
Alignment Integration Network for Salient Object Detection and Its Application for Optical Remote Sensing Images


Abstract
:1. Introduction
- We propose an alignment integration network (ALNet) to alleviate the misalignment problem in multi-level feature fusion, thereby generating effective representation for salient object detection.
- Strip attention is introduced into our network to augment global contextual information for the high-level integrated features as well as keep computational efficiency.
- To make the network focus more on the boundary and error-prone regions, we propose a boundary enhancement module and an attention weighted loss function to help the network generate results with sharper boundaries.
- Experimental results on SOD benchmarks as well as remote sensing datasets demonstrate the effectiveness and scalability of the proposed ALNet.
2. Related Work
2.1. Integrating Multi-Level Features for SOD
2.2. Boundary Learning for SOD
3. Materials and Methods
3.1. Pre-Process Module
3.2. Alignment Integration Module
3.2.1. Offset Generation
3.2.2. Feature Alignment
3.2.3. Aligned Integration
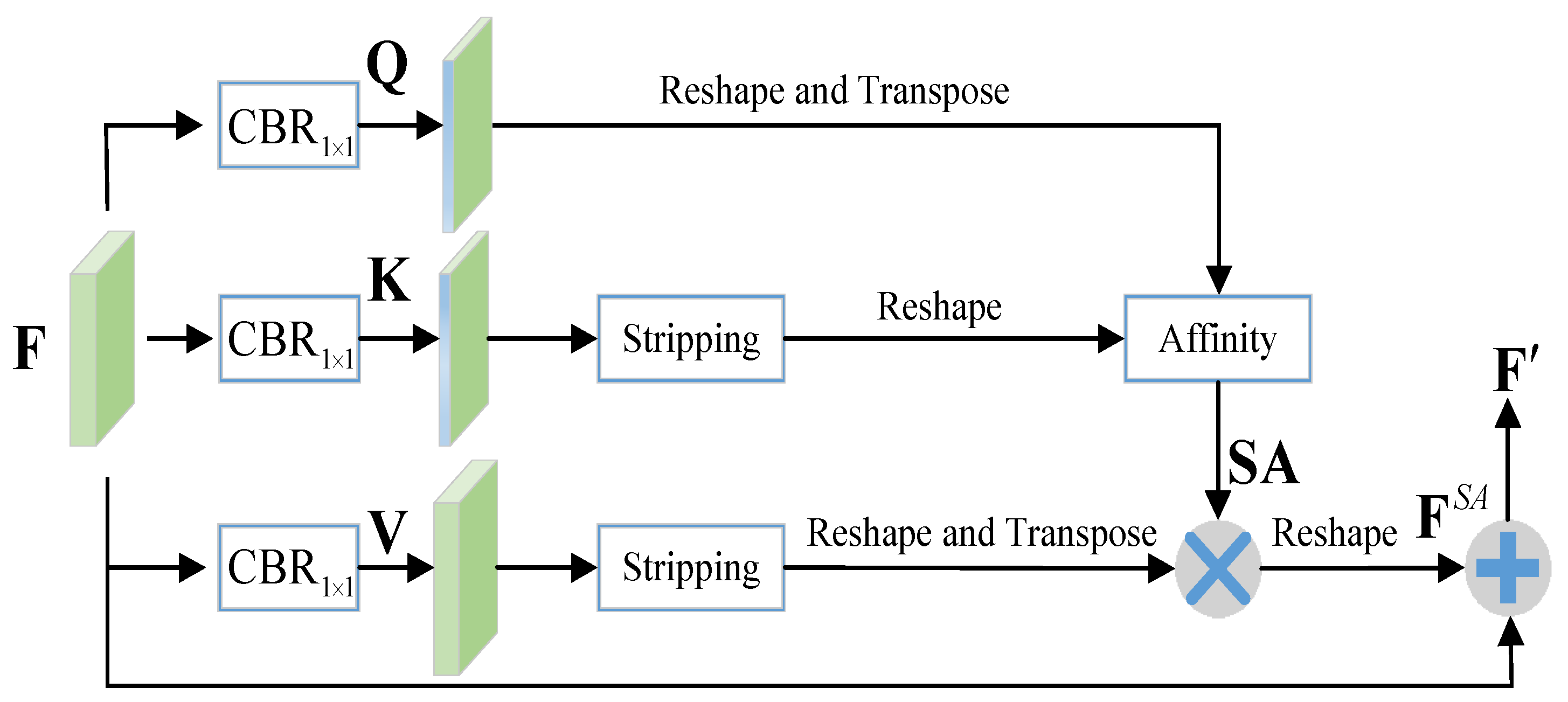
3.2.4. Strip Attention Module
3.3. Boundary Enhancement Module
3.4. Supervision Strategy
4. Results
4.1. Datasets
4.2. Metrics
4.3. Implementation Details
4.4. Comparison to State-of-the-Art Methods
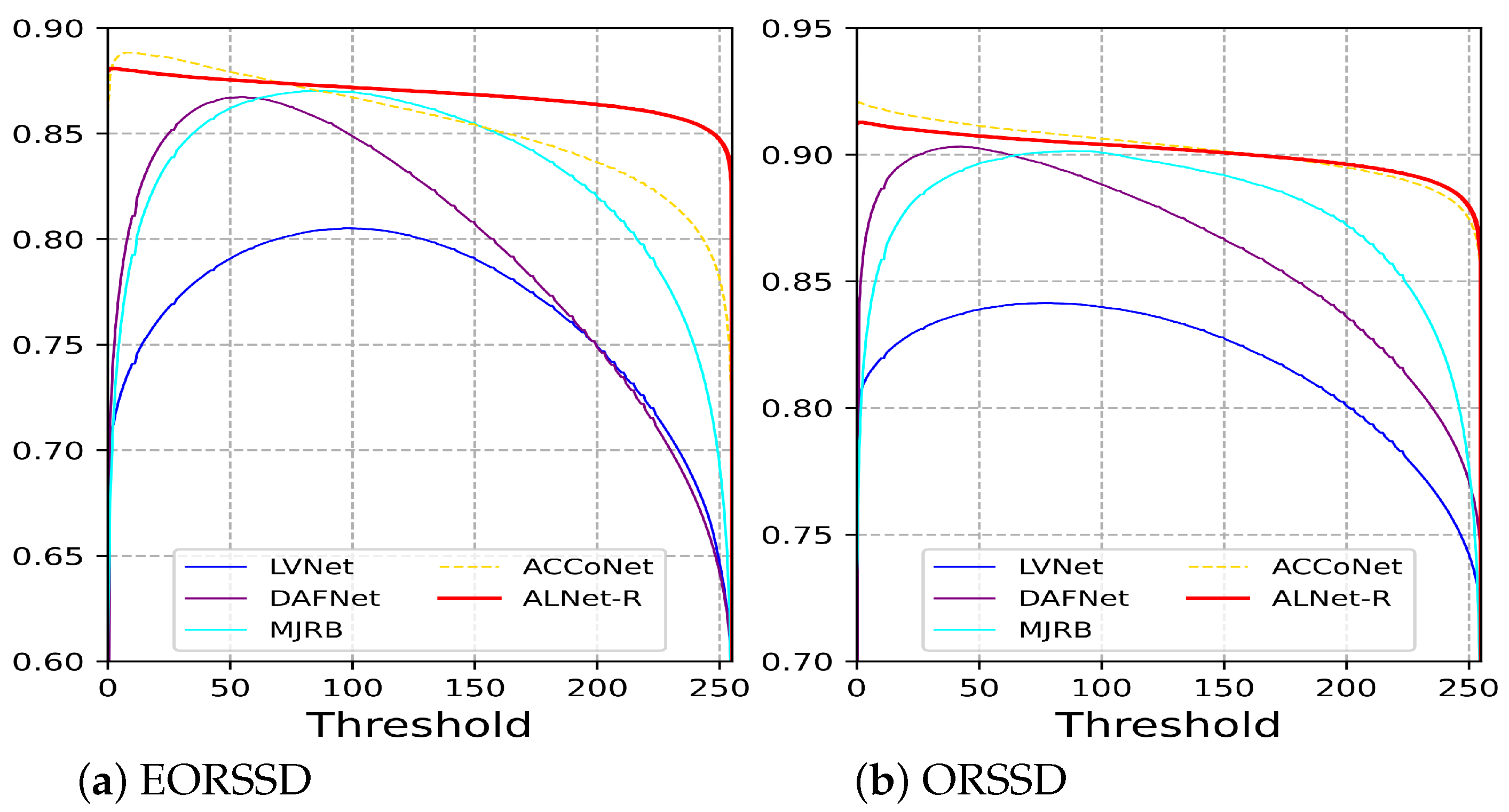
4.5. Extension Experiment on the Remote-Sensing Datasets
5. Discussion
5.1. Effectiveness of Feature Alignment
5.2. Effectiveness of SAM
5.3. Effectiveness of BEM
5.4. Failure Cases
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, D.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.-M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Yang, X.; Qian, X.; Xue, Y. Scalable mobile image retrieval by exploring contextual saliency. IEEE Trans. Image Process. 2015, 24, 1709–1721. [Google Scholar] [CrossRef] [PubMed]
- Mahadevan, V.; Vasconcelos, N. Biologically inspired object tracking using center-surround saliency mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 541–554. [Google Scholar] [CrossRef] [Green Version]
- Borji, A.; Frintrop, S.; Sihite, D.N.; Itti, L. Adaptive object tracking by learning background context. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 23–30. [Google Scholar]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. Bes-net: Boundary enhancing semantic context network for high-resolution image semantic segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]
- Zhao, K.; Han, Q.; Zhang, C.; Xu, J.; Cheng, M. Deep hough transform for semantic line detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4793–4806. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.-H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Zhu, L.; Chen, J.; Hu, X.; Fu, C.-W.; Xu, X.; Qin, J.; Heng, P.-A. Aggregating attentional dilated features for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3358–3371. [Google Scholar] [CrossRef]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- Wang, W.; Shen, J.; Cheng, M.-M.; Shao, L. An iterative and cooperative top-down and bottom-up inference network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5968–5977. [Google Scholar]
- Wang, W.; Shen, J.; Dong, X.; Borji, A.; Yang, R. Inferring salient objects from human fixations. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1913–1927. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Zhao, J.; Liu, J.; Fan, D.; Cao, Y.; Yang, J.; Cheng, M. Egnet:edge guidance network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7264–7273. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and balance: A simple gated network for salient object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–51. [Google Scholar]
- Chen, Z.; Xu, Q.; Cong, R.; Huang, Q. Global context-aware progressive aggregation network for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10599–10606. [Google Scholar]
- Zhou, H.; Xie, X.; Lai, J.; Chen, Z.; Yang, L. Interactive two-stream decoder for accurate and fast saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9141–9150. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Sun, L.; Chen, Z.; Wu, Q.J.; Zhao, H.; He, W.; Yan, X. Ampnet: Average-and max-pool networks for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4321–4333. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, T.; Piao, Y.; Yao, S.; Lu, H. Auto-msfnet: Search multi-scale fusion network for salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 667–676. [Google Scholar]
- Hu, X.; Fu, C.-W.; Zhu, L.; Wang, T.; Heng, P.-A. Sac-net: Spatial attenuation context for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1079–1090. [Google Scholar] [CrossRef]
- Hussain, R.; Karbhari, Y.; Ijaz, M.F.; Woźniak, M.; Singh, P.K.; Sarkar, R. Revise-net: Exploiting reverse attention mechanism for salient object detection. Remote Sens. 2021, 13, 4941. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Liu, B.; Wang, Z. Semantic-guided attention refinement network for salient object detection in optical remote sensing images. Remote Sens. 2021, 13, 2163. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Q.; Zhao, R. Progressive dual-attention residual network for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5902–5915. [Google Scholar] [CrossRef]
- Zhang, Q.; Duanmu, M.; Luo, Y.; Liu, Y.; Han, J. Engaging part-whole hierarchies and contrast cues for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3644–3658. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual saliency transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhuge, M.; Fan, D.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3738–3752. [Google Scholar] [CrossRef]
- Mei, H.; Liu, Y.; Wei, Z.; Zhou, D.; Wei, X.; Zhang, Q.; Yang, X. Exploring dense context for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1378–1389. [Google Scholar] [CrossRef]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3239–3259. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tan, S.; Tong, Y. Semantic flow for fast and accurate scene parsing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 775–793. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Song, Q.; Mei, K.; Huang, R. Attanet: Attention-augmented network for fast and accurate scene parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2567–2575. [Google Scholar]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef] [Green Version]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. Orsi salient object detection via multiscale joint region and boundary model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, June 2001; pp. 282–289. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Bokhovkin, A.; Burnaev, E. Boundary loss for remote sensing imagery semantic segmentation. In Proceedings of the International Symposium on Neural Networks, Moscow, Russia, 10–12 July; Springer: Berlin/Heidelberg, Germany, 2019; pp. 388–401. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Boer, P.-T.D.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Borse, S.; Wang, Y.; Zhang, Y.; Porikli, F. Inverseform: A loss function for structured boundary-aware segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5901–5911. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20—25 June 2009; pp. 1597–1604. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Perazzi, F.; Krahenbuhl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Guo, M.H.; Lu, C.; Hou, Q.; Liu, Z.; Cheng, M.; Hu, S. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. Neural Netw. Tricks Trade 2012, 7700, 421–436. [Google Scholar]
- Tay, F.E.H.; Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MACs | Params | ECSSD | HKU-IS | PASCAL-S | DUTS | DUT-OMRON | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG based Backbone | ||||||||||||||||||||||
| PAGENet (2019) | – | – | 0.904 | 0.886 | 0.042 | 0.936 | 0.884 | 0.865 | 0.037 | 0.935 | 0.811 | 0.783 | 0.076 | 0.878 | 0.793 | 0.769 | 0.052 | 0.883 | 0.743 | 0.722 | 0.062 | 0.849 |
| AFNet (2019) | 21.66 | 35.95 | 0.905 | 0.886 | 0.042 | 0.935 | 0.888 | 0.869 | 0.036 | 0.934 | 0.824 | 0.797 | 0.070 | 0.883 | 0.812 | 0.785 | 0.046 | 0.893 | – | – | – | – |
| ASNet (2020) | – | – | 0.890 | 0.865 | 0.047 | 0.926 | 0.873 | 0.846 | 0.041 | 0.923 | 0.817 | 0.784 | 0.070 | 0.882 | 0.760 | 0.715 | 0.061 | 0.854 | – | – | – | – |
| ALNet-V | 48.24 | 15.95 | 0.928 | 0.915 | 0.033 | 0.950 | 0.920 | 0.910 | 0.027 | 0.956 | 0.836 | 0.815 | 0.064 | 0.900 | 0.853 | 0.836 | 0.037 | 0.921 | 0.765 | 0.744 | 0.056 | 0.864 |
| ResNet50 based Backbone | ||||||||||||||||||||||
| PS (2019) | – | – | 0.904 | 0.881 | 0.041 | 0.937 | 0.883 | 0.856 | 0.038 | 0.933 | 0.814 | 0.780 | 0.071 | 0.883 | 0.804 | 0.762 | 0.048 | 0.892 | 0.760 | 0.730 | 0.061 | 0.867 |
| CPD (2019) | 17.7 | 47.85 | 0.913 | 0.898 | 0.037 | 0.942 | 0.892 | 0.875 | 0.034 | 0.938 | 0.819 | 0.794 | 0.071 | 0.882 | 0.821 | 0.795 | 0.043 | 0.898 | 0.742 | 0.719 | 0.056 | 0.847 |
| BASNet (2019) | 127.36 | 87.06 | 0.917 | 0.904 | 0.037 | 0.943 | 0.902 | 0.889 | 0.032 | 0.943 | 0.818 | 0.793 | 0.076 | 0.879 | 0.822 | 0.803 | 0.048 | 0.895 | 0.767 | 0.751 | 0.056 | 0.865 |
| EGNet (2019) | 157.21 | 111.69 | 0.918 | 0.903 | 0.037 | 0.943 | 0.902 | 0.887 | 0.031 | 0.944 | 0.823 | 0.795 | 0.074 | 0.881 | 0.839 | 0.815 | 0.039 | 0.907 | 0.760 | 0.738 | 0.053 | 0.857 |
| SCRN (2019) | 15.09 | 25.23 | 0.916 | 0.900 | 0.037 | 0.939 | 0.894 | 0.876 | 0.034 | 0.935 | 0.833 | 0.807 | 0.063 | 0.892 | 0.833 | 0.803 | 0.040 | 0.900 | 0.749 | 0.720 | 0.056 | 0.848 |
| F3Net (2020) | 16.43 | 25.54 | 0.924 | 0.912 | 0.033 | 0.948 | 0.910 | 0.900 | 0.028 | 0.952 | 0.835 | 0.816 | 0.061 | 0.898 | 0.851 | 0.835 | 0.035 | 0.920 | 0.766 | 0.747 | 0.053 | 0.864 |
| GateNet (2020) | 162.13 | 128.63 | 0.913 | 0.894 | 0.040 | 0.936 | 0.897 | 0.880 | 0.033 | 0.937 | 0.826 | 0.797 | 0.067 | 0.886 | 0.837 | 0.809 | 0.040 | 0.906 | 0.757 | 0.729 | 0.055 | 0.855 |
| GCPANet (2020) | 54.31 | 67.06 | 0.916 | 0.903 | 0.035 | 0.944 | 0.901 | 0.889 | 0.031 | 0.944 | 0.829 | 0.808 | 0.062 | 0.895 | 0.841 | 0.821 | 0.038 | 0.911 | 0.756 | 0.734 | 0.056 | 0.853 |
| ITSD (2020) | 15.96 | 26.47 | 0.921 | 0.910 | 0.034 | 0.947 | 0.904 | 0.894 | 0.031 | 0.947 | 0.831 | 0.812 | 0.066 | 0.894 | 0.840 | 0.823 | 0.041 | 0.913 | 0.768 | 0.750 | 0.061 | 0.865 |
| MINet (2020) | 87.11 | 126.38 | 0.923 | 0.911 | 0.033 | 0.950 | 0.909 | 0.897 | 0.029 | 0.952 | 0.830 | 0.809 | 0.064 | 0.896 | 0.844 | 0.825 | 0.037 | 0.917 | 0.757 | 0.738 | 0.056 | 0.860 |
| A-MSF (2021) | 17.5 | 32.5 | 0.927 | 0.916 | 0.033 | 0.951 | 0.912 | 0.903 | 0.027 | 0.956 | 0.842 | 0.822 | 0.061 | 0.901 | 0.855 | 0.841 | 0.034 | 0.928 | 0.772 | 0.757 | 0.050 | 0.873 |
| DCENet (2022) | 59.78 | 192.96 | 0.924 | 0.913 | 0.035 | 0.948 | 0.908 | 0.898 | 0.029 | 0.951 | 0.845 | 0.825 | 0.061 | 0.902 | 0.849 | 0.833 | 0.038 | 0.918 | 0.769 | 0.753 | 0.055 | 0.865 |
| ICON-R (2023) | 20.91 | 33.09 | 0.928 | 0.918 | 0.032 | 0.954 | 0.912 | 0.902 | 0.029 | 0.953 | 0.838 | 0.818 | 0.064 | 0.899 | 0.853 | 0.836 | 0.037 | 0.924 | 0.779 | 0.761 | 0.057 | 0.876 |
| ALNet-R | 19.82 | 28.46 | 0.932 | 0.923 | 0.030 | 0.955 | 0.921 | 0.913 | 0.026 | 0.959 | 0.843 | 0.826 | 0.059 | 0.907 | 0.860 | 0.847 | 0.035 | 0.928 | 0.778 | 0.761 | 0.055 | 0.874 |
| Attention based Backbone | ||||||||||||||||||||||
| VST-T2 (2021) | 23.16 | 44.63 | 0.920 | 0.910 | 0.033 | 0.951 | 0.907 | 0.897 | 0.029 | 0.952 | 0.835 | 0.816 | 0.061 | 0.902 | 0.845 | 0.828 | 0.037 | 0.919 | 0.774 | 0.755 | 0.058 | 0.871 |
| ICON-S (2023) | 52.59 | 94.30 | 0.940 | 0.936 | 0.023 | 0.966 | 0.929 | 0.925 | 0.022 | 0.968 | 0.865 | 0.854 | 0.048 | 0.924 | 0.893 | 0.886 | 0.025 | 0.954 | 0.815 | 0.804 | 0.043 | 0.900 |
| ALNet-MS | 15.14 | 27.45 | 0.943 | 0.938 | 0.024 | 0.964 | 0.936 | 0.932 | 0.020 | 0.969 | 0.866 | 0.851 | 0.051 | 0.922 | 0.899 | 0.893 | 0.024 | 0.955 | 0.817 | 0.806 | 0.043 | 0.903 |
| Methods | Backbone | EORSSD | ORSSD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| LVNet (2019) | VGG | 0.736 | 0.702 | 0.015 | 0.882 | 0.800 | 0.775 | 0.021 | 0.926 |
| DAFNet (2021) | ResNet | 0.784 | 0.783 | 0.006 | 0.929 | 0.851 | 0.844 | 0.011 | 0.954 |
| MJRB (2022) | ResNet | 0.806 | 0.792 | 0.010 | 0.921 | 0.857 | 0.842 | 0.015 | 0.939 |
| ACCoNet (2023) | ResNet | 0.846 | 0.852 | 0.007 | 0.966 | 0.895 | 0.896 | 0.009 | 0.977 |
| ALNet-R | ResNet | 0.865 | 0.865 | 0.006 | 0.967 | 0.895 | 0.892 | 0.009 | 0.975 |
| Settings | ECSSD | PASCAL-S | DUTS | DUT-OMRON | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Effectiveness of Alignment | ||||||||||||
| w.o.Align | 0.898 | 0.883 | 0.043 | 0.814 | 0.790 | 0.070 | 0.808 | 0.787 | 0.045 | 0.727 | 0.701 | 0.063 |
| F-Align | 0.921 | 0.908 | 0.035 | 0.834 | 0.812 | 0.062 | 0.847 | 0.830 | 0.038 | 0.757 | 0.736 | 0.056 |
| D-Align | 0.923 | 0.910 | 0.034 | 0.837 | 0.816 | 0.062 | 0.852 | 0.835 | 0.037 | 0.766 | 0.747 | 0.056 |
| Effectiveness of SAM | ||||||||||||
| +SAM-ver | 0.928 | 0.917 | 0.032 | 0.838 | 0.818 | 0.063 | 0.859 | 0.845 | 0.035 | 0.777 | 0.758 | 0.054 |
| +SAM-hori | 0.924 | 0.912 | 0.033 | 0.841 | 0.822 | 0.061 | 0.856 | 0.842 | 0.036 | 0.773 | 0.755 | 0.056 |
| +BSAM | 0.927 | 0.916 | 0.032 | 0.837 | 0.818 | 0.064 | 0.854 | 0.839 | 0.037 | 0.768 | 0.749 | 0.062 |
| +SAM-ver-1 | 0.926 | 0.915 | 0.033 | 0.842 | 0.822 | 0.062 | 0.855 | 0.840 | 0.036 | 0.769 | 0.750 | 0.058 |
| +Non-Local | 0.924 | 0.912 | 0.034 | 0.837 | 0.815 | 0.064 | 0.852 | 0.835 | 0.037 | 0.772 | 0.752 | 0.055 |
| Effectiveness of BEM | ||||||||||||
| +BEM | 0.932 | 0.923 | 0.030 | 0.843 | 0.826 | 0.059 | 0.860 | 0.847 | 0.035 | 0.778 | 0.761 | 0.055 |
| w/o | 0.927 | 0.917 | 0.031 | 0.836 | 0.817 | 0.064 | 0.855 | 0.841 | 0.036 | 0.771 | 0.753 | 0.057 |
| w/o | 0.928 | 0.917 | 0.031 | 0.843 | 0.824 | 0.061 | 0.855 | 0.841 | 0.035 | 0.777 | 0.759 | 0.053 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yu, Y.; Wang, Y.; Chen, X.; Wang, C. Alignment Integration Network for Salient Object Detection and Its Application for Optical Remote Sensing Images. Sensors 2023, 23, 6562. https://doi.org/10.3390/s23146562
Zhang X, Yu Y, Wang Y, Chen X, Wang C. Alignment Integration Network for Salient Object Detection and Its Application for Optical Remote Sensing Images. Sensors. 2023; 23(14):6562. https://doi.org/10.3390/s23146562
Chicago/Turabian StyleZhang, Xiaoning, Yi Yu, Yuqing Wang, Xiaolin Chen, and Chenglong Wang. 2023. "Alignment Integration Network for Salient Object Detection and Its Application for Optical Remote Sensing Images" Sensors 23, no. 14: 6562. https://doi.org/10.3390/s23146562
APA StyleZhang, X., Yu, Y., Wang, Y., Chen, X., & Wang, C. (2023). Alignment Integration Network for Salient Object Detection and Its Application for Optical Remote Sensing Images. Sensors, 23(14), 6562. https://doi.org/10.3390/s23146562