
Outdoor Vision-and-Language Navigation Needs Object-Level Alignment


Abstract
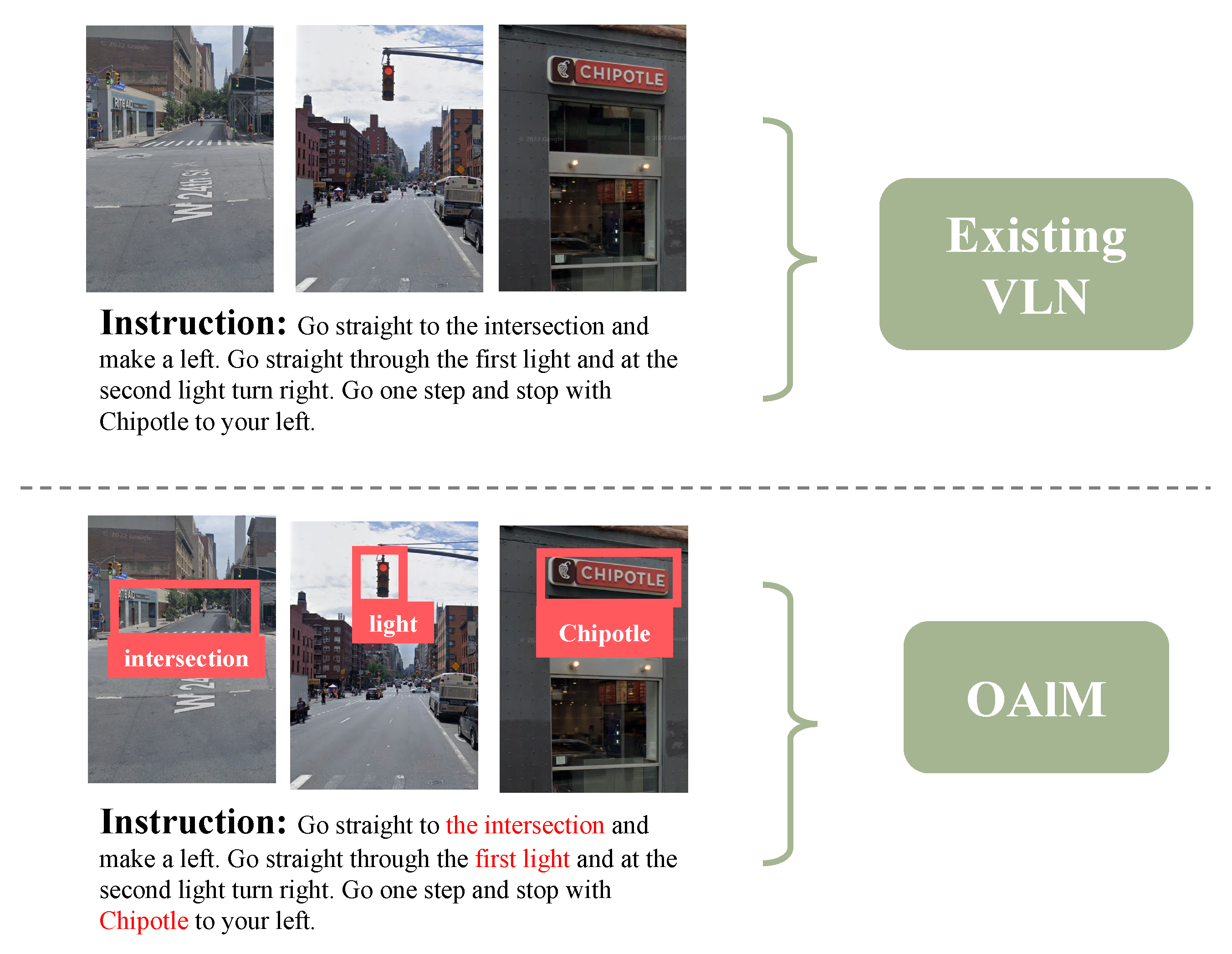
:1. Introduction
- We developed an object-level alignment module (OAlM) and used OCR and object-detection technology to identify the prominent landmarks. OAlM pays more attention to landmarks and helps the agent understand the environment to improve navigation ability.
- We extensively evaluated our approach and found that it outperforms all metrics on the Touchdown dataset against multiple existing methods, exceeding the baseline by 3.19% on task completion (TC).
2. Related Works
2.1. Vision-and-Language Navigation
2.2. Outdoor Vision-and-Language Navigation Models
2.3. Object-Aware Vision-and-Language Navigation
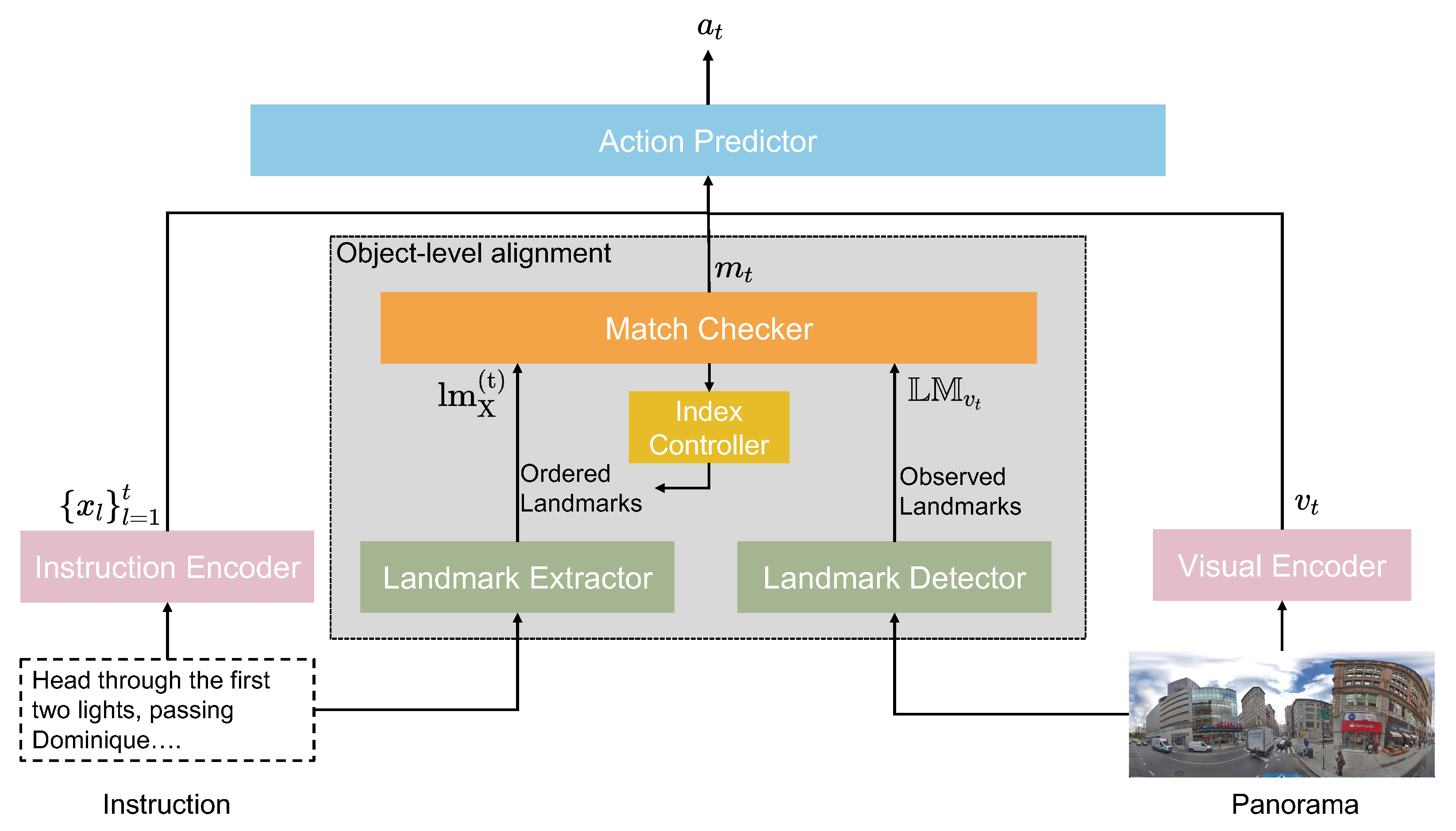
3. Proposed Methods: OAlM
3.1. VLN Problem Definition
3.2. Overview
3.3. OAlM
- Landmark Detector: At each timestep t, the landmark detector identifies the text on signboards and objects at the current node as . To obtain the high quality , we set a threshold.is a set of observed landmarks, where n is the maximum number of landmarks at a panoramic view location .
- Landmark Extractor: To extract this sequence from the natural language instructions, we employed a standard large language model, which in our prototype was GPT-3 [28]. We used a prompt with three examples of correct landmark extractions, and the model was then used to extract a list of landmarks from the instructions. We evaluated the performance on 20 test pairs, the accuracy of GPT-3 outputs was 99%. Therefore, the model’s output was reliable and robust to small changes in the input prompts. For instance, if the prompts give the instructions “Continue down the long block to the next light with Starbucks on the near left corner. Turn right, then stop. Dunkin’ Donuts should be ahead on your right”, the landmark extractor will output “Starbucks, Dunkin’ Donuts” as the ordered landmarks. In this case, the agent would check to see if it has arrived at Starbucks first and then check Dunkin’ Donuts. We extract the list of ordered landmarks from instructions X, where d is the maximum number of ordered landmarks extracted.
- Match Checker and Index Controller: The match checker determines if an agent has reached a known landmark, while the index controller keeps track of the reference landmark that the agent should arrive at next. At the beginning of navigation, the index controller points to the first of the ordered landmarks obtained using the landmark extractor.
- With Equation (2), the match checker calculates the cosine similarity between all of the landmarks observed in the environment and and uses this as a matching score to check if the agent has reached the current reference landmark . If the matching score is over the set threshold, the index controller will indicate to the agent the next reference landmark until the agent reaches the last landmark.
3.4. Inference of OAlM
4. Experiments
4.1. Implementation Details
4.2. Dataset
4.3. Metrics
- (1)
- Task Completion (TC): the accuracy of navigating to the correct location. The correct location is defined as the exact goal panorama or one of its neighboring panoramas.
- (2)
- Shortest-Path Distance (SPD) [6]: the mean distance between the agent’s final position and the goal position in the environment graph.
- (3)
- Success Weighted by Edit Distance (SED): the normalized Levenshtein edit distance [38] between the predicted path and the ground-truth path, with points only awarded for successful paths.
- (4)
- Coverage Weighted by Length Score (CLS) [39]: a measurement of the fidelity of the agent’s path with respect to the ground-truth path.
- (5)
- Normalized Dynamic Time Warping (nDTW) [40]: the minimized cumulative distance between the predicted path and the ground-truth path.
- (6)
- Success Weighted Dynamic Time Warping (SDTW): the nDTW value where the summation is only of successful navigation.
4.4. Results
4.4.1. Quantitative Results
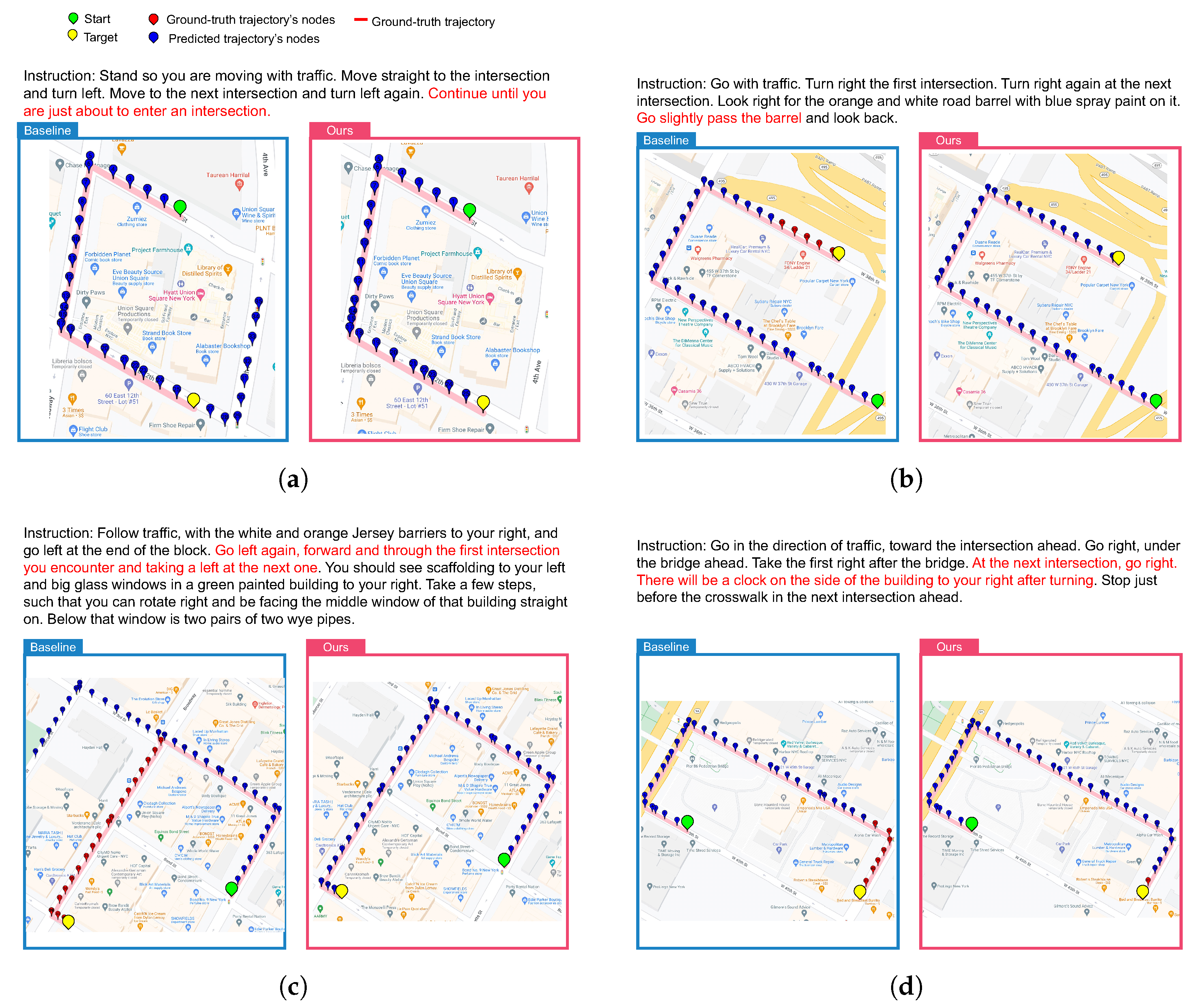
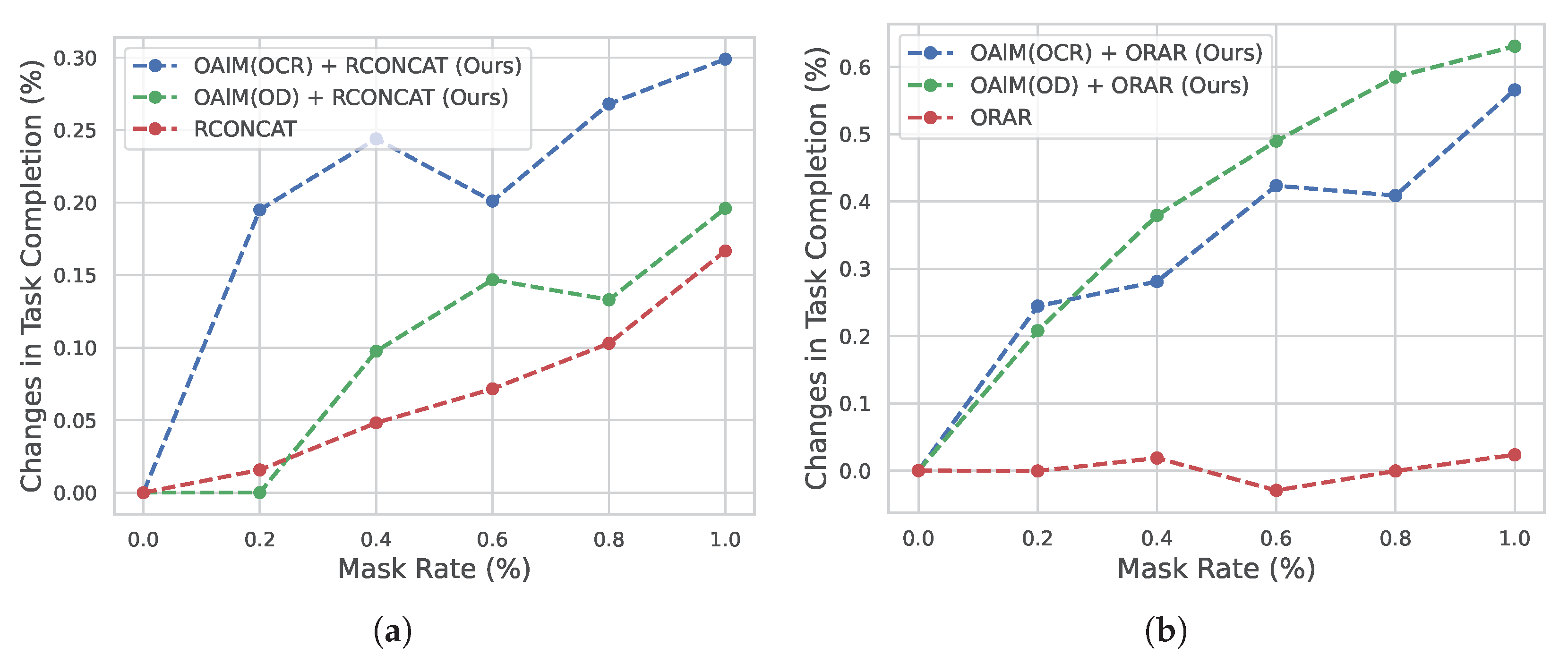
4.4.2. Qualitative Results
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| VLN | Vision-and-Lagnauge Navigation |
| LSTM | Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| GPT-3 | Generative Pre-trained Transformer 3 |
| FFNN | Feed-Forward Neural Network |
| OCR | Optical Character Recognition |
References
- Gu, J.; Stefani, E.; Wu, Q.; Thomason, J.; Wang, X. Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions. In Proceedings of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Qi, Y.; Pan, Z.; Zhang, S.; van den Hengel, A.; Wu, Q. Object-and-Action Aware Model for Visual Language Navigation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Gao, C.; Chen, J.; Liu, S.; Wang, L.; Zhang, Q.; Wu, Q. Room-and-Object Aware Knowledge Reasoning for Remote Embodied Referring Expression. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Sünderhauf, N.; Reid, I.; Gould, S.; van den Hengel, A. Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mirowski, P.; Grimes, M.K.; Malinowski, M.; Hermann, K.M.; Anderson, K.; Teplyashin, D.; Simonyan, K.; Kavukcuoglu, K.; Zisserman, A.; Hadsell, R. Learning to Navigate in Cities Without a Map. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Chen, H.; Suhr, A.; Misra, D.; Snavely, N.; Artzi, Y. TOUCHDOWN: Natural Language Navigation and Spatial Reasoning in Visual Street Environments. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chaplot, D.S.; Sathyendra, K.M.; Pasumarthi, R.K.; Rajagopal, D.; Salakhutdinov, R. Gated-Attention Architectures for Task-Oriented Language Grounding. In Proceedings of the Association for the Advancement of Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Xiang, J.; Wang, X.; Wang, W.Y. Learning to Stop: A Simple yet Effective Approach to Urban Vision-Language Navigation. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Zhu, W.; Wang, X.; Fu, T.J.; Yan, A.; Narayana, P.; Sone, K.; Basu, S.; Wang, W.Y. Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation. In Proceedings of the EAssociation for Computational Linguistics, Online, 19–23 April 2021. [Google Scholar]
- Schumann, R.; Riezler, S. Analyzing Generalization of Vision and Language Navigation to Unseen Outdoor Areas. In Proceedings of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Chan, E.; Baumann, O.; Bellgrove, M.; Mattingley, J. From Objects to Landmarks: The Function of Visual Location Information in Spatial Navigation. Front. Psychol. 2012, 3, 304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moudgil, A.; Majumdar, A.; Agrawal, H.; Lee, S.; Batra, D. SOAT: A Scene- and Object-Aware Transformer for Vision-and-Language Navigation. In Proceedings of the Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Zhu, F.; Liang, X.; Zhu, Y.; Yu, Q.; Chang, X.; Liang, X. SOON: Scenario Oriented Object Navigation with Graph-Based Exploration. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hu, R.; Fried, D.; Rohrbach, A.; Klein, D.; Darrell, T.; Saenko, K. Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation. In Proceedings of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Tan, H.; Bansal, M. Diagnosing the Environment Bias in Vision-and-Language Navigation. In Proceedings of the International Joint Conference on Artificial Intelligence, Online, 19–26 August 2020. [Google Scholar]
- Majumdar, A.; Shrivastava, A.; Lee, S.; Anderson, P.; Parikh, D.; Batra, D. Improving Vision-and-Language Navigation with Image-Text Pairs from the Web. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yan, A.; Wang, X.E.; Feng, J.; Li, L.; Wang, W.Y. Cross-Lingual Vision-Language Navigation. arXiv 2019, arXiv:1910.11301. [Google Scholar] [CrossRef]
- Ku, A.; Anderson, P.; Patel, R.; Ie, E.; Baldridge, J. Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Mehta, H.; Artzi, Y.; Baldridge, J.; Ie, E.; Mirowski, P. Retouchdown: Releasing Touchdown on StreetLearn as a Public Resource for Language Grounding Tasks in Street View. In Proceedings of the Empirical Methods in Natural Language Processing-SpLU, Online, 16–20 November 2020. [Google Scholar] [CrossRef]
- Hermann, K.; Malinowski, M.; Mirowski, P.; Banki-Horvath, A.; Anderson, K.; Hadsell, R. Learning to Follow Directions in Street View. Assoc. Adv. Artif. Intell. 2020, 34, 11773–11781. [Google Scholar] [CrossRef]
- Schumann, R.; Riezler, S. Generating Landmark Navigation Instructions from Maps as a Graph-to-Text Problem. In Proceedings of the Association for Computational Linguistics, Bangkok, Thailand, 1–6 August 2021. [Google Scholar]
- Vasudevan, A.B.; Dai, D.; Van Gool, L. Talk2Nav: Long-Range Vision-and-Language Navigation with Dual Attention and Spatial Memory. Int. J. Comput. Vis. 2021, 129, 246–266. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAAssociation for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Qi, Y.; Pan, Z.; Hong, Y.; Yang, M.H.; Hengel, A.v.d.; Wu, Q. The Road to Know-Where: An Object-and-Room Informed Sequential BERT for Indoor Vision-Language Navigation. In Proceedings of the International Conference on Computer Vision, Online, 11–17 October 2021. [Google Scholar]
- Song, C.H.; Kil, J.; Pan, T.Y.; Sadler, B.M.; Chao, W.L.; Su, Y. One Step at a Time: Long-Horizon Vision-and-Language Navigation With Milestones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15482–15491. [Google Scholar]
- Shridhar, M.; Thomason, J.; Gordon, D.; Bisk, Y.; Han, W.; Mottaghi, R.; Zettlemoyer, L.; Fox, D. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Volume 33. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition. In Proceedings of the Artificial Neural Networks: Formal Models and Their Applications—ICANN, Warsaw, Poland, 11–15 September 2005; Duch, W., Kacprzyk, J., Oja, E., Zadrożny, S., Eds.; 2005. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html (accessed on 15 October 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Srihari, S.N.; Shekhawat, A.; Lam, S.W. Optical Character Recognition (OCR). In Encyclopedia of Computer Science; Van Nostrand Reinhold Company: New York, NY, USA, 2003; pp. 1326–1333. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar] [CrossRef]
- Levenshtein, V. Leveinshtein Distance. 1965. Available online: https://rybn.org/ANTI/ADMXI/documentation/ALGORITHM_DOCUMENTATION/HARMONY_OF_THE_SPEARS/LEVENSHTEIN_EDIT_DISTANCE/ABOUT/NIST_Levenshtein_Edit_Distance.pdf (accessed on 10 November 2021).
- Jain, V.; Magalhaes, G.; Ku, A.; Vaswani, A.; Ie, E.; Baldridge, J. Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation. In Proceedings of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Magalhaes, G.I.; Jain, V.; Ku, A.; Ie, E.; Baldridge, J. General Evaluation for Instruction Conditioned Navigation using Dynamic Time Warping. In Proceedings of the Neural Information Processing Systems Visually Grounded Interaction and Language (ViGIL) Workshop, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Zhu, W.; Qi, Y.; Narayana, P.; Sone, K.; Basu, S.; Wang, X.; Wu, Q.; Eckstein, M.; Wang, W.Y. Diagnosing Vision-and-Language Navigation: What Really Matters. In Proceedings of the NAAssociation for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | TC↑ | SPD↓ | SED↑ | CLS↑ | nDTW↑ | sDTW↑ |
|---|---|---|---|---|---|---|
| ORAR (baseline) | 24.23 | 17.30 | 23.70 | 56.87 | 37.20 | 22.87 |
| OAlM (+OCR 0.70) | 25.86 | 16.94 | 25.27 | 58.21 | 38.23 | 24.29 |
| OAlM (+OCR 0.80) | 24.51 | 17.39 | 23.92 | 56.53 | 36.37 | 23.06 |
| OAlM (+OCR 0.90) | 25.84 | 17.45 | 25.17 | 56.37 | 37.45 | 24.20 |
| RCONCAT (baseline) | 8.94 | 22.48 | 8.55 | 43.23 | 18.20 | 7.98 |
| OAlM (+OCR 0.70) | 11.64 | 21.15 | 11.26 | 44.11 | 20.95 | 10.74 |
| OAlM (+OCR 0.80) | 9.94 | 21.47 | 9.67 | 44.28 | 20.34 | 9.21 |
| OAlM (+OCR 0.90) | 11.07 | 20.99 | 10.41 | 44.19 | 21.10 | 9.94 |
| GA (baseline) | 9.87 | 20.34 | 9.42 | 47.77 | 21.51 | 8.92 |
| OAlM (+OCR 0.70) | 10.36 | 20.58 | 9.91 | 48.01 | 22.55 | 9.24 |
| OAlM (+OCR 0.80) | 11.43 | 20.20 | 11.11 | 49.03 | 23.84 | 10.51 |
| OAlM (+OCR 0.90) | 10.93 | 19.62 | 10.63 | 47.85 | 22.68 | 10.09 |
| Experiment | TC↑ | SPD↓ | SED↑ | CLS↑ | nDTW↑ | sDTW↑ |
|---|---|---|---|---|---|---|
| ORAR (baseline) | 24.23 | 17.30 | 23.70 | 56.87 | 37.20 | 22.87 |
| OAlM (+OD 0.70) | 24.70 | 16.76 | 24.10 | 57.66 | 36.99 | 23.04 |
| OAlM (+OD 0.80) | 24.94 | 17.08 | 24.32 | 56.91 | 37.06 | 23.39 |
| OAlM (+OD 0.90) | 24.72 | 16.52 | 24.12 | 58.33 | 37.63 | 23.20 |
| RCONCAT (baseline) | 8.94 | 22.48 | 8.55 | 43.23 | 18.20 | 7.98 |
| OAlM (+OD 0.70) | 9.65 | 21.84 | 9.31 | 43.40 | 20.24 | 8.83 |
| OAlM (+OD 0.80) | 8.66 | 21.45 | 8.43 | 42.87 | 20.52 | 8.11 |
| OAlM (+OD 0.90) | 10.15 | 20.56 | 9.77 | 45.99 | 21.22 | 9.23 |
| GA (baseline) | 9.87 | 20.34 | 9.42 | 47.77 | 21.51 | 8.92 |
| OAlM (+OD 0.70) | 11.57 | 20.39 | 11.23 | 47.89 | 22.61 | 10.60 |
| OAlM (+OD 0.80) | 13.06 | 20.36 | 12.56 | 48.49 | 23.36 | 11.86 |
| OAlM (+OD 0.90) | 10.86 | 20.79 | 10.57 | 48.17 | 22.98 | 10.06 |
| Baselines | OAlM | |
|---|---|---|
| ORAR | 32.76 | 4.38 |
| RCONCAT | 15.34 | 7.87 |
| GA | 23.23 | 5.84 |
| Experiment | TC↑ | SPD↓ | SED↑ | CLS↑ | nDTW↑ | sDTW↑ |
|---|---|---|---|---|---|---|
| ORAR (baseline) | 24.23 | 17.30 | 23.70 | 56.87 | 37.20 | 22.87 |
| +OCR&OD 0.40 | 24.96 | 16.53 | 24.48 | 58.65 | 38.06 | 23.48 |
| +OCR&OD 0.50 | 24.81 | 16.85 | 24.10 | 57.08 | 36.90 | 23.19 |
| +OCR&OD 0.60 | 22.73 | 18.20 | 22.23 | 55.02 | 35.01 | 21.41 |
| +OCR&OD 0.70 | 22.92 | 16.90 | 22.87 | 57.41 | 36.37 | 21.43 |
| +OCR&OD 0.80 | 23.35 | 17.10 | 22.82 | 57.14 | 36.50 | 21.99 |
| +OCR&OD 0.90 | 22.27 | 18.47 | 21.73 | 53.57 | 34.34 | 20.85 |
| RCONCAT (baseline) | 8.94 | 22.48 | 8.55 | 43.23 | 18.20 | 7.98 |
| +OCR&OD 0.40 | 10.15 | 21.45 | 9.58 | 43.63 | 20.05 | 8.90 |
| +OCR&OD 0.50 | 9.44 | 21.51 | 9.03 | 44.08 | 20.25 | 8.49 |
| +OCR&OD 0.60 | 8.52 | 21.78 | 8.28 | 42.30 | 18.82 | 7.91 |
| +OCR&OD 0.70 | 9.01 | 21.69 | 8.55 | 44.46 | 19.05 | 7.73 |
| +OCR&OD 0.80 | 9.65 | 21.45 | 9.20 | 44.43 | 20.24 | 8.56 |
| +OCR&OD 0.90 | 8.87 | 21.02 | 8.49 | 44.35 | 20.00 | 7.93 |
| GA (baseline) | 9.87 | 20.34 | 9.42 | 47.77 | 21.51 | 8.92 |
| +OCR&OD 0.40 | 11.50 | 19.82 | 11.19 | 49.19 | 23.76 | 10.57 |
| +OCR&OD 0.50 | 10.01 | 19.70 | 9.73 | 48.33 | 22.17 | 9.22 |
| +OCR&OD 0.60 | 11.71 | 19.17 | 11.28 | 49.05 | 23.67 | 10.69 |
| +OCR&OD 0.70 | 7.67 | 23.23 | 7.34 | 42.95 | 16.32 | 6.74 |
| +OCR&OD 0.80 | 9.79 | 21.47 | 9.44 | 46.44 | 20.60 | 8.80 |
| +OCR&OD 0.90 | 10.43 | 20.97 | 10.17 | 46.19 | 20.63 | 9.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Qiu, Y.; Aoki, Y.; Kataoka, H. Outdoor Vision-and-Language Navigation Needs Object-Level Alignment. Sensors 2023, 23, 6028. https://doi.org/10.3390/s23136028
Sun Y, Qiu Y, Aoki Y, Kataoka H. Outdoor Vision-and-Language Navigation Needs Object-Level Alignment. Sensors. 2023; 23(13):6028. https://doi.org/10.3390/s23136028
Chicago/Turabian StyleSun, Yanjun, Yue Qiu, Yoshimitsu Aoki, and Hirokatsu Kataoka. 2023. "Outdoor Vision-and-Language Navigation Needs Object-Level Alignment" Sensors 23, no. 13: 6028. https://doi.org/10.3390/s23136028
APA StyleSun, Y., Qiu, Y., Aoki, Y., & Kataoka, H. (2023). Outdoor Vision-and-Language Navigation Needs Object-Level Alignment. Sensors, 23(13), 6028. https://doi.org/10.3390/s23136028