
RIS-Aided Proactive Mobile Network Downlink Interference Suppression: A Deep Reinforcement Learning Approach



Abstract
:1. Introduction
- We propose introducing RIS technology to solve the extensive and severe inter-user interference problem in PMN downlink communication. This permits the AN to rationally and uniformly regulate multiple RISs to suppress interference among users in the service region and simultaneously boost the target signal of multiple users.
- We designed a DRL-based AN dynamic management scheme for multiple RISs. The scheme overcomes the technical challenge that exact channel state information cannot be obtained in real time in PMNs, which is required for traditional RIS management schemes.
- A numerical evaluation verifies the efficacy of the proposed RIS-assisted PMN downlink scheme in interference suppression. The results indicate that the communication capacity of the PMN can be substantially increased by deploying multiple RISs and controlling the RISs’ phase shifts and reflection coefficients.
2. Related Works
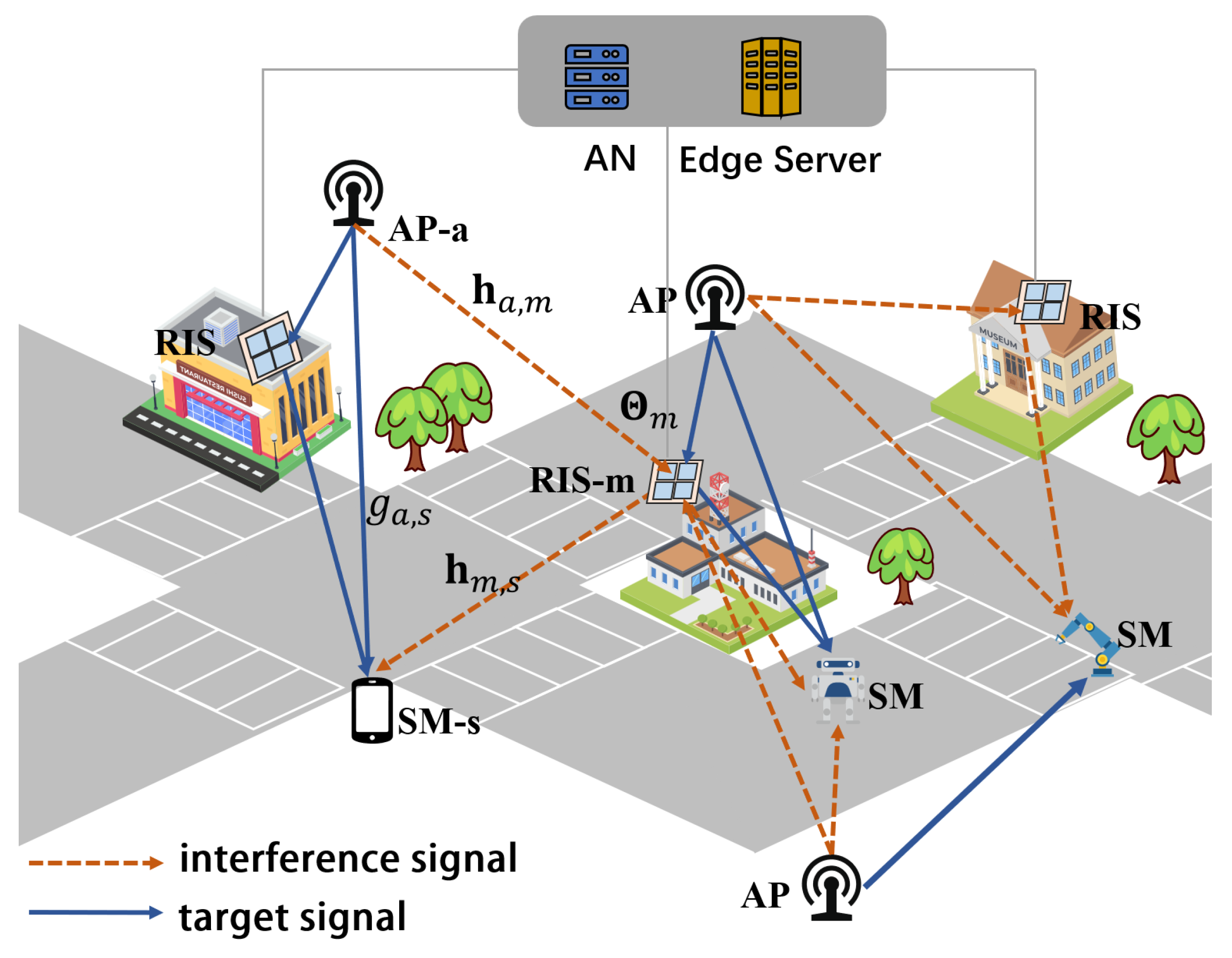
3. System Model and Problem Formulation
3.1. Channel Model
3.2. RIS-Aided PMN Downlink Capacity
3.3. Optimization Problem Formulation
4. Deep Reinforcement Learning Approach
4.1. Reinforcement Learning Problem Formulation
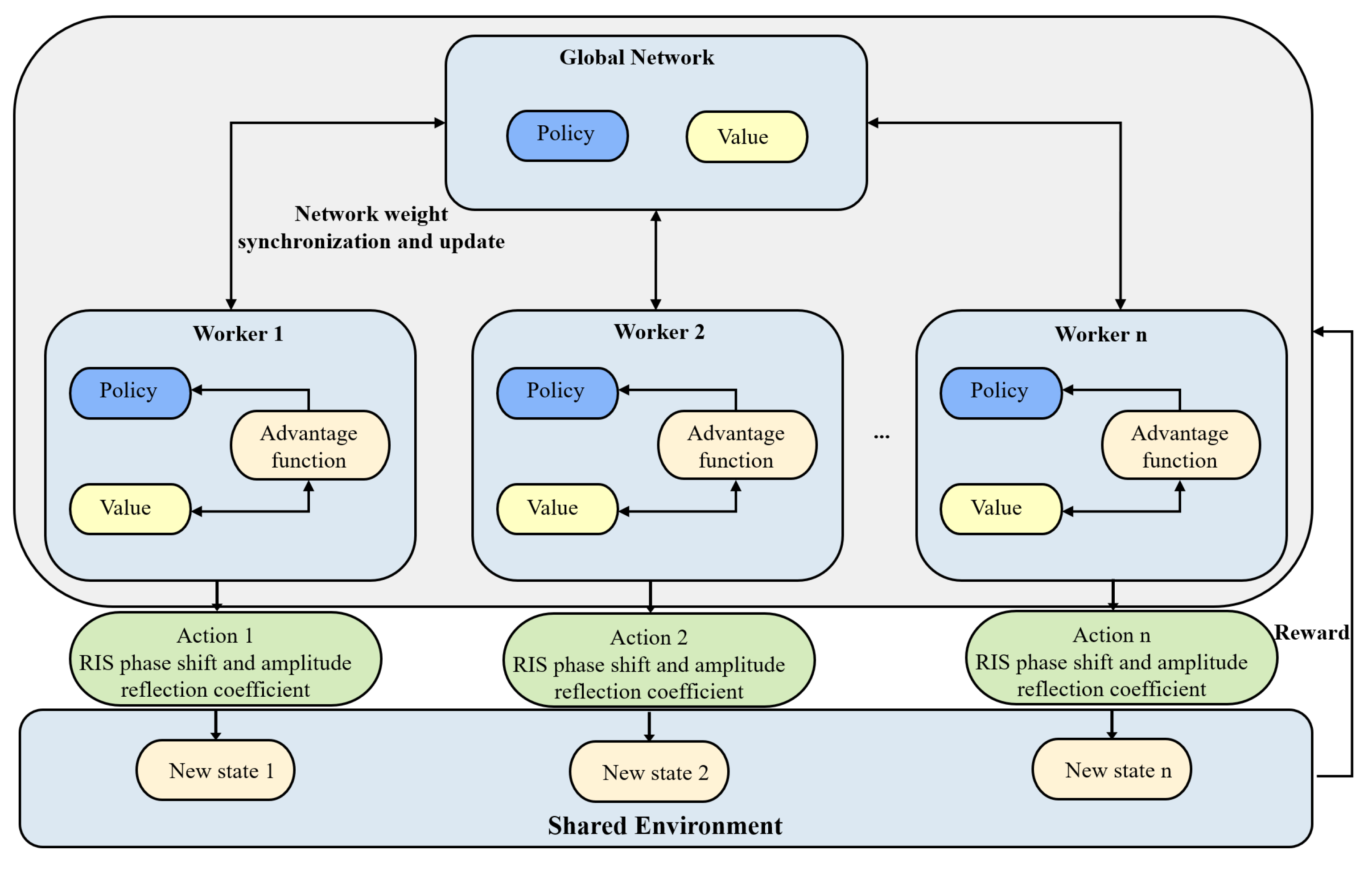
4.2. Actor–Critic Decision Framework
4.3. A3C-Based Approach
| Algorithm 1: A3C-Based Solution |
 |
5. Analysis of Simulation Results
5.1. Simulation Setting

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| The Rician factors , , and | (4, 5, 6) |
| The temporal correlation coefficient | 0.7 |
| Number of APs A | 20 |
| Number of SMs S | 18 |
| Number of elements in each RIS N | 32 |
| Discount factor | 0.8 |
| Coefficient | 0.1, 0.001, 0.0001 |
| Noise power density | −164 dBm/Hz |
| Max transmit power of each AP | 27 dBm |
5.2. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| URLLC | Ultra-Reliable Low-Latency Communication |
| PMN | Proactive Mobile Network |
| DRL | Deep Reinforcement Learning |
| A3C | Asynchronous Advantage Actor–Critic |
| RIS | Reconfigurable Intelligent Surfaces |
| RAN | Radio Access Network |
| AP | Access Point |
| AN | Anchor Node |
| SM | Smart Machine |
| PMCA | Proactive Multi-Cell Association |
| CSI | Channel State Information |
| MDP | Markov Decision Process |
| DNN | Deep Neural Network |
References
- Park, J.; Samarakoon, S.; Shiri, H.; Abdel-Aziz, M.K.; Nishio, T.; Elgabli, A.; Bennis, M. Extreme URLLC: Vision, challenges, and key enablers. arXiv 2020, arXiv:2001.09683. [Google Scholar]
- Eum, S.; Arakawa, S.; Murata, M. A probabilistic Grant Free scheduling model to allocate resources for eXtreme URLLC applications. In Proceedings of the 2022 IEEE Latin-American Conference on Communications (LATINCOM), Rio de Janeiro, Brazil, 30 November–2 December 2022; pp. 1–6. [Google Scholar]
- Shi, H.; Zheng, W.; Liu, Z.; Ma, R.; Guan, H. Automatic Pipeline Parallelism: A Parallel Inference Framework for Deep Learning Applications in 6G Mobile Communication Systems. IEEE J. Sel. Areas Commun. 2023, 41, 2041–2056. [Google Scholar] [CrossRef]
- 3GPP. Study on enhancement of Ultra-Reliable Low-Latency Communication (URLLC) Support in the 5G Core Network (5GC). Technical Report (TR) 23.725, 3rd Generation Partnership Project (3GPP), Version 16.2.0. 2019. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3453 (accessed on 12 May 2023).
- Chen, K.C.; Zhang, T.; Gitlin, R.D.; Fettweis, G. Ultra-low latency mobile networking. IEEE Netw. 2018, 33, 181–187. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, K.C.; Gong, Z.; Cui, Q.; Tao, X.; Zhang, P. Reliability-Guaranteed Uplink Resource Management in Proactive Mobile Network for Minimal Latency Communications. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Cui, Q.; Zhang, J.; Zhang, X.; Chen, K.C.; Tao, X.; Zhang, P. Online anticipatory proactive network association in mobile edge computing for IoT. IEEE Trans. Wirel. Commun. 2020, 19, 4519–4534. [Google Scholar] [CrossRef]
- Liu, C.H.; Liang, D.C.; Chen, K.C.; Gau, R.H. Ultra-Reliable and Low-Latency Communications Using Proactive Multi-Cell Association. IEEE Trans. Commun. 2021, 69, 3879–3897. [Google Scholar] [CrossRef]
- Alqahtani, F.; Al-Maitah, M.; Elshakankiry, O. A proactive caching and offloading technique using machine learning for mobile edge computing users. Comput. Commun. 2022, 181, 224–235. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Cui, Q.; Chen, K.C.; Ni, W. Machine Learning Enables Radio Resource Allocation in the Downlink of Ultra-Low Latency Vehicular Networks. IEEE Access 2022, 10, 44710–44723. [Google Scholar] [CrossRef]
- Louie, R.H.; McKay, M.R.; Collings, I.B. Open-loop spatial multiplexing and diversity communications in ad hoc networks. IEEE Trans. Inf. Theory 2010, 57, 317–344. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Zheng, F.C.; Luo, J.; Feng, D. Open-loop communications for up-link URLLC under clustered user distribution. IEEE Trans. Veh. Technol. 2021, 70, 11509–11522. [Google Scholar] [CrossRef]
- Hunter, A.M.; Andrews, J.G.; Weber, S. Transmission capacity of ad hoc networks with spatial diversity. IEEE Trans. Wirel. Commun. 2008, 7, 5058–5071. [Google Scholar] [CrossRef] [Green Version]
- Vaze, R.; Heath, R.W. Transmission capacity of ad hoc networks with multiple antennas using transmit stream adaptation and interference cancellation. IEEE Trans. Inf. Theory 2012, 58, 780–792. [Google Scholar] [CrossRef]
- Cui, Q.; Gong, Z.; Ni, W.; Hou, Y.; Chen, X.; Tao, X.; Zhang, P. Stochastic online learning for mobile edge computing: Learning from changes. IEEE Commun. Mag. 2019, 57, 63–69. [Google Scholar] [CrossRef]
- Wang, Y.; Cui, Q.; Chen, K.C. Machine Learning Enables Predictive Resource Recommendation for Minimal Latency Mobile Networking. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; pp. 1363–1369. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, Y. Machine learning empowered trajectory and passive beamforming design in UAV-RIS wireless networks. IEEE J. Sel. Areas Commun. 2020, 39, 2042–2055. [Google Scholar] [CrossRef]
- Lin, C.Y.; Chen, K.C.; Wickramasuriya, D.; Lien, S.Y.; Gitlin, R.D. Anticipatory Mobility Management by Big Data Analytics for Ultra-Low Latency Mobile Networking. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Musa, S.S.; Zennaro, M.; Libsie, M.; Pietrosemoli, E. Mobility-aware proactive edge caching optimization scheme in information-centric iov networks. Sensors 2022, 22, 1387. [Google Scholar] [CrossRef]
- Zhang, M.; Yi, H.; Chen, Y.; Tao, X. Proactive eavesdropping via jamming for power-limited UAV communications. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–5. [Google Scholar]
- Ying, X.; Demirhan, U.; Alkhateeb, A. Relay aided intelligent reconfigurable surfaces: Achieving the potential without so many antennas. arXiv 2020, arXiv:2006.06644. [Google Scholar]
- Abdullah, Z.; Chen, G.; Lambotharan, S.; Chambers, J.A. A hybrid relay and intelligent reflecting surface network and its ergodic performance analysis. IEEE Wirel. Commun. Lett. 2020, 9, 1653–1657. [Google Scholar] [CrossRef]
- Abdullah, Z.; Chen, G.; Lambotharan, S.; Chambers, J.A. Optimization of intelligent reflecting surface assisted full-duplex relay networks. IEEE Wirel. Commun. Lett. 2020, 10, 363–367. [Google Scholar] [CrossRef]
- Yang, L.; Yang, Y.; da Costa, D.B.; Trigui, I. Outage probability and capacity scaling law of multiple RIS-aided networks. IEEE Wirel. Commun. Lett. 2020, 10, 256–260. [Google Scholar] [CrossRef]
- Do, T.N.; Kaddoum, G.; Nguyen, T.L.; Da Costa, D.B.; Haas, Z.J. Multi-RIS-aided wireless systems: Statistical characterization and performance analysis. IEEE Trans. Commun. 2021, 69, 8641–8658. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Di Renzo, M.; Xiao, H.; Ai, B. Reconfigurable intelligent surfaces with outdated channel state information: Centralized vs. distributed deployments. IEEE Trans. Commun. 2022, 70, 2742–2756. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Gong, Y.; Wen, M.; Chambers, J.A. Deep reinforcement learning-based relay selection in intelligent reflecting surface assisted cooperative networks. IEEE Wirel. Commun. Lett. 2021, 10, 1036–1040. [Google Scholar] [CrossRef]
- Elhattab, M.; Arfaoui, M.A.; Assi, C.; Ghrayeb, A. Reconfigurable intelligent surface enabled full-duplex/half-duplex cooperative non-orthogonal multiple access. IEEE Trans. Wirel. Commun. 2021, 21, 3349–3364. [Google Scholar] [CrossRef]
- Zheng, B.; Zhang, R. IRS meets relaying: Joint resource allocation and passive beamforming optimization. IEEE Wirel. Commun. Lett. 2021, 10, 2080–2084. [Google Scholar] [CrossRef]
- Du, L.; Shao, S.; Yang, G.; Ma, J.; Liang, Q.; Tang, Y. Capacity characterization for reconfigurable intelligent surfaces assisted multiple-antenna multicast. IEEE Trans. Wirel. Commun. 2021, 20, 6940–6953. [Google Scholar] [CrossRef]
- Pan, C.; Ren, H.; Wang, K.; Xu, W.; Elkashlan, M.; Nallanathan, A.; Hanzo, L. Multicell MIMO communications relying on intelligent reflecting surfaces. IEEE Trans. Wirel. Commun. 2020, 19, 5218–5233. [Google Scholar] [CrossRef]
- Jia, Y.; Ye, C.; Cui, Y. Analysis and optimization of an intelligent reflecting surface-assisted system with interference. IEEE Trans. Wirel. Commun. 2020, 19, 8068–8082. [Google Scholar] [CrossRef]
- Ma, Z.; Wu, Y.; Xiao, M.; Liu, G.; Zhang, Z. Interference suppression for railway wireless communication systems: A reconfigurable intelligent surface approach. IEEE Trans. Veh. Technol. 2021, 70, 11593–11603. [Google Scholar] [CrossRef]
- Xia, X.; Xu, K.; Zhao, S.; Wang, Y. Learning the time-varying massive MIMO channels: Robust estimation and data-aided prediction. IEEE Trans. Veh. Technol. 2020, 69, 8080–8096. [Google Scholar] [CrossRef]
- Fleming, W.H.; Rishel, R.W. Deterministic and Stochastic Optimal Control; Springer Science & Business Media: New York, NY, USA, 2012; Volume 1. [Google Scholar]
- Cui, Q.; Zhao, X.; Ni, W.; Hu, Z.; Tao, X.; Zhang, P. Multi-Agent Deep Reinforcement Learning-Based Interdependent Computing for Mobile Edge Computing-Assisted Robot Teams. IEEE Trans. Veh. Technol. 2022, 72, 6599–6610. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, Z.; Jia, R.; Li, M. Visual tracking via hierarchical deep reinforcement learning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3315–3323. [Google Scholar]
- El-Bouri, R.; Eyre, D.; Watkinson, P.; Zhu, T.; Clifton, D. Student-teacher curriculum learning via reinforcement learning: Predicting hospital inpatient admission location. In Proceedings of the 37th International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 2848–2857. [Google Scholar]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power allocation in multi-user cellular networks: Deep reinforcement learning approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Cui, Q.; Hu, X.; Ni, W.; Tao, X.; Zhang, P.; Chen, T.; Chen, K.C.; Haenggi, M. Vehicular mobility patterns and their applications to Internet-of-Vehicles: A comprehensive survey. Sci. China Inf. Sci. 2022, 65, 1–42. [Google Scholar] [CrossRef]
- Yang, H.; Xiong, Z.; Zhao, J.; Niyato, D.; Xiao, L.; Wu, Q. Deep reinforcement learning-based intelligent reflecting surface for secure wireless communications. IEEE Trans. Wirel. Commun. 2020, 20, 375–388. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H.F. Deep reinforcement learning based resource allocation for V2V communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef] [Green Version]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning (PMLR), New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086. [Google Scholar]
- Pitis, S. Rethinking the discount factor in reinforcement learning: A decision theoretic approach. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7949–7956. [Google Scholar]
- Amit, R.; Meir, R.; Ciosek, K. Discount factor as a regularizer in reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 269–278. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited on 2012, 14, 2. [Google Scholar]
- Xu, J.; Ai, B.; Quek, T.Q.; Liuc, Y. Deep reinforcement learning for interference suppression in RIS-aided high-speed railway networks. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 337–342. [Google Scholar]
- Zhu, Y.; Li, M.; Liu, Y.; Liu, Q.; Chang, Z.; Hu, Y. DRL-based joint beamforming and BS-RIS-UE association design for RIS-assisted mmWave networks. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 345–350. [Google Scholar]
- Mei, H.; Yang, K.; Liu, Q.; Wang, K. 3D-trajectory and phase-shift design for RIS-assisted UAV systems using deep reinforcement learning. IEEE Trans. Veh. Technol. 2022, 71, 3020–3029. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, R. On the capacity of intelligent reflecting surface aided MIMO communication. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 2977–2982. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Sun, M.; Cui, Q.; Chen, K.-C.; Liao, Y. RIS-Aided Proactive Mobile Network Downlink Interference Suppression: A Deep Reinforcement Learning Approach. Sensors 2023, 23, 6550. https://doi.org/10.3390/s23146550
Wang Y, Sun M, Cui Q, Chen K-C, Liao Y. RIS-Aided Proactive Mobile Network Downlink Interference Suppression: A Deep Reinforcement Learning Approach. Sensors. 2023; 23(14):6550. https://doi.org/10.3390/s23146550
Chicago/Turabian StyleWang, Yingze, Mengying Sun, Qimei Cui, Kwang-Cheng Chen, and Yaxin Liao. 2023. "RIS-Aided Proactive Mobile Network Downlink Interference Suppression: A Deep Reinforcement Learning Approach" Sensors 23, no. 14: 6550. https://doi.org/10.3390/s23146550
APA StyleWang, Y., Sun, M., Cui, Q., Chen, K. -C., & Liao, Y. (2023). RIS-Aided Proactive Mobile Network Downlink Interference Suppression: A Deep Reinforcement Learning Approach. Sensors, 23(14), 6550. https://doi.org/10.3390/s23146550