [187], Semantic-Kitti [197] |
|
4.2.3. Metric–Semantic Factor Graphs
4.3. Mapping
| Mapping Type | Sensors | Methods | Limitations |
|---|---|---|---|
| Occupancy maps |
| Octomap [217] |
|
| ESDF and TSDF |
| Voxblox [223] |
|
| Voxgraph [224] |
| ||
| Voxblox++ [226] |
| ||
| NeRF |
| iMap [233], Urban Radiance Fields [246], Mega-NeRF [247] |
|
| Surfel maps |
| ElasticFusion [239], SurfelMeshing [248], Other [240] |
|
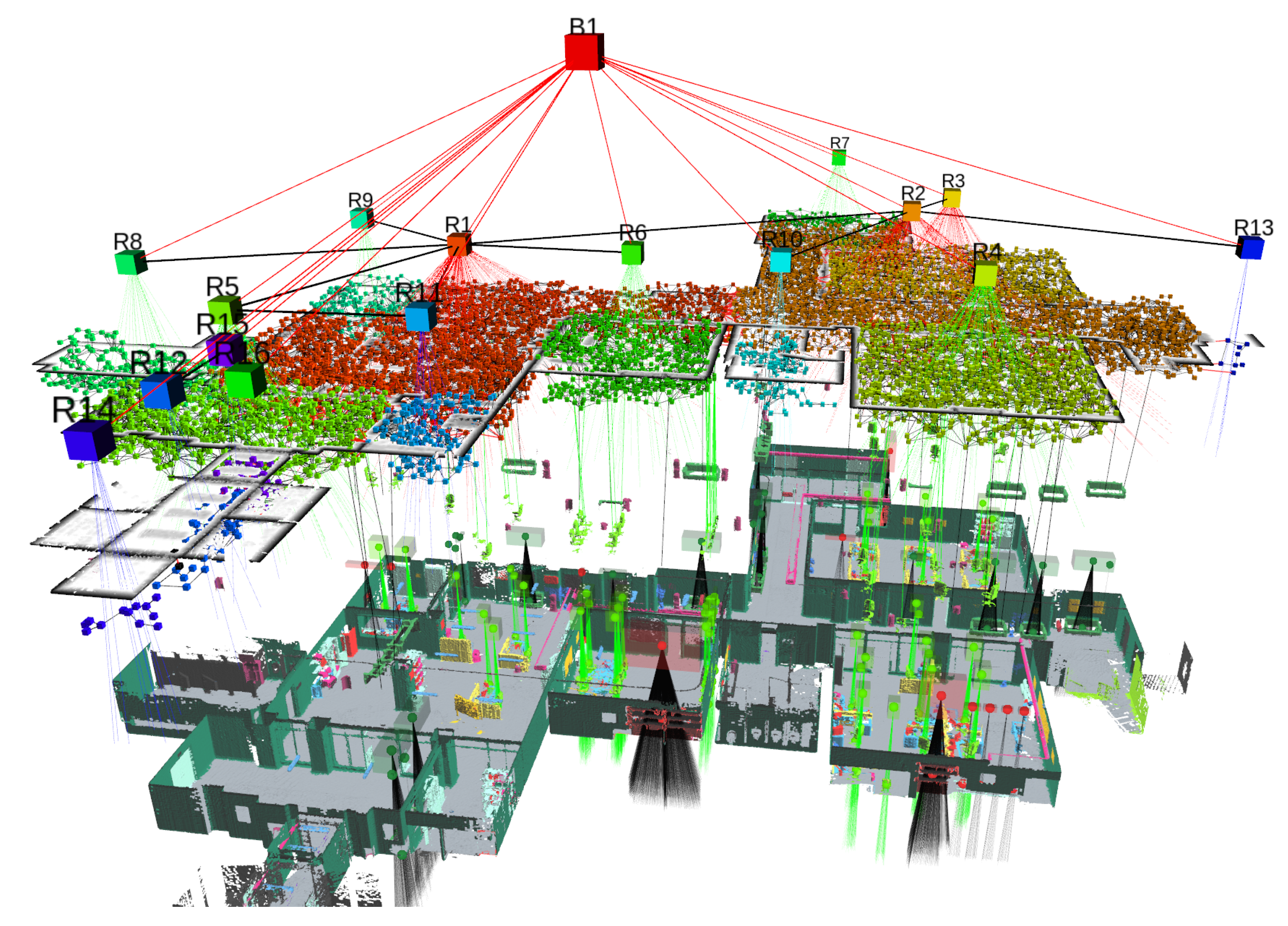
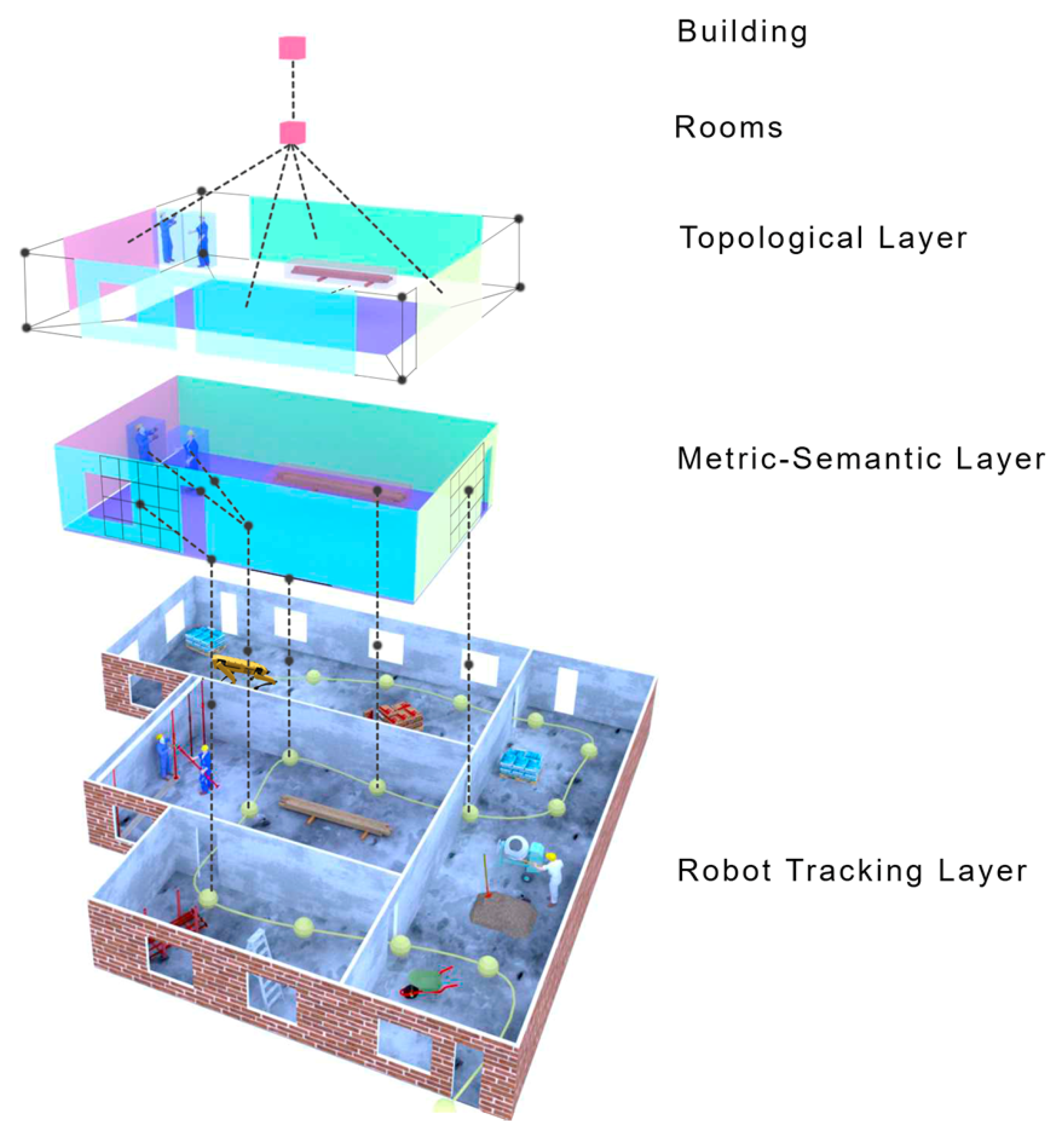
| 3D Scene Graphs |
| 3D DSG [241], Hydra [249] |
|
5. Situational Projection
Behavior Intention Prediction
6. Discussion
7. Conclusions
- What has been achieved so far, and what challenges remain?Given the advancements in AI and DL, we notice an improved comprehension layer by evaluating state-of-the-art algorithms. Comparing the initial approaches relying on heuristics and heavily engineered processing, current algorithms can solve complex tasks requiring generalization and adaptation in dynamic environments. Nevertheless, the algorithms follow a compartmentalized approach impeding a unified SA for mobile robots. Remarkably, forecasting the future situation is also in its infancy and relies on perfect data from the perception and comprehension layers to demonstrate meaningful results.
- What could the future direction of Situational Awareness be?We argue that after analyses of these algorithms, a situational awareness perspective can steer robots towards a faster achievement of their tasks, by comprising multimodal hierarchical S-Graphs generating a metric–semantic topological map of its environment as well as improving the robot’s pose uncertainty in it. We foresee the S-Graph will be characterized by a tighter coupling of situational projection, perception, and comprehension, to complete the transition from static world assumptions to natural dynamic environments.
Author Contributions
Funding
Conflicts of Interest
References
- Tzafestas, S.G. Mobile robot control and navigation: A global overview. J. Intell. Robot. Syst. 2018, 91, 35–58. [Google Scholar] [CrossRef]
- Dzedzickis, A.; Subačiūtė-Žemaitienė, J.; Šutinys, E.; Samukaitė-Bubnienė, U.; Bučinskas, V. Advanced Applications of Industrial Robotics: New Trends and Possibilities. Appl. Sci. 2021, 12, 135. [Google Scholar] [CrossRef]
- Siciliano, B.; Khatib, O. (Eds.) Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Makhataeva, Z.; Varol, H.A. Augmented Reality for Robotics: A Review. Robotics 2020, 9, 21. [Google Scholar] [CrossRef]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Wong, C.; Yang, E.; Yan, X.T.; Gu, D. Autonomous robots for harsh environments: A holistic overview of current solutions and ongoing challenges. Syst. Sci. Control Eng. 2018, 6, 213–219. [Google Scholar] [CrossRef]
- Salas, E. Situational Awareness; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Munir, A.; Aved, A.; Blasch, E. Situational Awareness: Techniques, Challenges, and Prospects. AI 2022, 3, 55–77. [Google Scholar] [CrossRef]
- Rubio, F.; Valero, F.; Llopis-Albert, C. A review of mobile robots: Concepts, methods, theoretical framework, and applications. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419839596. [Google Scholar] [CrossRef]
- Nirmal, K.; Sreejith, A.G.; Mathew, J.; Sarpotdar, M.; Suresh, A.; Prakash, A.; Safonova, M.; Murthy, J. Noise modeling and analysis of an IMU-based attitude sensor: Improvement of performance by filtering and sensor fusion. In Advances in Optical and Mechanical Technologies for Telescopes and Instrumentation II; SPIE: Edinburgh, UK, 2016. [Google Scholar] [CrossRef]
- Sabatini, A.; Genovese, V. A Stochastic Approach to Noise Modeling for Barometric Altimeters. Sensors 2013, 13, 15692–15707. [Google Scholar] [CrossRef]
- Zimmermann, F.; Eling, C.; Klingbeil, L.; Kuhlmann, H. Precise Positioning of Uavs—Dealing with Challenging Rtk-Gps Measurement Conditions during Automated Uav Flights. In ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences; ISPRS: Hannover, Germany, 2017; Volume 42W3, pp. 95–102. [Google Scholar] [CrossRef]
- Tourani, A.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H. Visual SLAM: What Are the Current Trends and What to Expect? Sensors 2022, 22, 9297. [Google Scholar] [CrossRef]
- Indiveri, G.; Douglas, R. Neuromorphic vision sensors. Science 2000, 288, 1189–1190. [Google Scholar] [CrossRef] [PubMed]
- Gallego, G.; Delbruck, T.; Orchard, G.M.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.; Conradt, J.; Daniilidis, K.; et al. Event-based Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 154–180. [Google Scholar] [CrossRef] [PubMed]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 dB 15 micro-sec Latency Asynchronous Temporal Contrast Vision Sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.C.; Delbruck, T. A 240 × 180 130 dB 3 µs Latency Global Shutter Spatiotemporal Vision Sensor. IEEE J. Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Posch, C.; Matolin, D.; Wohlgenannt, R. A QVGA 143 dB Dynamic Range Frame-Free PWM Image Sensor With Lossless Pixel-Level Video Compression and Time-Domain CDS. IEEE J. Solid-State Circuits 2011, 46, 259–275. [Google Scholar] [CrossRef]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. Events-to-Video: Bringing Modern Computer Vision to Event Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. High Speed and High Dynamic Range Video with an Event Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1964–1980. [Google Scholar] [CrossRef]
- Venon, A.; Dupuis, Y.; Vasseur, P.; Merriaux, P. Millimeter wave FMCW radars for perception, recognition and localization in automotive applications: A survey. IEEE Trans. Intell. Veh. 2022, 7, 533–555. [Google Scholar] [CrossRef]
- Kabiri, M.; Cimarelli, C.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H. A Review of Radio Frequency Based Localisation for Aerial and Ground Robots with 5G Future Perspectives. Sensors 2023, 23, 188. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef]
- Nguyen, T.; Park, E.A.; Han, J.; Park, D.C.; Min, S.Y. Object Detection Using Scale Invariant Feature Transform. In Genetic and Evolutionary Computing; Pan, J.S., Krömer, P., Snášel, V., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 65–72. [Google Scholar]
- Li, Q.; Wang, X. Image Classification Based on SIFT and SVM. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 762–765. [Google Scholar] [CrossRef]
- Kachouane, M.; Sahki, S.; Lakrouf, M.; Ouadah, N. HOG based fast human detection. In Proceedings of the 2012 24th International Conference on Microelectronics (ICM), Algiers, Algeria, 16–20 December 2012. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. Monocular Pedestrian Detection: Survey and Experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179–2195. [Google Scholar] [CrossRef]
- Messelodi, S.; Modena, C.M.; Cattoni, G. Vision-based bicycle/motorcycle classification. Pattern Recognit. Lett. 2007, 28, 1719–1726. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Hearst, M.; Dumais, S.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2018, arXiv:1708.02002. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. TensorMask: A Foundation for Dense Object Segmentation. arXiv 2019, arXiv:1903.12174. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. arXiv 2019, arXiv:1901.01892. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. arXiv 2020, arXiv:1912.08193. [Google Scholar]
- Poudel, R.P.K.; Liwicki, S.; Cipolla, R. Fast-SCNN: Fast Semantic Segmentation Network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic Feature Pyramid Networks. arXiv 2019, arXiv:1901.02446. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. arXiv 2020, arXiv:1911.10194. [Google Scholar]
- Xu, D.; Zhu, Y.; Choy, C.B.; Fei-Fei, L. Scene Graph Generation by Iterative Message Passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zareian, A.; Karaman, S.; Chang, S.F. Bridging Knowledge Graphs to Generate Scene Graphs. In Computer Vision – ECCV 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 606–623. [Google Scholar] [CrossRef]
- Suhail, M.; Mittal, A.; Siddiquie, B.; Broaddus, C.; Eledath, J.; Medioni, G.; Sigal, L. Energy-based learning for scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13936–13945. [Google Scholar]
- Wang, W.; Zhang, J.; Shen, C. Improved human detection and classification in thermal images. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2313–2316. [Google Scholar] [CrossRef]
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal Object Detection in Difficult Weather Conditions Using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Ippalapally, R.; Mudumba, S.H.; Adkay, M.; H.R., N.V. Object Detection Using Thermal Imaging. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Cannici, M.; Ciccone, M.; Romanoni, A.; Matteucci, M. Asynchronous Convolutional Networks for Object Detection in Neuromorphic Cameras. arXiv 2019, arXiv:1805.07931. [Google Scholar]
- Alonso, I.; Murillo, A.C. EV-SegNet: Semantic Segmentation for Event-based Cameras. arXiv 2018, arXiv:1811.12039. [Google Scholar]
- Stiene, S.; Lingemann, K.; Nuchter, A.; Hertzberg, J. Contour-Based Object Detection in Range Images. In Proceedings of the Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT’06), Chapel Hill, NC, USA, 14–16 June 2006; pp. 168–175. [Google Scholar] [CrossRef]
- Himmelsbach, M.; Mueller, A.; Lüttel, T.; Wünsche, H.J. LIDAR-based 3D object perception. In Proceedings of the 1st International Workshop on Cognition for Technical Systems, Munich, Germany, 6–8 October 2008; Volume 1. [Google Scholar]
- Kragh, M.; Jørgensen, R.N.; Pedersen, H. Object Detection and Terrain Classification in Agricultural Fields Using 3D Lidar Data. In Computer Vision Systems; Nalpantidis, L., Krüger, V., Eklundh, J.O., Gasteratos, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 188–197. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar] [CrossRef]
- Lyu, Y.; Huang, X.; Zhang, Z. Learning to Segment 3D Point Clouds in 2D Image Space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12255–12264. Available online: http://xxx.lanl.gov/abs/2003.05593 (accessed on 10 April 2023).
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. arXiv 2017, arXiv:1710.07368. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. arXiv 2018, arXiv:1809.08495. [Google Scholar]
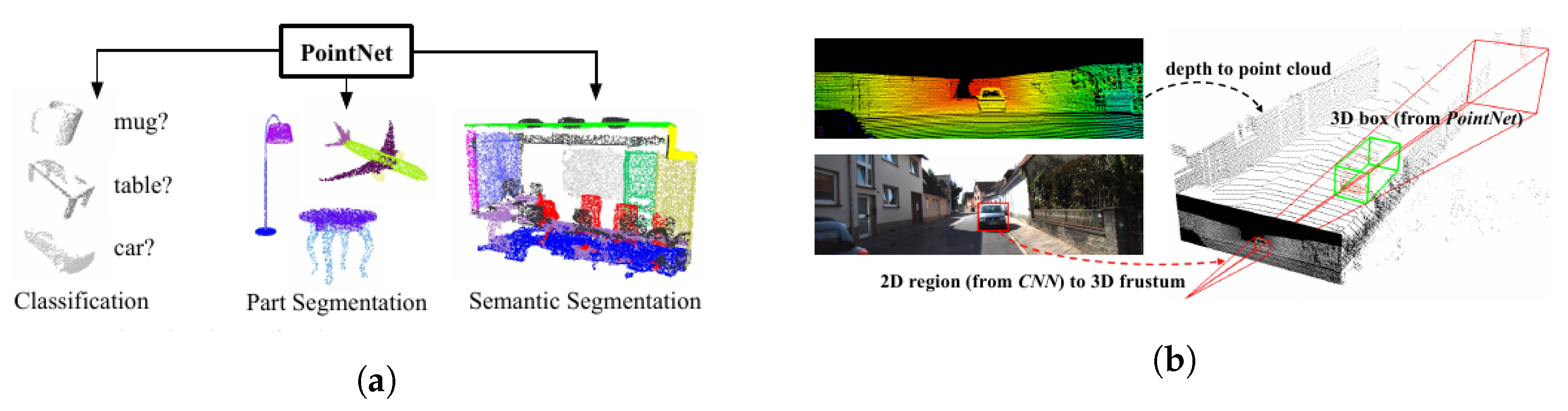
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. arXiv 2017, arXiv:1612.00593. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3887–3896. Available online: http://xxx.lanl.gov/abs/1807.02443 (accessed on 10 April 2023).
- Najibi, M.; Lai, G.; Kundu, A.; Lu, Z.; Rathod, V.; Funkhouser, T.; Pantofaru, C.; Ross, D.; Davis, L.S.; Fathi, A. DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes. arXiv 2020, arXiv:2004.01170. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; Available online: http://xxx.lanl.gov/abs/1911.11236 (accessed on 10 April 2023).
- González, A.; Vázquez, D.; López, A.M.; Amores, J. On-Board Object Detection: Multicue, Multimodal, and Multiview Random Forest of Local Experts. IEEE Trans. Cybern. 2017, 47, 3980–3990. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Fidler, S.; Urtasun, R. Holistic Scene Understanding for 3D Object Detection with RGBD Cameras. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. arXiv 2018, arXiv:1711.00199. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martin-Martin, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lin, Y.; Tremblay, J.; Tyree, S.; Vela, P.A.; Birchfield, S. Multi-view Fusion for Multi-level Robotic Scene Understanding. arXiv 2021, arXiv:2103.13539. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, USA, 24–28 September 2017; pp. 5108–5115. [Google Scholar] [CrossRef]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. PST900: RGB-Thermal Calibration, Dataset and Segmentation Network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9441–9447. [Google Scholar] [CrossRef]
- Sun, Y.; Zuo, W.; Yun, P.; Wang, H.; Liu, M. FuseSeg: Semantic Segmentation of Urban Scenes Based on RGB and Thermal Data Fusion. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1000–1011. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, K.; Stiefelhagen, R. ISSAFE: Improving Semantic Segmentation in Accidents by Fusing Event-based Data. arXiv 2020, arXiv:2008.08974. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. arXiv 2018, arXiv:1711.08488. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep Continuous Fusion for Multi-Sensor 3D Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. arXiv 2017, arXiv:1611.07759. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Papers With Code. Available online: https://paperswithcode.com/area/computer-vision (accessed on 10 April 2023).
- Mitrokhin, A.; Fermüller, C.; Parameshwara, C.; Aloimonos, Y. Event-Based Moving Object Detection and Tracking. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Hall, D.; Llinas, J. An introduction to multisensor data fusion. Proc. IEEE 1997, 85, 6–23. [Google Scholar] [CrossRef]
- Alldieck, T.; Bahnsen, C.H.; Moeslund, T.B. Context-Aware Fusion of RGB and Thermal Imagery for Traffic Monitoring. Sensors 2016, 16, 1947. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.N. ECFFNet: Effective and Consistent Feature Fusion Network for RGB-T Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1224–1235. [Google Scholar] [CrossRef]
- Spremolla, I.R.; Antunes, M.; Aouada, D.; Ottersten, B.E. RGB-D and Thermal Sensor Fusion-Application in Person Tracking. In Proceedings of the 11th Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 3: VISAPP; SciTePress: Rome, Italy, 2016; pp. 610–617. [Google Scholar]
- Mogelmose, A.; Bahnsen, C.; Moeslund, T.B.; Clapes, A.; Escalera, S. Tri-modal Person Re-identification with RGB, Depth and Thermal Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Dubeau, E.; Garon, M.; Debaque, B.; Charette, R.d.; Lalonde, J.F. RGB-D-E: Event Camera Calibration for Fast 6-DOF object Tracking. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Ipojuca, Brasil, 9–13 November 2020; pp. 127–135. [Google Scholar] [CrossRef]
- Dellaert, F.; Fox, D.; Burgard, W.; Thrun, S. Monte Carlo localization for mobile robots. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 10–15 May 1999; Volume 2, pp. 1322–1328. [Google Scholar] [CrossRef]
- Thrun, S.; Fox, D.; Burgard, W.; Dellaert, F. Robust Monte Carlo localization for mobile robots. Artif. Intell. 2001, 128, 99–141. [Google Scholar] [CrossRef]
- Anjum, M.L.; Park, J.; Hwang, W.; Kwon, H.i.; Kim, J.h.; Lee, C.; Kim, K.s.; “Dan” Cho, D.i. Sensor data fusion using Unscented Kalman Filter for accurate localization of mobile robots. In Proceedings of the ICCAS 2010, Gyeonggi-do, Republic of Korea, 27–30 October 2010; pp. 947–952. [Google Scholar] [CrossRef]
- Kong, F.; Chen, Y.; Xie, J.; Zhang, G.; Zhou, Z. Mobile Robot Localization Based on Extended Kalman Filter. In Proceedings of the 2006 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; Volume 2, pp. 9242–9246. [Google Scholar] [CrossRef]
- Teslic, L.; skrjanc, I.; Klanvcar, G. EKF-Based Localization of a Wheeled Mobile Robot in Structured Environments. J. Intell. Robot. Syst. 2011, 62, 187–203. [Google Scholar] [CrossRef]
- Chen, L.; Hu, H.; McDonald-Maier, K. EKF Based Mobile Robot Localization. In Proceedings of the 2012 Third International Conference on Emerging Security Technologies, Lisbon, Portugal, 5–7 September 2012; pp. 149–154. [Google Scholar] [CrossRef]
- Ganganath, N.; Leung, H. Mobile robot localization using odometry and kinect sensor. In Proceedings of the 2012 IEEE International Conference on Emerging Signal Processing Applications, IEEE, Las Vegas, NV, USA, 12–14 January 2012; pp. 91–94. [Google Scholar]
- Kim, S.J.; Kim, B.K. Dynamic Ultrasonic Hybrid Localization System for Indoor Mobile Robots. IEEE Trans. Ind. Electron. 2013, 60, 4562–4573. [Google Scholar] [CrossRef]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A robust and modular multi-sensor fusion approach applied to MAV navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3923–3929. [Google Scholar] [CrossRef]
- Sanchez-Lopez, J.L.; Arellano-Quintana, V.; Tognon, M.; Campoy, P.; Franchi, A. Visual Marker based Multi-Sensor Fusion State Estimation. IFAC-PapersOnLine 2017, 50, 16003–16008. [Google Scholar] [CrossRef]
- Moore, T.; Stouch, D.W. A Generalized Extended Kalman Filter Implementation for the Robot Operating System. In Proceedings of the IAS, Pedova, Italy, 15–18 July 2014. [Google Scholar]
- Wan, G.; Yang, X.; Cai, R.; Li, H.; Zhou, Y.; Wang, H.; Song, S. Robust and Precise Vehicle Localization Based on Multi-Sensor Fusion in Diverse City Scenes. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar] [CrossRef]
- Liu, F.; Li, X.; Yuan, S.; Lan, W. Slip-Aware Motion Estimation for Off-Road Mobile Robots via Multi-Innovation Unscented Kalman Filter. IEEE Access 2020, 8, 43482–43496. [Google Scholar] [CrossRef]
- Kimura, K.; Hiromachi, Y.; Nonaka, K.; Sekiguchi, K. Vehicle localization by sensor fusion of LRS measurement and odometry information based on moving horizon estimation. In Proceedings of the 2014 IEEE Conference on Control Applications (CCA), Juan Les Antibes, France, 8–10 October 2014; pp. 1306–1311. [Google Scholar] [CrossRef]
- Liu, A.; Zhang, W.A.; Chen, M.Z.Q.; Yu, L. Moving Horizon Estimation for Mobile Robots With Multirate Sampling. IEEE Trans. Ind. Electron. 2017, 64, 1457–1467. [Google Scholar] [CrossRef]
- Dubois, R.; Bertrand, S.; Eudes, A. Performance Evaluation of a Moving Horizon Estimator for Multi-Rate Sensor Fusion with Time-Delayed Measurements. In Proceedings of the 2018 22nd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 8–10 October 2018; pp. 664–669. [Google Scholar] [CrossRef]
- Osman, M.; Mehrez, M.W.; Daoud, M.A.; Hussein, A.; Jeon, S.; Melek, W. A generic multi-sensor fusion scheme for localization of autonomous platforms using moving horizon estimation. Trans. Inst. Meas. Control 2021, 43, 3413–3427. [Google Scholar] [CrossRef]
- Ranganathan, A.; Kaess, M.; Dellaert, F. Fast 3D pose estimation with out-of-sequence measurements. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 2486–2493. [Google Scholar] [CrossRef]
- Dellaert, F.; Kaess, M. Square Root SAM: Simultaneous Localization and Mapping via Square Root Information Smoothing. Int. J. Robot. Res. 2006, 25, 1181–1203. [Google Scholar] [CrossRef]
- Indelman, V.; Williams, S.; Kaess, M.; Dellaert, F. Factor graph based incremental smoothing in inertial navigation systems. In Proceedings of the 2012 15th International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 2154–2161. [Google Scholar]
- Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and mapping using the Bayes tree. Int. J. Robot. Res. 2012, 31, 216–235. [Google Scholar] [CrossRef]
- Merfels, C.; Stachniss, C. Pose fusion with chain pose graphs for automated driving. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 3116–3123. [Google Scholar] [CrossRef]
- Merfels, C.; Stachniss, C. Sensor Fusion for Self-Localisation of Automated Vehicles. PFG—J. Photogramm. Remote Sens. Geoinf. Sci. 2017, 85, 113–126. [Google Scholar] [CrossRef]
- Mascaro, R.; Teixeira, L.; Hinzmann, T.; Siegwart, R.; Chli, M. GOMSF: Graph-Optimization Based Multi-Sensor Fusion for robust UAV Pose estimation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 1421–1428. [Google Scholar] [CrossRef]
- Qin, T.; Cao, S.; Pan, J.; Shen, S. A General Optimization-based Framework for Global Pose Estimation with Multiple Sensors. arXiv 2019, arXiv:1901.03642. [Google Scholar]
- Li, X.; Wang, X.; Liao, J.; Li, X.; Li, S.; Lyu, H. Semi-tightly coupled integration of multi-GNSS PPP and S-VINS for precise positioning in GNSS-challenged environments. Satell. Navig. 2021, 2, 1. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Chen, W.; Shang, G.; Ji, A.; Zhou, C.; Wang, X.; Xu, C.; Li, Z.; Hu, K. An Overview on Visual SLAM: From Tradition to Semantic. Remote Sens. 2022, 14, 3010. [Google Scholar] [CrossRef]
- Lu, F.; Milios, E. Globally Consistent Range Scan Alignment for Environment Mapping. Auton. Robot. 1997, 4, 333–349. [Google Scholar] [CrossRef]
- Leonard, J.J.; Feder, H.J.S. A Computationally Efficient Method for Large-Scale Concurrent Mapping and Localization. In Robotics Research; Hollerbach, J.M., Koditschek, D.E., Eds.; Springer: London, UK, 2000; pp. 169–176. [Google Scholar]
- Guivant, J.; Nebot, E. Optimization of the simultaneous localization and map-building algorithm for real-time implementation. IEEE Trans. Robot. Autom. 2001, 17, 242–257. [Google Scholar] [CrossRef]
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM Algorithm. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–13 October 2006; pp. 3562–3568. [Google Scholar] [CrossRef]
- Thrun, S.; Montemerlo, M.; Koller, D.; Wegbreit, B.; Nieto, J.; Nebot, E. Fastslam: An efficient solution to the simultaneous localization and mapping problem with unknown data association. J. Mach. Learn. Res. 2004, 4, 380–407. [Google Scholar]
- Folkesson, J.; Christensen, H.I. Graphical SLAM for Outdoor Applications. J. Field Robot. 2007, 24, 51–70. [Google Scholar] [CrossRef]
- Olson, E.; Leonard, J.; Teller, S. Fast iterative alignment of pose graphs with poor initial estimates. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation (ICRA), Orlando, FL, USA, 15–19 May 2006; pp. 2262–2269. [Google Scholar]
- Thrun, S.; Montemerlo, M. The Graph SLAM Algorithm with Applications to Large-Scale Mapping of Urban Structures. Int. J. Robot. Res. 2006, 25, 403–429. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. REMODE: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Honkong, China, 31 May–5 June 2014; pp. 2609–2616. [Google Scholar] [CrossRef]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense Visual Odometry for a Monocular Camera. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1449–1456. [Google Scholar] [CrossRef]
- Gao, X.; Wang, R.; Demmel, N.; Cremers, D. LDSO: Direct Sparse Odometry with Loop Closure. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2198–2204. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Concha, A.; Civera, J. DPPTAM: Dense piecewise planar tracking and mapping from a monocular sequence. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5686–5693. [Google Scholar] [CrossRef]
- Zubizarreta, J.; Aguinaga, I.; Montiel, J.M.M. Direct Sparse Mapping. IEEE Trans. Robot. 2020, 36, 1363–1370. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hongkong, China, 31 May–5 June 2014; pp. 15–22. [Google Scholar] [CrossRef]
- Ma, L.; Kerl, C.; Stückler, J.; Cremers, D. CPA-SLAM: Consistent plane-model alignment for direct RGB-D SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), IEEE, Stockholm, Sweden, 16–21 May 2016; pp. 1285–1291. [Google Scholar]
- Lee, S.H.; Civera, J. Loosely-Coupled Semi-Direct Monocular SLAM. IEEE Robot. Autom. Lett. 2019, 4, 399–406. [Google Scholar] [CrossRef]
- Yang, N.; Stumberg, L.v.; Wang, R.; Cremers, D. D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1281–1292. [Google Scholar]
- Carlone, L.; Tron, R.; Daniilidis, K.; Dellaert, F. Initialization techniques for 3D SLAM: A survey on rotation estimation and its use in pose graph optimization. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), IEEE, Seattle, WA, USA, 26–30 May 2015; pp. 4597–4604. [Google Scholar]
- Jiao, J.; Jiao, J.; Mo, Y.; Liu, W.; Deng, Z. MagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network. arXiv 2018, arXiv:1811.10964. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar] [CrossRef]
- Bruno, H.M.S.; Colombini, E.L. LIFT-SLAM: A deep-learning feature-based monocular visual SLAM method. Neurocomputing 2021, 455, 97–110. [Google Scholar] [CrossRef]
- Peng, Q.; Xiang, Z.; Fan, Y.; Zhao, T.; Zhao, X. RWT-SLAM: Robust visual SLAM for highly weak-textured environments. arXiv 2022, arXiv:2207.03539. [Google Scholar]
- Naveed, K.; Anjum, M.L.; Hussain, W.; Lee, D. Deep introspective SLAM: Deep reinforcement learning based approach to avoid tracking failure in visual SLAM. Auton. Robot. 2022, 46, 705–724. [Google Scholar] [CrossRef]
- Sun, Y.; Hu, J.; Yun, J.; Liu, Y.; Bai, D.; Liu, X.; Zhao, G.; Jiang, G.; Kong, J.; Chen, B. Multi-objective location and mapping based on deep learning and visual slam. Sensors 2022, 22, 7576. [Google Scholar] [CrossRef]
- Godard, C.; Aodha, O.M.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3827–3837. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6621. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar] [CrossRef]
- Vödisch, N.; Cattaneo, D.; Burgard, W.; Valada, A. Continual slam: Beyond lifelong simultaneous localization and mapping through continual learning. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2023; pp. 19–35. [Google Scholar]
- Zhang, J.; Sui, W.; Wang, X.; Meng, W.; Zhu, H.; Zhang, Q. Deep online correction for monocular visual odometry. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), IEEE, Xi’an, China, 30 May–5 June 2021; pp. 14396–14402. [Google Scholar]
- Cimarelli, C.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H. RAUM-VO: Rotational Adjusted Unsupervised Monocular Visual Odometry. Sensors 2022, 22, 2651. [Google Scholar] [CrossRef]
- Kneip, L.; Lynen, S. Direct optimization of frame-to-frame rotation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2352–2359. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-Manifold Preintegration for Real-Time Visual–Inertial Odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef]
- Von Stumberg, L.; Usenko, V.; Cremers, D. Direct Sparse Visual-Inertial Odometry Using Dynamic Marginalization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar] [CrossRef]
- Usenko, V.; Demmel, N.; Schubert, D.; Stuckler, J.; Cremers, D. Visual-Inertial Mapping With Non-Linear Factor Recovery. IEEE Robot. Autom. Lett. 2020, 5, 422–429. [Google Scholar] [CrossRef]
- Delmerico, J.; Scaramuzza, D. A Benchmark Comparison of Monocular Visual-Inertial Odometry Algorithms for Flying Robots. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 2502–2509. [Google Scholar] [CrossRef]
- Qin, T.; Shen, S. Online Temporal Calibration for Monocular Visual-Inertial Systems. arXiv 2018, arXiv:1808.00692. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodriguez, J.J.; Montiel, J.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Khattak, S.; Papachristos, C.; Alexis, K. Keyframe-based Direct Thermal–Inertial Odometry. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef]
- Dang, T.; Tranzatto, M.; Khattak, S.; Mascarich, F.; Alexis, K.; Hutter, M. Graph-based subterranean exploration path planning using aerial and legged robots. J. Field Robot. 2020, 37, 1363–1388. [Google Scholar] [CrossRef]
- Dang, T.; Mascarich, F.; Khattak, S.; Nguyen, H.; Nguyen, H.; Hirsh, S.; Reinhart, R.; Papachristos, C.; Alexis, K. Autonomous Search for Underground Mine Rescue Using Aerial Robots. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, P.; Zhang, H.; Fang, Z.; Scherer, S. TP-TIO: A Robust Thermal-Inertial Odometry with Deep ThermalPoint. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4505–4512. [Google Scholar] [CrossRef]
- Saputra, M.R.U.; Lu, C.X.; de Gusmao, P.P.B.; Wang, B.; Markham, A.; Trigoni, N. Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks. arXiv 2021, arXiv:2104.07196. [Google Scholar] [CrossRef]
- Mueggler, E.; Gallego, G.; Rebecq, H.; Scaramuzza, D. Continuous-Time Visual-Inertial Odometry for Event Cameras. IEEE Trans. Robot. 2018, 34, 1425–1440. [Google Scholar] [CrossRef]
- Rebecq, H.; Horstschaefer, T.; Gallego, G.; Scaramuzza, D. EVO: A Geometric Approach to Event-Based 6-DOF Parallel Tracking and Mapping in Real Time. IEEE Robot. Autom. Lett. 2017, 2, 593–600. [Google Scholar] [CrossRef]
- Vidal, A.R.; Rebecq, H.; Horstschaefer, T.; Scaramuzza, D. Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High-Speed Scenarios. IEEE Robot. Autom. Lett. 2018, 3, 994–1001. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Kohlbrecher, S.; von Stryk, O.; Meyer, J.; Klingauf, U. A flexible and scalable SLAM system with full 3D motion estimation. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 155–160. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Robotics: Science and Systems; University of California: Berkeley, CA, USA, 2014. [Google Scholar]
- Wang, H.; Wang, C.; Chen, C.L.; Xie, L. F-LOAM: Fast LiDAR Odometry and Mapping. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar] [CrossRef]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. In Robotics: Science and Systems; University of California: Berkeley, CA, USA, 2018; Volume 2018, p. 59. [Google Scholar]
- Gräter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. arXiv 2018, arXiv:1807.07524. [Google Scholar]
- Shan, T.; Englot, B.; Ratti, C.; Rus, D. LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping. arXiv 2021, arXiv:2104.10831. [Google Scholar]
- Nguyen, T.M.; Cao, M.; Yuan, S.; Lyu, Y.; Nguyen, T.H.; Xie, L. LIRO: Tightly Coupled Lidar-Inertia-Ranging Odometry. arXiv 2020, arXiv:2010.13072. [Google Scholar]
- Nguyen, T.M.; Yuan, S.; Cao, M.; Nguyen, T.H.; Xie, L. VIRAL SLAM: Tightly Coupled Camera-IMU-UWB-Lidar SLAM. arXiv 2021, arXiv:2105.03296. [Google Scholar]
- Koide, K.; Miura, J.; Menegatti, E. A portable three-dimensional LIDAR-based system for long-term and wide-area people behavior measurement. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419841532. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping. arXiv 2020, arXiv:2007.00258. [Google Scholar]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguère, P.; Behley, J.; Stachniss, C. SuMa++: Efficient LiDAR-based Semantic SLAM. arXiv 2021, arXiv:2105.11320. [Google Scholar]
- Smith, M.; Baldwin, I.; Churchill, W.; Paul, R.; Newman, P. The New College Vision and Laser Data Set. I. J. Robot. Res. 2009, 28, 595–599. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef]
- Engel, J.; Usenko, V.; Cremers, D. A photometrically calibrated benchmark for monocular visual odometry. arXiv 2016, arXiv:1607.02555. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stueckler, J.; Cremers, D. The TUM VI Benchmark for Evaluating Visual-Inertial Odometry. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Salas, M.; Tardós, J.D.; Montiel, J.M.M. Real-time Monocular Object SLAM. arXiv 2015, arXiv:1504.02398. [Google Scholar] [CrossRef]
- Nicholson, L.; Milford, M.; Sünderhauf, N. QuadricSLAM: Constrained Dual Quadrics from Object Detections as Landmarks in Semantic SLAM. arXiv 2018, arXiv:1804.04011. [Google Scholar]
- Yang, S.; Scherer, S.A. CubeSLAM: Monocular 3D Object Detection and SLAM without Prior Models. arXiv 2018, arXiv:1806.00557. [Google Scholar]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A Visual Dynamic Object-aware SLAM System. arXiv 2020, arXiv:2005.11052. [Google Scholar]
- Judd, K.M.; Gammell, J.D. The Oxford Multimotion Dataset: Multiple SE(3) Motions With Ground Truth. IEEE Robot. Autom. Lett. 2019, 4, 800–807. [Google Scholar] [CrossRef]
- Rosinol, A.; Abate, M.; Chang, Y.; Carlone, L. Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1689–1696. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. arXiv 2019, arXiv:1904.01416. [Google Scholar]
- Pandey, G.; McBride, J.R.; Eustice, R.M. Ford Campus vision and lidar data set. Int. J. Robot. Res. 2011, 30, 1543–1552. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar] [CrossRef]
- Atanasov, N.; Zhu, M.; Daniilidis, K.; Pappas, G.J. Localization from semantic observations via the matrix permanent. Int. J. Robot. Res. 2016, 35, 73–99. [Google Scholar] [CrossRef]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic SLAM. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar] [CrossRef]
- Lianos, N.; Schönberger, J.L.; Pollefeys, M.; Sattler, T. VSO: Visual Semantic Odometry. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Doherty, K.; Baxter, D.; Schneeweiss, E.; Leonard, J. Probabilistic Data Association via Mixture Models for Robust Semantic SLAM. arXiv 2019, arXiv:1909.11213. [Google Scholar]
- Bavle, H.; De La Puente, P.; How, J.P.; Campoy, P. VPS-SLAM: Visual Planar Semantic SLAM for Aerial Robotic Systems. IEEE Access 2020, 8, 60704–60718. [Google Scholar] [CrossRef]
- Sanchez-Lopez, J.L.; Castillo-Lopez, M.; Voos, H. Semantic situation awareness of ellipse shapes via deep learning for multirotor aerial robots with a 2D LIDAR. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 1–4 September 2020; pp. 1014–1023. [Google Scholar] [CrossRef]
- Li, L.; Kong, X.; Zhao, X.; Li, W.; Wen, F.; Zhang, H.; Liu, Y. SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure. arXiv 2021, arXiv:2106.11516. [Google Scholar]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J. RDMO-SLAM: Real-time Visual SLAM for Dynamic Environments using Semantic Label Prediction with Optical Flow. IEEE Access 2021, 9, 106981–106997. [Google Scholar] [CrossRef]
- Mao, M.; Zhang, H.; Li, S.; Zhang, B. SEMANTIC-RTAB-MAP (SRM): A semantic SLAM system with CNNs on depth images. Math. Found. Comput. 2019, 2, 29–41. [Google Scholar] [CrossRef]
- Lai, L.; Yu, X.; Qian, X.; Ou, L. 3D Semantic Map Construction System Based on Visual SLAM and CNNs. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, IEEE, Singapore, 18–21 October 2020. [Google Scholar] [CrossRef]
- Hempel, T.; Al-Hamadi, A. An online semantic mapping system for extending and enhancing visual SLAM. Eng. Appl. Artif. Intell. 2022, 111, 104830. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar] [CrossRef]
- Tian, Y.; Chang, Y.; Arias, F.H.; Nieto-Granda, C.; How, J.; Carlone, L. Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems. IEEE Trans. Robot. 2022, 38, 2022–2038. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Q.; Li, J.; Zhang, S.; Liu, J. A Computationally Efficient Semantic SLAM Solution for Dynamic Scenes. Remote Sens. 2019, 11, 1363. [Google Scholar] [CrossRef]
- Liu, G.; Zeng, W.; Feng, B.; Xu, F. DMS-SLAM: A general visual SLAM system for dynamic scenes with multiple sensors. Sensors 2019, 19, 3714. [Google Scholar] [CrossRef] [PubMed]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. DP-SLAM: A visual SLAM with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Oleynikova, H.; Millane, A.; Taylor, Z.; Galceran, E.; Nieto, J.; Siegwart, R. Signed distance fields: A natural representation for both mapping and planning. In Proceedings of the RSS 2016 Workshop: Geometry and Beyond-Representations, Physics, and Scene Understanding for Robotics, University of Michigan, Ann Arbor, MI, USA, 18–22 June 2016. [Google Scholar]
- Oleynikova, H.; Taylor, Z.; Siegwart, R.; Nieto, J. Safe local exploration for replanning in cluttered unknown environments for microaerial vehicles. IEEE Robot. Autom. Lett. 2018, 3, 1474–1481. [Google Scholar] [CrossRef]
- Chibane, J.; Mir, A.; Pons-Moll, G. Neural Unsigned Distance Fields for Implicit Function Learning. arXiv 2020, arXiv:2010.13938. [Google Scholar]
- Han, L.; Gao, F.; Zhou, B.; Shen, S. FIESTA: Fast Incremental Euclidean Distance Fields for Online Motion Planning of Aerial Robots. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Venetian Macao, Macau, 3–8 November 2019. [Google Scholar] [CrossRef]
- Zucker, M.; Ratliff, N.; Dragan, A.D.; Pivtoraiko, M.; Klingensmith, M.; Dellin, C.M.; Bagnell, J.A.; Srinivasa, S.S. Chomp: Covariant hamiltonian optimization for motion planning. Int. J. Robot. Res. 2013, 32, 1164–1193. [Google Scholar] [CrossRef]
- Oleynikova, H.; Taylor, Z.; Fehr, M.; Siegwart, R.; Nieto, J. Voxblox: Incremental 3D Euclidean Signed Distance Fields for on-board MAV planning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar] [CrossRef]
- Reijgwart, V.; Millane, A.; Oleynikova, H.; Siegwart, R.; Cadena, C.; Nieto, J. Voxgraph: Globally Consistent, Volumetric Mapping Using Signed Distance Function Submaps. IEEE Robot. Autom. Lett. 2020, 5, 227–234. [Google Scholar] [CrossRef]
- Millane, A.; Oleynikova, H.; Lanegger, C.; Delmerico, J.; Nieto, J.; Siegwart, R.; Pollefeys, M.; Cadena, C. Freetures: Localization in Signed Distance Function Maps. arXiv 2020, arXiv:2010.09378. [Google Scholar] [CrossRef]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J.I. Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery. arXiv 2019, arXiv:1903.00268. [Google Scholar] [CrossRef]
- Pan, Y.; Kompis, Y.; Bartolomei, L.; Mascaro, R.; Stachniss, C.; Chli, M. Voxfield: Non-Projective Signed Distance Fields for Online Planning and 3D Reconstruction. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Kyoto, Japan, 23–27 October 2022; pp. 5331–5338. [Google Scholar]
- Narita, G.; Seno, T.; Ishikawa, T.; Kaji, Y. PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4205–4212. [Google Scholar] [CrossRef]
- Schmid, L.; Delmerico, J.; Schönberger, J.; Nieto, J.; Pollefeys, M.; Siegwart, R.; Cadena, C. Panoptic Multi-TSDFs: A Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8018–8024. [Google Scholar] [CrossRef]
- Sitzmann, V.; Zollhöfer, M.; Wetzstein, G. Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8 December 2019. [Google Scholar]
- Sitzmann, V.; Martel, J.N.P.; Bergman, A.W.; Lindell, D.B.; Wetzstein, G. Implicit Neural Representations with Periodic Activation Functions. arXiv 2020, arXiv:2006.09661. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit Mapping and Positioning in Real-Time. arXiv 2021, arXiv:2103.12352. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Rosinol, A.; Leonard, J.J.; Carlone, L. NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields. arXiv 2022, arXiv:2210.13641. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Cui, Z.; Oswald, M.R.; Geiger, A.; Pollefeys, M. NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM. arXiv 2023, arXiv:2302.03594. [Google Scholar]
- Johari, M.M.; Carta, C.; Fleuret, F. ESLAM: Efficient Dense SLAM System Based on Hybrid Representation of Signed Distance Fields. arXiv 2022, arXiv:2211.11704. [Google Scholar]
- Kruzhkov, E.; Savinykh, A.; Karpyshev, P.; Kurenkov, M.; Yudin, E.; Potapov, A.; Tsetserukou, D. MeSLAM: Memory Efficient SLAM based on Neural Fields. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, Prague, Czech Republic, 9–12 October 2022; pp. 430–435. [Google Scholar]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.; Glocker, B.; Davison, A. ElasticFusion: Dense SLAM without a pose graph. In Robotics: Science and Systems; Sapienza University of Rome: Rome, Italy, 2015. [Google Scholar]
- Wang, K.; Gao, F.; Shen, S. Real-time scalable dense surfel mapping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), IEEE, Montreal, QC, Canada, 20–24 May 2019; pp. 6919–6925. [Google Scholar]
- Armeni, I.; He, Z.; Gwak, J.; Zamir, A.R.; Fischer, M.; Malik, J.; Savarese, S. 3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera. In Proceedings of the the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5664–5673. [Google Scholar]
- Wald, J.; Dhamo, H.; Navab, N.; Tombari, F. Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions. arXiv 2020, arXiv:2004.03967. [Google Scholar]
- Wu, S.C.; Wald, J.; Tateno, K.; Navab, N.; Tombari, F. SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Rosinol, A.; Gupta, A.; Abate, M.; Shi, J.; Carlone, L. 3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans. arXiv 2020, arXiv:2002.06289. [Google Scholar]
- Rosinol, A.; Violette, A.; Abate, M.; Hughes, N.; Chang, Y.; Shi, J.; Gupta, A.; Carlone, L. Kimera: From SLAM to Spatial Perception with 3D Dynamic Scene Graphs. arXiv 2021, arXiv:2101.06894. [Google Scholar] [CrossRef]
- Rematas, K.; Liu, A.; Srinivasan, P.P.; Barron, J.T.; Tagliasacchi, A.; Funkhouser, T.; Ferrari, V. Urban Radiance Fields. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Turki, H.; Ramanan, D.; Satyanarayanan, M. Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 12922–12931. [Google Scholar]
- Schöps, T.; Sattler, T.; Pollefeys, M. Surfelmeshing: Online surfel-based mesh reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2494–2507. [Google Scholar] [CrossRef]
- Hughes, N.; Chang, Y.; Carlone, L. Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization. arXiv 2022, arXiv:2201.13360. [Google Scholar]
- Ravichandran, Z.; Peng, L.; Hughes, N.; Griffith, J.D.; Carlone, L. Hierarchical Representations and Explicit Memory: Learning Effective Navigation Policies on 3D Scene Graphs using Graph Neural Networks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), IEEE, Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar] [CrossRef]
- Agia, C.; Jatavallabhula, K.; Khodeir, M.; Miksik, O.; Vineet, V.; Mukadam, M.; Paull, L.; Shkurti, F. Taskography: Evaluating robot task planning over large 3D scene graphs. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 46–58. [Google Scholar]
- Looper, S.; Rodriguez-Puigvert, J.; Siegwart, R.; Cadena, C.; Schmid, L. 3D VSG: Long-term Semantic Scene Change Prediction through 3D Variable Scene Graphs. arXiv 2022, arXiv:2209.07896. [Google Scholar]
- Castillo-Lopez, M.; Ludivig, P.; Sajadi-Alamdari, S.A.; Sánchez-López, J.L.; Olivares-Méndez, M.A.; Voos, H. A Real-Time Approach for Chance-Constrained Motion Planning with Dynamic Obstacles. IEEE Robot. Autom. Lett. 2020, 5, 3620–3625. [Google Scholar] [CrossRef]
- Fang, J.; Wang, F.; Shen, P.; Zheng, Z.; Xue, J.; Chua, T.S. Behavioral intention prediction in driving scenes: A survey. arXiv 2022, arXiv:2211.00385. [Google Scholar]
- Rasouli, A.; Tsotsos, J.K. Autonomous Vehicles That Interact With Pedestrians: A Survey of Theory and Practice. IEEE Trans. Intell. Transp. Syst. 2020, 21, 900–918. [Google Scholar] [CrossRef]
- Guo, J.; Kurup, U.; Shah, M. Is it Safe to Drive? An Overview of Factors, Metrics, and Datasets for Driveability Assessment in Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3135–3151. [Google Scholar] [CrossRef]
- Wang, W.; Wang, L.; Zhang, C.; Liu, C.; Sun, L. Social Interactions for Autonomous Driving: A Review and Perspectives. Found. Trends® Robot. 2022, 10, 198–376. [Google Scholar] [CrossRef]
- Kwak, J.Y.; Ko, B.C.; Nam, J.Y. Pedestrian intention prediction based on dynamic fuzzy automata for vehicle driving at nighttime. Infrared Phys. Technol. 2017, 81, 41–51. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Wang, H.; Ai, Y.; Cao, D.; Velenis, E.; Wang, F.Y. Driver Lane Change Intention Inference for Intelligent Vehicles: Framework, Survey, and Challenges. IEEE Trans. Veh. Technol. 2019, 68, 4377–4390. [Google Scholar] [CrossRef]
- Fang, Z.; Lopez, A.M. Intention Recognition of Pedestrians and Cyclists by 2D Pose Estimation. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4773–4783. [Google Scholar] [CrossRef]
- Izquierdo, R.; Quintanar, A.; Parra, I.; Fernandez-Llorca, D.; Sotelo, M.A. Experimental validation of lane-change intention prediction methodologies based on CNN and LSTM. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), IEEE, Auckland, New Zealand, 27–30 October 2019. [Google Scholar] [CrossRef]
- Rasouli, A.; Yau, T.; Rohani, M.; Luo, J. Multi-Modal Hybrid Architecture for Pedestrian Action Prediction. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), IEEE, Aachen, Germany, 5–9 June 2022. [Google Scholar] [CrossRef]
- Cadena, P.R.G.; Qian, Y.; Wang, C.; Yang, M. Pedestrian Graph +: A Fast Pedestrian Crossing Prediction Model Based on Graph Convolutional Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21050–21061. [Google Scholar] [CrossRef]
- Achaji, L.; Moreau, J.; Fouqueray, T.; Aioun, F.; Charpillet, F. Is attention to bounding boxes all you need for pedestrian action prediction? In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), IEEE, Aachen, Germany, 4–9 June 2022. [Google Scholar] [CrossRef]
- Li, C.; Chan, S.H.; Chen, Y.T. Who Make Drivers Stop? Towards Driver-centric Risk Assessment: Risk Object Identification via Causal Inference. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef] [PubMed]
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; Arras, K.O. Human Motion Trajectory Prediction: A Survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Huang, Y.; Du, J.; Yang, Z.; Zhou, Z.; Zhang, L.; Chen, H. A Survey on Trajectory-Prediction Methods for Autonomous Driving. IEEE Trans. Intell. Veh. 2022, 7, 652–674. [Google Scholar] [CrossRef]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep Learning-Based Vehicle Behavior Prediction for Autonomous Driving Applications: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 33–47. [Google Scholar] [CrossRef]
- Ridel, D.; Rehder, E.; Lauer, M.; Stiller, C.; Wolf, D. A Literature Review on the Prediction of Pedestrian Behavior in Urban Scenarios. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3105–3112. [Google Scholar] [CrossRef]
- Chang, X.; Ren, P.; Xu, P.; Li, Z.; Chen, X.; Hauptmann, A. A Comprehensive Survey of Scene Graphs: Generation and Application. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Mees, O.; Zeng, A.; Burgard, W. Audio Visual Language Maps for Robot Navigation. arXiv 2023, arXiv:2303.07522. [Google Scholar]
- Jatavallabhula, K.M.; Kuwajerwala, A.; Gu, Q.; Omama, M.; Chen, T.; Li, S.; Iyer, G.; Saryazdi, S.; Keetha, N.; Tewari, A.; et al. ConceptFusion: Open-set Multimodal 3D Mapping. arXiv 2023, arXiv:2302.07241. [Google Scholar]
- Cornejo-Lupa, M.A.; Cardinale, Y.; Ticona-Herrera, R.; Barrios-Aranibar, D.; Andrade, M.; Diaz-Amado, J. OntoSLAM: An Ontology for Representing Location and Simultaneous Mapping Information for Autonomous Robots. Robotics 2021, 10, 125. [Google Scholar] [CrossRef]
- Bavle, H.; Sanchez-Lopez, J.L.; Shaheer, M.; Civera, J.; Voos, H. Situational Graphs for Robot Navigation in Structured Indoor Environments. IEEE Robot. Autom. Lett. 2022, 7, 9107–9114. [Google Scholar] [CrossRef]
- Bavle, H.; Sanchez-Lopez, J.L.; Shaheer, M.; Civera, J.; Voos, H. S-Graphs+: Real-time Localization and Mapping leveraging Hierarchical Representations. arXiv 2023, arXiv:2212.11770. [Google Scholar]







| Classification | Sensor | Measurement | Mobile Robotic Platforms | Limitations | Examples |
|---|---|---|---|---|---|
| Proprioceptive | IMU |
| Indoor/outdoor robots |
| MPU-6050 |
| GPS |
| Outdoor robots |
| u-blox NEO-M8N | |
| Barometer |
| Indoor/outdoor aerial robots |
| Bosch BMP280 | |
| Robot encoders |
| Indoor/outdoor ground robots |
| US Digital E4P | |
| RF Receiver |
| Indoor/outdoor robots |
| DecaWave DWM1000 | |
| Exteroceptive | RGB camera |
| Indoor/outdoor robots |
| IDS uEye LE |
| RGB-D Camera |
| Indoor/outdoor robots |
| Intel Realsense D435 | |
| IR Camera |
| Indoor/outdoor robots |
| FLIR Lepton | |
| Event camera |
| Indoor/outdoor robots |
| DAVIS 346 or SONY IMX636ES | |
| LIDAR |
| Indoor/outdoor robots |
| Velodyne VLP-16 | |
| MmWave FMCW RADAR |
| Indoor/Outdoor Robots |
| AWR6843AOP |
| Modality | Sensor | Method | DL | Limitations | References |
|---|---|---|---|---|---|
| Monomodal | RGB | Feature detection | ✗ |
| [25,26,27,28,29,30,31,32,33,34] |
| Object detection | ✓ |
| [35] | ||
| Semantic segmentation | ✓ |
| [36,37,38,39,40,41,42,43,44] | ||
| Panoptic segmentation | ✓ |
| [45,46] | ||
| 2D Scene graphs | ✓ |
| [47,48,49] | ||
| Thermal | Object detection | ✗ |
| [50] | |
| Object detection | ✓ |
| [51,52] | ||
| Event | Object detection | ✓ |
| [53,54] | |
| Semantic segmentation | ✓ |
| [54] | ||
| LIDAR | Object detection | ✗ |
| [55,56,57] | |
| Semantic segmentation | ✓ |
| [58,59,60,61,62,63,64,65,66] | ||
| Multimodal | RGB + Depth | Object detection | ✗ |
| [67,68] |
| Object detection | ✓ |
| [69,70,71,72,73] | ||
| RGB + Thermal | Semantic Segmentation | ✓ |
| [74,75,76,77] | |
| RGB + Event | Semantic segmentation | ✓ |
| [78] | |
| RGB + LIDAR | Object detection | ✓ |
| [79,80,81,82,83] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bavle, H.; Sanchez-Lopez, J.L.; Cimarelli, C.; Tourani, A.; Voos, H. From SLAM to Situational Awareness: Challenges and Survey. Sensors 2023, 23, 4849. https://doi.org/10.3390/s23104849
Bavle H, Sanchez-Lopez JL, Cimarelli C, Tourani A, Voos H. From SLAM to Situational Awareness: Challenges and Survey. Sensors. 2023; 23(10):4849. https://doi.org/10.3390/s23104849
Chicago/Turabian StyleBavle, Hriday, Jose Luis Sanchez-Lopez, Claudio Cimarelli, Ali Tourani, and Holger Voos. 2023. "From SLAM to Situational Awareness: Challenges and Survey" Sensors 23, no. 10: 4849. https://doi.org/10.3390/s23104849
APA StyleBavle, H., Sanchez-Lopez, J. L., Cimarelli, C., Tourani, A., & Voos, H. (2023). From SLAM to Situational Awareness: Challenges and Survey. Sensors, 23(10), 4849. https://doi.org/10.3390/s23104849