1. Introduction
Smart devices such as wearable and mobile sensors are increasingly utilized for health monitoring and personalized behavioral medicine. These technologies use machine-learning/deep-learning algorithms to detect lifestyle and physiological biomarkers and to provide real-time clinical interventions [
1,
2,
3,
4,
5,
6,
7]. However, the machine learning models are designed based on labeled training data collected in a particular domain, such as with a specific sensor modality, wearing site, or user. A significant challenge with this approach is that a machine learning model trained with a specific setting performs extremely poorly in new settings such as when the model is used with a sensor of a different modality, when the on-body location of the sensor changes, or when a new subject adopts the system [
8,
9]. This generalizability challenge has limited scalability of sensor-based health monitoring because collecting a sufficiently large number of labeled sensor data for every possible domain is a time-consuming, labor-intensive, expensive, and often infeasible process.
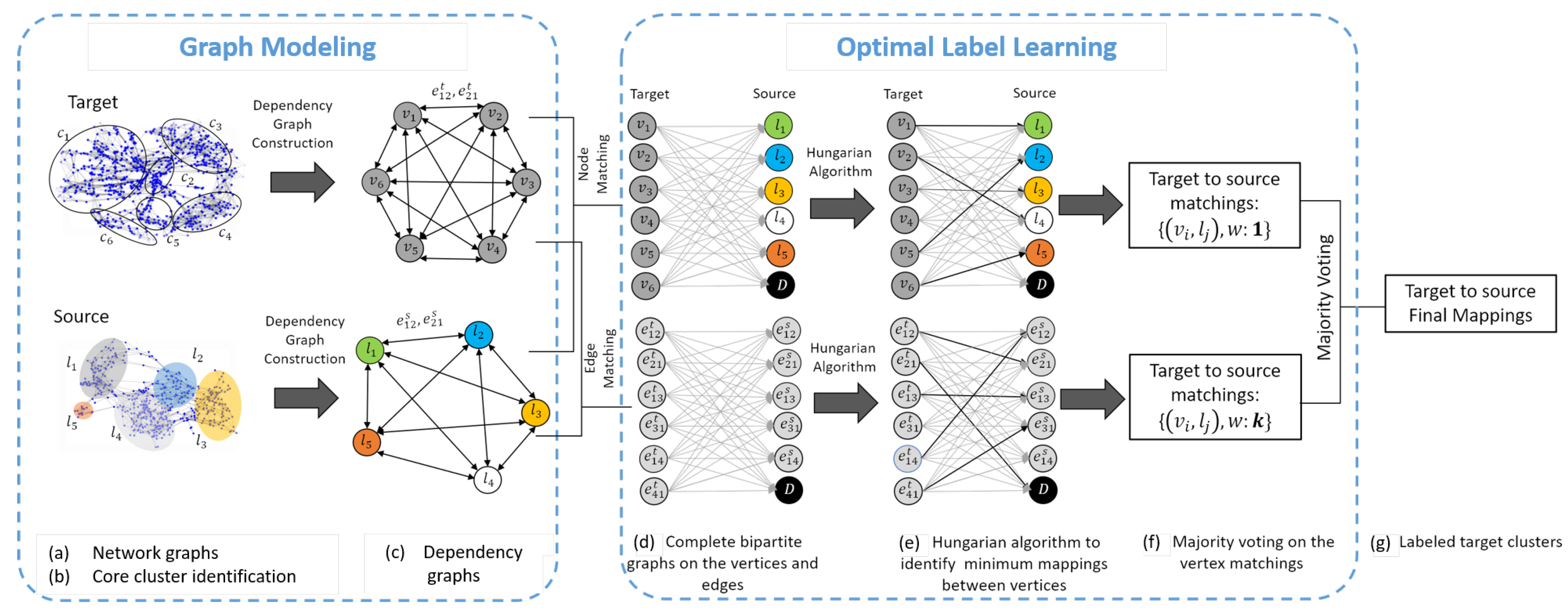
To address the aforementioned challenges, we introduce ActiLabel, a combinatorial framework that learns machine learning models in a new domain (i.e., target) without the need to manually collect any labels. Our pilot application in this paper is activity recognition, where ActiLabel is designed to detect human activities from wearable sensor data. A unique attribute of ActiLabel is that it examines structural relationships between activity events (i.e., classes/clusters) in the two domains and uses this information for target-to-source mapping. Such structural relationships allow us to compare the two domains at a much higher level of abstraction than the common feature space and therefore enable knowledge transfer across radically diverse domains. We hypothesize that even under sever cross-domain spatial and temporal uncertainties (i.e., significant distribution shift due to sensor modality change), physical activities exhibit similar structural dependencies across the two domains. We aim to uncover such structural dependencies from the sensor data gathered in the two domains and use this knowledge for mapping sensor data from the target domain to the data in the source domain.
To the best of our knowledge, our work is the first study that develops a combinatorial approach for structural transfer learning. Our notable contributions can be summarized as follows: (i) we introduce a model-agnostic combinatorial optimization formulation for transfer learning where no labeled data are available in the target domain, and we show that this problem is non-deterministic polynomial-time hardness (NP-hard); (ii) we devise methodologies for constructing a network representation of wearable sensor readings, referred to as network graph, as integral components of our framework for understanding structural dependencies among activity classes; (iii) we design algorithms that perform community detection on the network graph to identify core activity clusters; (iv) we introduce an approach to construct a dependency graph based on the core activity clusters identified on the network graph; (v) we show that combinatorial transfer learning can be transformed into a tractable assignment problem in the new knowledge transfer space given by the dependency graphs; (vi) we propose a novel multi-layer matching algorithm for mapping target-to-source dependency graphs; and (vii) we conduct an extensive assessment of the performance of ActiLabel for cross-modality, cross-subject, and cross-location activity learning using real sensor data collected with human subjects.
1.1. Transfer Learning
Transfer learning is the ability to extend what has been learned in one setting (i.e., source) to another, nonidentical but related, setting (i.e., target). Based on the common analogy in machine learning, we refer to the previous setting as the
source domain. The sensor data captured in this domain is referred to as the source dataset, which is fully labeled in our case. The new state of the system, which may exhibit radical changes from the source domain, is referred to as the
target domain where we intend to label the sensor data autonomously [
10].
Definition 1. (Transfer Learning). Given a source domain and learning task , a target domain and learning task , transfer learning aims to help improve the learning of the target predictive function in using the knowledge in and , where or .
Depending on how the source and target tasks and domains are defined, one can categorize transfer learning techniques into inductive transfer learning, transductive transfer learning, and unsupervised transfer learning. Inductive transfer learning refers to the case where the tasks in the target and source are different. Therefore, we need some labeled data to induce a prediction model in the target domain. In transductive transfer learning, the source and target obtain the same tasks but different domains. In this setting, there is no label in the target but a relatively large amount of labeled data is available in the source domain. Finally, in the unsupervised transfer learning, the target task is different from but related to the source, and no label is available in the target domain. Unsupervised transfer learning aims to solve unsupervised learning problems such as clustering and dimensionality reduction [
11,
12]. The transductive transfer learning, which is the focus of this paper, can be defined as follows.
Definition 2. (Transductive Transfer Learning) Given a source domain and a corresponding learning task , a target domain and a corresponding learning task , transductive transfer learning aims to improve the learning of the target predictive function in using the knowledge in and , where and . Additionally, some unlabeled target domain data must be available at training time.
Transductive transfer learning is categorized into two cases: (1) source and target adopt different feature domains ; (2) source and target adopt the same feature domains, but the probability distributions of their observations are different . This case is referred to as domain adaptation.
Transfer learning for cross-domain variations in the context of sensor-based monitoring can be categorized into cross-user, cross-modality, cross-platform, and cross-location activity recognition [
13]. Researchers have proposed several transfer learning techniques to address the challenge of domain shift in the context of sensor-based systems. Prior research utilized intra-affinity of classes to perform intra-class knowledge transfer where
% accuracy for cross-location and cross-subject transfer learning was achieved [
14]. Another study proposed a feature-level transfer learning approach for activity recognition where
% accuracy for cross-subject knowledge transfer was obtained [
13]. Prior research also developed OptiMapper as a transfer learning framework for the case where the target domain provides data about only a subset of the classes [
15]. However, as the degree of divergence between source and target domains grows, the transfer learning task becomes more challenging. These gaps result in a performance decline of pre-trained activity recognition algorithms. ActiLabel is proposed as a combinatorial optimization to address the problem of autonomous learning across highly diverse domains (e.g., across different sensor modalities, sensor locations, or users).
Prior research also proposed a deep convolution recurrent neural network to automate the process of feature extraction and to capture general patterns from activity data [
16]. In deep learning based methods, the goal is to have a pre-trained model obtained in a source domain and make it fit to our learning problem in the target domain by adding one more training step. Additionally, deep learning based methods need a labeled set for training and do not aim to label the unlabeled samples in the target domain. However, ActiLable is model-agnostic and does not rely on a specific type of machine learning model. We create a labeled training dataset in the target domain by mapping the target sensor data onto the labeled samples in the source domain prior. This model-agnostic approach allows designers to utilize the obtained training dataset and develop the machine learning of their choice for use in a target domain without being limited to the specific architecture that exists in the source domain.
We also note that deep learning models may perform very poorly in profoundly different domains such as cross-modality knowledge transfer or when the two domains exhibit a substantial amount of shift in the distribution of the sensor data. For example, previous research achieved only
% accuracy in classifying human gestures using deep learning with computationally dense algorithms when the system was used with sensors of different modalities than that of training [
8,
17]. More advanced models combine knowledge of transfer and deep learning [
18]. There have been studies attempting to transfer different layers of deep neural networks across different domains. In one study, a cross-domain deep transfer learning method was introduced that achieved
% accuracy with four activity classes for cross-location and cross-subject knowledge transfer [
9]. Unlike our transductive transfer learning approach in this paper, these approaches fall within the category of inductive transfer learning, where some labeled instances are required in the target domain.
1.2. Graph Modeling
Many areas of machine learning, such as clustering/community detection, dimensionality reduction, and semi-supervised learning, employ neighbor graphs to extract high-level global structures from local information within a dataset [
19,
20]. As an example, nearest neighbor graphs are commonly used to classify unknown events using feature representations. During the classification process, certain features are extracted from unknown events and classified based on the features extracted from their k-nearest neighbors.
The nearest neighbor or, in general, the k-nearest neighbor (k-NN) graph of a dataset is obtained by connecting each data point to its k closest points from the dataset. The closeness is defined based on a distance metric between the data points. The symmetric k-NN graphs are a special case where each point is connected to another only if both are in the k nearest vicinity of each other.
Definition 3 (Symmetric k-NN Grpah). A symmetric k-NN graph is a directed graph , where V is the set of vertices (i.e., data observations) and E is the set of edges. is connected to vertex if is one of the k-NNs of and vice versa according to a distance function .
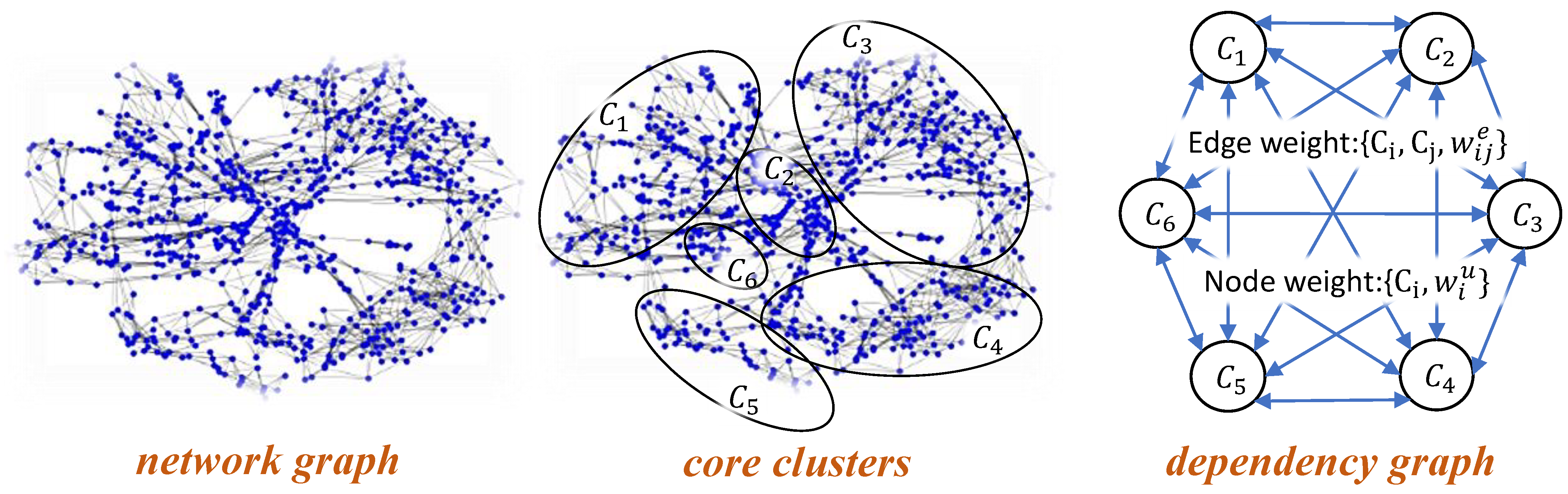
Community detection algorithms are widely used to identify clusters in large-scale network graphs. Clusters, which represent groups of densely connected vertices with sparse connections to each other, often provide useful structural information [
21]. Recent research compared different community detection algorithms with clustering techniques suggesting that detecting communities from a network representation of data could result in better clustering performance compared to traditional clustering algorithms [
22,
23]. We define some of the essential features related to community detection in network graphs in the following.
Definition 4 (Cut).
Given a graph G(,) and communities = {, ⋯, }, “Cut” between communities and is defined as the number of edges with one end in and the other end in , that is, Definition 5 (Cluster Density).
Given a graph G(,) and communities = {, ⋯, } within the graph G, “community density”, Δ
(), for community is defined as the number of edges with both ends residing in . Definition 6 (Community Size).
Given a graph G(,) and communities = {, ⋯, } within the graph G, “Community Size”, σ(), for community is defined as the number of vertices that reside in . 2. Problem Statement
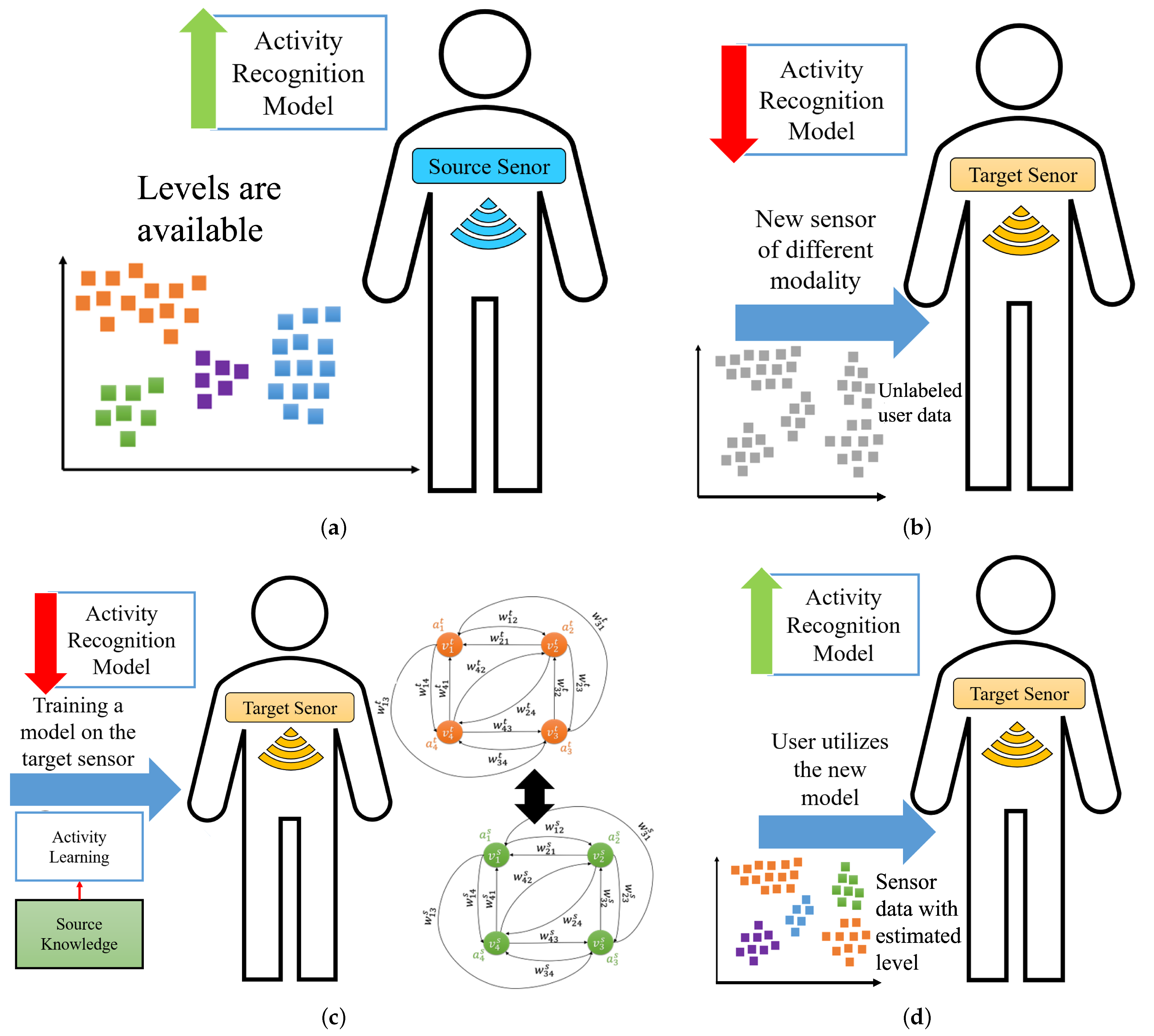
Figure 1 depicts an activity recognition framework when it is adopted on a new wearable sensor of different modality from the initial one. As shown in
Figure 1a, an activity recognition system consisting of a wearable sensor (e.g., accelerometer) uses a model learned based on annotated data. We refer to this setting as source domain. As shown in
Figure 1b, when the user replaces the existing sensor with a new sensor with different modality (e.g., stretch sensor), the performance of the existing model declines. We refer to this setting as the target domain. To overcome this challenge, we need to label the dataset autonomously in the new setting (e.g., new sensor modality), as shown in
Figure 1c. Finally, as shown in
Figure 1d, a more accurate classifier is trained using the labeled training data in the target domain.
2.1. Problem Definition
We represent each sensor observation in an arbitrary domain (e.g., target domain) as a k-dimensional feature vector , which are computed from a given time window. We define the activity recognition task as assigning activity label to an observation given a set of possible labels . The problem is to create a labeled dataset in the target domain by transferring the knowledge from the labeled observations in the source domain such that the activity misclassification in the target is minimized. We define this problem as combinatorial transfer learning.
Problem 1 (Combinatorial Transfer Learning (CTL)). Let = {, , ⋯, } be the set of sensor observations (i.e., sensor readings represented in feature space) captured in the target domain. Furthermore, let = {, , ⋯, } be the set of activity labels in the source domain that the target domain aims to detect. Combinatorial transfer learning involves assigning labels to and developing a classification model using the labeled data such that the classification error is minimized.
Because mislabeled sensor data adversely impacts the performance of the learned classifier, CTL can be viewed as the problem of assigning labels to target observations in such that the error of label assignment is minimized.
2.2. Problem Formulation
We formulate the CTL described in Problem 1 as follows:
Subject to:
where
is a decision variable indicating whether or not
is assigned label
, and
denotes error due to such a labeling. The constraint in (
5) guarantees that at most
target observations are assigned label
. Without such a constraint, a trivial solution is to label no observations in the target domain. The constraint in (
6) ensures that only one label is assigned to each observation
in the target domain.
2.3. Solution Overview
The difficulty in solving Problem 1 arises not only from the hardness of the problem but also from the fact that parameters
and
are not known
a priori. Therefore, the solution to the CTL problem in (
4)–(
7) needs to estimate
and
first. Since assigning a label to every observation in the target is unlikely to result in a high labeling accuracy, we propose to find groups of similar target observations that are reliable to receive the same label. Unsupervised clustering is one approach to divide observations into groups, exclude noisy observations from the labeling process, and therefore increase the specificity of the labeling. We can estimate the value of
by identifying clusters of observations that are safe to receive the same activity label, namely, core clusters. Let
be a
cluster in domain
D. After clustering the target data, the goal is to assign activity labels to the core clusters such that the label misassignment is minimized. Therefore, the CTL problem can be reformulated as below.
Subject to:
where
is a binary variable indicating whether or not
cluster in the target is assigned with label
from
cluster in the source domain, and
denotes the assignment error.
can be estimated as a structural dissimilarity between cluster
in the target and cluster
in the source domain. Cluster
is a cluster of observations with label
in the source domain. Note that computing the dissimilarity between the clusters will be further discussed in the next steps. The constraint in Equation (
9) ensures that only one label is assigned to each core cluster
from the target domain.
4. Time Complexity Analysis
Lemma 1. The optimal label learning phase in ActiLabel has a time complexity of , where n denotes the number of sensor observations and m represents the number of classes.
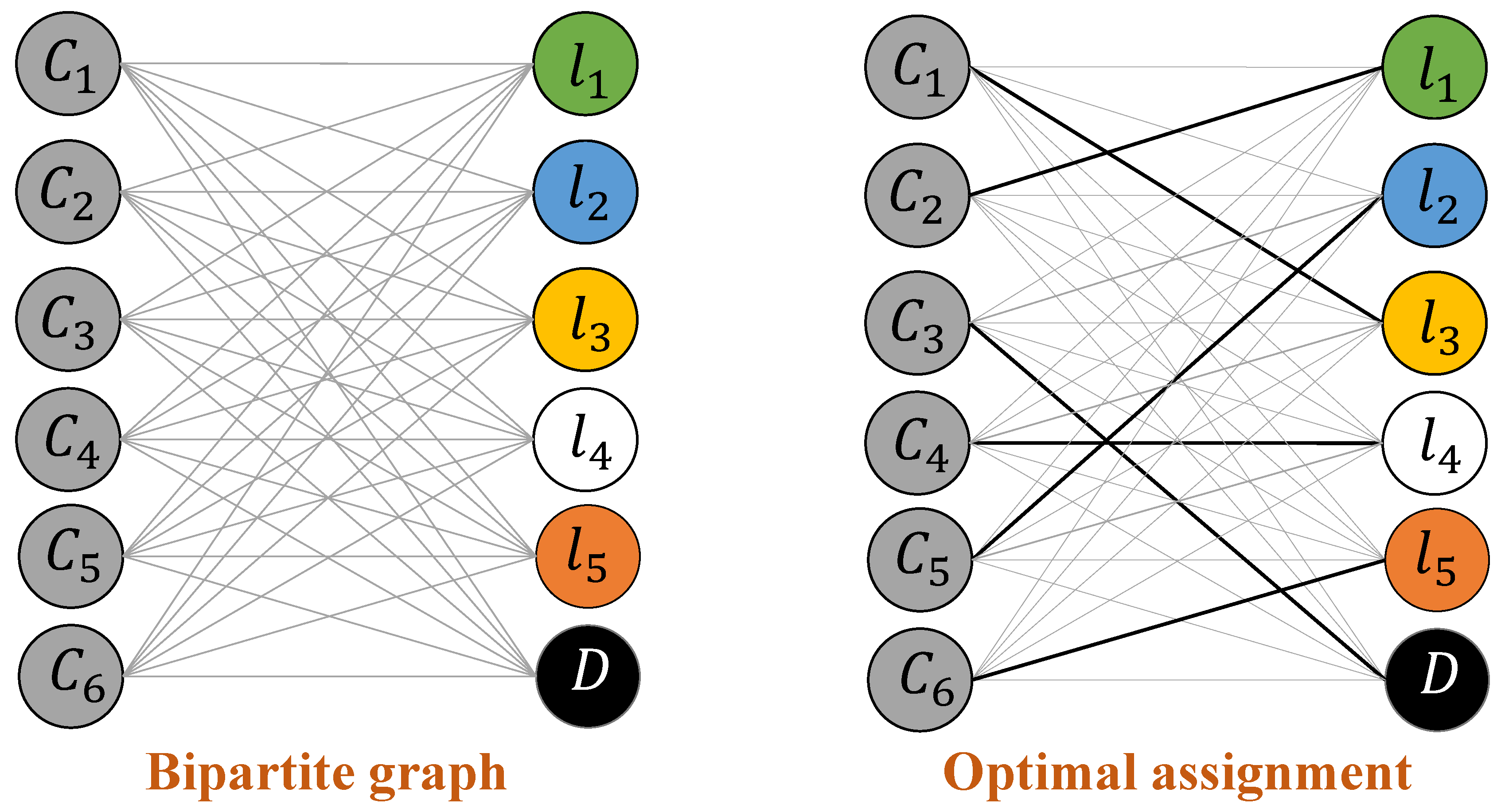
Proof. To learn the optimal labels, ActiLabel finds an optimal matching between source and target dependency graphs given the node and edge weight values. We solve the dependency graph matching problem by running the Hungarian algorithm three times. Given that the number of the core clusters is proportional to the number of labels, m, the time complexity of running Hungarian algorithm three times is . Distributing the labels to the cluster members can be done in . Therefore, the optimal label learning phase has a time complexity of . □
The last step is to assign the labels to the target observations within each cluster. A classification model is trained on the labeled target dataset for physical activity recognition.
Theorem 1. The time complexity of ActiLabel is quadratic in the number of sensor observations, n.
Proof. Assuming that the number of classes, m, is much smaller than the number of sensor observations, n, (i.e., ), the proof follows Lemma 2 and Lemma 1. □
Theorem 2. CTL is NP-hard.
Proof. Proof by reduction is done from the well-known generalized assignment problem [
27].
Theorem 2 claims that the CTL problem discussed in Problem 1 and formulated in (
4)–(
7) is NP-hard. In this section, we prove that Problem 1 is NP-hard by reduction from the generalized assignment problem (GAP), which is known to be NP-hard [
27]. The generalized assignment problem aims to assign a set of tasks to a set of agents while minimizing the total assignment cost. It needs to guarantee that each task is assigned to one and only one agent. In GAP, each agent has a limited capacity. Additionally, each task requires a given number of resources of each agent. Each task needs to be assigned to only one agent.
An instance of GAP is given by (
I,
J,
A,
B,
C) where
I = {1, 2, ⋯,
n} represents the set of
n tasks;
J = {1, 2, ⋯,
m} denotes the set of
m agents;
B={
,
, ⋯,
} maintains resource capacity
for each agent
j in
J;
A = {
} represents resource
needed if task
i is assigned to agent
j; and finally
C={
} represents the cost of assigning task
i to agent
j. The generalized assignment problem can be formulated as follows:
Subject to:
where
is a decision variable indicating whether or not task
i is assigned to agent
j.
Consider an instance of the generalized assignment problem, (
I,
J,
A,
B,
C). This problem can be reduced to the combinatorial transfer. In fact, the generalized assignment problem is equivalent to the CTL with
□
Lemma 2. The graph modeling in ActiLabel has a time complexity of , where ‘n’ denotes the number of sensor observations.
Proof. Lemma 2 claims that the complexity of the graph modeling phase in ActiLabel is , where ‘n’ represents the number of sensor observations. Here, we provide the proof for this claim.
The graph modeling phase includes three steps: network graph construction, core cluster identification, and dependency graph construction, which have a complexity of , , and , respectively, as discussed below.
Our introduced network graph in ActiLabel is a knn graph constructed using the input sensor observations. Constructing a knn graph requires computing pairwise distances between sensor observations. Therefore, the knn construction process has a time complexity of .
The core cluster identification algorithm consists of partitioning the network graph and merging the partitions into a final set of clusters. We use the Clauset–Newman–Moore greedy modularity maximization algorithm for network graph partitioning. Because the network graph is sparse, the partitioning algorithm runs in
[
28]. In the following, we show that the cluster merging process has a time complexity of
. Therefore, assuming
, the core cluster identification algorithm has a time complexity of
The cluster merging process requires (i) a computing pair-wise similarity between the clusters in (
12); (ii) finding a pair of clusters that are most similar; and (iii) merging the two clusters, which involves updating the membership of the sensor observations that reside in the merged clusters. We note that, in the worst case, steps (ii) and (iii) will repeat until the entire network graph is merged into a single cluster. To compute pair-wise cluster similarity, we use a fast algorithm that goes over non-zero elements of the adjacency matrix (e.g., edges in the network graph) only once. For each non-zero element, if the adjacent vertices in the network graph belong to the same cluster, we update the cluster weight; otherwise, we update the edge weight between the two clusters based on the similarity values. Therefore, computing the similarity measures runs in
. Note that because the network graph is sparse,
. Because the number of clusters is proportional to the number of labels,
m, the number of cluster-pairs is
. Therefore, finding a cluster-pair with maximum similarity takes
to complete. Finally, updating the cluster membership for data points that reside in the merged clusters takes
. Note that because steps (ii) and (iii) can repeat for at most
m times, the complexity of combined steps (ii) and (iii) is
. Combining complexity of the three steps (i), (ii), and (iii) in cluster merging process will give us an overall complexity of
=
.
The dependency graph is a weighted complete graph that is built on the core clusters. The process to compute edge weights and vertex weights in such a graph is similar to computing the pair-wise similarity score while merging the initial clusters. All the edge weights and vertex weights can be therefore calculated during the cluster merging process described earlier. Given that the number of the final clusters is proportional to the number of the labels, m, the dependency graph construction can run .
Combining time complexities for network graph construction, core cluster identification, and dependency graph construction will give us
=
. Assuming that in most real applications the number of sensor observations is orders of magnitude larger than the number of class labels, we can conclude that the complexity of the graph modeling phase is ActiLabel is
. Hence,
□
6. Results
As mentioned previously, the main focus of ActiLabel is to create a labeled dataset in a target domain. This dataset can then be used to train an activity recognition model. Therefore, the methodologies presented in this paper are independent of the choice of the classifier that can be used for activity recognition. For validation purposes, however, we performed an extensive experiment to identify the most accurate classification model that can be used for activity recognition.
Table 3 compares the F1-score for k-NN with
, support vector machine (SVM) with RBF kernel, logistic regression (LR), random forest (RF) with bagging of 100 decision trees, artificial neural network (ANN), Naive Bayes (NB), and quadratic discriminant analysis (QDA). k-NN (K = 5) achieves the highest performance, such as
average F1-score over different sensor locations in PAMAP2 dataset,
over different sensor modalities, and
over different sensor modalities for DAS dataset. ANN achieved the best F1-score for the rest of the cases.
In what follows, we discuss the performance of ActiLabel for core cluster identification, labeling accuracy, and activity recognition accuracy.
6.1. Performance of Core Cluster Identification
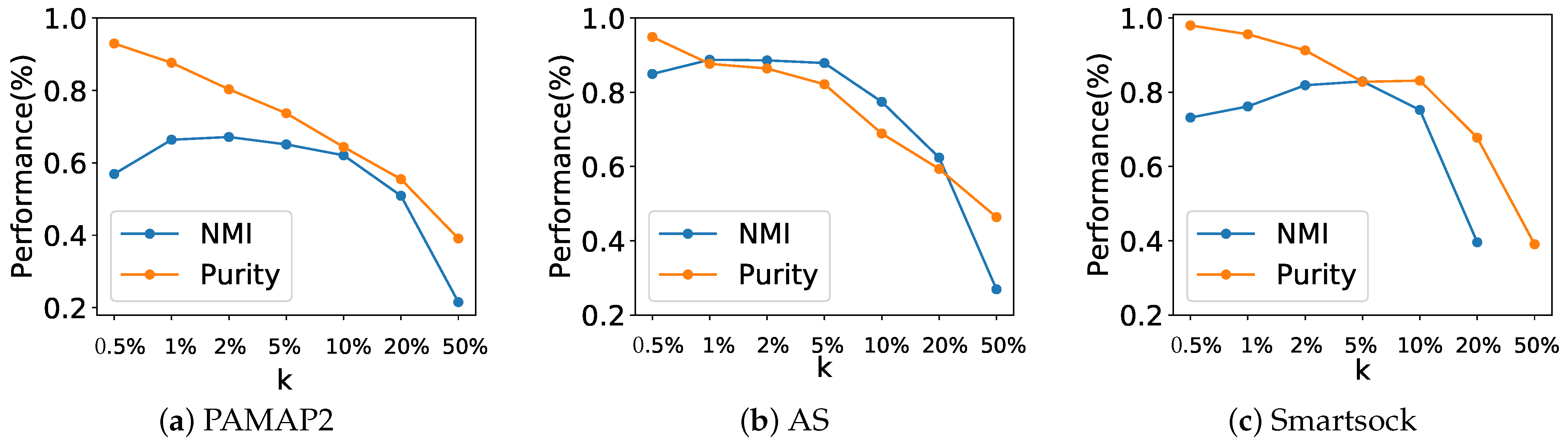
We analyzed the effect of parameter
k in the
k-NN network graph on the performance of the core cluster identification as measured by normalized mutual information (NMI) and clustering purity. As shown in
Figure 7, the value of parameter
k is set according to the size of the network graph. Specifically, measure NMI and purity for
k range from
% to 50% of the network graph size. Note that purity decreases as
k grows because a higher purity (e.g., 0.85 to 0.98) can be achieved when detecting more clusters. A smaller
k results in sparser network graph, which in turn leads to the acquisition of more clusters. As shown in
Figure 7, NMI achieved its highest value (i.e.,
for PAMAP2,
for DAS, and
for Smartsock) when
k was set to 2% or 5% of the graph network size. This translates into a
k = 8 for PAMAP2 and Smartsock and
for DAS datasets.
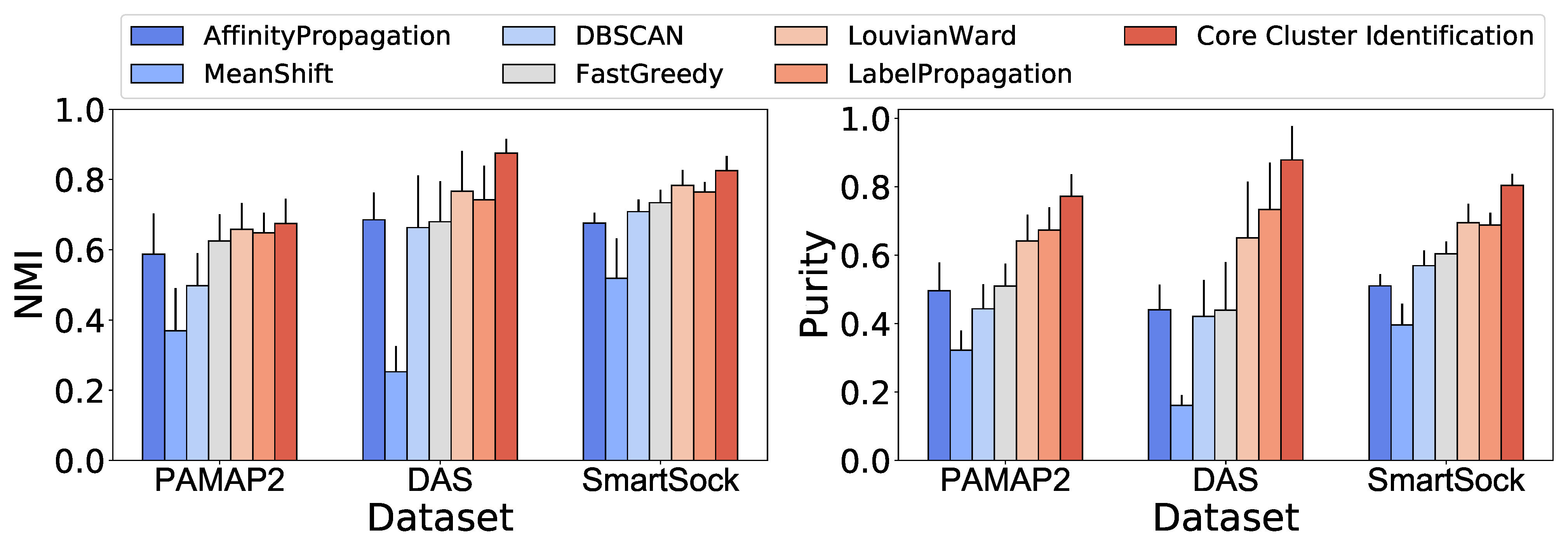
Figure 8 compares the average NMI score and purity of clustering between the proposed core cluster identification (CCI) method and well-known clustering and community detection algorithms. We chose the algorithms that do not require prior knowledge on the cluster counts because the activity labels are unknown in the target domain. Note that the community detection algorithms were applied to a symmetric k-NN graph (k = 10) built on the feature representation of observation after dimensionality reduction using the UMAP [
34] algorithm.
Affinity propagation is a graph-based clustering algorithm that extracts the clusters by relaying messages between pairs of samples until convergence [
38].
Mean shift is a centroid-based algorithm that extracts clusters on a smooth density of data [
39]
DBSCAN clustering algorithm detects the cluster based on a density measure [
40].
Fast greedy finds the communities in the graph using Clauset–Newman–Moore greedy modularity maximization [
28].
Lovain–Ward detects the communities in the graph by maximizing the modularity using the Louvain heuristics [
41].
Label propagation finds the communities in the graph using a semi-synchronous label propagation method [
42].
As shown in
Figure 8, CCI outperforms state-of-the-art clustering and community detection algorithms. The NMI for the competing methods ranged from 0.37–0.65 for PAMAP2, 0.25–0.77 for DAS, and 0.52–0.76 for Smartsock. The proposed algorithm CCI increased NMI to 0.67, 0.87, and 0.85 for PAMAP2, DAS, and Smartsock datasets, respectively.
Affinity propagation, DBSCAN, Lovain–Ward, fast greedy, and label propagation algorithms achieved 0.50–0.67, 0.44–0.73, and 0.51–0.69 purity for PAMAP2, DAS, and Smartsock datasets, respectively. Mean shift achieved the lowest purity compared to other comparison algorithms (0.32 for PAMAP2, 0.16 for DAS, and 0.40 for Smartsock). Using our core cluster identification The purity measure reaches 0.77 for PAMAP2, 0.88 for DAS, and 0.80 for Smartsock dataset. Note that the clustering was generally more accurate for Smartsock and DAS datasets because PAMAP2 contained data from sensor modalities (e.g., temperature) that might not be a good representative of the activities of interest.
6.2. Labeling Accuracy in ActiLabel
Because ActiLabel generates a labeled training dataset in the target domain, it is reasonable to assess the accuracy of the labeling task.
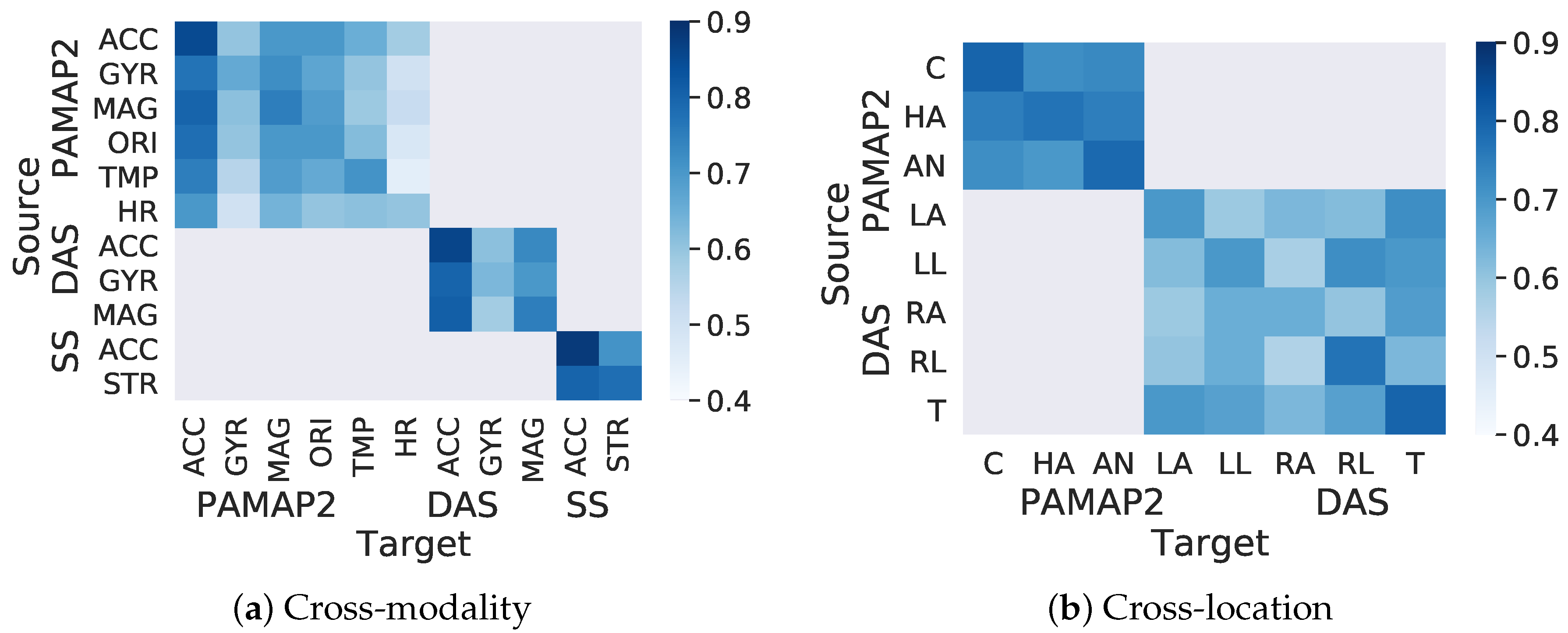
Figure 9 shows the labeling accuracy for various transfer learning scenarios and datasets. For brevity, the results from cross-subject labeling are not included in this figure.
6.2.1. Cross-Modality Transfer
As the heatmap in
Figure 9a shows, ActiLabel achieved
–
labeling accuracy when the accelerometer was the target modality. With the accelerometer being the target modality, the highest labeling accuracy (>80%) was obtained when the source modality was the magnetometer, the stretch sensor, or another accelerometer. We also observed that the labeling accuracy ranged from 60% to 75% when the target modality was magnetometer or orientation sensor. We also noted that transferring labels between orientation and heart rate sensors achieved the lowest accuracy (i.e., 45–
%), mainly because these sensor modalities are not as good representative of the physical activities as the accelerometer. The proposed mapping algorithm obtained
labeling accuracy for the remaining transfer scenarios except for “magnetometer to orientation” mapping (
%) and for “temperature to temperature” mapping (
%).
6.2.2. Cross-Location Transfer
The heatmap in
Figure 9b shows the labeling accuracy between sensor locations in PAMAP2 and DAS datasets. Note that the Smartsock dataset contained only one sensor location, and therefore a cross-location transfer did not apply to this dataset. As expected, mapping labels between the same or similar body locations such as “chest to chest”, “hand to hand”, “ankle to ankle”, “torso to torso”, “left arm to left arm”, “left leg to left leg”, and “left arm to right leg” achieved a relatively high labeling accuracy (i.e., >
). Furthermore, ActiLabel achieved
–
labeling accuracy for transfer tasks between chest, ankle, and hand in PAMAP2. One reason for a relatively high labeling accuracy in such transfer tasks involving dissimilar sensor locations is that PAMAP2 contains a rich collection of sensors (accelerometer, gyroscope, magnetometer, orientation, temperature, and heart rate sensors) that provide sufficient information about inter-event structural similarities captured by our label learning algorithms in ActiLabel.
6.3. Performance of Activity Recognition
Table 4 shows activity recognition performance (e.g.,F1-score) for ActiLabel as well as the algorithms under comparison, including baseline (BL), deep convolution LSTM (CL), DirectMap (DM), and upper-bound (UB), as discussed previously.
6.3.1. Cross-Modality Transfer
For this scenario, we examined transfer learning across these sensor modalities: accelerometer, gyroscope, magnetometer, orientation, temperature, heart rate, and stretch sensor. The cross-modality results in
Table 4 reflect average performance over all possible cross-modality scenarios. The baseline and ConvLSTM performed poorly with F1-scores of
and
in PAMAP2,
, and
in DAS, and
and
in Smartsock. This demonstrates a highly diverse distribution of data across sensors of different modalities. The DirectMap approach achieved
,
, and
F1-score for PAMAP2, DAS, and Smartsock datasets, respectively. ActiLabel outperformed DirectMap by
,
, and
for PAMAP2, DAS, and Smartsock, respectively.
6.3.2. Cross-Location Transfer
We examined transfer learning among chest, ankle, hand, arms, legs, and torso. The cross-location results in
Table 4 represent the average values over all possible transfer scenarios. The baseline and ConvLSTM methods achieved F1-scores of
and
for the PAMPA2 dataset, respectively. Similarly, the baseline and ConvLSTM algorithms achieved
and
F1-scores, respectively, for DAS dataset. The relatively low F1-scores of the baseline and ConvLSTM algorithms can be explained by the high level of diversity between the source and target domains during cross-location. The DirectMap and ActiLabel both outperformed the baseline and ConvLSTM models, specifically, DirectMap and ActiLabel
and
F1-scores for PAMAP2, respectively, and
and
F1-scores for DAS.
6.3.3. Cross-Subject Transfer
For this particular experiment, we included only four subjects from each dataset because there were only four subjects who performed all the activities in the protocol of the datasets. The baseline and ConvLSTM achieved and F1-score for PAMAP2, and F1-score for DAS, and and F1-score for Smartsock datasets. The baseline feature-based classifier achieved slightly higher performance than deep ConvLSTM. This can be explained by the fact that complex deep learning models may not be superior to feature-based algorithms when applied to data with low-dimensional feature space. Such deep learning models have been shown superiority to feature-based estimation models when adopted to datasets with high-dimensional channels (e.g., >100). However, the datasets used for our analysis had few channels of data from a few locations and sensors.
The DirectMap approach and ActiLabel obtained F1-scores of and in PAMAP2, and in DAS, and and in Smartsock, respectively. All the algorithms achieved higher F1-score values than the cross-location and cross-modality scenarios. This observation suggests that cross-subject transfer learning is an easier task to accomplish compared to cross-modality and cross-location because of the lower amount of variation in the distribution of the sensor data during cross-subject learning. These results suggest that data variations among different subjects can be normalized using techniques such as feature scaling, and feature selection before classification.
7. Discussions and Future Work
In this section, first, we discuss our work from several perspectives and discuss promising directions that will overcome some of the limitations of our work.
First, from the transfer learning perspective, the performance of different transfer learning algorithms depends on four factors. First, how well the target can distinguish between different physical activities when some correct labels are available. Second, how pure observations in target and source domains could be clustered into activity labels. Third, the accuracy of mapping between the source and target core clusters. Lastly, the capability of the source dataset in distinguishing between different activities when some labels are available.
Table 4 shows that ActiLabel obtained an average F1-score of
in activity recognition of the PAMAP2 dataset, compared to
and
F1-scores for the DAS and Smartsock datasets, respectively. The collection of more diverse sensor modalities such as accelerometer, gyroscope, magnetometer, orientation, temperature, and heart rate, which are less representative of human physical activity events, affects every step in Actilabel, including core cluster identification, min-cost mapping, and activity recognition. As shown in
Table 3, the strongest baseline classifier (e.g., 5-NN) achieved
average F1-score in detecting the activities from different sensor modalities from the PAMAP2 dataset; 5-NN reached a
activity recognition F1-score; and random forest obtained a
average F1-score for sensor modalities in DAS and Smartsock datasets, respectively.
Second, from the structural perspective, we note that the community detection-based algorithms outperform clustering algorithms in our setting. From
Figure 8, we can observe that fast greedy, Lovain–Ward, and label propagation community detection algorithms obtained NMI of 0.16–0.51 and purity of 0.25–59 for PAMAP2, DAS, and Smartsock datasets, respectively, while the clustering methods, including affinity propagation, mean shift, and DBSCAN, achieved NMI of 0.42–0.70 and purity of 0.62–0.78 for these datasets, respectively. CCI, which is proposed as an extension to the community detection algorithms, achieved up to 20.4% higher NMI and 17.5% purity than these techniques. These results suggest that community detection algorithms are more reliable in the unsupervised clustering of datasets, in particular, human physical activity, when the models do not have prior knowledge on the number of the clusters. Although the clustering algorithms, such as affinity propagation and mean shift, eliminate the need to specify the number of clusters, they have other parameters, such as “preference” and “damping” for affinity propagation and “bandwidth for mean shift, that are challenging to optimize [
43,
44]. We note that tuning the structure of the input graph (e.g., modifying k for K-NN graphs) and merging strongly connected communities again, as proposed in CCI, improves the clustering quality comparing to the other community detection algorithms such as label propagation.
Finally, from the machine learning viewpoint of the activity recognition, we discuss the problem of poor performance of the baseline models (e.g., 31.6% F1-score, as shown in
Table 4). Specifically, in the cross-modality scenario, the gap between the baseline and other transfer learning methods is the highest (e.g., gap of 32.6% to 59.9% in F1-score). One explanation is that the features adopted different distributions across different domains. We note that ConvLSTM did not meet the expectations in solving the problem of cross-domain transfer learning; the main reason that ConvLSTM could not improve the performance (e.g., 29.3% F1-score) of the baseline was an inadequate amount of data as the deep neural networks acquire a considerable amount to data to extract effective features through the deep convolution layers [
45]. We believe that adding more data to the training dataset will improve the performance of the baseline method. Overall, assuming a lower F1-score for the baseline represents higher diversity between domains and, therefore, a more challenging transfer scenario, the cross-modality with 40.4–72.7% F1-score for DirectMap and ActiLabel is the most challenging transfer learning scenario. Overall, assuming a lower F1-score for the baseline represents higher diversity between domains and, therefore, a more challenging transfer scenario, the cross-modality with a 40.4–72.7% F1-score for DirectMap and ActiLabel is the most challenging transfer learning scenario.
There are few limitations to the evaluation process of the ActiLabel. First, we assume that the target activity labels are a subset of ones in the source domains. However, there are cases in real-word settings in which some of the activities in the target are not known to the source. The straightforward solution to this scenario is to add dummy nodes in the construction of bipartite graphs for the domain with fewer activities (e.g., source domain). However, such a solution is naive and results in mapping the dummy nodes from the source to the nodes associated with unknown activity labels from the target domain in the best case. To solve this issue, our ongoing work involves investigating practical approaches that allow for more complex mapping scenarios such as many-to-many mappings that capture all possible complex mapping situations that might occur in real-world and uncontrolled settings. Second, graph-based algorithms such as ActiLabel might encounter scalability challenges when deployed in large real-world datasets. We are planning to investigate the efficacy of replacing the k-NN graph with less computationally expensive graph structures such as -graphs and minimum spanning trees to enhance the scalability of the ActiLabel. Finally, the practical challenges of deploying our system in a real-world scenario will provide valuable information on the applicability of ActiLabel and help us improve our system. Therefore, one interesting future direction is the optimization of various computational components of ActiLabel for time, power, and memory efficiency given the dynamics of real-world scenarios.
Based on our analysis,
Table 5 illustrates the merits and potential demerits of ActiLabels against analogous methods.
The aim of ActiLabel is to leverage the knowledge from a source domain where labeled data is abundant and use it to improve the performance of activity recognition task in a target domain where labeled data is limited. It is designed to handle transfer learning scenarios with different modalities, subjects, and sensor locations. The ActiLabel framework initiates community detection algorithms to identify core clusters of similar activities in the target domain and then maps them to corresponding activities in the source domain. By leveraging the relationships between activities and the knowledge from the source domain, ActiLabel aims to improve the activity recognition performance in the target domain. Additionally, ActiLabel’s performance is evaluated in three transfer learning setups: cross-modality transfer, cross-subject transfer, and cross-location transfer. These scenarios reflect the scope of application of ActiLabel in real-world situations where activity recognition needs to be performed across different sensor modalities, different individuals, and different sensor locations. While the focus of this study is activity recognition using wearable sensor data, the ActiLabel method’s underlying principles of transfer learning and community detection could potentially be applied to other domains and tasks where transfer learning deems fit. However, further research and experimentation would be needed to explore its effectiveness in those specific domains.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}